Адреса и маски
Существует два варианта протокола IP- IPv4 и IPv6, отличающихся разрядностью сетевых адресов и возможностью назначения гибкого приоритета пакета. В одной и той же сети оба протокола могут сосуществовать, но пока таких сетей, где поддерживался бы протокол IPv6, достаточно мало. Более того, сети, с поддержкой и администрированием которых нам придется столкнуться, скорее всего, созданы не сегодня и, следовательно, построены на основе "старого" варианта IP - IPv4. В существующей литературе, если надо подчеркнуть, что речь идет об IPv6, указывают, что это именно этот вариант IP, а если пишут об IPv4, употребляют термин "IP".
Здесь и далее в этой книге речь пойдет об IPv4, но многие из изложенных принципов будут справедливы и тогда, когда все перейдут на IPv6.
Мы будем называть сетевым интерфейсом физическое или виртуальное (т.е. подразумеваемое или программно эмулируемое) устройство, которое способно выполнять функции приема пакетов данных от других подобных устройств и передачи им пакетов данных. Характерным примером сетевого интерфейса являются сетевые адаптеры (сетевые карты) и модемы.
Каждый сетевой интерфейс, осуществляющий прием и передачу пакетов по протоколу IP, должен иметь уникальный сетевой адрес. Под уникальным здесь понимается такой адрес, который в пределах данной IP-сети не принадлежит ни одному другому сетевому интерфейсу. Один интерфейс может иметь несколько IP-адресов, но один и тот же IP-адрес не может принадлежать разным сетевым интерфейсам.
В протоколе IP определено, что IP-адрес состоит из четырех байт и записывается в виде четырех десятичных чисел, отделенных друг от друга точками. Каждое число соответствует значению одного из этих байтов. IP-адреса объединены в блоки, которые называются сетями. В этом значении слово "сеть" употребляется реже, чем в более привычном значении "совокупность компьютеров и других сетевых устройств". Блоки адресов (сети) классифицированы по классам сетей, которые отличаются друг от друга особенностями маршрутизации.
Разбиение всего множества адресов на блоки последовательных адресов (например, 212.133.5.0-212.133.5.255) обусловлено тем, что в каждой точке сети должно быть известно, в каком направлении следует отправить пакет, адресованный сетевому интерфейсу с неким адресом. Промежуточные маршрутизаторы, которые объединяют большие сети и являются своеобразными "вокзалами" для пакетов, следующих из одного региона планеты в другой, не должны хранить записи о местоположении каждого сетевого интерфейса и маршруте следования к нему. Им достаточно знать, предположим, что пакет, следующий по адресу 212.133.5.13, следует отправлять туда же, куда и прочие пакеты из вышеуказанного диапазона адресов. Это же относится и к маршрутизаторам, объединяющим сеть среднего офиса с двумя-тремя диапазонами адресов, но всю тяжесть нагрузки легче представить на примере более загруженных систем.
Мы можем уподобить пакет транзитной посылке, которая следует из одного города в другой на разных поездах с несколькими "пересадками". На каждом из промежуточных вокзалов работники почты знают, в какую сторону следует отправить посылку, когда она проходит мимо них, но их совершенно не заботит, куда ее отправят на следующем вокзале: там об этом позаботятся сотрудники следующего почтового отделения.
Чтобы облегчить маршрутизаторам работу по запоминанию диапазонов адресов, были придуманы маски сетей, определяющие, какую часть IP-адреса занимает номер сети, а какую - номер компьютера1) в этой сети. Фактически, номер компьютера нужен только тому маршрутизатору, к которому непосредственно подключена локальная сеть, в которой находится компьютер - адресат пакета. В отличие от номера компьютера, номер сети используется всеми промежуточными маршрутизаторами, которые передают пакет друг другу от места отправки до места назначения.
Рассмотрим, как используется маска сети, на примере. Представим себе сеть, состоящую из трех сегментов. В каждом из них - по 40 компьютеров. Для того, чтобы снабдить уникальными адресами каждый из них, нам понадобится 120 адресов.
Стало быть, мы можем назначить для каждой подсети свой диапазон адресов. Выберем три диапазона так, чтобы в каждом из них было не менее 40 доступных адресов: 192.168.0.0-192.168.0.63, 192.168.0.64-192.168.0.127 и 192.168.0.128-192.168.0.191. адреса сетей в целом и широковещательные адреса включены в диапазоны.
Компьютерам, которые находятся в одном сегменте, мы присваиваем адреса только из одного диапазона. Теперь наша задача - объяснить маршрутизатору, через какие сетевые интерфейсы следует передавать пакеты в каждый из сегментов, и именно здесь нам поможет маска сети. У нас есть совершенно неизменная часть адресов в нашей сети - 192.168.0. Эти три байта адреса одинаковы для всех компьютеров нашей сети. Видно, что адреса в разных диапазонах отличаются значением последнего байта. Отметим, что адреса первого диапазона в двух старших битах этого байта имеют нули (действительно, двоичное представление чисел до 63 включительно дает значения от 00000000 до 00111111, старшие два бита выделены жирным шрифтом). Во втором диапазоне в упомянутых битах содержится 01: значения от 64 до 127 представляются в двоичном виде числами от 01000000 до 01111111. Аналогично, третий диапазон дает нам двоичные числа от 10000000 до 10111111. Выделенные биты разнятся между диапазонами, но одинаковы в пределах диапазона. Значение этих двух битов (их может быть больше, это зависит от числа диапазонов - подсетей, на которые разбита сеть) принято называть номером подсети; первый диапазон называют нулевой подсетью, второй - первой подсетью и т.д., смотря по значению этих битов.
Для того чтобы сообщить маршрутизатору, что к его первому сетевому адаптеру присоединена нулевая подсеть, ко второму - первая и к третьему - вторая, мы должны всего лишь указать маску сети на каждом из его сетевых интерфейсов. Договорились считать номером сети в IP-адресе значения тех битов, которые в маске имеют двоичное значение "1". стало быть маска сети, разделенной на четыре подсети, будет иметь значение 255.255.255.192.
Почему значение последнего байта маски - 192? Потому, что 11000000 двоичное дает именно десятичное 192. Почему мы делим сеть на четыре подсети, хотя речь шла о трех диапазонах? Дело в том, что сеть можно разделить только на такое количество подсетей, которое кратно степени двойки. Поэтому вместо трех подсетей приходится брать ближайшее большее их количество.
Теперь остается назначить каждому интерфейсу маршрутизатора адреса из диапазона той подсети, которая присоединена к этому интерфейсу, и насладиться его четкой работой по пересылке пакетов между интерфейсами.
Активность свопинга
Если устройство, на котором находится область свопинга, загружено вводом-выводом, это говорит о нехватке памяти. Можно оценить дисковую активность с помощью программы iostat. В Solaris 2.6 и выше следует использовать команду
iostat -xPnce
для получения информации об активности передачи данных в/из конкретных разделов дисков, в Solaris 2.5.1 доступна команда
iostat -xc
которая позволяет получить статистику ввода-вывода только для целого диска (физического устройства), без деления на разделы.
Если своп-раздел расположен на отдельном диске (что неплохо), версия системыне важна, в противном случае в старых системах оценить реальную загрузку диска передачами данных свопинга тяжелее.
Можно также использовать
sar -d
или
vmstat
Длинная очередь страниц для выгрузки свидетельствует о необходимости нарастить оперативную память в системе.
Алгоритм пейджинга
В Solaris применяются оба широко известных типа обмена страницами между оперативной памятью и пространством свопинга на диске: свопинг и пейджинг. Как мы уже знаем, пейджинг - это выгрузка тех страниц, которые давно не использовались, а свопинг - выгрузка всех страниц процесса. Свопинг в Solaris выполняется только при сильной нехватке памяти. Какой из двух способов освобождения оперативной памяти для текущих нужд использовать - свопинг или пейджинг, ядро решает, сопоставляя объем свободной оперативной памяти с ключевыми пар аметрами ядра. Эти параметры перечислены в следующем разделе.
Алгоритм работы xntpd
Для синхронизации времени в сети был разработан специальный протокол NTP (Network Time Protocol), в настоящее время обычно используется версия 4 этого протокола, но серверы NTP обладают полной обратной совместимостью. Протокол предполагает существование нескольких "слоев" эталонных источников времени.
Как известно, в мире есть так называемые эталонные источники времени - цезиевые часы и радиосигналы точного времени со спутников. Такие эталонные источники, говоря языком протокола NTP, входят в слой 0 (stratum 0) и являются максимально точными из всех доступных эталонов времени.
К серверам слоя 0 обращаются серверы слоя 1. Работающие на последних демоны xntpd (или ntpd - в других системах UNIX) распространяют точное время дальше, к серверам слоя 2 (stratum 2). Именно к серверам слоя 2 обращаются обычные серверы точного времени из локальных сетей самых разных организаций.
Другими словами, сервер времени xntpd в нашей локальной сети представляет собой сервер слоя 3: вся совокупность таких серверов в локальных сетях и образует слой 3. Номер слоя фактически означает дистанцию (число промежуточных серверов времени) от данного компьютера до эталонного источника точного времени. Важно отметить, что серверы времени одного слоя не общаются между собой.
Каждый NTP-сервер использует один или несколько источников точного времени, полностью полагаясь на них. Эти источники указываются в файле /etc/inet/ntp.conf. При старте xntpd отправляет им запрос, уточняя текущее время.
Каждый из серверов времени, которым мы доверяем, опрашивается несколько раз для получения достоверной статистики задержки передачи пакета. Если указано несколько серверов, время с каждого из них запрашивается многократно. Как правило, 5 минут уходит на опрос каждого сервера для получения показаний времени, которые следует расценивать как достаточно точные.
Запрос к серверу времени выполняется так:
клиент (например, наш xntpd) указывает в отправляемом серверу пакете свое текущее системное время и отправляет этот пакет; сервер времени получает пакет, вкладывает в него время передачи пакета, вычисленное как разность между временем отправки и временем получения пакета сервером.
Затем он вкладывает в этот же пакет свое текущее системное время и отправляет пакет обратно; клиент получает пакет и запоминает свое локальное время получения пакета.
Теперь клиент имеет возможность рассчитать задержку передачи пакета как половину от "времени передачи туда и обратно минус время обработки пакета сервером".
Если разница между эталонным и текущим системным временем не превышает 128 миллисекунд, то xntpd подстраивает частоту системных часов так, чтобы они догнали или затормозились до эталонного времени. Подстройка происходит довольно медленно и плавно.
Если разница превышает 1000 секунд, xntpd полагает, что имеет место фатальный сбой времени на локальной машине и завершается с предсмертным воплем, который запишется в /var/adm/messages.
Если разница находится в пределах между 128 миллисекундами и 1000 секундами, то xntpd по умолчанию выставляет время сразу же, просто вызывая функцию settimeofday().
Таким образом, коррекция времени может быть постепенной и резкой. При резкой коррекции системное время изменяется быстрым скачком, одномоментно. Можно запретить такое изменение демону xntpd, указав при запуске ключ -x. Особенно не рекомендуется изменять время резко, если часы спешат, поскольку ряд приложений, зависимых от времени (например, СУБД), могут в результате сохранить неверные данные. Впрочем, при постоянной работе сервера xntpd, как и при регулярном опросе такого сервера с помощью ntpdate, сильное расхождение времени нашего сервера и эталона исключено. Не следует использовать в качестве сервера времени компьютеры со сбоями аппаратуры или разряженной (неисправной) батарейкой CMOS (x86). Кроме того, сервер времени не должен быть сильно нагруженным ресурсоемкими задачами компьютером: иначе он не сможет обеспечить быстрый ответ и корректную обработку запроса.
Для общения между собой серверы времени используют UDP порт 123.
Альтернатива NIS и NIS+ - LDAP. Подсистема PAM
Наиболее свежей тенденцией в мире UNIX и сетей вообще является использование протокола LDAP (Lightweight Directory Access Protocol - облегченный протокол доступа к каталогу, где каталог понимается как хранилище разнообразной информации, в том числе имен пользователей, паролей и т.п.) и соответствующих служб - демонов ldap для обеспечения доступа к информации о пользователях, компьютерах и их свойствах. В отличие от NIS, LDAP позволяет хранить информацию совершенно универсальным способом (в виде дерева объектов и атрибутов) и сейчас поддерживается основными игроками компьютерной индустрии.
Подробнее о протоколе LDAP можно узнать на web-сайте http://www.intuit.ru/department/os/adminsolaris/9/www.openldap.com, откуда можно еще и загрузить свежую версию бесплатного ldap-сервера.
Таким образом, использование NIS и NIS+ не является сейчас повсеместным и не представляет собой наилучшую альтернативу простой синхронизации файлов из /etc на всех компьютерах сети с помощью rsync. Дело в том, что протокол NIS недостаточно защищен, а NIS+ - довольно сложен в настройке. Поэтому, если вы планируете использовать централизованную аутентификацию и авторизацию в сетях UNIX, имеет смысл обратить внимание на LDAP и, кроме того, не забывать о возможностях PAM: ведь с помощью этой подсистемы возможно производить аутентификацию и авторизацию с использованием любых источников - от файлов passwd до контроллеров домена Windows NT/2000.
НАЗАД ВПЕРЕД

/td>
|
Анализ таблиц arp
Таблица маршрутизации показывает, через какие шлюзы и интерфейсы отправлять пакеты в те или иные IP-сети. В системах, работающих с протоколом IP, также всегда есть таблица соответствий IP-адресов MAC-адресам, т.е. внутренним адресам сетевых адаптеров. Эта таблица используется при пересылках пакетов в локальной сети; она называется таблицей протокола нахождения соответствий адресов (ARP - Address Resolution Protocol). Посмотреть таблицу вы можете с помощью команды arp (ключ -a нужен для показа всей таблицы):
arp -a Net to Media Table: IPv4 Device IP Address Mask Flags Phys Addr elxl0 hp5l 255.255.255.255 00:50:ba:03:b6:47 elxl0 baclan.q.spb.ru 255.255.255.255 00:60:b0:3c:99:05 elxl0 ip-119.q.spb.ru 255.255.255.255 00:10:5a:72:dd:9c elxl0 192.168.5.72 255.255.255.255 00:e0:29:9b:79:cd elxl0 lib.q.spb.ru 255.255.255.255 00:e0:29:9e:f3:3b elxl0 sunny 255.255.255.255 SP 00:60:08:cb:3b:c0 elxl0 192.168.5.11 255.255.255.255 00:e0:29:44:66:08 elxl0 mask.q.spb.ru 255.255.255.255 00:e0:29:48:63:64 elxl0 192.168.1.29 255.255.255.255 00:e0:b0:5a:66:90 elxl0 192.168.5.225 255.255.255.255 00:10:5a:73:6c:6b elxl0 192.168.5.208 255.255.255.255 00:e0:29:64:9e:e7 elxl0 192.168.5.183 255.255.255.255 00:e0:29:61:29:42 elxl0 192.168.5.158 255.255.255.255 00:e0:29:64:8f:b9 elxl0 BASE-ADDRESS.MCAST.NET 240.0.0.0 SM 01:00:5e:00:00:00
Рассматриваемая таблица соответствий динамически обновляется и содержит только те адреса, к которым происходили обращения в последнее время. Данные этой таблицы возможно использовать для обнаружения несанкционированных подключений к сети или неожиданных замен сетевых карт в компьютерах. Впрочем, мало кто ведет учет MAC-адресов сетевых карт, и мы это уже обсуждали выше.
Аппаратные средства хранения данных
К сегодяшнему дню не придумано более удобных средств хранения больших объемов данных, чем жесткие диски. Если говорить о накопителях, позволяющих с ними работать в режиме постоянного обмена данными с памятью компьютера, жесткие диски являются едва ли не единственными распространенными средствами хранения данных.
Для долговременного хранения и создания архивов по-прежнему применяют ленточные накопители (кассеты DLT могут содержать до 70 Гбайт данных, а SDLT - до 160 Гбайт, при аппаратном сжатии производитель - компания Hewlett-Packard обещает емкость 320 Гбайт1)), оптические диски (CD-R, CD-RW, DVD), Jaz- и ZIP-накопители. В некоторых случаях используют дискеты.
Для повышения надежности систем хранения, основанных на жестких дисках, применяют RAID-массивы, аппаратуру, которая позволяет сохранять данные с той или иной степенью избыточности. Solaris поддерживает аппаратуру RAID, подробное ее описание приводится в фирменной документации производителей (StorEdge и многие другие) или в доступных источниках в Интернете.
С точки зрения операционной системы, RAID-массив представляет собой просто один жесткий диск. То, что фактически такой массив состоит из многих (обычно пяти-семи) дисков и может обеспечивать возможность замены дисков "на лету", без выключения или перенастройки оборудования, скрыто от операционной системы и гарантируется аппаратурой самого RAID-массива. Такие массивы обычно присоединяются к шине SCSI и стоят достаточно дорого по сравнению с обычными дисками.
Аутентичность пользователей NFS
Работа с общим диском, разделяемым между многими пользователями сети, предполагает, что в пределах сети существует общее пространство имен пользователей, т.е. пользователь gregory на любом клиентском (в терминах NFS) компьютере имеет то же реальное имя и (что важнее) тот же идентификатор, что и пользователь gregory на сервере NFS. Это достигается использованием централизованной аутентификации (например, с помощью PAM и сервера аутентификации или с помощью NIS+). Кроме того, важно ограничить права пользователя root при доступе через NFS, т.к. пользователь root на любом компьютере в любой системе UNIX имеет идентификатор 0, но от имени пользователя root на разных компьютерах могут работать разные люди.
Для ограничения доступа пользователя root на сервере NFS, любые файловые запросы от имени пользователей root клиентских компьютеров выполняются от имени nobody. Можно указать, пользователям root каких компьютеров мы предоставляем привилегированный доступ от имени root и через NFS.
По умолчанию файловая система экспортируется с правами чтения и записи для тех, кто ее смонтирует. Однако, права доступа к конкретным каталогам могут запрещать запись в них, фактически права доступа к удаленной файловой системе определяются комбинацией прав, данными при монтировании системы и прав доступа к каталогам; силу имеют более строгие права (например, нельзя записать файл в каталог, если нет права записи в каталог ИЛИ если право есть, но файловая система экспортируется в режиме read-only - только для чтения).
Рассмотрим для примера файл /etc/dfs/dfstab системы Solaris:
share -F nfs -o rw=@212.231.110, ro=@192.168.4 /home share -F nfs -o ro=212.231.110@,root=212.231.110.112\ /usr/share/man
Файловая система /home экспортируется с возможностью чтения и записи для компьютеров сети 212.231.110, и только чтения - для компьютеров сети 192.168.4. Файловая система /usr/share/man экспортируется для чтения для компьютеров сети 212.231.110. Пользователю root с компьютера 212.231.110.112 разрешен доступ с правами суперпользователя к этой файловой системе.
Полный список доступных режимов и настроек при указании экспортируемой файловой системы доступен в man share и man share_nfs, а некоторые из них обсуждаются ниже, в разделе "параметры экспорта в /etc/dfs/dfstab".
Авторизации
Авторизация представляет собой право, включенное в профиль или данное пользователю, выполнять определенные действия в системе. В Solaris доступны только предопределенные авторизации, добавить новую нельзя. Список авторизаций хранится в файле /etc/security/auth_attr:
# # Copyright (c) 2001 by Sun Microsystems, Inc. All rights reserved. # # /etc/security/auth_attr # # authorization attributes. see auth_attr(4) # #pragma ident "@(#)auth_attr 1.101/03/19 SMI" # solaris.admin.volmgr.:::Logical Volume Manager:: solaris.admin.volmgr.write:::Manage Logical Volumes::help=AuthVolmgrWrite.html solaris.admin.volmgr.read:::View Logical Volumes::help=AuthVolmgrRead.html solaris.admin.printer.modify:::Update Printer Information::help=AuthPrinterModify.html solaris.admin.serialmgr.read:::View Serial Ports::help=AuthSerialmgrRead.html solaris.admin.logsvc.:::Log Viewer::help=AuthLogsvcHeader.html solaris.admin.procmgr.user:::Manage Owned Processes::help=AuthProcmgrUser.html solaris.admin.usermgr.read:::View Users and Roles::help=AuthUsermgrRead.html solaris.profmgr.:::Rights::help=ProfmgrHeader.html solaris.admin.procmgr.admin:::Manage All Processes::help=AuthProcmgrAdmin.html solaris.admin.logsvc.write:::Manage Log Settings::help=AuthLogsvcWrite.html solaris.admin.serialmgr.:::Serial Port Manager::help=AuthSerialmgrHeader.html solaris.admin.fsmgr.write:::Mount and Share Files::help=AuthFsmgrWrite.html solaris.admin.dcmgr.read:::View OS Services, Patches and Diskless Clients::help=AuthDcmgrRead.html solaris.device.cdrw:::CD-R/RW Recording Authorizations::help=DevCDRW.html solaris.admin.usermgr.:::User Accounts::help=AuthUsermgrHeader.html solaris.role.delegate:::Assign Owned Roles::help=AuthRoleDelegate.html solaris.admin.patchmgr.read:::View Patches::help=AuthPatchmgrRead.html solaris.project.read:::View Projects::help=AuthProjmgrRead.html solaris.profmgr.write:::Manage Rights::help=AuthProfmgrWrite.html solaris.system.shutdown:::Shutdown the System::help=SysShutdown.html solaris.device.grant:::Delegate Device Administration::help=DevGrant.html solaris.:::All Solaris Authorizations::help=AllSolAuthsHeader.html solaris.project.write:::Manage Projects::help=AuthProjmgrWrite.html solaris.admin.serialmgr.modify:::Manage Serial Ports::help=AuthSerialmgrModify.html solaris.admin.patchmgr.:::Patch Manager:: solaris.admin.diskmgr.write:::Manage Disks::help=AuthDiskmgrWrite.html solaris.device.revoke:::Revoke or Reclaim Device::help=DevRevoke.html solaris.jobs.grant:::Delegate Cron & At Administration::help=JobsGrant.html solaris.dhcpmgr.write:::Modify DHCP Service Configuration::help=DhcpmgrWrite.html solaris.network.hosts.write:::Manage Computers and Networks::help=NetworkHostsWrite.html solaris.mail.mailq:::Mail Queue::help=MailQueue.html solaris.admin.dcmgr.clients:::Manage Diskless Clients::help=AuthDcmgrClients.html solaris.project.:::Solaris Projects:: solaris.admin.logsvc.read:::View Log Files::help=AuthLogsvcRead.html solaris.admin.fsmgr.read:::View Mounts and Shares::help=AuthFsmgrRead.html solaris.admin.fsmgr.:::Mounts and Shares::help=AuthFsmgrHeader.html solaris.jobs.user:::Manage Owned Jobs::help=AuthJobsUser.html solaris.role.assign:::Assign All Roles::help=AuthRoleAssign.html solaris.network.hosts.:::Computers and Networks::help=NetworkHostsHeader.html solaris.admin.usermgr.write:::Manage Users::help=AuthUsermgrWrite.html solaris.compsys.read:::View Computer System Information::help=AuthCompSysRead.html solaris.audit.:::Audit Management::help=AuditHeader.html solaris.profmgr.read:::View Rights::help=AuthProfmgrRead.html solaris.device.config:::Configure Device Attributes::help=DevConfig.html solaris.profmgr.delegate:::Assign Owned Rights::help=AuthProfmgrDelegate.html solaris.admin.printer.delete:::Delete Printer Information::help=AuthPrinterDelete.html solaris.admin.dcmgr.admin:::Manage OS Services and Patches::help=AuthDcmgrAdmin.html solaris.admin.printer.:::Printer Information::help=AuthPrinterHeader.html solaris.admin.diskmgr.:::Disk Manager::help=AuthDiskmgrHeader.html solaris.role.write:::Manage Roles::help=AuthRoleWrite.html solaris.role.:::Roles::help=RoleHeader.html solaris.admin.patchmgr.write:::Add and Remove Patches::help=AuthPatchmgrWrite.html solaris.mail.:::Mail::help=MailHeader.html solaris.admin.procmgr.:::Process Manager::help=AuthProcmgrHeader.html solaris.device.allocate:::Allocate Device::help=DevAllocate.html solaris.system.:::Machine Administration::help=SysHeader.html solaris.compsys.write:::Manage Computer System Information::help=AuthCompSysWrite.html solaris.compsys.:::Computer System Information::help=AuthCompSysHeader.html solaris.network.hosts.read:::View Computers and Networks::help=NetworkHostsRead.html solaris.device.:::Device Allocation::help=DevAllocHeader.html solaris.snmp.:::SNMP Management::help=AuthSnmpHeader.html solaris.admin.dcmgr.:::OS Server Manager::help=AuthDcmgrHeader.html solaris.dhcpmgr.:::DHCP Service Management::help=DhcpmgrHeader.html solaris.login.enable:::Enable Logins::help=LoginEnable.html solaris.admin.logsvc.purge:::Remove Log Files::help=AuthLogsvcPurge.html solaris.audit.read:::Read Audit Trail::help=AuditRead.html solaris.login.remote:::Remote Login::help=LoginRemote.html solaris.system.date:::Set Date & Time::help=SysDate.html solaris.admin.serialmgr.delete:::Delete Serial Ports::help=AuthSerialmgrDelete.html solaris.audit.config:::Configure Auditing::help=AuditConfig.html solaris.jobs.admin:::Manage All Jobs::help=AuthJobsAdmin.html solaris.grant:::Grant All Solaris Authorizations::help=PriAdmin.html solaris.jobs.:::Job Scheduler::help=JobHeader.html solaris.profmgr.execattr.write:::Manage Commands::help=AuthProfmgrExecattrWrite.html solaris.admin.usermgr.pswd:::Change Password::help=AuthUserMgrPswd.html solaris.login.:::Login Control::help=LoginHeader.html solaris.snmp.write:::Set SNMP Information::help=AuthSnmpWrite.html solaris.admin.printer.read:::View Printer Information::help=AuthPrinterRead.html solaris.profmgr.assign:::Assign All Rights::help=AuthProfmgrAssign.html solaris.snmp.read:::Get SNMP Information::help=AuthSnmpRead.html solaris.admin.diskmgr.read:::View Disks::help=AuthDiskmgrRead.html
Значения полей в этом файле таковы:
name:res1:res2:short_desc:long_desc:attr
name - обязательное поле, имя набора прав (авторизации). Это уникальное имя, которое получается из комбинации префикса и суффикса, где префикс - это часть имени до самой правой точки.
Префикс - наборов прав, придуманных компанией Sun, всегда начинается со слова solaris. Все остальные разработчики должны для соблюдения уникальности имени указывать в качестве начала префикса имя своего домена в Интернете в обратном порядке (например, com.intel.) После имени компании идет дополнительная часть префикса, содержание которой зависит от смысла набора прав. Компоненты дополнительной части разделяются символом "точка"(.)
Суффикс - это слово, определяющее детальный смысл авторизации. Слово grant предполагает право обладающего этой авторизацией пользователя делегировать свои наборы прав (авторизации) другим.
База аутентификации NIS+
Несмотря на схожесть названий, NIS и NIS+ не имеют ничего общего, кроме похожих имен и функций. Организованы они по-разному. В данной лекции подробности настройки NIS+ не рассматриваются, ввиду малой распространенности таких решений в России. Основное применение NIS+ - крупные UNIX-сети больших компаний.
По сравнению с NIS, база NIS+ обладает лучшей безопасностью данных, более удобной системой хранения, и другим механизмом репликации баз данных по сети. Структуры баз данных, которые в NIS называются картами, в NIS+ называются таблицами.
Всего в NIS+ определено 16 таблиц:
Hosts, Bootparams, Password, Cred, Group, Netgroup, Aliases (псевдонимы компьютеров в домене, к почте не относятся), Timezone, Networks, Netmasks, Ethers, Services, Protocols, RPC, Auto_Home, Auto_master.
Для управления NIS+ следует использовать команды nisbladm (модификация таблиц NIS+), nisgrep (поиск в них), niscat (вывод таблицы NIS+).
Управление NIS+ доступно из Solaris Management Console.
В файле /etc/nsswitch.conf для указания того, что некую проверку следует производить в NIS+, служит ключевое слово nisplus.
Внимание! Нельзя в /etc/nsswitch.conf писать nis+ вместо nisplus!
Файл /etc/nsswitch.conf может выглядеть, например, так:
# /etc/nsswitch.conf # hosts: nis dns [NOTFOUND=return] files networks: nis [NOTFOUND=return] files services: files nis protocols: files nis rpc: files nis
Ключевая фраза [NOTFOUND=return] в записи hosts предписывает клиенту NIS прекратить поиск и вернуть ответ "не найдено", если нужный элемент не может быть найден в базе данных NIS или DNS. По умолчанию поиск производится во всех указанных источниках. Запись [NOTFOUND=return] имеет смысл для случая, когда серверы NIS и DNS недоступны, тогда поиск будет продолжен в файлах (источник информации - files).
База данных установленных пакетов
Информация об установленных пакетах сохраняется в файле /var/sadm/install/contents.
Можно просмотреть его содержимое для изучения того, что именно и куда было установлено при инсталляции пакета. Программа pkgrm использует содержимое этого файла для удаления пакета. Например, можно увидеть, какие файлы и с какими правами были созданы в результате установки пакета top. Кстати, если имя пакета начинается на SUNW, это значит, что пакет создан компанией Sun Microsystems, а если начало имени пакета иное - то это продукт третьей фирмы. Как видите, последнее относится и к программе top - ведь ее пакет называется SMCtop.
more /var/sadm/install/contents | grep SMCtop /usr/local/bin d none 0755 root bin SMCgcc SMCtop /usr/local/bin/top f none 2711 root sys 47348 46603 1081404717 SMCtop /usr/local/doc d none 0755 root bin SMCgcc SMCtop /usr/local/doc/top d none 0755 root bin SMCtop /usr/local/doc/top/Changes f none 0644 root bin 30674 28431 1081404751 SMCtop /usr/local/doc/top/FAQ f none 0644 root bin 15167 37360 1081404751 SMCtop /usr/local/doc/top/INSTALL f none 0644 root bin 7460 472 1081404751 SMCtop /usr/local/doc/top/Porting f none 0644 root bin 7058 38204 1081404751 SMCtop /usr/local/doc/top/README f none 0644 root bin 7958 47937 1081404751 SMCtop /usr/local/doc/top/SYNOPSIS f none 0644 root bin 2109 45452 1081404751 SMCtop /usr/local/man d none 0755 root bin SMCgcc SMCtop /usr/local/man/man1 d none 0755 root bin SMCgcc SMCtop /usr/local/man/man1/top.1 f none 0644 root bin 12736 8086 1081404723 SMCtop
Поскольку в файле /var/sadm/install/contents указано, в какой каталог установлена программа, можно искать в нем нужную программу, чтобы понять, в какой каталог она установлена (если установлена вообще).
Бесклассовая маршрутизация (CIDR)
В конце 80-х-начале 90-х годов XX века сеть Интернет росла очень быстрыми темпами. В результате стали проявляться серьезные недостатки в организации распределения адресного пространства, так как эта процедура не была рассчитана на лавинообразный рост потребителей адресов. Проблемы сводились к следующему:
нехватка IP-адресов. Размеры существующих классов сетей перестали отражать требования средних организаций. Количество компьютеров в сети организации часто оказывалось больше, чем количество адресов в сети класса С, но гораздо меньше, чем в сети класса В. замедление обработки таблиц маршрутизации. Рост размеров таблиц маршрутизации в Internet-маршрутизаторах привел к тому, что их стало сложно администрировать, маршрутизаторы работали на пределе своих возможностей.
Чтобы разрешить эти проблемы, в июне 1992 года IETF (Internet Engineering Task Force) принял решение об использовании технологии бесклассовой междоменной маршрутизации (Classless Inter-Domain Routing - сокращенно CIDR). В 1994-1995 годах технология была внедрена Интернет-провайдерами для маршрутизации между их сетями. Термин "междоменная" относится к так называемым доменам маршрутизации, т.е. совокупностям сетей, объединенных общим администрированием и политикой маршрутизации. Домен маршрутизации обычно ограничен сетью крупного провайдера и его субпровайдеров.
Технология CIDR (описывается в RFC 1519) успешно применяется в любой группе сетей Интернет, построенных как на основе IPv4, так и на IPv6, и может взаимодействовать со старыми технологиями адресации. В основе CIDR лежит принцип использования маски сети переменной длины (VLSM -variable length subnet masks) и отказ от деления сети Интернет на сети классов А, В и С. При этом все организации, предоставляющие услуги Internet, будут разделяться не по классам своих сетей, а по маске предоставленного им адреса.
Согласно идеологии CIDR, провайдеры должны объединять в одну запись информацию о блоках адресов своих клиентов и анонсировать в Интернете свой блок адресов в целом.
Анонсирование представляет собой передачу пакетов по протоколу динамической маршрутизации для уведомления соседних маршрутизаторов о том, что такая-то сеть теперь стала доступна через данный маршрутизатор. До 1994 года анонсировалась информация о каждой из сетей каждого класса в отдельности.
Например, провайдер Internet "Слон трафика", которому ICANN 3) делегировал адреса с 198.24.0.0 по 198.31.255.255 (маска 255.248.0.0), может назначить своему клиенту фирме "Моська АО" группу адресов с 198.24.8.0 до 198.24.11.255 (маска 255.255.252.0). Ясно, что сеть "Моськи" не принадлежит ни к какому классу, и, тем не менее, может успешно работать в Internet. Очевидно, что новая структура адресного пространства позволит значительно сэкономить адреса для тех организаций, которым они действительно нужны, и взять лишние у других.
Без использования CIDR еще один клиент "Слона трафика", магазин "Успешный повар" был бы вынужден задействовать приватные адреса (192.168.0.0) или заказывать отдельную сеть класса C. Теперь же "Успешный повар" может уживаться с "Моськой АО" в пределах одного домена маршрутизации, например, использовать адреса с 198.24.12.64 до 198.24.12.127 (маска 255.255.255.192).
В настоящее время, при необходимости получить несколько адресов для своих компьютеров для работы в Internet, организация заказывает диапазон адресов в виде "адрес, маска", исходя из своих потребностей. Если, к примеру, ей нужно подсоединить к Internet 998 компьютеров, нет необходимости заказывать четыре сети класса С или одну класса В - достаточно заказать адрес и маску, позволяющие работать заданному количеству компьютеров, например "199.14.8.0, 255.255.252.0" - 1024 сетевых адреса.4)
Такая схема помогает экономить на заказе адресов, так как за каждый адрес провайдер потребует вносить абонентскую плату, а платить за множество неиспользуемых адресов не придется. Благодаря CIDR стала легче жизнь системного администратора: больше не нужно хлопотать о настройке маршрутизации между группами интерфейсов, принадлежащих к сетям разных классов.Управление сетью с помощью CIDR также становится проще.
В настоящее время технология CIDR поддерживается некоторыми протоколами внутридоменной (OSPF, RIP-2,E-IGRP) и междоменной маршрутизации (BGP-4), большинство поставщиков сетевого оборудования внесли поддержку CIDR в свое программное обеспечение.
Безопасность системы в компьютерной сети
Безопасность в сети - это тема для отдельной книги или даже целого многотомника, поэтому здесь мы рассмотрим только основные аспекты, связанные с обеспечением безопасности систем Solaris в сети.
все сетевые службы (демоны) в системе представляют собой корректно работающие программы, реализующие стандартные протоколы работы; система предоставляет доступ к ограниченному набору сетевых служб, этот доступ жестко контролируется посредством аутентификации и авторизации обращающихся, сообщение о разрешении доступа сохраняется в файле протокола; при работе в сети используются безопасные протоколы передачи данных, там, где это применимо, данные передаются зашифрованными надежными (на данный момент) алгоритмами шифрования; администратор(ы) и пользователи системы всегда применяют свои собственные пароли и никогда не сообщают их другим лицам;
Картина получилась идеальной. Если вы работаете в компании, где все происходит в точности так, как здесь описано, вы - счастливый человек!
Что надо сделать, чтобы приблизиться к идеалу?
Для того чтобы все программы работали так, как вы ожидаете, следует:
регулярно следить за сообщениями о найденных в ПО уязвимостях. Для этого существует ряд списков рассылки, на которые вы можете подписаться совершенно бесплатно. Наиболее толковый вариант, по-моему, рассылка от CERT (Computer Emergency Response Team) - зайдите на www.cert.org и проверьте сами! всегда устанавливать рекомендованные рассылкой от CERT или производителем системы заплатки и обновления системы или отдельных программ; об установке программ в Solaris рассказывает лекция 12; строго следовать рекомендациям производителей программ, например, если сказано, что демона squid нельзя запускать от имени привилегированного пользователя root, то и не надо этого делать!
Ограничение набора служб, к которым можно обратиться, так же как и ограничение доступа к каждой службе в отдельности, мы рассмотрим ниже, в разделе "Ограничение доступа к сетевым службам". О протоколировании работы демонов заботятся программисты, которые их пишут, поэтому администратору надо знать лишь, где хранятся файлы протокола и к чему они относятся.
Об этом говорится в лекции 16.
Применяйте только безопасные протоколы в сети, для этого:
вместо telnet всегда используйте secure shell (ssh); используйте https вместо http там, где через web-интерфейс передаются конфиденциальные данные; запрещайте на сервере протоколы, позволяющие узнавать информацию о вашей сети (например, finger); пользуйтесь только теми программами, назначение которых вам известно.
Запретите всем пользователям системы (себе - тоже!):
передавать важные пароли открытым текстом через сеть; сообщать кому-либо свой пароль в системе; реагировать на провокационные сообщения по e-mail (мошенники уже пытались убедить вас в том, что вам нужно где-то перерегистрироваться и сообщить им свой пароль?); оставлять свой пароль записанным на видном месте; придумывать примитивные пароли.
Список глупостей можно продолжить, но мы ограничимся призывом вести себя осторожно: от нас зависит безопасность сетей в большом числе организаций!
Блокировка файлов на NFS-сервере
Для того чтобы несколько процессов не конфликтовали при доступе к одному и тому же файлу, обычно используется механизм блокировки файла. Подробнее о блокировках сказано в документации по системным функциям lockf() и flock(). В NFS механизм блокировки реализован посредством двух демонов: lockd и statd.
Оба демона запускаются на сервере NFS после mountd и nfsd.
Программа lockd устанавливает и снимает блокировку файлов по запросу, а демон statd следит за состоянием блокировок и работоспособностью NFS-сервера.
В сети демон statd сервера NFS обменивается информацией с демонами statd на других компьютерах. Демон lockd посылает запросы демону statd для установления статуса компьютеров, взаимодействующих с ним.
Если компьютер, за которым следит statd, перестает отвечать и перезапускается, удаленный statd сообщает об этом локальному, следящему за ним, и локальный демон информирует об этом программы, которые работали через это соединение. Если прекращает работу локальный сервис и затем следует его перезапуск, то statd информирует об этом другие компьютеры.
Частота сканирования страниц
Повышенная частота сканирования страниц (scan rate) - главный показатель того, что в системе перестало хватать оперативной памяти. Для просмотра значения scan rate используйте команды
sar -g
или
vmstat
При анализе частоты сканирования с помощью vmstat имеет смысл запустить эту программу с параметром 60 для получения статистики каждые 60 секунд:
vmstat 60 kthr memory page disk faults cpu r b w swap free re mf pi po fr de sr cd f0 s0 -- in sy cs us sy id 0 0 0 482100 7288 23 63 126 31 46 8 54 28 0 0 0 333 1519 327 5 11 84 0 1 0 470816 2060 0 26 1 51 103 0 123 240 0 0 0 960 969 649 4 92 4 ...
Первую строку (суммарную статистику) можно игнорировать. Если показатель page/sr остается выше 200 страниц в секунду в течение длительного времени, это говорит о вероятной нехватке оперативной памяти в системе.
Постоянно низкое значение частоты сканирования страниц говорит о том, что системе хватает памяти. С другой стороны, высокое значение может быть вызвано активностью процесса (или нескольких процессов одновременно), читающего данные с диска или получающего их через сеть - эти данные не только кэшируются операционной системой, но и занимают место в памяти процессов, поэтому вполне могут вызвать активный пейджинг. Таким образом, не следует слепо полагаться на обсуждаемые рекомендации и считать 200 страниц в секунду абсолютной догмой индикации нехватки памяти: действуйте по ситуации, смотрите, какие процессы в действительности запущены и насколько они требовательны к памяти.
Что будем оптимизировать?
Несмотря на кажущуюся простоту, компьютер состоит из большого числа частей, и быстродействие системы определяется тремя факторами: скоростью работы каждого компонента, согласованием быстродействия разных компонентов и точной настройкой системы для работы именно с этой конфигурацией аппаратуры. Здесь мы не будем касаться первых двух факторов и предположим, что мы имеем идеально согласованную конфигурацию аппаратных средств. Поскольку в реальной жизни такое встречается редко, наш глаз отдыхает при взгляде на этот прекрасный компьютер. Все, что мы можем сделать с ним - это установить подходящую операционную систему и настроить ее оптимальным образом.
Оптимизации подлежит следующее:
количество одновременно запущенных процессов; количество потребляемой процессами памяти; объем оперативной памяти в системе; размер swap-раздела; набор ресурсов, в которых несколько процессов нуждаются одновременно.
Вопросы анализа и увеличения производительности дисковой подсистемы будут изложены в лекции 7, сейчас мы затрагиваем только тему оптимизации работы процессов. Фактически, в этой лекции обсуждаются два вопроса: оптимизация использования памяти и оптимизация приоритетов процессов. Первый, как легко догадаться, в практических задачах встречается много чаще.
Начнем с изучения того, как устроена виртуальная память в Solaris, ибо она является первым по значимости ресурсом, который постоянно делят между собой все процессы, запущенные в системе.
Что настраивать в ядре?
Ядро состоит из статической части и динамической части (модулей). Кроме того, в ядре располагаются многочисленные таблицы, размер которых задается параметрами ядра. Фактически, настройка ядра сводится к следующим задачам:
определение (или переопределение) параметров ядра (например, числа доступных семафоров в ядре); принудительное добавление указанных модулей в ядро; принудительное запрещение загрузки указанных модулей.
Частным случаем задачи (2) является добавление и настройка драйверов устройств.
Сейчас мы рассмотрим, как именно следует выполнять эти задачи, включая те или иные команды в файл конфигурации ядра /etc/system.
Что такое домен
Домен - это совокупность компьютеров в сети. Их объединяет только имя домена , т.е. для того, чтобы некий компьютер оказался элементом домена , достаточно в описании домена указать, что данный компьютер к нему относится и самому компьютеру об этом сказать. Компьютеры одного и того же домена могут быть удалены друг от друга географически, могут быть подключены к совершенно разным сетям и, возможно, даже не общаться между собой.
Домен может содержать отдельные компьютеры и поддомены. Поддомен - это домен , входящий в домен верхнего уровня. Любой домен , кроме корневого, является чьим-то поддоменом. Иерархия доменов легко прослеживается в их именах: домен lcc.gatech.edu, очевидно, является поддоменом домена gatech.edu.
Домены общего пользования (generic top level domains, gTLD) - это COM, NET, ORG, INFO, BIZ, MUSEUM, NAME, AERO и COOP. К ним относят домены ограниченного пользования, в которых могут зарегистрироваться только определенные организации, а именно: INT - международные организации, EDU - высшие учебные заведения США (это не мешает, впрочем, существованию домена spb.edu, который зарегистрирован на Санкт-Петербургский Государственный Университет (бывший Ленинградский Государственный Университет), GOV - правительственные организации США, MIL - военные организации США, ARPA - бывший домен проекта ARPANET, из которого выросла сеть Интернет, сейчас он используется для обратных зон, см. ниже раздел "Обратные зоны". Еще один домен - PRO - зарезервирован для сообществ профессионалов, но пока его администрирование никто не осуществляет.
Координацией всего, что связано с системой доменных имен , занимается общественная организация ICANN (The Internet Corporation for Assigned Names and Numbers), зарегистрированная в Калифорнии в 1998 году. У ICANN имеются региональные регистраторы - RIPE NCC, которая координирует действия в европейско-азиатском регионе и Северной Африке; ARIN, которая работает с Северной и Центральной Америкой; APNIC, которая отвечает за страны Тихоокеанского региона; и LACNIC, координирующая работу в странах Латинской Америки и Карибского бассейна.
Информацию о выполняемой ими работе можно найти на сайтах регистраторов и на сайте ICANN (www.icann.org). В 2004-2005 году появился ряд новых доменов общего пользования, о которых мы не упоминаем.
В доменах верхнего (первого) уровня, таких, как RU, UK, FR и т.д., регистрируются домены второго уровня. В одних странах принято регистрировать домены общего пользования второго уровня (ac.uk для академического сообщества Великобритании и co.uk для коммерческих организаций там же), в других - нет. Обычно регистрацией доменов занимаются провайдеры Интернет, в том числе и в России.
Процедуры регистрации могут быть более или менее строгими в разных доменах , потому что эти процедуры определяет организация, ответственная за домен . Например, в домене FI (Финляндия) можно зарегистрировать домен только резиденту Финляндии или компании, имеющей государственную регистрацию в налоговой службе этой страны.
Организация, управляющая доменом , может делегировать право на управление частью этого домена другой организации или структурному подразделению. Например, если компания Ford Motor владеет доменом ford.com (а это так и есть!), то она могла бы делегировать право администрирования поддомена rus.ford.com своему российскому подразделению (а вот такого домена на самом деле нет - и не спрашивайте, почему...). Тогда картинка бы выглядела так:
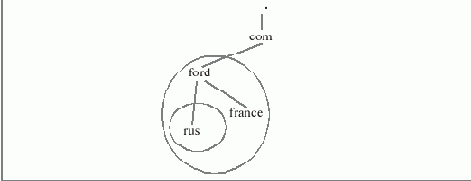
Рис. 15.1. Делегирование управления поддоменом rus.ford.com
Внешняя линия ограничивает пространство имен всего домена ford.com, а внутренняя - пространство имен rus.ford.com. То, что домен rus.ford.com "делегирован", означает, что право его администрирования, т.е. изменения записей о компьютерах, входящих в этот домен , передано другой организации (или подразделению). Так, администрирование домена france.ford.com, как видно из рисунка, осуществляется той же организацией, что и ford.com, а rus.ford.com администрируют другие люди. Делегирование дает возможность передать управление поддоменом не только организационно другой структуре, но и "переселить" информацию о поддомене на другой сервер имен, как будет показано ниже.
Что такое роль
Физически роль представляет собой учетную запись специального типа, пользователь не может зайти в систему, указав имя роли, но может "переключиться в роль", дав команду
su имя_роли
Можно сказать, что роль - это псевдопользователь, который обладает правами большими, чем обычный пользователь, но меньшими, чем root. Каждой роли могут быть делегированы те или иные права путем назначения ей профилей прав или авторизаций (наборов прав).
Что такое RPC
Идеология RPC очень проста и привлекательна для программиста. Как обычно работает сетевое приложение? Оно следует некоему протоколу (например, HTTP): формирует пакет с запросом, вызывает системную функцию установления соединения, затем функцию отправки пакета, затем ждет ответного пакета и вызывает функцию закрытия соединения. Это значит, что вся работа с сетью является заботой программиста, который пишет приложение: он должен помнить о вызове функций сетевого API системы, думать о действиях в случае сбоев сети.
RPC предполагает иной способ обмена данными между клиентом и сервером. С точки зрения программиста, приложение клиента, работающее с помощью RPC, вызывает функцию на сервере, она выполняется и возвращает результат. Пересылка запроса на выполнение функции через сеть и возврат результатов от сервера клиенту происходит незаметно для приложения, поэтому последнее не должно беспокоиться ни о сбоях сети, ни о деталях реализации транспортного протокола.
Для того чтобы обеспечить прозрачность пересылки данных через сеть, придумана двухступенчатая процедура. На сервере любое приложение, предоставляющее свой сервис через RPC, должно зарегистрироваться в программе, которая называется транслятором портов (port mapper). Функция этой программы - устанавливать соответствие между номером процедуры RPC, которую запросил клиент, и номером TCP или UDP порта, на котором приложение сервера ждет запросов. Вообще говоря, RPC может работать не только с TCP или UDP. В Solaris как раз реализована работа на базе механизма TI (TransportIndependent), поэтому в Solaris транслятор портов называется rpcbind, а не portmap, как в Linux или FreeBSD.
Приложение, которое регистрируется у транслятора портов, сообщает ему номер программы, номер версии и номера процедур, которые могут обрабатываться данной программой. Эти процедуры будут впоследствии вызываться клиентом по номеру. Кроме этого, приложение сообщает номера портов TCP и UDP, которые будут использоваться для приема запросов на выполнение процедур.
Клиент, желающий вызвать выполнение процедуры на сервере, сначала отправляет запрос транслятору портов на сервер, чтобы узнать, на какой TCP или UDP порт надо отправить запрос. Транслятор портов запускается при старте системы и всегда работает на стандартном порту 111. Получив ответ от него, клиент отправляет запрос на тот порт, который соответствует требуемому приложению. Например, сервер NFS работает на порту 2049.
Что такое зона
"Зоной" в пространстве доменных имен называется совокупность компьютеров, управление доменными именами которых делегировано одной организации (подразделению). Так, в примере с доменом ford.com Зоной ford.com называется совокупность всех компьютеров в домене ford.com и его поддоменах, за исключением поддомена rus.ford.com, так как зона rus.ford.com была делегирована другой организации (или подразделению). Зона ford.com на рисунке - это все, что находится между внутренней и внешней кривыми.

Рис. 15.2. Поиск адреса по имени сервером имен
Каждый домен обслуживается по крайней мере двумя постоянно доступными серверами имен. Сервер имен хранит список компьютеров домена и определяет соответствие имен компьютеров их IP-адресам. Информация о домене также содержит сведения о маршрутизации почтовых сообщений, адресованных в этот домен . Физически сервер имен представляет собой процесс (демон), работающий в системе.
Самый распространенный в Интернете сервер имен для UNIX-систем - это bind (Berkeley Internet Name Daemon). Вместе с Solaris 9 поставляется BIND 8. В пакет BIND, кроме программы named (это и есть собственно сервер имен), входят утилиты для получения информации от DNS и т.п.
Cистема печати в Solaris
Системы Solaris могут использоваться и в качестве мощных серверов, и в качестве рабочих станций на рабочих местах пользователей. В последнем случае пользователям необходимо иметь возможность печатать тексты и изображения со своих компьютеров. Поэтому в Solaris обеспечивается работа с любыми принтерами: установленными локально, предоставляемыми сервером печати или отдельно подключенными к сети. Компьютер под управлением Solaris может как выполнять функции сервера печати, так и быть клиентом печати.
Под сервером печати понимают систему, которая обрабатывает и выполняет запросы на печать, при этом принтер может быть присоединен непосредственно к этой системе или быть подключенным напрямую в локальную сеть. В последнем случае сервер печати выполняет роль "ретранслятора" - принимает задания на печать от других компьютеров, организует очередь печати и отправляет задания из очереди принтеру для выполнения.
Клиент печати - это любая система, которая требует от сервера печати выполнения задания на печать, клиент формирует задание и отправляет его на сервер. Клиентом и сервером печати одновременно может быть один и тот же компьютер. Сервером печати может быть как компьютер, так и отдельное специальное устройство; такие устройства также встраиваются в сетевые принтеры.
В Solaris есть программы, которые непосредственно управляют печатью, обращаясь к принтеру, программы, которые обрабатывают очередь заданий на печать, а также программы, управляющие принтерами (например, устанавливающими новый драйвер принтера в системе).
В этой лекции будут рассмотрены настройки системы печати, а в следующей - графический инструментарий системного администратора.
Для настройки системы печати необходимо выполнить следующие работы:
подключить принтер к серверу печати или к сети; настроить сервер печати, т.е. научить систему управлять принтером и предоставлять к нему доступ; настроить клиентов печати так, чтобы они могли обращаться к серверу печати; проверить возможность работы с принтером со всех клиентов печати, убедиться в правильности выполнения заданий на печать.
Compress, gzip, zip
Для сжатия архивов можно применять как gzip, так и compress - более старую утилиту из первых систем UNIX. Результатом выполнения команды сжатия файла data.txt
compress data.txt
будет файл data.txt.Z. При применении gzip результат будет в среднем лучше, так как этот архиватор обычно сжимает файлы сильнее. При этом он дописывает к имени сжатого файла суффикс .gz. В обоих случаях исходный (несжатый) файл исчезает, остается только сжатый файл. Надо помнить, что при нехватке места на диске архив не может быть создан, если свободного места осталось впритык, так как несжатый исходный файл удаляется только после его успешного сжатия и переименования временного сжатого файла в окончательный результат.
Для декомпрессии файлов, сжатых утилитами compress и gzip, используйте uncompress и gunzip соответственно. В некоторых версиях UNIX используется еще более новый архиватор bzip2 (и декомпрессор bunzip2), но в Solaris он пока еще не портирован.
Cpio
Команда cpio служит для копирования файлов в архив и из архива и умеет работать в трех режимах: входящего копирования, исходящего копирования и пассивного копирования. Режим исходящего копирования (копирования в архив, Copy Out Mode) используется для создания архива из файлов, подходящих по маске. Так, для архивации файлов, чьи имена начинаются с q, можно использовать такую последовательность команд:
ls q* | cpio -oc >Q/sccs.backup 16 blocks cd Q ls sccs.backup
Файл результата состоит из заголовка и записанного вслед за ним имен и содержимого архивируемых файлов. Сжатия информации не производится. Так выглядит начало получившегося файла sccs.backup:
head sccs.backup 070701000020fc0000812400000000000000010000000140dd6ab70000 0012000000660000000700000000000000000000000200000005q
test1
Применим входящее копирование (т.е. копирование из архива, Copy In Mode) для извлечения из архива определенных файлов, в нашем примере - файла q:
ls sccs.backup cat sccs.backup | cpio -i q 4 blocks ls q sccs.backup
Пассивное копирование (Pass Mode)2) служит для копирования файлов между файловыми системами, когда не применима команда mv. В этом режиме cpio читает список файлов со стандартного ввода и копирует эти файлы в указанный каталог (дерево каталогов).
Фактически, cpio всегда принимает список файлов со стандартного ввода (кроме случая входящего копирования). Ключи, которые описаны в man cpio, предписывают программе особенности поведения, такие как создание подкаталогов по необходимости и т.п.
Dd
Для копирования носителей целиком в их образы (например, дискет или компакт-дисков) и обратно служит программа dd. С ее помощью также можно копировать целые разделы дисков. Обычный формат вызова этой программы таков:
dd if=/dev/fd0 of=/usr/home/admin/diskettes/image1
Фактически, dd расценивает то, что она копирует, как блоки произвольных данных указанной длины (используется разумное умолчание в 512 байт). Использовать dd можно тогда, когда следует иметь две или более резервных копий: первую копию на ленту записывают с помощью программы ufsdump, а остальные копии создают копированием с ленты на ленту программой dd:
dd if=/dev/rmt/0h of=/dev/rmt/2h
Нельзя использовать эту программу для копирования файлов с одной файловой системы на другую, если размер блоков этих файловых систем - разный.
При копировании файлов, расположенных на блочных устройствах, последний копируемый блок может быть дополнен нулями от конца области данных до конца блока.
Дисковые квоты в NFS
Если на сервере NFS установлены дисковые квоты для отдельных пользователей, то для того, чтобы пользователь "издалека" мог узнать свою дисковую квоту, запускается демон rquotad.
Вообще говоря, установка дисковых квот (независимо от NFS) выполняется следующим образом:
В файле /etc/vfstab для файловой системы, для которой будет применяться квотирование, устанавливается параметр монтирования quota. Не забудьте демонтировать и снова смонтировать соответствующую файловую систему, если хотите, чтобы параметр оказал воздействие на работу файловой системы немедленно! Затем создается файл quotas в корне этой файловой системы (например, если речь идет о файловой системе /export/home, то файл будет называться /export/home/quotas). С помощью команды edquota устанавливаются квоты для каждого из пользователей в отдельности. Выполняется команда quotaon.
Для выключения поддержки квот достаточно выполнить команду
quotaoff
Для проверки квот в файловых системах надо выполнить команду
quota username
Добавление и настройка нового принтера
В моей сети есть принтер HP LJ 5L, который подключен к сети с помощью принт-сервера (маленькой коробочки с интерфейсом Ethernet, обученной работать с протоколом печати BSD). Адрес принт-сервера в сети - 192.168.5.22. Как добавить этот принтер в конфигурацию Solaris, чтобы на нем можно было напрямую печатать файлы?
Во-первых, надо создать запись об этом принтере в файле /etc/inet/hosts или на сервере имен, чтобы система могла обратиться к принтеру по имени:
cat /etc/inet/hosts # # Internet host table # 127.0.0.1 localhost 192.168.5.33 sunny loghost 192.168.5.22 hp5l
Затем следует модифицировать файл /etc/printers.conf:
cat /etc/printers.conf # # If you hand edit this file, comments and structure may change. # The preferred method of modifying this file is through the # use of lpset(1M) # hplj:\ :bsdaddr=hp5l,PS-1426:\ :description=hpjl: _default:\ :use=hplj:
Самая важная строка в нем - это bsdaddr. В этой строке должно быть указано имя сервера, к которому подключен принтер (в нашем случае это имя той самой коробочки - принт-сервера - hp5l), и логическое имя принтера на этом сервере, т.е. то имя, под которым принтер известен серверу (в нашем случае это PS-1426). Узнать это имя можно либо из документации к сетевому принтеру или принт-серверу, либо выяснить у администратора того компьютера, к которому подключен принтер, либо попробовать выяснить, подсоединившись с помощью telnet к принт-серверу:
telnet hp5l Trying 192.168.5.22... Connected to hp5l. Escape character is '^]'. *********************************** * Welcome to D-Link Print Server * * Telnet Console * *********************************** Server Name : ps-1426 Server Model : DP-101 F/W Version : 1.34 MAC Address : 00 50 BA 03 B6 47 Uptime : 64 days, 04:32:19
Еще немного о сетевых группах
Для удобства администрирования домена NIS следует применять сетевые группы. Формат записей в файле /etc/netgroup весьма прост:
имя_группы список_участников
В качестве списка участников принимаются имена членов группы, разделенные пробелами. Член группы - это либо имя другой сетевой группы, либо конструкция вида
(имя_компьютера, имя_пользователя, имя_домена_NIS)
Отсутствие любого из этих компонентов означает, что в соответствующей позиции подразумевается любой компонент. Например
(moon, ,columbia)
означает "любой пользователь компьютера moon в домене NIS columbia". Один компьютер может входить в несколько доменов NIS. Сетевые группы удобно использовать для назначения прав доступа к экспортируемым файловым системам NFS в командах share файла /etc/dfs/dfstab.
Файл конфигурации xntpd - ntp.conf
В файле /etc/inet/ntp.conf команды располагаются по одной в строке, за ключевым словом команды могут идти аргументы. Строки, начинающиеся со знака решетки (#), являются комментариями. Пустые строки игнорируются. Аргументы отделяются от команды и друг от друга пробелами.
Параметры настройки xntpd могут быть установлены в файле или из командной строки, ключи командной строки имеют преимущество перед установками в файле конфигурации.
Аргументы могут быть именами компьютеров или IP-адресами, а также спецификацией времени (числом с плавающей точкой) и текстовой строкой.
Рассмотрим пример конфигурации:
server ntp.cpsc.ucalgary.ca prefer server ntp.my-provider.ru server louie.udel.edu driftfile /var/db/ntp.drift
Параметр server указывает, какие эталонные серверы времени следует использовать, они перечисляются по одному в каждой строке. Если один из серверов указан с модификатором prefer, как ntp.cpsc.ucalgary.ca в нашем примере, то ответу этого сервера отдается предпочтение перед остальными. Параметр server нельзя использовать в случае, если наш сервер определяет соседей, слушая широковещательные пакеты NTP.
Ответ даже от предпочитаемого сервера будет отброшен, если он значительно отличается от ответов других серверов. В ином случае он будет использоваться вне зависимости от других ответов. Модификатор prefer используется для тех серверов NTP, о которых известно, что они очень точны. Например, серверам из слоя 2 имеет смысл отдавать предпочтение перед серверами провайдера, филиала вашей фирмы или дружественной компании.
Параметр driftfile задает файл, который надо использовать для хранения смещения частоты системных часов. Файл требуется программе xntpd для автоматической компенсации естественного смещения часов. При этом обеспечивается правильная настройка часов, даже если компьютер на некоторое время отключается от внешнего источника синхронизации времени, что может быть вызвано сбоем сети или этого источника.
В файле, имя которого указанно в строке driftfile, хранится история ответов серверов NTP.
Этот файл содержит служебную информацию для сервера NTP, и другие процессы не должны иметь доступа к этому файлу для записи в него.
Файл конфигурации /etc/inet/ntp.conf также определяет параметры доступа к нашему NTP-серверу. По умолчанию сервер NTP доступен любым хостам, которые могут к нему обратиться. При отсутствии фильтрации пакетов это означает свободный доступ из Интернета для всех.
Для ограничения группы компьютеров, имеющих право запрашивать время у xntpd, используется параметр restrict:
restrict 192.168.1.0 mask 255.255.255.0 nomodify
Такая установка разрешает обращаться к xntpd только компьютерам из сети 192.168.1.0 с маской сети 255.255.255.0, но запрещает им требовать от сервера NTP изменить его локальное время.
Директив restrict в файле /etc/inet/ntp.conf может быть несколько.
Демон xntpd также позволяет ввести аутентификацию для обращений к нему или настроить аутентификацию для обращения к тем эталонным серверам, которые ее требуют.
Если ваша сеть невелика, а требования к точности времени умеренные (часы могут спешить или отставать на 30 миллисекунд и немного больше), то xntpd может показаться не лучшим выбором. Для синхронизации часов только при загрузке системы достаточно использовать программу ntpdate.
Ее можно вызывать не только при загрузке системы. Если в процессе работы системные часы отклоняются несильно и высокая точность (30 мс или выше) не нужна, запускайте раз в два часа ntpdate для синхронизации с эталонным сервером из cron:
1 */2 * * * root /usr/sbin/ntpdate -b -s адрес_NTP-сервера
Файлы и каталоги конфигурации подсистемы печати Solaris
Принтер, выбираемый по умолчанию, должен быть поименован в переменных среды окружения LPDEST или PRINTER (проверяются именно в таком порядке), либо в переменной _default в файлах $HOME/.printers, /etc/printers.conf или в карте NIS printers.conf.byname. Если ни в одном из этих источников параметр с именем _default не обнаружится, стало быть, запрос на печать без указания имени принтера не может быть выполнен.
Исполняемые файлы подсистемы печати находятся в /usr/bin (lp, lpstat, cancel), /usr/sbin (lpadmin, lpusers, lpshut). В /usr/share/lib/terminfo содержится база данных принтеров и терминалов, в /usr/lib/lp находятся lpshed, фильтры для обработки файла перед отправкой на печать и некоторые другие полезные программы.
Каталог /etc/lp содержит файлы настроек подсистемы печати, а /var/spool/lp хранит текущие задания на печать и информацию о них.
Файл протокола подсистемы печати - это /var/lp/logs/requests:
... = hplj-1, uid 0, gid 1, size 5, Срд 05 Май 2004 19:48:34 z hplj C 1 D hplj F /export/home/filip/q P 20 T /export/home/filip/q t simple U root s 0x0040 v 2 = hplj-2, uid 0, gid 1, size 5, Срд 05 Май 2004 19:49:11 z hplj C 1 D hplj F /export/home/filip/q P 20 T /export/home/filip/q t simple U root s 0x0040 v 2 ...
Файлы настроек свойств сети в Solaris
Параметры сети определяются в следующих файлах:
/etc/defaultdomain - полное имя домена (например, company.ru); /etc/inet/hosts - таблица соответствия имен компьютеров и их адресов; /etc/hostname.le0 - краткое имя интерфейса le0. Остальные интерфейсы описаны соответствующими файлами. Имя должно совпадать с тем, что указано для адреса этого интерфейса в /etc/inet/hosts:
cat /etc/hostname.le0 hamburger cat /etc/inet/hosts | grep hamburger 192.243.78.11 hamburger.macro.su hamburger
/etc/hosts - символьная ссылка на /etc/inet/hosts; /etc/inet/nsswitch.conf - вместо host.conf в других вариантах UNIX - указание порядка опроса name-сервера и файла hosts, а также порядка опроса других служб; cat /etc/inet/nsswitch.conf
hosts: files, DNS
/etc/bootptab - адреса принт-сервера и принтера; /etc/resolv.conf - настройки DNS, включая адреса DNS-серверов; /etc/inet/netmasks - в каждой строчке пара: адрес сети, маска сети; cat /etc/netmasks 163.239 255.255.255.0
/etc/defaultrouter - адрес шлюза; /etc/nodename - имя компьютера.
Файлы /etc/hostname.* действительно называются hostname.название_интерфейса. НЕ НАДО подставлять в имя файла действительное имя компьютера, тем более не следует подставлять вывод команды hostname. Например, на компьютере sunny.macro.ru файл hostname.le0 содержит внутри слово sunny, а _называется_ файл hostname.le0, что говорит о его содержимом: имя хоста, сопоставляемое интерфейсу le0.
При обычной настройке подключенного к сети компьютера под управлением Solaris следует указать все те же параметры, что и при настройке любой системы, работающей с TCP/IP: адрес интерфейса, имя компьютера, имя домена, адрес DNS-сервера, адрес основного шлюза. Помните, что адрес DNS-сервера и основного шлюза должны быть указаны в виде IP-адресов, а не в виде доменных имен: при обращении к серверу имен система еще не обязана знать, какой IP-адрес какому компьютеру соответствует. Шлюз же следует указать в виде IP-адреса потому, что сервер имен может находиться и вне локальной сети, и тогда запросы к нему будут направляться через шлюз.
Для корректной работы системных вызовов, использующих resolver(3), т.е. тех, что обращаются к серверу имен с вопросом о соответствии IP-адреса имени или с требованием найти обратное соответствие, надо внести верную запись в файл /etc/resolv.conf. В этом файле допустимы команды:
nameserver IP-адрес search домен domain домен
Первая команда - nameserver - указывает IP-адрес сервера имен, всего допустимо использование до трех таких команд. Вторая указывает, имена каких доменов надо подставлять к имени хоста, если его ввели без имени домена (т.е. для поиска хоста с именем типа sunny), а команда domain определяет, в каком домене находится наш компьютер; это требуется для того, чтобы вначале попытаться найти компьютер с неполным именем (например, sunny) в своем домене, а уже затем попытать счастья в других доменах, которые перечислены в директиве search. Вот пример файла /etc/resolv.conf:
domain eu.spb.ru nameserver 192.168.5.18 search eu.spb.ru
Поиск имени компьютера по адресу или поиск адреса по имени выполняется при соблюдении всего двух условий: правильно указанного адреса сервера имен и возможности обменяться с ним данными.
Файлы протоколов
В Solaris администраторы часто находят полезным собирать в следующие файлы сообщения по уровням и источникам :
/var/log/notice - протоколирование всех сообщений почтовой подсистемы, кроме отладочных сообщений уровня debug) и всех сообщений уровня notice и выше (представляете, как их там много?); /var/log/critical - все сообщения о критических ошибках (уровня crit и выше), это может быть полезно для последующего анализа происходившего в системе перед серьезным сбоем; /var/log/auth - все сообщения подсистемы аутентификации (уровня warining и выше) - для своевременного обнаружения вторжения в систему или попыток такого вторжения.
Флаги netstat
Каждый маршрут отмечен своим флагом. Флаги в выводе netstat обозначают состояние и тип маршрута:
U - up - маршрут активен и действует; G - gateway - маршрут лежит к шлюзу; H - host - маршрут к хосту (компьютеру), а не к сети; S - static - маршрут добавлен статически (обычно - вручную); D - dynamic - маршрут добавлен динамически, посредством протокола маршрутизации.
В случае, если в системе активировано несколько сетевых интерфейсов, маршрутизация пакетов между ними по умолчанию разрешена. Если надо отключить это свойство, т.е. запретить маршрутизацию пакетов между интерфейсами, следует создать файл /etc/notrouter. Его существование будет проверяться при запуске системы, и если он существует, передача пакетов между интерфейсами будет выключена. Вы должны помнить, что Solaris обладает повышенной уязвимостью во время запуска, когда машина может перенаправлять пакеты независимо от /etc/notrouter. С другой стороны, это не очень серезная уязвимость: серверы Solaris, равно как и другие серверы приложений, не имеет смысл устанавливать вне корпоративной сети; вне такой сети вряд ли потребуется запрещать маршрут изацию средствами ОС.
Для того чтобы добавить или изменить маршрут пакетов к определенному адресату (компьютеру или сети), надо использовать команду route. Например, если требуется отправлять пакеты в сеть 193.13.13.0/24 (как вы помните, такая запись означает сеть класса C) через интерфейс с адресом 192.168.5.18, то следует дать команду route add:
netstat -rn Routing Table: IPv4 Destination Gateway Flags Ref Use Interface ------------ --------------- ------ ------ ---- --------- 192.168.5.0 192.168.5.33 U 1 5 elxl0 224.0.0.0 192.168.5.33 U 1 0 elxl0 default 192.168.5.1 UG 1 0 127.0.0.1 127.0.0.1 UH 54 5775 lo0 route add net 193.13.13.0 192.168.5.18 add net 193.13.13.0: gateway 192.168.5.18 netstat -rn Routing Table: IPv4 Destination Gateway Flags Ref Use Interface ------------ --------------- ------ ------ ---- --------- 193.13.13.0 192.168.5.18 UG 1 0 192.168.5.0 192.168.5.33 U 1 5 elxl0 224.0.0.0 192.168.5.33 U 1 0 elxl0 default 192.168.5.1 UG 1 0 127.0.0.1 127.0.0.1 UH 54 5905 lo0
Синтаксис команды route:
route [-dnqtv] команда [[модификаторы] аргументы]
-n - сообщать IP- адреса вместо имен компьютеров. Для вывода имени его еще нужно определить по адресу, это занимает время и окажется невозможным при сбое настроек или недоступности сервера имен;
-v - сообщить дополнительные детали;
-q - выполниться без выдачи сообщений.
Команда route также способна выполнять следующие действия в зависимости от содержания внутренних команд, переданных ей в качестве аргументов:
add - добавить маршрут; change - изменить маршрут (например, шлюз для сети); flush - удалить все маршруты; delete - удалить один указанный маршрут; get - найти и показать маршрут до определенного места назначения; monitor - следить за маршрутом и сообщать об изменении информации в таблице.
Внутренняя команда monitor имеет смысл для динамически обновляемых маршрутов:
route [-n] monitor
Обычно route вызывается для изменения или добавления маршрута, вот так:
route [-n] команда [-net | -host] куда через_что [netmask]
Для указания всех интерфейсов вообще используется ключевое слово default, синонимом которого является параметр -net 0.0.0.0.
В большинстве случаев ручной модификации таблицы маршрутов не требуется, все строки в таблицу заносятся автоматически на основании стандартных настроек системы ( адресов сетевых интерфейсов , адреса основного шлюза и масок сетей).
Функции модулей PAM
Модуль PAM представляет собой динамически присоединяемый модуль (файл с расширением .so), т.е. фактически - разделяемую библиотеку.
С точки зрения PAM, аутентификация состоит из нескольких независимых задач:
управление учетными записями; управление аутентификацией; управление паролями; управление сессиями.
Для идентификации этих задач в конфигурационном файле используются аббревиатуры account, auth, password, session.
Решение одной или нескольких из этих задач требуется при доступе пользователя к ресурсу.
Какие цели у модуля, решающего ту или иную задачу?
account - описывает службу проверки учетной записи, которая отвечает на вопросы: "есть ли такая запись и не истек ли срок действия пароля? имеет ли пользователь право доступа к запрошенному ресурсу?"
authentication - описывает службу проверки идентичности пользователя. Эта служба реализована посредством диалога между пользователем и программой аутентификации: "как тебя зовут и какой у тебя пароль?" Здесь пользователь обязан сообщить соответствующие друг другу имя и пароль (или иное подтверждение того, что пользователь именно тот, за кого он себя выдает).
Некоторые методы аутентификации (например, смарт-карты) не предполагают диалога, идентификацию выполняет специальная аппаратура, которая общается с написанным специально для нее модулем PAM. В этом проявляется гибкость PAM: старый добрый login может не задавать вопросов "login:", "password:".
Не меняя программ, требующих аутентификацию, PAM позволяет аутентифицировать пользователя любым способом, который изберет системный администратор. Может быть сейчас он еще и не знает, что он выберет через год, а кто-то уже пишет PAM-модуль для своей аппаратуры опознавания сотрудника по запаху.
password - описывает службу изменения пароля; такая служба должна быть тесно связана со службой проверки учетной записи. Например, по истечении срока действия пароля система требует у пользователя новый пароль.
session - описывает работы, которые должны быть выполнены до того, как ресурс будет предоставлен, или после того, как он будет освобожден (например, после разрыва соединения между программой-клиентом и вызванной им службой-сервером). Это может быть протоколирование начала и конца соединения, монтирование домашнего каталога пользователя и т.п.
Где сохранить резервную копию
Рассмотрим несколько возможных носителей для хранения копий данных. Они отличаются емкостью, скоростью записи и чтения, стоимостью, чувствительностью к внешним воздействиям.
Ленты (кассеты). Требуют использования накопителей на магнитной ленте. Емкость кассет обычно невелика, хотя современный формат DLT позволяет сохранять до 70 Гбайт на одной кассете. К сожалению, объем и скорость работы лент и кассет растет медленнее, чем объем и скорость жестких дисков, и поэтому ценность ленточных накопителей падает день за днем: невыгодно сохранять один раздел жесткого диска на нескольких кассетах - это очень замедляет и запись, и чтение данных. По традиции ленточные накопители остаются стандартом резервного копирования в больших системах, требующих регулярного сохранения данных в архивах. Долговременное хранение кассет достаточно удобно, хотя они подвержены воздействию электромагнитных полей и должны храниться вдали от сильных источников тепла и электромагнитов. Дополнительной проблемой является то, что емкие кассеты и быстрые накопители на магнитной ленте стоят довольно дорого: SDLT-стример на 160 Гбайт от компании Hewlett-Packard стоит примерно 3500-4000 долларов. Картридж к нему - 80 долларов.
Идеальным носителем могли бы быть оптические компакт-диски (CD-R или DVD): скорость их записи заметно выше, чем скорость записи лент, скорость чтения сравнима со скоростью жестких дисков, они практически не подвержены внешним воздействиям (конечно, их не следует поджаривать или колотить, как и прочие носители, но зато электромагнитные поля им нипочем), хранить диски можно в штабелях, в конвертах, коробках и т.п., более того, их можно прочесть в любой операционной системе - от Windows до Mac, включая все разновидности UNIX. Одно плохо: пока на такие диски не научились записывать более 700 Мбайт (CD-R) или 4,7 Гбайт (DVD) - а это слишком мало для сохранения копий больших разделов.
Jaz- и ZIP-диски. Обладают комбинацией недостатков лент и компакт-дисков, большого смысла рассматривать их как промышленное средство сохранения данных в настоящее время нет.
Объем Jaz-диска - 2 Гбайт, ZIP-диска - 100 или 250 Мбайт.
Дискеты. Очень маленький полезный объем (1, 44 Мбайта) компенсируется универсальностью: читаются повсюду, где есть дисковод. Чрезвычайно чувствительны к внешним магнитным полям - не рекомендуется, например, носить дискеты в портфеле рядом с мобильным телефоном. Качество современных дискет подстать их цене - из коробки ценой три доллара четыре дискеты из десяти легко окажутся бракованными еще до начала использования. Как средство хранения копий важных файлов лучше не рассматривать.
Флэш-память. Начиная с версии 8, Solaris стандартно поддерживает такой вид накопителей, хотя в некоторых случаях требуется установить обновление системы от Sun. Современные недорогие модели флэш-модулей, подключаемых к компьютеру по USB, имеют объем до 128 Мбайт, а более дорогие - до 1 Гбайт. Можно использовать как хорошую замену дискетам и даже компакт-дискам. Этот носитель следует беречь от воздействия сильных магнитных полей и высокой температуры.
Наконец, жесткие диски. По-видимому, следует признать их лучшим вариантом на сегодняшний день, так как обеспечить регулярное копирование данных на второй жесткий диск или диск соседнего компьютера сравнительно просто (достаточно написать скрипт), а обеспечить горячую замену вышедшего из строя диска на резервный не так уж и дорого. Кроме того, жесткие диски с резервными копиями стоят ненамного дороже емких магнитных лент, зато они существенно быстрее и удобнее в использовании, поэтому их можно применять не только для зеркалирования данных, но и для архивного хранения.
Имя устройства последовательного порта
В Solaris, как и в некоторых других системах UNIX, файл устройства, используемый для приема соединения через последовательный порт, и файл устройства, используемый для инициирования такого соединения, - это два разных файла. Входящие соединения принимаются устройствами /dev/ttyd*, а исходящие создаются через /dev/cua*. Имя устройства, например, для входящих соединений через COM2 будет /dev/ttyd1 (ttyd0 - COM1, ttyd1 - COM2), а для исходящих через COM2 - /dev/cua1.
Если вы настраиваете сервер удаленного доступа , надо заранее записать в конфигурацию модема (т.е. в NVRAM самого модема) значения S0=1 и S1=1 для того, чтобы модем снимал трубку с первого звонка.
Для непосредственного общения с модемом удобно использовать простейшую терминальную программу cu:
cu -l /dev/cua1
Если никакая программа не общается с /dev/cua1 в данный момент, то cu подключится к порту COM2. Теперь можно набирать команды модема: все, что будет набрано, попадет в последовательный порт. Для выхода из cu надо набрать ~. (тильда, затем точка) и подождать немного. Программа cu не умеет мгновенно отсоединяться.
По умолчанию, обращаться к устройствам напрямую с помощью cu может только root. Это соглашение можно изменить, установив нестандартные права доступа к файлам устройств /dev/cua* и /dev/ttyd*·.
Параметры pppd удобно записать в файл /etc/ppp/options. Если все PPP-сессии на сервере будут однотипными (одна скорость, соединение через один и тот же модем, звонки всегда только входящие), в этот файл можно записать все параметры pppd. Саму программу pppd можно прописать в качестве командного процессора по умолчанию в /etc/passwd всем, кто использует этот сервер как сервер удаленного доступа :
cat /etc/ppp/options /dev/cuaa0 # устройство 57600 # скорость crtscts # управл. сигн. RTS/CTS modem # модем, использовать DTR debug # протоколирование сессии passive # устанавливать соед. и ждать * dns1 193.114.38.65 # установить DNS 193.114.38.5:193.114.38.4 #назначить адреса local:dialup ** -detach # не уходить в background lock # блокировка порта по типу UUCP
Параметр debug включает протоколирование сессии. Программа pppd расценит этот параметр как требование записывать с использованием механизма syslog() все управляющие входящие и исходящие пакеты в удобочитаемой форме. Запись происходит от имени источника daemon с уровнем debug. Подробнее об источниках и уровнях записей в syslogd см. лекцию 16.
Параметр modem указывает, что нужно использовать сигналы управления модемом. Программа pppd ждет сигнала CD (carrier detect) от модема, если только не указан connect-script, и "передергивает" (коротко выключает, затем включает) сигнал DTR (data terminal ready) как только соединение завершается и перед тем, как запустить connect-script.
Если нужно установить индивидуальные настройки pppd для каждого пользователя, то в домашние каталоги пользователей нужно положить файлы .pppr, которые будут прочитаны демоном pppd после /etc/ppp/options и могут содержать дополнительные сведения для него.
Выдача динамических адресов клиентам PPP ("динамических" в том смысле, что клиент не знает заранее, какой адрес он получит) выполняется путем создания файлов с именами типа /etc/ppp/options.ttyd1.
В каждом таком файле можно указать конкретный адрес удаленного клиента, и тот будет получать разные адреса при соединении с разными последовательными портами сервера. В то же время, каждому порту сервера и его удаленному клиенту на этом порту при такой настройке всегда будет соответствовать фиксированная пара адресов, жестко определенная для каждого последовательного порта сервера.
Кроме этого, можно вообще ничего не писать в /etc/ppp/options про назначение адресов. По умолчанию всем позвонившим на сервер удаленного доступа pppd выдаст адрес ethernet-интерфейса этого сервера. Отличать разных клиентов он будет не по IP-адресу, а по имени создающегося при соединении через PPP интерфейса - ppp0, ppp1 и т.д.
Приведенный пример предполагает, что при дозвоне на сервер удаленного доступа не используется стандартный протокол аутентификации в Windows-системах, так называемый PAP (password authentication protocol).
В данном примере предполагалось, что пользователи применяют конфигурацию generic login из Windows XP или вводят имя и пароль вручную открытым текстом.
Если требуется настроить аутентификацию с использованием PAP и при этом использовать для аутентификации файл /etc/passwd, нужно записать в файл /etc/ppp/options параметр login. При этом пользователь, который соединяется с сервером удаленного доступа посредством PAP, должен иметь учетную запись и в /etc/passwd, и в /etc/ppp/pap-secrets. Формат записей в последнем таков:
имя_клиента имя_сервера пароль IP-адрес
В каждом из полей может стоять *, обозначающая допустимость любого значения. Как правило, строка аутентификации в pap-secrets выглядит так:
klara * KqZXV5-u *
Эта строка определяет имя и пароль пользователя klara, которому разрешено соединяться с данным сервером.
В некоторых версиях pppd при установленном параметре login программа в начале аутентификации полагает, что ей должен быть передан пароль, записанный открытым текстом в /etc/ppp/pap-secrets.
Если это так и есть, то любой, прочтя этот файл, сможет ввести в строку пароля именно то, что записано в этом файле, и будет аутентифицирован. Естественно, хранить незашифрованные пароли в /etc/ppp/pap-secrets небезопасно, поэтому там следует хранить зашифрованный пароль.
Чтобы объяснить программе pppd, что пароль в /etc/ppp/pap-secrets зашифрован, следует использовать параметр papcrypt при вызове pppd или указать его в файле /etc/ppp/options.
Есть, таким образом, две схемы организации сервера удаленного доступа :
Пользователь дозванивается на модем сервера, где его встречает программа ttymon (стандартная программа, обслуживающая вход на любой терминал, кроме псевдотерминала). Она спрашивает его login и password, которые пользователь сообщает вручную или с использованием скрипта на своей машине. Затем, уже после входа в систему, для пользователя запускается pppd, указанный в качестве командного процессора для этого пользователя в /etc/passwd. При запуске системы вместо ttymon, запускается pppd на том последовательном порту, где находится модем, и pppd ждет входящего звонка.
Когда кто- то дозванивается, pppd сам проводит аутентификацию с использованием /etc/ppp/pap-secrets.
Запуск ttymon для определенных терминалов контролируется в /etc/inittab в системах System V, включая Solaris. Старые версии Solaris и большинство других операционных систем используют программу getty вместо ttymon, в новых версиях Solaris программа getty также может быть вызвана, поскольку файл getty здесь представляет собой символическую ссылку на ttymon.
Файл /etc/ppp/pap-secrets может содержать как строки для аутентификации удаленных клиентов, так и строки, которые соответствуют аутентификации самого pppd на сервере удаленного провайдера. Имя пользователя, которое pppd будет использовать для того, чтобы идентифицировать самого себя, задается параметром user.
Индексные дескрипторы
Как уже обсуждалось в лекциях 5 и 6, при создании файловой системы для индексных дескрипторов выделяется отдельное пространство на разделе. Индексные дескрипторы хранят свойства файла, в том числе теневые индексные дескрипторы - расширенные права доступа. Количество индексных дескрипторов - это неизменяемая величина. Отсутствие свободных индексных дескрипторов в файловой системе приводит к невозможности записывать файлы в те каталоги, которые расположены в этой файловой системе. Количество свободных индексных дескрипторов можно определить, проанализировав вывод команды df -e:
df -e Filesystem ifree /proc 862 /dev/dsk/c0t0d0s0 294838 fd 0 /dev/dsk/c0t0d0s4 246965 swap 9796 /dev/dsk/c1t0d0s0 3256077
Использование файлов протоколов
Файлы протокола можно использовать как для анализа уже произошедших событий, так и для мониторинга. Последнее предпочтительнее: внимательный анализ файлов протоколов помогает понять происходящее в системе и вовремя предупредить сбой.
Особого внимания заслуживают файлы с сообщениями почтовой подсистемы и подсистемы аутентификации. Электронная почта - это ядро коммуникационной системы любого предприятия. Это только кажется, что доступ к сети Интернет - самое важное, что есть у сотрудников для общения, получения информации и даже (о ужас!) развлечений. На самом деле, и этот маленький секрет знает каждый опытный системный администратор, электронная почта намного важнее! Офис потерпит полдня без доступа в Интернет, пока провайдер меняет оборудование на узле, но если вдруг из-за настроек почтового фильтра кто-нибудь не получит важное письмо, это вызовет настоящий скандал.
Поэтому анализ последних сообщений от почтового сервера должен входить в список ежедневных (а то и ежечасных) задач системного администратора.
Для просмотров последних записей файла протокола удобно использовать команду tail с ключом f (tail -f), поскольку в таком случае tail выдает последние 10 строк файла протокола и затем постоянно выдает все новые и новые строки, по мере их появления после последней выведенной строки. Рассчитывайте свои силы: некоторые программы генерируют очень интенсивный поток сообщений в файл протокола. Завершение работы tail -f обеспечивается нажатием комбинации клавиш "Ctrl-C".
Следует также упомянуть файл /var/adm/messages, в котором по умолчанию собираются сообщения, выдаваемые при загрузке системы, а также важные сообщения по ходу работы.
Использование памяти процессами
В системах Solaris, начиная с версии 2.6, есть возможность выяснить, какие программы сколько памяти занимают (и подробнее - размеры сегментов данных, кода и т.п.) с помощью программы pmap.
Для получения детальной информации дайте команду
/usr/proc/bin/pmap -x PID
Информация о размере процесса в оперативной памяти также содержится в колонке RSS вывода программ top и ps (используйте ps -ly).
В пакете SunPro есть отладчик dbx, который помогает находить источник утечки памяти в программе; для такой работы следует компилировать программу компилятором SunPro с ключом -g.
Статистику использования разделяемой памяти вы получите по команде
ipcs -mb
Эти программы следует использовать для определения размера процессов и основных потребителей памяти в системе.
Изменение файла /etc/system
Конфигурация ядра Solaris, которая определяет технические параметры системы, может быть изменена в файле /etc/system. Файл содержит настройки ядра, отличные от принятых по умолчанию. Этот файл используется при загрузке системы. Изменения, внесенные в /etc/system, оказывают действие на конфигурацию ядра после перезагрузки.
Помните, что перед внесением изменений в любой файл конфигурации следует сделать его резервную копию - про запас.
Файл /etc/system содержит команды, которые представляют собой список пар имя=значение. Строки комментариев начинаются с символа "*" (звездочка) или "#" (решетка). Все команды, за специально оговариваемыми исключениями, можно давать в любом регистре как строчными, так и заглавными буквами. Длина команды не должна превышать 80 символов.
В командах перед именем параметра указывается пространство имен модуля, к которому относится параметр, например, semsys для изменения параметров подсистемы семафоров в приведенном ниже примере:
set semsys:seminfo_semmni=100
Следующие пространства имен являются общими для всех платформ под Solaris:
drv - драйверы устройств; exec - модули поддержки разных форматов исполняемых файлов, а именно:
aoutexec - модуль только для SPARC; coffexec - модуль только для Intel;
для обеих платформ:
elfexec intpexec javaexec
fs - модули этого пространства имен - это драйверы файловых систем; sched - реализация алгоритма планировщика задач; strmod - модули STREAMS; sys - модули исполнения системных вызовов; misc - другие модули, не попавшие в указанные выше категории.
Только для платформы SPARC реализованы модули:
dacf - модули автонастройки устройств; cpu - модули процедур ядра, связанных с конкретными процессорами.
Фактически, каждое пространство имен представляет собой каталог, в котором находится тот или иной модуль, например, модуль ipc находится в пространстве имен misc и располагается в каталоге /kernel/misc. Загрузка такого модуля выполняется командой
modload misc/ipc
В файле /etc/system допустимы следующие команды:
exclude: <namespace>/<modulename> - запрет загрузки модуля; include: <namespace>/<modulename> - разрешение загрузки модуля, любые модули по умолчанию разрешено загружать; forceload: <namespace>/<modulename> - требовать загрузки модуля при инициализации ядра, в отличие от принятой по умолчанию загрузки по мере необходимости; rootdev: <device name> - установить иное устройство для загрузки, чтобы изменить принятое по умолчанию при загрузке или установленное командой boot среды OpenBoot; rootfs: <root filesystem type> - указать тип файловой системы загрузочного устройства; moddir: <first module path>[[{:, }"second ...>]...] - установить список каталогов, в которых следует искать модули для загрузки; set [<module>:]<symbol> {=, |, &} [~][-]<value> - установить параметр ядра в указанное значение; если параметр относится к конкретному модулю, в команде следует указать явно этот модуль (см. выше пример с установкой параметров семафоров в ядре).
Эффективное использование памяти и свопинга
Вопрос об установке в систему дополнительной оперативной памяти представляет собой классический вопрос выбора между ценой и производительностью. Если цена важнее производительности, то при нехватке памяти увеличивают размер раздела свопинга, если важнее производительность - увеличивают объем оперативной памяти. Если же нет возможности сделать ни то ни другое, новые процессы не смогут быть запущены при нехватке виртуальной памяти (это можно заметить по сообщениям "Not enough space" или "WARNING: /tmp: File system full, swap space limit exceeded").
Если виртуальной памяти достаточно, но оперативной памяти хронически не хватает, система будет в значительной степени занята пейджингом и не сможет нормально откликаться на запросы. В такой ситуации можно наблюдать невиданную дисковую активность, а сканер страниц будет занимать до 80% времени процессора.
Индикаторами нехватки памяти в системе являются активность сканирования страниц на предмет пометки для выгрузки и активная работа устройства, на котором расположен swap-раздел.
При этом высокая активность может быть временной или постоянной. В любом случае, имеет смысл уяснить ее причину.
Как начать работу с SCCS
Прежде всего, надо создать подкаталог SCCS в том каталоге, где расположены файлы, подлежащие помещению в репозиторий. Их оригиналы сохраняются на прежних местах с прежними именами. А вот для работы с репозиторием следует применять программу SCCS.
Основные команды программы sccs перечислены в таблица 23.1:
| create | инициализация файла истории |
| clean | очистка текущего каталога |
| deledit | внесение изменений в репозиторий и извлечение файла |
| delget | внесение изменений в репозиторий и извлечение файла только для чтения |
| delta | внесение изменений в репозиторий |
| edit | извлечение файла |
| enter | инициализация файла истории |
| get | извлечение файла только для чтения |
| info | вывод полной информации о файле |
| unedit | возвращение файла к состоянию, в котором он был до последнего изменения |
Итак, начнем. Предположим, мы создаем репозиторий для файлов из каталога /usr/develop (пример c каталогом /etc так часто рассматривается в литературе, что мы сочли его банальным, если вы желаете сделать репозиторий для каталога /etc, просто замените все /usr/develop в нашем примере на /etc).
cd /usr/develop mkdir SCCS
теперь создаем файл истории проекта для файлов q и q1:
/usr/ccs/bin/sccs create q q1
q: No id keywords (cm7) q1: No id keywords (cm7) 1.1 2 lines No id keywords (cm7) 1.1 40 lines No id keywords (cm7)
Файлы оригиналов (т.е. того, что было до помещения файлов в репозиторий) сохраняются с именами, идентичными именам оригиналов, но с добавленной в начале запятой. Файлы истории предваряются префиксом s.:
ls -l SCCS total 6 -r--r--r-- 1 root other 155 Июн 26 16:01 s.q -r--r--r-- 1 root other 1877 Июн 26 16:01 s.q1
ls -l -rw-r--r-- 1 root other 7 Май 5 20:15 ,q -r--r--r-- 1 root other 7 Июн 26 16:01 q -rw-r--r-- 1 root other 1729 Июн 20 23:32 ,q1 -r--r--r-- 1 root other 1729 Июн 26 16:01 q1
Посмотрим содержимое файла q и попробуем его изменить.
Для редактирования файла следует его извлечь из репозитория; это делается командой sccs edit:
bash-2.05# /usr/ccs/bin/sccs edit q 1.1 new delta 1.2 2 lines
Посмотрим, как выглядит файл:
bash-2.05# cat q test
Отлично, выглядит по-прежнему. Если его изменить, а затем дать команду извлечения из репозитория, сделанные изменения пропадут, файл будет прежним. Изменения в файл следует вносить только после того, как файл извлечен из репозитория для модификации. Добавим строку в конец файла:
bash-2.05# cat >> q test1
Теперь внесем изменения в файл истории в репозитории:
bash-2.05# /usr/ccs/bin/sccs delta q comments? new line added No id keywords (cm7) 1.2 1 inserted 0 deleted 2 unchanged
Если после внесения изменений в файл истории снова требуется изменить сам файл (в нашем случае - файл q), то вместо delta следует указать подкоманду deledit, что эквивалентно последовательности команд
/usr/ccs/bin/sccs delta q /usr/ccs/bin/sccs edit q
Файл истории файла q в каталоге SCCS выглядит так:
h13611 s 00001/00000/00002 d D 1.2 04/06/26 16:12:03 root 2 1 c new line added e s 00002/00000/00000 d D 1.1 04/06/26 16:01:16 root 1 0 c date and time created 04/06/26 16:01:16 by root e u U f e 0 t T I 1 test
I 2 test1 E 2 E 1
Как видим, в файле истории сохраняется информация о самих изменениях, а также о времени и авторе этих изменений.
Как правильно запустить ufsdump
Синтаксис команды ufsdump отличается от синтаксиса большинства команд UNIX:
ufsdump [[ключи] [аргументы]] файловая_система
Сначала в командной строке друг за другом без пробелов указываются все ключи подряд, БЕЗ знака "минус" перед ними. Затем, через пробел, в том же порядке, что и ключи, указываются аргументы, относящиеся к этим ключам, например:
/usr/sbin/ufsdump 0ufBds /dev/rmt/0n 4194304 62000 1500 /var
Это означает дамп уровня 0 (ключ 0), с обновлением файла /etc/dumpdates (u), на устройство (f, файл) /dev/rmt/0n, размер тома (т.е. картриджа, кассеты, - В) - 4 194 304 килобайта (т.е. 4 Гбайта), плотность записи (d) 62000 бит на дюйм (bit per inch - BPI), длина ленты (s) - 1500 футов. Аргумент файловая_система обязателен, в то время как все остальные аргументы могут быть приняты по умолчанию, а какую именно файловую систему копировать, надо решать вам. Полагаться на умолчание не рекомендуется: указывайте параметры явно - так надежнее.
Конкретные параметры кассет и стримера необходимо заранее выяснить в документации на стример: разновидностей слишком много, чтобы их все привести здесь.
Если вы настраиваете сеть, в которой работают несколько разных систем UNIX, имейте в виду некоторые отличия Solaris и других систем. В частности, в версиях FreeBSD 4.х и выше программа dump принимает и вышеописанные ключи, и более стандартную форму ключей (со знаком "минус" и указанием значения параметра сразу после ключа). таблица 23.2 описывает конвенцию именования файлов устройств стримеров в разных системах UNIX.
| FreeBSD | /dev/rsa# | /dev/nrsa# |
| Linux | /dev/st# | /dev/nst# |
| Solaris | /dev/rmt/#l | /dev/rmt/#n |
В любой системе UNIX каждый ленточный накопитель представлен двумя файлами устройств - с перемоткой ленты в конце записи и без перемотки. Вы можете записать на одну кассету несколько разных файловых систем или несколько последовательных резервных копий одной системы.
Для этого надо в качестве устройства для записи указывать файл устройства без перемотки ленты в конце записи. Используйте эту возможность осторожно и всегда записывайте, какие именно файловые системы, в каком порядке и когда были сохранены. Обратите внимание: по умолчанию dump/ufsdump выбирает устройство с перемоткой.
Названия устройств могут быть другими, в зависимости от типа стримера и его интерфейса (обычно SCSI). Знак решетки (#) обозначает номер стримера, начиная с нуля. Вместо решетки в большинстве систем стоит ноль, так как обычно в компьютере устанавливают только один стример.
Когда вы решите, что резервное копирование должно прочно войти в жизнь вашей компании, обязательно закупите достаточное количество кассет (иначе их называют картриджами, по сути дела это специальные кассеты с магнитной лентой) для создания резервных копий.
Запись нескольких копий на одну ленту "от бедности" ведет к снижению надежности в разы. Перед восстановлением данных вы можете забыть перемотать ленту и в результате сотрете нужные еще целые данные вместо потерянных!
Маркируйте кассеты после выполнения копирования, к каждой из них не зря прилагается клейкий стикер. Не надейтесь на свою память: вы будете помнить о том, что где записано, неделю, а резервная копия может понадобиться через 10 дней...
Программа ufsdump, если задать ключ u, будет обновлять файл /etc/dumpdates, это полезная возможность, пользуйтесь ею! В этом файле в случае успешного завершения копирования появится новая строка с описанием того, что, с какими параметрами и на какое устройство было скопировано. Потом эти сведения могут оказаться важными, если данные и в самом деле придется восстанавливать.
Многие системные администраторы надеются, что им никогда не придется восстанавливать данные, а потому резервное копирование считают пустой тратой времени. Несмотря на это, мы настоятельно рекомендуем изучить процедуру восстановления данных - конечно же, на всякий случай.
Восстановление данных, записанных программой ufsdump, производится командой ufsrestore.
Ей можно указать, в какой каталог восстанавливать данные. Это сделано для того чтобы при необходимости указать новый каталог вместо прежнего, например, при крахе файловой системы.
Следует своевременно удалять восстановленные файлы из временных каталогов, если вы их уже перенесли по месту постоянной дисклокации, чтобы не занимать лишнего пространства забытыми файлами!
При записи нескольких файловых систем на одну кассету (помните: это не рекомендуется!) на кассете образуется несколько томов (volumes). Так как ни ufsdump, ни restore не умеют искать нужный том, важно знать, как сделать это самостоятельно. На кассете должно быть написано вашей рукой (рука вашего ассистента или предшественника тоже подойдет), в каком порядке и что именно на ней записано. Для перемотки ленты до нужного тома надо использовать команду mt.
Программа mt оперирует понятием файла (перемотать ленту на файл вперед, на два файла назад). При записи на ленту программой ufsdump таким "файлом" будет целый том (файловая система), пусть слово "файл" здесь не вводит вас в заблуждение.
Кроме ufsdump, данные на ленту можно записывать с помощью программы tar, речь о которой шла выше: она записывает целый каталог или группу файлов в один архив.
 |
|
|
1) На момент выхода книги (середина 2005 года).
2) Здесь был бы уместнее термин "сквозное копирование", но "пассивное" - это термин, введенный в переводе книги Пола Уотерса "Solaris 8. Руководство администратора". Поскольку эту книгу смело можно порекомендовать для изучения, а многие ее уже знают, я сохраняю терминологию, пусть немного в ущерб понятности термина. Смотрите детали в man cpio (прим. авт.).
НАЗАД ВПЕРЕД
|
Как работает DNS?
Представьте себе, что пользователь на компьютере с замысловатым именем 33-dialup.comstar.net решил посмотреть web-сайт www.example.ru. Что произойдет после того, как он наберет этот адрес в строке браузера?
Браузер нуждается в IP-адресе web-сервера, поэтому он запросит сервер имен о том, какой адрес у www.example.ru. Спрашивается, а какому серверу имен он задаст этот вопрос? Очевидно, тому, который указан в настройках компьютера 33-dialup.comstar.net. Там, скорее всего, указан адрес сервера имен провайдера, скажем, ns.comstar.net.
Получив этот запрос, сервер имен провайдера вначале поищет ответ в своем кэше, т.к. все DNS -запросы кэшируются. Если в кэше ответа нет, сервер имен проверит, нет ли ответа в его локальной базе. Его там не окажется, поскольку ns.comstar.net не отвечает за домен example.ru.
После этого сервер имен ns.comstar.net отправит запрос серверу имен корневого домена , как показано на рис. 17.2. Естественно, корневой сервер не имеет представления об адресе www.example.ru. Однако ему известен адрес сервера имен зоны ru. Этот адрес и будет сообщен вопрошающему серверу имен.
Сервер имен ns.comstar.net теперь отправит запрос серверу имен домена .ru, адрес которого он только что узнал. Тот сообщит ему адрес сервера имен example.ru, поскольку это самый близкий к www.example.ru из известных ему серверов имен.
Наконец, отправив запрос на сервер имен домена example.ru, сервер ns.comstar.net получит ответ на вопрос об IP-адресе компьютера www.example.ru, потому что этот компьютер находится в домене example.ru и его адрес известен серверу имен этого домена . Впрочем, если бы такого компьютера не существовало, то гарантированно достоверную информацию об этом все равно можно получить только от авторитетного сервера имен - то есть от сервера имен домена example.ru.
Теперь сервер ns.comstar.net отправляет долгожданную информацию на компьютер 33-dialup.comstar.net.
Почему сервер имен ns.comstar.net отправлял так много запросов, чтобы удовлетворить клиента, в то время как серверы имен других доменов ограничивались лишь ссылкой на известный им источник информации, пусть и самый близкий к авторитетному серверу имен из известных им? Может быть, потому, что сервер имен Comstar - самый вежливый в Сети? Оказывается, дело в том, что клиентская программа с 33-dialup.comstar.net прислала ему так называемый рекурсивный запрос, т.е.
просьбу найти сам адрес, а не присылать ссылку на ближайший сервер имен. Так поступают все клиенты. Серверы имен обычно настроены так, чтобы самостоятельно выполнить поиск, поэтому ns.comstar.net отправлял другим серверам имен нерекурсивные запросы.
Возникает вопрос: а не слишком ли долго ждал ответа пользователь у компьютера 33-dialup.comstar.net? Как ни странно, недолго. И объясняется это тем, что DNS -запросы - это высокоприоритетный трафик, и маршрутизаторы в сети стараются передавать их побыстрее, вне очереди (конечно, всегда может организоваться "очередь тех, кто без очереди", но в ней все-таки стоять немного лучше). Кроме того, все вышеупомянутые серверы имен связаны достаточно быстрыми каналами связи. И наконец, высока вероятность, что на каком-то этапе ответ на запрос окажется в кэше промежуточного сервера имен, и часть запросов окажется ненужной. Например, если в кэше сервера имен ns.comstar.net есть адрес сервера имен домена ru (а это весьма вероятно), то запрос к серверу имен корневого домена не потребуется.
Из этого примера ясно, что любой сервер имен обязан знать адреса серверов имен корневого домена . Этих серверов несколько в разных странах, и они регулярно обмениваются информацией, несмотря на то, что список доменов верхнего уровня и ответственных за них серверов имен меняется нечасто. Список серверов имен корневого домена всегда входит в дистрибутив ПО сервера имен.
Как синхронизировать время?
В Solaris есть возможность установить сервер синхронизации времени, который будет отвечать на вопросы "который час?", поступающие от других машин. Клиент этого сервера - программа ntpdate. Она спрашивает время у сервера точного времени (также называемого сервером синхронизации времени) и директивно устанавливает время в своей системе. При небольших отклонениях времени от эталонного она вызывает функцию "мягкого изменения" времени, когда время не устанавливается определенным одномоментно, а часы системы ежесекундно "подталкиваются" на долю секунды вперед или назад.
Программу ntpdate можно использовать и без собственного эталонного сервера времени, поскольку существуют публичные серверы времени.
Посмотрим, как работает ntpdate - программа установки системной даты и времени:
date Сбт 29 Май 2004 19:10:20
Установим заведомо неверное время:
date 1912 Сбт 29 Май 2004 19:12:00
Теперь запустим ntpdate и сообщим ей для ориентировки адреса двух эталонных серверов времени (они взяты из списка на http://www.intuit.ru/department/os/adminsolaris/16/www.ntp.org):
ntpdate tock.keso.fi ntp.psn.ru 29 May 19:10:31 ntpdate[10630]: step time server 194.149.67.130 offset -95.351227 sec
Повторим для надежности:
ntpdate tock.keso.fi ntp.psn.ru 29 May 19:10:39 ntpdate[10631]: adjust time server 194.149.67.130 offset -0.006045 sec
Как видим, вторая подвижка времени оказалась существенно меньше, чем первая: вначале часы были "возвращены" к правильному времени, а затем лишь слегка синхронизированы, причем в первом случае использовалась явная установка времени (step time server), а во втором - мягкая "подвижка" (adjust time server).
Программу ntpdate достаточно запускать только при старте системы, если только аппаратура компьютера исправна и таймер не требует постоянной коррекции.
Кроме программы ntpdate существуют и другие средства, предназначенные для синхронизации времени в сети. Программа ntpdate - это "клиентская" программа. В локальной сети организации имеет смысл установить по крайней мере один (а лучше - два, чтобы был запасной) сервер времени. Именно он будет опрашивать серверы слоя 2, а компьютеры локальной сети будут сверять свои часы по этому локальному серверу времени. В качестве такого сервера в Solaris используют демон xntpd.
Как устроена графическая среда под UNIX
Подсистема графического интерфейса под UNIX выполнена совершенно отдельно от системы. Любая система UNIX может работать без графического интерфейса вообще. В Solaris по умолчанию для всех терминалов (включая консоль), которые поддерживают графику, запускается графическая среда. Однако это легко отменить в любой момент.
Графическая среда представляет собой большой набор программ, объединенных общим названием X-Window и делящихся на две неравные части: X-клиенты и X-серверы. X-Window не имеет ничего общего с системами Windows, за исключением того, что в ней тоже используется оконный графический интерфейс.
То, что принято называть X-клиентами, есть разнообразные программы, написанные в расчете на работу в графическом (оконном) интерфейсе. Это значит, что в качестве элементов управления в них предусмотрены кнопки, меню и т.п. X-клиенты называются так потому, что свое желание вывести на экран пользователя те или иные графические элементы (окно, поле текстового ввода, кнопки и т.п.) они оформляют в виде обращений к X-серверу по стандартному для системы X-Window протоколу. Программа, которая называется X-сервером, выполняет просьбы X-клиентов по отображению на экране упомянутых графических элементов.
Таким образом, в X-Window разделяются функции программ, выполняющих некую конкретную полезную и уникальную работу (X-клиентов) и функции рисования на экране, которую выполняет X-сервер. Фактически это означает, что X-клиент и X-сервер могут работать как на одной машине, так и на разных, в том числе и удаленных друг от друга на многие тысячи километров оптического кабеля.
Когда мы видим на экране нашего компьютера, работающего под управлением Solaris, некую графическую картинку, мы не можем сразу сказать, относится ли она к программе, запущенной непосредственно на этом же компьютере, или эта программа работает на другой машине, а к нам лишь транслирует запросы на вывод изображения. Зато мы можем однозначно утверждать, что на нашем компьютере запущен X-сервер, коль скоро именно на этом компьютере мы видим картинку.
Итак, запомним: X-сервер - это программа, работающая на машине, где мы видим какие-то окна и прочую графику. X-клиент - это приложение, которое где-то работает и передает команды на вывод графики, связанной с этим приложением, некоему X-серверу.
Протокол X-Window весьма популярен и на его основе создано много графических сред, отличающихся друг от друга прежде всего внешним видом и программным интерфейсом высокого уровня (API). Это значит, что обычному пользователю почти все равно, в какой графической среде работать, хотя в новой для него среде придется выучить, как выглядят всякие нужные элементы управления типа "закрыть окно" или "переместить окно", а также изучить ряд нетривиальных действий. Например, в одних графических средах принято выполнять операцию Copy-and-Paste посредством выделения нужного фрагмена мышью и нажатия средней клавиши мыши в том месте, куда надо перенести текст. В других эта же операция требует выделения текста, нажатия Ctrl-Ins и затем нажатия Shift-Ins там, где надо вставить текст. В Solaris, к сожалению, по умолчанию используется второй, намного менее производительный способ.
Графической средой по умолчанию в Solaris является CDE (Common Desktop Environment), принятая в качестве отраслевого стандарта и использующаяся также в HP-UX. Впрочем, начиная с Solaris 8, Sun предоставляет для загрузки со своего web-сайта также среду GNOME, которая применяется в Linux-системах. В настоящее время вы можете загрузить и установить GNOME 2.0, надо лишь посетить страницу http://wwws.sun.com/software/star/gnome/. По адресу http://www.sugoi.org/bits/index.php?bit_id=11 находится довольно забавная страница с независимым рассказом о доступных в Solaris графических интерфейсах.
Самое важное в X-Window: X-server всегда работает на том компьютере, на экране которого пользователь видит окна запущенных им программ. Даже если это обычный персональный компьютер под управлением Microsoft Windows, на нем может работать X-server. Лучший X-server под все системы Microsoft Windows - это Exceed (http://www.hummingbird.com/products/nc/exceed/index.html).Также есть менее удобный, но кое-где популярный X-сервер MIX.
X-клиент - это программа, как правило, работающая под UNIX. Она может выполняться на том же компьютере, где запущен X-сервер, показывающий графическую картинку пользователю, а может работать сколь угодно далеко от него. X-сервер и X-клиент легко взаимодействуют через любую IP-сеть, например, через Интернет.
Чтобы дать знать программе - X-клиенту, куда ей следует направлять команды для X-сервера, установите переменную среды окружения DISLPLAY. В ней указывается адрес компьютера, на котором запущен X-сервер, и номер (обычно 0), идентифицирующий сеанс этого X-сервера:
export DISPLAY="my.home.computer.com:0"
Как узнать и установить системное время и дату?
Для того чтобы узнать, который час, в UNIX принято использовать команду date. Она сообщает и текущую системную дату, и время. Команда time предназначена для другой цели - она подсчитывает время, потраченное системой на выполнение команды. Попробуйте посредством команды
time "find / -name \* "
проверить, сколько процессорного времени займет составление и вывод полного списка файлов системы.
С помощью команды date можно не только узнать текущее время, но и установить его. Устанавливать системное время может только root.
Программа date понимает разные форматы дат, когда вы требуете установить дату. Наиболее стандартным является формат
date hhmm
или
date ссyyMMddhhmm.ss
где:
сс - 19 или 20 (cc - от "век" - century);
yy - год (98, если 1998, или 67, если 2067);
MM - месяц;
dd - число месяца;
hh - час;
mm - минуты;
ss - секунды.
date
без параметров выводит текущую дату и время, в формате, определяемом параметрами локализации (locale).
Какая аппаратура быстрее?
Естественно, для разных задач подходят разные компьютеры. Например, компьютеры с процессором Alpha обычно быстрее своих Intel-собратьев выполняют расчеты с числами с плавающей запятой. Это значит, что вычисления, связанные с расчетами координат, решением уравнений или моделированием молекул, быстрее выполнит компьютер с процессором Alpha.
В настоящее время процессоры Alpha широко используются в высокопроизводительных серверах от Hewlett-Packard и в других, еще более специализированных системах, таких как суперкомпьютеры Cray и Fujitsu.
Если же речь идет о целочисленных вычислениях, пусть и достаточно громоздких, например, рендеринге, преобразовании графических объектов, 3D-визуализации, где координаты могут быть заданы только целыми числами, процессоры Intel отлично справятся с ними.
Сейчас мы говорили о процессорах Alpha и Intel, но на деле разговор касается двух разных архитектур - RISC и CISC. Процессоры Intel традиционно тяготеют к последней, в то время как процессоры SPARC - к первой. ОС Solaris выпускается в версиях для обеих архитектур, хотя изначально компания Sun не выпускала версию Solaris для Intel, а многочисленные пользователи этой системы во всем мире до сих пор утверждают, что версия для SPARC более производительна и надежна. Это, в частности, объясняется тем, что механизмы обеспечения многозадачности тесно связаны с используемой аппаратурой, и версия Solaris под Intel "подогнана" под архитектуру процессоров Intel и архитектуру аппаратных средств, разработанных для них.
Надо отметить отличные результаты процессора Itanium, сравнительно нового процессора Intel с 64-разрядной архитектурой, который прекрасно показал себя в тесте вычислений с плавающей запятой SPECfp2000, что выгодно отличает его от предшествовавших 32-разрядных собратьев, но менее удачно выступил в целочисленном тесте.
В заключение разговора о предпочтительности той или иной аппаратуры следует сказать, что:
Для работы Solaris под серьезной нагрузкой, такой как СУБД Oracle с тысячами клиентов и важностью высокой скорости реагирования, система на базе процессоров RISC скорее всего окажется более результативной. Независимо от используемой аппаратной платформы конфигурация компьютера должна быть хорошо согласована: быстрый процессор должен работать с быстрой оперативной памятью, а дисковая подсистема (контроллеры и диски) обязана без задержек отрабатывать команды чтения и записи.
Недостаточный объем кэша любого уровня - как кэша процессора на кристалле, так и кэша дискового контроллера - может привести к значительному снижению производительности.
| Alpha21264C, 1.01 GHz | 561 | 585 | Compaq AlphaServer GS160 |
| Alpha21264C, 1 GHz | 776 | 621 | Compaq AlphaServer ES45 |
| Alpha21264B, 833 MHz | 518 | 621 | Compaq AlphaServer ES40 |
| Itanium, 800 MHz | 379 | 701 | HP rx4610 |
| Itanium, 800 MHz | 358 | 655 | HP i2000 |
| UltraSPARC III 1.05 GHz | 537 | 701 | Sun Blade 2050 |
| UltraSPARC III 900 MHz | 470 | 629 | Sun Blade 1000 |
| UltraSPARC III 750 MHz | 363 | 312 | Sun Blade 1000 |
| Power4, 1.3. GHz | 790 | 1098 | IBM eServer 690 |
Кэш поиска имен каталогов (DNLC)
Чтобы не искать номер индексного дескриптора по имени файла каждый раз, когда к файлу происходит обращение, система кэширует имена файлов и каталогов вместе с номерами их виртуальных индексных дескрипторов. Этот специальный кэш называется кэш поиска имен каталогов (directory name lookup cache - DNLC).
При открытии файла DNLC вычисляет соответствующий индексный дескриптор по имени этого файла. Если имя уже находится в кэше, то оно отыскивается очень быстро, поскольку не происходит сканирования каталогов на диске. Каждая запись DNLC в ранних версиях системы имела фиксированный размер, поэтому пространство для имени файла не могло превышать 30 символов, а более длинные имена файлов не кэшировались. Начиная с Solaris 7, это ограничение снято. Если каталог содержит несколько тысяч записей, поиск номера индексного дескриптора конкретного файла отнимет много времени. В том случае, когда в системе открыто много файлов, а количество файлов в рабочих каталогах велико, высокая частота успешных обращений к DNLC очень важна.
Кэш имен каталогов не нуждается в настройке, хотя его размер зависит от значения maxusers. По умолчанию он определяется как (17xmaxusers)+90 (в Solaris 2.5.1) или 4x(maxusers + max_nprocs)+320 (в Solaris 2.6 и выше). Другие параметры, на которые тоже оказывает влияние maxusers, обсуждены в лекции 10.
Команда
vmstat -s
показывает частоту успешных попаданий в DNLC с момента начала работы системы.
Если частота промахов велика (попаданий обычно не должно быть меньше 90%), следует подумать об увеличении размера DNLC. Проверим этот показатель работы системы командой
vmstat -s |grep 'name lookups' 422920 total name lookups (cache hits 99%)
Количество запросов к DNLC в секунду можно получить из поля namei/s в выводе команды sar -a:
sar -a 1 5 SunOS sunny 5.9 Generic_112234-03 i86pc 07/03/2004 19:26:50 iget/s namei/s dirbk/s 19:26:51 0 1 0 19:26:52 0 0 0 19:26:53 0 0 0 19:26:54 0 4 0 19:26:55 0 0 0
Как видно, система не очень-то загружена запросами к файлам и одыхает. А теперь запустим операцию, которая точно требует многократного обращения к DNLC:
find / -name "top" & [1] 577 sar -a 1 5 SunOS sunny 5.9 Generic_112234-03 i86pc 07/03/2004 19:27:14 iget/s namei/s dirbk/s 19:27:15 1675 2592 1922 19:27:16 1220 2365 1474 19:27:17 968 1882 1172 19:27:18 1057 2107 1292 19:27:19 1231 2211 1443 vmstat -s |grep 'name lookups' 503370 total name lookups (cache hits 86%)
При интенсивных файловых операциях и доступе ко многим каталогам одновременно эффективность кэша имен каталогов снижается, но по-прежнему остается достаточно большой.
Кэширование файловой системы
Ускорить доступ к любой медленной файловой системе, такой как удаленная система NFS или файловая система привода CD-ROM, можно за счет создания файловой системы кэша. Проще говоря, содержимое медленной файловой системы может быть закэшировано на локальном диске. Управление такой файловой системой кэша (cachefs) осуществляется утилитой cfsadmin.
НАЗАД ВПЕРЕД

/td>
|
Классы сетей
Самой крупной IP-сетью в мире является глобальная сеть Internet. Ее адресное пространство разделено на диапазоны адресов, которые называются "сетями". Сети разделены на классы. Адреса сетевых интерфейсов компьютеров в сети, как правило, относятся к классам A, B или С.
Разделение сетей на классы определяется в RFC 950 и ряде других RFC 2). Кроме сетей A, B, С есть и другие сети. Они представляют собой меньшие по размеру блоки сетей, которые используются для различных служебных надобностей.
Сети классов от A до С отличаются значением первого байта IP-адреса. Значение первого байта сети класса А находится в диапазоне от 1 до 126, класса B - от 128 до 191, класса C - от 192 до 223. классы сетей, в адресах которых первый байт имеет значение от 224 до 254, именуются от D до F. Они имеют служебное назначение и их адреса не используются обычными сетевыми интерфейсами.
Предполагается, что в сетях класса A номер сети занимает первый байт, а остальные три - это номер компьютера (точнее, номер сетевого интерфейса). Таким образом, в сети класса А может быть до 16777214 интерфейсов. В сети класса В номер сети занимает два байта адреса, максимальное число интерфейсов в такой сети - 65534. В сети класса С номер сети занимает три байта, номер компьютера - один, максимальное число интерфейсов в такой сети - 254.
Количество одновременно записываемых блоков
Так как размер кластера файловой системы, как правило, составляет 8 Кбайт, драйвер файловой системы при записи собирает данные в блоки по 8 Кбайт для большей эффективности использования дискового пространства. При записи файлов значительных размеров драйвер файловой системы группирует несколько блоков для того, чтобы вместо серии мелких операций ввода-вывода выполнить одну большую по объему операцию.
Количество группируемых блоков равно параметру файловой системы maxcontig . В версиях, предшествующих Solaris 8, этот параметр по умолчанию был равен семи, и, таким образом, операция ввода-вывода происходила одновременно с семью последовательными блоками и позволяла одновременно записать порцию данных размером 56 Kбайт. Такое значение по умолчанию связано с ограничениями конструкции в раннем оборудовании Sun: системы, основанные на архитектуре sun4, не способны передавать за одну операцию более 64 Kбайт. В архитектурах sun4c, sun4m, sun4d и sun4u таких ограничений нет. В Solaris 8 значение по умолчанию изменилось и составляет 16 блоков (128 Kбайт).
Изменение параметра maxcontig может серьезно повлиять на производительность файловой системы , при работе с которой преобладают последовательные операции по записи средних и больших (более нескольких десятков килобайт) файлов на диск. Если при доступе к файловой системе большинство операций ввода-вывода совершается с данными малого размера, то изменение maxcontig не принесет особой пользы.
Размер кластера файловой системы задается с помощью ключа -С blocks команды newfs при создании файловой системы. Для существующей файловой системы его можно изменить с помощью ключа -a команды tunefs.
Настройка maxcontig дает наилучший результат, если ее выполнить при создании файловой системы, так как это фактически определит размер кластера файловой системы. Проведение настройки уже используемой файловой системы не даст столь же впечатляющего результата, поскольку блоки, которые уже были записаны, не будут перекомпонованы.
Команды
Файл /etc/security/exec_attr представляет собой базу данных атрибутов запуска программ, ассоциированных с тем или иным профилем (из prof_attr);
# execution attributes for profiles. see exec_attr(4) # #pragma ident "@(#)exec_attr 1.1 01/10/23 SMI" # # iPlanet Directory Management:suser:cmd::: /usr/sbin/directoryserver:uid=0 Software Installation:suser:cmd:::/usr/bin/pkgparam:uid=0 Network Management:suser:cmd:::/usr/sbin/in.named:uid=0 File System Management:suser:cmd:::/usr/sbin/mount:uid=0 FTP Management:suser:cmd:::/usr/sbin/ftprestart:euid=0 Software Installation:suser:cmd:::/usr/bin/pkgtrans:uid=0 Name Service Security:suser:cmd:::/usr/bin/nisaddcred:euid=0 Mail Management:suser:cmd:::/usr/sbin/makemap:euid=0 Software Installation:suser:cmd:::/usr/sbin/install:euid=0 Process Management:suser:cmd:::/usr/bin/crontab:euid=0 Audit Review:suser:cmd:::/usr/sbin/praudit:euid=0 Name Service Security:suser:cmd:::/usr/sbin/ldapclient:uid=0 Media Backup:suser:cmd:::/usr/bin/mt:euid=0
Формат записей в файле /etc/security/exec_attr предполагает обязательное указание имени профиля прав, жестко установленных значений полей policy и cmd, идентификатора и, при необходимости, атрибутов:
name:policy:type:res1:res2:id:attr
name - имя профиля прав (помните регистр букв в имени важен!);
policy - политика, ассоциированная с профилем прав, единственное допустимое значение этого поля в настоящее время - suser;
type - тип объекта, определенного в данной записи, единственное допустимое значение этого поля в настоящее время - cmd;
id - строка, являющаяся уникальным идентификатором объекта, описанного в данной записи; для типа cmd этот идентификатор, кроме того, является полным именем файла выполняемой программы или символом звездочка (*), который разрешает запустить любую команду. Можно указывать звездочку в конце полного имени файла, что будет означать любую программу в соответствующем каталоге;
attr - атрибуты вида имя=значение, разделенные точкой с запятой; допустимые варианты атрибутов: euid, uid, egid и gid.
Все компоненты RBAC могут быть использованы как в виде файлов, так и в виде карт NIS или таблиц NIS+. Соответственно, в файле /etc/nsswitch.conf понадобится указать порядок обращения к различным источникам.
Итак, схема назначений прав в системе ролей следующая: определенные программы могут быть запущены не только пользователем root, что традиционно, но и другими пользователями. Для этого существуют права (авторизации, authorizations), которые могут быть назначены напрямую пользователям (что нежелательно с организационной точки зрения) или профилям прав. Профиль прав, представляющий собой набор определенных прав, назначается роли. Пользователь может претендовать на то, что он будет играть ту или иную роль, если он знает пароль этой роли и может "перевоплотиться" в нее с помощью команды su. Рис. 21.1 иллюстрирует взаимоотношения компонентов RBAC между собой.
Команды, поддерживающие роли
Следующие команды проверяют права (authorizations) пользователя, который пытается их выполнить, и поддерживают систему RBAC. Это значит, что выполнить эти команды может не только root, но и другие пользователи, которые начали играть определенную роль, "переключившись" в нее:

Рис. 21.1. Отношения между компонентами RBAC
все программы, запускаемые внутри как приложения из Solaris Management Console; программы запланированного запуска at, atq, batch, crontab; команды, связанные с работой физических устройств - allocate, deallocate, list_devices, cdrw.
Команды управления ролями
Управление ролями производится путем редактирования файлов в каталоге /etc/security или посредством программ roleadd, rolemod и roledel. Кроме того, управлять ролями и назначением прав в RBAC можно с помощью Solaris Management Console.
Можно, например, добавить роль printmgr с назначением прав по умолчанию:
roleadd printmgr
А с помощью команды
roleadd -D
эти самые установки по умолчанию можно увидеть воочию:
roleadd -D group=other,1 project=default,3 basedir=/home skel=/etc/skel shell=/bin/pfsh inactive=0 expire= auths= profiles=All
Для выполнения команд, предполагающих применение ролей, следует воспользоваться специальными командными процессорами, в которых реализована работа с ролями. Имеется набор таких командных процессоров, функционально эквивалентных своим "безролевым" аналогам: /bin/pfsh, /bin/pfcsh, или /bin/pfksh. Эти командные процессоры следует назначать в качестве login shell для ролей.
Компиляция, установка пакетов, управление пакетами, применение пакетов обновлений
Существует несколько способов установить программу или пакет программ в UNIX. Выбор способа зависит от того, в каком виде доступен пакет программ, который вам требуется. Если пакет доступен только в виде набора исполняемых файлов, уже скомпилированных для вашей платформы, то выбор невелик: придется устанавливать то, что имеется.
Например, требуется найти более наглядное средство наблюдения за процессами, чем ps. На http://www.sunfreeware.com/ ищем top и загружаем его на свой компьютер. Если прямо с sunfreeware его получить не удается, набираем имя файла top-3.5-sol9-intel-local.gz в строке поиска Google и получаем достаточное количество ссылок на ftp-серверы, где он лежит. Такое бывает часто: сервер sunfreeware перегружен и не всегда готов принять посетителя.
Теперь распаковываем подарочек...
gunzip top-3.5-sol9-intel-local.gz
и в нашем распоряжении оказывается файл пакета. Надо указать команде pkgadd, что именно отсюда мы будем пакет устанавливать:
pkgadd -d top-3.5-sol9-intel-local The following packages are available: 1 SMCtop top (intel) 3.5 Select package(s) you wish to process (or 'all' to process all packages). (default: all) [?,??,q]: y
ERROR: Entry does not match available menu selection. Enter the number of the menu item you wish to select, or the token which is associated with the menu item, or a partial string which uniquely identifies the token for the menu item. Enter ?? to reprint the menu.
Select package(s) you wish to process (or 'all' to process all packages). (default: all) [?,??,q]: all
Ошибка (сообщение ERROR в 6-й строке листинга) вызвана тем, что мы поторопились ввести y в ответ на вопрос: привычка сказывается. Честно напишем all, чтобы установить все программы, которые доступны в пакете. После этого получаем:
Processing package instance <SMCtop> from </export/home/top-3.5-sol9-intel-local>
top (intel) 3.5 William LeFebvre Using </usr/local> as the package base directory. ## Processing package information. ## Processing system information. 4 package pathnames are already properly installed. ## Verifying disk space requirements. ## Checking for conflicts with packages already installed. ## Checking for setuid/setgid programs.
The following files are being installed with setuid and/or setgid permissions: /usr/local/bin/top <setgid sys>
Наконец вопрос, на который как раз следует ответить утвердительно:
Do you want to install these as setuid/setgid files [y,n,?,q] y Installing top as <SMCtop> ## Installing part 1 of 1. /usr/local/bin/top /usr /usr/local/doc/top/Changes /usr/local/doc/top/FAQ /usr/local/doc/top/INSTALL /usr/local/doc/top/Porting /usr/local/doc/top/README /usr/local/doc/top/SYNOPSIS /usr/local/man/man1/top.1 [ verifying class <none> ] Installation of <SMCtop> was successful.
Проверить, удачно ли установился пакет, можно командой
pkginfo | grep top application SMCtop top system SUNWdtcor Solaris Desktop /usr/dt filesystem anchor system SUNWdtdst CDE Desktop Applications system SUNWdtdte Solaris Desktop Login Environment system SUNWdtezt Solaris Desktop Extensions Applications system SUNWdthez Desktop Power Pack Help Volumes system SUNWdtlog System boot for Desktop Login system SUNWdtmaz Desktop Power Pack man pages system SUNWeuodf UTF-8 Core OPENLOOK Desktop Files system SUNWsadmi Solstice Enterprise Agents 1.0.3 Desktop Management Interface
Как видно, пакетов, в названиях которых имеется подстрока top, установлено немало, и тот, которым занимались мы, - на самом первом месте.
Удалить пакет можно командой pkgrm, например, pkgrm SMCtop.
Иногда бывает необходимо не просто установить пакет, который получен в виде набора исполняемых файлов и документации, а собрать его из исходных текстов. В этом случае надо следовать инструкциям по установке, которые обычно находятся в файлах README и INSTALL дистрибутива пакета. В любом случае вам понадобится программа make (поставляется в комплекте с Solaris) и компилятор языка С (не поставляется).
Коммерческая версия компилятора С фирмы Sun не поставляется с бесплатным набором компакт-дисков дистрибутива Solaris. Его надо покупать отдельно, это можно сделать со страницы http://wwws.sun.com/software/sundev/suncc/buy/index.html.
Компания Sun предоставляет возможность использовать ее компилятор С в течение 60 дней бесплатно. Для этого с той же страницы надо загрузить trial-версию. Она является полнофункциональной - просто при установке следует выбрать вариант установки trial, и временный серийный номер продукта будет сгенерирован автоматически.
Кроме коммерческого компилятора можно работать с бесплатной версией GNUC под Solaris. Ее можно получить с http://www.sunfreeware.com/ или найти через центральный портал проекта GNU gnu.org. GNU C можно загрузить в виде пакета gcc.
Загрузим файл gcc_small-3.3.2-sol9-intel-local.gz и установим пакет gcc для того, чтобы иметь возможность компилировать программы из исходных текстов:
pkgadd gcc_small-3.3.2-sol9-intel-local.gz pkgadd: ERROR: no packages were found in </var/spool/pkg>
Ошибка: файл пакета сжат, ему требуется декомпрессия, кроме того, имя файла пакета надо указывать с ключом d:
gunzip gcc_small-3.3.2-sol9-intel-local.gz ls gcc_small-3.3.2-sol9-intel-local pkgadd -d gcc_small-3.3.2-sol9-intel-local The following packages are available: 1 SMCgcc gcc (intel) 3.3.2 Select package(s) you wish to process (or 'all' to process all packages). (default: all) [?,??,q]:
Далее действуем, как в предыдущем примере.
Если необходимо, то можно получить довольно много бесплатного программного обеспечения под Solaris со страницы http://www.sun.com/bigadmin/features/articles/x86_desktop.html.
Затем его можно установить вышеописанным образом.
При установке программ из исходных текстов, следует руководствоваться инструкциями из файлов README и INSTALL, которые присутствуют в дистрибутиве наряду с исходными текстами.
Компоненты RBAC
Рассмотрим все компоненты RBAC последовательно, начиная с пользователей и ролей.
Всего существует пять компонентов: пользователи, роли, профили, авторизации, команды.
Копирование дистрибутива
Для создания сервера установки прежде всего надо выполнить копирование дистрибутива Solaris на диск будущего сервера установки. Копируются образы дистрибутивных дисков (или только одного диска, если это DVD), это можно сделать с помощью программы, входящей в дистрибутив. Рассмотрим пример в предположении, что используются обычные диски CD-ROM, а не DVD. Допустим, что нам требуется установить Solaris на компьютеры разных архитектур, то есть одна часть этих компьютеров имеют архитектуру SPARC, а другая часть - Intel (x86). Тогда требуется копировать два разных дистрибутива - для разных архитектур - и для этого выполнить следующие действия:
Смонтировать первый компакт-диск дистрибутива для платформы SPARC (например, в каталог /cdrom сервера установки).
Создать каталог для образа дистрибутива командой:
mkdir -p /export/install/sparc
Затем выполнить следующие команды:
cd /cdrom/Solaris_9/Tools ./setup_install_server /export/install/sparc
Демонтировать /cdrom, вставить второй компакт-диск дистрибутива, смонтировать его в /cdrom.
Добавить к образу установки содержимое второго диска:
cd /cdrom/Solaris_9/Tools ./add_to_install_server /export/install/sparc
Аналогично смонтировать Solaris SPARC 9 Platform Edition Language CD_ROM и добавить его к образу установки:
cd /cdrom/Solaris_9/Tools ./add_to_install_server /export/install/sparc
Смонтировать первый компакт-диск дистрибутива для платформы Intel (например, в каталог /cdrom сервера установки).
Создать каталог для образа дистрибутива для платформы x86 командой:
mkdir -p /export/install/intel
Затем выполнить следующие команды:
cd /cdrom/Solaris_9/Tools ./setup_install_server /export/install/intel
Демонтировать /cdrom, вставить второй компакт-диск дистрибутива, смонтировать его в /cdrom.
Добавить к образу установки содержимое второго диска:
cd /cdrom/Solaris_9/Tools ./add_to_install_server /export/install/intel
Аналогично смонтировать Solaris INTEL 9 Platform Edition Language CD_ROM и добавить его к образу установки:
cd /cdrom/Solaris_9/Tools ./add_to_install_server /export/install/intel
При копировании с DVD процедура намного короче:
Смонтировать DVD-диск дистрибутива в /dvd;
Выполнить команды
mkdir -p /export/install/intel cd /dvd/Solaris_9/Tools ./setup_install_server /export/install/intel
Повторить то же самое для платформы SPARC с каталогом /export/install/sparc и компакт-диском для платформы SPARC.
Модули PAM
Механизм аутентификации PAM основан на модулях аутентификации. Сейчас можно уже называть его отраслевым стандартом, так как PAM поддерживается в Linux, FreeBSD, Solaris и HP-UX, а также в ряде других менее распространенных систем UNIX.
Со стороны приложения PAM предоставляет API для обращения к функциям аутентификации.
Программа (login, su, ftp, httpd и т.п.) вызывает функцию PAM API в ситуации, требующей провести аутентификацию. С другой стороны (со стороны модуля аутентификации), PAM располагает интерфейсом SPI (Service Provider Interface), через который вызов API транслируется к источнику аутентификации (файлу /etc/passwd, серверу TACACS и т.п.).
API является общим для всех программ, а SPI содержит по одному модулю на каждый вариант аутентификации (один - через /etc/passwd, другой - через Kerberos и т.п.).
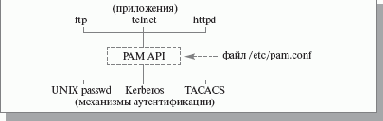
Рис. 20.1. Архитектура PAM
С помощью PAM системный администратор может установить свой способ аутентификации для любой сетевой службы. Более того, спектр способов весьма широк. Наиболее впечатляющей, на мой взгляд, является возможность аутентификации через базу данных о пользователях любого домена Windows NT или Windows 2000.
Самой важной возможностью PAM является гибкость настройки аутентификации. Системный администратор может указать любой способ аутентификации для любой программы. Правда, при этом необходимо, чтобы программа поддерживала аутентификацию через PAM. Например, web-сервер может не уметь работать с PAM. Однако Apache умеет это делать, хотя для этого требуется загружать отдельный модуль Apache.
В Solaris настройки PAM хранятся в файле /etc/pam.conf. Во многих других системах UNIX допускается также хранение настроек в каталоге /etc/pam.d/. Если такой каталог существует, то подпрограммы PAM игнорируют содержимое /etc/pam.conf.
Аутентификацию через PAM используют программы login, passwd, su, rlogind, rshd, telnetd, ftpd, rpc.rexd, uucpd, init, sac, cron, ppp, dtsession, ssh и ttymon. Программа dtlogin, которая является службой входа в сеть в графической среде Common Desktop Environment (CDE), тоже использует PAM.
Модули PAM могут располагаться в любых каталогах, однако негласное правило требует, чтобы файл имел имя, начинающееся с pam, pam_modulename.so.x, например pam_smb_auth.so.6, и хранился в подкаталогах каталога /usr/lib/security/.