Дисковод CD-ROM
Довольно легко заставить Linux проигрывать для вас CD диски: все, что вам нужно - это дисковод CD-ROM, колонки или наушники, CD-диск с музыкой и немного трудолюбия. Если вы устанавливали Linux на компьютер, в котором уже стоял CD-дисковод, то все необходимые настройки, скорее всего, сделаны автоматически. Если же вы поставили CD-ROM после установки Linux, то надо научить Linux распознавать этот дисковод. Для этого в каталоге /dev должна иметься ссылка (линк) на устройство. Если ее нет, создайте, выполнив следующие команды:
[root]# cd /dev [root]# ln -s hdc cdrom
где вместо hdc вы, естественно, должны указать ваш CD-дисковод. Если не знаете, что тут указать, то внимательно просмотрите те сообщения, которые Linux выдает при загрузке. Для этого не требуется перезагружаться, протокол загрузки сохранен в файле /var/log/dmesg и выдается на экран по команде dmesg.
После этого можно запустить программу управления проигрыванием CD-дисков, например xplaycd. В графической оболочке KDE имеется простой проигрыватель CD-дисков с названием "CD Player" (рис. 9.12). Вызвать его можно через меню оболочки KDE.

Рис. 9.12. CD Player
Драйверы устройств
Как уже говорилось выше, одной из основных задач операционной системы является управление аппаратной частью. Ту программу или тот кусок программного кода, который предназначен для управления конкретным устройством, и называют обычно драйвером устройства. Необходимость драйверов устройств в операционной системе объясняется тем, что каждое отдельное устройство воспринимает только свой строго фиксированный набор специализированных команд, с помощью которых этим устройством можно управлять. Причем команды эти чаще всего предназначены для выполнения каких-то простых элементарных операций. Если бы каждое приложение вынуждено было использовать только эти команды, писать приложения было бы очень сложно, да и размер их был бы очень велик. Поэтому приложения обычно используют какие-то команды высокого уровня (типа "записать файл на диск"), а о преобразовании этих команд в управляющие последовательности для конкретного устройства заботится драйвер этого устройства. Поэтому каждое отдельное устройство, будь то дисковод, клавиатура или принтер, должно иметь свой программный драйвер, который выполняет роль транслятора или связующего звена между аппаратной частью устройства и программными приложениями, использующими это устройство.
В Linux драйверы устройств бывают трех типов.
Драйверы первого типа являются частью программного кода ядра (встроены в ядро). Соответствующие устройства автоматически обнаруживаются системой и становятся доступны для приложений. Обычно таким образом обеспечивается поддержка тех устройств, которые необходимы для монтирования корневой файловой системы и запуска компьютера. Примерами таких устройств являются стандартный видеоконтроллер VGA, контроллеры IDE-дисков, материнская плата, последовательные и параллельные порты.
Драйверы второго типа представлены модулями ядра. Они оформлены в виде отдельных файлов и для их подключения (на этапе загрузки или впоследствии) необходимо выполнить отдельную команду подключения модуля, после чего будет обеспечено управление соответствующим устройством. Если необходимость в использовании устройства отпала, модуль можно выгрузить из памяти (отключить). Поэтому использование модулей обеспечивает большую гибкость, так как каждый такой драйвер может быть переконфигурирован без остановки системы. Модули часто используются для управления такими устройствами как SCSI-адаптеры, звуковые и сетевые карты.
Файлы модулей ядра располагаются в подкаталогах каталога /lib/modules. Обычно при инсталляции системы задается перечень модулей, которые будут автоматически подключаться на этапе загрузки. Список загружаемых модулей хранится в файле /etc/modules. А в файле /etc/modules.conf находится перечень опций для таких модулей. Редактировать этот файл "вручную" не рекомендуется, для этого существуют специальные скрипты (типа update-modules).
Для подключения или отключения модулей в работающей системе имеются специальные утилиты.
lsmod - выдает список загруженных в данный момент модулей.insmod - служит для загрузки или "установки" модуля из командной строки.
Пример:
insmod joystickrmmod - служит для выгрузки или "удаления" модуля .
Пример:
rmmod joystickmodprobe - автоматически загружает модули. Для того, чтобы отобразить текущую конфигурацию всех модулей можно воспользоваться командой: modprobe -c.
Примечание Хотя файлы модулей имеют суффикс .o, при использовании этих команд ссылки на модули указываются без упоминания этого суффикса. Например: при упоминании модуля, файл которого называется "joystick.o", вы должны использовать в командной строке просто "joystick". |
И, наконец, для третьего типа драйверов устройств программный код драйвера поделен между ядром и специальной утилитой, предназначенной для управления данным устройством. Например, для драйвера принтера ядро отвечает за взаимодействие с параллельным портом, а формирование управляющих сигналов для принтера осуществляет демон печати lpd (который использует для этого специальную программу-фильтр, о чем подробнее будет рассказано ниже). Другие примеры драйверов этого типа - драйверы модемов и X-сервер (драйвер видеоадаптера), о котором шла речь в лекции 7.
Но надо специально отметить, что во всех трех случаях непосредственное взаимодействие с устройством осуществляет ядро или какой-то модуль ядра. А пользовательские программы взаимодействуют с драйверами устройств через специальные файлы, расположенные в каталоге /dev и его подкаталогах. То есть взаимодействие прикладных программ с аппаратной частью компьютера в ОС Linux осуществляется по следующей схеме:
устройство <-> ядро <-> специальный файл устройства <-> программа пользователя
Такая схема обеспечивает единый подход ко всем устройствам, которые с точки зрения приложений выглядят как обычные файлы.
Файл /etc/printcap
Файл /etc/printcap - это главная база данных системы печати LPD. Принтер будет получать задания на печать только в том случае, если он (принтер) описан в этом файле. Поэтому для получения возможности использовать принтер вы должны добавить очередь печати к lpd, т. е. создать новый буферный подкаталог в каталоге /var/spool/lpd и добавить соответствующую запись в файл /etc/printcap.
Запись в файле /etc/printcap выглядит примерно так:
# ЛОКАЛЬНЫЙ djet500 lp|dj|deskjet:\ :sd=/var/spool/lpd/dj:\ :mx#0:\ :lp=/dev/lp0:\ :sh:
Каждый элемент файла /etc/printcap начинается со строки, задающей имена принтера (их может быть несколько), разделяемые вертикальной чертой. Затем следует ряд параметров конфигурации, разделенных двоеточиями (обычно каждый параметр заключается в двоеточия с обеих сторон). Каждый параметр имеет вид xx=строка или xx#число, где xx - двухсимвольное имя параметра, а строка и число - присваиваемые ему значения. Если никакого значения не присваивается, переменная является булевой, и ее присутствие означает "истина". Допускаются пустые операторы: два рядом стоящих двоеточия. Строки, начинающиеся символом #, содержат комментарий. Обратная косая черта в конце строки означает, что в следующей строке идет продолжение текущей строки.
Приведенный выше пример записи определяет принтер называемый lp, dj, или deskjet, его спул размещается в директории /var/spool/lpd/dj, максимальный размер задания не имеет ограничения, печать производится на устройство /dev/lp0, и страница с заголовком (с именем пользователя, который отправил задание на печать, и другой информацией) не добавляется в начало задания печати.
Подробнее о том, как создавать такие записи, можно прочитать на справочной странице для printcap. Но о некоторых самых важных (и обязательных) параметрах стоит рассказать здесь, хотя бы просто для примера.
sd=буферный_каталог. У каждого принтера должен быть свой буферный каталог. Все буферные каталоги должны находиться в одном каталоге (обычно это /var/spool/lpd) и иметь имена, совпадающие с полными именами обслуживаемых ими принтеров. Буферный каталог нужен даже в том случае, если описываемый принтер подключен к другой машине: задания находятся на локальной машине до тех пор, пока они не будут переданы на печать.lp=имя_устройства. В таком виде этот параметр должен задаваться только для локального принтера. Если принтер находится на другой машине, вместо имени устройства указывается имя уникального файла, который существует и расположен на локальном диске. Чтобы принтер мог возвращать через указанный файл информацию о своем состоянии, необходимо задать в элементе булеву переменную rw, чтобы устройство было открыто и для чтения, и для записи.rm и rp. Во многих случаях в качестве печатающего устройства используется сетевой принтер, подключенный к какому-то другому компьютеру в локальной (или даже глобальной) сети. В таком случае на вашей машине в файле /etc/printcap должны присутствовать две переменные rm и rp. В переменной rm определяется машина, на которую должны посылаться задания, а переменная rp задает имя принтера на этой машине.mx. Переменная mx используется для задания максимального размера (в байтах) печатаемого файла. Этот параметр может использоваться системными администраторами для того, чтобы предотвратить отрицательные последствия распространенной ошибки начинающих пользователей, состоящей в посылке на печать двоичных файлов (которые обычно имеют большую длину). Поскольку такие файлы могут содержать произвольные символы, в том числе символы, которые служат в качестве управляющих команд для принтера, печать двоичных файлов может приводить, например, к неоправданному расходованию бумаги и другим неприятным последствиям. На локальном принтере персонального компьютера этот параметр можно и не задавать. Я привел его для того, чтобы отметить, что для этого параметра, как и для всех других числовых параметров, значение должно отделяться от имени параметра знаком #, например, mx#0. Если написать mx=0, то такая запись не вызовет сообщений об ошибке, но она не изменяет значения переменной mx.
Еще один очень существенная группа параметров - это параметры of, if и nf. Но о них надо поговорить особо, что мы и сделаем чуть ниже в подразделе "Фильтры". Однако вначале рассмотрим программу, которая позволяет осуществить настройку принтера и создать файл /etc/printcap/.
Фильтры
Когда задание на печать дождется своей очереди, lpd создает ряд программных каналов между буферным файлом и печатающим устройством для передачи данных, подлежащих печати. Посередине этой цепочки lpd устанавливает процесс-фильтр, в задачи которого входит просмотр и дополнительная обработка потока данных, направляемых на принтер. Процессы-фильтры могут выполнять над данными различные преобразования, в частности, форматирование и поддержку различных протоколов, которые могут понадобиться для работы с данным принтером.
Фильтр - это, как правило, просто сценарий shell, который вызывает ряд конвертирующих программ. Фильтр можно указать в командной строке вызова программы lpr. Если в командной строке фильтр не указан, то используются фильтры, заданные параметрами if, of и nf соответствующей записи в файле /etc/printcap. Если в этой записи присутствует переменная if, а параметра of нет, то устройство (принтер) будет открываться один раз для каждого задания, а фильтр будет посылать одно задание на принтер и завершать работу. Если есть of, а if нет, то lpd однократно откроет устройство и вызовет программу-фильтр для посылки сразу всех заданий, стоящих в очереди. Это полезно для печати на тех устройствах, соединение с которыми требует большого времени. Одновременного использования параметров of и if следует избегать, а из двух предыдущих вариантов рекомендуется выбирать использование параметра if. Соответствующий элемент в записи файла /etc/printcap может иметь примерно такой вид:
:if=/var/spool/lpd/dj/filter:\
Если никакого фильтра вообще не задано, то вывод на печать может выглядеть очень некрасиво. Например, при печати обычного текстового файла вывод может выглядеть примерно так:
This is line one. This is line two. This is line three.
Печать файла в формате PostScript выдаст листинг команд PostScript, напечатанных с этим "лестничным эффектом", а не полезный вывод. В руководстве "Printing HOWTO" приводится следующий пример простого фильтра, предназначенного только для того, чтобы устранить "лестничный эффект":
#!perl # Предыдущая строка должна содержать полный путь к perl # Скрипт должен быть исполнимым: chmod 755 filter while(<STDIN>){chop $_; print "$_\r\n";}; # вы можете также добавить в конец прогон страницы: print "\f";
Этот текст надо сохранить в виде файла /var/spool/lpd/dj/filter, после чего будут нормально печататься обычные текстовые файлы.
Но печать простых ASCII-файлов - это только частный случай печати. В большинстве случаев в настоящее время печатаются файлы в других форматах, например, PostScript. Проблема вывода таких файлов на печать тоже решается путем использования фильтра, только гораздо более сложного. Таких фильтров разработано уже достаточно много, но самый важный из них - программа ghostscript.
Форматирование жесткого диска
Низкоуровневое форматирование жесткого диска под Linux невозможно. Впрочем, в этом нет особой необходимости, поскольку современные диски выпускаются отформатированными на низком уровне.
Форматирование на высоком уровне заключается в создании на диске разделов и файловой системы. Для создания разделов под Linux используются программы fdisk, cfdisk и sfdisk. Как сообщает man-страница к программе fdisk, программа cfdisk позволяет создать качественную таблицу разделов, но имеет некоторые ограничения. Программа fdisk, хотя и позволяет произвести разбиение диска в большинстве случаев, но содержит несколько ошибок. Ее главное преимущество в том, что она поддерживает разделы DOS, BSD и других систем. Программа sfdisk работает более корректно, чем fdisk, и она гораздо мощнее и fdisk, и cfdisk, но имеет неудобный пользовательский интерфейс. Так что man-страница рекомендует пытаться применять эти программы в следующем порядке: cfdisk, fdisk, sfdisk.
Однако, на мой взгляд, интерфейс любой из этих программ не предназначен для начинающих пользователей. Поэтому для создания разделов на диске я бы рекомендовал использовать программу Partition Magic фирмы Power Qwest. Несколько слов о ней было сказано в лекции 2, как и о разбиении диска, поэтому на этом вопросе более не будем останавливаться.
После разбиения диска на разделы надо создать файловую систему в разделах, предназначенных для использования под Linux,. Для этого используется команда mkfs. С ее помощью можно создать не только файловую систему типа ext2fs, но и файловые системы других типов. Типичный пример запуска этой команды:
[root]# mkfs -t тип /dev/hda3
где тип - тип создаваемой файловой системы, например, ext2, а /dev/hda3 - указание форматируемого раздела диска1).
Чтобы использовать mkfs, не обязательно иметь права суперпользователя, достаточно иметь право записи в файл соответствующего устройства.
|
Внимание! Команда mkfs очень опасна! Она перезаписывает область диска, в которой хранятся inodes. Так что если вы ошибетесь в указании раздела диска, вы можете уничтожить ценные для вас данные. |
После создания файловой системы ее надо смонтировать в общее дерево каталогов. Делается это с помощью команды mount, которую мы уже рассматривали, так что повторяться не стоит. Единственное, что можно отметить, так это то, что смонтировав первый раз диск или раздел, в котором вы только что создали файловую систему, вы увидите, что она пуста, т. е. не содержит никаких файлов и каталогов, кроме единственного каталога с именем lost+found. Этот каталог должен существовать в каждой файловой системе, поскольку он выполняет служебную роль: при проверке файловой системы командой fsck в этом каталоге собираются "потерянные" файлы и подкаталоги. О команде fsck мы еще поговорим, но до этого рассмотрим кратко вопрос об оптимизации работы жесткого диска, которая выполняется с помощью команды hdparm.
Изменение раскладки клавиатуры для текстового режима
В дистрибутиве Red Hat загрузка таблицы раскладки клавиатуры и системного фонта производится в файле /etc/rc.d/rc.sysinit. Но лезть в этот файл и корректировать его содержимое для изменения раскладки не требуется. Дело в том, что файлы с различными раскладками находятся в каталоге /lib/kbd/keymaps/i386/qwerty или /usr/lib/kbd/keymaps/i386/qwerty, а выбор конкретного файла раскладки задается файлом /etc/sysconfig/keyboard. Этот файл можно отредактировать вручную, а можно - с помощью программы kbdconfig.
Команда kbdconfig прописывает новое значение в файл /etc/sysconfig/keyboard и загружает указанную таблицу в оперативную память. Того же эффекта можно добиться, если прописать имя новой таблицы в файл /etc/sysconfig/keyboard и выполнить команду
[root]# /etc/rc.d/init.d/keytable start
Оба этих варианта позволяют переключиться на новую раскладку "на ходу".
Если же только откорректировать содержимое файла /etc/sysconfig/keyboard, то перезагрузка таблицы произойдет только после перезапуска компьютера или после выполнения команды (в примере загружается раскладка из файла ru-win.map):
[root]# loadkeys /usr/lib/kbd/keymaps/i386/qwerty/ru-win.map
Впрочем, переключение "на ходу" вряд ли требуется делать, поскольку обычно человек привыкает к одной раскладке, и пальцы сами находят привычные клавиши, так что всякое изменение тут только осложнит работу. Поэтому имеет смысл поэкспериментировать один раз с различными раскладками, выбрать наиболее удобную (считай, привычную) и на этом можно успокоиться.
При установке русифицированных дистрибутивов Linux (по крайней мере Black Cat) обычно выбирается раскладка ru1 (точка на <Shift>+<7>, запятая на <Shift>+<6>). Для тех, кто привык работать в Windows, может оказаться более привычной раскладка как в Windows (в русском регистре точка и запятая находятся рядом с правой кнопкой <Shift>). Для таких пользователей имеется раскладка ru_ms. Если вас не удовлетворяют эти варианты, то можете выбрать любую из имеющихся в вашей системе, либо найти что-либо подходящее в Интернет. Предположим, что вы нашли и скачали файл ru_win_ctrl.map.gz от IP Labs (http://www.iplabs.ru/Linux/ru_win_ctrl.map.gz). Остается только положить этот файл в /usr/lib/kbd/keytables/i386/qwerty/, запустить kbdconfig и выбрать ru_win_ctrl.
После установки новой таблицы раскладки клавиатуры иногда возникают затруднения в определении того, какая именно клавиша или комбинация клавиш переключает из режима ввода английских символов в режим ввода русских. Гадать тут не надо, достаточно просмотреть файл таблицы раскладки клавиатуры. Обычно в самом начале файла эта комбинация указывается открытым текстом, правда, в большинстве случаев английским. (Если вы забыли, какая именно таблица загружена, то посмотрите файл /etc/sysconfig/keyboard).
Клавиатура
Клавиатура к вашему компьютеру уже, скорее всего, подключена, вопрос может состоять только в том, чтобы настроить ее. Настройка клавиатуры заключается в настройке таких вещей, как:
раскладка клавиатуры;скорость повтора посылаемых клавиатурой сигналов в случае удержания клавиш пользователем;длительность интервала задержки от момента нажатия клавиши до того момента, когда клавиатура начинает повторять посылку сигналов.
Два последних параметра (скорость повтора и время задержки) устанавливаются с помощью специальной команды kbdrate.
Команда fsck
Описание команды fsck, наверное, правильное было бы отнести к разделу о файловых системах, но, поскольку ее предназначение состоит в том, чтобы по возможности восстановить работоспособность дисковой подсистемы, мы рассматриваем ее в разделе о настройке жесткого диска.
Основная функция программы fsck заключается в восстановлении логической непротиворечивости файловой системы, созданной в разделе жесткого диска. При выполнении этой команды производится поиск следующих ошибок:
сектора, которые используются одновременно двумя файлами;сектора, которые включены в список свободных секторов, хотя они содержат часть какого-то файла;сектора, которые не содержат информации, но не включены в список свободных секторов;индексные дескрипторы файлов (inodes), не указанные ни в одном каталоге;неверная общая информация в суперблоке и т. д.
Формат запуска команды следующий:
[root]# fsck [опции] [-t fstype] [--fs-options] filesystem
где fstype - тип проверяемой файловой системы, а в качестве filesystem можно указать либо имя устройства (например, /dev/hda4), либо точку монтирования (/, /opt, /mnt/wint) (Примечание: в man-странице по fsck сказано, что можно еще использовать метку (label) файловой системы, либо UUID, но, что такое два последних варианта, я пояснить не берусь).
Вообще говоря, команда fsck не является самостоятельной утилитой, она просто предоставляет единый интерфейс вызова специализированных программ для проверки файловых систем разных типов. Эти программы называются fsck.fstype (например, fsck.ext2) и команда fsck при запуске производит поиск соответствующей специфической программы сначала в /sbin, затем в /etc/fs и /etc, и, наконец, в каталогах, перечисленных в переменной PATH. Опции, указанные после двойного дефиса, передаются команде fsck.fstype.
Из собственных опций команды fsck (они указываются сразу после имени) стоит отметить опции -A, -a, -r и -N. Если указать опцию -a, то при обнаружении ошибок в файловой системе будет производиться их автоматическое исправление. Указание опции -A приводит к тому, что команда просмотрит файл /etc/fstab и за один прогон проверит все перечисленные в нем файловые системы. Опция -r переключает команду в интерактивный режим работы, т. е. перед тем, как произвести какие-то изменения, будет выдаваться запрос на подтверждение действия. Задание опции -N приводит к тому, что никаких изменений в файловой системе производится не будет, будет только сказано, что должно быть сделано.
При загрузке ОС Linux в некоторых случаях происходит автоматический запуск команды fsck. Основных причин для выполнения fsck на этапе загрузки системы две: некорректный выход из системы в предыдущий раз (например, резкое отключение питания или неисправность аппаратуры) и достижение заданного порога для количества выполнений операции размонтирования файловой системы. При каждом выполнении операций монтирования-размонтирования файловой системы в ее суперблоке (см. лекцию 16) делаются специальные отметки. Если последнее размонтирование завершилось корректно, то файловая система помечается как "чистая" (clean) и число операций монтирования-размонтирования увеличивается на единицу. Если корректного размонтирования не было, то файловая система помечена как "грязная" (dirty). На этапе загрузки ОС проверяется, являются ли все файловые системы "чистыми", и если нет, то для "грязных" систем выполняется команда fsck. Кроме того, даже если все системы "чистые", но достигнут порог для числа операций монтирования/размонтирования, запускается та же команда с опцией -A. Как было сказано выше, при этом производится проверка всех файловых систем, перечисленных в файле /etc/fstab. Порядок, в котором проверяются файловые системы, определяется числами, указанными в последнем поле каждой строки файла /etc/fstab. Файловые системы проверяются в порядке возрастания этих номеров. Первым всегда следует проверять корневой раздел. Если две файловые системы расположены на разных дисках, им может быть присвоен один и тот же номер. Это приводит к тому, что они будут проверяться одновременно, а, значит, сократится общее время проверки. Но если файловые системы расположены на одном и том же физическом устройстве (например, в разных разделах), то совпадение номеров вызовет только замедление процедуры проверки, так как головки диска должны будут совершать лишние перемещения.
Иногда требуется запустить fsck и вручную. При этом лучше всего предварительно перевести систему в однопользовательский режим и размонтировать проверяемые файловые системы (или смонтировать их в режиме "только для чтения"). Например, запуск fsck в разделе /usr обычно требуется тогда, когда файловая система разрушена и тогда любые дальнейшие действия в разрушенной системе могут привести к полному краху, а, значит, fsck должна быть запущена как можно скорее. Обычно о необходимости перехода в однопользовательский режим говорит также то, что fsck не может автоматически восстановить файловую систему при загрузке. Такое случается относительно редко, обычно при выходе из строя жесткого диска или при попытках установить какую-либо экспериментальную версию ядра, но все же об этом надо знать, чтобы не растеряться в затруднительной ситуации.
К сожалению, в процессе восстановления файловой системы приходится полностью полагаться на возможности программы fsck. Начинающему пользователю не стоит самостоятельно пытаться произвести какие-то действия в поврежденной файловой системы, потому что вы рискуете перевести ядро в паническое состояние (kernel panic).
Если fsck обнаруживает "потерянные файлы", т. е. такие файлы, которые не указаны ни в одном из каталогов, она помещает их в каталог lost+found на верхнем уровне проверяемой файловой системы. Поскольку имена файлов регистрируются только в родительском каталоге, то в данном случае их "истинные" имена неизвестны, и команда присваивает им имена, совпадающие с номерами их индексных дескрипторов.
Команда hdparm
Команда hdparm служит для того, чтобы получить или установить некоторые параметры IDE-интерфейса жесткого диска (ов). С помощью этой команды можно попытаться оптимизировать работу с жестким диском. Однако имейте в виду, что команда эта не безопасна. Если задать значение параметра, которое не поддерживается аппаратным обеспечением, можно потерять данные на диске.
Данные о том, в каких случаях стоит использовать эту команду, весьма противоречивы. Одни авторы http://linux.oreillynet.com/pub/a/linux/2000/06/29/hdparm.htmlуверяют, что с ее помощью добиться чуть ли не 10-кратного увеличения скорости обмена данными с жестким диском, другие [П1.5] утверждают, что можно потратить много времени на настройку интерфейса жесткого диска, а в результате получить лишь незначительное увеличение скорости работы. По-видимому, получаемый выигрыш определяется, в основном, моделью жесткого диска, так что сами решайте, имеет ли смысл этим заниматься. Но, как утверждает Rob Flickenger http://linux.oreillynet.com/pub/a/linux/2000/06/29/hdparm.html, если у вас IDE или EIDE диск, выпущенный не более 2 лет назад, то заняться оптимизацией стоит!
Экспериментировать с этой командой рекомендуется получив права суперпользователя, причем лучше, если система запущена в однопользовательском режиме. Поскольку существует опасность потери данных, перед использованием команды hdparm необходимо сделать резервную копию ценной информации, и каждый раз перед ее запуском выполнять команду sync, чтобы сбросить на диск данные, находящиеся временно в буферах.
Формат запуска команды прост:
[user]$ hdparm опция устройство
Если после указания опции не указывать нового значения для соответствующего параметра, то будет просто выдано его действующее значение. А если запустить команду без указания опций вообще, то будут выведены значения основных параметров, действующих при работе с данным устройством (IDE-диском). Вывод выглядит примерно следующим образом:
[user]$ hdparm /dev/hda /dev/hda: multcount = 0 (off) I/O support = 0 (default 16-bit) unmaskirq = 0 (off) using_dma = 0 (off) keepsettings = 0 (off) nowerr = 0 (off) readonly = 0 (off) readahead = 8 (on) geometry = 1870/255/63, sectors = 30043440, start = 0
Обычно это значения, устанавливаемые по умолчанию. Как видите, большинство возможностей просто отключено. Это и естественно, поскольку разработчики дистрибутивов выбирают такие значения параметров, при которых будут работать любые типы дисков. А уж об оптимизации параметров для вашего диска придется позаботиться вам самим!
Для начала посмотрим, какую еще информацию о диске и параметрах интерфейса можно получить с помощью команды hdparm.
Опция -i позволяет получить информацию о модели жесткого диска, его серийном номере и некоторых других параметрах.Опция -g выводит информацию о геометрии диска (число цилиндров/головок/секторов), его размере (числе секторов), и начальном смещении (номер сектора, с которого начинается используемое пространство, обычно 0).Опция -T позволяет протестировать скорость обмена данными с кэшем (т. е. скорость работы подсистемы память-ЦПУ-буфер кэш).Опция -е служит для тестирования скорости непосредственно записи на диск (а не в кэш-память).
Поскольку опции в команде можно комбинировать, давайте, выполним команду
[root]# hdparm -Tt /dev/hda
Результатом будут примерно такие строки (для вашего диска цифры, конечно, будут другими):
/dev/hda: Timing buffer-cache reads: 128 MB in 1.34 seconds = 95.52 MB/sec Timing buffered disk reads: 64 MB in 17.86 seconds = 3.58 MB/sec
Эти данные позволяют судить о производительности подсистемы ввода-вывода вашего жесткого диска. Если ваш диск не очень давнего выпуска, можно попытаться поднять производительность этой подсистемы, используя следующие опции команды hdparm:
С помощью опции -c вы имеете возможность воздействовать на формат обмена данными между процессором и жестким диском. По умолчанию используется значение 16 бит, но если после -c указать 1 или 3, то произойдет переключение на один из режимов 32-битной передачи. Режим, имеющий номер 3, считается более надежным, хотя и работает чуть медленнее.Используя опцию -d 1 можно активизировать режим DMA (Direct Memory Access - прямой доступ к памяти). Однако, чтобы это имело смысл, ядро должно быть скомпилировано с поддержкой DMA.Опция -m задает многосекторный режим ввода-вывода. Число после опции указывает максимальное количество секторов, которые можно передать вместе. Это ускоряет передачу больших файлов. Максимально допустимое значение этого параметра для вашей модели жесткого диска указано под ключевым словом MaxMultSect в перечне параметров, выдаваемых командой hdparm -i.С помощью опции -p можно настраивать режим PIO (программируемый ввод-вывод). Чем выше число (можно использовать значения в интервале от 0 до 5), тем быстрее осуществляется передача данных. Повышение этого параметра ничего не дает при работе с медленным диском, но повышает опасность потери данных, так что подходите к его использованию осторожно.Включение опции -u приводит к тому, что снимается запрет на обработку других прерываний, установленный на время обработки дискового прерывания. Это означает, что во время ожидания запрошенных с диска данных ядро сможет принять и обработать другие запросы (например, полученные от сетевых устройств или модема). Это должно положительно сказаться на общей производительности системы, но не все аппаратные конфигурации способны работать в таком режиме!
Давайте попробуем осторожно улучшить настройки подсистемы ввода-вывода данных для жесткого диска. Изменяйте значения параметров по одному, и после каждого изменения проверяйте результат с помощью команды
hdparm -tT /dev/hda
В случае зависания компьютера или каких-то других неприятностей (вы к ним готовы, не так ли!), перезагружайте компьютер (снова в однопользовательском режиме) и пробуйте другое значение для параметра, изменявшегося последним. Поскольку задаваемые вами установки нигде не зафиксировались, вы будете каждый раз начинать с одной и той же точки. Приведу для иллюстрации тот результат, на котором я решил остановить эксперименты:
[root]# hdparm -X66 -d1 -u1 -m16 -c3 /dev/hda /dev/hda: setting 32-bit I/O support flag to 3 setting multcount to 16 setting unmaskirq to 1 (on) setting using_dma to 1 (on) setting xfermode to 66 (UltraDMA mode2) multcount = 16 (on) I/O support = 3 (32-bit w/sync) unmaskirq = 1 (on) using_dma = 1 (on) [root]# hdparm -tT /dev/hda /dev/hda: Timing buffer-cache reads: 128 MB in 1.43 seconds =89.51 MB/sec Timing buffered disk reads: 64 MB in 3.18 seconds =20.13 MB/sec
Как видите, скорость обмена данными возросла у меня примерно в 6 раз!
Как уже было сказано, после выполнения команды hdparm с любым набором опций вновь установленные значения действуют только в текущем сеансе работы системы, а после перезагрузки оптимизированные установки будут потеряны. Поэтому после завершения экспериментов надо еще записать вызов команды с подобранными значениями опций в один из системных скриптов загрузки, например, в /etc/rc.d/rc.sysinit (в ALT Linux Junior 1.0 для настройки IDE-дисков имеется специальный скрипт /etc/rc.d/scripts/idetune). Желательно перед этим убедиться, что система ведет себя стабильно и даже выполнить команду проверки состояния файловой системы на данном устройстве.
В заключение заметим, что кроме опций, влияющих на производительность подсистемы ввода-вывода (имейте в виду, что далеко не все они были рассмотрены выше), команда hdparm имеет еще ряд опций, позволяющих управлять энергопотреблением и другими характеристиками дисковой подсистемы. Полный список всех опций команды hdparm смотрите на соответствующей man-странице (man 8 hdparm).
Команда kbdrate
Скорость повтора задается в символах в секунду и может принимать только определенные значения в пределах от 2 до 30 символов в секунду. Но задать (после опции -r) вы можете любое значение в этих пределах, программа сама выберет ближайшее допустимое значение. Число после опции -d задает задержку в миллисекундах (допустимы значения от 250 до 1000 с шагом 250). Чтобы не устанавливать эти значения после каждого перезапуска компьютера, можно добавить в файл /etc/rc.d/rc.sysinit сроку следующего вида:
/sbin/kbdrate -s -r 16 -d 500
где опция -s просто подавляет вывод ненужных в данном случае сообщений. Если эту команду выполнить без указания параметров, для скорости повтора и задержки будут установлены значения по умолчанию: для скорости повтора - 10,9 символов в секунду, а для задержки - 250 миллисекунд.
Еще один вопрос, относящийся к настройке клавиатуры, - это способ изменения положения переключателей NumLock, CapsLock и ScrollLock. Для этого можно воспользоваться командой setleds. Например, для того, чтобы переключатель NumLock был по умолчанию включен, добавьте в файл /etc/rc.d/rc.sysinit следующие строки:
for tty in /dev/tty[1-9]*; do setleds -D +num < $tty done
Изменение раскладки клавиатуры - это вопрос значительно более сложный. Но, поскольку этот вопрос имеет большое значение как вообще для настройки клавиатуры, так и для решения проблемы русификации, его необходимо рассмотреть подробнее.
И начать придется с краткого изложения проблем кодировки символов.
Конфликты по прерываниям
Сначала надо определить, какое прерывание использует ваша мышь, и убедиться, что она не конфликтует с каким-нибудь другим устройством. Этот момент очень важен, потому что под Linux мышь не может использовать одно и то же прерывание с каким-либо другим устройством, даже если все прекрасно работает под управлением другой ОС. Так что проверьте документацию на все подключенные у вас периферийные устройства, чтобы знать, какие прерывания они используют!
Список занятых (используемых) на данный момент прерываний можно получить, выполнив команду
[user]$ cat /proc/interrupts
или просмотрев файл /proc/interrupts.
В большинстве случаев IRQ4 используется первым последовательным портом (/dev/ttyS0), IRQ3 - вторым последовательным портом (/dev/ttyS1, предполагается, что у вас есть такие устройства, если нет - вы можете использовать их IRQ). IRQ5 используется некоторыми SCSI-устройствами, а IRQ12 - некоторыми сетевыми картами. Если ваша сетевая карта использует IRQ12, а ваша мышь - типа PS/2, то у вас будут проблемы, поскольку вы вынуждены будете использовать IRQ12 только для порта PS/2. Для мышей ATI-XL, Inport и Logitech ядро по умолчанию использует прерывание IRQ5, так что если вы не хотите перекомпилировать ядро, вам придется использовать для мыши именно это прерывание. Впрочем, последние версии ядра позволяют задать опции командной строки, определяющие прерывание, которое будут использовать мыши типа Inport и Logitech. Мыши типа PS/2 всегда используют прерывание IRQ12, и не существует способа изменить это, так что в случае конфликтов надо перенастраивать другие периферийные устройства.
Модуль XKB
В последних версиях дистрибутивов Linux устанавливается дополнительный модуль работы с клавиатурой - XKB. Модуль XKB точно также сообщает программе только скан-код и свое "состояние". Но в отличие от "старого" модуля (который называют "core protocol", или "core-модуль") XKB имеет более сложную таблицу символов, другой набор "модификаторов" и некоторые дополнительные параметры "состояния клавиатуры". Поэтому для полноценной работы с XKB, библиотека X-lib должна содержать модифицированные процедуры интерпретации скан-кодов (процедуры, "знающие" о XKB). Естественно, все версии X-Window, у которых X-сервер "укомплектован" модулем XKB, имеют и соответствующую библиотеку X-lib. Таким образом, XKB фактически делится на две части - модуль, встроенный в X-сервер, и набор подпрограмм, входящих в библиотеку X-lib.
Однако, поскольку существуют программы, которые были рассчитаны на работу со старой библиотекой X-lib, "не подозревающей" о существовании XKB, возникает "проблема совместимости". То есть, модуль XKB должен уметь общаться как со "своей" X-lib, так и со "старой" (работающей в соответствии с "core protocol"). Естественно, "общение" не ограничивается только передачей сообщений о нажатии/отпускании клавиш. Процедуры X-lib могут обращаться к X-серверу с различными запросами (например - взять таблицу символов) и командами (например, поменять в этой таблице расположение символов). На все эти запросы и команды модуль XKB должен реагировать так, чтобы даже "старая" X-lib могла работать правильно (насколько это возможно).
При старте X-сервера, модуль XKB зачитывает все необходимые данные из текстовых файлов, которые образуют "базу данных" настроек XKB. Строго говоря, большинство из этих файлов сам модуль XKB не читает. Он вызывает программу xkbcomp, которая переводит содержимое этих файлов в двоичный формат, понятный непосредственно модулю XKB. Но для настройки это не так уж важно, поскольку вызов xkbcomp происходит автоматически, незаметно для пользователя.
База данных, необходимых модулю XKB, находится в каталоге /usr/X11R6//lib/X11/xkb и состоит из 5 компонентов, расположенных в подкаталогах с именами:
keycodes
Здесь расположены таблицы, которые просто задают символические имена для скан-кодов. Например
<TLDE>= 49; <AE01> = 10;types
Здесь описываются возможные типы клавиш. Тип клавиши определяет как должно меняться значение, выдаваемое клавишей в зависимости от модификаторов (<Control>, <Shift> и т. п.). Так, например, "буквенные" клавиши относятся к типу ALPHABETIC, что означает, что они имеют разное значение в зависимости от состояния <Shift> и <Caps Lock>. А клавиша <Enter> имеет тип ONE_LEVEL, что означает, что ее значение всегда одно и то же, независимо от состояния модификаторов.
compat (сокращение от compability)
Здесь описывается "поведение" модификаторов. В модуле XKB имеется несколько внутренних переменных, которые, в конечном счете, и определяют, какой символ будет генерироваться при нажатии клавиши в конкретной ситуации. Так вот, в файлах из каталога compat как раз описывается, как должны меняться эти переменные при нажатии различных клавиш-модификаторов. В этом же разделе обычно описывается и поведение "лампочек-индикаторов" на клавиатуре.
symbols
Это каталог содержит таблицы, в которых для каждого скан-кода (задаваемого именем скан-кода, определенным в keycodes) перечисляются все значения (symbols), которые должна выдавать клавиша. Естественно, количество различных значений зависит от типа клавиши (которые описываются в types), а какое именно значение будет выдано в конкретной ситуации, определяется состоянием модификаторов и их "поведением" (которое описывается в compat).
geometry
Здесь описываются варианты "геометрии" клавиатуры, т. е. расположение клавиш на клавиатуре. Эти описания нужны не столько самому X-серверу, сколько прикладным программам, которые рисуют изображение клавиатуры.
Надо сказать, что в каждом из этих каталогов имеется несколько файлов (иногда, довольно много) с разными настройками. Более того, каждый файл внутри себя может содержать несколько блоков (секций, разделов) вида
тип_компонента "имя_блока" {........};
Поэтому, для того, чтобы выбрать конкретную настройку, ее обычно указывают в виде имя_файла(имя_блока), например, us(pc104). В то же время, обычно один из блоков в файле (не обязательно самый первый) помечается флагом default. Это означает, что если указать только имя файла, то будет выбран именно этот блок.
Полная конфигурация XKB задается в секции InputDevice, определяющей клавиатуру, файла конфигурирования пакета XFree86, т. е. в файле /etc/X11/XF86Config-4. При этом имеется три способа задания конфигурации клавиатуры в этом файле.
Первый способ задания конфигурации заключается в том, что вы можете указать непосредственно каждый из компонентов, например
Option "XkbKeycodes" "xfree86" Option "XkbTypes" "default" Option "XkbCompat" "default" Option "XkbSymbols" "us(pc104)" Option "XkbGeometry" "pc(pc104)"
Как легко догадаться, это означает, что:
описание keycodes берется из файла "xfree86" в подкаталоге keycodes, причем из файла будет выбран тот блок, который помечен в нем флагом default;описание types берется из файла "default" в подкаталоге types;описание compat берется из файла "default" в подкаталоге compat;описание symbols берется из файла "us" в подкаталоге symbols, причем будет выбран блок "pc104";описание geometry берется из файла "pc" в подкаталоге geometry, блок "pc104";
Надо заметить, что в любом блоке (в любых компонентах) может встретиться инструкция include "имя_файла(имя_блока)" (естественно, имя_блока может отсутствовать) что означает, что в текущий блок должно быть вставлено другое описание из указанного файла (указанного блока). Поэтому полное описание может неявно включать в себя данные из многих других файлов, кроме тех, которые вы явно укажете в файле конфигурации X-сервера.
Второй способ задания конфигурации клавиатуры заключается в том, что вы можете указать одной инструкцией сразу полный набор настроек. Такие наборы называются keymaps и, также как и обычные компоненты конфигурации XKB, располагаются в отдельных файлах (которые, тоже содержат в себе несколько именованных блоков) в подкаталоге keymap.
Обычно, в каждом блоке в файлах из keymap просто указывается из каких файлов XKB должен извлечь соответствующие компоненты (хотя, в принципе, там может быть и полное описание всех компонентов), например
xkb_keymap "ru" { xkb_keycodes { include "xfree86" }; xkb_types { include "default" }; xkb_compatibility { include "default" }; xkb_symbols { include "en_US(pc105)+ru" }; xkb_geometry { include "pc(pc102)" }; };
Обратите внимание, что в одной инструкции include может быть указано несколько файлов (блоков) через знак "+". Понятно, что это означает, что должны быть вставлены последовательно все указанные файлы.
Таким образом, в файле конфигурации X-сервера можно вместо пяти компонентов указать сразу один из готовых наборов keymap, например
Option "XkbKeymap" "xfree86(ru)"
Кроме того, эти два способа можно комбинировать. Например, если вы выбрали один из подходящих наборов keymap, но вас не устраивает один из компонентов, например geometry, то в файле конфигурации можно указать
Option "XkbKeymap" "xfree86(ru)" Option "XkbGeometry" "pc(pc104)"
При этом, в соответствии с первой инструкцией, все компоненты будут взяты из keymap "xfree86(ru)", а вторая инструкция "перепишет" geometry, не затрагивая остальные компоненты.
Третий способ несколько отличается от предыдущих. Набор настроек можно указывать не перечислением компонентов, а с помощью задания "правил" (Rules), "модели" (Model), "схемы" (Layout), "варианта" (Variant) и "опций" (Option).
В этом наборе только Rules представляют собой некий файл (эти файлы тоже находятся в отдельном подкаталоге rules каталога /usr/X11R6//lib/X11/xkb), в котором находится таблица правил - "как выбрать все пять компонентов настроек XKB в зависимости от значений Model, Layout и т. д.". Все остальные параметры представляют собой просто "ключевые слова":
Model обычно определяет тип "железа" - клавиатуры;Layout - язык или, точнее, алфавит, который "навешивается" на кнопки клавиатуры;Variant - различные варианты размещения знаков алфавита (заданных Layout'ом);Options - обычно меняет "поведение" или "расположение" модификаторов Control и Group (переключатель групп - это переключатель "языка", например, русский/латинский).
По этим словам модуль XKB при старте ищет в таблицах "правил" подходящие файлы настроек (keycodes, types, compat, symbols и geometry). Другими словами, Rules определяет некоторую функцию, аргументами которой являются Model, Layout, Variant и Options, а значение, которое возвращает эта функция, представляет собой полный набор из компонентов настроек XKB - keycodes, types, compat, symbols и geometry (или полная keymap).
Итак, если вы используете третий способ указания конфигурации XKB, то в файле конфигурации X-сервера, надо задать параметры XkbRules, XkbModel, XkbLayout и, если вам нужно что-то не совсем стандартное - XkbVariant и XkbOptions.
Например,
Option "XkbRules" "xfree86" Option "XkbModel" "pc104" Option "XkbLayout" "ru" Option "XkbVariant" "" Option "XkbOptions" "ctrl:ctrl_ac"
означает, что модуль XKB должен в соответствии с правилами, описанными в файле ./rules/xfree86, выбрать настройки для клавиатуры типа "pc104" (104 кнопки), русского алфавита (английский алфавит будет включен "по умолчанию"), вариант - "стандартный" (т. е., этот параметр можно было не писать) и, наконец, дополнительные опции для вашей "раскладки клавиатуры" - "ctrl:ctrl_ac".
Что означают различные опции, а также какие "модели" и "схемы" определены в "правилах" (и что они означают), можно посмотреть в файле xfree86.lst (или другом файле *.lst, если вы выбрали "правила", отличные от xfree86), который находится в той же директории, что и файл "правил", т. е. в подкаталоге rules.
Небольшое отступление о клавише - переключателе "рус/лат". В первых вариантах модуля XKB раскладка "русской" клавиатуры включала в себя и "переключатель групп" - рус/лат, "подвешенный" на клавишу CapsLock. С одной стороны это было удобно: в простейшем случае достаточно было выбрать "русскую раскладку" и вы автоматически получали и клавишу для переключения "на русский". Но, с другой стороны, это было неудобно для тех, кто предпочитает в качестве переключателя рус/лат другую клавишу (или комбинацию клавиш). Конечно, выбрать другой переключатель не составляло труда, но при этом оставался и переключатель на CapsLock, что многим не нравилось. Для того, чтобы убрать его, надо было "залезть" в соответствующий файл и вручную подправлять соответствующую раскладку.
В конце концов (начиная с версии 3.3.4) сами разработчики Xfree86 убрали этот "переключатель" из "русской раскладки". Но, в связи с этим появились и некоторые проблемы - теперь клавишу-переключатель надо явно "заказывать" при конфигурировании XKB.
Мышь
Существуют два основных типа мышей - подключаемые через последовательный порт (serial mice) и подключаемые к шине (bus mice). Большинство компьютеров оборудуются в настоящее время мышами второго типа. Дальнейший текст относится к bus-мышам и основан на Busmouse HOWTO Криса Багвелла (Chris Bagwell), версии 1.91 от 15 июня 1998 г.
Настройка lpd с помощью программы printconf-gui
Настройка системы LPD состоит в том, что обеспечивается возможность создавать очереди файлов и отправлять задания из этих очередей на принтер. Такую настройку можно произвести вручную, и я надеюсь, что приведенное выше описание позволяет это сделать. Однако в большинстве дистрибутивов имеются специальные утилиты, облегчающие конфигурацию подсистемы печати. В дистрибутиве Red Hat версии 6 такая утилита называлась printtoool, а в версии 7.1 вместо printtool включена утилита printconf-gui, которую можно вызвать из меню оболочки KDE. Эта утилита поддерживает ведение конфигурационного файла /etc/printcap, создание областей спулинга и выбор фильтров. Если в файле /etc/printcap не имеется ни одной записи о принтерах, то главное окно программы printconf-gui выглядит так, как показано на рис. 9.2.
увеличить изображение
Рис. 9.2. Основное окно printconf-gui
Мы рассмотрим только случай подключения локального принтера, а остальные варианты вы можете изучить с помощью имеющейся в программе подсказки (экранная кнопка Справка).
После выбора типа принтера и указания имени устройства щелкните по строке Printer Driver в левой колонке, и вы увидите список известных программе драйверов, упорядоченный по фирмам-производителям (рис. 9.5):
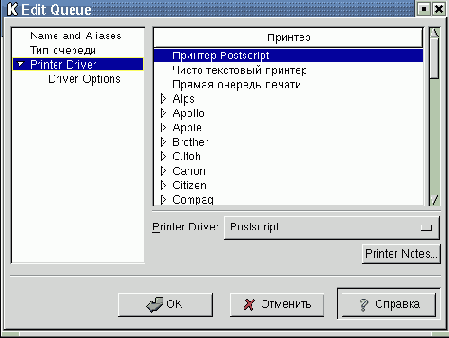
Рис. 9.5. Выбор драйвера
Если щелкнуть по треугольному значку слева от имени фирмы, раскроется список драйверов для принтеров данного производителя. На рис. 9.6 видна часть списка принтеров, производимых фирмой Hewlett Packard.
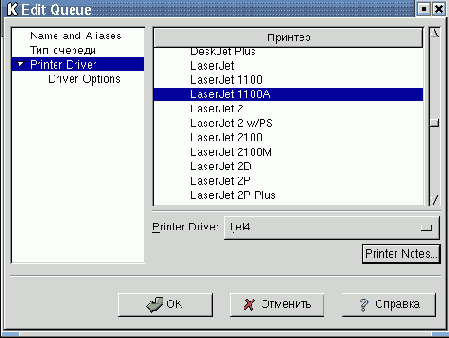
Рис. 9.6. Принтеры фирмы Hewlett Packard
Щелчок по кнопке с надписью Printer Notes: приводит к появлению окна с краткой информацией о выбранном принтере (рис. 9.7).
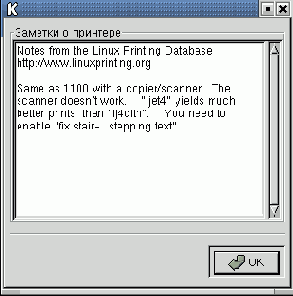
Рис. 9.7. Заметки о принтере
Ну, и последнее окно в этом ряду (рис. 9.8) позволяет задать некоторые параметры для выбранного принтера: режим печати (нормальный, экономичный, высокое качество), разрешение печати, размер бумаги, и т. п.

Рис. 9.8. Задание параметров печати
Завершив ввод, нажмите кнопку OK. После этого введенные вами данные будут сохранены в базе данных в файле /etc/printcap.
Команда Правка основного меню программы позволяет таким же способом отредактировать установки для принтера, который уже был описан ранее.
После того, как вы добавили в базу данных новый принтер или отредактировали установки ранее заведенного, обязательно необходимо перезапустить демон lpd. Для этого можно воспользоваться кнопкой Применить в основном окне программы.
Теперь можно попытаться распечатать пробную страничку, воспользовавшись командой Тест главного меню программы. Вам будет предложено 3 варианта тестовой страницы: Print PostScript Test Page, Print A4 PostScript Test Page, или Print ASCII Test Page. Скорее всего, тестовая страница у вас распечатается без проблем. Но если вы попробуете распечатать страницу текста из какого-либо приложения, тем более, если используются разные шрифты, да еще с кириллицей, то результат, к сожалению, может оказаться не таким радующим. Дело в том, что мы пока настроили только "нижний" слой подсистемы печати, обеспечивающий передачу потока байт от ядра ОС в параллельный порт или на сетевой принтер. Но проблема управления самим принтером (а не параллельным портом) пока не решена. В системе LPD эта проблема решается с помощью фильтров.
Настройка мыши
Далее необходимо проверить настройки в некоторых конфигурационных файлах. Вначале убедитесь, что существует файл /etc/sysconfig/mouse, и что в нем записано что-то вроде:
MOUSETYPE="Microsoft" XMOUSETYPE="Microsoft" XEMU3=yes
Естественно, что тип мыши должен соответствовать вашей мыши, у меня, например, это "PS/2".
Чтобы вырезать и вставлять куски текста в консоли, должен быть установлен сервер мыши gpm.
Проверьте, что сервер мыши gpm запущен, для чего дайте команду:
[user]$ ps -A | grep gpm
Если в результате вы получите непустую строку, то драйвер работает. Если же процесс gpm не найден, надо проверить наличие скрипта /etc/rc.d/init.d/gpm, в котором должна найтись строка вызова демона gpm. Эта строка может иметь примерно такой вид:
daemon gpm -t $MOUSETYPE -d 2 -a 5 -B 132 # two-button mouse
(смысл параметров см. на странице man gpm).
Если сервер gpm работает, то выделять и вставлять куски текста можно следующим образом. Нажмите левую кнопку и выделяйте текст. Когда дойдете до конца нужного куска текста, отпустите кнопку. Потом нажмите правую кнопку в том месте, где вы хотите осуществить вставку. Можно даже в другой виртуальной консоли. То же самое можно проделать в X Window, но для вставки нужно нажимать среднюю клавишу, или обе, если у вас двухкнопочная мышь.
Несколько практических рекомендаций по настройке модуля XKB
Самый простой способ - использовать программу для автоматической настройки X-Window. В XFree86 версии 3 такая программа называется XF86Setup. Она использует третий метод задания конфигурации XKB. При этом "по умолчанию" используются "правила" (XkbRules) - xfree86. Вам нужно будет только выбрать "модель" (XkbModel), "схему" (XkbLayout) и "способ переключения групп" (переключатель "РУС/ЛАТ").
Кроме того, при желании вы можете изменить "положение клавиши Ctrl". Естественно, в конфигурации это будет выглядеть как соответствующие строчки XkbOptions. Итак, запустите программу XF86Setup, выберите раздел Keyboard. В этом разделе выберите из меню Model (тип клавиатуры) и Layout (язык). Не забудьте отметить в отдельных списках (в правой части) подходящий "переключатель групп" и, если хотите - "расположение Ctrl". При выходе из программы она запишет соответствующие строчки в файл конфигурации Xfree86 в секции Keyboard.
А теперь рассмотрим то, как можно задать эти настройки путем прямого редактирования секции InputDevice (Keyboard) файла /etc/X11/XF86Config.
Прежде всего, надо сказать, что "ключевыми словами" в этих настройках будут:
xfree86 - название "архитектуры" X-Window;pc101 (pc104, pc105 и т.п.) - тип клавиатуры (количество кнопок);ru - название "раскладки клавиатуры" с русским алфавитом.
Проще всего сразу задать конфигурацию клавиатуры с помощью keymap. В файлах конфигурации есть набор "полных keymap'ов" для архитектуры xfree86, отличающихся "языком". Все они лежат в файле xfree86, а название блока внутри файла отражает название "языка" (точнее - алфавита) - xfree86(us), xfree86(fr), xfree86(ru) и т. д. Полный список keymap-файлов можно посмотреть в файле /usr/X11R6//lib/X11/xkb/keymap.dir.
Для "русифицированной" клавиатуры вполне подойдет
Option "XkbKeymap" "xfree86(ru)"
К сожалению, после исключения CapsLock как переключателя рус/лат из русской раскладки (см. замечание в конце предыдущего раздела) получилось так, что "полная keymap" для русского языка осталась вообще без какого-либо переключателя "по умолчанию". Но вы можете добавить его вручную. Для этого придется найти в файле /keymap/xfree86 блок "ru". И дописать в строчку xkb_symbols ссылку на описание соответствующего переключателя групп. Для CapsLock это будет - group(caps_toggle). То есть, строчка xkb_symbols будет выглядеть как
xkb_symbols { include "en_US(pc105)+ru+group(caps_toggle)"};
Полный список возможных переключателей групп (т. е. возможных переключателей "рус/лат") можно найти в файле /usr/X11R6//lib/X11/xkb/symbols/group (проведите в этом файле поиск по ключевому слову xkb_symbols).
Теперь рассмотрим случай, когда для задания конфигурации клавиатуры используется третий способ - через "правила", "модель", "схему" и т. д. Как было сказано выше:
название "правил" (rules) соответствует "архитектуре" (xfree86);"модель" (model) соответствует типу клавиатуры (pc101, pc102 и т.п.);"схема" (layout) отражает "язык" (ru).
Поэтому, подходящая конфигурация будет выглядеть примерно так:
Option "XkbRules" "xfree86" Option "XkbModel" "pc104" Option "XkbLayout" "ru"
С помощью строки XkbOptions можно подобрать "поведение" управляющих клавиш. Возможные значения XkbOptions и их смысл можно подсмотреть в файле /rules/xfree86.lst в той части, которая начинается строкой "! option".
Не забудьте, что, как и в предыдущем случае, надо явно выбрать переключатель групп. Для CapsLock это будет
Option "XkbOptions" "grp:caps_toggle"
И, наконец, рассмотрим первый способ - описание отдельных компонентов настройки (keycodes, compat, types, symbols, geometry).
Если вы не знаете с чего начать, подсмотрите соответствующий набор в keymap. Или попробуйте "вычислить" его через rules/model/layout. Чаще всего подойдут следующие значения:
для keycodes выбрать файл xfree86;для types и compat подойдут файлы default ("по умолчанию") или complete ("полная");geometry, скорее всего, "pc", а количество кнопок задается названием блока в файле pc - pc(pc101), pc(pc102), pc(pc104). Полный список "геометрий" имеется в файле /usr/X11R6/lib/X11/xkb/geometry.dir.
А вот на symbols обратите особое внимание. Файл symbols/ru описывает только "буквенные" клавиши. Если вы укажете только его, то у вас не будут работать все остальные кнопки (включая Enter, Shift/Ctrl/Alt, F1-F12 и т. д.). Поэтому symbols должен состоять по крайней мере из двух файлов - en_US(pc101) (в скобках - тип клавиатуры) и, собственно, ru. Полный список symbols - в файле /usr/X11R6/lib/X11/xkb/symbols.dir.
Сюда же надо добавить и описание подходящего "переключателя рус/лат" (как уже говорилось, их перечень - в файле symbols/group).
Для первого метода список может выглядеть так
Options "XkbKeycodes" "xfree86" Options "XkbTypes" "complete" Options "XkbCompat" "complete" Options "XkbSymbols" "en_US(pc101)+ru+group(alt_shift_toggle)" Options "XkbGeometry" "pc(pc101)"
Если вам хочется задать дополнительные изменения "поведения" управляющих клавиш (то, что в третьем методе задается XkbOptions), то подсмотрите подходящую "добавку" в rules/xfree86.lst и "приплюсуйте" ее в строчку XkbSymbols. Например,
XkbSymbols "en_US(pc101)+ru+group(shift_toggle)+ctrl(ctrl_ac)"
На этом мы ограничим описание методов настройки клавиатуры, а точнее - настройки модуля XKB. Если вы хотите разобраться с этим детальнее, то обратитесь к исходному материалу И. Паскаля http://www.mgul.ac.ru/~t-alex/Linux/X-Keyboard/index.htm.
Нумерация
Сначала приведем дополнительные сведения о нумерации жестких дисков в системе Linux (табл. 9.3).
| IDE на 1 контроллере | 22 | /dev/hda и /dev/hdb | 0 : 63 | 64 : 127 |
| IDE на 2 контроллере | 33 | /dev/hdc и /dev/hdd | 0 : 63 | 64 : 127 |
| SCSI | 8 | /dev/sd | 0 : 15 | 16 : 31 |
Первые жесткие диски на обоих IDE-контроллерах получают младшие номера 0, а вторые диски - номера 64 (и имена /dev/hda и /dev/hdb). По этим номерам происходит обращение ко всему диску в целом, независимо от количества разделов на этом диске. Разделы на дисках получают, соответственно, следующие по порядку номера: первый раздел на первом диске - номер 1 и имя /dev/hda1, второй раздел - номер 2 и имя /dev/hda2 и так далее.
Более двух дисков на IDE-контроллере не бывает, и более двух контроллеров на персональные компьютеры обычно не ставят, так что всего бывает не более 4 IDE-дисков (/dev/hd[a-d]).
Аналогично, целые SCSI-диски получают младшие номера 0, 16, 32 и так далее, и имена /dev/sd[a-g]. Разделы на этих дисках получают младшие номера, следующие по порядку за младшим номером всего диска: первый раздел на диске /dev/sda получает младший номер 1 (и имя /dev/sda1), первый раздел на диске /dev/sdb получает младший номер 17 (и имя /dev/sdb1), и так далее.
Определение типа мыши
Вы должны знать две важных характеристики своей мыши: какой у нее интерфейс и какой она использует протокол.
Интерфейс - это совокупность аппаратных параметров мыши, включающая такие параметры, как используемые мышью прерывания, порты ввода-вывода и количество контактов в разъеме. Ядро Linux поддерживает 4 типа интерфейсов bus-мыши: Inport (Microsoft), Logitech, PS/2 и ATI-XL. Не существует однозначного алгоритма определения типа интерфейса мыши.
Мыши типа Inport обычно подключаются к интерфейсной карте на материнской плате. Если разъем, который подключается к интерфейсной карте, круглый, имеет 9 контактов и желобок (направляющую выемку) с одной стороны, то вполне возможно, что у вас мышь типа Inport. Если только не Logitech, поскольку эти мыши внешне имеют те же характеристики. Различить их можно только если у вас сохранилась упаковка или руководство, в котором указан тип мыши.
Мыши типа PS/2 подключаются не к плате расширения, а к специальному разъему (PS/2 Auxiliary Device port) на контроллере клавиатуры. Этот разъем имеет 6-контактов (6-pin mini DIN connector), и похож на разъем для подключения клавиатуры.
Мыши типа ATI-XL - это вариант мышей типа Inport. Они подключаются к комбинированной карте, являющейся видео-адаптером и контроллером мыши. Если только вы не знаете точно, что у вас видеоадаптер ATI-XL (и следовательно мышь ATI-XL), то, скорее всего, у вас мышь другого типа.
Протокол - это чисто программная характеристика мыши. Большинство мышей Inport, Logitech и ATI-XL используют протокол "BusMouse", а мыши типа PS/2 используют протокол "PS/2".
Печать на удаленный принтер
Если ваш компьютер подключен к локальной сети, то не обязательно иметь принтер, непосредственно к нему подключенный, можно пользоваться принтером, подключенным к какому-то другому компьютеру. Настройка такого принтера на вашем компьютере требует только указания того, к какому компьютеру в сети подключен принтер (это делается с помощью задания переменных rm и rp в файле /etc/printcap, о чем было сказано выше). Если использовать утилиту printconf-gui, то достаточно при выборе типа очереди (см. рис. 9.4) выбрать вариант "UNIX printer (lpd Queue)", если это другой Linux-компьютер. Если принтер подключен к Windows-компьютеру или отдан в сеть через Samba-сервер, то, естественно, надо выбирать тип очереди "Принтер Windows (ресурс Samba)".
На удаленном компьютере должен быть разрешен доступ к этому принтеру. В Linux это делается с помощью файла /etc/lpd.perms (см. соответствующую страницу руководства man).
PostScript и Ghostscript
К сожалению пользователей, фирмы-производители принтеров долгое время не могли достигнуть согласия в вопросе о выборе управляющих сигналов для производимых ими устройств. В результате для каждого принтера до сих пор необходим особый драйвер. Однако со времен так называемой "революции настольных издательских систем" 80-х годов в качестве в качестве стандартного языка управления принтером постепенно утвердился язык PostScript, разработанный фирмой Adobe Systems, Inc. И не только в UNIX-среде, а в издательском деле вообще.
Этот язык представляет собой специальный язык программирования для описания выводимой на печать страницы с текстом или графикой. Adobe Systems, Inc., изначально разработавшая стандарт на PostScript, открыла его для свободного распространения. Отметим еще, что формат PDF (Формат Переносимого Документа Adobe) - это в действительности чуть больше чем несколько преобразованный PostScript в сжатом файле.
Идея, заложенная в основу разработки PostScript, проста: все, что можно напечатать, описывается с помощью специального языка программирования, принтер же должен этот язык понимать. И принтеры, "понимающие" язык PostScript, т. е. имеющие встроенный PostScript-интерпретатор (так называемые PostScript-принтеры), быстро появились. К сожалению, они оказались стабильно дороже обычных принтеров. Тогда были разработаны программные PostScript-интерпретаторы, которые берут данные в формате PostScript и преобразуют в специфический для данного принтера управляющий код. Это дает вам виртуальный PostScript-принтер и позволяет использовать принтеры, не имеющие аппаратного интерпретатора.
Вероятно, одним из лучших программных интерпретаторов языка PostScript является Ghostscript (http://www.cs.wisc.edu/~ghost/), или просто gs. Он существует в двух вариантах. Коммерческая версия Ghostscript, называемая Aladdin Ghostscript или AFPL Ghostscript, свободна для персонального использования, но не может распространяться с коммерческими дистрибутивами Linux. В составе последних доступен GNU Ghostscript, представляющий собой тот же gs, только версией ниже и с другим лицензионным соглашением. На сегодняшний день можно загрузить версию AFPL Ghostscript 7.0, тогда как версия GNU Ghostscript - 5.5. В составе Ghostscript имеется внушительный набор фильтров - аппаратно ориентированных модулей, позволяющих получать изображение на различных устройствах. Устройствах, а не принтерах, поскольку Ghostscript может обеспечить вывод на любое графическое устройство. Именно gs присутствует в качестве фильтра в /etc/printcap - конфигурационном файле lpd. Опции запуска gs в качестве фильтра определяются типом принтера.
Работа с клавиатурой в графическом режиме
В графическом режиме работа с клавиатурой организована значительно сложнее. Подробное описание этого вопроса можно найти в обстоятельном (но, к сожалению, очень трудном для понимания) материале Ивана Паскаля "X Keyboard Extension"http://www.mgul.ac.ru/~t-alex/Linux/X-Keyboard/index.htm. Приведем очень краткий конспект основных положений этого материала.
Как было сказано выше, при работе в системе X Window клавиатура передает этой системе чистые скан-коды. Клавиатурный модуль X-сервера передает сообщение о нажатии (и отпускании) кнопки прикладной программе. В этом сообщении указывается только скан-код нажатой кнопки и "состояние клавиатуры" - набор битовых "флагов", который отражает состояние клавиш-модификаторов (<Shift>, <Control>, <Alt>, <CapsLock> и т.п.). "Клиентская" программа должна сама решить - какой код символа, соответствующий скан-коду, надо выбрать при таком сочетании битов-модификаторов. Разумеется, при создании программ никто не пишет каждый раз программу для интерпретации скан-кодов. Для этих целей существуют специальные подпрограммы в библиотеке X-lib. Процедуры из X-lib, зная скан-код и "состояние клавиатуры", выбирают подходящий символ в соответствии с таблицей символов, которая хранится в X-сервере и которую они обычно "запрашивают" у X-сервера при старте программы. Эта таблицу можно менять с помощью утилиты xmodmap. Действующая таблица выводится командой xmodmap -pk.
Шрифты для Ghostscript
Для пакета Ghostscript разработаны PostScript-шрифты, которые обеспечивают высокое качество печати на не-PostScript принтерах. Такие шрифты наверняка найдутся на вашем дистрибутивном диске в виде пакета ghostscript-fonts. Однако именно со шрифтами и связано большинство проблем, которые возникают при настройке принтера.
Дело в том, что программе Ghostscript надо точно знать, где расположены шрифты для нее. Но поскольку стандарт FHS (Filesystem Hierarhy Standard), о поддержке которого заявили все составители дистрибутивов, пока еще не утвердился окончательно, структура каталогов в Linux меняется от версии к версии даже в пределах одного дистрибутива. Поэтому файлы шрифтов могут оказаться где угодно. Очень часто - не там, где их будет искать Ghostscript. В результате при попытке распечатать какой-либо документ вы можете получить далеко не то, что ожидали: от несоответствия внешнего вида распечатанного документа вашему замыслу до искажения или отсутствия фрагментов текста, требующего, в соответствии с PostScript-файлом, того самого шрифта, который не смог загрузить Ghostscript. Положение усугубляется тем, что, по крайней мере, часть документов включает кириллицу, а некоторые дистрибутивы не имеют в каталогах, сканируемых по умолчанию Ghostscript, шрифтов с кириллицей.
Преодолеть эти трудности в принципе не сложно. Но, прежде чем рассказать, как это сделать, надо сказать, что в Linux имеется программа ghostview (gv), назначение которой - принять вывод ghostscript и вывести изображение на экран. Это дает инструмент, обеспечивающий возможность предварительного просмотра ("print preview") для любого приложения, генерирующего PostScript-файлы. С помощью gv вы сможете определить, связаны ли ваши проблемы с выбором типа принтера или c работой gs в целом. Видите на экране, но не получаете на печати - попробуйте другой фильтр (выберите другой принтер), не видите ничего "путного" - продолжаем разбираться с настройкой ghostscript.
Теперь надо отметить, что программу Ghostscript можно запускать не только в качестве фильтра для LPD, но и из командной строки (для этого надо дать команду gs). Этой возможностью и воспользуемся для целей отладки.
Сначала запустите команду gs с опцией -help. В результате вы получите, во-первых, краткий информативный список опций и доступных драйверов (заметим, что этот список является списком только вкомпилированных, а не всех доступных драйверов), и, во-вторых, перечень путей поиска. Этот список можно, конечно, изменить, но для этого надо перекомпилировать программу. Если же вы не хотите заниматься компиляцией, надо поместить файлы шрифтов именно в эти каталоги.
Но этого еще недостаточно для того, чтобы Ghostscript могла использовать шрифты. Дело в том, что эта программа обращается к шрифтам по именам, записываемым в той нотации, в которой допускается их использование в PostScript-файлах. Соответствие между такими названиями шрифтов и именами реальных файлов шрифтов задается файлом Fontmap (или Fontmap.GS), который располагается в каталоге /usr/share/ghostscript/N.NN, где N.NN - номер версии программы ghostscript (на данный момент - 5.50). Каждая строка (кроме строк комментариев) этого файла состоит из трех элементов.
Первым стоит имя, под которым шрифт будет известен программе Ghostscript, причем перед этим именем должен стоять слэш (/), либо имя должно быть заключено в круглые скобки;Далее следует имя файла шрифта либо синоним (aliace) имени шрифта. Если указывается имя файла шрифта, то оно должно быть заключено в круглые скобки и записано с указанием расширения (обычно это gsf, но допускаются также pfa и pfb), а также должно соответствовать правилам формирования имен файлов в MS-DOS, т. е. состоять из букв (в нижнем регистре), цифр и знаков подчеркивания. Если же это синоним, то указывается имя одного из уже известных программе Ghostscript шрифтов, причем перед этим именем должен стоять слэш (/).Завершает строку точка с запятой, перед которой должен стоять, по крайней мере, один пробел или знак табуляции.
Пути к файлам шрифтов в файле Fontmap не указаны. Если вы не использовали предлагаемые руководством средства принудительной "ориентации" ghostscript (параметры командной строки и переменные окружения), то gs будет использовать "пути по умолчанию", заданные при компиляции. В этих каталогах должны иметься файлы fonts.dir, которые содержат описание фонтов в данном каталоге (подробнее о файлах fonts.dir вы можете прочитать в лекции 11).
Таким образом, в зависимости от потребностей вы можете либо внести в Fontmap необходимый шрифт (предварительно поместив соответствующий файл в один из доступных программе каталогов и указав имя файла в добавляемой строке), либо назначить в качестве синонима нужного шрифта имя одного из уже известных программе шрифтов. Например, сделать шрифт /Courier синонимом изначально известного программе шрифта /NimbusMonL-Regu (которому, в свою очередь соответствует файл (n022024l.pfb)). Если задача - в основном печатать файлы, PostScript-содержимое которых вне вашего контроля, - подберите синонимы для нужных шрифтов из числа известных программе. Если PostScript-файл генерируется под вашим контролем - просто выбирайте один из имеющихся в системе шрифтов. Разумеется, не забыв при этом описать его в Fontmap.
После этого выполните команду
[user]$ gv filename.ps
Если вы при этом увидите на экране весь текст из файла filename.ps, вы можете попытаться отпечатать файл и на принтере. Если же вместо текста увидите пустой лист или шрифт вам не нравится, продолжайте экспериментировать с настройкой шрифтов. Но предварительно прочитайте статью В. Попова http://www.softerra.ru/review/oses/linux/11295/, которая послужила основой для моего рассказа о шрифтах для Ghostscript, и в которой вы найдете несколько дополнительных подсказок. Кроме того, в Интернете имеются два очень полезных ресурса http://www.linuxprinting.org/ и http://www.geocities.com/SiliconValley/5682/postscript.html, куда будет не вредно заглянуть.
Создание собственной раскладки
Если вас не устраивает ни одна из тех раскладок клавиатуры, которые имеются в каталоге /usr/lib/kbd/keytables/i386/qwerty/, можете попробовать подправить ту раскладку, которая ближе всего к вашему идеалу. Попробуем показать, как это делается, на примере выбора клавиши переключения между русской и латинской клавиатурой (этот совет позаимствован у Романа Минакова, pharao@kma.mk.ua).
Для переключения между русской и латинской клавиатурой часто используется правая клавиша <Ctrl>, в то время как на любой более-менее современной IBM-клавиатуре есть три клавиши, которые, как правило, в Linux не задействованы. Вот одну из них и приспособим для переключения алфавитов. Для начала надо узнать какой у них код. Запускаем команду showkey с опцией --keycodes (запуск showkey, естественно, производится с консоли и необходимо предварительно выйти из mc) и последовательно (слева направо) нажимаем эти три клавиши, чтобы узнать их коды:
[root]# showkey --keycodes kb mode was XLATE press any key (program terminates after 10s of last keypress)... keycode 125 press keycode 125 release keycode 126 press keycode 126 release keycode 127 press keycode 127 release
Числа 125, 126, 127 и есть коды этих клавиш. Далее переходим в каталог /usr/lib/kbd/keytables/i386/qwerty, находим файл, который используется в данный момент (что-то типа ru1.map, если в каталоге /usr/lib/kbd/keytables/i386/qwerty вы найдете только ru1.map.gz, то выполните предварительно разархивацию: gunzip ru1.map.gz).
Для того, чтобы заставить клавишу работать как временный переключатель с русского на латинский (пока клавиша удерживается), надо придать ей значение AltGr, а чтобы она использовалась как постоянный переключатель - AltGr_Lock. Находим внутри ru1.map:
keycode 125 = keycode 126 = keycode 127 =
и меняем на:
keycode 125 = keycode 126 = AltGr keycode 127 = AltGr_Lock
Далее надо изменить установки тех клавиш, которые ранее использовались для переключения. Например, если в качестве постоянного переключателя использовалась клавиша <Ctrl> (код клавиши 97), находим строку
keycode 97 =
и вписываем:
keycode 97 = Control
В итоге получаем: клавиша, расположенная возле правой клавиши <Ctrl>, - фиксированный переключатель "рус/лат", а та что рядом с правой клавишей <Alt> - временный переключатель "рус/лат" (т. е. действующий только на то время, пока удерживается в нажатом положении соответствующая клавиша).
После редактирования сохраняем файл под новым именем (например, mymap.kmap) и записываем это имя в /etc/sysconfig/keyboard.
Специальные файлы устройств
Однако, в отличие от обычных файлов, специальные файлы устройств в действительности есть только указатели на соответствующие драйверы устройств в ядре. По сравнению с обычными файлами файлы устройств имеют три дополнительных атрибута, которые характеризуют устройство, соответствующее данному файлу:
Класс устройства. В ОС Linux различают устройства блок-ориентированные и байт-ориентированные. Блок-ориентированные (или блочные) устройства, например, жесткий диск, передают данные блоками. Байт-ориентированные (или символьные) устройства, например, принтер и модем, передают данные посимвольно, как непрерывный поток байтов. Взаимодействие с блочными устройствами может осуществляться лишь через буферную память, а для символьных устройств буфер не требуется. Кроме этих двух классов устройств имеются еще два - небуферизованные байт-ориентированные устройства и именованные каналы (FIFO).Старший номер устройства, обозначающий тип устройства, например, жесткий диск или звуковая плата. Текущий список старших номеров устройств можно найти в файле /usr/include/linux/major.h. Вот небольшая выдержка из этого списка
| 1 | Оперативная память |
| 2 | Дисковод гибких дисков |
| 3 | Первый контроллер для жестких IDE-дисков |
| 4 | Терминалы |
| 5 | Терминалы |
| 6 | Принтер (параллельный разъем) |
| 8 | Жесткие SCSI-диски |
| 14 | Звуковые карты |
| 22 | Второй контроллер для жестких IDE-дисков |
Файлы устройств одного типа имеют одинаковые имена и различаются по номеру, прибавляемому к имени. Например, все файлы сетевых плат Ethernet имеют имена, начинающиеся на eth: eth0, eth1 и т. д.
Младший номер устройства применяется для нумерации устройств одного типа, т. е. устройств с одинаковыми старшими номерами.
Если вы заглянете в каталог /dev и выполните команду ls -l, вы увидите, что эта команда вместо размера файла в байтах, как для обычного файла, выводит два числа, разделенных запятой. Это и есть старший и младший номера данного устройства. Эти номера задаются в соответствии с таблицей устройств, определенной разработчиками ядра.
Старшие номера известных ядру устройств можно увидеть, выполнив команду
[user]$ cat /proc/devices
Если вы решили подключить к системе какое- то новое устройство, необходимо вначале проверить, что в каталоге /dev имеется специальный файл (или ссылка на специальный файл) для этого устройства. Специальные файлы устройств создаются с помощью команды mknod (но, естественно, использовать команду mknod без необходимости и полного понимания последствий не стоит). Эта команда имеет следующий формат:
mknod [опции] имя_устройства тип_устройства старший_номер младший_номер
где тип_устройства может принимать одно из четырех значений:
b - блок-ориентированное устройство;c - байт-ориентированное (символьное) устройство;u - небуферизованное байт-ориентированное устройство;p - именованный канал.
Для блок-ориентированных и байт-ориентированных устройств (b, c, u) нужны и старший и младший номера, для именованных каналов номера не используются. В следующем примере создается специальный файл для терминала, подключенного к порту COM3, который в Linux обозначается как /dev/ttyS2:
[root]# mknod -m 660 /dev/ttyS2 c 4 66
(устройства-терминалы представляют собой байт-ориентированные устройства со старшим номером 4 и младшими номерами, которые начинаются с 64).
Но вот о чем стоит подумать, так это о том, как дать пользователям права, необходимые для доступа к устройствам. Эти права устанавливаются через атрибуты специальных файлов. Можно, например, дать всем пользователям полные права (chmod 666) на доступ к таким устройствам, как /dev/cdrom, /dev/floppy, /dev/modem и так далее. Можете поступить иначе, создав группу "cdrom", сделать /dev/cdrom принадлежащим группе cdrom, а потом добавлять пользователей в эту группу по мере необходимости. Аналогичную процедуру можно применить к другим устройствам.
Таблицы кодировки символов
В человеческом мире информация представляется последовательностями символов. Каждый символ имеет каноническое изображение, которое позволяет однозначно идентифицировать данный символ. Шрифты задают разные варианты начертания символов.
В вычислительных машинах для представления информации используются цепочки байтов. Поэтому для перевода информации из машинного представления в человеческий необходимы таблицы кодировки символов - таблицы соответствия между символами определенного языка и кодами символов.
Самой известной таблицей кодировки является код ASCII (Американский стандартный код для обмена информацией), который был разработан для передачи текстов по телеграфу задолго до появления компьютеров. Этот код является 7 битовым, т. е. для кодирования символов английского языка, служебных и управляющих символов используются только 128 7-битовых комбинаций. При этом первые 32 комбинации (кода) служат для кодирования управляющих сигналов (начало текста, конец строки, перевод каретки, звонок, конец текста и т. д.).
При разработке первых компьютеров фирмы IBM этот код был использован для представления символов в компьютере. Поскольку в исходном коде ASCII было всего 128 символов, для их кодирования хватило тех однобайтовых кодов, у которых 8-й бит равен 0. Во второй половине кодовой таблицы (значения байта с 8-м битом равным 1) фирма IBM разместила символы псевдографики, математические знаки и некоторые символы из языков, отличных от английского (немецкие умляуты, французские диакритические знаки, символы греческого алфавита и т.п.). Эту кодовую таблицу стали называть кодировкой IBM.
Когда IBM-совместимые персональные компьютеры стали использовать в других странах, потребовалось обеспечить обработку информации на языках, отличных от английского. Для того, чтобы полноценно поддерживать другие языки, фирма IBM ввела в употребление несколько кодовых таблиц, ориентированных на конкретные страны. Так для скандинавских стран была предложена таблица 865 (Nordic), для арабских стран - таблица 864 (Arabic), для Израиля - таблица 862 (Israel) и так далее. В этих таблицах часть кодов из второй половины кодовой таблицы использовалась для представления символов национальных алфавитов (за счет исключения некоторых символов псевдографики). Для представления символов кириллицы была введена кодировка IBM-866.
Однако с русским языком ситуация развивалась особым образом. Очевидно, что замену символов во второй половине кодовой таблицы можно произвести разными способами. В других европейских странах сумели найти единое решение, а для русского языка появилось несколько разных таблиц кодировки символов кириллицы: IBM-866, CP-1251, KOI8-R, ISO-8859-5. Все они одинаково изображают символы первой половины таблицы (от 0 до 127) и различаются представлением символов русского алфавита и псевдографики во второй половине.
Одна из самых известных кодовых таблиц для кириллицы получила название альтернативной (по отношению к кодировке IBM-866, наверное). Она была разработана фирмой Microsoft для MS-DOS. При ее разработке постарались сделать так, чтобы результирующая таблица была насколько это возможно совместима с кодировкой IBM. Поэтому альтернативная кодировка - это кодировка IBM, в которой все специфические европейские символы в верхней половине были заменены на кириллицу, оставляя псевдографические символы нетронутыми. Следовательно, это не портило вид программ, использующих для работы текстовые окна, что было очень существенным фактором для работы в среде MS-DOS, основой которой был именно текстовый режим.
Кодировка KOI-8 была разработана изначально с ориентировкой на UNIX. Так как UNIX в своей основе сетевая ОС, то основной идеей при создании KOI-8 была идея об обеспечении перемещения кириллической информации по сети. Но для передачи-то использовался 7-битный стандарт ASCII. Разработчики поместили кириллические символы в верхней части таблицы таким образом, что позиции кириллических символов соответствуют их фонетическим аналогам в английском алфавите в нижней части таблицы. Это означает, что, если в тексте, написанном в KOI-8, мы убираем восьмой бит каждого символа, то мы все еще имеем "читабельный" текст, хотя он и написан английскими символами! Не удивительно, что KOI8-R быстро стал фактически стандартом для кириллицы в Интернет, что и нашло отражение в RFC 1489 ("Registration of a Cyrillic Character Set"). Автором этого документа является Андрей А. Чернов, который проделал огромный объем работы, чтобы превратить KOI-8 в стандарт Интернет.
Международная организация по стандартизации (ISO) внесла свою лепту в создание различных кодировок кириллицы, когда ввела семейство стандартов, известных как ISO 8859-X. Это семейство есть совокупность 8-битных кодировок, где младшая половина каждой кодировки (символы с кодами 0-127) соответствует ASCII, а старшая половина определяет символы для различных языков. Например:
8859-0 - новый европейский стандарт (так называемый Latin 0);8859-1 - Европа, Латинская Америка (также известный как Latin 1);8859-2 - Восточная Европа;8859-5 - кириллица;8859-8 - идиш.
Фирма Microsoft еще больше запутала ситуацию с кодировками для русского языка, когда при разработке Windows ввела кодировку CP-1251.
Таблицы кодировок, содержащие 256 символов, стали называть расширенными кодами ASCII (потому что в основе любой из них лежит 128-символьный код ASCII), кодовыми страницами или английским термином character set (который часто сокращают до charset).
Но в мире есть языки, такие как китайский или японский, для которых 256 символов в принципе недостаточно. Кроме того, всегда существует проблема вывода или сохранения в одном файле одновременно текстов на разных языках (например, при цитировании). Поэтому была разработана универсальная кодовая таблица UNICODE, содержащая символы, применяемые в языках всех народов мира, а также различные служебные и вспомогательные символы (знаки препинания, математические и технические символы, стрелки, диакритические знаки и т. д.). Очевидно, что одного байта недостаточно для кодирования такого большого множества символов. Поэтому в UNICODE используются 16-битовые (2-байтовые) коды, что позволяет представить 65 536 символов. К настоящему времени задействовано около 49 000 кодов (последнее значительное изменение - введение символа валюты EURO в сентябре 1998 г.). Для совместимости с предыдущими кодировками первые 128 кодов совпадают со стандартом ASCII. На рис. 9.1 схематично представлено размещение символов разных языков в кодовом пространстве UNICODE.
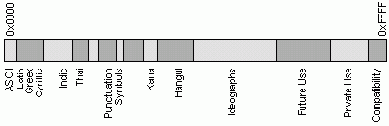
Рис. 9.1. Структура UNICODE
В стандарте UNICODE кроме определенного двоичного кода (эти коды принято обозначать буквой U, после которой следуют знак + и собственно код в шестнадцатеричном представлении) каждому символу присвоено определенное имя. В следующей таблице приведено несколько примеров кодов и имен символов из стандарта UNICODE.
| A | U+0041 | LATIN CAPITAL LETTER A |
| a | U+0061 | LATIN SMALL LETTER A |
| Ю | U+042E | CYRILLIC CAPITAL LETTER YU |
| + | U+002B | PLUS SIGN |
| 1 | U+0031 | DIGIT ONE |
| ? | U+03A9 | GREEK CAPITAL LETTER OMEGA |
| ? | U+2569 | BOX DRAWINGS DOUBLE UP AND HORIZONTAL |
Еще одним компонентом стандарта UNICODE являются алгоритмы для взаимно-однозначного преобразования кодов UNICODE в последовательности байтов переменной длины. Необходимость таких алгоритмов обусловлена тем, что не все приложения умеют работать с UNICODE. Некоторые приложения понимают только 7-битовые ASCII-коды, другие приложения - 8-битовые (расширенные) ASCII-коды. Для представления символов, не поместившихся, соответственно, в 128 символьный или 256 символьный набор, такие приложения используют цепочки байтов переменной длины. Алгоритм UTF-7 служит для обратимого преобразования кодов UNICODE в цепочки 7-битовых ASCII-кодов, а UTF-8 - для обратимого преобразования кодов UNICODE в цепочки из расширенных 8-битовых ASCII-кодов. Подробнее об алгоритмах UTF-7 и UTF-8 и кодировках вообще вы можете прочитать в [http://turnbull.sk.tsukuba.ac.jp/Tools/I18N/LJ-I18N.html - http://czyborra.com/charsets/].
Отметим, что и ASCII, и UNICODE, и другие стандарты кодировки символов не определяют изображения символов, а только состав набора символов и способ его представления в компьютере. Кроме того (что, может быть, не сразу очевидно) они еще задают порядок перечисления символов в наборе, который очень важен, так как он влияет самым существенным образом на алгоритмы сортировки. Именно таблицу соответствия символов из какого-то определенного набора (скажем, символов, применяемых для представления информации на английском языке, или на разных языках, как в случае с UNICODE) и обозначают термином таблица кодировки символов или charset. Каждая стандартная кодировка имеет имя, например, KOI8-R, ISO_8859-1, ASCII. К сожалению, стандарта на имена кодировок не существует.
Традиционные средства печати UNIX
Исторически для печати в UNIX-системах существовали две системы печати: LPD (Line Printer Daemon) [RFC1179], разработанная для Berkeley UNIX (или BSD-система), и AT&T Line Printer system. Эти системы печати были созданы в 70-х годах для печати текстов на построчно-печатающих (линейных) принтерах. Принимая во внимание, что аппаратные средства печати (проще говоря, принтеры) с тех пор существенно изменились, можно было бы предположить, что существенно переработаны и программные средства для управления печатью. Однако, этого не произошло. Хотя и были созданы различные улучшенные системы печати [LPRng, Palladin, PLP], однако ни одна из этих новых разработок не изменяла фундаментальные возможности этих систем. Впрочем, как показало время и практика, возможности этих систем вполне достаточны и при небольших доработках удовлетворяют и современные потребности.
Как и во всех UNIX-системах, в Linux файл, предназначенный для печати, вначале пересылается во временную область (проще говоря, временный каталог), которая называется областью спулинга. Дело в том, что принтеры являются относительно медленными устройствами, и система заботится о том, чтобы не задерживать работу на время распечатки файла. Фоновый процесс - демон печати - постоянно сканирует область спулинга в ожидании файлов, предназначенных для печати. Для каждого принтера, подключенного к системе, заводится своя область спулинга. Таким образом, область спулинга представляет собой очередь заданий на печать, дожидающихся того момента, когда освободится соответствующий принтер и демон печати отправит данное задание на печать (в фоновом режиме).
В основу подсистемы печати в Linux положена BSD-система - LPD, а точнее, доработанный вариант этой системы LPRng. LPRng состоит из отдельных программ, которые обеспечивают выполнение отдельных функций подсистемы печати.
lpd - демон системы печати. Обычно запускается на этапе загрузки системы из файла rc, но может быть запущен и пользователем.lpr - пользовательская команда печати. Программа lpr принимает подлежащие печати данные и помещает их в буферный каталог, где их находит lpd и выводит на печать. Программа lpr - единственная программа, которая может ставить новые задания в очередь печати. Другие программы, которым необходимо использовать печать, обращаются для этого к lpr.lpq - программа, позволяющая просматривать очередь заданий, ожидающих печати на указанном принтере.lpc - команда контроля системы lpd. С помощью lpc можно отключать принтеры, останавливать или переупорядочивать очереди печати и т.п. Некоторые из функций этой команды доступны пользователям, но в основном это средство для администратора.lprm - эта команда позволяет удалить одно или несколько заданий из очереди печати. При этом стираются соответствующие файлы данных и из системы печати удаляются все ссылки на них.
Взаимодействие lpr и других программ этого набора с демоном lpd осуществляется с использованием сетевых средств, так что они могут запускаться и на других компьютерах. Рассмотрим вкратце, как осуществляется печать файла в системе LPD.
Когда вызывается программа lpr, она первым делом выбирает принтер, на который будет производиться печать. Этот выбор определяется либо параметром командной строки Pprinter, либо значением переменной окружения PRINTER, либо же используется общесистемный принтер, заданный по умолчанию (это принтер с именем lp). Как только lpr узнает, на какой принтер отправлять текущее задание, она ищет описание этого принтера в базе данных об имеющихся принтерах, которая хранится в файле /etc/printcap. Из этой базы lpr получает имя каталога (области спулинга), в который следует помещать задания для найденного принтера. Обычно этот буферный каталог имеет имя /var/spool/lpd/printer. Такой каталог (область спулинга) должен существовать, если вы хотите печатать на принтере с именем printer.
Для каждого задания программа lpr помещает в буферный каталог два файла: cfxxx и dfxxx, где xxx - номер текущего задания. Файл cfxxx содержит справочную информацию и информацию об обработке задания. Источником этих сведений являются командная строка запуска программы, переменные среды процесса, который запустил эту программу, и глобальная конфигурация системы. Файл dfxxx содержит данные, подлежащие печати.
После постановки задания в очередь lpr уведомляет демона lpd о появлении задания на печать. Взаимодействие lpr с lpd происходит через именованный сокет /dev/printer. Демон lpd тоже обращается к файлу /etc/printcap, чтобы узнать, какой принтер должен использоваться для печати, и является он локальным или удаленным. Если в /etc/printcap указано, что принтер подключен локально, lpd проверяет наличие демона печати, обрабатывающего соответствующую очередь. Дело в том, что для обработки каждой очереди lpd создает отдельную копию самого себя. Если такой копии еще не имеется, она создается и ей передается обработка очереди. Если соответствующий принтер подключен к другой машине, lpd устанавливает соединение с демоном lpd удаленной машины и пересылает туда файл данных и управляющий файл.
Обслуживание заданий печати осуществляется по правилу "первым пришел - первым обслужен" (FIFO). Системный администратор может при желании изменить порядок печати с помощью программы lpc.
Начиная с ядра 2.1.33 устройство lp является клиентом нового устройства parport. Введение parport решает некоторые проблемы, связанные с lp - теперь можно разделять параллельные порты с другими драйверами, динамически связывать порты с устройствами, не устанавливая жесткого соответствия между адресами I/O и номером порта и т. д. Подробнее об этом вы можете прочитать в статье http://dimitr.obninsk.net.
Ввод символов с клавиатуры
В процессе ввода символов с клавиатуры можно выделить четыре соответствия или отображения (в математическом смысле этого слова).
На клавиатуру нанесены (или наклеены) символы. Это первое соответствие: символ -> клавиша.Микропроцессор клавиатуры реализует второе соответствие: комбинация клавиш -> скан-код.Далее скан-код клавиатуры преобразуется в код символа, понятный приложению, например, ASCII-код или UNICODE; это третье соответствие: скан-код -> код символа, используемый приложением.И, наконец, для изображения символа на экране или принтере используется четвертое соответствие: ASCII-код -> изображение символа.
О наличии этих соответствий полезно помнить при рассмотрении вопросов взаимодействия пользователя с приложениями. А теперь вернемся к вопросу о том, как работает клавиатура.
Управление работой клавиатуры в текстовом режиме осуществляется драйвером терминала, который входит в состав ядра Linux. Драйвер терминала состоит как бы из двух отдельных драйверов: драйвера клавиатуры и драйвера экрана. Драйвер клавиатуры обрабатывает нажатия клавиш пользователем и передает результат прикладной программе, которая, в свою очередь, посылает экранному драйверу символы, которые должны быть отображены на экране.
При каждом нажатии на клавишу микропроцессор клавиатуры генерирует последовательность так называемых скан-кодов, которая представляет собой последовательность из двух или большего числа байтов. Эта последовательность передается драйверу клавиатуры, который может работать в одном из 4 режимов:
K_RAW, когда прикладной программе передается последовательность скан-кодов, сгенерированных клавиатурой. Этот режим используется при работе с приложениями, которые имеют собственный драйвер клавиатуры. Примером такого приложения является система X Window.K_MEDIUMRAW, когда скан-код клавиши преобразуется в один из 127 возможных кодов, называемых кодами клавиш (keycodes). Каждый код клавиши состоит из кода нажатия клавиши и кода отпускания клавиши. Преобразование скан-кодов в коды клавиш осуществляется в соответствии с внутренней таблицей драйвера клавиатуры. Обычно эта таблица фиксирована, и изменять ее не требуется, хотя в системе существуют команды getkeycodes и setkeycodes, с помощью которых можно просмотреть или изменить некоторые соответствия в этой таблице. Эти команды используются только в том случае, если у вас программируемая клавиатура.K_XLATE (или режим ASCII), когда код клавиши преобразуется в ASCII-код символа или некоторую последовательность ASCII-кодов символов в соответствии с таблицей раскладки клавиатуры, которая хранится в виде отдельного файла. Например, для Red Hat Linux 5.2 по умолчанию используется файл defkeymap.map в каталоге /usr/lib/kbd/keymaps/i386/qwerty. Команда dumpkeys выводит на экран содержание действующей в данный момент таблицы раскладки клавиатуры, а команда loadkeys загружает в драйвер таблицу раскладки клавиатуры из указанного файла.K_UNICODE, когда скан-коды преобразуются в двухбайтовые коды таблицы UNICODE (этот режим пока используется очень редко).
Выбор режима работы драйвера терминала определяется прикладной программой, которая в данный момент времени выполняется компьютером. Чаще всего используется третий режим, когда код клавиши либо преобразуется в ASCII-код символа или строку таких кодов в соответствии с таблицей раскладки клавиатуры, либо выполняется действие, определенное для конкретной комбинации клавиш в таблице раскладки клавиатуры. Например, нажатие <Ctrl>+<Alt>+<Del> эквивалентно вызову команды shutdown -r 0, т. е. приводит к останову системы и перезагрузке компьютера.
Режим работы драйвера клавиатуры можно узнать или изменить с помощью команды kbd_mode. Однако не торопитесь менять режим, так как перевод драйвера клавиатуры в режим RAW или MEDIUMRAW может сделать его недоступным для большинства приложений, т. е. легко можно вообще потерять возможность ввода команд.
Не для всех клавиш и комбинаций клавиш процесс обработки проходит так прямолинейно, как это описано выше. Во-первых, имеется несколько особых клавиш, так называемых клавиш-переключателей. Это клавиши <Shift> (левая и правая), <Alt> (левая и правая), <Ctrl> (левая и правая), <Caps Lock>, <Num Lock>, <Ins>. Нажатие на клавишу-переключатель изменяет значение одного из разрядов (битов) в двухбайтовом слове, которое хранит состояние клавиш-переключателей. Поэтому драйвер клавиатуры вначале должен проанализировать состояние этого слова, а затем соответственно преобразовать коды.
Клавиша <Ins> является единственной из клавиш переключателей, нажатие которой не только заносит признак в слово состояния переключателей, но и порождает передачу соответствующего кода драйверу терминала.
С помощью ASCII-кодов можно представить 256 различных символов, а, значит, ASCII-коды можно сопоставить 256-ти кодам клавиш. Учитывая наличие клавиш переключателей, комбинаций клавиш существует гораздо больше. Поэтому некоторые комбинации клавиш драйвер клавиатуры преобразует в цепочки из нескольких байтов, так называемые Escape-последовательности, в которых два первых байта служат признаком Escape-последовательности, а последующие представляют собой собственно значащие байты. Escape-последовательности обычно представляют те комбинации клавиш, которые используются для управления работой программ, таких как стрелки, клавиши <Page Down>, <Page Up>, <Home>, <End>, <F1> - <F12>, <Ins>, <Del> и т. д.
В комплект Red Hat Linux входит программа showkey, которая показывает все три вида кодов, связанных с нажатиями клавиш. Если запустить эту программу с параметром -s, она будет показывать скан-коды нажатий клавиш (чтобы выйти из программы, надо просто выждать 10 секунд, не нажимая в это время ни одной клавиши). Ввод команды showkey -k приводит к выводу на экран кодов клавиш (выходим так же). Ввод команды showkey -m позволяет просмотреть ASCII-коды, которые выдаются драйвером клавиатуры после того, как скан-код клавиши будет оттранслирован с помощью таблицы раскладки клавиатуры. Попробуйте в этом режиме нажать <Ctrl>+<=> или <Ctrl>+<Esc>, и вы увидите, что не каждая комбинация клавиш порождает ASCII-код (попробуйте также клавиши-переключатели). В новых версиях программы showkey появилась опция -u, при которой отображаются коды UNICODE.
Примечание Если вы уже перешли в графический режим, то программа showkey может работать некорректно, о чем она вежливо сообщает при запуске. Обратите внимание на эти сообщения! Кстати, showkey неправильно работает не только в графическом режиме, но и при подключении через telnet и т.п. |
Zip-диск фирмы Iomega для параллельного порта
Для того, чтобы использовать Zip-дисковод, подключаемый к параллельному порту, вы можете использовать драйвер ppa, скомпилированный либо в составе ядра, либо в виде отдельного модуля. В последнем случае необходимо либо добавить строку insmod ppa в файл /etc/rc.d/rc.sysinit, либо просто каждый раз подключать нужный модуль той же командой insmod ppa. После этого вы будете иметь возможность смонтировать диск, установленный в ZIP-дисководе фирмы Iomega, с помощью обычной команды
mount -t vfat /dev/sda4 /mnt/zip
Может оказаться, что команда insmod ppa не срабатывает (например, если не скомпилирован модуль поддержки ppa). В этом случае после выполнения команды insmod ppa появляется сообщение об ошибке, и получить доступ к Zip-диску этим способом не удается. У меня такая ситуация возникла после перехода с версии 5.2 дистрибутива Black Cat на версию 6.02.
Тем не менее, мне удалось получить доступ к Zip-дискам. Я нашел пакет lomega версии 1.0.1 (обратите внимание на название программы - lomega, а не iomega), созданный Джоном Хоком (John Hawk, e-mail: visionary@gtemail.net). Этот пакет дает возможность работать под Linux с дисками Zip и/или Jaz фирмы Iomega. После обычной процедуры установки tar-gz-пакета (которая выполнялась с правами суперпользователя), мне легко удалось (все еще с правами суперпользователя и при условии, что в дисководе имеется носитель) смонтировать ZIP-диск.
Для того, чтобы монтирование дисков могли выполнять обычные пользователи, необходимо (от имени root) выполнить следующие команды:
[root]# chown root:root /directory/lomega [root]# chmod +s /directory/lomega
Помимо обычного способа доступа к диску командами mount/umount, можно запустить отдельную программу /usr/local/bin/lomega. Запускается она только в графическом режиме и представляет собой интерфейс для работы с Zip-диском. С помощью этой программы можно смонтировать и размонтировать Zip-диск, защитить диск от записи или снять эту защиту, а также извлечь носитель из дисковода простым щелчком мыши по соответствующей кнопке. Отметим только, что для того, чтобы установить защиту от записи, необходимо размонтировать диск.
В окне программы можно увидеть статус диска (смонтирован, размонтирован, защищен ли от записи), просмотреть содержимое файловой системы и отдельно - файлы на Zip-диске, а также сделать back-up выбранных файлов. Для этого надо просто отметить нужные файлы в окне программы и нажать экранную кнопку Back Up. После этого будет выведено диалоговое окно, в котором вы можете изменить предлагаемые по умолчанию параметры команды архивации tar. Таким образом, программа lomega предоставляет удобный интерфейс для архиватора tar.
Щелкнув правой кнопкой мыши в окне программы, вы получите выпадающее меню, с помощью которого можно выполнить много разных команд, в частности, удалить некоторые файлы и каталоги. При этом удаляемые файлы фактически не уничтожаются, а просто перемещаются в "корзину" (trash), откуда их, при необходимости, можно еще восстановить. Однако эта возможность сохраняется только до тех пор, пока вы не опустошили корзину командой "Empty Trash", которую можно вызвать через то же выпадающее меню.
Программа lomega использует конфигурационный файл /etc/lomega.conf. Структура этого файла подобна структуре файла /etc/fstab и не требует подробных пояснений.
При запуске программы можно задать в командной строке следующие опции:
-e - открывает окно файлового менеджера;-v - просто выводит версию программы;/dev/sda - указывает имя используемого устройства (должно иметься в файле lomega.conf).
Помимо двух уже описанных, имеется еще один способ получения доступа к Zip-диску из Linux: с помощью пакета mtools. Этот пакет, конечно, необходимо предварительно установить, а затем добавить следующую строку в файл /etc/mtools.conf:
drive z: file="/dev/sda4" exclusive
И все же основным способом подключения Zip-дисковода остается первый из трех описанных - с помощью модуля ppa. Упомянутые выше затруднения возникли у меня только с одной версией дистрибутива. После перехода на Red Hat 7.1 и ALT Linux Junior 1.0 (на двух разных компьютерах) я без затруднений подключаю Zip-диски стандартным способом.
Помимо двух уже описанных, имеется еще один способ получения доступа к Zip-диску из Linux: с помощью пакета mtools. Этот пакет, конечно, необходимо предварительно установить, а затем добавить следующую строку в файл /etc/mtools.conf:
drive z: file="/dev/sda4" exclusive
И все же основным способом подключения Zip-дисковода остается первый из трех описанных - с помощью модуля ppa. Упомянутые выше затруднения возникли у меня только с одной версией дистрибутива. После перехода на Red Hat 7.1 и ALT Linux Junior 1.0 (на двух разных компьютерах) я без затруднений подключаю Zip-диски стандартным способом.
 |
|
|
Под служебную информацию файловой системы (так называемые метаданные) тратится примерно 5% от исходного объема жесткого диска.
| © 2003-2007 INTUIT.ru. Все права защищены. |
Звуковая карта
Если у вас одна из последних версий Red Hat Linux, запустите программу sndconfig. Делать это надо от имени суперпользователя и только в консольном режиме. Первым делом эта программа попытается сама определить наличие у вас звуковой карты (рис. 9.9).

увеличить изображение
Рис. 9.9. Запуск программы sndconfig
Для этого она вызывает утилиту isapnptools. Если автоматически определить карту не удается, вам придется самому выбрать тип карты из списка (рис. 9.10).

увеличить изображение
Рис. 9.10. Выбор типа звуковой карты
Далее программа спросит вас о таких установках звуковой карты, как адрес порта ввода/вывода (I/O base address), IRQ, DMA, и 16-bit DMA (рис. 9.11). Будьте готовы ответить на эти вопросы. Затем программа попробует воспроизвести 2 музыкальных фрагмента, после каждого из которых спросит вас, слышали ли вы что-нибудь. Если вы ответите положительно, будет создан файл /etc/modules.conf, и вам остается только установить программу-проигрыватель, вроде xmms (о программах воспроизведения чуть позже, в лекции 15).

увеличить изображение
Рис. 9.11. Выбор параметров звуковой карты
У меня установка звуковой карты и программы x11amp (с дистрибутивного диска) прошли почти без запинки (пришлось только подобрать порт, предлагаемое по умолчанию значение почему-то оказалось неподходящим), после чего я смог прослушивать записи из mp3-файлов так же, как делал это раньше под Windows с помощью winamp. Кстати, программа x11amp теперь называется xmms.
Если у вас возникнут какие-то затруднения, обратитесь к "Звук в Linux HOWTO" [П11.15].
Два способа установки ПО
Необходимость в установке новых программных пакетов под LINUX возникает в двух основных случаях:
когда появляется новая версия одного из уже установленных у вас пакетов;когда возникает желание или необходимость использовать какой-то пакет, еще не установленный в системе.
Во втором случае это может быть один из пакетов, имеющихся на вашем установочном диске, но не установленный в процессе инсталляции. Однако чаще всего новое ПО вы будете находить в Интернете, тем более, что значительная часть этого ПО бесплатна. Как бы то ни было, но рано или поздно вы все равно окажетесь перед необходимостью установить новый пакет.
Для дистрибутивов, основанных на Red Hat Linux, существует две основных формы распространения ПО: в исходных текстах и в виде исполняемых модулей. В первом случае пакет ПО обычно поставляется в виде tar-gz архива, во втором случае - в виде rpm-пакета (но это не обязательно, исполняемые модули также могут распространяться в виде tar-gz-архива).
Проще всего установить ПО, представленное в виде rpm-пакета, содержащего исполняемые файлы, этот способ и рассмотрим первым. Отметим только, что для инсталляции новых пакетов вы должны войти в систему как пользователь root.
Инсталляция пакетов ПО из исходных текстов
Теперь, когда мы получили общее представление о компиляции программ на языке С, можно рассмотреть обращение с пакетами программ, распространяемыми в виде исходных кодов. Первое, что надо сказать в этой связи, это то, что для установки таких пакетов вы, естественно, должны иметь в своей системе утилиты gcc и make.
Непосредственно процесс инсталляции пакета состоит из следующих шагов:
Перейти (с помощью команды cd) в каталог, содержащий исходные коды устанавливаемого пакета.Выполнить команду ./configure, которая осуществляет конфигурирование пакета в соответствии с вашей системой. Процесс выполнения этой команды занимает довольно длительное время, причем команда выдает на экран сообщения о том, какие именно особенности системы испытываются.Выполнить команду make, для того, чтобы скомпилировать пакет.После этого можно выполнить (это шаг не является обязательным) команду make check, которая вызывает запуск процедур самотестирования, которые поставляются с пакетом.Выполнить команду make install для установки программ, а также файлов данных и документации.Заключительный этап состоит в выполнении команды make clean, которая удаляет промежуточные объектные и двоичные файлы из каталога с исходными кодами. Для удаления временных файлов, которые создала команда configure (после чего пакет можно компилировать для другого типа компьютеров), надо выполнить команду make distclean.
В большинстве случаев выполнение этой последовательности команд достаточно для установки нового пакета.
Основная проблема, с которой приходится сталкиваться при инсталляции программ из исходных кодов, связана с конфликтами версий: для вновь устанавливаемого пакета требуются новые версии каких-то системных утилит, которые пока еще не установлены в вашей системе. Более того, часто возникает целая цепочка (или даже дерево): для программы нужна какая-то новая версия утилиты, для последней нужно обновить еще какие-то утилиты, и т. д. Но, если вы не очень давно устанавливали (или обновляли) дистрибутив, то таких проблем не возникает, и обновление пакета пройдет без затруднений. Желаю вам успеха!
Компиляция ПО из исходных текстов
Если rpm-пакеты с необходимым вам программным обеспечением нужно еще поискать (и не всегда можно найти), то tar-gz-архив любого ПО для Linux найдется в Интернете непременно. В некоторых случаях такие архивы содержат исполняемые модули приложений. Тогда установка приложения лишь немного сложнее, чем в случае установки из rpm-пакета: необходимо просто развернуть архив с помощью программ gunzip и tar, перейти в созданный каталог и можно уже запускать полученное приложение. Но чаще всего приложения поставляются в исходных текстах, т. е. в виде программы на языке Си. Установить их в этом случае немного сложнее, хотя и тут нет ничего невозможного даже для начинающего пользователя. Давайте рассмотрим, как это делается.
Необходимые сведения о программировании на языке Си
Начать стоит с того, что операционная система UNIX родилась на свет одновременно с языком программирования C (Си). Более того, язык C был создан специально для разработки этой ОС, значительная часть UNIX была написана на языке С. ОС Linux тоже написана на Си. Поэтому, а также в соответствии с принципом свободного распространения исходных кодов, многие приложения для Linux распространяются в виде текстов на С (а в последнее время - и на С++). Естественно, что для установки и запуска такого приложения на исполнение, его необходимо предварительно скомпилировать. Для выполнения процедур компиляции обычно используется программа gcc (хотя существуют и некоторые альтернативные разработки).
|
Примечание Изначально аббревиатура GCC имела смысл GNU C Compiler, но в апреле 1999 года сообщество GNU решило взять на себя более сложную миссию и начать создание компиляторов для новых языков с новыми методами оптимизации, поддержкой новых платформ, улучшенных runtime-библиотек и других изменений (http://gcc.gnu.org/gccmission.html). Поэтому сегодня GCC расшифровывается как GNU Compiler Collection (коллекция компиляторов GNU) и содержит в себе компиляторы для языков C, C++, Objective C, Chill, Fortran, Ada и Java, а также библиотеки для этих языков (libstdc++, libgcj, ...). |
GNU-компилятор с языка С gcc, содержит в себе 4 основных компонента, соответствующие четырем этапам преобразования исходного кода в исполняемую программу.
Первый компонент - это препроцессор, который модифицирует исходный код программы перед компиляцией в соответствии с командами препроцессора, содержащимися в С-программе. В соответствии с этими командами выполняются простые подстановки текста. Второй - собственно компилятор, который обрабатывает исходный код и преобразует его в код на языке ассемблера. Третий компонент - ассемблер, который генерирует объектный код. И, наконец, четвертый компонент - компоновщик, который собирает исполняемый файл из файлов объектного кода. Дело в том, что большие программы обычно пишутся по частям, в виде множества отдельных файлов, содержащих исходный код соответствующей части. Компилятор обрабатывает каждый такой файл отдельно и создает отдельные объектные модули (файлы таких модулей обычно имеют расширение o). Создание единой исполняемой программы из таких модулей и является задачей компоновщика. При таком подходе, если в какой-то модуль программист вносит исправление, нет необходимости заново компилировать всю программу: достаточно откомпилировать исправленный модуль и заново запустить компоновщик.
Для выполнения стандартных операций программист может использовать функции из стандартных библиотек. Самый характерный пример - это библиотека libc, которая содержит функции, выполняющие такие задачи, как управление памятью и операции ввода-вывода. Программисты могут создать свои собственные библиотеки и использовать их при написании новых программ.
Библиотеки бывают статическими, разделяемыми и динамическими. Статическая библиотека - это библиотека, код которой встраивается в программу при компиляции. Код разделяемой библиотеки не встраивается в программу, а загружается в память одновременно с программой и программа получает доступ к функциям этой библиотеки. Динамические библиотеки - разновидность разделяемых, но библиотечные функции загружаются в память только тогда, когда из программы поступит вызов соответствующей функции. В процессе выполнения программы они могут выгружаться и заменяться другими функциями из той же или другой библиотеки. Имена статических библиотек обычно имеют суффикс .a, а имена разделяемых библиотек - суффикс .so, за которым следует старший и младший номера версии. Имя может быть любой строкой, которая однозначно характеризует библиотеку. Обычно имена библиотек начинаются с lib. Примеры: libm.so.5 - общая математическая библиотека, libX11.so.6 - библиотека для работы с системой X Window. Библиотека libc.so.5 компонуется автоматически, в то время как большинство других библиотек необходимо явно указывать в командной строке при вызове программы gcc. Это делается через опцию -l, за которой следует уникальная часть имени библиотеки, например, для вызова математической библиотеки достаточно указать -lm.
Многие системные библиотеки располагаются в системных каталогах, например, в /usr/lib и /lib, но некоторые могут располагаться и в других местах. Список этих каталогов помещается в файл /etc/ld.so.conf. Каждый раз, когда разделяемая библиотека изменяется или инсталлируется вновь, нужно выполнять команду ldconfig, чтобы обновить файл /etc/ld.so.conf, а также ссылки на него. Если библиотека инсталлируется из RPM-пакета, это обычно делается автоматически, хотя и не всегда.
При компиляции больших программ, использующих фрагменты исходного кода, расположенные в разных файлах, бывает очень трудно отследить, какие файлы нужно перекомпилировать, а какие только компоновать. В таких случаях очень помогает утилита make, которая автоматически определяет, следует ли компилировать файл исходного кода, по дате его последней модификации. Утилита make оперирует файлами, исходя из их зависимости друг от друга. Эти зависимости определяются файлом с именем makefile. Строка файла makefile состоит из трех частей: имени целевого файла, списка файлов, от которых он зависит, и команды. Если какой-либо файл из списка изменился после целевого файла, то выполняется указанная в строке команда. В строке может быть указано несколько команд. Обычно команда - это вызов компилятора для компиляции файла исходного кода или компоновки файлов объектного кода. Строки, определяющие зависимости, отделяются друг от друга пустой строкой.
Программа rpm
Название этой программы (или команды) является аббревиатурой от Redhat Package Manager. Такая расшифровка дается в большинстве книг и руководств по Linux и кажется мне более правильной и логичной, хотя в главе 6 "The Official Red Hat Linux Reference Guide" говорится: "The RPM Package Manager (RPM), is an open packaging system available for any-one to use, and works on Red Hat Linux as well as other Linux and UNIX systems", т. е. предлагается рекурсивная расшифровка названия RPM, подобная расшифровке GNU - GNU is Not Unix).
Программа rpm в некотором смысле аналогична программам типа setup wizard для MS Windows. Преимуществом использования этой программы по сравнению с установкой tar gz архивов является то, что она автоматически проделает все необходимые действия по установке ПО: создаст необходимые каталоги, распределит по ним файлы, создаст ссылки. Кроме того, она может быть использована не только для установки нового пакета, но и для обновления версий ПО, получения перечней установленного ПО и проверки установки, а также для деинсталляции отдельных пакетов (например, если после периода пробной работы с программой вы решили отказаться от ее дальнейшего использования). С помощью той же программы rpm можно самому создать пакет формата rpm, однако для начинающих лучше, наверное, этим не заниматься, а воспользоваться готовыми rpm-пакетами.
Rpm-пакеты - это специальным образом подготовленные архивы, предназначенные для обработки программой rpm. Название rpm-пакетов оканчивается на суффикс .rpm, например, xzip-180-1.i386.rpm или xzip-180-1.src.rpm. Как видите, перед суффиксом .rpm стоит еще один суффикс. Если это .i386, .i686 или .i586, то в пакете находятся исполняемые файлы (оптимизированные для соответствующего типа процессора), а если этот суффикс .src, - то в пакете исходные тексты, которые после установки еще надо скомпилировать. Обычно как на установочных компакт-дисках, так и в интернет-каталогах rpm-пакеты с исполняемыми файлами располагаются в каталогах с названием RPMS, а rpm-пакеты с исходными текстами - в подкаталогах SRPMS. Часто встречаются также rpm-пакеты с суффиксом .noarch.rpm, содержащие файлы, которые просто без всякой дополнительной обработки устанавливаются в соответствующие каталоги (например, файлы страниц интерактивного руководства man). И, наконец, если rpm-пакет рассчитан на версию Linux, предназначенную для другой аппаратной платформы (AMD, DEC Alpha, SUN Sparc, MIPS, PowerPC), это тоже будет отображено в имени пакета: вместо i386 в суффиксе будет стоять, соответственно, athlon, alpha, sparc, mips или ppc.
В Интернете rpm-пакеты можно найти на различных серверах. По моему опыту наиболее удобным сервером в Интернете для поиска rpm-архивов является сервер http://rufus.w3.org (недаром он имеет другое имя http://rpmfind.net). На нем установлена поисковая система, которая позволяет упорядочивать список пакетов наиболее удобным для вас способом:
по именам пакетов;по дистрибутивам;по группам приложений;по датам;по поставщикам (производителям) ПО.
Общий объем архива rpm-пакетов на этом сервере составляет более 66 Гигабайт. Очень богатые архивы хранят также два ftp-сервера в России: ftp://ftp.chg.ru/pub/Linux и ftp://ftp.nc.orc.ru/.
Необходимо только заметить, что если для перекачки пакетов из Интернета вы используете компьютер, работающий под Windows 95, то все имена пакетов у вас будут, скорее всего, искажены. Дело в том, что Windows "не любит" имена, в которых несколько точек (например, glib-1.0.6-3.i386.rpm) и заменит "лишние", по его мнению, точки на знаки подчеркивания - glib-1_0_6-3_i386.rpm. Так что после получения пакета (при переносе его на ПК с ОС Linux) желательно эти "исправления" устранить, вернувшись к исходным именам UNIX. Правда, делать это не обязательно, поскольку внутри rpm-пакет все равно правильно идентифицирован, но для единообразия и облегчения поиска файлов все же целесообразно.
Общий объем архива rpm- пакетов на этом сервере составляет более 66 Гигабайт. Очень богатые архивы хранят также два ftp-сервера в России: ftp://ftp.chg.ru/pub/Linux и ftp://ftp.nc.orc.ru/.
Необходимо только заметить, что если для перекачки пакетов из Интернета вы используете компьютер, работающий под Windows 95, то все имена пакетов у вас будут, скорее всего, искажены. Дело в том, что Windows "не любит" имена, в которых несколько точек (например, glib-1.0.6-3.i386.rpm) и заменит "лишние", по его мнению, точки на знаки подчеркивания - glib-1_0_6-3_i386.rpm. Так что после получения пакета (при переносе его на ПК с ОС Linux) желательно эти "исправления" устранить, вернувшись к исходным именам UNIX. Правда, делать это не обязательно, поскольку внутри rpm-пакет все равно правильно идентифицирован, но для единообразия и облегчения поиска файлов все же целесообразно.
Итак, вы нашли и скачали rpm-архив с исполняемой версией нужного вам пакета. Если вы ставите совершенно новый пакет (у вас не было на компьютере предыдущих версий этого ПО), то для установки пакета из этого архива достаточно перейти в тот каталог, где находится архив, и дать команду (для самых нетерпеливых: не спешите выполнять эту рекомендацию, прочитайте еще хотя бы пару абзацев)
[root]# rpm -i имя_rpm-архива
Если у вас была установлена предыдущая версия пакета, то в простейшем случае надо дать команду следующего формата:
[root]# rpm -U --force имя_rpm-архива
Здесь параметр -U говорит программе, что надо произвести обновление (upgrade) пакета, а опция --force требует безусловно (и без лишних вопросов) обновить все входящие в пакет файлы. Заметьте, что это очень сильное требование, и в некоторых случаях может быть лучше сохранить какие-то (например, конфигурационные) файлы от предыдущей версии. Если установка проходит нормально, и никаких дополнительных сообщений не появляется, то после завершения работы программы (после появления приглашения оболочки) вы можете пользоваться вновь установленным пакетом.
К сожалению, не всегда все так просто. Приведу конкретный пример. У меня был установлен RedHat Linux версии 5.2, причем программа Midnight Commander (mc) была версии 4.1.36. На ftp-сервере я увидел версию 4.5.30 этой программы (пакет mc-4.5.30-12.i386.rpm) и, естественно, решил ее поставить. Однако оказалось, что для этого необходимо установить еще 4 других пакета, о чем rpm мне и сообщила:
ошибка: неудовлетворенные зависимости: redhat-logos нужен для mc-4.5.30-12 libglib-1.2.so.0 нужен для mc-4.5.30-12 libc.so.6(GLIBC_2.1) нужен для mc-4.5.30-12 libc.so.6(GLIBC_2.0) нужен для mc-4.5.30-12
Это не удивительно, если вы вспомните, что и при первоначальной установке Linux программа инсталляции тоже проверяла взаимозависимости пакетов и предлагала установить недостающие. Однако в случае инсталляции с CD-ROM все необходимые пакеты находятся на том же диске, а здесь мне пришлось вначале поискать нужные пакеты. Два пакета (redhat-logos-1.0.5-1.noarch.rpm и glibc-2.1.1-6.i386.rpm) я нашел без труда, после чего rpm перестала просить и GLIBC_2.0. А вот с libglib.so.1 вышло сложнее. Во-первых, я никак не мог найти пакета с таким названием. Как оказалось, такого пакета и не существует, файл libglib.so.1 входит в состав пакета glib-1.0.6-3.i386.rpm.
Программа rpm позволяет выяснить, какие файлы установит тот или иной пакет. Для этого надо дать следующую команду (только учтите, что текущим должен быть каталог, содержащий интересующий вас пакет):
[root]# rpm -qpl имя_rpm-архива
А для получения информации о том, для чего служит ПО, содержащееся в rpm-пакете, используйте команду
[root]# rpm -qpi имя_rpm-архива
Дело в том, что файлы RPM кроме собственно архива файлов содержат информацию о пакете, включая имя, версию и краткое описание. С помощью той же программы rpm вы можете просмотреть эту дополнительную информацию. Например, для пакета glib-1.0.6-3.i386.rpm вывод команды
[root]# rpm -qpi glib-1.0.6-3.i386.rpm
будет примерно таким:
Name : glib Relocations: (not relocateable) Version : 1.0.6 Vendor: Red Hat Software Release : 3 Build Date: Суб 10 Окт 1998 04:49:03 Install date: (not installed) Build Host : porky.redhat.com Group : Libraries Source RPM: glib-1.0.6-3.i386.rpm Size : 55305 Packager : Red Hat Software <bug@redhat.com> Summary : Handy library of utility functions Description : Handy library of utility functions. Development libs and headers are in gtk+-devel.
Если дать команду:
[root]# rpm -qpl glib-1.0.6-3.i386.rpm
будет выдан список входящих в пакет файлов с указанием того, куда они будут установлены:
/usr/lib/libglib.so.1 /usr/lib/libglib.so.1.0.6
RPM также предоставляет мощную систему запросов по установленным в системе пакетам. По команде
[root]# rpm -qа
вы получите перечень всех установленных в системе пакетов (перечень будет очень большим, так что лучше сразу направить вывод в фильтр more или в файл, который потом просматривать с помощью less или встроенной программы просмотра из оболочки Midnight Commander). Вы можете искать информацию об отдельном пакете или об отдельных файлах. Например, вы можете легко найти, какому пакету принадлежит файл и откуда появился. Команда
[root]# rpm -qf /etc/bashrc
сообщит:
bash-1.14.7-16
Если вы беспокоитесь о том, что случайно удалили важный файл из установленного пакета, просто проверьте это:
[root]# rpm -Va
Вы будете оповещены об любых аномалиях. Потом можно переустановить пакет, если это необходимо. Любые конфигурационные файлы будут сохранены.
Как видите, rpm это очень полезная утилита, и у нее имеется много разных опций. Выше приведено только несколько примеров. Всего rpm имеет 16 основных режимов работы, которые можно объединить в 6 групп (после двоеточия приводится формат команды для соответствующего режима).
Запросы
Запрос: rpm [--query] [queryoptions]Показать метки запросов (Querytags): rpm [--querytags]
Установка и поддержка установленных пакетов
Установка: rpm [--install] [installoptions] [package_file]+Обновление: rpm [--freshen|-F] [installoptions] [package_file]+Деинсталляция: rpm [--uninstall|-e] [uninstalloptions] [package]+Проверка: rpm [--verify|-V] [verifyoptions] [package]+
Подписи (пакеты подписываются электронной цифровой подписью в формате PGP, с целью обеспечения неизменяемости и сохранения авторства пакетов).
Проверка подписи: rpm [--verify|-V] [verifyoptions] [package]+Переподписывание: rpm [--resign] [package_file]+Добавление подписи: rpm [--addsign] [package_file]+
Работа с базой
Инициализация базы: rpm -i [--initdb]Обновление базы (Rebuild Database): rpm -i [--rebuilddb]
Создание rpm-пакетов
Создать пакет: rpm [-b|t] [package_spec]+Перекомпилировать пакет: rpm [--rebuild] [sourcerpm]+Скомпилировать пакет из tar-архива: rpm [--tarbuild] [tarredsource]+
Разное
Показать конфигурацию программы rpm: rpm [--showrc]Задать пользователей: rpm [--setperms] [package]+Задать группы: rpm [--setgids] [package]+
Подробное описание всех возможностей команды rpm выходит за рамки нашей книги Его вы можете найти в RPM-HOWTO, на страницах man и info. Кроме того, большой раздел о программе rpm имеется в книге [П1.3].
Примечание Как и другие программы для Linux, программа rpm постоянно развивается и совершенствуется. При этом при замене версии этой программы могут возникнуть трудности с установкой пакетов, созданных в предыдущих версиях. Так было, например, при переходе с третьей на четвертую версию rpm. Так что надо использовать пакеты, соответствующие установленной у вас версии программы. |
Bash
Хотя для большинства программ вполне достаточно установки LANG=ru_RU.KOI8-R чтобы начать распознавать русские буквы, многие программы, основанные на библиотеке readline (например bash) все равно считают символы с кодами больше 128 особыми META-символами (пищит при вводе).
Чтобы "отучить" библиотеку readline от этого, необходимо установить три переменные.
set meta-flag on set convert-meta off set output-meta on
Этого можно добиться разными способами. Поскольку вы являетесь суперпользователем своего компьютера, можно определить переменную INPUTRC=, например, создав файл /etc/profile.d/readline.sh следующего содержания:
#!/bin/bash INPUTRC="/etc/inputrc"; export INPUTRC
и сделать этот файл исполняемым. Кроме того, прописать в файле /etc/inputrc
set meta-flag on set convert-meta off set output-meta on
После этого библиотека readline (и bash) начнет воспринимать русские буквы.
Еще один вариант: не задавать INPUTRC=, а прописать те же значения в файле ~/.inputrc в домашнем каталоге каждого пользователя.
См. страницу man readline.
Что нужно сделать
Если вы внимательно прочитали лекцию 9 и предыдущий разделы, то представляете, что для русификации консоли (а консоль - это, грубо говоря, совокупность клавиатуры и дисплея) требуется загрузить в драйвер консоли три таблицы:
таблицу раскладки клавиатуры;таблицу экранного шрифта (SFM), в которой хранятся изображения символов;таблицу перекодировки символов (ACM).
Таблицы раскладки клавиатуры находятся в каталоге /usr/lib/kbd/keymaps/i386/qwerty. Выбор конкретного файла раскладки задается файлом /etc/sysconfig/keyboard. Этот файл можно отрегулировать вручную, а можно с помощью программы kbdconfig. В последнем случае нужная таблица с раскладкой клавиатуры загружается в память. При ручном изменении файла /etc/sysconfig/keyboard перезагрузка таблицы произойдет только после перезапуска компьютера или после выполнения команды (в примере загружается раскладка из файла ru-win.map):
[root]# loadkeys /usr/lib/kbd/keymaps/i386/qwerty/ru-win.map
Второй шаг русификации состоит в задании и загрузке таблицы экранного шрифта (SFM) в драйвер дисплея. Эти таблицы хранятся в виде файлов в каталоге /usr/lib/kbd/consolefonts. Загрузка шрифтов осуществляется немного по-разному в пакетах kbd и consoletools (соответственно, в версиях 5.2 и 6.x Red Hat Linux). В версии 5.2 загрузка шрифта осуществлялась с помощью команды setfont. Например, чтобы загрузить кодовую страницу из файла Cyr_a8x16, нужно дать команду
[root]# setfont /usr/lib/kbd/consolefonts/Cyr_a8x16
В версии 6.0 и последующих надо использовать команду consolechars с опцией -f:
[root]# consolechars -f /usr/lib/kbd/consolefonts/Cyr_a8x16
(Отметим, что команда setfont тоже сработает, только выдаст предупреждение о том, что надо пользоваться командой consolechars.)
Файлы шрифтов являются бинарными файлами размером 256*H байт, содержащими битовые образы для каждого из 256 символов, по одному байту на каждую линию образа и по H байт на символ (0 < H <= 32). В этом случае о размере шрифта по вертикали можно судить по длине файла. В качестве файлов шрифтов могут использоваться файлы .psf; они имеют тот же самый формат и, кроме того, заголовок размером 4 байта. Некоторые файлы шрифтов содержат сразу три шрифта разного размера (например, 8х8, 8х14, 8х16), тогда в команде consolechars надо добавить опцию -H, например: -H 16, для выбора одного из размеров. Поскольку ядро Linux не поддерживает пока переключение режимов работы экрана, consolechars (как и setfont) не может изменить текущий режим EGA/VGA. Таким образом, пользователь полностью ответственен за выбор шрифта, соответствующего текущему режиму экрана.
Соответствие между символами кода ASCII и образами (или изображениями символов) из файла шрифта можно изменить, используя таблицу перекодировки (ACM - Application Charset Map). Если эту таблицу не загрузить, то, например, в программе Midnight Commander вы можете вместо красивых рамочек увидеть столбцы и строки из непонятных символов. Некоторые файлы шрифтов включают таблицу перекодировки шрифта, и тогда consolechars загрузит эту таблицу. По умолчанию файлы шрифтов находятся в каталоге /usr/lib/kbd/consolefonts, а таблицы перекодировки - в каталоге /usr/lib/kbd/consoletrans.
Таблицу перекодировки в 6-ой версии Red Hat (т. е. в пакете consoletools) можно загрузить отдельной командой consolechars с опцией -m file:
[root]# consolechars -m /usr/lib/kbd/consoletrans/koi2alt
Если таблица перекодировки не включена в файл шрифта и не указана в опции -m, то используется "тривиальная" таблица.
В версии 5.2 для загрузки таблицы перекодировки используется команда mapscrn:
[root]# mapscrn /usr/lib/kbd/consoletrans/koi2alt
В этом случае драйвер консоли должен быть дополнительно переведен в режим перекодировки, задаваемый таблицей, путем вывода на консоль специальной escape-последовательности. Эта последовательность есть <esc>(K для набора символов G0 (G0 character set) и <esc>)K для набора символов G1 (G1 character set). Заметим, что активизировать эту таблицу необходимо в каждой консоли. При этом команда loadkeys действует одновременно во всех виртуальных консолях, а вот команда mapscrn действует только в той виртуальной консоли, в которой выполнена команда echo -ne '\033(K'.
Замечание: Esc(K требуется, когда загружается альтернативная кодировка и активизируется таблица перекодировки псевдографики командой mapscrn koi2alt. Если шрифт koi-8, то никаких Esc(K не надо. |
Замечание: Все это не действует из-под Midnight Commander! |
Итак, для того, чтобы русифицировать консоль, нужно выполнить следующую последовательность команд:
для версии 5.2 Red Hat: loadkeys /usr/lib/kbd/keytables/i386/qwerty/ru.map setfont /usr/lib/kbd/consolefonts/Cyr_a8x16 mapscrn /usr/lib/kbd/consoletrans/koi2alt echo -ne '\033(K'для версии 6.0 Red Hat (и последующих): loadkeys /usr/lib/kbd/keytables/i386/qwerty/ru.map consolechars -f /usr/lib/kbd/consolefonts/Cyr_a8x16 consolechars -m /usr/lib/kbd/consoletrans/koi2alt
Но выполнять эту последовательность команд после каждого перезапуска компьютера, да еще в каждой виртуальной консоли, слишком обременительно. Поэтому рассмотрим вкратце, как русификация выполняется в дистрибутиве Black Cat Linux.
Диски Win'95 и DOS
Чтобы подмонтировать диск Windows'95 и DOS с правильной поддержкой русских букв, необходимо воспользоваться командой:
[user]$ mount -t vfat -o umask=002,noexec,gid=500,codepage=866,iocharset=koi8-r /dev/hdb1 /mnt
То есть все русские имена на диске FAT сохраняются в Codepage 866 ! Для работы этой опции ядро (>2.0.36) должно быть пересобрано с поддержкой NLS, кодовыми страницами CP866, NLS KOI8-R и, конечно же, с поддержкой VFAT.
Файлы fonts.dir, fonts.alias и fonts.scale
Если вы последуете приведенному Выше совету и выполните команду
xlsfonts > fontlist
а после этого пересчитаете число файлов в каталогах, перечисленных в FontPath, то скорее всего обнаружите, что в fontlist перечислено гораздо больше шрифтов, чем имеется файлов со шрифтами. Чтобы понять, почему это так, надо разобраться с файлами fonts.dir, fonts.alias и fonts.scale. Если вы заглянете в любой каталог со шрифтами, то найдете там по крайней мере файл fonts.dir, а может быть и два других: fonts.alias и fonts.scale. Для чего же они нужны?
Структура файла fonts.dir очень проста и из нее становится ясно, зачем этот файл нужен. Каждая строка файла fonts.dir (кроме первой) содержит имя одного из файлов со шрифтом, содержащегося в том каталоге, где расположен данный файл fonts.dir, вслед за которым (после пробела или символа табуляции) указывается имя содержащегося в этом файле шрифта. Пример:
koi12x24.pcf.gz -cronyx-fixed-medium-r-normal--24-170-100-100-c-120-koi8-u
Первая строка файла fonts.dir содержит число шрифтов, перечисленных в этом файле (и, соответственно, имеющихся в данном каталоге со шрифтами). Файл fonts.dir совершенно необходим для того, чтобы X-сервер мог работать со шрифтами. По-видимому (я могу судить об этом только на основании проведенных экспериментов, поскольку в литературе такого описания не встречал), при запуске X-сервера или фонт-сервера на основе файлов fonts.dir из каталогов шрифтов в оперативной памяти создается таблица доступных для системы шрифтов.
Файл fonts.scale, по-видимому, задает список масштабируемых шрифтов и необходим некоторым приложениям для корректной работы с такими шрифтами. В большинстве случаев это либо точная копия файла fonts.dir, либо просто ссылка на fonts.dir. Естественно, что в каталогах с растровыми шрифтами мы такого файла не найдем.
Файл fonts.alias - это еще один конфигурационный файл, оказывающий влияние на работу со шрифтами. Уже по названию ("alias" - прозвище, кличка) можно догадаться о его назначении. Строки этого файла имеют следующий вид:
синоним XLFD_имя_реального_шрифта
При этом каждая строка должна оканчиваться только символом конца строки и владельцем файла должен быть суперпользователь. Вот для примера первые строки из файла /usr/X11R6/lib/X11/fonts/misc/fonts.alias в системе Redhat :
fixed -misc-fixed-medium-r-semicondensed--13-120-75-75-c-60-iso8859-1 variable -*-helvetica-bold-r-normal-*-*-120-*-*-*-*-iso8859-1
Слово fixed здесь является синонимом или ссылкой ('alias'). Каждый раз, когда запрашивается шрифт fixed, будет фактически происходить обращение к шрифту, указанному во второй колонке. Шрифт кажется маловат? Просто поменяйте имя, на которое дана ссылка этим определением. Тот же самый принцип применим ко всем шрифтам, включая True Type. Более того, если у вас не установлены шрифты True Type, вы можете использовать этот же трюк для того, чтобы использовать какой-то из шрифтов Type 1 вместо запрашиваемых приложением шрифтов True Type.
Маленькое ПРЕДОСТЕРЕЖЕНИЕ для тех, кто имеет привычку "сильно быстро делать": некоторые синонимы должны быть известны системе в любой момент времени! В первую очередь это относится к синонимам "cursor", "fixed" и "variable" в каталогах /misc. Если таких строк в misc/fonts.alias нет, или они указывают на несуществующий шрифт, то графическая оболочка просто откажется запускаться. |
arial.ttf -monotype-Arial-medium-r-normal--0-0-0-0-p-0-ascii-0 arial.ttf -monotype-Arial-medium-r-normal--0-0-0-0-p-0-fcd8859-15 arial.ttf -monotype-Arial-medium-r-normal--0-0-0-0-p-0-iso8859-15 arial.ttf -monotype-Arial-medium-r-normal--0-0-0-0-p-0-iso8859-1
Это масштабируемые шрифты, так что в их именах не указаны размеры. Поэтому в файле fonts.alias должны, соответственно, присутствовать строки (в файле они должны быть записаны без переносов, просто в книге строка целиком не умещается в рамках страницы):
| -monotype-Arial-medium-r-normal--6-60-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--9-90-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--6-60-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--9-90-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--7-70-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--9-90-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--8-80-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--10-100-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--9-90-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--11-110-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--10-100-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--12-120-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--11-110-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--12-120-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--12-120-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--12-120-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--13-130-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--13-130-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--14-140-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--14-140-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--15-150-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--15-150-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--18-180-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--18-180-75-75-p-0-iso8859-1 |
| -monotype-Arial-medium-r-normal--24-240-0-0-p-0-iso8859-1 | -monotype-Arial-medium-r-normal--24-240-75-75-p-0-iso8859-1 |
Обратите внимание на различие в размерах шрифта в правой и левой колонках. Например, в первой строке слева указан размер в 6 точек, а справа - 9 точек. С помощью этого приема удается преодолеть "склонность" Netscape к использованию слишком маленьких шрифтов. Просто подберите справа цифры в соответствии с Вашими вкусами.
Создавать файлы fonts.dir, fonts.scale и fonts.alias вручную - занятие не из простых. Поэтому разработаны специальные программы, которые запускаются в каталоге со шрифтами и создают эти файлы. Файл fonts.dir в каталоге с растровыми шрифтами можно создать с помощью команды mkfontdir. Для создания файлов fonts.dir и fonts.scale в каталогах со шрифтами Type1 надо воспользоваться утилитой type1inst (ftp://ftp.metalab.unc.edu/pub/Linux/X11/xutils/). Это скрипт на языке perl, который автоматически создает файлы fonts.dir и fonts.scale, необходимые для того, чтобы система X-Window могла использовать шрифты. Рекомендации по установке и настройке этого скрипта вы найдете в файле README, который поставляется вместе с пакетом.
Для шрифтов True Type необходима своя утилита ttmkfdir, которую можно найти на многих сайтах с программным обеспечением для Linux. В Redhat эта утилита включена в состав rpm-пакета Freetype.
На странице "Some Linux for Beginners" (http://home.c2i.net/dark/linux.html) вы можете найти скрипт на языке python, с помощью которого можно создать файл fonts.alias.
Фонт-сервер xfs
Если вы пользуетесь дистрибутивом, основанным на Red Hat (Mandrake и т.п.), то фонт-сервер xfs у вас, вероятно, установлен. Сообщение о запуске фонт-сервера xfs появляется на экране монитора в процессе загрузки, а, кроме того, соответствующее сообщение об успешном запуске xfs можно найти в файле /var/log/messages.
В случае применения xfs, в файле XF86Config вместо перечня каталогов со шрифтами вы увидите всего одну строку следующего вида:
FontPath "unix/:-1"
Эта строка является ссылкой на номер порта, который будет использоваться для связи с фонт-сервером.
Использование фонт-сервера не означает, что имеет место полный отказ от перечня каталогов со шрифтами. Только теперь это перечень переносится в конфигурационный файл программы xfs. По умолчанию это файл /etc/X11/fs/config. В секции "catalogue" этого файла и перечислены теперь все каталоги со шрифтами. Соответствующая секция файла /etc/X11/fs/config должна выглядеть примерно так:
catalogue = /usr/X11R6/lib/X11/fonts/misc:unscaled, /usr/X11R6/lib/X11/fonts/100dpi:unscaled, /usr/X11R6/lib/X11/fonts/75dpi:unscaled, /usr/X11R6/lib/X11/fonts/Type1, /usr/X11R6/lib/X11/fonts/Speedo, /usr/X11R6/lib/X11/fonts/misc, /usr/X11R6/lib/X11/fonts/100dpi, /usr/X11R6/lib/X11/fonts/75dpi, /usr/local/share/fonts/ttfonts
(обратите внимание на отсутствие запятой в последней строке).
Правда, вы можете по-прежнему включить строки с указанием путей к каталогам шрифтов в файл XF86Config (вместе со строкой "FontPath "unix/:-1"), но они будут обрабатываться не фонт-сервером, а X-сервером.
xfs от Redhat способен обслуживать как шрифты Type 1, так и шрифты True Type.
Фонт-сервера xfstt и xfsft
Если ваш дистрибутив не включает фонт-сервер xfs, вы можете воспользоваться одним из альтернативных фонт-серверов
xfstt (http://metalab.unc.edu/pub/Linux/X11/fonts/) илиxfsft (http://www.dcs.ed.ac.uk/home/jec/programs/xfsft/).
xfstt - это фонт-сервер, созданный исключительно с целью обслуживания шрифтов True Type на локальной машине. Поэтому он поддерживает только шрифты True Type и не может обслуживать шрифты на нескольких машинах в сети. Учитывая это, предпочтительнее пользоваться фонт-сервером xfsft или фонт-сервером xfs от Red Hat, о котором мы уже говорили. Заметим, что фонт-сервер xfsft послужил основой для доработки xfs, и модуль работы со шрифтами в XFree86 версии 4 создан разработчиком xfsft. Наверное поэтому этот фонт-сервер перестал поддерживаться разработчиком, так что вам лучше сразу ориентироваться на xfs или переходить на XFree86 версии 4.
Фонт-серверы
Хотя вывод символов на экран с помощью X-сервера графической подсистемы XFree86 и обеспечивает вывод текста, однако, этот способ имеет два крупных недостатка. Во-первых, шрифты должны располагаться на том же компьютере, на котором запущен X-сервер. Во-вторых, не обеспечивается вывод шрифтов True Type. Для преодоления этих недостатков были разработаны специальные серверы шрифтов или фонт-серверы (надо отметить, что в версии XFree86 4.x второй недостаток уже отсутствует, так что специальный фонт-сервер уже не нужен, если речь идет только о поддержке шрифтов True Type).
В настоящее время существует три разных сервера фонтов: xfs, xfstt и xfsft.
Формат задания значений переменных локализации
В качестве значений переменных локализации используются строки формата
ll[ _CC[.EEEE]][@dddd]
где
ll - это двухбуквенный код языка в соответствии со стандартом ISO для названий языков (ISO 639), записываемый в нижнем регистре (строчными латинскими буквами);CC - это двухбуквенный код страны в соответствии со стандартом ISO для названий стран (ISO 3166), записываемый в верхнем регистре;EEEE - это имя (название) таблицы кодировки, записываемое в верхнем регистре;dddd - название диалекта языка, который задается в том случае, если названия кодировки недостаточно для однозначного определения варианта локализации.
Для переменной LINGUAS задаваемые значения разделяются двоеточиями. Пример строки задания значений переменной вы уже видели: ru_RU.KOI8-R.
Как уже говорилось, стандарта на названия кодовых таблиц нет, тем более на название диалектов. То, что в шаблоне дано только 4 символа, ничего не означает - символов может быть и больше, и меньше. Квадратные скобки, как всегда, выделяют необязательные элементы. Обязательным в этом шаблоне является только название языка, но в некоторых источниках рекомендуется для русского языка указывать все три части. Напомню еще, что аббревиатура SU теперь означает Судан, а не нашу страну.
Форматы файлов шрифтов
В недавние времена буквально каждый графический редактор или издательская программа использовали свой формат файлов шрифтов и, как правило, одни программы не поддерживали форматы других. Со временем число реально используемых форматов существенно сократилось, так как происходит своеобразный "естественный отбор".
Графический режим
В графическом режиме нет разбиения экрана на знакоместа, изображение любого символа можно вывести практически в любую позицию экрана. Изображения символов для конкретного набора символов составляют шрифт. Шрифты хранятся в файлах, которые принято называть файлами шрифтов. Вывод символов того или иного шрифта на экран организуется с помощью специального сервера шрифтов. Поэтому проблема русификации графического режима сводится к выбору русифицированного шрифта. Вопрос о том, что такое шрифты и как работает сервер шрифтов, подробно рассмотрен ниже.
Будем предполагать, что вы можете
Будем предполагать, что вы можете получить права суперпользователя. В таком случае выполните команду su и проделайте следующее.
Создайте новый каталог и распакуйте в него полученный пакет шрифтов. Кстати, я встречал где-то рекомендацию, что лучше ставить новые шрифты в отдельный каталог, чтобы не нарушить работоспособность ранее установленных шрифтов. Можете последовать этому совету.
Перейдите в новый каталог (если не сделали этого ранее). Если производится инсталляция растровых шрифтов (когда в новом каталоге вы видите файлы с расширением pcf), то выполните в этом каталоге команду
[root]# mkfontdir
которая создает в каталоге со шрифтами файл fonts.dir.
Если производится инсталляция шрифтов Type1, то чтобы сделать эти шрифты доступными для X-Window, надо воспользоваться утилитой type1inst (ftp://ftp.metalab.unc.edu/pub/Linux/X11/xutils/), которая создаст файлы fonts.dir и fonts.scale. После установки утилиты просто перейдите в каталог с новыми шрифтами и запустите type1inst:
[root]# cd directory [root]# type1inst
Далее необходимо добавить имя нового каталога со шрифтами к перечню каталогов шрифтов. Если пакет xfs у вас уже запущен, вы можете сделать это путем редактирования конфигурационного файла /etc/X11/fs/config.
Теперь надо заставить шрифт-сервер перечитать перечень каталогов, что можно сделать командой:
[root]# /etc/rc.d/init.d/xfs restart
Ваши новые шрифты должны быть теперь доступны для X.
Если вы не используете шрифт-сервер, то вам необходимо добавить имя каталога, содержащего файлы Ваших новых шрифтов, к перечню каталогов шрифтов X-сервера в файле /etc/X11/XF86Config. Это можно сделать в каком-либо текстовом редакторе, а можно с помощью команды
[root]# xset fp+ /usr/share/fonts/new
(имя каталога будет добавлено в конец списка) или
[root]# xset +fp /usr/share/fonts/new
(имя каталога будет добавлено в начало списка). После этого надо дать команду
[root]# xset fp rehash
чтобы X-сервер нашел новые шрифты.
Инсталляция шрифтов TrueType
Мы подробно рассмотрим случай, когда используется дистрибутив, основанный на Red Hat, и фонт-сервер xfs.
Создайте новый каталог и распакуйте в него полученный пакет шрифтов. Для примера будем предполагать, что новые шрифты оказались в каталоге /usr/share/fonts/ttf.
Первым делом надо проверить, что в именах файлов шрифтов не встречаются заглавные буквы и пробелы (это требование xfs). Так что получите права суперпользователя, перейдите в каталог с вновь установленными шрифтами:
[root]# cd /usr/share/fonts/ttf
и, если в именах файлов встречаются заглавные буквы, преобразуйте все имена в нижний регистр. В http://pegasus.rutgers.edu/~elflord/font_howto приводится небольшой скрипт для автоматического преобразования имен файлов в нижний регистр, однако у меня этот скрипт отказался работать. Но в любом случае преобразовать имена и удалить пробелы из имен файлов можно и вручную.
Далее необходимо создать в каталоге со шрифтами True Type файлы fonts.scale и fonts.dir. Это, конечно, тоже можно сделать вручную, если вы внимательно прочитали весь предыдущий материал, но я, например, не хотел бы этим заниматься. Тем более, что существует утилита ttmkfdir, которую можно найти на многих сайтах с программным обеспечением для Linux. В Redhat эта утилита включена в состав rpm-пакета Freetype. Выполните следующие команды:
[root]# /usr/sbin/ttmkfdir -o fonts.scale [root]# mkfontdir
После этого в каталоге с новыми шрифтами True Type должны появится файлы fonts.dir и fonts.scale.
К сожалению, команды ttmkfdir и mkfontdir не всегда сообщают об ошибках, поэтому после их запуска необходимо убедиться, что нужные файлы созданы, не пусты и содержат корректно сформированные (т. е. соответствующие XLFD, смотри выше) наименования шрифтов. Как пишут авторы [http://pegasus.rutgers.edu/~elflord/font_howto, http://www.rodsbooks.com/wpfonts/], неприятности могут возникнуть потому, что иногда файлы шрифтов могут не в полной мере соответствовать формату True Type. Если такое имеет место, то описание этого шрифта, выдаваемое по команде ttmkfdir, будет существенно отличаться от формата описаний шрифтов, определяемого стандартом XLFD. Возможно, содержащееся в файле описание шрифта не корректно. Файлы шрифтов, вызывающие такой эффект, рекомендуется просто удалить. Поэтому до создания файла fonts.scale надо запустить программу ttmkfdir без параметров. В этом случае вывод идет на экран. Длина выдаваемых строк может отличаться, но их структура должна быть одинаковой и соответствовать стандарту XLFD. Если же какой-то из файлов со шрифтами вызывает появление в выводе чего-то другого, то такой файл лучше удалить. Только после этого можно выполнять команду
[root]# ttmkfdir -o fonts.scale
Еще одна причина возникновения проблем состоит в том, что ttmkfdir почему-то сортирует имена шрифтов в файле fonts.scale в обратном порядке. Этот факт не вызывает затруднений, если вы используете команду ttmkfdir в указанном выше формате. Но если вы попытаетесь подключить декоративные шрифты, которые часто содержат изображения не для всех возможных символов, то просто дать команду
[root]# ttmkfdir -o fonts.scale
уже недостаточно. Дело в том, что по умолчанию ttmkfdir допускает отсутствие в шрифте не более 5 символов. Но имеется специальная опция (-m nnn, где nnn - число), которая позволяет увеличить допустимое число отсутствующих изображений. Если запустить ttmkfdir в следующем виде:
[root]# ttmkfdir -m 100 -o fonts.scale
то созданный в том же каталоге и при тех же файлах шрифтов файл fonts.scale получится гораздо большего объема, т. е. будет содержать больше наименований шрифтов. При этом, как раз из-за обратного порядка перечисления имен, файлы с неполным набором символов окажутся в начале файла fonts.scale. В силу этого приложения могут быть "введены в заблуждение" и "схватить" первый попавшийся (в данном случае - неполный) шрифт. Тогда вместо отсутствующих символов вы увидите просто пробелы. Впрочем, с этой проблемой нетрудно справиться. Просто после создания файла fonts.scale надо изменить порядок строк в нем, для чего после выполнения команды
[root]# ttmkfdir -m 100 -o fonts.scale
надо сделать следующее:
Выполнить команду [root]# tac fonts.scale > fonts.dirПеренести строку с числом шрифтов из конца полученного таким образом файла fonts.dir в его начало;Убедиться, что файл fonts.dir заканчивается символом конца строки.
Теперь мы имеем корректно сформированный файл fonts.dir! Но список в файле fonts.scale все еще имеет обратный порядок. Однако, поскольку эти два файла (по крайней мере в данном случае) должны быть идентичны, то остается только выполнить команду
[root]# cat fonts.dir > fonts.scale
или
[root]# cp fonts.dir fonts.scale
Следующий шаг, вообще говоря, не является обязательным, но позволяет в некоторых случаях повысить читаемость шрифтов на экране. Этот шаг заключается в создании файла fonts.alias в каталоге с TT-шрифтами (или в корректировке существующего файла). О том, как это можно сделать, говорилось выше. В том же разделе упоминался скрипт, который позволяет (по словам автора интернет-страницы http://home.c2i.net/dark/linux.html#ttf легко создать файл fonts.alias в каталоге со шрифтами True Type. Полученный с помощью скрипта файл fonts.alias может оказаться очень большим, особенно если создавали файл fonts.dir (который используется скриптом как основа для создания fonts.alias) с помощью команды ttmkfdir с опцией "-m 100". Да и без этого в нем окажется масса имен шрифтов, которые вы никогда не будете использовать. Поскольку в типичном случае вполне достаточно только кириллических шрифтов, можно попробовать удалить из fonts.alias все неиспользуемые шрифты с помощью следующей последовательности команд (оставляем только кириллические шрифты):
[root]# grep 'iso8859-5"' fonts.alias > newfonts.alias [root]# grep 'koi8-r"' fonts.alias >> newfonts.alias [root]# cat newfonts.alias > fonts.alias
Возможно, этот же прием стоит применить к файлам fonts.dir и fonts.scale, только предварительно продумав все последствия. Если вы войдете в азарт и захотите провести такие же корректировки не только в каталогах со шрифтами True Type, но в других каталогах со шрифтами, то, по крайней мере, не забывайте, что нельзя просто удалить шрифты, которые имеют в качестве второго имени (синонима) названия cursor, fixed и variable.
Теперь вы можете добавить новый каталог к перечню каталогов шрифтов xfs. Пользователи дистрибутивов, основанных на Redhat, могут сделать это с помощью утилиты chkfontpath (она тоже входит в пакет Freetype):
[root]# /usr/sbin/chkfontpath --add /usr/share/fonts/ttf
Если такой утилиты нет, это можно сделать редактированием конфигурационного файла фонт-сервера xfs, а именно, файла /etc/X11/fs/config. (Помните, что имена каталогов в перечне НЕ ДОЛЖНЫ иметь слэша (/) в конце!)
После этого осталось только перестартовать фонт-сервер xfs. Если вы пользовались утилитой chkfontpath, то она осуществляет рестарт xfs автоматически. Если вы вручную редактировали перечень каталогов со шрифтами, то перестартовать xfs можно командой
[root]# /etc/rc.d/init.d/xfs restart
После того, как вы перезапустили xfs, перезапустите также X-сессию.
На этом все! Вы можете проверить, подключились ли новые шрифты с помощью команды xlsfonts. Например, если среди устанавливаемых шрифтов должны были быть шрифты arial, можно выполнить команду:
[root]# xlsfonts | grep arial
(можно также воспользоваться командой xfontsel). Если новые шрифты видны через xlsfonts, тогда они доступны и для X Window, и наоборот.
Теперь, когда шрифты True Type установлены, вы можете попробовать, как они работают, например, в Netscape.
Запустите Netscape.Откройте окно "Preferences/Appearence/Fonts" и раскройте выпадающий список "Variable Width Fonts". Там теперь должны появиться вновь установленные шрифты (я, например, увидел "Verdana (Microsoft)", именно тот единственный ttf-шрифт, который устанавливал). Выберите один из них.Разрешите масштабирование, нажав кнопку "Allow Scaling" рядом со списком "Variable Width Font".Установите опцию "Use my default fonts".Затем выберите размер 12 в выпадающем списке справа.Щелкните по кнопке OK.
Теперь текст в окне Netscape должен отображаться выбранным Вами шрифтом.
IrcII
Добавить в файл конфигурации ~/.ircrc следующие строчки:
/set translation russian /set eight_bit_characters on
Источники шрифтов
Итак, вы удалили ненужные вам шрифты. Теперь предположим, что вы хотите добавить в набор шрифтов вашей системы какие-то новые шрифты (скорее всего кириллические). Вначале возникает вопрос, где их взять.
Очень часто большие коллекции шрифтов поставляются вместе с некоторыми графическими, издательскими или офисными программами. Примером может служить Microsoft Office или Corel Draw, в состав поставки которого входит громадный набор шрифтов. Если пакет русифицирован, то в этом наборе шрифтов найдутся и кириллические шрифты.
В Internet тоже существует громадный выбор бесплатных или условно-бесплатных шрифтов, однако не многие из них являются кириллическими. Адреса наиболее крупных и полезных сайтов с кириллическими шрифтами перечислены ниже.
Паратайп (http://www.paratype.com/) - Сайт отечественной компании, занимающейся созданием кириллических шрифтов. На данном сайте можно заказать как шрифты, так и диспетчеры шрифтов и редакторы шрифтов.Веди (http://www.vedi.d-s.ru/obzory/f_art/fart1.htm) - Сайт независимого центра по разработке и распространению кириллических шрифтов.sunsite.unc.edu (ftp://sunsite.unc.edu/pub/Linux/X11/fonts/) - Здесь есть несколько пакетов кириллических шрифтов.Freshmeat (http://freshmeat.net/) - Задайте поиск по слову "font" и вы найдете несколько пакетов кириллических шрифтов.www.funet.fi (http://www.funet.fi/pub/culture/russian/comp/fonts/) - Архив, предоставляющий довольно неплохой выбор кириллических шрифтов.КиАрхив (http://ftp.kiae.su/pub/linux/) - На КиАрхив тоже проще всего воспользоваться предоставляемой там возможностью поиска. Там имеется, в частности, классический набор шрифтов от Cronyx.На странице Д.Болховитянова CYR-RFX (ftp://ftp.inp.nsk.su/pub/BINP/X11/fonts/cyr-rfx/doc/README.ru.html) вы найдете разработанные им шрифты.
В этот список включены далеко не все сайты, на которых имеются кириллические шрифты.
Кроме того, существует много сайтов со шрифтами для английского и других языков. Конечно, коллекции англоязычных шрифтов гораздо богаче, чем для русского языка. Если вы хотите отыскать какой-то конкретный шрифт для латиницы или просто пополнить свою коллекцию таких шрифтов, начните поиск с одного из следующих сайтов:
http://www.007fonts.com/,
http://www.freewarefonts.com/,
http://www.1001freefonts.com/,
http://www.fontfreak.com/,
http://www.freewareconnection.com/fonts.html.
После того, как вы скачали пакет шрифтов, можно приступить к его инсталляции. Процедура инсталляции несколько отличается для шрифтов Type 1 и True Type, поэтому рассмотрим эти два случая отдельно.
Как это сделано в дистрибутиве Black Cat
Во-первых, в файле /etc/sysconfig/i18n вводится новая переменная: в версии 5.2 это переменная SCRNMAP, а в версии 6.02 - SYSFONTACM. Этой переменной по умолчанию присваивается значение "koi2alt". Вот стандартный файл i18n из Black Cat Linux версии 6.02:
LANG=ru LINGUAS=ru LC_ALL=ru_RU.KOI8-R SYSFONT=RUSCII_8x16 SYSFONTACM=koi2alt
Вызов файла i18n для задания значений переменных осуществляется из скрипта /sbin/setsysfont, из которого вызываются также команды setfont и mapscrn (в версии 5.2) или consolechars (в версии 6.0). Вот этот скрипт из Black Cat Linux версии 5.2:
----------------------------------- #!/bin/sh if [ -f /etc/sysconfig/i18n ]; then . /etc/sysconfig/i18n fi if [ -x /usr/bin/setfont ]; then if [ -n "$SYSFONT" ]; then /usr/bin/setfont $SYSFONT fi if [ -x /usr/bin/mapscrn ]; then if [ -n "$SCRNMAP" ]; then /usr/bin/mapscrn $SCRNMAP fi fi else echo "can't set font" exit 1 fi ------------------------------------
Как видно, при вызова скрипта /sbin/setsysfont выполняются команды "setfont Cyr_a8x16" и "mapscrn koi2alt". После этого, для включения в ядре кодовой таблицы пользователя, необходимо выдать на каждую виртуальную консоль последовательность "\033(K". Это реализовано путем добавления этой последовательности к файлу /etc/issue, который генерируется при загрузке системы скриптом /etc/rc.d/rc.local и вызывается на исполнение при логировании каждого пользователя. Вот пример скрипта /etc/rc.d/rc.local из версии 5.2:
------------------------------------- #!/bin/sh # This script will be executed *after* all the other init scripts. # You can put your own initialization stuff in here if you don't # want to do the full Sys V style init stuff. if [ -f /etc/blackcat-release ]; then R=$(cat /etc/blackcat-release) elif [ -f /etc/redhat-release ]; then R=$(cat /etc/redhat-release) else R="release 3.0.3" fi arch=$(uname -m) a="a" case "_$arch" in _a*) a="an";; _i*) a="an";; esac # This will overwrite /etc/issue at every boot. So, make any changes you # want to make to /etc/issue here or you will lose them when you reboot. . /etc/sysconfig/i18n echo "" > /etc/issue.net echo "Black Cat Linux $R" >> /etc/issue.net echo "Kernel $(uname -r) on $a $(uname -m)" >> /etc/issue.net if [ -n "$SCRNMAP" ]; then echo -ne "\033(K" > /etc/issue else echo "" > /etc/issue fi if [ -f /usr/bin/linux_logo ]; then /usr/bin/linux_logo -n -o 2 >> /etc/issue echo "" >> /etc/issue fi cat /etc/issue.net >> /etc/issue echo "" >> /etc/issue -------------------------------------
В версии 6.02 все происходит примерно так же. Просмотрите упомянутые выше файлы, и вы убедитесь в этом сами.
Какие шрифты имеются в Вашей системе?
Давайте теперь посмотрим, какие шрифты установлены в системе. Поскольку вы уже знаете (загляните еще раз в FontPath), в каких каталогах находятся файлы шрифтов, вы можете непосредственно просмотреть эти каталоги. Но одного наличия файла со шрифтом еще недостаточно для того, чтобы шрифт был доступен для X-сервера. Для того, чтобы увидеть список шрифтов, известных X-серверу, лучше воспользоваться командой xlsfonts, которая выводит на экран перечень таких шрифтов. Если запустить ее с опцией -lll, то она дополнительно выдаст массу информации о каждом шрифте. Перенаправьте вывод в файл :
[root]# xlsfonts > fontlist
и вы получите список доступных шрифтов в файле fontlist.
Но для того, чтобы этот список прочитать, надо иметь представление о том, как именуются шрифты. Без этого прочитать полученный файл fontlist будет очень трудно.
Существует стандарт консорциума X (X Consortium) на имена шрифтов для X Window System, который называется X Logical Font Description Conventions (обычно упоминаемый как XLFD). Полное описание его дано в ftp://ftp.x.org/pub/R6.4/xc/doc/hardcopy/XLFD/xlfd.PS.gz. В соответствии с этим стандартом имя шрифта состоит из 14 полей:
foundry (fndry) - производитель шрифта (Adobe, Bitstream и т.п.);family (fmly) - название семейства шрифтов (например, Times);weight (wght) - толщина (bold, demibold, medium);slant (slant) - наклон (roman, italic, oblique);set width (sWdth) - ширина (normal, condensed, double wide);add style (adstyl) - стиль (serif, sans serif, decorated);pixel size (pxlsz) - размер символа по вертикали (в пикселах, 0 означает масштабируемый шрифт);point size (ptSz) - размер символа по горизонтали;resolutionX (resx) - разрешение по горизонтали;resolutionY (resy) - разрешение по вертикали;spacing (spc) - ширина символов (пропорциональный, моноширинный);avg width (avgWdth) - среднее значение ширины глифов шрифта;registry (rgstry) - название стандарта на кодировку символов (koi8, iso8859);encoding (encdng) - язык или кодовая страница (r, u).
Здесь в начале каждой строки указано наименование поля, затем (в скобках) сокращение этого наименования, используемое в программе xfontsel (о ней чуть ниже), после чего дается перевод (приблизительный) наименования поля. В скобках после русского перевода названия поля приводится по несколько примеров возможных значений этого поля, которые поясняют его назначение.
При задании конкретного шрифта поля в его имени принято разделять дефисами. Приведем пару примеров имен в стандарте XLFD:
-adobe-times-medium-r-normal-*-14-140-75-75-p-74-iso8859-1 -misc-fixed-medium-i-semicondensed-*-13-120-75-75-c-60-koi8-r -adobe-courier-bold-o-normal-*-10-100-75-75-M-60-iso8859-1
(если какое-то поле не определено, то в соответствующей позиции ставится звездочка; таким образом можно одной строкой задать множество шрифтов).
В качестве параметра команде xlsfonts можно указать имя конкретного шрифта или семейства шрифтов (этой возможностью просто необходимо воспользоваться, если вы задали опцию -lll, иначе масса полученной информации окажется слишком велика).
Но просмотр списка шрифтов, выдаваемого командой xlsfonts, мало информативен в том смысле, что при этом вы не видите изображений символов, которые будет давать на экране данный шрифт. В этом плане гораздо удобнее воспользоваться программой xfontsel, которая работает в графическом режиме и выводит в своем окошке изображения некоторых символов данного шрифта, позволяющих представить себе, как будет выглядеть выводимый текст.
Эти две команды могут оказаться полезными, как для определения того, какие шрифты уже имеются в системе, так и для проверки того, что новые шрифты успешно установились. Я не буду здесь подробно описывать, как пользоваться этими командами. Воспользуйтесь соответствующими man-страницами или системой info.
На мой взгляд, пользователь обычно руководствуется в выборе шрифта только следующими признаками из перечисленных выше: семейство шрифтов (fmly), вариант шрифта - жирный шрифт или обычный (wght), наклон (slant), ширина шрифта (sWdth), размер шрифта в пикселах (pxlsz), стандарт (rgstry) и язык (encdng).
Попробуйте выбирать разные значения этих параметров в программе xfontsel и вы получите неплохое представление о том, какие шрифты установлены в вашей системе. Для русскоязычных пользователей выбор шрифта для просмотра стоит начать с двух последних полей. Задайте для поля rgstry значение koi8, а для поля encdng - значение r, и вы увидите сколько русскоязычных шрифтов в кодировке koi8-r у вас установлено. Кириллические шрифты задаются также значениями iso8859-5 в двух последних полях.
Кроме xlsfonts и xfontsel cуществуют еще несколько программ для просмотра установленных в системе шрифтов.
Чтобы увидеть полный набор символов шрифта, можно воспользоваться командой xfd -fn fontname. В качестве fontname здесь можно использовать как полное имя шрифта, так и строку с символами маскирования (*), а также синонимы имен шрифтов, заданные в файле font.alias. Пример: xfd -fn -*-helvetica-medium-r-* &В графической среде KDE имеется Менеджер шрифтов, который тоже показывает все установленные шрифты, а также позволяет удалить некоторые (но устанавливать новые, кажется, не умеет!).В Gnome имеются утилиты font selector, character picker и gfontview.
Кириллизация печати
До сих пор наше внимание было сосредоточено на выводе текста на экран. Однако, когда мы говорим об использовании шрифтов, нельзя совсем уж оставить в стороне вопрос о том, как можно организовать печать на принтере различными шрифтами.
В отличие от других операционных систем (например, Windows и MacOS), Linux, как и другие UNIX-системы, не имеет аппаратно-независимой подсистемы печати. Некоторые приложения сами обеспечивают поддержку печати, но большая часть приложений предполагает, что принтер обладает возможностью интерпретировать язык Adobe PostScript. Но принтеры со встроенными PostScript-интерпретаторами достаточно дороги и довольно редко встречаются в наше время. Для того, чтобы можно было использовать другие типы принтеров, была разработана специальная программа, Ghostscript, которая может интерпретировать код PostScript, преобразовывать контурный шрифт в растровый, формировать соответствующие команды для принтера, обеспечивая тем самым печать на большинстве типов принтеров.
Поскольку все версии PostScript и Ghostscript поддерживают как шрифты Type 1 и Type 42, а Ghostscript версии 4 и выше поддерживает и шрифты True Type, то больших трудностей с организацией красивой печати под Linux не возникает. По умолчанию (в Red Hat) шрифты для Ghostscript устанавливаются в каталог /usr/share/fonts/defaults/ghostscript/. Поэтому если вы хотите добавить какие-то шрифты для печати, поместите файлы новых шрифтов в этот каталог или создайте в нем символические ссылки на новые шрифты. Впрочем, можно поместить файлы шрифтов и в другие каталоги, но тогда нужно будет указывать точный путь к шрифтам в файле /usr/share/ghostscript/N.M/Fontmap, который делает шрифты доступными для Ghostscript.
Например, для того, чтобы добавить шрифт Times New Roman и его варианты, скопируйте файлы times.ttf, timesbd.ttf, timesbi.ttf, и timesi.ttf в каталог /usr/share/fonts/defaults/ghostscript/ и добавьте следующие строки в файл Fontmap
/Times New Roman (times.ttf); /Times New Roman Bold (timesbd.ttf); /Times New Roman Bold Italic (timesbi.ttf); /Times New Roman Italic (timesi.ttf);
Более подробные инструкции вы найдете в документации к программе Ghostscript и в лекции 9.
Конечно, я рассказал далеко не обо всех моментах, связанных с подключением новых и использованием имеющихся шрифтов для системы X Window. Например, за рамками рассмотрения остались вопросы настройки шрифтов в конкретных приложениях, а также вопросы преобразования шрифтов True Type в шрифты Type1. Но все изложить невозможно, поэтому остается только отослать читателя к списку доступной литературы приложения).
Более подробные инструкции вы найдете в документации к программе Ghostscript и в лекции 9.
Конечно, я рассказал далеко не обо всех моментах, связанных с подключением новых и использованием имеющихся шрифтов для системы X Window. Например, за рамками рассмотрения остались вопросы настройки шрифтов в конкретных приложениях, а также вопросы преобразования шрифтов True Type в шрифты Type1. Но все изложить невозможно, поэтому остается только отослать читателя к списку доступной литературы приложения).
|
|
|
К сожалению, это мое предсказание не сбылось - Е.Балдин так и не закончил работу над Ciryllic HOWTO. Правда, с одной стороны вопрос оказался сложнее, чем первоначально казалось, из-за непоследовательности в развитии ПО, а с другой стороны, актуальность вопроса снизилась в силу того, что появились хорошо русифицированные дистрибутивы, а также потому, что Линукс начал движение в сторону UNICODE.
| © 2003-2007 INTUIT.ru. Все права защищены. |
Кириллизация shell и других программ
К сожалению, в Linux нет единой системы работы со шрифтами. Каждую отдельную программу, каждое приложение надо отдельно настраивать для того, чтобы эта программа могла использовать шрифты True Type, Type 1 или какие-то другие, почему-либо привлекательные для вас. И в каждой программе это может делаться по-своему! Я приведу здесь краткие рекомендации по русификации некоторых наиболее употребительных программ. Эти рекомендации заимствованы из http://www.inp.nsk.su/~baldin. Однако, перечень этот далеко не полон, так что ответы на те вопросы, которые мне не удалось осветить, ищите в источниках, ссылки на которые приведены в конце книги.
Для полноценной работы с кириллицей в текстовом режиме необходимо, чтобы программы умели интерпретировать значения 8-го бита в коде ASCII (напомним, что первоначально этот код был 7-ми битным). Вот этого давайте и добьемся.
Конфигурация X-сервера
Теперь, когда введены все используемые в последующем термины и даны необходимые сведения о форматах шрифтов, можно перейти к рассмотрению того, как настроить ваш Linux на корректную работу со шрифтами. При этом я буду ориентироваться на пользователей дистрибутива Red Hat и его аналогов (я проверял изложенные ниже рекомендации на дистрибутиве Black Cat 6.02).
Выводом изображений и, в частности, изображений символов, на экран занимается X-сервер. Когда приложение обращается к X-серверу с требованием вывести на экран какой-то текст, X-сервер обращается к своему конфигурационному файлу XF86Config, в котором должен быть определен перечень каталогов со шрифтами (FontPath). Откройте файл XF86Config (обычно он находится в каталоге /etc/X11/ или /usr/X11R6/lib/X11/) с помощью любого текстового редактора. Недалеко от начала файла в секции "Files" вы должны увидеть примерно такие строки:
FontPath "/usr/X11R6/lib/X11/fonts/misc/" FontPath "/usr/X11R6/lib/X11/fonts/Type1/" FontPath "/usr/X11R6/lib/X11/fonts/Speedo/" FontPath "/usr/X11R6/lib/X11/fonts/75dpi/" FontPath "/usr/X11R6/lib/X11/fonts/100dpi/"
Это и есть перечень каталогов шрифтов X-сервера, который в англоязычной документации называется коротко FontPath. Порядок перечисления каталогов в этом перечне существенен: когда приложение запрашивает вывод текста на экран определенным шрифтом, X-сервер поочередно просматривает каталоги из FontPath и использует для вывода текста первый шрифт, который соответствует запросу приложения.
Если используются установки, задаваемые по умолчанию, то растровые шрифты с разрешением 75 DPI обычно оказываются размещены в этом перечне перед шрифтами с разрешением 100 DPI. Следствием этого может оказаться то, что на экранах с высоким разрешением символы будут очень маленькими. Если такой эффект у вас проявляется, поменяйте порядок перечисления каталогов в FontPath.
Еще один момент, относящийся к растровым шрифтам, связан с их масштабированием. При отображении символов большого размера с помощью таких шрифтов может оказаться, что изображение символа распадается на отдельные точки. Этот эффект проявляется, например, в Netscape при выводе крупных заголовков. Чтобы избежать этого, вы можете указать после имени каталога ключевое слово "unscaled" (не масштабировать), отделив его двоеточием:
FontPath "/usr/X11R6/lib/X11/fonts/misc/:unscaled" FontPath "/usr/X11R6/lib/X11/fonts/100dpi/:unscaled" FontPath "/usr/X11R6/lib/X11/fonts/75dpi/:unscaled" FontPath "/usr/X11R6/lib/X11/fonts/Type1/" FontPath "/usr/X11R6/lib/X11/fonts/Speedo/" FontPath "/usr/X11R6/lib/X11/fonts/misc/" FontPath "/usr/X11R6/lib/X11/fonts/100dpi/" FontPath "/usr/X11R6/lib/X11/fonts/75dpi/"
При этом можно, как в приведенном выше примере, указать как возможность использования масштабируемых, так и немасштабируемых шрифтов, определив свои предпочтения порядком перечисления строк в XF86Config.
Кстати, раз уж вы заглянули в XF86Config, неплохо заодно проверить и другие установки, определяющие конфигурацию X-сервера. Неправильное задание параметров работы монитора может доставить гораздо больше головной боли, чем неправильный выбор шрифта. В частности, убедитесь, что частота обновления экрана выбрана максимально возможной для вашей аппаратной конфигурации (85 Hz - это великолепно, 75 Hz - неплохо, а 60 Hz - это просто вредно для вашего зрения).
Less
Если локализация не настроена (а она обязана быть настроенной), то вывод кириллицы через less можно получить, установив переменную окружения LESSCHARSET:
export LESSCHARSET=koi8-r
Это решение годится для всех 8-битовых кириллических кодировок.
При правильно настроенной локализации указывать LESSCHARSET НЕ НАДО. Более того, в ~/.lesskey надо добавить
#env LESSCHARSET=
чтобы программа игнорировала установку LESSCHARSET= другими "глупыми" программами (к примеру, man). После этого надо запустить lesskey для получения бинарного файла ~/.less. В противном случае он не будет вызывать setlocale(LC_CTYPE,"") и, как следствие, не будет icase search для русских букв.
Локализация
Только организовать ввод и вывод символов национального языка еще недостаточно для того, чтобы можно было считать решенным проблему применения компьютеров в той или иной стране. В разных странах в силу сложившихся традиций имеются различия не только в используемом алфавите, но и в способах представления некоторых конкретных данных. Это касается, например, символов, используемых для обозначения валюты, форматов представления даты и времени, обычаев записи (чтения) текстов слева направо или справа налево и т.д. При создании ПО, рассчитанного на применение в разных странах, приходится учитывать такие местные особенности. Кроме того, большие трудности вызывают такие вопросы как проверка орфографии на конкретном языке, автоматическая расстановка переносов при вводе текста или перевод на данный язык всех меню и служебных сообщений в программном обеспечении.
Способ проектирования ПО (включая ОС), при котором возможность многоязыковой поддержки закладывается с самого начала, принято называть интернационализацией (кстати, загадочное i18n - это просто сокращение для слова internationalization: i - потом еще 18 букв - n, аналогично, 110n = localization). При интернационализации программного обеспечения КОД не зависит от национальных особенностей. Все языково-зависимые данные сосредотачиваются в особых "объектах локализации", которые разбиты на функциональные группы: категории локализации. При таком подходе локализация - это процесс настройки программной системы на особенности конкретной страны.
В стандарте POSIX (Portable Operating System) были определены средства локализации, которые состоят из следующих компонент:
набор библиотечных (libc) вызовов (locale API): setlocale(), isalpha(), toupper(), и т.д;исходные тексты описания средств локализации, в том числе файл(ы) описания кодировки (Character Set Definition File);наборы данных для локализации, которые в Linux размещаются в каталогах /usr/share/i18n/* и /usr/share/locale/*;утилита для получения информации о средствах локализации: locale;утилита для изготовления (компиляции) объектов локализации: localedef;переменные окружения, для управления средствами локализации: LANG, LC_ALL, LC_CTYPE, LC_TIME, LC_COLLATE, LC_NUMERIC и LC_MONETARY (они соответствуют категориям локализации).
В табл.11. 1 кратко перечислено, на что именно влияет та или иная из этих переменных (или категорий локализации).
| LC_CTYPE | Определяет правила классификации и преобразования одиночных символов. Позволяет правильно определять вид символа: цифра, буква, значок, заглавная буква или прописная и т.д. Другими словами, включает правильную работу системных вызовов isalnum(), isalpha(), iscntrl(), isdigit(), ... и т.п. для местного алфавита. Вдобавок, включает правильный перевод строчных - прописных букв: toupper() и tolower() |
| LC_COLLATE | Определяет правила сравнения и преобразования строк. Позволяет определять лексикографический порядок символов (порядок сортировки) в местном алфавите. Включает правильную работу strcoll() и strxfrm(). Оказывает непосредственное влияние на работу утилит типа sort и т.д |
| LC_TIME | Определяет правила национального представления времени и даты. Задает именование дней недели, месяцев и т.п. а также задает способ написания даты и времени (12/24). Hепосредственно влияет на strftime(), а через нее на утилиты date и т.д. |
| LC_NUMERIC | Определяет правила национального представления чисел с плавающей точкой. Влияет на strtod() и форматы %f и %g printf(), scanf() |
| LC_MONETARY | Определяет правила национального представления денежных величин |
Заметим, что включение средств локализации изменяет также некоторые пути поиска, в частности, пути поиска к файлам помощи (man-страницам), так что вначале команда man ищет переведенные man-страницы и только при их отсутствии выдает информацию на английском.
Подводя краткий итог всему вышеизложенному, можно сказать, что процедура русификации системы состоит из следующих этапов:
настройка средств локализации;русификация текстового режима (консоли);русификация графического режима;русификация используемого ПО;русификация процесса печати.
В последующих разделах каждый из этих этапов рассматривается по отдельности.
Ls
Если локализация настроена неправильно, то ls не будет печатать кириллические символы. В этом случае, возможно, поможет одна из следующих команд: ls -N, dir -N или ls --show-control-chars.
Man
В последнее время появляется все больше и больше man-статей, переведенных на русский язык, но вот отобразить их не всегда удается. Для исправления этого неудобства следует поправить соответствующие строки в /usr/lib/man.config, если этот файл есть, или правильно настроить less.
Mc (The Midnight Commander)
Чтобы корректно отображался текст кириллицы, необходимо установить флажки в опции Полный 8-битный вывод (full 8 bits) и Полный 8-битный ввод в команде меню Настройки | Биты символов (Options | Display).
Метафонт
Метафонт был разработан Дональдом Кнутом (Donald E Knuth) как часть его типографской системы TEX. Метафонт - это язык программирования графики (a graphics programming language), подобный Postscript. Сфера применения этого языка шире, чем просто вывод изображений символов. У метафонта имеется ряд очень привлекательных качеств. Одна из очень важных особенностей, - то, что масштабирование выполняется очень изящно. Символы метафонта Computer Modern имеют различный вид при размере 20 точек и 10 точек. Изображения символов изменяются при изменении размера, потому что для малых размеров желательно увеличить ширину несколько больше, чем высоту (это делает символы больших размеров более элегантными, а символы маленьких размеров более читабельными).
Файлы метафонтов обычно имеют расширение mf. При выводе на печать или экран они преобразуются в растровые шрифты, определяемые устройством вывода. Это преобразование, хотя и дает высокое качество, осуществляется медленно, так что эти шрифты не очень удобны для использования в WYSIWYG-приложениях.
Немного о терминологии
Для начала надо пояснить некоторые термины, часть из которых появилась еще в те времена, когда типографии называли словолитнями, а часть - уже в наше время, вместе с широким внедрением компьютеров в типографское дело. Некоторые из этих терминов получены прямым заимствованием из английского языка, например, фонт-сервер, рендеринг, глиф.
Пожалуй, важнейшим типографским термином является шрифт. В обычном, или "бытовом", если так можно выразиться, понимании шрифт - это только набор графических изображений символов, который служит для представления букв на бумаге или другой поверхности (например, экране, причем экране в широком смысле слова - экране кино, телевизора, компьютера). Поскольку можно сказать, что шрифты появились вместе с изобретением книгопечатания, история разработки и создания шрифтов исчисляется уже веками. За это время создание шрифтов превратилось в особый вид деятельности (может быть, даже в отрасль науки) со своей терминологией, инструментарием, традициями, школами и т.д. Новый импульс эта наука получила с переходом на компьютерные технологии.
|
Субъективное замечание: Вместе с широким распространением компьютеров в русском языке появился новый термин - фонт. Первоначально это была простая подмена русскоязычного термина его английским эквивалентом, применявшаяся только в компьютерном сленге. Однако постепенно стало проявляться различие в употреблении этих терминов. Понятие "фонт" стало охватывать понятие "шрифт", но начало трактоваться в более широком смысле, подразумевая не только собственно шрифт, как набор изображений символов, но и способ формирования этих изображений на экране и/или бумаге, и способ сохранения этих изображений в файле. Кроме того, словом "фонт" называют просто файл, содержащий закодированные неким образом изображения символов шрифта (например, битовые карты изображений символов). Мне кажется, что в последнем случае правильнее употреблять термин "файл фонта", а термин "фонт" следует употреблять во втором смысле: как совокупность собственно шрифта (как набора изображений символов), способа вывода этих изображений символов на печать или экран и способа сохранения шрифта в виде файла. Таким образом, можно сказать, что шрифт - понятие типографское, а фонт - компьютерное. Впрочем, такая трактовка этих терминов не является пока общепринятой и всюду ниже употребляется единый термин - шрифт. |
Существует два основных типа шрифтов: растровые и контурные (их еще называют векторными).
В растровых шрифтах изображение символа составляется из отдельных точек и сохраняется в файле в виде двоичной матрицы или "битовой карты" (bitmap). Поэтому такие шрифты можно назвать матричными. Растровые шрифты являются аппаратно-зависимыми - они предназначены для получения только определенных разрешений. Матричный шрифт с разрешением 75 точек на дюйм (75 DPI) даст только 75 точек на дюйм даже на принтере, обеспечивающем разрешение 1200 DPI. Для обеспечения возможности изменения размера шрифта приходится либо хранить в файле битовые карты для разных размеров шрифта, либо изображение приходится увеличивать или уменьшать в целое число раз, что приводит к деформации изображений символов. Кроме того, при использовании растровых шрифтов для печати необходимы дополнительные принтерные шрифты, соответствующие экранным.
Матричные экранные шрифты обычно используются в терминальных окнах, в консоли и в простых текстовых редакторах, где отсутствие масштабируемости и тот факт, что они не могут использоваться для печати, не так существенны.
В контурных (или векторных) шрифтах для вывода изображения символа применяется математический аппарат, основанный на использовании кривых Безье. Как известно, для описания прямой линии нам необходимо и достаточно задать только две точки - начало и конец прямой. Кривая Безье задается своими начальной и конечной точками, и, кроме того, набором промежуточных точек, к которым стремится данная кривая. Регулируя отклонение кривой от этих промежуточных точек, можно достичь гладких изгибов кривой Безье. Каждый символ (точнее говоря, глиф, см. ниже) контурного шрифта представляется набором контуров, задающих границы изображения. Контуры описываются замкнутыми кривыми Безье. При выводе изображения на экран или принтер производится преобразование заданного таким образом изображения символа в матрицу точек (грубо говоря, в растровое изображение соответствующего размера).
Достоинством контурных шрифтов является их независимость от устройства вывода - они одинаково выглядят как на экране, так и на принтере. Каждый символ может иметь различное начертание: курсив, полужирный, подчеркивание и обычное. Кроме того, он может иметь абсолютно любой размер (т. е. эти шрифты являются масштабируемыми), что невозможно в случае с растровыми шрифтами.
Отдельным элементом контурного шрифта, выводимым на экран или принтер, является не символ, что казалось бы более естественным для незнакомого с предметом человека, а так называемый глиф (этот термин является прямым заимствованием соответствующего английского термина "glyph"). Глиф может представлять либо отдельный символ, либо два или большее число символов (так называемые лигатуры), либо часть изображения символа.
Еще одно понятие, которое необходимо для описания и классификации шрифтов - это сериф. Серифы - это небольшие выступы у оснований символов и в верхней части изображений символов. Например, буква "i" в таких шрифтах как Times Roman имеет серифы у основания и в верхней части вертикальной черты. Серифы появились в изображениях символов шрифтов относительно недавно и позволили улучшить зрительное восприятие символов. Шрифты, в которых используются серифы, считаются более читабельными, чем шрифты без серифов. При малых размерах символов серифы обычно не используются, так как отсутствие лишних элементов позволяет легче их воспринимать. Например, фирма Microsoft рекомендует шрифт Verdana как наиболее подходящий для очень малых размеров символов при выводе на экран.
Межсимвольное расстояние задает интервал, на который символы шрифта отстоят друг от друга. Бывают шрифты с фиксированным межсимвольным расстоянием и фиксированным размером символов (речь идет о ширине, высота символов у обычных шрифтов и так фиксирована) или fixed width fonts, и шрифты переменной ширины - variable width fonts. Шрифт фиксированной ширины выглядят как текст, напечатанный на пишущей машинке, поскольку все буквы имеют одну и ту же ширину. Это качество желательно для таких применений как компьютерная консоль, но нежелательно для больших печатных документов. Шрифты с фиксированной шириной символов часто используются, например, в примерах, иллюстрирующих компьютерные команды.
В шрифтах переменной ширины для повышения читабельности и улучшения внешнего вида текста варьируется как ширина отдельных символов, так и межсимвольное расстояние, для чего используется техника трекинга и кернинга.
Трекинг - это специальные приемы улучшения оптических свойств текста при больших и малых размерах за счет изменения расстояния между символами. Трекинг определяет межсимвольное расстояние как функцию от размера шрифта.
Кернинг улучшает качество восприятия текста, изменяя межсимвольное расстояние в некоторых парах символов, которые называются парами кернинга. Например, при изображении пары символов "То" маленькая буква "о" должна быть приближена к заглавной "Т", и даже размещаться частично "под" этой "Т", что повышает качество изображения.
Для достижения наилучшего качества отображения символов шрифта при работе с малыми размерами используется такое средство, как хинтинг (hinting). При отображении символа в малом размере учитывают, какие части контура символа следует использовать, а какие нет. Для этого в описание контура символа помещаются "хинты" - специальные инструкции, указывающие каким образом надо изменять форму контура для достижения наилучшего качества. Как правило, редакторы шрифтов сами выполняют хинтинг, избавляя пользователя от дополнительной работы над шрифтом.
Совокупность данных о ширине символов, межсимвольном расстоянии, а также информации, необходимой для кернинга и трекинга, называют метриками шрифта.
Варианты шрифтов. Каждый шрифт обычно содержит несколько вариантов изображений каждого символа. Большинство шрифтов содержат такие варианты как полужирный (bold), курсив (italic) и полужирный курсив (bold-italic). Некоторые шрифты имеют дополнительные варианты, например, жирный или small caps, когда строчные буквы заменяются уменьшенными заглавными (этот вариант шрифта чаще всего используется для создания заголовков).
Nroff
Для того, чтобы через nroff можно было "пропустить" символы кириллицы, надо использовать его с ключом -Tlatin1. Пропишите где-нибудь в стартовом скрипте (если у вас bash, то в .bashrc)
alias nroff='nroff -Tlatin1'
Просмотр некоторых файлов в mc запускается через nroff, вызов которого осуществляется по расширению имени файла. Поэтому в файле /usr/lib/mc/mc.ext следует в строке вызова nroff изменить параметр вызова с -Tascii на -Tlatin1.
Переключение кодировок
Теперь поговорим о том, как "на лету" изменить кодировку символов. Необходимость в этом возникает в тех случаях, когда просматриваешь какой-то файл и вместо читаемого текста видишь непонятную абракадабру. В таких случаях хочется превратить ее в нормальный текст нажатием пары горячих клавиш. Можно, конечно, для каждого из необходимых шрифтов создать специальную команду, записав в небольшой файл приведенные выше команды, естественно соответствующим образом модифицированные. Однако ясно, что это не совсем удобно. В этом отношении хочется работать так же комфортно, как в программе FAR Е. Рошаля, где в том случае, когда просматриваешь файл по клавише <F3> или редактируешь его по <F4>, достаточно набрать <Shift>+<F8> и получаешь возможность перекодировать выводимый на экран текст в любую из нескольких кодировок. Можно считать, что это уже роскошь, но что поделаешь, все мы быстро привыкаем к хорошему, и отказываться уже трудно.
2 июля 2000 г на сайте linux.ru.net появилась сообщение о заплате (патче) к Midnight Commander версии 4.5.50, которая позволяет производить перекодировку как в FAR, по нажатию клавиш <Ctrl>+<T>. Тогда это можно было делать только во встроенной программе просмотра. На сегодня автор патча В. Студенников доработал его, так что перекодировка стала возможна и во встроенном редакторе (см. http://www.linux.zp.ua:8100/mc/ или http://www.sama.ru/~despaire/mc/my-patches.html).
Это что касается перекодировки "на лету". Как видите, такая перекодировка является функцией отдельных программ просмотра файлов. Если перекодировка "на лету" недоступна, то можно перекодировать сам текстовый файл. Для преобразования потока символов из одной кодовой страницы (charset) в другую, в стандарте POSIX существуют утилита iconv и функция iconv(). О других программах перекодировки мы поговорим в лекции 12.
Предварительные сведения
В лекции 9 мы уже рассмотрели вопрос о кодировке символов и о работе клавиатуры, а также научились задавать (изменять) раскладку клавиатуры, т. е. вопрос о вводе информации в компьютер. Теперь надо рассмотреть вторую сторону этого вопроса - вопрос о выводе информации для восприятия человеком.
Проверка наличия средств локализации
Современные дистрибутивы Linux (а тем более русифицированные) по умолчанию содержат системные средства локализации, перечисленные в предыдущем разделе.
Чтобы убедиться в этом, проверьте, что у вас имеются каталоги /usr/share/locale/* и /usr/share/i18n/*, а также файл /etc/sysconfig/i18n.
Кроме того, дайте команду
[user]$ locale
В ответ вы должны получить значения, присвоенные переменным окружения для управления средствами локализации. Я, например, увидел следующее:
LANG=ru LC_CTYPE="ru_RU.KOI8-R" LC_NUMERIC="ru_RU.KOI8-R" LC_TIME="ru_RU.KOI8-R" LC_COLLATE="ru_RU.KOI8-R" LC_MONETARY="ru_RU.KOI8-R" LC_MESSAGES="ru_RU.KOI8-R" LC_ALL=ru_RU.KOI8-R
Можно также дать команду locale с параметром, совпадающим с именем одной из переменных окружения, например:
[user]$ locale LC_TIME
(но я не берусь объяснить то, что вы увидите).
Если результат этих проверок отрицательный (что маловероятно), то установите пакет локализации для русского языка. Найти его можно в коллекции средств локализации по адресу http://www.ping.be/linux/locales/ или на www.kiarchive.ru.
После этого надо сказать Linux, какой язык вы хотите использовать, для чего необходимо задать значения переменных окружения для управления средствами локализации: LC_CTYPE, LC_TIME, LC_COLLATE, LC_NUMERIC, и LC_MONETARY. Вообще говоря, достаточно задать всего одну переменную LC_ALL, задание которой одновременно определяет значения всех перечисленных выше переменные.
Есть еще две переменных окружения, которые имеют отношение к локализации: LANG и LINGUAS. Они действуют примерно так же, как и LC_ALL, в том смысле, что они определяют значения по умолчанию всех других переменных локализации, но, в отличие от LC_ALL, они не переопределяют значений других переменных LC_*, для которых значения заданы отдельно.
Переменная LINGUAS является GNU-расширением переменой LANG. Не все программы знают о существовании этой переменой (хотя не знают очень немногие, и таких все меньше), но эта переменная обладает тем преимуществом, что она позволяет задать несколько вариантов локализации, в порядке предпочтения. В большинстве случаев достаточно задать только одну переменную локализации - LANG. Если вы хотите использовать несколько вариантов локализации, то надо задать LANG и LINGUAS. Остальные переменные необходимо задавать только в особых случаях, которые мы здесь не рассматриваем.
Растровые шрифты (Bitmap Fonts)
Существует два типа матричных шрифтов - принтерные матричные шрифты (bitmap printer fonts), такие как шрифты pk, генерируемые программой dvips, и матричные экранные шрифты, используемые в системе X Window и в консольном режиме. Файлы матричных шрифтов обычно имеют расширения bdf или pcf.
Rlogin
Удостоверьтесь, что shell на месте адресата установлена правильно. Если ваш rlogin не работает как надо по умолчанию, то используйте 'rlogin -8'.
Пропишите в стартовом скрипте (если вы используете bash, то это .bashrc)
alias rlogin='rlogin -8'
Русификация X Window
Так же, как и в текстовом режиме, в графическом русификация определяется таблицей раскладки клавиатуры и файлами шрифтов. Впрочем, о том, как разобраться с клавиатурой, было достаточно сказано в лекции 9. Давайте теперь подробно рассмотрим, как организовать вывод на экран символов кириллицы.
Samba
Чтобы увидеть русские буквы в именах файлов на диске Samba, в файл /etc/smb.conf следует добавить строки:
[global] character set = koi8-r client code page = 866 preserve case = yes short preserve case = yes
Первые две опции указывает внутреннюю кодировку имен файловой системы (client code page) и внешнюю кодировку пользователя (character set).
Следующие две опции указывают, что надо сохранять регистр длинных и коротких имен файлов.
Шрифты True Type
Технология True Type была создана фирмой Apple для использования в операционной системе MacOS в 1990 году. Позже лицензию на эту технологию приобрела фирма Microsoft. Благодаря гигантской популярности MS Windows шрифты True Type стали ведущим форматом для компьютерных шрифтов. Шрифты True Type хранят метрики и информацию о начертаниях символов в одном файле (обычно с расширением ttf). Недавно были разработаны серверы шрифтов, или фонт-серверы, которые сделали шрифты True Type доступными для X Window. С некоторых пор стандарты postscript и ghostscript тоже поддерживают True Type шрифты. В силу этого, а также из-за того, что имеется большое количество высококачественных и доступных шрифтов True Type, они становятся все более популярными в Linux.
В Linux ведущим форматом шрифтов
В Linux ведущим форматом шрифтов является Adobe PostScript. Вообще, PostScript - это язык для описания страницы документа, он используется для вывода страницы с текстом и графикой на экран и на принтер (который поддерживает этот язык). Шрифты Adobe Type основаны на данном языке. Существуют две основные разновидности: Type 1 PostScript font и Type 3 PostScript font. Стандартом является Type 1. Шрифт Type 3 используется довольно редко. Шрифты Type 1 применяются в различных графических и издательских программах, например Adobe PageMaker, но они не являются стандартными в Microsoft Windows и поэтому их использование ограничивается программами, специально разработанными для поддержки данных шрифтов.
Язык Postscript традиционно используется для печати в UNIX, и поэтому шрифты Type 1 широко применяются в Linux. Они поддерживаются в графической системе X Window и программе управления печатью ghostscript.
Обычно шрифт Type 1 для UNIX задается двумя файлами: файлом метрик с расширением afm (adobe font metric), и файлом контуров, который имеет расширение pfb (printer font binary) или pfa (printer font ascii). Файл контуров содержит все глифы, а файл метрик содержит метрики шрифта.
Шрифты Type 1 для других платформ могут поставляться в других форматах. Например, шрифты postscript для Windows часто используют формат pfm для файла метрик.
Эти шрифты распространяются примерно таким
Эти шрифты распространяются примерно таким же образом, как шрифты Type1 - в виде пары afm-файла метрик и pfa-файла контуров. Хотя они поддерживаются стандартом postscript, но не поддерживаются в X Window, поэтому имеют ограниченное применение.
в действительности являются просто шрифтами
Шрифты Type42 в действительности являются просто шрифтами True Type с дополнительным заголовком, что делает возможным обработку их интерпретатором PostScript. Большинство приложений, таких как ghostscript и SAMBA могут работать с этими шрифтами. Однако, если вы имеете postscript-принтер, может оказаться необходимым явно создать файлы шрифтов типа Type42.
Сравнение форматов Type1 и TrueType
Несмотря на длительное противостояние между сторонниками шрифтов Type1 и True Type, эти форматы имеют много общего. Оба они представляют масштабируемые контурные шрифты. Разница в том, что шрифты Type1 используют для построения глифов кривые Безье третьей степени в отличие от квадратичных кривых, на которых строятся шрифты True Type. Теоретически это является преимуществом, поскольку тем самым Type1 включает все кривые, которые можно построить с помощью True Type. На практике, однако, разница очень незначительна.
Шрифты True Type имеют преимущество, заключающееся в том, что обеспечивают лучшую поддержку хинтинга (шрифты Type1 тоже поддерживают хинтинг, но не так эффективно). Это существенно только для устройств с низким разрешением, таких как экраны (улучшение хинтинга не дает заметной разницы на принтерах с разрешением 600dpi, даже при малых размерах точки). Улучшенный хинтинг не имеет большого практического значения еще и потому, что шрифты True Type с хорошим хинтингом встречаются достаточно редко. Причина этого в том, что пакеты программного обеспечения для создания шрифтов, поддерживающих хинтинг, слишком дороги для большинства дизайнеров шрифтов. Только крупные фирмы, такие как Monotype, создают шрифты с полноценной поддержкой хинтинга.
Основная разница между шрифтами True Type и Type1 состоит в доступности и поддержке приложениями. Широкое распространение шрифтов True Type для Windows привело к тому, что многие страницы на сайтах Интернета создаются в предположении, что определенные шрифты True Type установлены на компьютере пользователя. Многие пользователи имеют на своих компьютерах большое число шрифтов True Type, поставляемых с приложениями Windows. Однако, под Linux большинство приложений поддерживают шрифты Type1, но не поддерживают на том же уровне шрифты True Type. Кроме того, некоторые из основных производителей шрифтов поставляют свои шрифты в формате Type1. Например, фирма Adobe выпускает очень мало шрифтов True Type. Учитывая, что преобразование из одного формата в другой не может быть проведено без определенных потерь качества, надо стараться использовать в каждом приложении те шрифты, на использование которых это приложение рассчитано.
Текстовый режим
Работа экранного драйвера текстового режима основана на использовании 16 битовой кодировки символов UNICODE (UCS2). Изображение каждого символа, соответствующего любому двухбайтовому коду кодировки UNICODE, представляется матрицей из нолей и единиц размером 8 столбцов на H строк (обычно H принимает значения 8, 14 или 16). Единица в этой матрице соответствует светящейся точке на экране, а ноль - затемненной точке. Каждая строка этой матрицы кодируется одним байтом. Совокупность таких матриц (точнее, их байтовых представлений) для всех символов UNICODE образует таблицу экранного шрифта (Screen Font Map - SFM). Файл, в котором хранится такая таблица, может содержать шрифт одного размера по высоте (H) или шрифты нескольких размеров.
Сам экранный драйвер может работать в одном из двух режимов: режиме UTF или байтовом режиме. Выбор режима определяется приложением, которое обращается к этому драйверу для вывода символов на экран.
В режиме UTF последовательности байтов, получаемые от приложения для отображения на экране консоли, преобразуются по алгоритму UTF в коды UNICODE. После такого преобразования драйвер экрана обращается к загруженной в память таблице экранного шрифта (SFM) за соответствующим данному коду изображением символа.
В байтовом режиме драйвер экрана использует дополнительную таблицу - таблицу перекодировки символов (Application Charset Map или кратко ACM) для преобразования получаемых от приложения последовательностей байтов в коды UNICODE. Эта таблица зависит от кодировки символов, применяемой приложением. В дальнейшем драйвер экрана, как и в режиме UTF, обращается к таблице экранного шрифта (SFM) для того, чтобы извлечь из нее изображение нужного символа.
|
Примечание: Для того, чтобы определить, работает ли виртуальная консоль в режиме UTF или в байтовом режиме, можно воспользоваться скриптом vt-is-UTF8, а для переключения режимов работы виртуальной консоли служат два скрипта: unicode_start и unicode_stop. |
В ядре Linux отведено место для хранения четырех таблиц перекодировки ACM. Первые три таблицы определяют 437 кодовую страницу IBM (cp437), таблицу для набора символов терминала DEC VT100 (vt100) и таблицу для набора символов ISO latin1 (iso01). Эти три таблицы встроены в ядро и никогда не меняются. В качестве четвертой таблицы перекодировки в ядре может быть записана таблица перекодировки, выбранная пользователем.
Консольный драйвер Linux позволяет для каждой виртуальной консоли определить (с помощью команды charset) две ссылки (в документации их называют "сокетами") на таблицы перекодировки ACM. Эти две ссылки обозначаются как G0 и G1, причем для каждого виртуального терминала значения, присвоенные этим ссылкам, выбираются независимо. Однако, хотя ссылки G0 и G1 задаются независимо для каждого виртуального терминала, выбор таблицы перекодировки, определяемой каждой ссылкой, можно производить только из четырех таблиц, записанных в ядре. Поэтому реально все терминалы используют одну и ту же пользовательскую таблицу ACM. То есть, вы можете задать для tty1 использование G0=cp437 и G1=vt100, а для tty2 использование G0=iso01 и G1=user1 (определяемая пользователем кодировка), но не можете сделать так, что в одно и то же время tty1 использует таблицу user1, а tty2 использует таблицу user2.
Команда consolechars используется для изменения ACM, так же как и для задания шрифта и ассоциированной с ним таблицы SFM. С помощью команды consolechars можно считать консольный шрифт (таблицу экранного шрифта SFM) 8xH из файла и загрузить его в память, а также сохранить в файле шрифт, загруженный в память. Эта же команда служит для загрузки в ядро таблицы перекодировки, а также позволяет переопределить ссылки G0 и G1.
В качестве одной из опций команды consolechars при загрузке экранного шрифта из файла может быть задан размер шрифта по вертикали H. Значение H должно считываться из файла шрифта. Однако файлы некоторых форматов (в частности, файлы, содержащие только битовые образы символов) не содержат прямого указания на этот размер. В таком случае значение опции -H вычисляется исходя из размера файла (обычно -H 8, -H 14 или -H 16). Поскольку в настоящее время Linux не позволяет программно переключать режим работы дисплея, то выбор подходящего значения H в зависимости от установленного разрешения экрана полностью возлагается на пользователя.
В заключение отметим еще, что файлы с экранными шрифтами по умолчанию располагаются в каталоге /usr/lib/kbd/consolefonts/, а каталог /usr/lib/kbd/consoletrans/ используется для хранения как таблиц ACM, так и SFM.
Telnet
Если возникают проблемы с вводом русских символов, надо создать файл ~/.telnetrc со следующей строкой:
DEFAULT set outbinary
Вы можете встретить проблемы при работе в кодировке cp1251 - не передается маленькая русская буква "я" (ASCII-код 0xff). У протокола Telnet 0xff - это первый символ управляющей последовательности. Дабы передать собственно "я", нужно его удваивать: 0xff, 0xff. При использовании KOI8-R такая проблема отсутствует.
Удаление ненужных шрифтов
Когда я просмотрел с помощью программы xfontsel, какие шрифты установлены в системе, я с удивлением обнаружил, что по умолчанию устанавливаются шрифты с какими-то иероглифами (поскольку я не знаю ни китайского, ни японского, то не могу точно сказать, какому языку эти иероглифы соответствуют). Естественно, что появилось желание удалить эти ненужные шрифты, хотя бы для того, чтобы не занимать зря драгоценное место на диске. Теперь, когда мы знаем, где эти шрифты расположены (см. перечень каталогов шрифтов), а также как шрифты именуются, удалить ненужные довольно просто.
Вначале давайте удалим шрифты с иероглифами (если вы не возражаете!). При работе с программой xfontsel я обнаружил, что иероглифы появляются на экране программы xfontsel тогда, когда в поле registry стоит комбинация jisx с какими-то еще цифрами. Перейдя в каталог /usr/X11R6/lib/X11/fonts/misc я просмотрел файл fonts.dir, устанавливающий связь между именами шрифтов и именами файлов, в которых хранятся соответствующие шрифты. С помощью этого файла нужно найти имена файлов с иероглифами и удалить их. После этого надо запустить команду mkfontdir, которая подкорректирует файл fonts.dir. Можно, конечно, и просто вручную удалить из fonts.dir строки, соответствующие удаленным файлам. Только не забудьте, что первая строка файла fonts.dir должна указывать число разных вариантов шрифта (не файлов в каталоге, а уменьшенное на единицу число строк в файле fonts.dir).
Кроме шрифтов с иероглифами, которые являются просто самым характерным примером, имеются еще множество шрифтов, которые вы, скорее всего, никогда не будете использовать. Но здесь я не буду давать советов, экспериментируйте, если не боитесь.
Установлен ли фонт-сервер?
Давайте начнем такую ревизию с проверки того, что корректно установлен фонт-сервер xfs. Вначале запустите команду:
[root]# ps ax | grep xfs
Если xfs уже установлен в вашей системе (в противном случае установите его), вы должны увидеть строку примерно такого вида:
401 ? S 0:04 xfs -droppriv -daemon -port -1
По этой строке можно определить, какой порт использует эта программа. Этот же номер должен быть указан в строке вида
FontPath "unix/:port_number"
в секции "Files" в конфигурационном файле X-сервера (в xfree86 это файл /etc/X11/XF86Config). Скорее всего секция "Files" в этом случае вообще содержит только одну строку FontPath, например, такую:
FontPath "unix/:-1"
Впрочем, можно не искать файл /etc/X11/XF86Config, а выполнить команду:
[root]# xset -q
в выводе которой вы должны увидеть такие строки:
FontPath "unix/:-1"
Если перечень каталогов шрифтов XFree86 содержит строку типа unix:/port_number, где port_number совпадает с номером порта, используемым программой xfs (Вы получили его по команде ps), то сервер xfs у вас установлен корректно. В противном случае, вы должны добавить ссылку на него в перечень каталогов шрифтов XFree86 либо с помощью команд:
[root]# xset fp+ unix/:port_number [root]# xset fp rehash
либо путем непосредственной корректировки файла /etc/X11/XF86Config и последующего перезапуска X Window.
Для редактирования файла /etc/X11/XF86Config вы должны иметь права суперпользователя. Если вы таких прав получить не можете, то для корректной установки фонт-сервера вы должны обратиться к администратору.
Включение средств локализации
Включение системных средств локализации в Red Hat Linux (а, следовательно, и в других дистрибутивах, основанных на Red Hat) осуществляется из файла /etc/profile.d/lang.sh.
Как известно, при старте любого shell-а сначала выполняется /etc/profile. В Red Hat в /etc/profile прописаны команды, благодаря которым на исполнение вызываются также все файлы /etc/profile.d/*.sh
Значения переменных локализации в файлах lang.sh задаются путем вызова на выполнение файла /etc/sysconfig/i18n. В файле /usr/doc/initscripts-4.16/sysconfig.txt.rus приведены краткие рекомендации относительно того, как задавать значения переменных в файле /etc/sysconfig/i18n, в частности, предлагается для LANG указать в качестве значения просто двухбуквенный код ISO для желаемого языка; для переменной LINGUAS - список кодов языков, разделенных двоеточием, а переменной LC_ALL присвоить имя в соответствии с приведенным выше описанием формата для переменных локализации. Таким образом, в файле /etc/sysconfig/i18n рекомендуется прописать три строки следующего вида:
LANG="ru_RU.KOI8-R" LINGUAS="ru:en" LC_ALL="ru_RU.KOI8-R"
Заметим, что в RU.LINUX.FAQ написано следующее: "Хотя в принципе допустимо задавать короткое именование, вроде LANG=ru_RU или даже LANG=ru, лучше использовать полное имя: LANG=ru_RU.KOI8-R. Совершенно недопустимо задавать LANG=ru_SU, такой страны больше нет :-)".
Если все, что было перечислено, сделано, можно считать, что локализация включена.
Правда, это верно только для случая, когда вы имеете права суперпользователя root. Но даже если вы простой пользователь Linux-системы и не можете редактировать файл /etc/sysconfig/i18n, то вы все же можете включить локализацию для себя, но несколько иным способом. А именно, поместите в свой файл $HOME/.profile (или в любой файл, который исполняется в процессе логирования пользователя: $HOME/.Xclients, $HOME/.xinitrc или другой) следующие строки:
export LANG=ru_RU.KOI8-R export LINGUAS=ru_RU:en export LC_ALL="ru_RU.KOI8-R"
Вот и все! (О том, как проверить, что локализация заработала, было сказано выше.)
Вывод символов на экран
Обычно (если не считать управляющих комбинаций) код нажатой клавиши либо записывается в файл, либо соответствующий символ отображается на экране. В файл, разумеется, записываются последовательности байтов, а не символы как таковые, но и они в конечном итоге предназначены для прочтения человеком, а человек воспринимает только изображения печатных знаков на экране или в распечатке.