Адресное пространство
Адресное пространство — это просто диапазон адресов, обозначающих определенное место в памяти. Адресные пространства подразделяются на три разновидности:
Физическое адресное пространство
Линейное адресное пространство
Логическое адресное пространство, известное также как виртуальное адресное пространство
(Многие считают адреса ввода/вывода четвертым типом адресного пространства, но в этой книге они не рассматриваются.)
Физические адреса — это реальные, аппаратные адреса, доступные в системе. Если в системе имеется 64 Мб памяти, в ней допустимые физические адреса могут находиться в диапазоне от 0 до 0x3fffffff (в шестнадцатиричном формате). Каждый адрес соответствует одному набору транзисторов в микросхемах SIMM, установленных вами (или изготовителем), и отдельному сочетанию сигналов на адресной шине процессора.
Страничный обмен позволяет перемещать процессы или только фрагменты процессов в различные области физической памяти (различные физические адреса) и обратно в течение срока существования процесса. Именно по этой причине процессам предоставляется пространство логических адресов. Когда речь идет о любом конкретном процессе, предусмотренное для него его адресное пространство начинается с 0 и продолжается (в Linux) до шестнадцатиричного адреса 0xbfffffff, составляя адресное пространство в 3 Гб, вполне достаточное для обычных потребностей. Несмотря на то, что каждому процессу предоставляется одинаковое логическое пространство, соответствующие физические адреса для каждого процесса различны, поэтому в действительности они не могут помешать друг другу.
Для обеспечения работы ядра и логические, и физические адреса подразделяются на страницы. Поэтому, рассуждая о логических и физических адресах, мы должны всегда подразумевать под этим логические и физические страницы: каждый действительный логический адрес располагается на одной и только одной логической странице, и это же касается физических адресов.
В противоположность этому, линейные адреса обычно не рассматриваются как адреса, находящиеся на страницах. Процессор (на самом деле модуль управления памятью, рассматриваемый ниже) преобразует логические адреса, используемые процессом, в линейные адреса с применением способа, зависящего от архитектуры. В архитектуре х86 это преобразование предусматривает простое сложение виртуального адреса с другим адресом — базовым адресом сегмента процесса; поскольку этот базовый адрес устанавливается равным 0 для любой задачи, логические адреса и линейные адреса в этой архитектуре одинаковы. Затем результирующий линейный адрес преобразуется в физический адрес для взаимодействия с оперативной памятью системы.
Brk
Системный вызов brk— это примитивная операция, лежащая в основе библиотечных функций malloc и free языка С. Значение brk процесса — это граничная точка между пространством кучи процесса и обычно неотображаемой областью между его кучей и стеком. Если рассматривать это значение под другим углом, оно обозначает максимальный допустимый адрес кучи процесса.
Куча располагается между вершиной сегмента кода и brk. Поэтому библиотечная функция malloc языка С активизирует значение brk, если уже не доступен достаточный объем свободного пространство ниже brk для выполнения запроса; функция free может уменьшить значение brk, если освобождаемое пространство располагается непосредственно под brk. Кстати, Linux — это единственный вариант Unix, известный автору, в котором действительно происходит сокращение пространства памяти процесса после освобождения; в коммерческих вариантах системы Unix, с которыми работал автор, это пространство остается зарезервированным за процессом, очевидно, «на всякий случай». (В других бесплатных версиях Unix, вероятно, предусмотрено то же, что и в Linux, но автор не имеет опыта работы с ними.) Между прочим, при распределении больших объемов в библиотеке С версии GNU для реализации функций malloc и free используются системные вызовы mmap и munmap.
Взаимосвязь между кодом, данными и стеком показана на рис. 8.5.
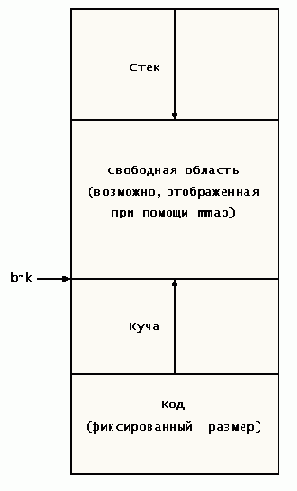
Рис. 8.5. Код, данные и стек
Буфера хранения результатов преобразования
При непродуманной реализации преобразование линейных адресов в физические адреса потребовало бы нескольких обращений к памяти по мере прохождения цепочки указателей. Оперативная память работает намного быстрее диска, но все же значительно медленнее по сравнению с процессором, поэтому такой способ вполне мог бы стать причиной возникновения узкого места с точки зрения производительности. В целях снижения издержек самые последние результаты выполнения преобразования адресов хранятся в буферах хранения результатов преобразования TLB (translation lookaside buffer) модуля MMU. Системе Linux не приходится явно управлять этими буферами TLB, если не считать того, что иногда в системе возникает необходимость сообщить процессору, что содержимое буферов TLB потеряло актуальность в результате каких-то действий ядра.
Из всех функций и макрокоманд, которые работают с TLB, мы рассмотрим только __flush_tlb; однако эта функция в архитектуре х86 является основой большинства других функций.
Дамп памяти
При определенных обстоятельствах, например, когда сбойная программа пытается обратиться к памяти за пределами отведенного ей пространства памяти, процесс может выполнить дамп памяти. Так называемый «дамп памяти» сводится к записи образа пространства памяти процесса, наряду с некоторой идентификационной информацией о самом приложении и о его состоянии, в файл для дальнейшего изучения с применением отладчика типа gdb. (В именах этих функций слово «core» является устаревшим синонимом слова «memory»— память.)
Безусловно, в вашем коде никогда не возникают подобные ошибки, но поскольку они могут появиться у менее талантливого программиста из соседнего отдела, и он придет к вам за помощью, рассмотрим эту тему.
Различные двоичные обработчики выполняют дамп памяти по-разному. (Двоичные обработчики описаны в .) Наиболее распространенным двоичным форматом Linux является ELF, поэтому рассмотрим, как двоичный обработчик ELF выполняет дамп памяти.
Динамическая память пространства пользователя и пространства ядра
И задачи пользователя и само ядро часто должны распределять память динамически. Программы С в основном выполняют это с помощью широко известных функций malloc и free; ядро имеет свой собственный аналогичный механизм. Безусловно, ядро должно предоставить в распоряжение пользователя, по крайней мере, операции нижнего уровня, которые обеспечивают возможность выполнения функций malloc и free языка С.
В Linux, как и в других разновидностях Unix, область данных процесса подразделяется на две части разного назначения — на стек и кучу. Чтобы предотвратить столкновение этих частей, стек начинается с верхней части (фактически, рядом с ней) доступного адресного пространства и растет вниз, в область младших адресов, а куча начинается непосредственно над сегментом кода и растет вверх. Между кучей и стеком находится «ничейная земля» обычно неиспользуемой памяти, хотя память может быть распределена и в этом месте с помощью mmap.
Можно получить довольно хорошее представление о том, где находятся эти области адресов, даже не изучая соответствующий код ядра (хотя, безусловно, мы именно этим и занимаемся). В следующей короткой программе показаны адреса нескольких избранных объектов в этих трех различных областях. По разным причинам нельзя гарантировать перенос этого кода на все платформы, но он будет работать на любой версии Linux и должен работать на большинстве других платформ, где вы его проверите.
#include <stdio.h> /* printf() */ #include <stdlib.h> /* malloc() */ static void one(void * p, const char * description) { printf("%10p: %s\n", p, description); }
int main(void) { int i; int j; one(&i, "A stack variable, \"i\""); one(&j, "Next stack variable, \"j\""); one((void *) one, "The function \"one\""); one((void *) main, "The function \"main\""); one(malloc(1), "First heap allocation"); one(malloc(1), "Second heap allocation"); return 0; }
В своей системе автор получил следующие числа. Вы можете получить немного другие результаты, в зависимости от ваших версий ядра и gcc, а также от того, какие флажки компилятора вы использовали. Однако они все равно будут довольно близки к этим результатам, а может даже идентичны.
0xbffff824: A stack variable, "i" 0xbffff820: Next stack variable, "j" 0x80484a0: The function "one" 0x80484bc: The function "main" 0x80496f8: First heap allocation 0x8049708: Second heap allocation
Очевидно, что стек, грубо говоря, начинается примерно с адреса 0хC0000000 и растет вниз, код начинается примерно с 0x8000000, а куча, как мы и утверждали, начинается немного выше кода и растет вверх.
Do_mmap
Функция do_mmap принимает несколько параметров; вместе они определяют файл или устройство, которое должно быть отображено в память, если оно указано, а также предпочтительный адрес и характеристики области памяти, которая должна быть создана.
Величина TASK_SIZE составляет то же, что и PAGE_OFFSET, которая определена в строке ; она равна 0хс0000000 или 3 Гб. Это максимальный объем памяти, который может занимать любой пользовательский процесс, в чем и состоит назначение этого кода: очевидно, что если от функции do_mmap потребуют распределить более 3 Гб или в пространстве адресов 3 Гб вслед за addr не осталось достаточно места, запрос должен быть отвергнут.
Если параметр file имеет значение NULL, это значит, что функция do_mmap получила запрос выполнить анонимное отображение, т.е. отображение, которое фактически не подключено к какому-либо файлу или к другому специальному объекту. В ином случае отображение связано с файлом и do_mmap должна перейти к проверке того, что флажки, которые предполагается установить для этой области памяти, совместимы с операциями, которые пользователю разрешено выполнять с этим файлом. Например, в строке функция проверяет, что если область памяти предназначена для записи, файл был открыт для записи. Пропуск этих проверок создавал бы возможность игнорировать проверки, которые были выполнены при открытии файла.
Вызывающей программе разрешено настаивать на том, чтобы функция do_mmap либо предоставила отображение по затребованному адресу, либо вообще его не предоставила. В таком случае функция do_mmap просто проверяет, что указанный адрес начинается на границе страницы. Иначе она получает первый доступный адрес до или после addr (с помощью вызова функции get_unmapped_area, которая начинается в строке ) и использует его.
Создает область VMA и начинает ее заполнять.
Если на обработку функции mmap поступает файл, предназначенный для чтения, область памяти будет отмечена как предназначенная для чтения, записи и выполнения. (Функция do_mmap может вскоре отозвать разрешение на запись — это сделано только для упрощения.) К тому же, если функция получает запрос сделать область памяти разделяемой, она это делает.
Если файл не предназначен для записи, область памяти также не должна быть предназначена для записи.
В этом случае нет файла, с режимами открытия и разрешениями которого должна быть совместима функция do_mmap, то есть ей разрешено действовать по своему усмотрению. Поэтому она отмечает область памяти как предназначенную для чтения, записи и выполнения.
Очистка всех старых отображений памяти в устанавливаемом диапазоне адресов с использованием do_munmap (вскоре она будет рассмотрена). Поскольку новая область VMA еще не была вставлена в список процесса (о ней сейчас знает только функция do_mmap), на новую область VMA этот вызов не распространяется.
Больше ничего плохого не может случиться. Функция do_mmap вставляет область VMA в список областей VMA процесса (и, возможно, в его дерево AVL), сливает все сегменты, ставшие теперь смежными (функция merge_segments рассматривается ниже), обновляет некоторую статистическую информацию и возвращает адрес нового отображения.
Do_munmap
Очевидно, что функция do_munmap противоположна do_mmap; она удаляет отображения виртуальной памяти из пространства памяти процесса.
Если адрес, который должен быть изъят из отображения с помощью функции do_munmap, не выровнен по границе страницы или соответствующая ему область памяти лежит вне пространства памяти процесса, ясно, что он недействителен, поэтому такая попытка будет здесь отвергнута.
Если не была освобождена, по крайней мере, одна страница, попытка отвергается.
Поиск области VMA, которая включает указанный адрес. Любопытно, что функция do_munmap возвращает 0 — признак отсутствия ошибки — если адрес не находился ни в одной области VMA. В определенном смысле, это правильно; функция do_rnunmap получила запрос проверить то, что процесс больше не имеет отображения для данной области памяти и это легко сделать, если такого отображения не было с самого начала. Но это все равно вызывает удивление; может оказаться, что со стороны вызывающей функции допущена ошибка и что функция do_munmap должна поэтому как-то об этом сообщить. Однако некоторые вызывающие функции основаны на том, что так и должно быть на самом деле, например, см. строку .
Если указанный диапазон памяти лежит полностью внутри отдельной области VMA, но не соприкасается ни с одним концом содержащей его области VMA, то удаление этого участка привело бы к возникновению отверстия во включающей его области VMA. Ядро не может допустить возникновения отверстия, поскольку области VMA по определению представляют собой непрерывные области памяти. Поэтому в таком случае функция do_munmap должна создать другие области VMA, по одной с каждой стороны отверстия. Однако, если ядро уже создало такое количество областей VMA, какое разрешено для данного процесса, оно не может это выполнить, поэтому функция do_munmap не в состоянии удовлетворить запрос.
Поиск всех областей VMA, перекрывающих или лежащих внутри участка, предназначенного для освобождения, и размещение каждой из этих областей в локальном стеке областей VMA, предназначенных для освобождения. В этом процессе функция do_munmap удаляет области VMA из содержащего их дерева AVL, если оно имеется.
Функция do_munmap построила стек областей VMA, предназначенных для освобождения; теперь она может их освободить.
Вычисление точного размера диапазона адресов, предназначенного для освобождения, с учетом того, что он может не охватывать всю эту область VMA. Предусмотрев подходящие определения для min и max, эти три строки можно записать следующим образом:
st = max(mpnt->vm_start, addr); end = min(mpnt->vm_end, addr + len);
Поэтому st — это начало области, с которого функция do_munmap фактически начнет освобождение, а end — конец этой области.
Если эта область VMA составляла часть разделяемого отображения, функция do_munmap удаляет mpnt из списка разделяемых областей VMA с помощью вызова функции remove_shared_vm_struct (строка ).
Обновляет структуры данных MMU, соответствующие текущей подобласти, которая была освобождена внутри данной области VMA.
Исправляет отображение с помощью вызова функции unmap_fixup, которая будет рассмотрена ниже.
Функция do_munmap освободила все отображения, представленные областями VMA в этом диапазоне; последний важный шаг состоит в освобождении таблиц страниц одного и того же диапазона, что было выполнено с помощью вызова функции free_pgtables (строка ).
Do_page_fault
do_page_fault — это функция ядра, вызываемая при возникновении ситуаций отсутствия страницы (это установлено в строке ). Когда возникает ситуация отсутствия страницы, процессор настраивает регистры процесса так, чтобы после разрешения этой ситуации процесс продолжил сою работу с команды, которая активизировала эту ситуацию. Таким образом, попытка доступа к памяти, вызвавшая нарушение, автоматически повторяется после того, как ядро обеспечивает возможность ее выполнения. Иначе, если этот отказ действительно вызван ошибкой и не может быть устранен, ядро сообщает об этом процессу-нарушителю. Если ситуация отсутствия страницы возникла в самом ядре, то применяется аналогичная, но не идентичная стратегия, как будет показано ниже.
Регистр управления 2 (CR2) — это регистр процессора Intel, содержащий линейный адрес, который вызвал ситуацию отсутствия страницы. Этот адрес считывается непосредственно из указанного регистра в локальную адресную переменную.
Функция find_vma (строка ) возвращает первую область VMA, диапазон адресов которой заканчивается после этого адреса. Как известно, одно это не гарантирует наличия данного адреса в области VMA: мы знаем, что адрес расположен перед концом области VMA, но он может также находиться перед началом VMA. Поэтому выполняется и эта проверка. Если адрес успешно проходит проверку, то есть находится в пределах VMA, управление передается вперед на метку good_area (строка ); вскоре будет дано ее описание.
Если значение, возвращенное из функции find_vma, представляет собой NULL, то адрес находится после всех областей VMA данного процесса, другими словами, за пределами всей памяти, относящейся к данному процессу.
И начало, и конец VMA расположены строго после адреса; следовательно, адрес находится перед этой областью VMA. Но еще не все потеряно. Если область VMA входит в число объектов такого типа, которые возрастают в сторону младших адресов, другими словами, если она является стеком, этот стек может просто вырасти в сторону младших адресов, чтобы захватить и этот адрес.
Выполняется проверка бита 2 кода ошибки error_code, полученного от процессора. Этот бит устанавливается, если ситуация отсутствия страницы возникает в режиме пользователя, а не в режиме супервизора (ядра). В режиме пользователя функция do_page_fault проверяет, не находится ли данный адрес в пределах области стека, отведенной для процесса, в соответствии с установкой регистра ESP. (Это может произойти, если, например, код выходит за пределы массива, размещенного в стеке.) В режиме супервизора (ядра) последняя проверка не выполняется и просто предполагается, что ядро действует правильно.
Выполняется расширение области VMA для включения нового адреса с использованием функции expand_stack (строка ), если это возможно. В случае успеха член vm_start объекта VMA будет скорректирован для включения адреса.
Достижение метки good_area означает, что область VMA включает данный адрес, поскольку он либо уже находился в ней, либо для его включения был расширен стек.
Так или иначе, теперь можно проверить два самых младших бита кода ошибки error_code, которые включают дополнительную информацию о том, почему возникла ситуация отсутствия страницы. Бит 0 — это бит присутствия/защиты: если он равен 0, то страница просто не находилась в памяти; если он равен 1, то страница присутствовала в памяти, но попытка доступа противоречила установкам битов защиты уровня страницы. Бит 1 — это бит чтения/записи: 0 обозначает чтение, 1 — запись.
Этот переключатель методически прорабатывает четыре возможности, представленные этими двумя битами:
Случай 2 или 3. Проверяет, разрешена ли запись в области VMA, включающей данный адрес. Если да, то это была запись на странице с копированием при записи; значение переменной write увеличено (путем установки ее в 1) так, что последующий вызов функции handle_mm_fault приведет к попытке выполнить копирование при записи.
Случай 1. Это значит, что ситуация отсутствия страницы возникла при попытке чтения со страницы, которая присутствовала в памяти, но не была доступна для чтения; попытка была отвергнута.
Случай 0. Он означает, что ситуация отсутствия страницы возникла при попытке чтения со страницы, которая не присутствовала в памяти. Если признаки защиты области VMA, включающей этот адрес, говорят о том, что эта область не подлежит ни чтению, ни выполнению, то попытка чтения с этой страницу была бы только потерей времени: если бы эта попытка была повторена, возникла бы еще одна ситуация отсутствия страницы и функция do_page_fault закончила бы свою работу в соответствии со случаем 1, поэтому такая попытка отвергается. Иначе, функция do_page_fault продолжает свою работу и пытается считать эту страницу с диска.
Выполняется запрос к функции handle_mm_fault (которая описана ниже), чтобы она выполнила попытку сделать эту страницу присутствующей в памяти. Если эта попытка терпит неудачу, выдается ошибка SIGBUS.
Код очистки для большинства функций ядра не заслуживает особого внимания. Функция do_page_fault составляет исключение; мы рассмотрим ее код очистки более подробно. Эта метка, bad_area, достигается в любом из следующих обстоятельств:
Вызываемый адрес находится после всей памяти, распределенной (или зарезервированной) для процесса.
Вызываемый адрес лежит за пределами всех областей VMA, а стек не может быть расширен для его включения, возможно, потому, что область VMA, перед которой находится этот адрес, не является стеком.
Страница не предназначалась для режима копирования при записи.
Если код пользователя допустил любую из перечисленных выше ошибок, в него отправляется ужасающее сообщение SIGSEGV — нарушение сегментации. (Обратите внимание, что здесь термин «сегментация» применяется по традиции, а не по смыслу: когда речь идет о процессоре, технически — это нарушение страничного обмена, а не обязательно нарушение сегментации.) Этот сигнал обычно приводит к уничтожению процесса, как описано в .
В процессоре Pentium компании Intel (и в некоторых из его разновидностей) есть так называемая ошибка f00f, которая позволяет любому процессу остановить работу процессора, выполнив неверную команду 0xf00fc7c8. Здесь реализован обходной маневр, предложенный компанией Intel.
Часть таблицы дескрипторов прерываний IDT (interrupt descriptor table) (см. ) была заранее отмечена как предназначенная только для чтения, поскольку это заставляет процессор активизировать ситуацию отсутствия страницы вместо останова процессора в случае выполнения недопустимой команды. Здесь do_page_fault проверяет, не находился ли адрес, который привел к возникновению ситуации отсутствия страницы, в том месте IDT, которое связано с выполнением этой недопустимой команды. Если это так и есть, процессор пытается обслуживать прерывание «Invalid Opcode» — ошибка в процессоре не позволяет выполнить это действие правильно, но данный код исправляет ситуацию, непосредственно вызывая функцию do_invalid_op. В ином случае, процессор никогда бы не пытался писать в IDT (то есть писать в ней, если она предназначена только для чтения), поэтому при неудачном завершении проверки в строке недопустимая команда так и не будет выполнена.
Метка no_context будет достигнута в одном из следующих случаев:
В режиме ядра (а не пользователя) была достигнута метка bad_area и процессор не выполнил недопустимую команду, которая вызывает ошибку f00f.
Ситуация отсутствия страницы возникла во время прерывания или при отсутствии контекста пользователя (когда задача пользователя не выполнялась).
Выполнение функции handle_mm_fault окончилось неудачей и система находилась в режиме ядра (автор с таким случаем еще не сталкивался).
Любая из этих ситуаций — это проблема ядра (часто вызываемая драйвером), а не ситуация отсутствия страницы, активизированная каким-то кодом пользователя. Если ядро (или драйвер) подготовлено к этой возможности путем предварительной настройки кода обработки ошибок, этот код будет найден и будет выполнен переход к нему с помощью некоторых уловок, которые не входят в тематику данной книги.
Иначе, ядро пыталось обратиться к недопустимой странице и функция do_page_fault не знала, что с этим делать. Эта попытка все еще могла быть преднамеренной. Код запуска ядра проверяет, правильно ли работает защита записи MMU; ошибка, возникающая при такой проверке, не является настоящей ошибкой, и функция do_page_fault может просто вернуть управление.
Ядро обратилось к недопустимой странице и функция do_page_fault не смогла устранить проблему. Функция do_page_fault выводит некоторую информацию с описанием проблемы и в строке прекращает работу самого ядра. Это приводит к останову всей системы, поэтому, естественно, к такому действию нельзя относиться легкомысленно. Однако, если дело дошло до этой точки, ядру уже ничем не поможешь.
Последняя рассматриваемая метка — do_sigbus, которая достигается, только если функция handle_mm_fault не смогла обработать ситуацию. Этот случай относительно прост; в основном он сводится к отправке ошибки SIGBUS задаче-нарушителю и обратному переходу к метке no_context, если это произошло в режиме ядра.
Do_wp_page
Как было упомянуто ранее, копирование при записи фактически реализовано здесь, поэтому рассмотрим эту функцию хотя бы вкратце. В функции tsk была предпринята попытка выполнить запись по адресу, который находился в пределах указанной области vma и контролировался переданным параметром page_table.
Происходит вызов функции __get_free_page (строка , которая просто возвращается назад и вызывает функцию __get_free_pages в строке ) для предоставления процессу новой страницы — это должна быть новая копия страницы, защищенной от записи. Обратите внимание, что это позволяет обеспечить переключение заданий. Любопытно отметить, что в этом коде не предусмотрена проверка того, смогла ли функция __get_free_page успешно распределить новую страницу: для него фактически может не потребоваться новая страница, как мы вскоре увидим, поэтому проверка откладывается до того момента, когда в этом появится смысл.
Наращивается число «малых» ситуаций отсутствия страницы: ситуаций отсутствия страницы, которые были разрешены без обращения к диску.
Существуют только два пользователя данной страницы, и одним из них является кэш свопинга — временный пул страниц, выведенных на диск, но еще не возвращенных в память. Страница просто удалена из кэша свопинга (с использованием функции delete_from_swap_cache, строка ) и теперь она имеет только одного пользователя.
Либо эта страница была только что возвращена из кэша свопинга, либо она имела для начала только одного пользователя. Страница отмечается как предназначенная для записи и грязная (поскольку на ней была выполнена запись).
Если новая страница была распределена ранее, она не понадобится: копия не нужна, поскольку страница имеет только одного пользователя. Функция do_wp_page освобождает новую страницу, а затем возвращает ненулевое значение в качестве свидетельства успеха.
: Страница имеет более одного пользователя и не могла быть просто возвращена в память из кэша свопинга. Поэтому в функции do_wp_page возникает потребность в получении новой страницы для копии. Если оказалось, что предыдущая попытка распределения страницы окончилась неудачей, теперь эта информация становится важной; функция do_wp_page должна возвратить отказ.
Получение копии содержимого страницы с использованием функции copy_cow_page (строка ). Это обычно лишь вызов макрокоманды copy_page (строка ), которая представляет собой просто команду memcpy.
Выполняется синхронизация содержимого старой и новой копии страницы с оперативной памятью с использованием функции flush_page_to_ram (строка ). Как и функция update_mmu_cache, эта функция в архитектуре х86 является пустой операцией.
Как и прежде, обозначает страницу как предназначенную для записи и грязную, но оставляет нетронутыми все другие признаки защиты страницы (например, обозначение выполняемого кода) из содержащей ее области VMA.
Этот вызов функции free_page (строка , где просто происходит вызов функции free_pages, строка ) фактически не освобождает старую страницу, поскольку она имеет несколько пользователей — она только уменьшает на единицу число ссылок на старую страницу. Поскольку запрос вызвавшей программы был удовлетворен, функция do_wp_page может вернуть ненулевое значение в качестве свидетельства успеха.
Elf_core_dump
Функция elf_core_dump начинает свою работу здесь. Поскольку дамп памяти процесса является результатом получения сигнала (который он мог послать сам себе, например, путем вызова функции abort), номер сигнала представлен параметром signr. Значение signr не влияет на то, как будет выполнен дамп памяти процесса и будет ли он выполнен вообще, но пользователь, рассматривая файл дампа в отладчике, сможет узнать, какой сигнал вызвал дамп памяти, и получить подсказку о том, что пошло не так, как надо. Параметр regs указывает на объект struct pt_regs (см. строку ), который содержит описание регистров процессора. Кроме других причин, параметр regs важен, поскольку он включает содержимое регистра EIP — указателя команды, который определяет, какая команда выполнялась при получении сигнала.
Немедленно возвращает управление, если процесс не смог пройти некоторые основные проверки допустимости, первой из которых является проверка наличия установленного флажка dumpable. Обычно флажок dumpable процесса (строка ) установлен; он, как правило, очищается при смене идентификаторов пользователя или группы процесса. Это, по-видимому, является мерой защиты. Вряд ли можно допустить создание доступного для чтения файла дампа недоступного для чтения выполняемого модуля, для которого, например, была выполнена команда setuid root, поскольку это противоречит цели применения недоступного для чтения выполняемого модуля (защита).
Функция elf_core_dump также немедленно возвращает управление, если предел размера файла дампа не позволяет вывести в дамп ни одной страницы или если другие потоки ссылаются на память, которую она должна выгрузить. Выполнение дампа памяти связано с выходом из процесса, а с точки зрения пользователя, процесс еще существует, если продолжает существовать какой-либо из его потоков.
Если процесс прошел эти проверки, функция elf_core_dump продолжает действовать и очищает бит dumpable с тем, чтобы ей не пришлось предпринять попытку снова выполнить дамп памяти процесса. (Однако ничто не говорит о том, что это может случиться; по мнению автора, это просто ненужная мера предосторожности.)
Входит в цикл для подсчета числа областей VMA, для которых может быть выполнен дамп без превышения размера файла дампа. Хотя функция elf_core_dump хранит счетчик в переменной под названием segs, она подсчитывает не «сегменты памяти» в той трактовке, которую мы используем в этой главе. Не следует думать, что в имени этой переменной есть какой-то особый смысл. Поскольку функция elf_core_dump записывает некоторую информацию заголовка в файл дампа перед дампом областей VMA и поскольку размер этих заголовков не учитывается в расчетах, вывод может немного превышать предел размера файла дампа. Это можно было бы легко исправить: простой метод состоял бы в уменьшении предела по мере записи заголовков и переноса цикла за пределы кода, в котором выполняется запись заголовков. Более полное решение было бы немного сложнее.
Формат файла дампа ELF определен в соответствии с официальным стандартом; его первым компонентом является заголовок с описанием файла. Формат заголовка определен в соответствии с типом struct elfhdr (см. строки и ) и функция elf_core_dump заполняет локальную переменную elf этого типа.
Устанавливает имя файла, в который должен быть выполнен дамп, и пытается открыть этот файл. Изменив значение #if 0 в строке на #if 1, мы могли бы предусмотреть включение в имена файлов дампа имен выполняемых модулей, которые привели к их созданию (или, по крайней мере, первых 16 символов этих имен — см. член comm объекта struct task_struct, который определен в строке ). Это средство иногда может стать чрезвычайно полезным; было бы прекрасно иметь возможность взглянуть на имя файла дампа и сразу же узнать, какое приложение явилось причиной его создания. Однако такое поведение является нестандартным и может нарушить работу существующего кода, например, работу контрольных сценариев, которые периодически проверяют наличие файла с именем «core», поэтому следует придерживаться стандартной практики и вместо этого называть эти файлы просто «core». Однако было бы неплохо, если бы этот параметр стал настраиваемым параметром ядра. Отметим, что эта версия дальнейшего развития разработок позволяет понять, почему таким внешне необычным способом в строке определена локальная переменная corefile.
Устанавливает флажок PF_DUMPCORE (строка ), сигнализирующий о том, что процесс выполняет дамп памяти. Этот флажок не используется в коде, рассматриваемом в данной книге, но просто для вашего сведения отметим, что он применяется в учете процессов. Учет процессов предусматривает слежение за использованием ресурсов процессом и сбор другой соответствующей информации, включая то, выполнял ли процесс дамп памяти после выхода; именно эта информация первоначально использовалась в вычислительных центрах, позволяя определить, какую сумму нужно предъявить к оплате каждому отделу или пользователю за потребление ресурсов. Разве не замечательно, что эти дни уже давно позади?
Выполняется запись заголовка файла дампа ELF, который был подготовлен ранее. В этом участвуют некоторые скрытые переключатели управления: макрокоманда DUMP_WRITE, чье определение начинается в строке , заставляет функцию elf_core_dump закрыть файл и вернуть управление, если запись окончилась неудачей.
За заголовком файла дампа ELF следует ряд заметок; каждая из них имеет определенное назначение и регистрирует конкретную информацию о процессе. Мы по очереди рассмотрим каждую из этих заметок. Заметка (с типом struct memelfnote, строка ) содержит указатель на дополнительные данные (ее член data) и длину данных (ее член datasz; основной объем работы по заполнению заметки фактически состоит в заполнении структуры с дополнительными данными и записи в заметке указателя на эту структуру.
Некоторая информация записывается в нескольких заметках. Причины этого повторения в коде не объясняются, хотя, по крайней мере, эти причины отчасти связаны с имитацией поведения других вариантов Unix. Поддержка форматов файлов, совместимых с другими платформами, помогает переносить в Linux такие программы, как gdb; лучше немного потратить места на повторную запись данных, чем отложить перенос программ и усложнить сопровождение столь важных инструментальных средств.
В заметке 0 регистрируется наследие процесса, сигналы и загрузка процессора, во вспомогательной структуре данных prstatus (типа struct elf_prstatus; см. строку ). Заметим, в частности, что функция elf_core_dump хранит номер сигнала, который заставил процесс выполнить дамп ядра, в строке . Поэтому если вы (или, скорее, не столь талантливый программист из соседнего отдела) выполните gdb на файле дампа и получите сообщение «Program terminated with signal 11, Segmentation fault», вы будете знать, откуда исходила эта информация.
В заметке 1 регистрируется общая информация процесса — его владелец, состояние, приоритет и так далее — во вспомогательной структуре данных psinfo (типа struct elf_prpsinfo; см. строку ). Строка содержит в высшей степени непригодный, хотя и правильный, индекс массива в строке с литеральной константой; выбранный символ представляет собой мнемоническое обозначение состояния процесса. Это те же буквенные обозначения состояния, о которых сообщает поле STAT программы ps (безусловно, за исключением тех случаев, когда индекс находится за пределами диапазона). Более интересной является строка , в которой выполняется копирование имени выполняемого модуля (вплоть до 16 символов, как было описано ранее) в эту заметку. И программа gdb, и «файл» программы используют это поле для сообщения о том, какая программа породила дамп памяти.
В заметке 2 регистрируется объект struct task_struct вызвавшего дамп процесса, который четко представляет большой объем важной информации о процессе. Поскольку часть информации в объекте struct task_struct состоит из указателей, которые больше не на что не указывают при просмотре этого кода в отладчике, функция elf_core_dump затем выводит отдельно часть информации, соответствующую этим указателям и, что важнее всего, пространство памяти процесса.
Если в системе имеется FPU (floating-point unit или математический сопроцессор), записывается заметка с его состоянием. Иначе, в строке уменьшается число заметок, которые должны быть записаны в файл.
Для каждой созданной заметки записывается заголовок с описанием заметки; сама заметка появится позже. Заголовок относится к типу struct elf_phdr; его определение см. в строках и .
Это первый проход функции записи пространства памяти процесса. В этом проходе функция записывает информацию заголовка (тоже типа phdr) с описанием всех областей VMA, которые были обработаны для записи.
И наконец, функция elf_core_dump действительно записывает заметки, которые она так трудолюбиво подготовила ранее.
Переход вперед в файле к следующей границе в 4 Кб, где должны начаться фактические данные файла дампа. Макрокоманда DUMP_SEEK, используемая для этой цели, определена в строке , и подобно DUMP_WRITE, она заставляет функцию elf_core_dump вернуть управление, если поиск оканчивается неудачей.
После этой настройки все остальное кажется неинтересным. Но это главная часть дампа памяти: запись каждой области VMA процесса, вплоть до предела, рассчитанного ранее и записанного в переменной segs. После этого — небольшая очистка, и функция elf_core_dump заканчивает свою работу.
Find_vma
В общих чертах назначение функции find_vma состоит в поиске первой области VMA, содержащей заданный адрес. Вернее, ее назначение состоит в поиске первой области VMA, в которой значение vm_end превышает заданный адрес, но этот адрес все еще может находиться за пределами VMA, поскольку он может быть меньше значения vm_start этой области VMA. Функция возвращает указатель на VMA или NULL, если ни одна область VMA не соответствует запросу.
Вначале проверяется та же область VMA, которая соответствовала последнему запросу к этому процессу, с использованием члена mmap_cache объекта mm, предназначенного специально для этой цели. Автор не проверял это сам, но в документации по этой функции указано, что коэффициент попадания в кэш составляет 35 процентов, а это весьма неплохой показатель, если учитывать то, что кэш состоит только из одной структуры VMA. Безусловно, этому способствует широко известное свойство, которое часто называют «локализацией ссылок»: согласно этому принципу программное обеспечение, как правило, обращается к данным (и командам), расположенным рядом с недавно использованными данными (и командами). Поскольку VMA содержит ряд смежных адресов, локализация ссылок способствует повышению вероятности того, что необходимые адреса будут находиться в той же области VMA, которая удовлетворяла предыдущему запросу.
При модификации списка VMA это значение кэша в нескольких других местах устанавливается в NULL для указания на то, что изменения в списке VMA могли сделать содержимое кэша недействительным. По крайней мере, в одном из этих случаев, в строке , очистка кэша иногда может не потребоваться; сделав этот код немного интеллектуальнее, можно существенно повысить коэффициент попадания в кэш.
Этот маленький кэш не применяется. Если дерево AVL не существует, функция find_vma просто проходит по всем структурам VMA в списке, возвращая первую из них, которая соответствует условию. Помните, что этот список структур VMA находится в отсортированном порядке, поэтому первая же область VMA, которая соответствует условию, представляет собой область VMA с наименьшим адресом, являющуюся таковой. Если функция выходит за конец списка, не найдя соответствия, переменная vma устанавливается в NULL и возвращается именно это значение.
При наличии достаточно большого количества областей VMA прохождение по дереву становится быстрее, чем перебор связанного списка; поскольку деревья AVL сбалансированы, это операция с логарифмическими, а не линейными затратами времени. Итеративное прохождение по дереву встречается не так уж редко, но эта структура обладает некоторыми особенностями, которые не сразу бросаются в глаза. Прежде всего, обратите внимание на присваивание в строке ; в ней отслеживается наилучший узел, найденный до сих пор, поэтому будет возвращен именно он, если не нашлось ничего лучшего. Проверка if в следующей строке— это оптимизация для проверки того, лежит ли addr полностью в пределах VMA (мы уже знаем, что к этому моменту addr меньше значения vm_end для данной области VMA). Поскольку области VMA никогда не перекрываются, не существует другой, более подходящей области VMA, поэтому можно сразу же прекратить обход дерева.
Если во время обхода дерева или просмотра списка была найдена область VMA, полученное значение сохраняется в кэше до следующего поиска.
В любом случае возвращается значение vma; оно может быть равным NULL или может указывать на первую область VMA, которая удовлетворяет условию поиска.
Find_vma_prev
Как было упомянуто в приведенном выше описании, эта функция (которая начинается со строки ) аналогична find_vma, но дополнительно возвращает указатель на область VMA, находящуюся перед той, где содержится искомое значение addr (если она существует). Эта функция интересует нас не сама по себе, а как источник дополнительной информации, необходимой для понимания особенностей программирования ядра в целом и программировании ядра Linux в частности.
Наиболее вероятно, что прикладной программист написал бы функцию find_vma как надстройку над более общей функцией find_vma_prev, просто отбросив указатель на предыдущую область VMA, следующим образом:
struct vm_area_struct * find_vma(struct mm_struct * mm, unsigned long addr) { struct vm_area_struct * notused; return find_vma_prev(mm, addr, ¬used); }
Прикладной программист сделал бы это потому, что быстродействие для приложений не имеет такого большого значения. В этой области программирования на передний план выходят иные соображения, которые продиктованы не стремлением к оригинальности, а неуклонным повышением быстродействия процессора: теперь можно позволить себе применять то здесь, то там вызов дополнительной функции в целях повышения удобства сопровождения.
В противоположность этому, программист ядра не может позволить себе роскошь выполнения дополнительного вызова функции; он скорее возьмет на себя ответственность за создание почти полного дубликата какой-то функции, чем потеряет несколько циклов процессора для ее вызова. Если даже исключить всё прочие соображения, именно такое отношение разработчиков ядра к своей работе является частью того, что позволяет прикладным программистам быть более расточительными.
Но есть более глубокая причина того, что в ядре Linux подобное дублирование менее важно по сравнению, скажем, с сопоставимой операционной системой с закрытым исходным кодом. Хотя ядро Linux должно ограничивать потребляемое им процессорное время, усилия разработчика ядра Linux не ограничены рабочим временем программиста, работающего по найму. Даже наиболее крупные коммерческие проекты разработки не могут сравниться по численности сотрудников с числом программистов, которые вносят свой вклад в создание Linux. (К тому же, автор не может удержаться от язвительного замечания: разработчики Linux не обязаны тратить свое время на бесконечные заседания, и они не связаны искусственными графиками.) Существование этой огромной команды, этого огромного коллективного мозга меняет правила разработки программного обеспечения.
Исходный код ядра Linux доступен каждому и сам Линус когда-то обронил знаменитую фразу: «... в мире столько внимательных глаз, что они обязательно найдут все ошибки». Если между реализациями функций find_vma и find_vma_prev возникнут какие-то важные расхождения, то разработчик ядра Linux, о существовании которого вы даже и не догадываетесь, найдет их и устранит быстрее, чем можно произнести слово «перетранслировать». На практике, разработка ядра системы Linux идет быстрее по сравнению с ее коммерческими аналогами, и результирующий код выполняется быстрее и содержит меньше ошибок, несмотря на наличие конструкций, которые при любых других обстоятельствах можно было бы считать нарушением принципов сопровождения кода.
Безусловно, автор может оказаться не прав, если просто никто не заметил, что можно объединить эти функции, и в следующем выпуске ядра одна из них исчезнет. Но это маловероятно, и даже если он окажется не прав в данном конкретном случае, автор настаивает, что в целом эта мысль справедлива. В этой операционной системе применяются несколько иные принципы, и именно благодаря таким отличиям Linux является столь оригинальной операционной системой.
__Flush_tlb
CR3 (Control Register 3 — регистр управления 3) — регистр процессора х86, который содержит базовый адрес каталога страниц. Загрузка значения в этот регистр заставляет процессор считать, что буфера TLB потеряли актуальность, даже если произошла загрузка того же значения, которое уже находилось в CR3. Следовательно, функция __flush_tlb состоит просто из двух команд ассемблера: она сохраняет значение CR3 во временной переменной tmpreg, а затем копирует tmpreg обратно в CR3. Вот и все!
Обратите внимание, что процессор х86 позволяет также сделать недействительным только один вход TLB, а не весь буфер. В этом методе используется команда invlpg — см. строку для ознакомления с ее использованием.
Ядро Linux в комментариях
Функция get_swap_page получает страницу на доступном незаполненном устройстве свопинга с наивысшим приоритетом; она возвращает ненулевой код с описанием входа, если таковой найден, или 0, если в системе пространство свопинга заполнено.
Позволяет продолжить итерацию с того места, где она закончилась в последний раз. Если список пуст или не осталось больше места для свопинга, функция здесь выполняет возврат.
Иначе, есть основания надеяться, что где-то еще есть пространство для свопинга и функции get_swap_page остается только его найти. Прохождение по этому циклу повторяется до тех пор, пока функция не найдет свободный вход (что более вероятно) или не просмотрит каждое устройство свопинга и придет к заключению, что ни на одном из них не осталось свободного места (что менее вероятно).
Просмотр массива swap_map текущего устройства свопинга в поисках свободного элемента с использованием функции scan_swap_map (строка ), которая также обновит члены lowest_bit и highest_bit, если такой вход будет найден. Параметр offset будет содержать либо 0, либо возвращаемый вход.
Текущее устройство свопинга смогло распределить страницу. Теперь функция get_swap_page наращивает итеративный курсор члена swap_list, чтобы запросы правильно распределялись между устройствами свопинга. Если достигнут конец списка данного устройства свопинга или следующее устройство свопинга имеет более низкий приоритет по сравнению с текущим, итерация возобновляется с начала списка. Это влечет за собой два важных последствия:
Если станет доступным место для свопинга на устройстве с более высоким приоритетом, функция get_swap_page в следующей итерации начнет распределять страницы свопинга на этом устройстве. Рассматривая этот код в отрыве от остального, можно подумать, что эта функция может, в принципе, распределить несколько страниц на устройствах с более низким приоритетом, даже если доступно устройство с высоким приоритетом. Но это не так, что станет очевидным после знакомства с тем, как происходит освобождение страниц свопинга.
Если на устройстве с более высоким приоритетом больше нет места для свопинга, то в следующий раз, когда ядро станет распределять вход свопинга, функция get_swap_page будет выполнять итерацию по списку, пока не найдет первое устройство с текущим приоритетом, и попытается получить место для свопинга на этом устройстве. Таким образом, ядро продолжает просматривать все устройства с высокими приоритетами, пока на них совсем не останется места и только после этого перейдет к устройствам с более низкими приоритетами. Именно так реализована ротация, о которой было сказано выше.
На текущем устройстве не было места для свопинга или текущее устройство не было доступно для записи (что в данном контексте означает одно и то же). Поэтому ядро переходит к следующему устройству и возвращается в начало списка, если достигнут его конец и возврат в начало еще не произошел.
Если функция get_swap_page достигла конца списка и уже один раз возвращалась в его начало, это значит, что она просмотрела все устройства свопинга и не нашла ни на одном из них свободного места. Поэтому она должна сделать вывод, что больше нет места для свопинга и возвратить 0.
Ядро Linux в комментариях
Функция get_vm_area пытается возвратить свободный участок в диапазоне от VMALLOC_START до VMALLOC_END. Обычно она выполняет это от имени vmalloc; эта функция используется также в нескольких других случаях, которые здесь не рассматриваются. Вызывающая функция отвечает за обеспечение того, что параметр size является ненулевым кратным размера страницы. Функция vmalloc работает по так называемому алгоритму «первого подходящего», поскольку она возвращает указатель на первый же найденный блок, который удовлетворяет запросу. Существуют также алгоритмы «наиболее подходящего», которые распределяют память из наименьшей доступной свободной области, которая достаточно велика для выполнения запроса, и алгоритмы «наихудшего подходящего», которые всегда распределяют память из наибольшей доступной свободной области. Распределитель памяти каждого типа имеет свои преимущества и недостатки, но реализованный здесь алгоритм «первого подходящего» является простым и быстрым и вполне соответствует своему назначению.
Распределение объекта struct vm_struct для представления новой области. Распределяемые области отслеживаются с помощью отсортированного связанного списка vmlist (строка ) объектов struct vm_struct. Файл заголовка, к которому принадлежит struct vm_struct, был опущен в целях экономии места, но определение этого объекта является весьма простым:
struct vm_struct { unsigned long flags; void * addr; unsigned long size; struct vm_struct * next; };
Каждый элемент списка связан с одним распределенным блоком памяти, как показано на рис.8.6. Можно видеть, что задача функции get_vm_area состоит в поиске достаточно широкого промежутка между распределенными областями.

Рис. 8.6. Список vmlist
Начинается циклический просмотр списка. Цикл должен либо найти достаточно большую свободную область, либо показать, что такой области не существует. В нем вначале проверяется VMALLOC_START, а затем адрес, непосредственно следующий за каждой распределенной областью.
Список был пуст или в цикле была обнаружена достаточно большая область для нового блока; так или иначе, addr теперь представляет собой наименьший доступный адрес. Заполняется новый объект struct vm_struct, который и будет возвращен.
Добавление страницы (размером 4 Кб в архитектуре х86) к размеру зарезервированного блока для перехвата выхода за пределы ядра в направлении старших адресов памяти и, возможно, выхода в направлении младших адресов памяти из следующего по порядку блока. Поскольку это дополнительное пространство не учтено при определении того, было ли достаточно велико текущее отверстие (строка ), область, зарезервированная этим входом, может перекрывать следующую, и выход за пределы памяти ядра в эту «лишнюю» область в направлении старших адресов может в действительности перезаписать распределенную память. Правильно? Неправильно. Легко доказать, что значение addr всегда выровнено по странице, и мы уже знаем, что параметр size всегда кратен размеру страницы. Поэтому, если величина size + addr меньше начального адреса следующей области, она должна быть меньше, по крайней мере, на целую страницу. Безусловно, выход за пределы памяти более чем на одну страницу может затронуть следующую область, но выход за пределы памяти менее чем на одну страницу — нет. Поскольку ядро не устанавливает отображение страницы для этой дополнительной памяти, ошибочная попытка обратиться к ней вызовет неразрешимую ситуацию отсутствия страницы (что является почти неслыханным в современных версиях Linux!). В результате ядро перейдет в состояние жесткого останова, но это лучше, чем позволить ядру молча крушить его собственные структуры данных. По крайней мере, вы сразу же узнаете о тяжелом останове, что позволит вам диагностировать проблему; последний же сценарий не станет очевидным до тех пор, пока ядро не разгромит все внешние устройства.
Память
Память — один из наиболее важных ресурсов, которым управляет ядро. Процессы отличаются друг от друга, в частности, тем, что функционируют в логически раздельных пространствах памяти (с другой стороны, потоки совместно используют основную часть своей памяти). Даже если оба процесса являются экземплярами одной и той же программы, как в случае применения двух программ xterm или двух редакторов Emacs, ядро принимает меры, чтобы каждый процесс видел память так, как если бы он был единственным процессом в системе. Безопасность и стабильность системы повышаются, если один процесс не может случайно или преднамеренно записать свои данные в чужую рабочую область.
Ядро также существует в своем собственном пространстве памяти; оно известно как пространство ядра, в противоположность пространству пользователя, которое служит общим обозначением для пространства памяти любой задачи, отличной от задачи ядра.
Handle_mm_fault
Вызывающая программа обнаружила необходимость обеспечить доступ к странице. Это— та страница, которая содержит адрес, и этот адрес принадлежит к VMA. Сама функция handle_mm_fault довольно проста, но лишь потому, что она построена на других макрокомандах и функциях, которые выполняют всю черную работу. Мы последовательно рассмотрим эти функции низкого уровня после описания данной функции.
Выполняет поиск соответствующих входов каталога страниц и промежуточного каталога страниц (это платформа х86, поэтому, как описано выше, эти два каталога фактически совпадают).
Получает или распределяет (если это возможно) таблицу страниц для данного входа промежуточного каталога страниц.
Вызывает функцию handle_pte_fault для считывания страницы во вход таблицы страниц; если это выполняется успешно, вызывается также функция update_mmu_cache для обновления кэша MMU. Если управление достигает этой точки, это значит, что все прошло хорошо, и функция handle_mm_fault может вернуть ненулевое значение (чаще всего 1) в качестве подтверждения успеха. Если любой этап на этом пути оканчивается неудачей, управление переходит на строку и функция возвращает 0 в качестве обозначения неудачи.
Handle_pte_fault
Функция handle_pte_fault пытается выбрать или создать отсутствующую таблицу РТЕ.
Данный вход не был связан ни с одной страницей в физической памяти (строка ) и в действительности даже не был установлен (строка ). Поэтому вызывается функция do_no_page (строка ) для создания нового отображения страницы.
Страница не присутствовала в памяти, но имела отображение, поэтому она должна находиться в пространстве свопинга. Для ее чтения обратно в память вызывается функция do_swap_page (строка ).
Страница присутствовала в памяти, поэтому проблема, вероятно, была связана с тем, что ядро обработало ситуацию нарушения защиты страницы. Вначале функция handle_pte_fault отмечает, что к странице было выполнено обращение, с помощью pte_mkyoung (строка ).
Если это был доступ для записи, а запись на странице не разрешена, функция handle_pte_fault вызывает функцию do_wp_page (строка ). Это именно та функция, которая выполняет копирование при записи, поэтому далее мы ее рассмотрим вкратце.
Это был доступ для записи к странице, предназначенной для записи. Функция handle_pte_fault устанавливает бит страницы «dirty» (грязная), указывая, что она должна быть снова скопирована в пространство свопинга перед ее уничтожением.
Затребованная страница теперь доступна вызвавшей программе для использования, поэтому функция handle_pte_fault возвращает ненулевое значение (а именно 1) для обозначения успешного выполнения.
Каталоги страниц и таблицы страниц
В архитектуре х86 преобразование линейного адреса (или логического адреса — в Linux они совпадают) в физический адрес представляет собой двухэтапный процесс, который схематически показан на рис. 8.2. Линейный адрес, предоставляемый процессом, делится на три части: индекс каталога страниц, индекс таблицы страниц и смещение. Каталог страниц — это массив указателей на таблицы страниц, а таблица страниц — это массив указателей на страницы, поэтому преобразование адреса предусматривает прохождение по цепочке указателей. Каталог страниц позволяет найти таблицу страниц, которая указывает на конкретную страницу, а смещение позволяет перейти к адресу на странице.

Рис. 8.2. Страничный обмен в x86
Опишем этот процесс более подробно и точно: вход каталога страницы в данном индексе каталога страниц содержит адрес таблицы страниц, которая хранится в физической памяти; вход таблицы страниц в данном индексе таблицы страниц содержит базовый адрес в физической памяти соответствующей физической страницы, и с этим физическим адресом складывается смещение линейного адреса для вычисления окончательного искомого адреса на физической странице.
В других процессорах предусмотрен трехуровневый подход, как показано на рис. 8.3. Это особенно удобно в 64-разрядных архитектурах типа Alpha, где более обширное 64-разрядное адресное пространство при использовании преобразования адресов по принципу х86 потребовало бы применения огромных каталогов страниц, таблиц страниц или смещений, или всех трех одновременно. В связи с этим разработчики Alpha ввели еще один уровень в схему линейных адресов, который в системе Linux называется «промежуточным каталогом страниц»; он находится между каталогом страниц и таблицей страниц.

Рис. 8.3. Представление ядра о страничном обмене
Итак, в действительности страничная адресация — это метод, аналогичный описанному выше, но еще с одним уровнем. В трехуровневом подходе снова применяется каталог страниц, каждый из входов которого содержит адрес промежуточного каталога страниц, каждый из входов которого содержит адрес таблицы страниц, каждый из входов которой, как и прежде, содержит адрес страницы в физической памяти, с которым нужно сложить смещение для получения окончательного адреса.
Только для того, чтобы запутать вопрос еще больше, заметим, что схема трехсоставного адреса ассоциируется с двухуровневым преобразованием адреса, а схема четырехсоставного адреса ассоциируется с трехуровневым преобразованием адреса. Это связано с тем, что «уровни», о которых мы обычно говорим, не включают первого этапа индексации, с переходом в каталог страниц (поскольку, по мнению автора, это — не преобразование).
Нет ничего неожиданного в том, что разработчики ядра решили иметь дело только с одной из этих схем. В основной части кода ядра все модули MMU рассматриваются одинаково, то есть так, как если бы в них всегда применялась трехуровневая процедура (то есть четырехсоставные адреса). В архитектуре х86 макрокоманды адресации страниц успешно заменяют трехуровневое преобразование двухуровневым, устанавливая размер промежуточного каталога страниц равным единице. За пределами действия макрокоманд промежуточный каталог страниц считается почти равнозначным каталогу страниц, поэтому в основном коде ядра остается возможность обрабатывать адреса так, как если бы они состояли из четырех частей.
В архитектуре х86 десять битов каждого 32-разрядного адреса отведено для индекса каталога страниц, еще 10 битов — для индекса таблицы страниц, а оставшиеся 12 битов отведено для смещения. Вот почему размер страницы равен 4 Кб — 12 битов соответствует 4096 смещениям.
Функции и макрокоманды для создания и управления входами на каждом уровне определены в файлах include/asm-i386/page.h (строка ) и include/asm-1386/pgtable.h (строка ). Просматривая эти функции и макрокоманды, помните, что PGD обычно означает «вход каталога страниц»(а не просто «каталог страниц»), PMD обычно означает «вход промежуточного каталога страниц» (а не просто «промежуточный каталог страниц»), а РТЕ обычно означает «вход таблицы страниц». Кроме того, как подчеркивает наречие «обычно» в предыдущей фразе, существуют исключения, например, функция pte_alloc, которая рассматривается далее в этой главе, распределяет таблицу страниц, а не вход таблицы страниц (как можно было предположить). К сожалению, обсуждение всех этих программных процедур могло бы занять в этой главе больший объем, чем для нее отведено. Однако некоторые из них далее будут рассмотрены.
Входы таблицы страниц регистрируют не только базовый адрес страницы, но и признаки ее защиты — набор флажков, обозначающих страницу как предназначенную для чтения, записи и/или выполнения (вполне очевидно, что они напоминают по смыслу биты защиты файла). Вход таблицы страниц включает еще несколько других флажков, свойственных для конкретной страницы, как будет описано ниже при более подробном рассмотрении средств защиты страниц.
Компоновка процессов памяти
Важным средством обеспечения использования процессом отведенной ему памяти являются следующие три структуры данных: struct vm_area_struct (строка ), struct vm_operations_struct (строка ) и struct mm_struct (строка ). В этом разделе последовательно рассматривается каждая из этих структур данных.
Копирование при записи
Одним из способов повышения эффективности является просто лень — стремление выполнять только минимально необходимую работу, и только тогда, когда в этом действительно возникает необходимость. Иногда в реальном мире это — плохая привычка, по крайней мере, в том случае, если она ведет к промедлению. Однако в мире компьютеров такая привычка часто становится достоинством. Копирование при записи является одним из способов повышения эффективности ядра Linux за счет избавления от лишней работы. Основная идея состоит в том, что страница обозначается как предназначенная только для чтения, но ее заключительная область VMA отмечается как предназначенная для записи. Любая запись на странице нарушает защиту уровня страницы и активизирует ситуацию отсутствия страницы. Обработчик сообщений об отсутствии страницы замечает противоречие между установками защиты страницы и области VMA, а затем создает вместо нее копию этой же страницы, предназначенную для записи.
Копирование при записи весьма полезно. Процессы часто выполняют команду fork и сразу после этого exec, поэтому копирование их страниц во время выполнения команды fork становится ненужной расточительностью — их все равно приходится отбрасывать после выполнения exec. Как будет описано ниже, такой же механизм применяется, когда процесс распределяет большие объемы памяти. Все распределенные страницы отображаются на единственную пустую страницу, которая обозначается как предназначенная для копирования при записи. Первая же запись на этой странице активизирует ситуацию отсутствия страницы и тогда создается копия пустой страницы. Таким образом, страницы распределяются только тогда, когда их распределение больше нельзя откладывать.
В следующих нескольких разделах будет показано, как копирование при записи фактически реализовано в ядре.
Merge_segments
merge_segments— это интересная функция, которая сливает смежные области VMA в одну область VMA с большим охватом. Таким образом, если одна область VMA покрывает (вполне очевидно, что вымышленный) диапазон от 0x100 до 0x200, а другая покрывает диапазон от 0x200 до 0x300 и они имеют одинаковые признаки защиты, то функция merge_segments заменяет их обе одной областью VMA, которая покрывает диапазон от 0x100 до 0x300. (Отметим, что слово «segments» в имени функции не говорит о том, что мы используем сегменты процессора — это не так.)
Параметрами функции merge_segments являются: объект struct mm_struct, содержащий интересующие нас области VMA, а также начальный и конечный адреса, в пределах которых может оказаться возможным слияние.
find_vma_prev (строка ) находит первую область VMA, для которой значение vm_end следует за предоставленным значением start_addr, поэтому это первая область VMA, которая может содержать start_addr. Напомним также, что функция find_vma_prev возвращает также указатель на предыдущую область VMA в параметре prev1 (NULL, если запросу удовлетворяет первая же область VMA).
Входит в цикл, в котором будут рассмотрены все области VMA, перекрывающие заданный диапазон. В этом цикле функция merge_segments пытается слить каждый сегмент с предшествующим, который всегда можно определить с помощью prev.
Основная часть этого условия if относительно проста, но последняя проверка, вероятно, сложнее. Она проверяет смежность prev и mpnt, т.е. отсутствие неотображенной памяти между концом prev и началом mpnt. Даже если она обнаруживает, что vm_end одной области равен vm_start другой, это пока не значит, что эти две области являются смежными — помните, что vm_end на единицу больше последнего адреса, принадлежащего VMA. Строки с до предписывают аналогичное свойство для файлов и разделяемой памяти, обработанных функцией mmap: конец одной области должен быть равен началу следующей.
Функция merge_segments нашла смежные области VMA, которые она может слить. Она удаляет mpnt из списка областей VMA (и возможно также из дерева) и вкладывает это значение в prev. Отметим, что эта функция не демонтирует дерево, даже если число областей VMA снова становится меньше значения AVL_MIN_MAP_COUNT.
Если исчезнувшая область VMA была частью файла, обработанного функцией mmap, функция merge_segments удаляет ее ссылку на этот файл.
Модуль управления памятью
Преобразование логических адресов в физические адреса и обратно находится под совместным контролем ядра и аппаратного модуля управления памятью (MMU — memory management unit). Модуль MMU встроен в современные процессоры и вместе с ними составляет часть одной и той же микросхемы, но иногда удобно считать MMU отдельным компонентом. Ядро сообщает модулю MMU, какие логические страницы должны быть отображены на конкретные физические страницы для каждого процесса, и MMU выполняет фактическое преобразование адресов, когда процесс выдает запрос к памяти.
Когда не удается выполнить преобразование адреса, например в связи с тем, что поступивший логический адрес оказался недопустим, или потому, что логическая страница больше не имеет физического аналога и должна быть загружена в память, MMU сообщает об этом ядру. Данную ситуацию называют ситуацией отсутствия страницы, и она подробно рассматривается далее в этой главе.
MMU отвечает также за обеспечение защиты памяти и сообщает операционной системе о том, что приложение пытается выполнить запись на странице в своей памяти, которая была назначена только для чтения.
Основным преимуществом MMU является быстродействие. Для получения того же результата без MMU операционной системе пришлось бы пересчитывать программным способом каждую отдельную ссылку на адрес в памяти для каждого процесса — каждую выборку и каждую запись, как для данных, так и для команд, возможно, создавая виртуальную машину для поддержки функционирования процессов. (Нечто вроде этого предусмотрено в языке Java.) В результате система работала бы невыносимо медленно. Но MMU встроен в аппаратное обеспечение компьютера, поэтому обработка допустимых адресов памяти вообще не замедляется. После подготовки MMU для использования в этом процессе ядру приходится вмешиваться в него только изредка, например, при возникновении ситуации отсутствия страницы, что происходит очень редко по сравнению с общим числом ссылок на адрес в памяти.
Кроме того, MMU может помочь защитить ядро от самого себя. Ядро смогло бы защититься от незаконного проникновения посторонних процессов в его пространство памяти или защитить процессы друг от друга и без MMU. Но как защитить ядро от нарушений со стороны собственных процессов? В процессоре 80486 и последующих процессорах компании Intel (но не в 80386) средства защиты памяти MMU применяются также и к ядру.
Операции со структурами VMA
В настоящем разделе рассматривается функция find_vma, которая будет применяться далее в этой главе, и вкратце описана тесно связанная с ней функция find_vma_prev. Это позволяет понять некоторые особенности обработки VMA и подготовиться к изучению описанного ниже кода.
Отображение памяти с помощью mmap
Функция mmap— это важный системный вызов, который позволяет зарезервировать для различных целей произвольные области памяти. Память может быть отведена для файла или какого-то специального объекта и в этом случае ядро будет поддерживать согласование между областью памяти и объектом, лежащим в ее основе, или это может быть просто старая добрая оперативная память, которая нужна для приложения. (Однако в приложениях mmap обычно не используется просто для распределения памяти, поскольку для этой цели лучше приспособлена malloc.)
Одним из наиболее распространенных способов использования mmap является выполняемое самим ядром отображение в память исполняемого файла (см. в качестве примера строку ). Именно так двоичные обработчики работают с механизмом страничного обмена для поддержки исполняемых модулей со страничным обменом по требованию, как упоминалось ранее в этой главе. Выполняемая программа отображается с помощью mmap в соответствующую область пространства памяти процесса и функция do_page_fault переносит в память остальные страницы выполняемой программы по мере необходимости.
Память, заполненная с помощью функции mmap, может быть отмечена как предназначенная для выполнения, заполнена командами, а затем в нее может быть выполнен переход; именно так работают JIT-компиляторы Java. Еще проще отобразить выполняемые файлы прямо в пространство памяти процесса, во время его выполнения; этот метод используется для реализации библиотек с динамическим связыванием.
Функцией ядра, которая реализует функциональные возможности mmap является do_mmap.
Pgd_offset
Эта макрокоманда просто делит адрес на PGDIR_SHIFT (это значение установлено директивой #define равным 22 в строке ), округляет в меньшую сторону и использует результат (верхние 10 битов перед сдвигом) в качестве индекса массива pgd, размещенного в объекте struct mm_struct. Поэтому это значение представляет собой вход каталога страниц, в котором расположен адрес соответствующей таблицы страниц.
Это эквивалентно выражению
&((mm)->pgd[(address) >> PGDIR_SHIFT]);
хотя, возможно, более эффективно.
Pmd_alloc
Поскольку промежуточные каталоги страниц на платформе х86 не предусмотрены, эта функция предельно проста: она лишь возвращает переданный ей указатель pgd, приведя его к иному типу. На других платформах она должна выполнять больше работы, по аналогии с pte_alloc.
Подробный обзор средств защиты страниц
Как упоминалось ранее, входы таблицы страниц содержат не только базовый адрес страницы, но и другие флажки, которые, кроме прочей информации, показывают, какие операции могут выполняться над этой страницей. Теперь рассмотрим эти флажки более подробно. Поскольку вход таблицы страниц содержит только базовый адрес страницы, а страница, естественно, выровнена по границе страницы, в архитектуре х86 младшие 12 битов этого адреса (содержащие смещение) должны быть всегда равны 0. Но эти биты не оставляют с нулевыми значениями, а применяют для кодирования дополнительных флажков, относящихся к странице, а при получении адреса страницы просто их маскируют. Ниже перечислены флажки, закодированные в этих 12 битах:
Бит _PAGE_PRESENT (строка ), если он установлен, обозначает, что страница физически присутствует в оперативной памяти.
Бит _PAGE_RW (строка ) бит равен 0, если страница предназначена только для чтения, или 1, если она предназначена для чтения и записи. Поэтому не существует такого понятия, как страница, предназначенная только для записи.
Бит _PAGE_USER (строка ) установлен для страниц пространства пользователя и очищен для страниц пространства ядра.
Бит _PAGE_WT (строка ) равен 1, когда нужно указать, что для этой страницы должны применяться правила кэша с немедленной записью, и равен 0, когда нужно указать, что должны применяться правила отложенной записи (значение по умолчанию). При немедленной записи все данные, записанные в кэш, немедленно копируются и в основную память, хотя и остаются в кэше для доступа по чтению. В отличие от этого, отложенная запись является более эффективной, поскольку предусматривает запись изменений в основную память только в случае удаления строки из кэша при освобождении места для чего-то иного. (Все это выполняет аппаратное обеспечение, а не Linux.) Ко времени написания данной книги этот бит в ядре нигде не использовался, но следует ожидать, что положение вскоре изменится. Кстати, в документации к процессору Intel этот бит именуется битом PWT, а не WT.
Бит _PAGE_PCD (строка ) отключает кэширование для страницы; он не используется в коде, рассматриваемом в этой книге. (Здесь «CD» обозначает «caching disabled» — кэширование отменено.) Это способствовало бы повышению эффективности, если бы мы могли заранее знать, что страница не будет использоваться достаточно часто для того, чтобы имело смысл применять кэширование. Однако создается впечатление, что этот бит был бы более полезным для устройств ввода/вывода с отображением на оперативную память, для которых необходимо гарантировать, что запись в память, представляющую устройство, не буферизирована с помощью кэша, а влечет за собой немедленное копирование данных на устройство.
Бит _PAGE_ACCESSED (строка ), если он установлен, означает, что к странице недавно выполнялся доступ. Система Linux способна устанавливать или очищать этот бит самостоятельно, но обычно эту операцию выполняет аппаратное обеспечение. Поскольку страницы, на которых этот бит очищен, не использовались в недавнем прошлом, они являются первыми кандидатами для выгрузки на диск.
Бит _PAGE_DIRTY (строка ), если он установлен, означает, что содержимое страницы изменилось с того времени, когда была выполнена очистка этого бита. Это значит, что страницу нельзя просто отбросить, не записав ее содержимое в область свопинга. Этот бит устанавливается модулем MMU или системой Linux при первой записи на страницу и считывается системой Linux при удалении страницы из памяти.
Бит _PAGE_PROTNONE (строка ), по-видимому, применяется в качестве средства использования неиспользовавшегося ранее бита во входе таблицы страниц для отслеживания присутствия страницы в памяти.
Биты _PAGE_4M и _PAGE_GLOBAL присутствуют в одном и том же блоке директив #define, но они не используются для защиты на уровне страницы, как и следующие биты, поэтому здесь они не рассматриваются.
Далее в этом файле описанные биты объединяются в макрокоманды более высокого уровня.
Pte_alloc
Функция pte_alloc получает два параметра: указатель на вход промежуточного каталога страниц, где находится желаемый адрес, и сам адрес. Извращенную логику этой функции будет проще объяснить, если мы приступим к ее описанию не сразу, поэтому пройдем по следующим номерам строк.
Преобразует адрес в смещение в PMD почти непостижимым способом.
Эта строка заслуживает подробного описания. Для начала напомним, что каждый вход в PMD представляет собой указатель, а указатели в архитектуре х86 занимают 4 байта (здесь мы находимся в части кода, зависящей от архитектуры, поэтому можем делать такие предположения). К тому же, мы знаем из определения языка С, что строка
&pmd[middle_10_bits(address)]
(здесь автор для ясности ввел фиктивный массив pmd и функцию middle_10_bits— средние десять битов) эквивалентна
pmd + middle_10_bits(address)
которая, в свою очередь, представляет тот же адрес, что и
((char *) pmd) + middle_10_bits(address) * sizeof(pte_t*)
Здесь весь фокус состоит в том, чтобы понять, что эта последняя форма или, если быть точнее, та ее часть, которая следует за знаком +, больше всего напоминает команду, которая фактически вычисляется в строке .
Чтобы убедиться в этом, вначале отметим, что
4 * (PTRS_PER_PTE - 1)
равно 4092 (величина PTRS_PER_PTE установлена директивой #define равной 1024 в строке ). В двоичном коде в числе 4092 установлены только младшие 12 битов, не считая последних двух. Это равно числу 1023, в котором установлены только 10 младших битов, сдвинутому влево на 2 бита. Затем имеется команда
(address >> (PAGE_SHIFT - 2))
которая сдвигает адрес на 10 битов вправо (величина PAGE_SHIFT установлена директивой #define равной 12 в строке ). Затем над этими двумя выражениями выполняется поразрядная операция AND. Чистый результат выглядит так:
((address >> PAGE_SHIFT) & (PTRS_PER_PTE - 1)) << 2
Хотя это выражение все еще выглядит сложным, уже многое прояснилось: в нем адрес сдвигается на 12 битов вправо (для удаления части со смещением страницы), маскируются все биты, кроме младших 10 (для удаления части с индексом каталога страниц и сохранения только индекса промежуточного каталога страниц в младших 10 битах), а затем выполняется сдвиг полученного результат на 2 бита влево (что равносильно умножению на 4 — на число байтов в указателе — sizeof(pte_t*)). Однако более простой способ был бы, вероятно, немного медленнее, а в программировании ядра мы экономим циклы процессора везде, где это возможно. (Однако простой способ внешне не выглядит как более медленный: в версии ядра выполняются два сдвига, два вычитания и поразрядная операция AND, а в методе автора выполняются два сдвига и две поразрядные операции AND. В испытаниях, проведенных автором, оба эти варианта показали почти одинаковую скорость.)
Независимо от используемого метода, после этих вычислений сложение адреса с базовым адресом его таблицы PMD в формате unsigned long (что происходит в строке и в другом месте) позволяет определить вход для этого указателя в таблице РТЕ, связанной с первоначальным значением адреса.
Если этот вход PMD не указывает ни на одну таблицу страниц, эта функция выполняет переход вперед, к метке getnew, для ее распределения.
Попытка выбрать таблицу страниц из списка pte_quicklist с помощью вызова функции get_pte_fast (строка ). Это кэш таблиц страниц — идея состоит в том, что распределение таблиц страниц (которые сами являются просто отдельными страницами) происходит медленно, но распределение памяти из списка недавно освобожденных таблиц страниц происходит немного быстрее. Поэтому в коде часто выполняется освобождение таблиц страниц с помощью функции free_pte_fast (строка ), которая переводит таблицы страниц в список pte_quicklist, a не освобождает их на самом деле.
Список pte_quicklist смог предоставить страницу для таблицы страниц. Таблица страниц введена в промежуточный каталог страниц и функция возвратила смещение этой страницы в таблице страниц.
В кэше pte_quicklist не осталось ни одной страницы, поэтому функция pte_alloc вынуждена распределить страницу медленным способом, вызвав функцию get_pte_slow (строка ). Эта функция распределяет страницу с помощью функции __get_free_page и выполняет во многом такую же обработку, как и при получении страницы из кэша.
Если вход PMD не равен 0, но является недействительным, функция pte_alloc выводит сообщение (с помощью вызова функции bad_pte, строка ) и отвергает попытку.
Обычный случай, на который мы рассчитываем: функция pte_alloc возвращает указатель на таблицу РТЕ, которая содержит адрес.
Сегменты
Не зависящая от архитектуры часть ядра Linux ничего не знает о сегментах, поскольку сегменты предусмотрены не во всех процессорах. Не менее важно то, что принципы работы с сегментами, там где они предусмотрены, в значительной степени зависят от архитектуры процессора. Поэтому мы не будем тратить слишком много времени на обсуждение этой темы, но способ использования сегментов ядром в архитектуре х86 заслуживает краткого описания.
Сегменты можно рассматривать просто как еще один механизм определения областей памяти, немного напоминающий страницы. Эти два метода могут перекрываться: адрес всегда принадлежит одной странице и может также находиться только в одном сегменте. В отличие от страниц сегменты могут иметь изменяющийся размер и даже могут увеличиваться и уменьшаться в течение срока своего существования. Как и страницы, сегменты могут быть защищены и эти средства защиты предписаны в аппаратном обеспечении; когда в архитектуре х86 возникает конфликт между защитой уровня сегмента и защитой уровня страницы для одного и того же адреса, побеждает сегмент.
Процессор Х86 следит за сегментами с помощью нескольких регистров и таблиц двух разных типов: таблицы глобальных дескрипторов (GDT) и таблиц локальных дескрипторов (LDT). Эти дескрипторы являются дескрипторами сегмента — 8-байтовыми объектами, которые хранят базовый адрес и размер сегмента, а также описывают защиту. В системе Linux существует только одна GDT, а таблицы LDT создаются для каждой задачи.
Ниже вкратце показано, как ядро использует эти таблицы для настройки сегментов. Само ядро имеет отдельные сегменты кода и данных, которые описаны во входах 2 и 3 таблицы GDT. Каждая задача также имеет отдельные сегменты кода и данных. Сегменты кода и данных текущей задачи описаны во входах 4 и 5 таблицы GDT, а также во входах 0 и 1 ее собственной таблицы LDT.
Каждая задача также использует два входа в GDT: один — для указания на ее LDT, а другой — для указания на ее TSS (сегмент состояния задания, вкратце описанный в предыдущей главе). Поскольку в процессоре х86 размер таблицы GDT ограничен 8192 входами и в Linux применяются два входа GDT для каждой задачи, ясно, что в системе нельзя иметь более 4096 задач — об этом лимите было упомянуто в . В действительности, максимальное число задач еще немного ниже, 4090, поскольку первый десяток входов GDT зарезервирован для других целей.
Опытные программисты х86 уже могли заметить, что в Linux применение механизмов сегментации х86 сведено к минимуму; основное применение сегментов состоит просто в предотвращении доступа пользовательского кода к сегменту ядра. В системе Linux предпочтение отдано механизмам страничного обмена процессора. Это в основном связано с тем, что страничный обмен в той или иной степени реализован одинаковым образом на разных процессорах, или, по крайней мере, была проделана определенная работа для того, чтобы все выглядело именно так, поэтому, чем больше сделано по обеспечению поддержки страничного обмена в ядре, тем оно более переносимо.
В заключение отметим, что для разработчиков, заинтересованных в глубоком изучении механизма поддержки сегментов процессора х86, нет лучшей возможности, кроме знакомства с документом Intel Architecture Software Developer's Manual Volume 3, который можно получить бесплатно с Web-сайта компании Intel ().
Ситуация отсутствия страницы
В этой главе уже было несколько раз упомянута возможность отсутствия страницы в оперативной памяти— и действительно, если бы все нужные страницы всегда находились в оперативной памяти, виртуальная память вряд ли бы была нужна. Но в этой главе еще не рассматривалось подробно, что происходит, когда страница не находится в оперативной памяти. Когда процесс пытается обратиться к странице, которая не находится в оперативной памяти, модуль MMU активизирует ситуацию отсутствия страницы, которую ядро пытается разрешить. Ситуации отсутствия страницы возникают также, когда процесс нарушает защиту уровня страницы, например, пытается писать в области памяти, предназначенной только для чтения.
Поскольку ситуации отсутствия страницы возникают при любом недопустимом доступе к памяти, тот же механизм применяется и для поддержки страничного обмена по требованию. Страничным обменом по требованию называют чтение страниц с диска только тогда, когда к ним обращаются, то есть по требованию — еще один пример повышения эффективности за счет лени.
В частности, страничный обмен по требованию применяется для создания исполняемых модулей, которые загружаются в память по требованию. Для этого при первой загрузке программы в физическую память считывается только небольшая часть образа исполняемого модуля, а затем для получения других страниц исполняемого модуля ядро применяет страничный обмен по требованию (например, когда процесс первый раз переходит к подпрограмме). Если не считать патологических ситуаций, это всегда быстрее считывания сразу всей программы: диск работает медленно, и вся программа может никогда не потребоваться. И действительно, обычно вся программа и не нужна, поскольку в любом отдельно взятом сеансе работы основная часть средств большой программы не используется (фактически, это также справедливо и для большинства небольших и средних программ). Этим области применения исполняемых модулей со страничным обменом по требованию не исчерпываются: если все хорошо обдумать, можно понять, что страничный обмен по требованию может также применяться и для модулей ядра, но эти компоненты слишком важны.
Страничный обмен
Общее описание страничного обмена было приведено ранее в этой главе. Теперь рассмотрим более подробно, как происходит страничный обмен в Linux.
Struct mm_struct
Все области VMA, зарезервированные процессом, находятся под управлением объекта struct mm_struct. Указателем на структуру этого типа является член mm структуры struct task_struct. Это именно тот параметр, который применялся в функции goodness (строка ) в предыдущей главе для определения того, находились ли две задачи в одной и той же группе потоков. Две задачи, которые имеют один и тот же член mm (как мы теперь знаем), управляют одними и теми же областями глобальной памяти, а это является отличительной особенностью потоков.
Член mmap объекта struct mm_struct (строка ) представляет собой связанный список структур VMA, упомянутый ранее, а его член mmap_avl, если он отличен от NULL, представляет собой дерево AVL структур VMA. Как можно убедиться, вкратце ознакомившись с его определением, объект struct mm_struct включает довольно значительное число других членов, часть которых рассматривается в этой главе.
Struct vm_area_struct
Ядро следит за областями памяти, используемыми процессом, с помощью набора из одного или нескольких объектов struct vm_area_struct, которые принято сокращенно обозначать как VMA. Каждая структура VMA представляет одну сплошную область адресного пространства процесса. Две области VMA никогда не перекрываются— в каждом конкретном процессе адрес может принадлежать не более, чем к одной области VMA; адрес, к которому процесс не обращался никоим образом, не принадлежит ни к одной области VMA.
Одну область VMA отличают от другой следующие две особенности:
Две соседние области VMA могут быть несмежными. Это значит, что конец одной области не обязан быть началом другой.
Две области VMA могут иметь разные признаки защиты. Например, в одной из них запись может быть разрешена, а в другой — запрещена. Даже если две такие области VMA являются смежными, управление ими должно осуществляться отдельно, поскольку для них могут быть предусмотрены разные признаки защиты.
Отметим следующий важный факт: адрес может быть уже охвачен областью VMA, даже несмотря на то, что ядро еще не выделило страницу для его хранения. И действительно, одно из основных назначений областей VMA состоит в поддержке принятия решения о том, как реагировать, когда возникает ситуация отсутствия страницы. Можно считать VMA абстрактным описанием областей памяти, о которых известно процессу, и способов защиты этих областей. Ядро могло бы повторно вычислять большую часть информации, содержащейся в структурах VMA, из таблиц страниц, но это происходило бы гораздо медленнее.
Структуры VMA процесса хранятся в виде отсортированного списка с двойными связями, в котором для управления списком используются указатели в самих структурах VMA. Когда процесс приобретает такое число структур VMA, которое превышает величину AVL_MIN_MAP_COUNT (установлена директивой #define равной 32 в строке ), ядро создает также для их хранения дерево AVL, опять-таки с применением указателей в самих структурах VMA для управления этим деревом. Дерево AVL — это информационная структура в виде уравновешенного двоичного дерева, поэтому такой подход обеспечивает значительное повышение эффективности поиска при увеличении числа областей VMA. Однако даже после построения дерева AVL поддерживается и линейный список, чтобы ядро могло последовательно просматривать все структуры VMA процесса легко и без рекурсии.
Двумя наиболее важными элементами объекта struct vm_area_struct являются его члены vm_start и vm_end (соответственно, строки и ), которые определяют начало и конец диапазона адресов, охваченных областью VMA: vm_start — это наименьший адрес в области VMA, a vm_end — на единицу больше наибольшего адреса. В данной главе эти члены будут упоминаться неоднократно.
Обратите внимание, что vm_start и vm_end имеют тип unsigned long, а не void *, как можно было бы ожидать. Отметим, что в ядре тип данных unsigned long применяется вместо void * во всех местах, где должны быть представлены адреса. Это отчасти предусмотрено для предотвращения появления предупреждающих сообщений компилятора при проведении некоторых вычислений, которые ядро должно выполнять над этими адресами (типа поразрядных операций), и, возможно, также отчасти для предотвращения случайной разадресации с их использованием. При обращении к адресу структуры данных, существующей в пространстве ядра, код ядра использует переменную с указателем. При манипуляции адресами в пространстве пользователя он часто использует unsigned long, и действительно, в коде, рассматриваемом в данной главе, применяется почти исключительно только этот тип данных.
Отметим, что это накладывает определенные ограничения на компилятор, который используется для компиляции ядра. Применение в качестве адресов переменных с типом данных unsigned long означает, что компилятор должен использовать для unsigned long тип данных такого же размера, как для void *. Однако на практике эти ограничения не столь существенны. При использовании компилятора gcc на компьютере х86 оба эти типа, естественно, имеют размер 32 бита. В архитектурах с 64-разрядными указателями, таких, как Alpha, тип данных unsigned long компилятора gcc также обычно имеет размер 64 бита. Тем не менее, в будущем в результате переноса компилятора gcc на другую архитектуру тип данных unsigned long может приобрести в нем размер, отличный от void *, и эту возможность должны всегда учитывать те, кто занимаются переносом ядра на другую архитектуру.
Кстати отметим, что изучая возможность применения компиляторов, отличных от gcc, нужно учитывать, что в самом коде ядра уже присутствует значительная часть других особенностей, свойственных gcc. Вполне можно себе представить, что при попытке скомпилировать ядро с использованием какого-то другого компилятора к многочисленному списку полученных ошибок добавится множество сообщений, связанных с различием относительных размеров типов данных unsigned long и void *.
Struct vm_operations_struct
Область VMA может представлять обычный участок памяти, типа того, какой возвращает функция malloc. Однако она может также представлять область памяти, которая была установлена в качестве соответствия файлу, участку разделяемой памяти, разделу свопинга или какому-то иному специальному объекту; такое соответствие устанавливается с помощью системного вызова mmap, рассматриваемого далее в этой главе.
Однако вряд ли кто-то захочет засорять код ядра конкретной информацией о каждом из объектов, на который может быть отображена структура VMA, поскольку необходимость снова и снова принимать решение о закрытии файла, отключении от разделяемой памяти и т.д. привела бы к значительному усложнению кода. Вместо этого, в объекте типа struct vm_operations_struct применяется абстрактное представление всех доступных операций, предусмотренных в объекте, на который отображена область памяти VMA: open, close и т.д. Объект struct vm_operations_struct — это просто набор указателей на функции, часть которых может быть установлена в NULL для указания о том, что данная операция не доступна для отображаемого объекта данного типа. Например, поскольку нет смысла синхронизировать страницы объекта разделяемой памяти с диском, если разделяемая память не участвует в отображении, в составе операций с разделяемой памятью в объекте struct vm_operations_struct функция синхронизации будет установлена в NULL.
Все это означает, что если область VMA отображена на какой-либо объект, то член vm_ops структуры VMA — это отличный от NULL указатель на объект struct vm_operations_struct, который представляет операции, поддерживаемые отображаемым объектом. Для объекта каждого типа, на который может быть отображена область VMA, где-то существует единственный статический объект struct vm_operations_struct, на который могут указывать структуры VMA. В качестве примера можно указать строку .
Свопинг и страничный обмен
На первых порах системы виртуальной памяти (VM) могли перемещать на диск или обратно код и данные только целого приложения, иными словами, сразу весь процесс. Этот метод называется «свопингом» (swapping) (в буквальном смысле слова — «замещением», поскольку в нем один процесс замещается другим). По этой причине область диска, отведенную для виртуальной памяти, часто называют «пространством свопинга«, даже несмотря на то, что в современных системах уже не происходит полного замещения одного процесса другим. Аналогичным образом, в качестве синонимов часто применяются термины «устройство свопинга» и «раздел свопинга», для обозначения области диска, применяемой в качестве пространства свопинга, и «файл свопинга», для обозначения обычного файла постоянной длины, используемого для подкачки.
Свопинг полезен, и для работы системы гораздо лучше, если предусмотрен хотя бы он, даже при отсутствии виртуальной памяти, но он имеет свои ограничения. Прежде всего, для него требуется размещение в памяти одновременно всего процесса, поэтому свопинг не применим, если нужно выполнить процесс, требующий больше оперативной памяти, чем установлено в системе, даже если есть много свободного пространства на диске, которое могло бы компенсировать эту нехватку.
Кроме того, свопинг часто бывает неэффективным. При его применении нужно перекачивать на диск весь процесс одновременно, даже если это требует выгрузки на диск всего объема памяти процесса, составляющего 8 Мб, лишь с той целью, чтобы освободить 2 Кб. Аналогичным образом, свопинг предусматривает загрузку в оперативную память одновременно всего процесса, даже если нужно выполнить только небольшую часть кода приложения, загружаемого в память.
Перейдем к описанию страничного обмена, который предусматривает разделение памяти системы на небольшие фрагменты — страницы, которые можно перемещать с диска и на диск независимо друг от друга. Страничный обмен аналогичен свопингу, но предусматривает большую степень детализации. Осуществление страничного обмена требует больше административных издержек по сравнению со свопингом, поскольку число страниц во много раз превышает число процессов, но позволяет достичь значительной гибкости. К тому же, страничный обмен осуществляется быстрее по нескольким причинам — одна из них состоит в том, что при страничном обмене обычно не требуется перемещать на диск или с диска весь процесс, а только те страницы, которые необходимы для выполнения запроса. Помните также, что скорость обрашения к различным устройставм памяти различается в миллион раз — необходимо любым способом избегать обращения к диску.
Как правило, страницы на каждой конкретной платформе имеют постоянный размер (например, в архитектуре х86 — 4 Кб), что позволяет упростить реализацию страничного обмена. Однако большинство современных процессоров предоставляют аппаратную поддержку страниц переменного размера, часто до 4 Мб или даже больше. Страницы переменного размера могут обеспечить более быструю и эффективную реализацию страничного обмена, но за счет дополнительного усложнения. Ядро Linux стандартного дистрибутива не поддерживает страницы переменного размера, поэтому остановимся на предположении, что страницы имеют размер 4 Кб. (Есть программные заплаты, которые поддерживают механизм обмена страниц переменного размера VSPM (variable-sized paging mechanism) процессора Cyrix, но ко времени написания этой книги они не входили в состав официального дистрибутива. К тому же, стало известно, что полученный при этом прирост производительности весьма невелик.)
Поскольку страничный обмен позволяет выполнять все Функции свопинга, но более эффективно, в современных системах типа Linux свопинг больше не применяется; строго говоря, в них применяется только страничный обмен. Но термин «свопинг» является таким привычным, что на практике термины «свопинг» и «страничный обмен» стали практически взаимозаменяемыми; в настоящей книге мы также следуем этой практике, поскольку ее придерживаются и разработчики ядра.
Система Linux может выполнять свопинг в отведенные для этого разделы диска или файлы, или одновременно и в разделы, и в файлы, в различных комбинациях. Она даже позволяет увеличивать и уменьшать пространство свопинга во время работы системы, что очень удобно, если возникает необходимость в увеличении объема пространства свопинга, но только на время, или если появляется потребность в дополнительном пространстве свопинга, но нет смысла выполнять перезагрузку системы только для того, чтобы его предоставить. Кроме того, в отличие от других разновидностей Unix, Linux может вполне обходиться и без пространства свопинга.
Swap_free
Функция swap_free— это противоположность функции get_swap_page; она освобождает один вход свопинга.
Выполнив ряд простых проверок непротиворечивости параметров, функция swap_free проверяет, не имеет ли устройство, на котором она освобождает страницу свопинга, более высокий приоритет свопинга по сравнению с устройством, которое должно рассматриваться следующим. Если это действительно так, она воспринимает это в качестве указания о том, что нужно переустановить итератор объекта swap_list на начало списка. Следующее обращение функции get_swap_page, начиная с начала списка, обнаружит вновь освобожденное пространство с более высоким приоритетом.
Корректировка членов lowest_bit и/или highest_bit, если вновь освобожденная страница лежит за определенными ими пределами. Можно видеть, что если функция swap_free освобождает страницу на устройстве, которое перед этим было полностью заполнено, она обычно корректирует либо lowest_bit, либо highest_bit, но не оба эти члена. В результате диапазон становится шире, чем он должен быть, и поэтому распределение страниц свопинга может стать немного медленнее, чем должно быть. Но это происходит крайне редко. Так или иначе, диапазон принимает более правильные значения по мере распределения и освобождения дополнительного числа страниц свопинга.
Подсчет коэффициента использования каждого элемента массива swap_map ведется только вплоть до максимума, SWAP_MAP_MAX (это значение установлено директивой #define равным 32767 в строке ). После достижения этого максимума ядро не знает, насколько выше может быть истинный коэффициент использования; поэтому оно не может безопасно уменьшать это значение. Иначе, функция swap_free уменьшает коэффициент использования и увеличивает общее число свободных страниц.
Sys_brk
Функцией, которая реализует brk является sys_brk. Она может изменить значение brk процесса и возвращает новое значение. Возвращенное значение brk равно старому значению, если значение brk нельзя было изменить.
Если новое значение brk лежит в области кода, оно явно слишком занижено и должно быть отброшено.
Округление параметра brk к адресу следующей расположенной выше страницы с использованием макрокоманды PAGE_ALIGN (строка ).
Выравнивание старого значения brk процесса по границе страницы. Это может показаться немного расточительным, поскольку если значение brk процесса устанавливается только здесь, оно уже должно быть выровнено по границе страницы. Но значение brk процесса может быть установлено в другом месте, например, при его инициализации, и этот код не выравнивает его по границе страницы. Могло бы оказаться немного быстрее выравнивание значения brk процесса по границе страницы везде, где оно устанавливается; это позволило бы ядру пропустить выравнивание по странице здесь, но поскольку brk процесса устанавливается здесь чаще, чем где бы то ни было, это вообще не должно замедлять выполнение, поэтому иной подход может привести только к незначительному улучшению.
brk уменьшается, но не находится в области кода, поэтому эта попытка допустима.
Если размер кучи имеет предел, он соблюдается. Как показывает рис. 8.5, размер кучи равен brk - mm->end_code.
Если brk области возрастает и попадает в ту часть, которая уже была отображена в виде области VMA с помощью mmap, это новое значение brk не доступно для использования и поэтому должно быть отброшено.
Заключительная проверка допустимости позволяет узнать, существует ли достаточное число свободных страниц для размещения пространства, подлежащего распределению.
Функция do_mmap (строка ) применяется для распределения пространства для новой области. Затем функция sys_brk обновляет информацию процесса о расположении brk и возвращает новое значение.
Sys_swapoff
Функция sys_swapoff удаляет указанное устройство или файл свопинга из списка устройств свопинга, если это возможно.
Поиск в списке объектов swap_info_structs соответствующего входа, установка р в качестве указателя на этот элемент, type в качестве индекса этого элемента и prev в качестве индекса предшествующего элемента, prev равен –1 при удалении первого элемента.
Если функция sys_swapoff просмотрела весь список и не нашла соответствия, то ей, безусловно, было передано недействительное имя. Она возвращает ошибку.
Если член prev имеет отрицательное значение, функция sys_swapoff удаляет первый элемент в списке; она соответствующим образом обновляет swap_list.head. Это, вероятно, эквивалентно
swap_list.head = swap_info[swap_list.head].next
но быстрее, поскольку требует меньшего числа операций разадресации.
Если удаляемое устройство является тем следующим устройством, на котором ядро в ином случае попыталось бы выполнить свопинг, итеративный курсор переустанавливается на начало списка. Это может слегка замедлить выполнение следующего распределения, но не слишком значительно; так или иначе, этот случай на практике должен встречаться крайне редко.
Если устройство нельзя было освободить, поскольку оно все еще используется, его восстанавливают на соответствующем месте в списке. Если это было одно из нескольких устройств свопинга с одинаковым приоритетом, оно может в конечном итоге оказаться не в том же относительном положении, как прежде: скажем, оно станет первым устройством с этим приоритетом, а не последним, но все еще будет находиться в порядке сортировки по приоритетам. Создается впечатление, что действие по удалению элемента из списка устройств свопинга, когда есть еще вероятность, что его придется сразу же возвращать назад, является довольно расточительным: почему бы не подождать, пока мы не сможем убедиться, что его действительно можно удалить? Ответ состоит в том, что вызов функции try_to_unuse (строка ) в предыдущей строке может привести, через цепочку вызовов функций, к прохождению по swap_list. Код, который приведет к выполнению этого, может оказаться в неопределенном состоянии, если к данному моменту удаляемое устройство свопинга все еще будет находиться в массиве swap_list.
Если это свопинг в разделе диска, функция sys_swapoff освобождает свою ссылку на него.
Функция sys_swapoff заканчивает свою работу, обнуляет поля и освобождает распределенную память. В частности, в этой строке выполняется очистка бита SWP_USED, чтобы ядро могло узнать, что устройство свопинга не доступно для использования, если оно будет пытаться снова выполнить на него свопинг. Затем функция sys_swapoff очищает индикатор err и готовится вернуть код успешного выполнения.
Sys_swapon
Функция sys_swapon, противоположность функции sys_swapoff, добавляет устройство или файл свопинга к списку системы.
Поиск неиспользуемого входа. Это довольно тонкая операция. На основании имени nr_swapfiles можно сделать вывод, что это — число используемых файлов (или устройств) свопинга, но это не так. В действительности, это максимальное индексное значение члена swap_info, которое встретилось до настоящего времени; оно никогда не уменьшается. (Это значение позволяет отслеживать верхнюю отметку данного массива.) Поэтому циклический проход по всем этим входам в массиве swap_info должен либо обнаружить неиспользуемый вход, либо оставить р, после последнего наращивания цикла, указывающим на адрес после входа nr_swapfiles. В последнем случае, если значение nr_swapfiles меньше MAX_SWAPFILES, это значит, что все используемые входы компактно расположены в левой части массива, и цикл оставляет р указывающим на свободный слот в правой части. Когда это происходит, выполняется обновление nr_swapflles. Интересно, что этот цикл все равно работал бы правильно, даже если бы значение nr_swapfiles представляло собой число активных устройств свопинга, а не верхнюю отметку. Однако если мы изменим смысл переменной nr_swapfiles, то будет нарушена работа кода в другом месте этого файла.
В массиве swap_info был найден неиспользуемый вход; теперь функция sys_swapon начинает его заполнять. Некоторые из представленных здесь значений изменятся.
Если бит SWAP_FLAGS_PREFER установлен, то желаемый приоритет закодирован в младших 15 битах переменной swap_flags. (Константы, используемые в этой и в нескольких следующих строках, определены, начиная со строки .) Иначе приоритет не был задан. Как было упомянуто ранее, в этом случае применяемое по умолчанию действие состоит просто в присвоении каждому новому устройству постепенно уменьшающегося приоритета в надежде получить приемлемую производительность свопинга без помощи человека.
Проверка того, что файл или устройство, которое ядро предполагает применить для свопинга, может быть открыто.
Проверка того, предоставлен ли функции sys_swapon файл или раздел. Если функция S_ISBLK возвращает true, это блочное устройство представляет собой раздел диска. В этом случае функция sys_swapon должна проверить, можно ли открыть это блочное устройство и не выполняет ли ядро уже на нем свопинг.
Аналогичным образом, если это не раздел, функция sys_swapon должна проверить, что это обычный файл. Если это так, она должна проверить, что ядро уже не выполняет свопинг в этот файл.
Если обе проверки оканчиваются неудачей, функция sys_swapon не получила запрос выполнить свопинг в допустимый раздел диска или файл; она отвергает попытку.
Чтение заголовка страницы с устройства свопинга в объект swap_header; это объект типа union swap_header, который определен в строке .
Проверяет логическую последовательность байтов, которая сообщает, к какой версии относится этот заголовок свопинга. Эту последовательность байтов записывает программа mkswap.
Свопинг версий 1. Здесь страница заголовка рассматривается как большое битовое отображение, в котором каждый бит представляет применимую страницу для использования в остальной части устройства. Страница заголовка, как и все страницы, имеет размер 4 Кбайт или 32 Кбит. Поскольку каждый бит представляет одну страницу, на устройстве можно размещать 32768 страниц с общим объемом 128 Мб в расчете на одно устройство свопинга. (Фактически, немного меньше, поскольку последние 10 байтов заголовка отведены для сигнатуры, и поэтому мы не можем предполагать, что доступны соответствующие 80 страниц; для свопинга также нельзя использовать страницу заголовка.) Если устройство меньше этого размера, некоторые из битов в заголовке просто не будут использоваться. В строке функция входит в цикл для проверки того, какие страницы являются применимыми, и для установки значений членов lowest_bit, highest_bit и создаваемого ей объекта swap_info_struct.
Отметим, что битовое отображение заголовка не поддерживается вечно: в действительности, оно освобождается после выхода из функции sys_swapon. Ядро использует отображение свопинга для отслеживания того, какие страницы используются; это битовое отображение заголовка используется только для установки lowest_bit и других членов объекта swap_info_struct.
Распределяет отображение свопинга и устанавливает все его коэффициенты использования в 0.
Свопинг версии 2 существено ослабляет ограничения на размер области свопинга (максимальный размер составляет около 2 Гб), а также предусматривает хранение информации заголовка немного более естественным и эффективным способом. В этом случае член info объекта swap_header содержит информацию, необходимую для функции sys_swapon.
Это новая версия заголовка свопинга не требует от функции sys_swapon, чтобы она рассматривала заголовок как битовое отображение для вычисления значений lowest_bit, highest_bit и max — значение lowest_bit всегда равно 1, а другие два значения можно вычислить за постоянное время из информации, явно хранимой в заголовке. Это и быстрее, и проще по сравнению с циклом, который проверяет 32768 битов и выполняет вдвое больше присваиваний! Тем не менее, эта и остальная работа концептуально во многом аналогична выполнявшейся ранее; функция sys_swapon только получает большую часть необходимых для нее значений непосредственно из заголовка устройства свопинга и не должна их вычислять.
Теперь становится очевидным, что автор в одном из предыдущих абзацев допустил неточность; в действительности, свопинг версии 2 все же немного ослабляет ограничения по размерам. В этой версии 80 страниц в конце файла не являются недоступными из-за сигнатуры заголовка свопинга, поэтому каждое отдельное устройство может иметь еще 320 Кб области свопинга. Однако предел все равно составляет около 128 Мб.
Функция sys_swapon закончила чтение заголовков. Она устанавливает первый элемент отображения устройства свопинга в значение SWAP_MAP_BAD (строка ), чтобы помочь ядру предотвратить попытку выполнить свопинг в страницу заголовка.
Распределяет и обнуляет отображение блокировки.
Обновляет общее число доступных страниц свопинга и выводит сообщение об этом. (Она вычитает 10 из величины сдвига в строке , чтобы вывод был в килобайтах, где 210 составляет 1 Кб.)
Вставка нового элемента в логический список устройств свопинга, как всегда, в порядке сортировки по приоритетам. Этот код функционально идентичен соответствующему коду в функции sys_swapoff и поэтому нет разумных оснований вести их отдельно. Оба эти фрагмента кода может заменить простая встроенная функция.
Очистка и выход.
Try_to_swap_out
Функцией выгрузки на диск почти самого низкого уровня является try_to_swap_out, которая периодически вызывается (через цепочку других вызовов функций) из задачи ядра kswapd (см. функцию kswapd в строке ). Эта функция записывает страницу, контролируемую единственным входом таблицы страниц и расположенную в данной области VMA данной задачи.
Если страница уже отсутствует в памяти, ее нельзя переписать из памяти на диск, поэтому функция try_to_swap_out возвращает отказ. Она также отвергает эту попытку, если заданный адрес явно недействителен (max_mapnr — это число страниц физической памяти, присутствующих в системе; см. строку ).
Если страница зарезервирована, заблокирована или используется периферийным устройством для доступа к памяти, ее нельзя переписать на диск.
Если к странице недавно выполнялся доступ, то вывод ее на диск из памяти, возможно, нецелесообразен: принцип локальности ссылок позволяет утверждать о высокой вероятности того, что страница вскоре снова потребуется. Теперь страница отмечается как «старая», чтобы будущая попытка вывести ту же страницу на диск, что может произойти очень быстро, если ядру крайне не хватает свободной памяти, была успешной. Но в данный момент перезапись страницы еще не происходит. На небольшом расстоянии от этой строки в самом коде приведены весьма содержательные комментарии, поэтому мы не будем пытаться превзойти идеал и перейдем к следующим нескольким фрагментам кода.
Уменьшение размера резидентного набора задачи (обратите внимание, что vma->vm_mm — это просто указатель обратно на объект struct mm_struct, содержащий адрес vma). Размер резидентного набора — это число страниц, принадлежащих задаче в физической памяти и, безусловно, одна из этих страниц теперь исчезает.
Поскольку страница становится недействительной, функция try_to_swap_out теперь должна сообщить, что в буферах TLB нужно сделать ссылки на эту страницу недействительными. Буфера TLB не должны разрешать адреса, относящиеся к странице, которой больше не существует. Затем функция try_to_swap_out добавляет страницу к кэшу свопинга.
И наконец, функция try_to_swap_out записывает старую страницу на диск с помощью функции rw_swap_cache (строка ). Запись происходит асинхронно, чтобы система могла выполнять другую работу, ожидая доступа к диску.
Освобождение самой страницы с помощью функции __free_page (строка ) и возврат ненулевого значения в качестве свидетельства успеха.
Unmap_fixup
Функция unmap_fixup исправляет переданное ей отображение областей VMA путем корректировки одного из концов, создания отверстия в середине или полного удаления области VMA.
Первый из этих случаев прост: отмена отображения всей области. Функция unmap_fixup просто должна закрыть основополагающий файл или другой объект, если он имеется. Можно видеть, что это не приводит к удалению самой области VMA из current->mm; она уже была удалена вызывающей функцией. Поскольку для всего диапазона области VMA отменено отображение, нечего откладывать, поэтому функция unmap_fixup просто возвращает управление.
Следующие два случая касаются удаления диапазона с начала или с конца VMA. Они также довольно просты; в основном они должны скорректировать члены vm_start или vm_end объекта VMA.
Это самый интересный из всех четырех случаев — удаление участка в середине VMA и, тем самым, создание отверстия. Функция начинает свою работу с создания локальной копии переданной ей дополнительной области VMA, а затем устанавливает параметр *extra в NULL в качестве указания для вызывающей функции, что была использована дополнительная область VMA.
Процесс разбиения VMA показан на рис. 8.4. Большая часть информации просто копируется из старой области VMA в новую, после чего функция unmap_fixup корректирует диапазоны обоих областей VMA с учетом отверстия. Первоначальная область VMA, area, сокращается, с тем, чтобы представить подобласть перед новым отверстием, a mpnt становится подобластью, расположенной после него.

Рис. 8.4. Разделение VMA
Вставляет полностью новую подобласть в current->mm.
Во всех случаях, кроме первого, функция unmap_fixup сохраняет старую область VMA. Она стала меньше, но не пуста, поэтому она снова будет вставлена в набор current->mm областей VMA.
Update_mmu_cache
В архитектуре х86 функция update_mmu_cache— это пустая операция. Она находится здесь в качестве так называемой функции-заглушки, вызов которой осуществляется в соответствующих точках не зависящей от архитектуры части ядра, чтобы в версиях для разных архитектур ее можно было определять по мере необходимости.
Устройства свопинга
В Linux ведется отсортированный по приоритету список действительных устройств свопинга (и файлов, но для простоты в настоящем разделе мы часто называем «устройствами» и то, и другое). Когда возникает необходимость распределить страницу свопинга, Linux распределяет ее на устройстве свопинга с наивысшим приоритетом, которое еще не заполнено.
В системе Linux также выполняется циклический переход от одного незаполненного устройства свопинга с равным приоритетом к другому, то есть применяется ротация устройств свопинга, что позволяет повысить производительность свопинга путем распределения запросов страничного обмена по нескольким дискам. Во время ожидания, пока один диск выполняет первый запрос, второй запрос отправляется к следующему диску. Поэтому оптимальная настройка состоит в распределении разделов свопинга по нескольким аналогичным дискам и присвоении им одинакового приоритета; более медленные диски должны иметь более низкий приоритет.
Однако ротация может также замедлять свопинг. Если несколько устройств свопинга на одном и том же диске имеют одинаковый приоритет, приходится снова и снова перемещать головки чтения/записи диска от одного устройства свопинга на диске к другому; именно в такой ситуации печально знаменитый коэффициент различия в скорости между оперативной памятью и диском, составляющий порядка 1000000, почти невозможно замаскировать.
К счастью, системный администратор может избежать этой проблемы, правильно распределив приоритеты свопинга. Истинный наследник Unix, система Linux всегда предоставляет системному администратору возможность сделать свою жизнь невыносимой, но она также всегда позволяет стать истинным триумфатором.
Простейшая схема состоит в присвоении каждому устройству свопинга на одном и том же диске разных значений приоритета; это позволяет избежать наихудших ситуаций, но вместе с тем, вероятно, не будет являться наилучшим решением.
Однако, поскольку это несложно и позволяет избежать наихудшего варианта, такой принцип применяется в системе по умолчанию, если администратор сам не назначает приоритеты.
Устройства свопинга представлены типом struct swap_info_struct (строка ). Массив этих объектов struct swap_info определен в строке . Функции в различных файлах манипулируют и используют swap_info для управления свопингом; мы приступим к их изучению чуть позже. Однако эти функции станут намного более понятными, если вначале мы изучим некоторые члены объекта struct swap_info_struct:
swap_device. Номер устройства, на котором будет выполняться свопинг; он равен 0, если объект представляет файл, а не раздел.
swap_file. Файл или раздел свопинга, представляемый этим объектом.
swap_map. Массив для подсчета числа пользователей каждой страницы свопинга в пространстве свопинга; если это число равно 0, страница свободна.
swap_lockmap. Массив, который отслеживает, происходит ли в данный момент чтение из памяти или запись на диск размещенной на диске страницы, соответствующей каждому биту в этом массиве. Страницы во время ввода/вывода должны быть заблокированы, чтобы ядро не пыталось дважды выполнять ввод/вывод одной и той же страницы одновременно или совершать еще какие-то подобные глупости. Помните, что при любой возможности со вводом/выводом совмещается любая другая обработка, поэтому попасть в такую ситуацию совсем несложно.
lowest_bit и highest_bit. Отслеживают позиции первой и последней доступных страниц на устройстве свопинга. Это позволяет ускорить поиск, связанный с определением свободного элемента. Первая страница устройства— это заголовок, который не должен использоваться для свопинга, поэтому значение lowest_bit никогда не равно 0.
cluster_next и cluster_nr. Используются для более эффективной группировки страниц свопинга на диске.
prio. Приоритет этого устройства свопинга.
pages. Число страниц, доступных на устройстве.
max. Максимальное число страниц, которое разрешено использовать ядру на этом устройстве.
next. Позволяет реализовать односвязный список (который, как вы помните, ведется в порядке приоритетов) этих объектов в массиве swap_info. Таким образом, массив отсортирован логически, а не физически. Значение next — это индекс логически последующего элемента в списке или –1 в конце списка.
Член объекта swap_list, определенный в строке , включает индекс заголовка списка (т.е. его заглавный член — см. определение объекта struct swap_list_t в строке ); этот индекс равен –1, если список пуст. Он также включает член со сбивающим с толку названием next, который позволяет определить следующее устройство свопинга, на котором мы должны попытаться распределить страницу. Поэтому данный член next представляет собой итеративный курсор. Он равен –1, если список пуст или если в настоящее время пространство свопинга заполнено.
Vfree
Функция vfree гораздо проще по сравнению с vmalloc (по крайней мере, если функция vmalloc рассматривается в сочетании с get_vm_area), но ради полноты вкратце рассмотрим vfree. Безусловно, здесь addr обозначает начало области vmallocd, которая подлежит освобождению.
Вслед за несколькими простыми проверками допустимости функция выполняет в цикле просмотр vmlist, отыскивая область для освобождения. Этот линейный просмотр заставляет думать, что было бы интересно посмотреть, позволит ли структура сбалансированного дерева, наподобие деревьев AVL, используемая для управления областями VMA, повысить производительность функций vmalloc и vfree.
Если будет найден объект struct vm_struct, соответствующий параметру addr, функция vfree удалит его из списка, освободит структуру и связанные с ней страницы, затем вернет управление. В каждом объекте struct vm_struct хранятся сведения не только о его начальном адресе, но также о его размере; это было удобно для функции get_vm_area и это также удобно здесь, поскольку позволяет функции vfree знать, сколько памяти нужно освободить.
Если бы функция vfree нашла соответствие в списке, она бы уже вернула управление, поэтому соответствие не было найдено. Возможно это плохо, но не настолько плохо, чтобы впадать в панику. Поэтому vfree довольствуется выводом предупредительного сообщения.
Виртуальная память
Компьютерные системы создаются с применением нескольких уровней памяти. На рис. 8.1 показаны наиболее важные из них с указанием ориентировочных значений, полученных в системе Linux автора. По мере перехода к правой части рисунка эти виды памяти становятся более крупными, но менее быстродействующими (а также более дешевыми в расчете на один байт). В частности, можно видеть, что скорости доступа характеризуются шестью порядками величины и крайние их значения отличаются друг от друга в 1000000 раз, а емкости характеризуются восемью порядками величины и крайние их значения отличаются друг от друга в 312500000 раз. (На практике разница в быстродействии иногда не столь заметна, но эти цифры вполне приемлемы для целей нашего описания.) Наиболее значительным отличием является последнее — различие между оперативной памятью (или основной памятью) и диском (или внешней памятью).
Рис. 8.1. Уровни хранения с характеристиками скорости и обмена
Потребность в дополнительной внешней памяти чрезвычайно велика, даже несмотря на такое низкое ее быстродействие. Было бы неплохо заставить диск подменять оперативную память, когда ее не хватает, временно перемещая неиспользуемый код и данные на диск, чтобы освободить место для действующих процессов. Как вы уже наверно знаете, в Linux это уже сделано: это так называемая виртуальная память.
Таким образом, виртуальная память представляет собой метод безукоризненного совмещения доступа к оперативной памяти и диску — к основной и внешней памяти. Приложения имеют доступ ко всей оперативной памяти, как будто она действительно существует. Мы знаем, что ее на самом деле нет и поэтому называем ее «виртуальной», но благодаря ядру приложения этого не замечают. С точки зрения приложений, виртуальная память равносильна наличию огромного объема оперативной памяти, которая на практике иногда просто медленно работает.
Термин «виртуальная память» имеет еще одно значение, которое, строго говоря, не связано с первым значением. Такое понятие, как виртуальная память, относится также к методу предоставления процессам откорректированной информации об адресах, в которых они находятся. Каждому процессу разрешено считать, что его адреса начинаются с нулевого адреса и от него наращиваются. Безусловно, в действительности это не может быть истинным для всех процессов одновременно, но это соглашение удобно при выработке выполняемого кода, поскольку процессам не нужно сообщать, что они в действительности не располагаются с нулевого адреса, и они не должны этого учитывать.
Эти два толкования не обязательно связаны, поскольку теоретически любая операционная система может предоставить каждому процессу его собственное логическое адресное пространство, не объединяя при этом основную и внешнюю память. Однако во всех реальных системах, известных автору, предусмотрены либо обе эти формы реализации виртуальной памяти, либо ни одной. Именно с этим была связана та путаница, которая возникала на первых этапах развития операционных систем.
Чтобы избежать этой многозначности, многие предпочитают закреплять за термином «виртуальная память» значение, связанное с логическим адресным пространством, и использовать для обозначения способа временного хранения информации на диске термин «страничный обмен» или «подкачка» (свопинг), характеризуя применение виртуальной памяти лишь в качестве способа хранения информации (мы дадим определения этих терминов немного позднее). Хотя в рассуждениях этих приверженцев чистоты терминологии есть доля истины, автор придерживается более распространенного толкования и редко подчеркивает такое различие, если этого не требует контекст.
Vmalloc
Функция vmalloc принимает один параметр — размер области памяти для распределения. Она возвращает указатель распределенной области или NULL, если память нельзя было распределить. Диапазон виртуальных адресов, в пределах которых функция vmalloc может распределять память, ограничена константами VMALLOC_START (строка ) и VMALLOC_END (строка ). VMALLOC_START начинается на 8 Мб выше конца физической памяти для перехвата любых ошибочных операций доступа к памяти ядра в промежуточной области, a VMALLOC_END располагается немного ниже максимально возможного 32-разрядного адреса в 4 Гб. Если в вашей системе намного больше физической память, чем в системе автора, это значит, что для функции vmalloc потенциально доступно почти все адресное пространство процессора.
Функция vmalloc начинает свою работу с округления затребованного размера в большую сторону до границы следующей страницы, если он еще не выровнен по границе страницы. (Макрокоманда PAGE_ALIGN определена в строке .) Запрос отвергается, если результирующий размер либо слишком мал (0), либо, безусловно, слишком велик.
Попытка найти участок, достаточно большой для размещения блока с размером size с помощью функции get_vm_area, которая рассматривается ниже.
Проверка того, что может быть установлено отображение таблицы страниц с помощью вызова функции vmalloc_area_pages (строка ).
Возвращает распределенную область.
Vmalloc и vfree
Одним из интересных аспектов программирования ядра является необходимость обходиться без многих вспомогательных функций, которые прикладные программисты обычно считают само собой разумеющимися, например, без функций malloc и free библиотеки С, которые основаны на примитиве brk ядра.
Автор допускает, что код ядра можно было бы пересмотреть для увязки со стандартной библиотекой С и использования ее функций malloc и free, но конечный результат стал бы и неуклюжим, и медленным— предполагается, что вызов этих функций происходит в режиме пользователя, поэтому ядру для их вызова приходилось бы переключаться в режим пользователя, а этим функциям затем пришлось бы выполнять противоположную задачу и направлять прерывания в ядро, которому пришлось бы как-то следить за тем, что происходит, и т.д. Для того, чтобы можно было обойтись без всех этих сложностей, в ядро включены его собственные версии многих знакомых функций, в том числе функций malloc и free.
И действительно, в ядре предусмотрены две отдельные пары функций, аналогичные malloc и free. Первая пара, kmalloc и kfree, управляет памятью, которая была распределена в самом сегменте ядра — фрагментами реальной, физической памяти, чьи фактические адреса известны. Вторая пара, vmalloc и vfree, распределяет и освобождает виртуальную память для нужд ядра. Память, возвращенная функцией kmalloc, лучше приспособлена для таких целей, как размещение драйверов устройств, поскольку они всегда присутствуют в физической памяти и, вместе с тем, занимают физически непрерывный участок. Однако функция kmalloc пользуется намного более ограниченными ресурсами, чем vmalloc, поскольку vmalloc может получать место в пространстве свопинга.
Функции vmalloc и vfree частично реализованы по принципам kmalloc и kfree, поскольку им нужно немного невыгружаемой памяти для ведения учета. Функции kmalloc и kfree, с другой стороны, реализованы на основе __get_free_pages, free_pages и других функций нижнего уровня для манипулирования страницами памяти.
Автор здесь не рассматривает kmalloc и kfree, но этот код включен для вашего пользования (см. соответственно, строки и ). Вместо этого, ограничимся рассмотрением более интересных функций vmalloc и vfree.
Вывод страниц на диск
Теперь, после краткого знакомства с тем, как происходит определение ситуации, когда возникает необходимость в загрузке страниц с диска в оперативную память, рассмотрим другую сторону этого уравнения: выгрузку страниц на диск.