Что такое системный вызов?
Системный вызов возникает, когда пользовательский процесс (наподобие emacs) требует некоторой службы, реализуемой ядром (такой как открытие файла), и вызывает специальную функцию (например, open). В этот момент пользовательский процесс переводится в режим ожидания. Ядро анализирует запрос, пытается его выполнить и передает результаты пользовательскому процессу, который затем возобновляет свою работу. Несколько ниже весь механизм будет рассматриваться более подробно.
Системные вызовы в общем случае защищают доступ к ресурсам, которыми управляет ядро, при этом самые большие категории системных вызовов имеют дело с вводом/выводом (open, close, read, write, poll и многие другие), процессами (fork, execve, kill и т.д.), временем (time, settimeofday и т.п.) и памятью (mmap, brk и пр.) Под это категории подпадают практически все системные вызовы.
Однако за сценой системный вызов может и не оказаться тем, чем выглядит. Во-первых, библиотека С в Linux реализует некоторые системные вызовы полностью в терминах других системных вызовов. Например, реализация waitpid сводится к простому вызову wait4, однако в документации на обе функции ссылаются как на системные вызовы. Другие, более традиционные системные вызовы, наподобие sigmask и ftime, реализованы почти полностью в библиотеке С, а не в ядре Linux.
Разумеется, подобная ловкость рук вполне безобидна, поскольку с точки зрения приложения системный вызов выглядит как вызов любой другой функции; до тех пор пока результаты получаются необходимым образом, приложение не в состоянии сказать, что и как привлекает ядро в каждом конкретном случае. (Имеет место даже скрытый выигрыш: пользователи обращаются напрямую к меньшему объему кода ядра, что минимизирует проблемы, связанные с нарушением безопасности.) Однако беспорядок, появляющийся в результате подобных фокусов, может существенно усложнить обсуждение. На практике термин «системный» вызов зачастую означает любой системный вызов в первой версии Unix, используемой тем, кто о нем говорит! Однако, в данной главе нас будут интересовать только «истинные» системные вызовы — то есть те, которые имеют дело с пользовательским процессом, обращающимся к определенному коду ядра.
Системный вызов должен возвращать значение типа int и только int. В соответствие с принятыми соглашениями, возвращаемое значение равно 0 или любому положительному числу в случае успеха и любому отрицательному числу в случае неудачи. Ветеранам программирования на С хорошо известно, что в случае, когда какая-либо функция из стандартной библиотеки С завершается неудачей, она устанавливает глобальную целочисленную переменную errno для отражения природы возникшей ошибки; те же соглашения актуальны и для системных вызовов. Однако, способы, в соответствие с которыми это происходит в случае с системными вызовами, невозможно предугадать, изучая лишь исходный код ядра. В случае сбоя системные вызовы возвращают отрицательные значения кодов ошибок, а за оставшуюся обработку отвечает стандартная библиотека С. (В нормальных ситуациях системные функции ядра не вызываются непосредственно из пользовательского кода, а через тонкий слой кода в рамках стандартной библиотеки С, который в точности ответственен за подобного рода трансляцию.) Взглянем для примера на строку (часть sys_nanosleep), возвращающую -EINVAL для указания на то, что передаваемое значение выходит за пределы допустимого диапазона. Код в стандартной библиотеке С, ответственный за вызов sys_nanosleep, замечает отрицательное возвращаемое значение, устанавливает errno в EINVAL, а сам возвращает –1 вызывающему коду.
Так сложилось, что в недавних версиях ядра отрицательные значения возврата из системных вызовов больше не указывают на наличие ошибки. Несколько системных вызовов (подобных lseek) реализованы таким образом, что они даже в случае успеха возвращают большие отрицательные значения; в настоящий момент возвращаемые значения, соответствующие ошибке, лежат в пределах от –1 до –4095. Теперь стандартная библиотека С более искушена в интерпретации значений возврата из системных вызовов — собственно ядро при получении отрицательных значений возврата не предпринимает никаких особых действий.
Системные вызовы
В большинстве книг, посвященных внутренностям Unix, системным вызовам уделяется относительно небольшое внимание. Я считаю это в корне неверным. Разумеется, мы уже располагаем достаточно обильной информацией, необходимой для понимания системных вызовов, поэтому заниматься исследованием их реализации совершенно лишено смысла. В конце концов, если вы собираетесь содействовать развитию ядра Linux, то найдутся более предпочтительные области для приложения ваших талантов.
Однако принимая во внимание наши цели, время, затраченное на детальное рассмотрение нескольких системных вызовов, окупится с лихвой. Это хорошая возможность познакомиться с некоторыми концепциями, которые будут детально рассматриваться в книге, такими как обработка процессов и управление памятью. Кроме того, появляется реальный шанс изучить природу программирования под Linux, которая может существенно отличаться от того, что вы знали раньше. Программирование под Linux — это непрекращающееся сражение между тремя концепциями — быстродействием, корректностью и ясностью, причем одновременно победителями все вместе они стать не могут (правда, иногда бывают и исключения).
Linux поддерживает стандарт, именуемый Intel
Linux поддерживает стандарт, именуемый Intel Binary Compatibility Specification, версия2 (iBCS2, Спецификация двоичной совместимости Intel). (To, что в названии стандарта 1BCS2 буква i является строчной, а не прописной, сделано явно умышленно, однако никаких официальных объяснений сему факту не имеется; скорее всего, это объясняется попыткой согласовать название стандарта с принятой практикой именования процессоров Intel: i386, i486 и т.д.) Спецификация iBCS2 распределяет стандартный интерфейс ядра для приложений по всем базирующимся на Unix системам, куда относятся не только Linux, но и ряд бесплатных Unix-подобных систем для процессоров х86 (таких как FreeBSD), Solaris/x86, SCO Unix и т.п. Стандартный интерфейс делает возможным запуск двоичного представления коммерческого программного обеспечения, которое разрабатывалось для других Unix-подобных систем, на компьютере с установленным Linux и наоборот (причем в последнее время это «наоборот» случается все чаще и чаще). Например, двоичное представление Corel WordPerfect для SCO Unix, за счет соответствия стандарту iBCS2, отлично работает под Linux, даже не имея специальной версии для Linux.
Стандарт iBCS2 имеет несколько компонентов, одна из которых представляет особый интерес для нас: каким образом достигается непротиворечивая обработка системных вызовов в различных модификациях Unix. Это становится возможным благодаря наличию шлюза вызовов lcall7. lcall7 представляет собой достаточно простую (особенно по сравнению с system_call) ассемблерную функцию, которая всего лишь отыскивает С-функцию, занимающуюся соответствующей обработкой, и передает ей все полномочия по совершению требуемых действий. Шлюз вызовов (call gate) — это возможность, заложенная в процессоры х86, позволяющая пользовательским задачам обращаться к коду ядра безопасным и управляемым способом. Шлюз вызовов устанавливается в строке .
В нескольких первых строках выполняется настройка стека ЦП, чтобы он выглядел так, как того ожидает system_call.
Опять-таки подобно system_call, lcall7 получает указатель на текущую задачу в регистре ЕВХ. Что несколько удивляет, так это то, что способ реализации не такой, как в system_call. Три строки кода, начиная с , эквивалентны следующим двум строкам:
pushl %esp GET_CURRENT(%ebx)
Это не будет выполняться быстрее, поскольку после подстановки макроса получатся те же три команды, но в другом порядке. Однако, все выглядело бы в большей степени согласованно, и скорее всего, более понятно.
Получение указателя на поле exec_domain текущей задачи, использование этого поля для поиска указателя на соответствующий обработчик lcall7 и вызов найденного обработчика.
Области выполнения детально в книге не рассматриваются, однако следует знать что они используются ядром для реализации части стандарта iBCS2. В строке находится определение struct exec_domain. Область выполнения по умолчанию default_exec_domam (строка ) содержит стандартный обработчик lcall7 — no_lcall7 (см. строку ), который ведет себя подобно разновидности Unix под названием SVR4, отправляя вызываемому процессу сигнал нарушения сегментации.
Переход на метку ret_from_sys_call (строка , принадлежащая функции system_call) для завершения обработки и возврата так, как будто это представляет собой обычный системный вызов.
Прерывания, пространство пользователя и пространство ядра
Понимание этих концепций будет углубляться в , когда будут рассматриваться прерывания, и в при изучении памяти. Здесь же потребуется разобраться лишь с несколькими терминами.
Первый термин — прерывания (interrupts), которые поступают в двух разновидностях: аппаратные, когда, например, диск сообщает о наличии у себя каких-либо данных (к тематике главы это не имеет никакого отношения), и программные, представляющие собой эквивалентный программный механизм. В ЦП х86 программные прерывания — это то, как пользовательский процесс сигнализирует ядру о необходимости совершения системного вызова (для этих целей используется прерывание 0x80, хорошо известное хакерам как INT 80h). Ядро реагирует на прерывание обращением к функции system_call (строка ), которая рассматривается чуть ниже.
Два других термина, пространство ядра и пространство пользователя, относятся к памяти, зарезервированной, соответственно, ядром и пользовательским процессом. Разумеется, множество пользовательских процессов обычно запускаются одновременно и свою память совместно не используют, тем не менее, память, используемая любым пользовательским процессом носит название «пространства пользователя». Как правило, ядро взаимодействует только с одним пользовательским процессом в каждый момент времени, поэтому на практике каких-либо коллизий не возникает.
Поскольку упомянутые области памяти являются независимыми и пользовательские процессы не могут осуществлять доступ ко всей области ядра, то ядро реализует доступ к области пользователя посредством макросов put_user (строка ) и get_user (строка ) и им родственных. Ввиду того что системные вызовы служат в качестве интерфейса между конкретным процессом и операционной системой, в среде которой они выполняются, системные вызовы должны обладать возможностями частого обращения к пользовательским областям. Именно поэтому подобного рода макросы постоянно присутствуют в системных вызовах. Они не нуждаются в передаче параметров по значениям, однако им необходимо, чтобы пользователь передавал указатель, с использованием которого производится запись и чтение.
Примеры системных вызовов
К этому моменту уже должно быть понятно, как активизируются системные вызовы, так что самое время рассмотреть несколько примеров совершения системных вызовов, дабы в полной мере ощутить изящество их работы. Следует заметить, что системный вызов foo практически всегда реализуется функцией ядра с именем sys_foo, хотя иногда внутренности функции переносятся во вспомогательную функцию do_foo.
Способы реализации системных вызовов
Системные вызовы задействуются в соответствие с двумя путями: использование функции system_call и шлюз вызовов lсаll7 (см. строку ). (Вы могли слышать и о другом механизме, связанном с применением функции syscall, который реализован в виде обращения к lcall7 — во всяком случае, для платформы х86 — потому-то он и не выделяется как особый метод.) В данном разделе главы рассматриваются оба метода.
Неплохо было бы уяснить, что сами по себе системные вызовы не заботятся, как их инициировали — вызовом system_call или вызовом lсаll7. Такого рода разделение системных вызовов от механизмов, которые делают их возможными, оказывается исключительно элегантным. Если по ряду причин добавляется другой метод активизации системных вызовов, возможность изменения собственно системных вызовов станет недоступной.
Перед знакомством с этим ассемблерным кодом следовало бы отметить, что последовательность операндов в командах диаметрально противоположна стандартной последовательности операндов, принятой для Intel. Несмотря на существование других синтаксических отличий, наиболее сильно дезориентирует именно обратная последовательность операндов. Если запомнить, что принятый в Intel синтаксис команды
mov eax,0
(которая заносит константу 0 в регистр ЕАХ) выглядит здесь как
movl $0,%еах
это будет правдой во всех отношениях. (Используемый в ядре синтаксис — это синтаксис ассемблера AT&T. Дополнительную информацию можно отыскать в документации GNU по ассемблеру.)
Sys_ni_syscall
sys_ni_syscall, вне всяких сомнений, представляет собой простейший системный вызов; он просто возвращает ошибку ENOSYS. Поначалу он выглядит бесполезным, однако это не так. Действительно, sys_ni_syscall занимает несколько позиций в sys_call_table и на то существует несколько причин. Во-первых, sys_ni_syscall находится в позиции0 (строка ) для того, чтобы в случае, когда ошибочный код вызывает system_call некорректно (скажем, без инициализации переменной, передаваемой в качестве аргумента), передавался 0. Не стоит в таких случаях прибегать к решительным мерам наподобие уничтожения процесса. (Нельзя предупредить возникновение ошибок, не отменив заодно и всю полезную функциональность.) Подобная практика использования элемента 0 с целью предохранения от упомянутых ошибок применяется в ядре повсеместно.
Кроме того, в доброй дюжине позиций таблицы явным образом присутствует sys_ni_syscall. Такие элементы представляют системные вызовы, которые из ядра были удалены. Один из примеров находится в строке , где имеет место устаревший системный вызов prof. Здесь нельзя помещать другие, «реальные» системные вызовы, поскольку некоторые старые исполняемые модули могут все еще обращаться к этим устаревшим вызовам. Как будет выглядеть программа, которая выполняет устаревший системный вызов, а в результате получает, скажем, окно открытия файлов?
В конечном итоге, sys_ni_syscall занимает все неиспользуемые позиции в конце таблицы; это устанавливается в строках с по , которые повторяют элемент необходимое количество раз с целью заполнения таблицы. Поскольку sys_ni_syscall просто возвращает код ошибки ENOSYS, обращение к sys_ni_syscall эквивалентно переходу на метку badsys в рамках system_call, таким образом эффект от использования номера системного вызова, расположенного в данных позициях таблицы, такой же как и в случае применения номера, лежащего за пределами таблицы. Следовательно, системные вызовы можно добавлять в таблицу (или удалять из нее) без изменений NR_syscalls, тем не менее, эффект будет таким, как если бы вносились изменения в NR_syscalls (во всяком случае, в рамках установленных пределов). Буквосочетание «ni» в имени sys_ni_syscall означает ни что иное, как «not implemented» (не реализовано).
В этой простой функции присутствует дескриптор asmlinkage, относящийся к специфике компилятора gcc. Он уведомляет компилятор, что функция не будет искать свои аргументы в регистрах (случай общепринятой оптимизации), поскольку она ожидает их в стеке ЦП. Вспомните последнее утверждение о том, что system_call работает с собственными первыми четырьмя аргументами, номером системного вызова и допускает до четырех дополнительных аргументов, которые передаются реальному системному вызову. Такое достигается за счет оставления своих аргументов (передаваемых в регистрах) в стеке. Все системные вызовы помечаются дескриптором asmlinkage, поэтому они ищут аргументы в стеке. Разумеется, что в случае с sys_ni_syscall это ничего не меняет, поскольку sys_ni_syscall не принимает каких-либо аргументов. Теперь-то вы уже знаете, о чем идет речь, когда перед функциями присутствует asmlinkage.
Sys_reboot
Если и есть в ядре места, способные привести к паранойе, так вот sys_reboot— несомненный лидер в этом отношении. И причина, в общем-то, неплохая: как гласит имя функции, она должна использоваться для перезагрузки компьютера. Кроме того, в зависимости от передаваемых аргументов, эта функция может останавливать компьютер, выключать его питание и разрешать либо запрещать использование комбинации клавиш Ctrl+Alt+Del для перезагрузки. При написании кода, использующего sys_reboot следует соблюдать особую осторожность и принимать во внимание замечание, находящееся выше данной строки кода. Это замечание гласит, что перед обращением к sys_reboot следует обязательно синхронизировать жесткие диски, иначе данные, хранящиеся в дисковом кэше будут потеряны.
Принимая во внимание возможные неприятные последствия для системы, sys_reboot требует указания нескольких магических аргументов, которые будут рассматриваться немного позже.
В случае игнорирования характеристики CAP_SYS_BOOT (строка ) возвращается код ошибки EPERM. Характеристики более подробно обсуждаются в , а сейчас достаточно упомянуть, что с их помощью реализуется метод проверки допустимых привилегий для конкретного пользователя.
А здесь — паранойя во всей своей красе! sys_reboot сравнивает аргументы magic1 и magic2 с магическими числами, определенными в строках с по . Идея заключается в том, что если функция sys_reboot вызывается случайно, то весьма нежелательно так же случайно получить значения из аргументов magic1 и magic2. Следует заметить, что это не рассматривается как мера по увеличению степени безопасности, но только как защита от небрежного использования.
Между прочим, упоминаемые магические числа не выбирались случайным образом. Первое число относительно очевидно — этакий каламбур из «feel dead» (чувствовать себя мертвым). На следующие три числа для максимального эффекта лучше смотреть в шестнадцатиричном виде: 0x28121969, 0x5121996 и 0x16041998. Они выглядят как день рождения супруги Линуса (или, возможно, кого-то из его родственников) и дни рождения двух его дочерей. Соответственно, это наводит на мысль, что с увеличением семьи Линуса, вероятность случайного вызова функции перезагрузки будет стремиться к уменьшению. Однако, я думаю, что жена его остановит до того, как он исчерпает возможности 32-разрядного пространства.
Запрос блокировки ядра, поэтому в каждый момент времени данный код будет выполнять только один процессор. Любой другой код, защищенный парой lock_kernel/unlock_kernel, для других процессоров не доступен. Для однопроцессорных компьютеров lock_kernel не делает ничего, действия же функции в случае мультипроцессорной системы описываются в .
В случае LINUX_REBOOT_CMD_RESTART функция sys_reboot обращается к списку функций в reboot_notifier_list, уведомляя их о том, что система перезагружается. В общем случае эти функции представляют собой часть модуля, для которого требуется выполнение определенных действий перед завершением работы системы. Кажется, что этот список не используется где-либо в ядре — по крайней мере, в рамках стандартного дистрибутива; возможно, его используют какие-то внешние модули. Во всяком случае, такой список существует и при необходимости им можно воспользоваться.
LINUX_REBOOT_CMD_RESTART и другие значения cmd определяются начиная со строки . Никакого скрытого смысла эти значения не несут; они установлены такими просто потому, что не должны возникать из-за всякого рода случайностей и не должны совпадать с другими значениями. (Самое интересное, что значение LINUX_REBOOT_CMD_CAD_OFF равно 0, а 0 относится как раз таким случайно возникающим значениям. Однако, поскольку LINUX_REBOOT_CMD_CAD_OFF просто запрещает использование комбинации клавиш Ctrl+Alt+Del для перезагрузки системы, случайное возникновение подобной ситуации считается «безопасным».)
После вывода предупредительного сообщения sys_reboot вызывает machine_restart (строка ) для перезапуска компьютера. Как можно заметить в строке , возврат из функции machine_restart никогда не происходит, тем не менее сразу за ее вызовом находится break.
Следует ли это рассматривать как классический стиль хорошего программирования? Пожалуй, да, и сейчас я кое-что добавлю. Файл kernel/sys.c относится к архитектурно-независимой части кода. Однако machine_restart, будучи явно архитектурно-зависимой, находится в архитектурно-зависимой части кода (файл arch/i386/kernel/process.c).
Следовательно, в зависимости от платформы, упомянутый код будет отличаться. В настоящий момент неизвестно, будут ли будущие реализации machine_restart характеризоваться отсутствием возврата; например, может случиться так, что перезагрузка запланируется, а участвующие аппаратные средства приведут к задержке на несколько минут, в то время как возврат из функции уже произойдет. Или рассмотрим более правдоподобную ситуацию, когда существуют определенные причины невозможности совершения перезагрузки, связанные с невозможностью сброса некоторых аппаратных средств, находящихся под контролем программного обеспечения.
На такого рода платформах будет иметь место возврат из machine_restart, таким образом подобная возможность должна учитываться в коде.
По такому случаю в официальном дистрибутиве существует, по крайней мере, одна версия, допускающая возврат из machine_restart — версия для m68k. Код отличается для различных версий m68k-компьютеров. Поскольку книга ориентируется на х86-компьютеры, более подробный анализ всех особенностей упомянутого кода здесь не приводится.
(В некоторых случаях machine_restart просто входит в бесконечный цикл, не перезагружая компьютер, но и не возвращаясь из функции.)
Сейчас самое время немного прерваться. Оказывается, что чем бы ни считалось все рассмотренное — простой привычкой или паранойей — все оно необходимо для обеспечения переносимости ядра.
Следующие два случая разрешают или запрещают перезагрузку с использованием нечестной комбинации клавиш Ctrl+Alt+Del (известной в миру как «вулканический удар по нервам», «прах хакера», или, наиболее понравившаяся мне, «трехпальцевый привет»). Здесь просто выполняется установка состояния глобального флажка C_A_D, определенного в строке и проверяемого в строке .
Этот случай подобен случаю LINUX_REBOOT_CMD_RESTART, но он останавливает систему, а не перезагружает ее. Отличие состоит только в обращении не к machine_restart, а к machine_halt (строка ), которая не предпринимает никаких действий для платформы х86, однако выполняет ощутимую работу по завершению работы системы для других платформ. Кроме того, здесь имеется план перехода на аварийный режим для компьютеров, которые не останавливаются при помощи machine_halt — выполняется обращение к функции do_exit (строка ), уничтожающей само ядро.
Здесь можно заметить знакомый шаблон. sys_reboot обесточивает компьютер, что практически то же самое, что и останов системы, за исключением вызова machine_power_off (строка ) для тех систем, которые обладают возможностью программного отключения электропитания.
Случай LINUX_REBOOT_CMD_RESTART2 — это одна из вариаций на известную тему. Здесь принимается команда, передаваемая в ASCII-строке, которая выражает способ, по которому компьютер должен завершать работу. Эта строка интерпретируется не функцией sys_reboot, a machine_restart; следовательно, строка, если она вообще присутствует, имеет отношение к платформо-зависимому коду. (Стоит, однако, заметить, что обычно имеется только один способ перезагрузки компьютера, поэтому эта дополнительная информация функцией machine_restart игнорируется.)
Вызывающая функция передала нераспознанную команду. sys_reboot не выполняет никаких действий и возвращает ошибку. Следовательно, даже если sys_reboot передает корректные магические числа в magic1 и magic2, нет необходимости в выполнении каких-либо действий.
sys_reboot получила допустимую команду. Если поток управления добирается до этого места, возможно, это одна из команд установки C_A_D, поскольку другие команды, как правило, останавливают или перезагружают компьютер. Во всех ситуациях sys_reboot просто разблокирует ядро и вернет значение 0, указывающее на успех.
Sys_sysinfo
Системный вызов имеет возможность вернуть только одно целочисленное значение (int). В том случае, когда требуется вернуть больший объем информации, придется прибегнуть к тем же ухищрениям, что имели место при передаче более четырех аргументов в системный вызов — к возврату информации через указатель на структуру. Хороший пример — это системный вызов sysinfo, который собирает статистику по использованным системным ресурсам.
Распределение в памяти и обнуление struct sysinfo (строка ), предназначенной для временного хранения возвращаемых значений. sys_sysinfo могла бы копировать каждое поле структуры по отдельности, однако это более медленный, неудобный и менее читабельный способ.
Запрещение прерываний. Более детальное описание можно найти в ; сейчас достаточно сказать, что это необходимо для сохранения используемых sys_sysinfo значений от изменений.
Поле uptime в структуре sysinfo хранит количество секунд, в течение которых работает система с момента запуска. Упомянутое значение вычисляется на основе jiffies (строка ), которая подсчитывает тики внутреннего таймера в течение работы системы, и HZ, представляющим собой системный параметр, равный количеству тиков внутреннего таймера в секунду.
Массив avenrun (строка ) хранит среднюю длину очереди выполнения (т.е. среднее количество процессов, готовых для передачи в ЦП) за последние 1, 5 и 15 секунд. Эти значения периодически пересчитываются за счет обращения к calc_load (строка ). Поскольку разработчики ядра сознательно избегали операций с плавающей точкой, вычисления производятся с фиксированной точкой, поэтому в них присутствует некоторая неточность.
Записывается общее количество процессов, присутствующих (и присутствовавших) в системе.
Функция si_meminfo (строка ) заполняет поля структуры, относящиеся к использованию оперативной памяти, в то время как si_swapinfo (строка ) — поля, фиксирующие статистику по использованию виртуальной памяти.
Заполнение структуры завершено. sys_sysinfo пытается скопировать ее обратно в пространство пользователя, возвращая 0 в случае успешного исхода и EFAULT — в случае ошибки.
Sys_time
sys_time представляет собой простой системный вызов, иллюстрирующий несколько важных концепций. Он реализует системный вызов time, который возвращает количество секунд, прошедших от полночи по универсальному времени 1 января 1970 г. Это число хранится в поле глобальной переменной xtime (см. строку ; она объявлена как volatile, поскольку модифицируется из прерывания, как будет показано в ) и доступ к нему организуется через макрос CURRENT_TIME (см. строку ).
Функция слепо следует своему простому объявлению. Вначале текущее время сохраняется в локальной переменной i.
Если получаемый указатель tloc не равен NULL, значение возврата будет также копироваться в место, определяемое этим указателем. Здесь присутствует одна тонкость — взамен обращения к макросу CURRENT_TIME переменная i просто копируется в пользовательское пространство. На то имеются две причины:
Определение макроса CURRENT_TIME в будущем может измениться, и эти новые версии могут оказаться более медленными, тогда как доступ к i был, есть и будет самым быстрым из возможных.
Подобный подход гарантирует получение непротиворечивых результатов: если так случится, что между строками и время изменится, sys_time скопирует одно значение, а вернет другое.
Небольшое удивление вызывает то, что эта часть кода не написана с использованием && вместо двух операторов if. Стандартная причина появления в ядре необычно выглядящего кода связана с повышением быстродействия, однако поскольку gcc генерирует одинаковый код для случаев && и двух if, в данной ситуации она не применима, если только упомянутый вид кода не связан со спецификой ранних версий gcc, в которых этот код разрабатывался.
Если sys_time не может получить доступ в передаваемое местоположение (чаще всего это связано с некорректным значением tloc), в i заносится -EFAULT и в строке производится возврат кода ошибки.
Возврат значения переменной i, которая содержит либо текущее время, либо -EFAULT.
System_call
System_call (строка )— это точка входа для всех системных вызовов (в случае родного рода; lcall7 используется для поддержки iBCS2). Как гласит находящийся выше комментарий, цель заключается в сохранении кода максимально последовательным без переходов, поэтому части функций разбросаны повсюду — общий поток управления усложнен ради исключения любых ветвлений. (Ветвления стоят того, чтобы их исключить, поскольку им присущи дополнительные накладные расходы. Они могут полностью разгрузить конвейер ЦП, отвергая внутренний параллелизм, который существенно повышает быстродействие современных процессоров.)
На рис. 5.1 показаны метки переходов, являющиеся частью system_call, а также направление потока управления между ними. Рисунок может оказаться полезным в плане настоящей дискуссии. Метки system_call и restore_all на этом рисунке изображены более крупным шрифтом, поскольку они представляют собой точки нормального входа и нормального выхода для данной функции.
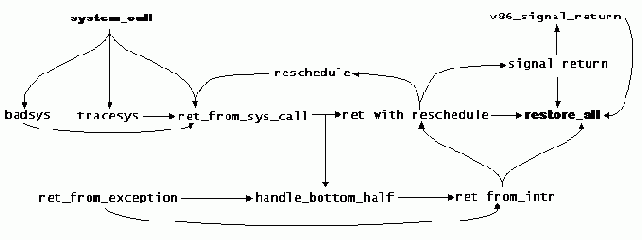
Рис. 5.1. Поток управления для system_call
System_call вызывается из стандартной библиотеки С, которая обеспечивает загрузку необходимых аргументов в регистры ЦП и последующий вызов прерывания 0x80. (Таким образом, system_call представляет собой обработчик прерываний.) В строке ядро регистрирует ассоциацию между программным прерыванием и функцией system_call (SYSCALL_VECTOR определен как 0x80 в строке ).
Читает указатель на текущую задачу из регистра ЕВХ. Это одно из немногих мест, где используется макрос, отвечающий за выполнение данных действий, GET_CURRENT (строка ). В подавляющем большинстве кода применяется функция get_current (строка ).
Начиная с этого места, выражения наподобие foo(%ebx) или foo(%esp) представляют собой код доступа к полям структуры, представляющей текущий процесс (struct task_struct в строке ), которая подробно рассматривается в . (Чтобы быть более точным, смещения относительно %ebx находятся в struct task_struct, а смещения относительно %esp — в struct pt_regs, связанной с struct task_struct. Однако, существующие различия здесь не важны.)
Превысил ли номер системного вызова (в регистре ЕАХ) свое максимальное значение? (Значение ЕАХ обрабатывается здесь как беззнаковое, поэтому оно не может быть отрицательным.) Если превышение имеет место, выполняется переход на badsys (строка ).
Отслеживаются ли системные вызовы? Программы, подобные strace, обеспечивают трассировку для особо заинтересованных разработчиков, а также дополнительную отладочную информацию — вы сможете сказать гораздо больше о такого рода программах после того, как с их помощью проследите за выполнением системных вызовов. В случае, если системные вызовы таки отслеживаются, управление передается tracesys (строка ).
Вызов системной функции. Здесь выполняются многие вещи. Во-первых, ничего не делающий макрос SYMBOL_NAME просто заменяется текстом его аргументов, поэтому его можно проигнорировать. sys_call_table определяется в конце файла arch/i386/kernel/entry.S, начиная со строки . Здесь расположена таблица указателей на функции ядра, которые реализуют разнообразные системные вызовы.
Второй набор скобок в строке содержит аргументы, разделенные запятыми (первый аргумент — пустой); все это необходимо для индексирования элементов в массиве. Разумеется, индексируется массив sys_call_table; он-то и носит название смещения. Три аргумента представляют базовый адрес массива, индекс (ЕАХ, в котором хранится номер системного вызова) и размер, который суть количество байт, приходящихся на каждый элемент массива (в данном случае 4). Поскольку базовый адрес массива пуст, он трактуется как 0, тем не менее, он добавляется к адресу смещения sys_call_table, что в конечном итоге приводит к тому, что sys_call_table рассматривается в качестве базового адреса массива. Данная строка эквивалентна следующему выражению на С:
/* Вызов функции в массиве функций. */ (sys_call_table[eax]) ();
Не следует забывать, что С обеспечивает выполнение черновой работы, такой как запоминание размера элементов массива. Кстати, аргументы, передаваемые в системный вызов, уже находятся в стеке, поскольку они передаются в system_call вызывающей функцией и записываются в стек при помощи SAVE_ALL.
Возврат из системного вызова. Возвращаемое значение (которое является также и возвращаемым значением system_call), находящееся в регистре ЕАХ, сохраняется. Значение возврата сохраняется в позиции ЕАХ стека, поэтому RESTORE_ALL имеет возможность восстановить актуальное значение регистра ЕАХ, равно как и других регистров.
Следующий код, будучи частью system_call, представляет собой отдельную точку входа, известную под именами ret_from_sys_call и ret_from_intr. Так получилось, что на эти точки производятся ссылки из system_call плюс они вызываются непосредственно из С.
Несколько следующих строк проверяют, активна ли «нижняя половина» (bottom half), и если это так, обеспечивают переход на метку handle_bottom_half (строка ) с целью обработки этой нижней (или отложенной) половины прерывания. Нижние половины являются частями процесса обработки прерываний и подробно рассматриваются в следующей главе.
Проверка, помечен ли процесс как такой, для которого должно повторно выполниться планирование (вспомните, что выражение $0 — ни что иное как константа 0). Если для процесса должно выполняться планирование, происходит переход на метку reschedule (строка ).
Проверка, задержан ли сигнал, и если так, то следующая строка выполнит переход непосредственно на signal_return (строка ).
Метка restore_all соответствует точке возврата для system_call. Весь код сводится к вызову макроса RESTORE_ALL (строка ), который восстанавливает аргументы, ранее сохраненные по SAVE_ALL, и возвращается в точку вызова system_call.
Метка signal_return достигается, когда до возврата из системного вызова system_call выясняет, что сигнал достиг текущего процесса. Все начинается с разрешения прерываний (см. ).
Если произошел возврат в виртуальный режим 8086 (в книге не рассматривается), выполняется переход на метку v86_signal_return (строка ).
system_call собирается вызвать С-функцию do_signal (строка , обсуждаемая в ) с целью доставки сигнала. do_signal ожидает два аргумента, передаваемые в регистрах; первый аргумент — это регистр ЕАХ, а второй — регистр EDX. system_call уже установила (в строке A HREF="part1_01.htm#l200">200) ЕАХ в значение, необходимое для первого аргумента; в данном случае выполняется операция XOR для регистра EDX, в результате чего он обнуляется, поэтому do_signal будет рассматривать его как указатель NULL.
Вызов do_signal с целью доставки сигнала и переход на restore_all (строка ) для завершения обработки.
Поскольку виртуальный режим 8086 не относится к тематике книги, в основном, v86_signal_return будет игнорироваться, Однако, следует отметить, что он подобен случаю signal_return.
Метка tracesys достигается в случае, если системные вызовы, присутствующие в текущем процессе, трассируются его родительским процессом, как это делается программой strace. Основная идея, заложенная в эту порцию кода, связана с вызовом системной функции через syscall_table (см. строку ), но с помещением вызова в скобки вместе с обращениями к функции syscall_trace. Последняя функция в книге не рассматривается; она останавливает текущий процесс и уведомляет соответствующий родительский процесс о необходимости активизации системного вызова.
Первым делом путаницу вносят чередующиеся с кодом манипуляции с ЕАХ. system_call устанавливает сохраненную в стеке копию ЕАХ в значение -ENOSYS, обращается к syscall_trace, восстанавливает значение ЕАХ на основе сохраненной в строке копии, выполняет реальный системный вызов и затем помещает значение возврата из системного вызова в стек по месту хранения ЕАХ, после чего еще раз вызывает syscall_trace.
Основная подоплека всего этого связана с тем, что syscal_trace (точнее, программа трассировки) должна знать, когда она вызывается — до или после реального системного вызова. Значение -ENOSYS можно использовать для отражения того, что обращение происходит перед реальным системным вызовом, поскольку ни одна из существующих систем не возвращает -ENOSYS. Следовательно, стековая копия ЕАХ будет равна -ENOSYS перед первым вызовом syscall_trace, но не будет равна упомянутому значению перед вторым вызовом (исключая обращение к sys_ni_syscall, когда о трассировке никто и не думает). Задействование ЕАХ в строках и просто отыскивают активизируемый системный вызов, как и в случае отсутствия трассировки.
Возврат их вызова системы трассировки; управление передается ret_from_sys_call (строка ), как и в случае, когда трассировка отсутствует.
Метка badsys достигается, когда передаваемый номер системного вызова выходит за пределы допустимых значений. В таком случае system_call должен вернуть -ENOSYS (значение ENOSYS устанавливается равным 38 в строке ). Как упоминалось ранее, вызывающая функция воспринимает это как ошибку, поскольку значение возврата попадает в диапазон между –1 и –4095.
Метка ret_from_exception достигается, когда имеют место прерывания в исключительных ситуациях ЦП, такие как ошибка деления на ноль (см. строку ); эта метка никогда не достигается из кода system_call. В случае активности «нижней половины» обеспечивается ее обслуживание.
Метка ret_from_intr достигается после обработки «нижней половины» либо когда имеет место случай возникновения исключительной ситуации ЦП. К данной метке имеется глобальный доступ из многих мест в ядре.
Сохраненные регистры ЦП EFLAGS и CS комбинируются в ЕАХ таким образом, что старших 24 разряда (в том числе и одно интересное значение VM_MASK, определенное в строке ) представляют EFLAGS, а младших 8 разрядов — из CS. Эта строка скрыто проверяет части обоих регистров одновременно, чтобы выяснить, вернулся ли процесс в виртуальный режим 8086 (часть VM_MASK) или в пользовательский режим (часть с константой 3 — пользовательский режим имеет уровень привилегий 3). Эквивалентный код на С выглядит следующим образом:
/* Скомпоновать в еах значения eflags и cs. */ еах = eflags & ~0xff; еах |= cs & 0xff; /* Проверить одновременно 2 младших разряда и разряд VM_MASK. */ if (еах & (VM_MASK | 3)) goto ret_with_reschedule; goto restore_all;
Если одно из двух условий оказывается истинным, управление передается на метку ret_with_reschedule (строка ) для выяснения того, следует ли выполнить повторное планирование для процесса перед возвратом из system_call. В противном случае system_call пропускает часть, относящаяся к повторному планированию, и переходит на метку restore_all (строка ), поскольку вызов был произведен задачей ядра.
Метка handle_bottom_half достигается всякий раз, когда в system_call имеется «нижняя половина». Все сводится к вызову функции С с именем do_bottom_half (строка ; см. ) и переходу на метку ret_from_intr (строка ).
Последний компонент system_call находится под меткой reschedule. Эта метка достигается, когда процесс, выполнивший системный вызов, помечен как такой, для которого необходимо выполнить повторное планирование; как правило, подобное происходит в случае, если выделенный для процесса квант времени исчерпан и ЦП следует отдать для других процессов. За подобного рода обработку отвечает функция С с именем schedule (строка ). Далее управление переходит на строку . Планированию процессов посвящена вся .
Calc_load
calc_load вызывается из верхней половины таймера и обновляет приближенное время загрузки системы. Функция, в основном, заинтересует тех, кто желает разобраться, как вычисляется это постоянно присутствующее в памяти число. Рассмотрим кратко данную функцию.
Статическая переменная count запоминает, сколько прошло с момента последнего вычисления среднего времени загрузки. Переменная инициализируется значением LOAD_FREQ, которое определяется в строке и означает число тиков таймера за пять секунд. Каждое обращение к этой функции приводит к увеличению количества тиков таймера, которые остаются до следующего вычисления загрузки.
Когда количество оставшихся тиков становится меньше 0, наступает время пересчета. (Я ожидал, что в данном случае должно было быть сравнение «меньше либо равно», однако на самом деле используется сравнение «строго меньше». Причина заключается в том, что на практике это различие оказывается весьма незначительным.)
После повторной инициализации count, которая «заведет» его на следующий пятисекундный интервал, функция count_active_tasks (строка ) выясняет количество задач, присутствующих в системе. Несмотря на то что реализация count_active_tasks особой сложностью не отличается, все же существует несколько вопросов, которые будут рассматриваться в .
Макрос CALC_LOAD, определенный в строке , применяется для обновления трех элементов массива avenrun (строка ), которые отслеживают загрузку системы за последние 5, 10 и 15 секунд. Как утверждалось в предыдущей главе, арифметика с плавающей запятой изгнана из ядра, поэтому вычисления производятся с фиксированной запятой.
Действия и IRQ
Небольшой, хорошо подобранный набор функций выполняет связывание и разрыв связи между действиями и IRQ. В этом разделе рассмотрены эти функции, а также функции, которые инициализируют систему IRQ в целом.
Dequeue_signal
Функция dequeue_signal изымает сигнал из сигнальной очереди процесса, пропуская те сигналы, которые определены mask. Функция возвращает номер сигнала и соответствующую siginfo_t через указатель info.
Установка нескольких псевдонимов во избежание повторных разыменований: s — это набор ожидающих сигналов для процесса (помните, что некоторые из них могут быть также и заблокированными), a m — маскирующий набор. В частности, выражение *s, несколько раз встречающееся в функции, — ни что иное как ускоренная версия current->signal.sig[0].
Внутри этого оператора switch значение sig устанавливается равным первому ожидающему сигналу. Этот простейший случай проще всего доступен для понимания; остальные случаи представляют собой лишь его обобщения.
Вот он простейший случай: поразрядная операция И между набором ожидающих сигналов и проинвертированной маской, после чего результат сохраняется во временной переменной х; теперь х представляет собой набор ожидающих сигналов, непроигнорированных маской. Если х не равно 0, значит, такой ожидающий сигнал существует (х содержит, по крайней мере, один установленный разряд); dequeue_signal получает соответствующий номер сигнала с использованием ffz (в книге не рассматривается) и приводит его к нумерации, начиная с 1. Результат сохраняется в sig. Как уже упоминалось, другие случаи являются просто обобщениями данного; важно только то, что в каждом из них sig получает набор — состояние же прочих переменных (i, s, m и х) с этого момента во внимание не принимается. Если после выполнения оператора switch значение sig равно 0, значит, при помощи маски не удалось найти ни одного ожидающего сигнала.
Если сигнал задерживается, dequeue_signal будет пытаться изъять его из очереди, reset отслеживает, удаляет ли dequeue_signal сигнал из очереди задержанных сигналов для процесса. Начальная установка reset в 1 — это просто предположение, что reset будет изменяться по мере выполнения функции.
Для сигналов не реального времени ядро не сохраняет оригинальную siginfo_t (даже если она существует), поэтому dequeue_signal придется реконструировать как можно больше информации. К сожалению, в данной реализации это не настоль много — только собственно номер сигнала. Остаток полей просто обнуляется.
В случае сигналов реального времени siginfo_t находится где-то рядом. В ее поисках dequeue_signal сканирует sigqueue процесса.
Если удается найти siginfo_t, dequeue_signal изымает сигнал из очереди, копирует siginfo_t сигнала в info и освобождает память, занятую элементом очереди.
Если очередь не содержит более ни одного экземпляра данного сигнала, это означает, что сигнал больше не является задержанным. Однако dequeue_signal все же проходит по очереди, убеждаясь, что это так. Эта функция сканирует элементы очереди на предмет присутствия в них других экземпляров данного сигнала. Если таковые найдены, dequeue_signal сбрасывает флаг reset — единственное условие завершения.
Из очереди изымался сигнал реального времени, однако он не найден в очереди задержанных сигналов для процесса по причинам, указанным в коде. Сейчас функция dequeue_signal ведет себя так же, как и по отношению к сигналу не реального времени (т.е. знает, что сигнал доступен, но не знает, где он размещается) и предпринимает те же действия по ответу, помещая в info только номер сигнала.
Если не сбросить флаг reset, сигнал обслуживается и удаляется из набора задержанных сигналов для процесса.
Сигнал вытолкнут из очереди, поэтому dequeue_signal должна пересчитать флаг sigpending процесса. Мне здесь видится возможность проведения небольшой оптимизации: dequeue_signal должна делать упомянутое действие только в случае истинного значения reset. recalc_sigpending подсчитывает ответы, полученные ею из наборов заблокированных и ожидающих сигналов для процесса; набор заблокированных сигналов не изменялся, поэтому dequeue_signal должна обращаться к recalc_sigpending лишь при изменении набора ожидающих сигналов. Если значение reset ложно, значит, не изменялся набор ожидающих сигналов, поэтому необходимость в вызове recalc_sigpending отпадает.
При помощи оператора switch не удалось найти ни одного сигнала, т.е. задержанных сигналов нет. Кроме того, в целях внутренней проверки корректности, dequeue_signal гарантирует, что ядро не думает, что сигнал задержан для задачи.
Возврат количества сигналов, изъятых из очереди, т.е. 0 означает их отсутствие.
Do_bottom_half
Функция do_bottom_half вызывается из трех точек в коде Linux: из строк , и , (Две из них, как можно заметить, находятся в архитектурно-зависимых файлах; эта функция вызывается также в соответствующих точках архитектурно-зависимых файлов для портов систем, отличных от х86,) Следовательно нижние половины обслуживаются при трех условиях:
При решении вопроса, какой процесс должен следующим получить доступ к центральному процессору.
При возврате из системного вызова.
Непосредственно перед возвратом из do_IRQ — т.е. после каждого прерывания. В примечании к коду отмечается, что возможно не всегда ядро будет здесь запускать нижние половины.
Для нижних половин желательно, чтобы одновременно могла выполняться только одна из них. Это свойство поддерживается здесь, в одном из мест, где блокировка имеет значение для кода однопроцессорных систем. Во-первых, вызывается функция softing_trylock (версия для однопроцессорных систем приведена в строке , а SMP-версия рассмотрена в ), которая устанавливает значение local_bh_count[cpu] равным 1 и выполняет возврат, только если оно первоначально было равным 0. Благодаря строке , для однопроцессорной машины значение переменной cpu всегда равно 0, и читатели должны были обратить внимание, что сама функция softing_trylock не может быть прервана, поскольку к этому моменту прерывания отключены. Функция softing_trylock и ее аналог softing_endlock (строка ) служат только одной цели: помочь убедиться в том, что нижние половины не прерываются другими нижними половинами (хотя они могут быть прерваны верхними половинами).
Если эта блокировка была получена, функция делает еще одну попытку: harding_trylock в строке . Эта функция всего лишь сообщает, находится ли выполнение внутри пары harding_enter/harding_exit (строки и ). Для однопроцессорной машины определения этих функций эквивалентны irq_enter и irq_exit (строки и ), которые используются в функции handle_IRQ_event, а также в ряде других мест. Эти макросы работают вместе, чтобы обеспечить надлежащую вложенность пар __cli и __sti — поскольку процессор не вкладывает их друг в друга, необходимо убедиться, что мы не выполняем __sti для __cli пользователя, который не ожидает этого.
Никто другой не выполняет нижние половины, и функция do_bottom_half имеет право включить аппаратные прерывания. Поэтому она включает аппаратные прерывания, выполняет нижние половины, а затем снова отключает прерывания.
Освобождает полученные функцией блокировки, после чего выполняет возврат.
Do_IRQ
Обновляет некоторые статистические данные ядра и вызывает функцию обработчика, связанную с этим IRQ. Для IRQ с низкими номерами в только что выпущенном компьютере этим обработчиком будет handle_IRQ_event.
Если нижние половины активны, теперь они обрабатываются функцией do_bottom_half (строка ).
Do_sigation
Функция do_sigation реализует интересную часть системной функции sigation. (Остальная часть реализована в функции sys_sigation, строка .) Функция sigation представляет собой POSIX-эквивалент функции signal ISO С — она связывает действие с сигналом, чтобы действие выполнялось при получении сигнала процессом.
Выполнение профилактических проверок: функция убеждается, что sig находится в допустимом диапазоне, что процесс не пытается связать действие с сигналом SIGKILL или SIGCONT. Просто процессам не разрешается изменять стандартное поведение этих двух сигналов. Однако, в отличие от обработчиков, устанавливаемых функцией signal, обработчики, устанавливаемые функцией sigaction, не принадлежат к типу SA_ONESHOT и поэтому не должны повторно устанавливаться при каждом вызове обработчика.
Получает указатель на связанную с этим сигналом структуру struct k_sigaction.
Посредством одного из двух переданных указателей, функция sigaction может вернуть старое действие. Это удобно для «помещения обработчиков в стек», когда обработчик временно замещается, а затем восстанавливается. Если значением указателя cast является не NULL, в него копируется старое действие. (Однако, это не приводит к копированию информации обратно в область пользователя; это должен сделать вызывающий процесс.)
Если функции do_sigaction было передано действие, которое должно быть связанно с сигналом, теперь они связанны. Кроме того, сигналы SIGKILL и SIGSTOP должны быть удалены из маски действия, чтобы они не были заблокированы или перезаписаны.
Как утверждается в заглавном комментарии, начинающемся в строке , для приведения их в соответствие со стандартом POSIX следующие несколько строк должны быть несколько изменены, обеспечив, при необходимости, отмену некоторых ожидающих обработки сигналов. Мы потеряем не слишком много, пропустив подробности.
Do_signal
do_signal— место, где сигнал доставляется процессу. Эта функция вызывается из многих мест в ядре — в строках и , как рассматривалось в , а также в строках и . Общее, что эти случаи имеют, — это обработка текущим процессом ожидающего сигнала (если таковой имеется).
Если oldset не равен NULL, он используется для возврата набора заблокированных сигналов в текущем процессе. Поскольку do_signal набор заблокированных сигналов не изменяет, можно просто возвратить указатель на существующий набор.
Вход в цикл, который тянется практически до конца функции (строка ). Существует всего два пути выхода из цикла: когда все сигналы, требующие обработки, подошли к концу, или за счет обработки одного сигнала.
Удаление сигнала из очереди при помощи dequeue_signal (строка ). Функция dequeue_signal возвращает либо 0, либо число сигналов для обработки, а также заполняет всю дополнительную информацию в info.
Если больше нет ожидающих сигналов, цикл завершается. Обычно это происходит не после первой итерации.
Если текущий процесс трассируется родителем (скажем, отладчиком) и этот сигнал — не SIGKILL, который блокировке не подлежит, родитель процесса должен быть уведомлен о доставке сигнала.
Номер сигнала, доставленного для дочернего процесса, передается родителю в поле exit_code дочернего процесса; родитель будет собирать их с использованием sys_wait4 (строка , которая рассматривается в ). do_signal останавливает дочерний процесс, обращается к notify_parent (строка ) для отправки родителю сигнала SIGCHLD и затем вызывает функцию планировщика schedule (строка , см. ), чтобы предоставить остальным процессам (в частности, родителю) возможность продолжить выполнение. Функция schedule будет уступать ЦП другому процессу, поэтому возврата из нее не будет до тех пор, пока ядро не выполнит переключение вновь на этот процесс.
Если отладчик отменяет сигнал, do_signal его здесь обрабатывать не будет и цикл продолжается.
Возможно, возник SIGSTOP из-за того, что выполняется трассировка процесса. Нет необходимости его обрабатывать, поэтому цикл продолжается.
Если отладчик изменил номер сигнала, который должен обрабатываться do_signal, do_signal заполняет info в соответствие с новой информацией.
Как гласит комментарий, если новый сигнал заблокирован, он повторно помещается в очередь и цикл продолжается. В противном случае управление передается на следующий код.
В этот момент либо процесс не трассируется, либо он трассируется, но получил сигнал SIGKILL, либо управление передалось из предыдущего блока. В любом из перечисленных случаев do_signal имеет сигнал, который сейчас будет обработан. Все начинается с чтения структуры struct k_sigaction, из которой получается информация о том, как должен обрабатываться конкретный номер сигнала.
В том случае когда процесс пытается проигнорировать сигнал, do_signal продолжает цикл, если только это не сигнал SIGCHLD. Почему здесь не проверяется также, не пытается ли процесс проигнорировать SIGKILL, который по определению нельзя ни игнорировать, ни блокировать? Ответ заключается в том, что действие, соответствующее SIGKILL, никогда не может быть SIG_IGN, и тем более не SIG_DFL — это гарантируется в строке (в функции do_sigaction). Таким образом, если действием является SIG_IGN, номером сигнала не может быть SIGKILL.
Как гласит комментарий в строке , стандарт POSIX определяет, что действие «проигнорировать» для SIGCHLD означает автоматически отсечь дочерний процесс. Дочерний процесс отсекается при помощи sys_wait4 (строка ) и цикл продолжается.
Процесс выполняет для данного сигнала стандартное действие. Стандартные действия для всех сигналов, полученные от специального процесса init, сводятся к полному игнорированию сигнала.
Стандартные действия для сигналов SIGCONT, SIGCHLD и SIGWINCH — это не делать ничего, следовательно, просто продолжить цикл.
Для сигналов SIGTSTP, SIGTTIN и SIGTTOU стандартные действия изменяются. В том случае когда группа, к которой принадлежит данный процесс, оказывается висячей (ни с чем не связана) — это может означать, что она не присоединена к TTY — POSIX определяет, что стандартным действием для этих терминальных сигналов должно быть игнорирование. Если же группа процессов не является висячей, то стандартной реакцией на сигналы должен быть останов процесса — то же самое, что и случай с SIGSTOP, поэтому именно туда передается управление.
В ответ на SIGSTOP (либо в результате передачи управления из предыдущего случая) do_signal останавливает процесс. Кроме того, выполняется уведомление родительского процесса об останове одного из его дочерних процессов, если только родительский процесс не отменил необходимость такого уведомления. Как и в строке , выполняется вызов schedule для передачи ЦП другим процессам. После того как ядро вновь вернет ЦП текущему процессу, цикл продолжит свою работу и займется вытаскиванием из очереди следующего сигнала.
Это несколько неожиданно — я думал, что когда произойдет возврат из schedule, цикл должен завершиться, поскольку сигнал обработан. Кажется, рациональнее было бы пробуждать остановленный процесс только по приходу сигнала, например SIGCONT, чтобы можно было также и проверить и обработать сигнал.
Стандартная реакция на другие сигналы сводится к завершению процесса. Некоторые сигналы сначала порождают процесс, чтобы попытаться записать дамп ядра (см. ) — это SIGQUIT, SIGILL, SIGTRAP, SIGABRT, SIGFPE и SIGSEGV. Если данный двоичный формат (см. ) знает, как записать дамп и дамп завершается успешно, в коде завершения процесса устанавливается соответствующий разряд, указывающий, что перед завершением процесс успел записать дамп. Далее управление передается на общий случай, который и завершает процесс. Из функции do_exit (строка , см. ) никогда не происходит возврата — отсюда и комментарий «NOTREACHED» в строке .
В этот момент do_signal изъяла из очереди сигнал, который не ассоциируется ни с действием SIG_IGN, ни с действием SIG_DFL. Единственное, что можно предположить, что сигнал имеет пользовательский обработчик. do_signal обращается к handle_signal (строка ), чтобы вызвать пользовательский обработчик сигнала, и возвращает 1, уведомляя отправителя о факте обработки сигнала.
Здесь do_signal не может получить из очереди сигнал для текущего процесса. (В эту строку можно попасть только после break в строке .) Если процесс прерван из середины системного вызова, do_signal настраивает таким образом, что системный вызов сможет возобновить выполнение.
Возврат 0, информирующего отправителя о том, что do_signal не обработала ни одного сигнала.
Do_timer
Эта верхняя половина таймера представляет для нас интерес.
Обновляет глобальную переменную jiffies, которая отслеживает количество тиков системных часов, произошедших с момента начальной загрузки. (Очевидно, что в действительности выполняется подсчет тиков таймера, произошедших с момента установки прерывания таймера, который не совпадает с моментом начальной загрузки системы.)
Увеличивает число «потерянных» тиков таймера — тиков, которые не были обработаны нижней половиной. Вскоре будет показано, как нижняя половина таймера использует эту переменную.
Верхняя половина выполняется, поэтому ее нижняя половина помечается для скорейшего выполнения.
Кроме отслеживания общего количества тиков таймера, произошедших с момента последнего выполнения нижней половины таймера, необходимо знать, сколько из этих тиков произошло в режиме системы. Повторим снова, вскоре будет показано, зачем это значение нужно нижней половине; а пока, отметим, что значение lost_ticks_system увеличивается, если процесс выполняется в режиме системы (ядра), а не в режиме пользователя.
Если какие-либо задачи ожидают в очереди таймера, нижняя половина очереди таймера помечается как готовая к выполнению (нижняя половина очереди таймера описана несколько ниже). Вот и все, что касается прерывания таймера. Код кажется простым, но в значительной степени это обусловлено тем, что основная часть работы была оправданно передана нижней половине.
Другие функции, связанные с обработкой сигналов
Осталось рассмотреть еще несколько показательных функций, связанных с обработкой сигналов.
Force_sig_info
Функция force_sig_info используется ядром для обеспечения принудительного получения сигнала процессом вне зависимости, желает он того или нет. Одно из применений функции связано с принудительным получением процессом сигнала SIGSEGV в случае, когда происходит разыменовывание ошибочного указателя (см. строку , где находится обращение к обратно-совместимой функции force_sig, но force_sig реализована полностью в терминах force_sig_info). Аргументы force_sig_info— те же, что и в send_sig_info, причем означают то же самое.
Если процесс является мертвым, то отправить ему сигнал не сможет даже ядро; попытка отправки отвергается.
Если процесс задумал проигнорировать сигнал, force_sig_info заставляет его отказаться от этой затеи, переводя его в состояние, соответствующее стандартным реакциям на сигналы. Это не настоль безобидно, как может показаться: в случаях, когда эту функцию использует ядро, стандартной реакцией на сигнал будет уничтожение процесса.
Удаление сигнала и набора заблокированных сигналов в t.
Сейчас force_sig_info устанавливает такие условия, что t обязана принять сигнал, поэтому сигнал может быть доставлен с использованием send_sig_info. Однако, в случае изменения реализации send_sig_info, сигнал может и не добраться до получателя, так что эти две функции должны изменяться согласовано.
Free_irq
Действие функции free_irq противоположно действию request_irq. Если request_irq аналогична конструктору действий, то эта функция по своему действию наиболее напоминает деструктор.
Убедившись, что значение irq находится в допустимом диапазоне, функция free_irq находит соответствующую запись в массиве irq_desc и начинает итерации по ее списку действий.
Игнорирует этот элемент очереди, если только он не имеет правильный идентификатор устройства.
Удаляет этот элемент из очереди и освобождает выделенную ему память.
Если теперь очередь действий пуста— т.е., если только что был удален единственный элемент очереди — устройство отключается.
Если поток управления доходит до этой точки, значит функция free_irq прошла весь список действий, не найдя походящего dev_id. Если бы она нашла соответствующий идентификатор устройства, оператор goto в строке привел бы к пропуску этой строки. Следовательно, имела место ошибочная попытка освободить действие IRQ; функция free_irq выводит предупреждение об этом.
Функции работы с наборами
В дополнение к предшествующей группе, следующая группа макросов и функций выполняет операции с sigset_ts как над набором. Как и в предшествующей группе, функции предохраняются препроцессорным символом __HAVE_ARCH_SIG_SETOPS. На данный момент не существует ни одной платформенно-зависимой версии этой группы функций, а лишь только универсальная.
Сигналы, прерывания и время
Сигналы (signals) представляют собой одну из форм взаимодействия между процессами (interprocess communication, или IPC) — способа передачи информации от одного процесса другому. Однако передавать можно не так много информации — вместе с сигналом нельзя передавать сложные сообщения и даже идентификацию отправителя; все, что в данной ситуации имеется, — это сам факт отправки сигнала. (Во всяком случае, речь идет о классических сигналах, поскольку сигналы реального времени POSIX допускают передачу несколько большей информации.) Сигналы практически непригодны для детализации двунаправленных взаимодействий. Кроме того, в рамках существующих ограничений получатель сигнала не обязан каким-либо образом отвечать на него и даже может позволить себе проигнорировать большую часть сигналов.
Тем не менее, несмотря на такие ограничения, сигналы остаются мощным и полезным механизмом, который используется, пожалуй, гораздо чаще других. Каждый раз когда завершается некоторый процесс или разыменовывается указатель со значением NULL, при каждом нажатии Ctrl+С или применении программы kill, генерируется какой-то сигнал.
Механизмы IPC, заложенные в Linux, подробно описываются в . В этой главе речь пойдет в основном о сигналах.
Прерывания (interrupts), как прокомментировано в коде Linux, похожи на сигналы для ядра. Прерывания посылаются ядру от аппаратных устройств наподобие дисков с целью уведомления ядра о том, что то или иное устройство требует к себе некоторого внимания. Одним из важных источников аппаратных прерываний является таймер, периодически уведомляющий ядро о продвижении времени. Как показано в , прерывания могут также генерироваться пользовательскими процессами, т.е. программно.
В этой главе будет проанализирована реализация механизма сигналов и прерываний в Linux, а также существующие способы манипуляции временем.
Код, который здесь рассматривается, исключительно понятен и хорошо написан, причем даже по высоким требованиям к коду ядра. Исследование материала построено следующим образом: вначале будут проанализированы соответствующие структуры данных и их взаимосвязи друг с другом, а затем функции, которые манипулируют и обращаются к таким структурам.
Handle_IRQ_event
Функция handle_IRQ_event выполняет основную часть работы для функции do_8259_IRQ (строка ). Она вызывается также из некоторых других функций, которые не освещены в этой книге.
Вопреки документации (строка ), флаг SA_INTERRUPT не является фиктивным. Если этот флаг не установлен, во время выполнения следующего за ним кода прерывания разрешены. Это историческое наследие различения ядром быстрых и медленных прерываний, как было описано ранее. (Код, обрабатывающий оба вида прерываний, обычно имел гораздо больше различий, но результат оставался почти таким же— код реализовался гораздо элегантнее.) Похоже, что главным образом этот флаг предназначен для использования с очень медленными устройствами — например, с дисководами гибких дисков.
Выполняет итерации по очереди действий для данного IRQ (начало очереди было передано вызывающей функцией), вызывая функцию обработчика для каждого из них.
Здесь случай прерывания используется для добавления некоторой случайной информации для использования устройствами /dev/random и /dev/urandom — предположительно, большинство прерываний происходит случайно.
Запрещает прерывания (вызывающая функция снова разрешит их, когда будет готова).
Handle_signal
handle_signal вызывается из функции do_signal, когда требуется выполнить обращение к пользовательскому обработчику сигналов.
Установка фрейма стека, в котором будет выполняться пользовательский обработчик сигналов. Если процесс запрашивает любую дополнительную информацию, которую может сообщить ядро, связанную с начальным адресом и контекстом сигнала, фрейм стека устанавливается при помощи setup_rt_frame (строка ); в противном случае вызывается setup_frame (строка ). Обе последовательности действий обеспечивают корректную передачу управления обработчику сигналов и корректный возврат из него в соответствующую позицию кода.
Если флаг SA_ONESHOT установлен, обработчик сигналов будет выполняться только один раз. (Следует заметить, что sys_signal, реализация системного вызова signal, использует обработчики с типом SA_ONESHOT — см. строку .) В данном случае восстанавливается стандартное действие.
SA_NODEFER означает, что в течение выполнения обработчика данного сигнала дополнительные сигналы блокироваться не будут. Если этот разряд не установлен, в набор заблокированных процессов добавляются дополнительные разряды.
Ignored_signal
ignored_signal помогает send_sig_info принять решение, посылать ли процессу сигнал.
Если процесс трассируется родителем (скажем, отладчиком) или сигнал присутствует в наборе заблокированных сигналов процесса, он не может быть проигнорирован. Второе утверждение несколько неожиданно: если сигнал заблокирован, будет ли send_sig_info (а также и ignored_signal) его игнорировать? Так получается, что нет. Все, что в этих функциях понимается под игнорированием сигнала, сводится к установке соответствующего разряда в наборе signal, относящемся к процессу. Как было показано ранее, поддержка системного вызова sigpending требует, чтобы ядро устанавливало упомянутый разряд, если сигнал был доставлен заблокированным. Отсюда и следует, что заблокированные сигналы игнорироваться не могут.
Если процесс является мертвым, сигнал игнорируется. Эта проверка не является необходимой, поскольку такая ситуация уже была отслежена в строке , перед вызовом ignored_signal.
В большинстве случаев поведение SIG_DFL (стандартное) заключается в обработке сигнала, а не в игнорировании его. Несложно заметить, что исключениями являются SIGCONT, SIGWINCH, SIGCHLD и SIGURG.
Процессам разрешено игнорировать большинство сигналов, но не SIGCHLD. По отношению к SIGCHLD стандарт POSIX придает SIG_IGN специальный смысл, как задокументировано в строке . Упоминаемое здесь «автоматическое отсечение дочерних процессов» выполняется в строке .
В общем случае ignored_signal предположительно имеет реальный указатель на функцию, а не одно из псевдозначений SIG_DFL или SIG_IGN. Следовательно, сигнал связывается с пользовательским обработчиком, а это означает, что процесс желает обработать сигнал. Возвращается 0, указывающий, что сигнал не игнорируется.
Init_IRQ
init_IRQ инициализирует обработку IRQ.
Символ CONFIG_X86_VISWS_APIC определен для рабочих станций SGI Visual Workstation, линии рабочих станций производства SGI, собранных на основе центрального процессора х86. Хотя они основываются на центральном процессоре х86, рабочие станции Visual Workstation не обладают многими другими характеристиками архитектуры IBM PC— в частности, они несколько иначе обрабатывают прерывания. Код, характерный для Visual Workstation, в книге рассматриваться не будет.
Устанавливает таблицу дескриптора прерываний, присваивая стандартные значения записям с десятичными номерами от 32 до 95 (включительно). При этом используется функция set_intr_gate (строка ), которая вскоре будет рассмотрена.
Устанавливает IRQ 2 (прерывание каскада) и 13 (для FPU — см. примечание в строке ). Связанными с этими IRQ структурами struct irqactions соответственно являются irq2 (строка ) и irq13 (строка ).
Init_ISA_irqs
Эта функция заполняет массив irq_desc, инициализируя IRQ для компьютеров с шинами ISA (т.е. для всех стандартных PC). Хотя эта функция не объявляется static и не помечается тэгом __initfunc, она вызывается только функцией init_IRQ и, следовательно, нужна только во время инициализации ядра.
Для каждого элемента массива irq_desc вполне оправданными и объяснимыми стандартными значениями являются значения, присваиваемые членам status, action и depth.
Старые (использовавшиеся до появления PCI) IRQ обрабатываются структурой i8259A-irq-type (строка ).
IRQ с наибольшими номерами инициализируются значением no_irq_type (строка ), которая по существу представляет собой ничего не выполняющий обработчик. Они могут быть изменены впоследствии — в действительности это и происходит при наличии каких-либо плат PCI, как имеет место в современных ПК.
IRQ
IRQ — interrupt request (запрос прерывания) — это уведомление о прерывании, отправляемое из аппаратного устройства центральному процессору. В ответ на IRQ центральный процессор выполняет переход к специальному адресу — interrupt service routine (подпрограмма обслуживания прерывания или ISR), чаще называемой обработчиком прерывания — который ранее был связан с данным IRQ ядром. Обработчик прерывания — это функция, которую ядро выполняет для обслуживания прерывания; возврат из обработчика прерывания приводит к продолжению выполнения с того места, где оно было прервано.
IRQ нумеруются и каждое аппаратное устройство в системе связывается с номером IRQ. Например, в архитектуре IBM PC IRQ 0 связано с аппаратным таймером, генерирующим 100 прерываний в секунду. Связывание номера IRQ с устройством позволяет центральному процессору выяснить, какое устройство сгенерировало каждое прерывание, и, следовательно, позволяет ему выполнить переход к нужному обработчику прерывания. (В некоторых случаях номер IRQ может совместно использоваться несколькими устройствами в системе, хотя это и не очень распространено.)
Kill_pg_info
Эта функция отправляет сигнал и структуру struct siginfo каждому процессу в группе. Тело функции подобно некоторому коду из kill_something_info, которая рассматривалась ранее.
Итерация по всем процессам системы.
Если текущий процесс принадлежит требуемой группе, отправить сигнал.
В случае успешной отправки сигнала retval устанавливается в 0 и в строке возвращается. Если сигнал не может быть отправлен ни одному процессу либо заданная группа не содержит ни одного процесса, в строке значение retval устанавливается равным –ESRCH. Если же kill_pg_info предпринимала попытки отправить сигнал одному и более процессов, но каждый раз терпела неудачу, retval получает значение последней ошибки из send_sig_info. Это несколько отличается от случая kill_something_info, при котором состояние ошибки возвращалось, когда все доставки сигналов завершались сбоями. Здесь, в функции kill_pg_info, успех возвращается даже при условии удачной доставки сигнала хотя бы одному процессу.
Значение retval устанавливается либо как описывалось ранее, либо в –EINVAL (строка ), если был передан неверный номер группы процессов.
Kill_proc_info
kill_proc_info— это исключительно простая функция, которая отправляет сигнал и структуру struct siginfo одному процессу, заданному идентификатором PID.
Поиск процесса по переданному PID; функция fmd_task_by_pid (строка ) вернет либо соответствующий указатель, если процесс найден, либо NULL в противном случае.
Если совпадение найдено, сигнал отправляется требуемому процессу при помощи send_sig_info.
Возврат состояния ошибки, которое равно либо –ESRCH (строка ), если процесс не найден, либо, в противном случае, значению возврата из send_sig_info.
Kill_something_info
Аргументы этой функции такие же, как и для sys_kill плюс указатель на структуру struct siginfo.
Если pid равен 0, это значит, что текущий процесс желает отправить сигнал во всю свою группу процессов; это достигается обращением к kill_pg_info (строка ).
Если pid равен –1, это значит, что сигнал передается (почти) каждому процессу в системе. Как это делается— описано ниже.
Использование макроса for_each_task (определенного в строке ; см. ) для выполнения итерации по списку всех существующих процессов в системе.
Если данный процесс не является ожидающим (или процессом init), отправить сигнал с использованием send_sig_info (строка ). При каждом нахождении подходящей задачи увеличивается count, хотя функцию kill_something_info мало интересует подобный подсчет. Если попытка отправки сигнала успехом не увенчалась, запоминается состояние ошибки, таким образом, kill_something_info может вернуть соответствующий код ошибки в строке ; если имело место более одного сбоя, возвращается код ошибки только для последнего из них.
Если найден хотя бы один подходящий кандидат, kill_somcthing_info возвращает 0 в случае успеха либо код последней возникшей ошибки в случае неудачи. Если ни одного кандидата не нашлось, возвращается код ошибки ESRCH.
Отрицательные значения pid, отличные от –1, определяют группу процессов, которые должны получить сигнал; при этом модуль pid представляет собой номер группы. Как и ранее, для отправки сигнала используется kill_pg_info.
Здесь учитываются другие возможности, когда pid положительный. В данном случае передаваемое значение представляет собой PID для одиночного процесса, которому должен отправляться сигнал. Для отправки выполняется обращение к kill_proc_info (строка ).
Краткое замечание о блокировках
Основная идея, связанная с блокировкой, заключается в защите доступа к совместно используемому ресурсу — файлу, области памяти или фрагменту кода, который должен выполняться строго одним ЦП в один и тот же момент времени. В случае однопроцессорной (UP) системы ядру Linux блокировки не нужны, поскольку при его написании как раз и ставилась цель избежать подобного рода ситуаций. Однако, в случае с мультипроцессорными (SMP) системами иногда один процессор желает избавиться от нежелательного влияния со стороны другого процессора.
Вместо помещения всех обращений к функциям блокировки в неприглядные оболочки из #ifdef, применен другой подход: были разработаны отдельно макросы для UP-систем (по большей части пустые) и для SMP-систем (содержащие реальный код), после чего все макросы были сведены в файл include/asm-i386/spmlock.h (начинается со строки ). В результате остальной код, если иметь в виду блокировки, выглядит одинаково как для UP-, так и для SMP-систем, но приводит к совершенно разным эффектам.
Блокировки подробно рассматриваются в . Однако сейчас следует хотя бы прочувствовать, откуда взялись эти макросы и почему в большинстве случаев в этой главе их можно благополучно игнорировать (существуют несколько важных исключений из этого правила, о которых рассказывается позже).
Нижние половины
Нижняя половина обработчика прерывания — та его часть, которую не нужно выполнять немедленно. Для некоторых прерываний может вообще не потребоваться ее выполнять.
Следует отметить, что каждый обработчик прерывания делится на верхнюю и нижнюю половины; верхняя половина вычислений выполняется немедленно в момент прерывания, в то время как нижняя половина (если она существует) откладывается. Это достигается путем реализации верхней и нижней половины отдельными функциями и путем различной их обработки. В целом, верхняя половина принимает решение о необходимости выполнения нижней половины. Очевидно, что все что не может быть отложено, не входит в нижнюю половину, но все, что может быть отложено, является кандидатом для включения в нее.
Читателей может интересовать вопрос, почему Linux утруждает себя этим разделением — зачем нужна эта задержка? Одной из причин является стремление минимизировать общую продолжительность прерываний. Ядро Linux определяет два вида прерываний: быстрый и медленный, и одно из различий между ними состоит в том, что медленные прерывания сами могут быть прерваны, а быстрые — нет. Следовательно, во время обработки быстрых прерываний все остальные поступающие прерывания — как медленные, так и быстрые — должны просто дожидаться своей очереди. Чтобы обработать эти прерывания как можно раньше, ядро откладывает как можно больше вычислений в нижние половины.
Другая причина заключается в том, что на самом нижнем уровне чипу контроллера прерываний указывается отключать конкретный IRQ, подлежащий обработке, пока ядро выполняет верхнюю половину (Это отличается от отключения на уровне центрального процессора, которое не различает быстрые и медленные прерывания). Нежелательно, чтобы эта ситуация продолжалась дольше, чем необходимо, поэтому только наиболее критичная в смысле времени часть выполняется в верхней половине, а все остальное переносится в нижнюю половину.
Еще она причина разделения верхней и нижней половин в том, что нижняя половина обработчика состоит из процедур, которые не обязательно должны выполняться для каждого отдельного прерывания, а только тогда, когда ядро доберется до них в определенный момент после выполнения каждого пакета прерываний, поступающего от устройства. В подобном случае выполнение нижней половины обработки для каждого прерывания, в то время, как она может быть отложена на некоторое время и затем выполнена только один раз — явное расточительство.
Следует упомянуть об одном выводе, вытекающем из предшествующего абзаца: нижняя половина не обязательно вызывается один раз для каждого прерывания. Вместо этого, верхняя половина (или, иногда, какая-либо другая часть кода) просто «помечает» нижнюю половину, устанавливая разряд, который указывает на необходимость выполнения нижней половины. Если нижняя половина помечается снова, будучи уже помеченной, она просто остается такой; ядро обслуживает ее, когда может это сделать. Если для данного устройства 100 прерываний произойдут прежде, чем ядро получит возможность выполнить нижнюю половину, верхняя половина будет выполнена 100 раз, а нижняя — 1 раз.
Иногда нижние половины называются в ядре «мягкими IRQ» или «обработчиками мягких прерываний», что помогает пояснить некоторые имена файлов и другие термины, с которыми вы встретитесь.
В остальной части этого раздела представление о нижних половинах останется достаточно абстрактным. В следующем разделе прерывание таймера исследуется несколько глубже, включая обработку его нижней половины; кроме того в ней показано интересное неверное употребление — имеется в виду интересное обобщение — представления о нижних половинах.
Notify_parent
notify_parent отыскивает родителя процесса и информирует его об изменении состояния дочернего процесса— как правило, дочерний процесс либо остановлен, либо уничтожен.
Заполняет внутреннюю переменную info информацией о контексте, в котором произошел сигнал.
В случае если дочерний процесс завершился, why устанавливается в значения, указывающие на факт сохранения процессом дампа, на факт уничтожения процесса по сигналу или на факт завершения процесса по собственному желанию.
Аналогично, если процесс остановлен по сигналу, why устанавливается соответствующим образом.
Предполагается, что предыдущие случаи покрыли все возможности. Если же нет, функция печатает предупредительное сообщение и продолжает работу; в таком случае why примет значение SI_KERNEL в строке .
Отправка сигнала родителю процесса. Следующая строка обеспечивает пробуждение всех процессов, ожидающих данного дочернего, предлагая в их распоряжение ЦП.
Обработчики и нижние половины аппаратных прерываний
Действительные обработчики прерываний для порта х86 тривиальны; на самом нижнем уровне они построены посредством многократного использования макроса BUILD_IRQ (строка ) для построения последовательностей небольших ассемблерных функций. Сам макрос BUILD_IRQ используется макросом BI (строка ), который в свою очередь используется макросом BUILD_16_IRQS (строка ), который в строках с по применяется для создания подпрограмм ассемблера. Эта последовательность вызовов макросов предназначена всего лишь для уменьшения объема и избыточности действительного кода, который должен быть написан— вместо 16 применений макроса BUILD_16_IRQS могло бы потребоваться 256 обращений к макросу BUILD_IRQ.
Подпрограммы ассемблера выглядят подобно следующему:
IRQ0x00_interrupt: pushl 0x00-256 jmp common_interrupt
Т.е. каждая из них просто выталкивает свой номер IRQ (минус 256, по причинам, которые описаны в стоке ) в стек, а затем выполняет переход к общей подпрограмме прерывания.
Общая подпрограмма прерывания называется common_interrupt и также является короткой. Она образована макросом BUILD_COMMON_IRQ (строка ) и просто вызывает функцию do_IRQ, обеспечив, чтобы та выполнила возврат к функции ret_from_intr (строка ), являющейся частью подпрограммы system_call, которая была исследована в . Функция do_IRQ, которая вскоре будет рассмотрена, принимает на себя ответственность проследить за тем, чтобы прерывания были обслужены.
Прежде чем исследовать весь код, не помещает на верхнем уровне рассмотреть, как отдельные части взаимодействуют во время обслуживания отдельного прерывания:
Центральный процессор выполняет переход к подпрограмме IRQxNN (где NN — номер прерывания), которая выталкивает свой уникальный номер в стек, а затем выполняет переход к common_interrupt.
Подпрограмма common_interrupt вызывает функцию do_IRQ и следит за тем, чтобы при возврате из нее управление было передано функции ret_from_intr.
Функция do_IRQ вызывает код, который является характерным для чипа контроллера прерываний — код, который при необходимости обращается непосредственно к чипу и обслуживает прерывание. Для чипа контроллера 8259А, имеющего наибольшее распространение в архитектурах PC, функцией обработчика является do_8259A_IRQ, которая и используется здесь для примера.
Функция do_8259A_IRQ временно отключает конкретное прерывание, подлежащее обслуживанию, вызывает функцию handle_IRQ_event и затем снова включает этот отдельный IRQ.
Функция handle_IRQ_event включает прерывания для медленных IRQ или оставляет их отключенными для быстрых IRQ. Затем она просматривает очередь функций, которые были связаны с этим IRQ, поочередно вызывая их. Поскольку IRQ включены для медленных IRQ, именно здесь обработчик медленных IRQ может быть прерван другим прерыванием. После того, как очередь функций исчерпана, функция handle_IRQ_event отключает прерывания и выполняет возврат к характерной для контроллера функции обработчика, которая выполняет возврат к функции do_IRQ.
Функция do_IRQ обслуживает любые ожидающие обработки нижние половины, а затем выполняет возврат. Как вы уже знаете, это возврат к функции ret_from_intr. Происходящее в дальнейшем освещено в .
Очереди таймера
Изначально потрясающая идея, лежащая в основе очереди таймера, заключается в том, что нижняя половина, связанная с верхней половиной, не должна иметь никакого отношения к обслуживанию прерывания. Взамен это может быть просто какое-то действие, которое необходимо выполнять периодически. Если функция делается частью нижней половины прерывания по таймеру, то это будет гарантировать ее вызов около 100 раз в секунду. (Если 100 раз в секунду оказывается многовато, функция могла бы поддерживать счетчик и просто возвращаться, скажем, 9 из каждых 10 раз — нечто подобное делает calc_load.) Результирующий эффект весьма похож на создание нового процесса, в части main которого в бесконечном цикле вызывается наша функция, но без накладных расходов, обычно имеющих место для процесса.
Однако, нижние половины относятся к ограниченным ресурсам; их может существовать максимум 32, поскольку bh_mask и bh_active должны занимать одно число типа unsigned long каждое. Количество нижних половин можно было бы расширить, используя систему, подобную реализованной для сигналов, но это расширило бы только количество статически доступных нижних половин, но отнюдь не динамически доступных.
По существу, это как раз то, что и обеспечивает очередь таймера: динамически расширяемый список нижних половин, связанных с прерыванием по таймеру. Имеется и отдельная нижняя половина TQUEUE_BH, которая присутствует вместе с TIMER_BH, если в очереди таймера находится хотя бы одна задача. Следовательно, прерывание по таймеру обладает двумя нижними половинами.
В настоящий момент очередь таймера представляет собой просто экземпляр более общей сущности ядра — очереди задач. Очереди задач достаточно неплохо задокументированы в самом ядре — взгляните на файл include/linux/tqueue.h, который начинается со строки . Следовательно, рассматривать их в книге нет никакого смысла. Тем не менее, очереди задач — достаточно важный аспект ядра, поэтому не пренебрегайте возможностью уделить должное внимание этому небольшому файлу.
Отправка сигналов
С точки зрения пользователя отправка сигналов предельно проста: стоит лишь инициировать системный вызов kill и передать ему идентификатор процесса и собственно сигнал. Однако, сама реализация оказывается не настоль простой.
Платформенно-независимая версия функций для sigset_t
Код упомянутых функций находится в файле include/linux/signal.h, который начинается в строке . Эти функции, также называемые «bitops» (bit-level operations, т.е. поразрядные операции), описываются ниже.
Платформенно-зависимая версия функций для sigset_t
Несмотря на простоту и эффективность кода на С, имеется возможность уточнить платформенно-независимую версию рассмотренных функций для семейства процессоров х86, воспользовавшись удобными и мощными поразрядными операциями для х86. В большинстве случаев функции сокращаются до одной машинной команды, потому обсуждение будет коротким.
Для платформы х86 (а также и m68k) компилятор не использует платворменно-независимые версии функций. В строке включается файл asm/signal.h, который в случае х86, благодаря символической ссылке, устанавливаемой makefile, разрешается файлом include/asm-i386/signal.h. Строка определяет препроцессорный символ __HAVE__ARCH_SIG_BITOPS, который обеспечивает замену определений платформенно-независимых функций (см. строку ).
Прерывания
Прерывания названы так весьма удачно, поскольку они прерывают нормальную работу системы. Пример прерывания уже был приведен ранее в : в ней было рассмотрено программное прерывание, которое обеспечивает принципиальный механизм для вызова системных функций. В этой главе мы рассмотрим аппаратные прерывания.
Как и в случае прерываний системных функций, аппаратные прерывания могут вызвать переход в режим ядра и обратно. Когда прерывание происходит во время выполнения процесса пользователя, система переходит в режим ядра, и ядро отвечает на прерывание. Затем ядро возвращает управление процессу пользователя, который продолжается с той точки, где он был прерван.
Одно отличие аппаратных прерываний от прерываний системных функций состоит в том, что аппаратные прерывания могут происходить в то время, когда ядро уже работает в режиме ядра. С системными вызовами такое происходит редко — обычно ядро не утруждает себя запуском прерывания системного вызова, поскольку может просто непосредственно вызвать целевую функцию ядра. Если прерывание происходит в то время, когда система находится в режиме ядра, результат во многом аналогичен тому, как если бы оно произошло в режиме пользователя. Различие лишь в том, что временно прерывается выполнение процесса самого ядра, а не процесса пользователя.
Когда ядро не желает быть временно прерванным, оно выключает и включает прерывания с помощью функций cli и sti (строки и — версии для однопроцессорных машин, а строки и — SMP-верcии). Эти функции названы в соответствии с базовыми инструкциями х86: cli означает «CLear the Interrupt flag» («очистить флаг прерываний»), a sti — «SeT the Interrupts flag» («установить флаг прерываний»). Их работа соответствует названию: процессор имеет флаг «прерывания разрешены», который разрешает прерывания, если установлен, и запрещает их, если снят. Таким образом, прерывания отключаются посредством сброса флага с помощью функции cli и включаются впоследствии посредством повторной его установки с помощью функции sti. В коде для однопроцессорных машин вместо этих функций можно вызывать макросы __cli и __sti — строки и , соответственно.
Естественно, порты ядра для платформ, отличных от х86, будут использовать другие базовые инструкции — просто в этих архитектурах функции cli и sti реализованы иначе.
Probe_irq_off
probe_irq_off реализует вторую важную часть автоматического зондирования IRQ. В данном случае задача состоит в определении того, какие IRQ ответили на зондирующий запрос, и в возврате номера IRQ одного из них.
Проверяет неудачно названный аргумент unused, чтобы выяснить является ли он тем же магическим номером, который возвращает функция probe_irq_on. Предполагается, что вызывающая функция выполняет нечто вроде следующего:
magic = probe_irq_on(); /* ... */ probe_irq_off (magic);
Если функция probe_irq_off оказывается вызванной каким-либо иным образом (например, какая-либо дополнительная логика в вызывающей функции случайно приведет к пропуску вызова функции probe_irq_on), то переданный аргумент вряд ли имеет правильное значение. Вероятно, еще большее значение имеет то, что этот аргумент передает определенную информацию программисту, который создает код для его использования: при исследовании того, каким должен быть этот аргумент, приходится выяснять протокол, который предполагается использовать при вызове этого аргумента. Эта тактика вполне могла бы иметь более широкое распространение. Исходя строго из следующего сообщения об ошибке, кажется, что предыдущая версия функции могла принять в качестве своего аргумента что-то вроде адреса вызывающей функции. Если это так, то эта проверка служит и третьей цели: выявлению того, что какая-то вызывающая функция продолжает неверно использовать функцию.
Выполняет цикл по всем IRQ, отыскивая любые устройства, которые ответили на зондирующий запрос вызывающей функции. Этот цикл также мог бы начинаться с 1, по тем же причинам, что были приведены во время предшествующего рассмотрения функции probe_irq_on.
Ядро не пытается выявить что-либо, связанное с этим IRQ; оно переходит к следующему.
Флаг IRQ_INPROGRESS указывает, что прерывание прибыло для этого IRQ. Поскольку предположительно функция probe_irq_on отсекает любые фальшивые прерывания, представляется вполне разумным ответить на зондирующий запрос. Значение счетчика успешно автоматически прозондированных IRQ увеличивается с сохранением номера первого IRQ.
Независимо от того, был ли этот IRQ успешно автоматически прозондирован, флаг автоматического выявления снимается, и обработчик снова отключается.
Если было успешно автоматически прозондировано более одного IRQ, это сообщается вызывающей функции путем отрицания значения irq_found.
Возвращает значение irq_found — 0 или (возможно отрицательный) номер первого успешно автоматически прозондированного IRQ. Обратите внимание, что это значение никогда не равно 0, если устройство было найдено, поскольку ядро никогда не пытается автоматически выявить IRQ 0. Следовательно, функция probe_irq_off возвращает 0 только тогда, когда никакие IRQ не были выявлены автоматически.
Probe_irq_on
Функция probe_irq_on реализует значительную часть автоматического зондирования IRQ ядра. Описание всего процесса приведено в заглавном комментарии, начинающемся в строке . Задачей этой функции является реализация третьего шага (только) этого описания: временно активизировать любые неприсвоенные IRQ, чтобы функция, вызывающая функцию probe_irq_on, могла их прозондировать.
Для каждого IRQ, за исключением IRQ 0 (таймера), если IRQ еще не имеет никаких связанных с ним действий, функция probe_irq_on записывает, что данный IRQ должен быть определен автоматически, и запускает связанное с ним устройство. Кстати, не думаю, что выполнение этого цикла в обратном направлении обусловлено какой-либо специальной причиной.
Занято — выжидает около одной десятой доли секунды, чтобы дать возможность выдать себя любым устройствам, которые генерируют фальшивые прерывания. Этот цикл мог бы начинаться с 1 а не с 0, поскольку IRQ, которые не выявляются автоматически, игнорируются, a IRQ 0 никогда не выявляется автоматически. Не то, чтобы это ускорение имело какое-либо значение в данном случае; по сравнению с задержкой в одну десятую секунды — целая вечность с точки зрения даже самого медленного процессора — выполнение на один цикл больше или меньше не имеет значения.
Если устройство запускает прерывание во время задержки в строке , вероятно, прерывание является фальшивым: во время этой задержки система не должна обращаться к этому устройству, значит, и устройство не должно было обращаться к системе. Бит автоматического выявления очищается и обработчик снова отключается.
Возвращает магический номер 0x12345678, по причинам, которые станут понятны в ходе дальнейшего рассмотрения.
Различия кода для сигналов реального и не реального времени
Эти различия не слишком велики. В большинстве случаев ими можно пренебречь, поскольку их не очень много. А теперь, чтобы окончательно прояснить вопрос, мы рассмотрим две версии системной функции sigprocmask, которая позволяет процессу манипулировать набором его блокируемых сигналов— добавляя, удаляя или просто устанавливая набор сигналов.
Recalc_sigpending
Эта функция пересчитывает флаг sigpending процесса; она вызывается при изменении наборов signal или blocked, связанных с процессом.
В простейшем случае recalc_sigpending выполняет поразрядное И (AND) набора signal с инверсией набора blocked. (Инверсия набора blocked дает в результате набор разрешенных сигналов allowed.) Другие случаи представляют собой простые обобщения рассмотренного.
Если в результате выполнения предшествующих операций в ready остается хотя бы один разряд, равный 1, это значит, что в наборе ожидающих сигналов имеется, по крайней мере, один незаблокированный сигнал; в таком случае recalc_sigpending взводит флаг sigpending.
Поскольку для recalc_sigpending требуется знать, имеется ли хотя бы один ожидающий сигнал (не количество, а лишь факт наличия одного), в нетривиальных случаях код мог бы остановить выполнение изменений в ready (например, прервав цикл в строке ) как только ready получит ненулевое значение. Однако, все выигрыши, которые получаются от такого рода оптимизации, тут же поглощаются накладными расходами от дополнительных проверок условий. В этой связи и по причине небольших размеров, _NSIG_WORDS, код работает быстрее, чем кажется на первый взгляд.
Request_irq
request_irq создает из переданных значений структуру struct irqaction и добавляет ее в список структур struct irqaction для данного IRQ. (Если вы знакомы с языками программирования C++ или Java, можете считать эту функцию конструктором действий.) Ее реализация достаточно проста.
Выполняет профилактическую проверку нескольких входных значений. Обратите внимание, что нет никакой необходимости проверять, меньше ли 0 значение irq, поскольку оно имеет тип без знака.
Динамически выделяет новую структуру struct irqaction. Используемая для этой цели функция kmalloc кратко освещается в .
Заполняет новое действие и с помощью setup_x86_irq предпринимает попытку добавить его в список действий.
Run_bottom_halves
Теперь ядро готово выполнить ждущие обработки нижние половины.
Сохраняет текущий набор активных — т.е. помеченных — нижних половин в локальной переменной active и с помощью макроса clear_active_bhs (строка ) очищает установленные разряды в глобальной переменной bh_active. Очистка этих разрядов в переменной bh_active одновременно удаляет метки со всех нижних половин.
Теперь читатели могут убедиться, что иногда нижние половины объединяются в пакеты, как и утверждалось ранее без доказательств. К этому моменту прерывания включены, поэтому если другое прерывание запускается и отмечает уже помеченную нижнюю половину раньше, чем функция run_bottom_halves успеет скопировать bh_active в active, верхняя половина будет выполнена дважды, а нижняя — только один раз. И, поскольку само прерывание также может быть прервано, верхняя половина могла бы быть выполнена трижды при однократном выполнении нижней половины, и т.д. Однако вероятность этого быстро уменьшается с увеличением количества рекурсивных прерываний.
Может ли данный код пропустить какие-либо нижние половины? Давайте предположим, что прерывание происходит в самый неудачный момент времени: между строками и — т.е. после копирования переменной bh_active но перед очисткой разрядов установки в ней. Возможны три случая:
Новое прерывание не помечает ни одной нижней половины. Совершенно очевидно, что этот случай не создает никаких проблем — набор нижних половин, подлежащих обслуживанию, после прерывания остается тем же, что и до него; таким образом функция run_bottom_halves выполняет все нижние половины, которые она должна была выполнить.
Новое прерывание помечает нижнюю половину, которая уже была помечена. В этом случае также не возникает никаких проблем — функция run_bottom_halves все равно собиралась выполнить эту нижнюю половину, и она делает это, когда выполняется возврат из нового прерывания.
Новое прерывание помечает нижнюю половину, метка с которой ранее была удалена. В этом случае переменная active больше не соответствует bh_active, когда функция run_bottom_halves выполняет цикл по нижним половинам. Однако, строка не очистит вновь установленный разряд в bh_active, поскольку функция clear_active_bhs очищает только те разряды, которые устанавливаются в active. Функция clear_active_bhs использует функцию atomic_clear_mask (строка ), которая выполняет просто поразрядное AND разрядов установленных в active и оставляет остальные разряды неизменными. Таким образом, когда функция выполняет цикл, она не станет обслуживать вновь помеченную нижнюю половину немедленно, но поскольку в bh_active ее разряд все же установлен, run_bottom_halves запомнит о необходимости обслужить ее со временем. Точнее говоря, любые нижние половины, которые пропускаются таким образом, будут обслужены во время обработки нижних половин, следующей за следующим прерыванием таймера, одним мигом позже — или даже раньше, если до этого произойдет какое-нибудь другое прерывание. Таким образом, «пропущенным» нижним половинам обычно не придется ожидать дольше, чем сотую доли секунды, а поскольку, по определению, нижние половины в любом случае не критичны в отношении времени, эта небольшая задержка не имеет никакого значения.
Одновременно просматривает массив bh_base и разряды в переменной active. Если самый младший разряд в active установлен, соответствующая нижняя половина вызывается; затем цикл переходит к следующей записи массива bh_base и к следующему разряду в active.
Поскольку данный цикл является циклом do/while, он выполняется по меньшей мере один раз. Частично это связанно с тем, что вызывающая функция всегда, прежде чем вызывать функцию do_bottom_half, проверяет, нуждаются ли какие-либо нижние половины в обслуживании, и поэтому цикл должен быть выполнен по меньшей мере один раз. Кстати, та проверка могла бы быть помещена и внутрь самой функции do_bottom_half, но выполнение проверки прежде вызова функции предотвращает вызов, если никакие нижние половины не нуждаются в выполнении. В любом случае цикл будет выполняться правильно, даже если никакие нижние половины не нуждаются в выполнении; это привело бы к напрасной трате времени, но не принесло бы никакого иного вреда.
Цикл прерывается, когда в active не остается установленных разрядов. Поскольку по мере выполнения цикла выполняется сдвиг active, все остальные разряды проверяются одновременно, без необходимости выполнения цикла по каждому из них.
Run_old_timers
Ядро обладает устарелой возможностью, подобной нижним половинам, которая заключается в следующем: функции ядра могут регистрироваться в специальной таблице, связываться с определенным временем и вызываться при достижении этого времени. Это обеспечивает функция, вызывающая другие функции в случае возникновения необходимости. Поскольку все предназначение функции связано с поддержкой старого кода, она детально рассматриваться не будет. Все что она делает, так это проходит по списку элементов массива timer_table (строка ) и обращается к функциям, время вызова которых наступило.
Send_sig_info
Функция send_sig_info является несомненно основополагающей, так сказать «рабочей лошадкой», для множества функций, рассмотренных до сего момента. Эти функции каким-то образом отыскивали необходимый процесс (или процессы), а всю реальную работу перекладывали на плечи send_sig_info. Сейчас мы рассмотрим, что же здесь на самом деле происходит. send_sig_info отправляет сигнал sig, используя дополнительную информацию, на которую указывает info (кстати, может быть и NULL), процессу, заданному указателем t (предполагается, что t никогда не может быть NULL; об этом должны позаботиться перед вызовом).
Проверка значения sig на предмет попадания в диапазон допустимых значений. Следует заметить, что существующая проверка:
sig > _NSIG
отличается от той, что можно было ожидать:
sig >= _NSIG
Все дело в том, что нумерация сигналов начинается с 1, а не с 0. Следовательно, допустимое количество сигналов _NSIG может рассматриваться и как допустимый номер сигнала.
Еще одна разумная проверка готовности. Главная идея заключается в том, чтобы убедиться в законности отправки сигналов. Ядро имеет право отправлять сигналы любому процессу, в то время как пользователи, отличные от привилегированного (root), не могут посылать сигналы процессам, принадлежащим другим пользователям, за исключением покрытого мраком случая с привлечением SIGCONT. В общем, длинное условие в if означает следующее:
(Строка ). Если дополнительная информация не задана или, если задана, но сигнал поступает от пользователя, а не от ядра, и...
(Строка ). ...сигнал — не SIGCONT или он SIGCONT, но отправляется другому процессу в том же сеансе и...
(Строки и ). ...актуальный идентификатор (ID) пользователя для отправителя — ни сохраненный ID пользователя для процесса-адресата, ни текущий ID пользователя для процесса-адресата, и...
(Строки и ). ...текущий ID пользователя для отправителя — ни сохраненный ID пользователя, ни текущий ID пользователя для процесса-адресата, и ...
(Строка ). ... пользователь не имеет полномочий послать сигнал (например, поскольку получатель — это root). В этом случае сигнал не посылается и происходит обход кода отправки сигналов.
Из рассмотренного выше условия можно сделать два заключения. Во-первых, если info равен 1 при приведении к unsigned long, то это не настоящий указатель на struct siginfo. Напротив, это специальное значение, указывающее, что сигнал поступает из ядра без дополнительной информации. Ядро никогда не распределяет память под собственные нужды в младшей странице (см. ), поэтому в качестве такого специального значения годится любой адрес, не превышающий 4096 и не равный 0, т.е. NULL.
Во-вторых, во многих местах условия место более общей операции логического неравенства (!=) занимает поразрядная операция XOR (^). В данном случае значение обеих операций одно и то же, поскольку если хотя бы один разряд в сравниваемых целочисленных значениях будет отличаться, тогда в результате выполнения XOR появится хотя бы один разряд, равный 1; это означает, что результат ненулевой и, следовательно, логически истинен. Причина применения XOR, возможно, связана с тем, что старые версии gcc для ^ генерировали более эффективный код, нежели для !=, хотя сейчас это не наблюдается.
Игнорирование сигнала 0 и отказ в отправлении сигнала мертвому процессу (т.е. процессу, который уже завершен, но пока еще не удален из структур данных системы; более подробную информацию о процессах можно найти в ).
Перед отправкой некоторых сигналов должна производится небольшая дополнительная работа. Именно в этом switch она и делается.
Если посылается SIGKILL или SIGCONT, send_sig_info пробуждает процесс (т.е. позволяет ему выполняться вновь, если он пребывал в состоянии останова).
Установка кода завершения для процесса в 0; если процесс был остановлен сигналом SIGSTOP, поле кода завершения используется для взаимодействия сигнала останова с родительским процессом.
Отмена всех ожидающих SIGSTOP (останов по запросу отладчика), SIGTSTP (останов по запросу от клавиатуры, например после нажатия Ctrl+Z), SIGTTIN (фоновый процесс пытается читать из TTY) и SIGTTOU (фоновый процесс пытается записывать в TTY); сложились условия, которые остановили процесс и возможной реакцией на станов стал SIGCONT или SIGKILL.
Обращение к recalc_sigpending (строка ) для выяснения, остались ли после удаления еще какие-либо ожидающие сигналы.
В предыдущем случае по прибытию SIGCONT или SIGKILL отменялись четыре сигнала. Частично ради симметрии, если поступает один из этих четырех сигналов, отменяются все ожидающие SIGCONT. Однако, SIGKILL не отменяется, поскольку SIGKILL принципиально не может ни блокироваться, ни отменяться.
Если процесс-получатель желает, и это разрешено, проигнорировать пришедший сигнал, сигнал игнорируется.
Сигналы не реального времени не очередизуются, а это означает, что если второй экземпляр определенного процесса поступает до завершения обработки первого экземпляра, то второй экземпляр игнорируется. Как раз это здесь и выполняется (вспомните, что набор ожидающих сигналов для конкретного процесса хранится в поле signal структуры struct task_struct).
А вот сигналы реального времени — очередизуются, но с определенными ограничениями. Наиболее важное ограничение — это настраиваемый верхний предел количества сигналов, которые могут присутствовать в очереди одновременно; это max_queued_signals, определяемый в строке и изменяемый при помощи характеристики sysctl. Если имеется место для помещения в очередь дополнительных сигналов, распределяется структура struct signal_queue.
Почему на первом месте находится максимальное количество присутствующих в очереди сигналов? Для того чтобы избежать ситуаций, связанных с отказом обслуживания. Если не предусмотреть такой предел, пользователи могут посылать сигналы реального времени до тех пор, пока не исчерпается память ядра и ядро попросту не сможет далее обслуживать процессы.
Если элемент очереди распределен, send_sig_info должна записать в него информацию о сигнале.
Добавление информации в очередь достаточно прямолинейно: send_sig_info увеличивает глобальное количество ожидающих сигналов и затем добавляет новый элемент в очередь сигналов для процесса-получателя.
Заполнение поля info элемента очереди на основе аргумента info, передаваемого в send_sig_info.
Значение 0 (NULL) означает, что сигнал отправлен пользователем и, возможно, был передан с использованием одной из обратно-совместимых функций посылки сигналов, которые определены в строках с по . Результирующая siginfo_t содержит относительно очевидные значения.
Значение 1 обозначает тот факт, что сигнал поступил от ядра, причем опять-таки, с использованием обратно-совместимых функций посылки сигналов. Как и в предыдущем случае, результирующая siginfo_t содержит относительно очевидные значения.
В нормальном случае send_sig_info получает реальную siginfo_t и может преспокойно копировать ее в элемент очереди.
Не распределен ни один элемент очереди — либо kmem_cache_alloc возвратила NULL в строке по причине нехватки памяти в системе, либо send_sig_info даже не пыталась распределить элемент, поскольку максимальное количество сигналов в очереди уже достигнуто. Так или иначе, но функция send_sig_info выполняет те же вещи: вне зависимости от того, отправлен ли сигнал ядром, либо сигнальными функциями старого стиля (например, kill), send_sig_info возвращает код ошибки EAGAIN. Этот код ошибки уведомляет отправителя, что в данный момент сигнал не может быть помещен в очередь, однако отправитель может попытаться послать тот же сигнал позже. В противном случае send_sig_info доставляет сигнал, не помещая его в очередь.
В конечном итоге, send_sig_info фактически готова доставить сигнал. Первоначально сигнал заносится в набор ожидающих сигналов для данного процесса. Следует заметить, что упомянутое занесение будет иметь место даже в случае, если сигнал заблокирован, — немного странно. Однако, для такого поведения есть все основания: ядро поддерживает функцию sys_sigpending (строка ), которая дает возможность процессам запрашивать, какие сигналы доставлялись заблокированными.
Если сигнал не является заблокированным, процесс будет уведомлен о его доставке. Соответственно, устанавливается его флаг sigpending.
Если процесс ожидал прибытия сигнала, а сигнал теперь ожидает процесса, последний пробуждается путем вызова функции wake_up_process (строка ) и может приступать к обработке сигнала.
Сервисные функции
Одна из наиболее важных структур данных, относящихся к сигналам, sigset_t, обслуживается набором простых функций, определенных в файле include/linux/signal.h, начало которого находится в строке . Те же функции для платформы х86 реализованы более оптимально, на ассемблере; их реализация начинается со строки . (Единственная платформа, которая отличается специфической реализацией рассматриваемого кода,— это m68k.) Поскольку для понимания важны как платформенно-независимая, так и версия для х86, мы рассмотрим обе реализации.
Set_intr_gate
set_intr_gate устанавливает запись в таблице дескрипторов прерываний (interrupt descriptor table— IDT) процессора x86. Каждое аппаратное или программное прерывание, происходящее в системе на базе процессора х86, имеет номер, который используется центральным процессором в качестве индекса этой таблицы. (Включая прерывание системных функций — с номером 0x80 — которое было рассмотрено в .) Соответствующими записями в таблице являются адреса функций (ядра), к которым необходимо выполнить переход в случае прерывания.
Setup_x86_irq
setup_x86_irq добавляет действие (структуру struct irqaction) для данного IRQ. Например, в строке это используется для регистрации прерывания таймера. Эта функция используется также, во время выполнения функции request_irq (строка ), которая исследуется в следующем разделе.
Linux использует несколько источников физических случайных величин — например, прерываний — для передачи потока случайных значений устройствам /dev/random, источника ограниченных, но выбираемых по совершенно случайному закону данных и /dev/urandom, неограниченного, но менее случайного аналога /dev/random. Система генерации случайных значений в целом не освещается в этой книге, но если не знать о ее существовании, этот фрагмент кода кажется весьма непонятным.
Если существующий список действий не пуст, setup_x86_irq должна убедиться, что существующие и новое действия согласны совместно использовать IRQ.
Убеждается, что IRQ может использоваться совместно всеми существующими структурами struct irqaction, уже связанными с этим IRQ. Эта проверка очень эффективна, частично благодаря тому, что нет необходимости выполнять цикл по всем действиям в очереди и что каждое из них будет использовать IRQ совместно с другими. Ни одному действию, следующему за первым, не будет разрешено присоединиться к очереди, если только это действие не согласится использовать IRQ совместно с первым действием. Таким образом, если первое действие будет использовать IRQ совместно, это же будут делать и остальные действия в очереди; а если первое действие не согласно использовать IRQ совместно с другими, в очереди вообще не будет никаких других действий.
IRQ, подлежащий совместному использованию, setup_x86 перемещает указатель р к концу очереди действий, оставляя его указывающим на поле next последнего элемента очереди. Кроме того, устанавливает флаг shared, который будет использоваться в строке .
Теперь указатель р указывает на поле next последнего элемента очереди, если IRQ должен использоваться совместно, или на irq_desc[irq].action — указатель начала очереди — если он не будет использоваться совместно. В любом случае указатель устанавливается на новый элемент.
Если с IRQ еще не были связаны никакие действия, остальная часть структуры irq_desc[irq] еще не установлена и, следовательно, нуждается в инициализации в этом месте. В частности, обратите внимание на строку , в которой вызывается функция startup для этого IRQ.
_SIG_SET_BINOP
Все три двоичных операции, которые требуется определить (sigorsets, sigandsets и signandsets), имеют практически одинаковые реализации. Рассматриваемый макрос просто выносит за скобки код, общий для всех трех операций, т.е. передаваться должны только имя и операция. Это очень похоже на шаблонные функции C++, за исключением того, что мы делаем работу самостоятельно, а не перекладываем ее на компилятор— цена, которую приходится платить за использование языка С.
Для начала следует пройтись по всей четверке значений типа unsigned long в sigset_ts, применяя заданные операции. Цикл организуется только для скорости — хорошо известная технология увеличения быстродействия за счет сокращения накладных расходов по управлению циклом. Однако, в большинстве случаев цикл никогда не выполняется. Например, для платформы х86 компилятор в состоянии выяснить, что тело цикла никогда не будет выполняться, поскольку результат целочисленного деления _NSIG_WORDS / 4 оказывается равным 0. (Вспомните, что для х86 _NSIG_WORDS определено как 2.)
Оператор switch в этой строке обрабатывает все результаты, полученные из цикла. Если имеет место платформа, для которой _NSIG_WORDS равен 6, цикл for будет выполняться один раз, равно как и случай 2 оператора switch. Для платформы х86 цикл for не выполняется ни разу, поэтому выполнится только случай 2 оператора switch.
Кстати, не вижу ни одной причины, почему switch не был реализован прямолинейно, подобно родственному ему _SIG_SET_OP, который рассматривается ниже.
Существующая версия несомненно лучше использует кэш (можете убедиться сами, когда начнете пытаться переписывать ее код), однако если уж это причина, то она в равной степени применима и для _SIG_SET_OP.
_SIG_SET_OP
_SIG_SET_OP подобен _SIG_SET_BINOP, но реализует унарные, а не бинарные операции. Поэтому не стоит рассматривать реализацию очень подробно. Несложно заметить, что код используется всего один раз (для генерации signotset в строке ), в отличие от _SIG_SET_BINOP. Следовательно, в определенном смысле этот код не нужен, поскольку можно было реализовать код напрямую, без посредничества _SIG_SET_OP. Однако, существующий подход позволяет упростить добавление кода других унарных операций, если в будущем возникнет подобная необходимость.
Sigaddset
sigaddset добавляет один сигнал в набор, т.е. устанавливает один разряд набора.
Преобразует нумерацию сигналов с основания1 в основание 0, чтобы достигнуть соответствия нумерации разрядов в поразрядных операциях.
Если сигналы помещаются в одно значение типа unsigned long, соответствующий разряд устанавливается в нем.
В противном случае sigaddset должна предпринять дополнительные действия, определив соответствующий элемент в массиве и установив корректный разряд в нем.
Строка , подобно и другому коду в этом файле, на первый взгляд вызывает легкое замешательство. Сущностью всего кода ядра является быстродействие. Таким образом, можно было бы рассчитывать, что вместо решения на этапе выполнения, подобного:
if (_NSIG_WORDS == 1) set->sig[0] |= 1UL << sig; else set->sig[sig / _NSIG_BPW] |= 1UL << (sig % _NSIG_BPW);
должно присутствовать решение на этапе компиляции:
#if (_NSIG_WORDS == 1) set->sig[0] |= 1UL << sig; #else set->sig[sig / _NSIG_BPW] |= 1UL << (sig % _NSIG_BPW); #endif
Неужели последний код не будет работать быстрее? В конце концов, ведь все условия в операторах if поддаются расчету на этапе компиляции, поэтому препроцессор может убрать все, что связано с проверкой на этапе выполнения.
Туман рассеивается, стоит только подумать о том, что те же действия делает также и оптимизатор. Оптимизатор gcc интеллектуален настолько, что способен выяснить, что оператор if может работать только в одной своей части и удалить код, который никогда не будет выполняться. Результирующий объектный код оказывается одинаковым как для версии «этапа выполнения», так и для версии «этапа компиляции».
Но почему бы не счесть второй вариант кода, основанный на использовании препроцессора, в любом случае более удачным, вдобавок предположив наличие не очень хорошего оптимизатора? Нет необходимости. С одной стороны, такой код более труден в понимании. Разница в читабельности становится более ощутимой, когда речь идет о более сложном коде. Возьмите, например, фрагмент с оператором switch в sigemptyset, который начинается в строке . Сейчас упомянутый фрагмент кода выглядит так:
switch (_NSIG_WORDS) { default: memset(set, 0, sizeof(sigset_t)); break; case 2: set->sig[1] = 0; case 1: set->sig[0] = 0; break; }
(Отметьте преднамеренную перестановку порядка случаев 2 и 1.) Если код переписать так, чтобы задействовать препроцессор, он может выглядеть так:
#if ((_NSIG_WORDS != 2) && \ (_NSIG_WORDS != 1)) memset(set, 0, sizeof(sigset_t)); #else /* (_NSIG_WORDS is 2 or 1. */ #if (_NSIG_WORDS == 2) set->sig[1] = 0; #endif set->sig[0] = 0; #endif /* _NSIG_WORDS test. */
Оптимизатор gcc сгенерирует один и тот же объектный код для обоих случаев. Какая из версий кода более удобочитаема?
Кроме того, если оптимизатор не настоль хорош (это один из относительно простых случаев оптимизации), то компилятор, возможно, в любом случае не сможет сгенерировать качественный код. Поэтому все жертвы, которые мы ему принесем, окажутся напрасными. Пожалуй, в такой ситуации лучше все-таки писать более понятный код, который будет проще и сопровождать. (Кстати, это еще один общепринятый компромисс.) В конечном итоге, как было показано ранее и вновь можно заметить сейчас, компиляция ядра не под gcc большого воодушевления не вызывает.
Sigaddsetmask
Эта и несколько следующих функций содержат по одной строке кода, которые упрощают и ускоряют чтение и установку младших 32-х (или стольких, сколько определяет размер слова) сигнала. sigaddsetmask устанавливает разряды в соответствие с mask.
Sigdelset
Этот код весьма похож на код sigaddset, с той лишь разницей, что здесь разряд удаляется из набора, т.е. сбрасывается.
Аналогично, специфическая для платформы х86 реализация sigdelset с использованием команды btrl очищает один разряд в передаваемом ей операнде.
Sigemptyset
sigemptyset очищает поддерживаемый набор, т.е. сбрасывает все разряды. (Следующая функция sigfillset идентична данной, с той лишь разницей, что она устанавливает все разряды. Подробно ее реализацию рассматривать не будем.)
В общем случае производится обнуление всех разрядов набора при помощи функции memset.
Для небольших значений _NSIG_WORDS быстрее просто напрямую установить один или два элемента sigset_t, что, собственно, здесь и делается.
Sigfindinword
Эта функция возвращает первый установленный в слове разряд. Функция ffz (не рассматриваемая в книге) возвращает позицию первого равного 0 разряда, содержащегося в передаваемом ей аргументе. Позиция первого равного 0 разряда в поразрядно инвертированном слове (что, собственно, и делает функция) — суть то же самое, что и позиция первого разряда, равного 1, в оригинальном слове. Подсчет позиции ведется с 0 и в направлении от младших разрядов к старшим.
В завершение, специфическая для платформы х86 реализация sigfindinword использует команду bsfl, которая отыскивает установленный разряд в передаваемом ей операнде.
Siginfo_t
Структура struct siginfo (известная также как siginfo_t) хранит дополнительную информацию, отправляемую вместе с сигналом, в особенности, сигналом реального времени.
Ничего удивительного, si_signo— это номер сигнала.
Предположительно, si_errno — это значение errno отправителя в момент посылки им сигнала, так что получатель может проверить это значение. Само ядро абсолютно не заботится об этом значении; в тех немногих случаях, когда это поле устанавливается, оно устанавливается в 0.
si_code записывает источник сигнала (не идентификатор процесса (PID) источника, который записывается в другом месте). Допустимые значения источников сигнала объявлены, начиная со строки .
Последний компонент структуры имеет тип union; он относится к типам union, которые используются в зависимости от значения si_code.
Первый компонент union — это _pad, который дополняет размер siginfo_t до 128 * sizeof(int) байт (для платформы х86 значение составляет 512). Следует заметить, что размер этого массива SI_PAD_SIZE (строка ) рассчитан для первых трех полей структуры, т.е. при добавлении в структуру новых полей соответствующим образом корректируется и SI_PAD_SIZE.
Siginitset
Устанавливает младшие 32 (или сколько-то) разрядов из передаваемого mask и сбрасывает все другие разряды. Следующая функция, siginitsetinv (строка ), делает обратное: устанавливает младшие 32 (или сколько-то) разрядов из передаваемого инвертированного mask и устанавливает все прочие разряды.
Sigismember
Опять-таки, код похож на код sigaddset, но здесь выполняется проверка, установлен ли разряд. Заметьте, что строка работала бы так же хорошо, имея вид:
return set->sig[0] & (1UL << sig);
Большинство сказанного применимо и к строке . Это нельзя расценивать как усовершенствование, однако можно воспринимать как существенно более согласованый вариант по сравнению с текущей реализацией этих функций.
После такого изменения поведение функций приобрело бы слегка другой оттенок: сейчас они возвращают 0 или 1, а в нашем случае они возвращали бы другое ненулевое значение, если разряд установлен. Однако подобное изменение не разрушило бы существующий код, поскольку вызывающие функции проверяют, равно возвращаемое значение 0 или нет, а равно ли оно конкретно1 — их особо не заботит.
sigismember выбирает реализацию на основе того, является ли передаваемый аргумент константным выражением, подсчитанным на этапе компиляции. Недокументированное чудо __builtin_constant_p компилятора gcc представляет собой оператор этапа компиляции (наподобие sizeof), который выясняет, может ли его аргумент быть вычислен на этапе компиляции.
Если это так, sigismember использует для обсчета значения функцию __const_sigismember (строка ). В противном случае применяется более общая версия __gen_sigismember (строка ). В этой более общей версии задействована команда btl, проверяющая один разряд в передаваемом ей операнде.
Следует отметить, что константа времени компиляции в результирующий код не попадает, а это значит, что вся проверка осуществляется во время компиляции— по сути, sigismember просто заменяется либо __const_sigismember, либо __gen_sigismember, безо всякого намека в объектном кода даже на сам факт подобной замены. Правда, неплохо?
Sigmask
В конце всего полезный макрос sigmask преобразует номер сигнала в поразрядную маску с соответствующим набором разрядов.
Специфическая для платформы х86 реализация sigmask идентична своей платформенно-независимой версии.
Сигналы
Ядро Linux разделяет сигналы на две категории:
Сигналы не реального времени (nonrealtime). Наиболее традиционные сигналы Unix, такие как SIGSEGV, SIGHUP и SIGKILL.
Сигналы реального времени (realtime). Одобренные стандартом POSIX 1003, они обладают несколько отличающимися характеристиками по сравнению с их аналогами не реального времени. Сигналам реального времени присущ смысл, связанный с конфигурированием процессов, как в случае с сигналами не реального времени SIGUSR1 и SIGUSR2, кроме того, вместе с ними поступает и дополнительная информация. Они также поддаются очередизации, так что если множество экземпляров сигнала поступает до того, как обрабатывается первый поступивший, то все сигналы будут доставлены по назначению. Последнее не справедливо для сигналов не реального времени.
В подробно рассказывается, что означает и не означает понятие «реальное время» для ядра.
Множество #define для номеров сигналов берет свое начало в строке . Номера сигналов реального времени находятся в пределах от SIGRTMIN до SIGRTMAX (соответственно, строки и ).
Sigset_t
sigset_t представляет набор сигналов. В зависимости от мест использования, структура обозначает различные вещи: например, она может хранить набор сигналов, ожидающих процесса (подобно полю signal в struct task_struct; см. строку ) или набор сигналов, которые должны быть заблокированы по запросу от некоторого процесса (как в поле blocked той же структуры). Далее будут встречаться и другие применения sigset_t.
Единственный компонент в sigset_t— это массив значений типа unsigned long, каждый разряд которого соответствует одному сигналу. Следует заметить, что на тип unsigned long по всему коду ссылаются как на «слово», которое может оказаться не тем, что вы могли ожидать — даже если речь идет о современных х86-подобных процессорах, «слово» иногда означает 16 разрядов. Поскольку Linux является истинной 32-разрядной ОС, вполне корректно предполагать, что длина слова составляет 32 разряда. (На мой взгляд, немного неаккуратно называть Linux «истинной 32-разрядной ОС», поскольку тот же Linux является и истинной 64-разрядной ОС на 64-разрядных процессорах.)
Размер обсуждаемого сейчас массива, _NSIG_WORDS, в лоб рассчитывается в строке . (Аббревиатура «BPW» в _NSIG_BPW означает «bits per word», т.е. количество разрядов на слово.) Для различных платформ _NSIG_WORDS варьируется от 1 (Alpha) до 4 (MIPS). Что касаемо платформы х86, то это значение равно 2, а это означает, что два значения типа unsigned long содержат достаточно разрядов для представления всех сигналов, используемых Linux на этой платформе.
Struct sigaction
struct sigaction представляет действие, которое должен выполнить процесс по приходу сигнала. Структура помещена в рамки структуры struct k_sigaction (строка ), которая, в свою очередь, — в рамки struct signal_struct, на экземпляр которой ссылается поле sig структуры task_struct (строка ). Если этот указатель равен NULL, процесс завершается и не будет получать каких бы то ни было сигналов. В противном случае каждый процесс имеет _NSIG структур struct sigaction, по одной struct sigaction на каждый номер сигнала.
sa_handler (типа __sighandler_t — тип указателя на функцию, определенный в строке ) определяет, как процесс будет обрабатывать сигнал. sa_handler может принимать одно из следующих значений:
SIG_DFL (строка ) требует выполнения стандартного действия для сигнала, причем в зависимости от конкретного сигнала. Следует заметить, что SIG_DFL эквивалентен NULL.
SIG_IGN (строка ) означает, что сигнал будет игнорироваться. Однако, не все сигналы можно проигнорировать.
Любое другое значение, представляющее адрес функции из пространства пользователя, которая будет вызываться по приходу сигнала.
sa_flags выполняет дальнейшую специализацию действия кода обработки сигнала. Определения множества допустимых флагов начинается со строки . Эти флаги дают возможность пользовательскому коду восстанавливать стандартные действия после доставки одного экземпляра сигнала, сохранять установленные действия и т.д., в соответствии с комментариями, приведенными выше блока объявлений флагов.
sa_restorer используется в ряде фрагментов кода обработки сигналов, рассмотрение которых выходит за рамки этой книги.
sa_mask представляет собой набор сигналов, которые должны быть заблокированы в течение обработки данного сигнала. Например, если для процесса необходимо заблокировать сигналы SIGHUP и SIGINT, пока обрабатывается SIGCHLD, тогда относящаяся к SIGCHLD sa_mask для процесса устанавливает разряды, соответствующие SIGHUP и SIGINT.
Struct signal_queue
struct signal_queue используется для обеспечения доставки всех сигналов реального времени вместе со вспомогательной информацией (siginfo_t) для каждого сигнала. Как будет показано далее, ядро поддерживает отдельную очередь ожидающих сигналов реального времени для каждого процесса. Тип собственно очереди минимален и включает только указатель на следующий элемент очереди, а также siginfo_t.
Структуры данных
В этом разделе рассматриваются наиболее важные структуры данных, используемые в коде обработки сигналов.
Просмотрев несколько из них, читатель получит представление о всех. Этот фрагмент был выбран, как читатели вероятно догадались, из раздела файла, содержащего идентификаторы устройств для РСI-видеоплат на основе чипов S3.
Хотя dev_id является указателем, он ни на что не указывает и попытка раскрыть его была бы ошибкой. Значение имеет только его разрядный шаблон.
next — указатель на следующую структуру struct irqaction в очереди, если IRQ используется совместно. Обычно IRQ не является используемым совместно, и, следовательно, значение этого члена равно NULL.
Следующие две представляющие интерес структуры данных находятся в архитектурно-зависимом файле arch/i386/kernel/irq.h. Первая структура struct hw_interrupt_type (строка ) аннотирует контроллер прерываний. В основном, она представляет собой набор указателей на функции, которые выполняют характерные для контроллера операции:
typename — читабельное имя контроллера.
startup — разрешает в этом контроллере события данного IRQ.
shutdown — запрещает в этом контроллере события данного IRQ.
handle — обрабатывает отдельное прерывание в IRQ, переданного функции.
enable и disable — в основном аналогичны startup и shutdown; существующие различия не имеют значения ни для одного из кодов, анализируемых в этой книге. (Фактически, функции enable/disable и startup/shutdown идентичны для всех приведенных в книге кодов.)
Вторая, представляющая интерес структура данных этого файла, irq_desc_t (строка ), имеет следующие члены:
status — целое значение, разряды которого для ноля или более флагов получены из набора, определенного в строках с по . Вместе они представляют состояние IRQ — отключен ли IRQ, являются ли в настоящий момент связанные с IRQ устройства автоматически определяемыми и т.п.
handler — указатель на структуру struct hw_interrupt_type.
action — указывает на начало очереди структур struct irqaction. Обычно, как отмечалось ранее, для каждого IRQ существует только одно действие, поэтому связанный список имеет длину равную 1 (или 0). Но, если IRQ используется совместно двумя или более устройствами, в очереди будет соответствующее количество действий.
depth — количество текущих пользователей этой структуры irq_desc_t. В основном этот член используется, чтобы убедиться в том, что IRQ не отключен, пока событие обслуживается.
Структуры irq_desc_t организуются в массив irq_desc (строка ). Для каждого IRQ существует одна запись массива, и таким образом массив сопоставляет номер каждого IRQ соответствующему обработчику и другой информации в структуре irq_desc_t.
Последний заслуживающий упоминания набор структур данных начинается в строке ; эти структуры связанны с нижними половинами:
bh_mask_count (строка ) — массив, который отслеживает вложенные пары запросов включения/отключения для каждой нижней половины. Эти запросы выполняются посредством вызова функций enable_bh (строка ) и disable_bh (строка ), Каждый запрос на отключение увеличивает значение счетчика; каждый запрос на включение уменьшает его. Если значение счетчика достигает 0, значит все непогашенные отключения были замещены включением, и, следовательно, нижняя половина наконец снова включена.
bh_mask и bh_active (строки и A HREF="part1_39.htm#l14857">14857) — вместе эти члены управляют тем, будет ли выполнена нижняя половина. Каждый из них имеет 32 разряда, по одному разряду на нижнюю половину. Когда верхняя половина (или какая-либо другая часть кода) решает, что его нижняя половина должна быть выполнена, она помечает ее, устанавливая разряд в bh_active (используя mark_bh, строка ). Независимо от того, была ли она помечена таким образом, нижняя половина может быть полностью отключена посредством очистки соответствующего разряда в bh_mask — enable_bh и disable_bh делают это, одновременно настраивая запись bh_mask_count.
Следовательно, поразрядное AND членов bh_mask и bh_active определяет, какие нижние половины должны быть выполнены. В частности, если результатом поразрядаого AND является 0, никакие нижние половины не должны быть выполнены. Эта технология используется в ядре неоднократно, как, например, в макросе get_active_bhs (строка ).
bh_base (строка ) — это просто массив указателей на функции нижней половины.
Неименованная структура enum — неименованная структура enum, начинающаяся в строке , связывает символическое имя с каждой из используемых ядром нижних половин. Например, чтобы пометить в качестве активной нижнюю половину таймера, нужно было бы написать:
mark_bh (TIMER_BH);
Строка именно это и делает.
Sys_kill
sys_kill представляет собой обманчиво простую реализацию системного вызова kill; реальная работа сокрыта в kill_somethmg_info, к которому вы вернемся несколько позже. sys_kill принимает следующие аргументы: отправляемый сигнал sig и идентификатор адресата, которому предназначается сигнал, pid. Как вскоре будет показано, pid может и не быть идентификатором процесса. (PID и другие базовые концепции, связанные с процессами, рассматриваются в .)
Объявление и заполнение структуры struct siginfo на основе информации, переданной в sys_kill. В частности, поле si_code устанавливается в SI_USER (поскольку этот системный вызов может выполнить только пользовательская программа; само ядро этого никогда не делает, предпочитая пользоваться низкоуровневыми функциями).
Передает подготовленную информацию в функцию kill_something_info, которая и делает всю работу.
Sys_rt_sigprocmask
sys_rt_sigprocmask очень похожа на функцию sys_sigprocmask, но она учитывает также новые сигналы реального времени. В связи со сходством этих двух функций, здесь освещаются только примечательные различия между ними.
Если взять в качестве примера SIG_BLOCK, вместо кода, аналогичного
/* Как sys_sigprocmask выполняет SIG_BLOCK. */ new_set = *set; /* Строка 28939 */ blocked |= new_set; /* Строка 28952 */
используется код
/* Как sys_rt_sigprocraask выполняет SIG_BLOCK. */ new_set = *set; /* Строка 28625 */ new_set |= old_set; /* Строка 28639 */ blocked = new_set; /* Строка 28648 */
He нахожу ни одной причины, почему sys_rt_sigprocmask не может быть реализована так же, как sys_sigprocmask, причем с небольшим выигрышем в производительности.
Sys_rt_sigtimedwait
Функция sys_rt_sigtimedwait ожидает прибытия сигнала, необязательно выходя из этого состояния по истечении указанного интервала времени. Не каждый сигнал будет принят; sigset_t, на которую указывает uthese, сообщает, каким сигналом интересуется вызывающий процесс.
Объект uthese (скопированный в локальную переменную these) — это набор разрешенных сигналов, но примитивы ядра знают только как блокировать сигналы. Однако все в порядке: инвертирование набора разрешенных сигналов превращает их в набор сигналов, подлежащих блокированию, который затем можно использовать непосредственно.
Если вызывающий процесс передал значение истечения времени ожидания, оно копируется в область пользователя и его значение подвергается профилактической проверке.
Проверяет, дожидается ли обработки какой-либо сигнал — если да, то нет необходимости дожидаться сигнала. В противном случае вызывающий процесс должен подождать.
Сохраняет старый блокируемый набор и временно ограничивает набор заблокированных сигналов в соответствие со значением, определенным переменной these.
Если пользователь не передал никакого значения истечения времени ожидания, этим значением будет MAX_SCHEDULE_TIMEOUT (определенное переменной LONG_MAX, или значением 231–1 в строке ). Это не навсегда — значение истечения времени ожидания выражается в мигах, количестве тиков системных часов, частота которых равна 100 в секунду; таким образом, время ожидания составляет около 248 дней. (На 64-разрядном компьютере это значение составляет около 3 миллиардов лет.)
Если пользователь передал значение истечения времени ожидания, оно преобразуется в миги. Часть этого выражения, которая следует за символом «+» — разумный способ выполнения округления до следующего мига. Смысл этого заключается в том, что функция timespec_to_jiffies (строка ) может выполнять округление в сторону уменьшения, в то время как ядро должно выполнять округление в сторону увеличения, поскольку оно должно выждать не меньше мигов, чем запросил пользователь. Ядро могло бы проверять, не выполнила ли функция timespec_to_jiffies округление в сторону уменьшения, но использованный способ дешевле и проще: оно добавляет один миг, если переданное пользователем значение не было нулем, и больше о нем не беспокоится. В любом случае, Linux не является операционной системой реального времени — когда пользователь просит о выжидании, ему гарантируется лишь то, что Linux выждет не меньше указанного интервала времени.
Устанавливает состояние текущего процесса в TASK_INTERRUPTIBLE (см. ). Функция schedule_timeout (строка ) используется для освобождения процессора; выполнение продолжится либо по истечении указанного времени, либо, если произойдет какое-либо другое событие, пробуждающее процесс (например, повторное получение сигнала).
Процесс исходит из предположения, что он был пробужден сигналом. Функция sys_rt_sigtimedwait снова пытается вытолкнуть сигнал из очереди сигналов, дожидающихся этого процесса, и восстанавливает старый блокируемый набор.
На данный момент функция все еще не знает, прибыл ли сигнал — мог быть получен сигнал, не требующий ожидания, сигнал мог прибыть во время ожидания или функция могла ожидать, а никакой сигнал не прибыл.
Если сигнал прибыл, функция доставляет информацию процессу пользователя и возвращает номер сигнала.
В противном случае, несмотря на то, что сигнал ожидается, никакой сигнал не прибыл. В этом случае функция возвращает либо -EAGAIN (указывая, что процесс пользователя может повторить попытку с этими же аргументами), либо -EINTR (указывая, что ее ожидание было прервано сигналом, который по какой-либо причине не смог быть доставлен).
Sys_sigpending
Эта короткая системная функция позволяет процессам запрашивать о прибытии каких-либо сигналов не реального времени, пока они были заблокированы. Посредством передаваемого указателя функция возвращает набор разрядов, который указывает, какие это были сигналы.
В основе этой функции лежит простая поразрядная операция AND с наборами blocked и signal процесса. Значение -EFAULT возвращается, если операция не удается, а значение 0— если она выполняется успешно. Обратите внимание, что пребывание любых сигналов в состоянии задержки — т.е. то, пуст ли возвращаемый набор — не является критерием успешности операции.
Sys_sigprocmask
sys_sigprocmask — исходная версия этой функции, ничего не знающая о сигналах реального времени. Аргумент how указывает операцию, подлежащую выполнению; аргумент set, если его значением является не NULL, служит операндом этой операции; старый блокируемый набор возвращается посредством аргумента oset, если его значение — не NULL.
Если значением set является NULL, значение аргумента how не важно: оператор не будет иметь операнда, следовательно, функция ничего не сможет с ним сделать. В противном случае она приступает к выполнению оператора.
Копирует новый блокируемый набор, удаляя сигналы SIGKILL и SIGSTOP, которые не подлежат блокировке.
Сохраняет копию текущего блокируемого набора в переменной old_set на тот случай, если в будущем его потребуется копировать обратно в область пользователя. В последующем коде текущий блокируемый набор вероятно будет изменен, поэтому перед изменением его значение должно быть сохранено.
Естественно, неверные операторы игнорируются.
Оператор SIG_BLOCK указывает, что переменная new_set должна интерпретироваться в качестве набора дополнительных сигналов, подлежащих блокированию. Сигналы добавляются в блокируемый набор.
Оператор SIG_UNBLOCK указывает, что переменная new_set должна интерпретироваться в качестве набора сигналов, подлежащих удалению из блокируемого набора. Сейчас они удаляются.
Оператор SIG_SETMASK указывает, что переменная new_set должна интерпретироваться в качестве нового блокируемого набора посредством простой перезаписи ее предшествующего значения. Функция sys_sigprocmask именно это и делает. Обратите внимание, что она устанавливает только самый нижний элемент массива blocked.sig — этот элемент содержит младшие 32 разряда, определяющие сигналы не реального времени, о которых только и заботится эта функция.
Если вызывающий процесс запрашивает предшествующее значение блокируемого набора, выполняется переход вперед к метке set_old (строка ).
Если значением set было NULL, значит, вызывающий процесс не просит изменить блокируемый набор, но ему все же может требоваться знать текущее значение блокируемого набора.
Значением oset было не NULL (и, возможно, значением set, также). Во всяком случае, переменная old_set содержит копию старого блокируемого набора, которую функция sys_sigprocmask пытается скопировать обратно в область пользователя прежде, чем выполнить возврат.
Timer_bh
Это нижняя половина таймера. Она вызывает функции, предназначенные для обновления связанных со временем статистических данных процесса и самого ядра и для обслуживания таймеров ядра, как в старом, так и в новом формате.
Update_times
В основном, эта функция обновляет статистические данные: она вычисляет среднюю загрузку системы, обновляет глобальную переменную, которая отслеживает текущее время, и обновляет вычисленный ядром объем времени центрального процессора, который потребуется текущему процессу.
Получает количество тиков таймера, произошедших с момента последнего выполнения нижней половины, и сбрасывает счетчик.
Если данное количество не равно 0 (нормальная ситуация), update_times определяет, сколько из этих тиков произошло в системном режиме.
Обращение к calc_load (строка ) для обновления приближения показателя загрузки системы, необходимого ядру.
Обращение к update_wall_time (строка ) для обновления xtime, которая отслеживает граничное время.
Обращение к update_process_times (строка ), которая вместе со вспомогательной функцией update_one_process (строка ) обеспечивает обновление общего времени выполнения текущего процесса. Подобного рода статистика выдается такими общеиспользуемыми программами, как time, top и ps. Несложно заметить, что выдаваемая программами статистика не настоль точна, как этого хотелось бы: если процесс запланирован как такой, который никогда не выполняется в течение прерывания от таймера, он может потреблять циклы ЦП безо всякого отражения в статистических данных. Однако, очень трудно понять, почему и как таким «злостным» процессам удается это делать; для процессов «с хорошими намерениями» статистика естественным образом усредняется.
Update_wall_time
Вызов update_wall_time_one_tick (строка ) для каждого обрабатываемого тика. Это приводит к обновлению глобальной переменной xtime, по возможности синхронизируя ее с реальным временем с целью соответствия с протоколом Network Time Protocol.
Преобразование xtime в микросекунды, лежащие в диапазоне от 0 до 999999. Для исключительно нежелательных событий, отымающих у таймера более секунды, компонент tv_usec, принадлежащий xtime, может содержать значения более 2000000, поэтому данный код не сможет выполнить нормализацию xtime. Однако, xtime будет окончательно нормализована в последующих вызовах.
Время и таймер
В этом разделе в ходе рассмотрения работы примера прерывания (прерывания таймера) связывается воедино все, что читателям уже известно о прерываниях и нижних половинах.
Функция прерывания таймера timer_interrupt связывается с IRQ0 в строке . Используемая здесь переменная irq0 определяется в строке . Посредством использования функции init_bh (строка ) в строке функция timer_bh регистрируется в качестве нижней половины обработчика прерывания таймера.
Когда IRQ 0 запускается, timer_interrupt считывает некоторые значения из счетчика отметок времени центрального процессора, если таковой имеется (этот счетчик используется некоторыми кодами, не рассматриваемыми в этой книге), а затем вызывает функцию do_timer_interrupt (строка ). Кроме выполнения некоторых других задач, эта функция вызывает функцию do_timer, которая является интересной частью прерывания таймера.
