Монтирование удаленных файловых систем
Монтирование файловых систем NFS осуществляется практически так же, как и монтирование файловой системы любого другого типа. Рассмотрим, как смонтировать файловую систему машины под управлением Linux, если роль файлового сервера выполняет Solaris (компьютер pxy работает под Linux, компьютер с адресом 192.168.5.33 под Solaris):
root@pxy# mount -t nfs 192.168.5.33:/nfst ./nfst root@pxy# mount /dev/hda1 on / type ext2 (rw) none on /proc type proc (rw) none on /dev/pts type devpts (rw,mode=0620) /dev/hda3 on /usr type ext2 (rw) /dev/hda2 on /var type ext2 (rw) 192.168.5.33:/nfst on /usr/home/filip/nfst type nfs (rw,addr=192.168.5.33)
Удаленная файловая система успешно смонтирована, о чем говорит последняя строка вывода mount.
Попробуем осуществить копирование файла:
root@pxy# cp /etc/mail/aliases /usr/home/filip/nfst/ root@pxy# ls /usr/home/filip/nfst/ aliases root@pxy# ls -l /usr/home/filip/nfst/ total 1 -rw-r--r-- 1 root root 406 Jun 20 22:30 aliases
Файл был записан, как отсюда видно, от имени пользователя root и группы root. На самом деле, в выводе команды ls таится подвох. Ведь команда ls на локальной машине использует для получения соответствия между идентификатором в файловой системе и именем пользователя (группы) локальный файл /etc/passwd. Потенциальная опасность состоит в том, что на удаленном сервере и на локальной машине файлы /etc/passwd окажутся разными. В случае пользователя root это не важно, если только на сервере NFS пользователю root нашей машины разрешено монтировать файловую систему от имени root. В противном случае все файлы, которые локальный root будет записывать на удаленный сервер, будут записываться от имени nobody (или иного имени, если так определено конфигурацией сервера).
root@pxy# ls -ld /usr/home/filip/nfst/ drwxrwxr-x 2 root bin 512 Jun 20 22:30 /usr/home/filip/nfst/
Поскольку в нашем примере файл был записан от имени root, следует предположить, что настройки сервера NFS это позволяют. Проверим это на компьютере 192.168.5.33:
192.168.5.33# cat /etc/dfs/dfstab # Place share(1M) commands here for automatic execution # on entering init state 3. # # Issue the command '/etc/init.d/nfs.server start' to run # the NFS daemon processes and the share commands, after # adding the very first entry to this file. # # share [-F fstype] [ -o options] [-d "<text>"] # <pathname> [resource] # .e.g, # share -F nfs -o rw=engineering -d "home dirs" # /export/home2 share -F nfs -o root=pxy.spb.ru /nfst
Здесь, на компьютере 192.168.5.33, управляемом Solaris, разделяется общий каталог /nfst, а с компьютера pxy.spb.ru разрешено работать с этим каталогом от имени root. Следует осторожно раздавать подобные права и в большинстве случаев избегать разделения в сети каталогов с настроечной или секретной информацией.
По команде showmount можно получить список компьютеров, подключенных к серверу NFS:
192.168.5.33# showmount pxy.spb.ru www.spb.ru
Таким образом, на сервере NFS имя хозяина файла совпадает с тем, что мы видели с клиента NFS, а имя группы файла - нет, так как под одним и тем же идентификатором в файлах /etc/group на сервере и на клиенте значатся разные группы. На практике не следует допускать подобных расхождений, чтобы не возникало файлов, угрожающих безопасности системы. Синхронизация файлов passwd и group на сервере и клиентах или использование общей базы NIS помогут избежать путаницы в именах групп и владельцев файлов на сервере и клиенте NFS.
192.168.5.33# pwd /nfst 192.168.5.33# ls -l total 2 -rw-r--r-- 1 root root 406 Июн 20 22:30 aliases
Обратите внимание на одинаковое время создания файла с точки зрения команды ls сервера и клиента. В поле времени указывается время создания, которое записывает туда сервер NFS. Следует синхронизировать не только файлы group и passwd, но и время на сервере NFS и его клиентах, чтобы не было расхождений между клиентом и сервером при выполнении резервного копирования или выяснения "свежести" файлов.
Надежное хранение данных
Ни один системный администратор не хотел бы иметь дело с восстановлением файлов из резервной копии. Во-первых, в большинстве нормальных систем поломки случаются не каждый день, и поэтому опыта в восстановлении данных у большинства наших коллег мало или нет совсем. Во-вторых, поломки сами по себе создают массу неудобств и часто ведут к авральным работам служб технической поддержки. Поэтому счастлив тот системный администратор, чья система спроектирована так, чтобы обеспечить максимальную надежность хранения данных.
Под надежностью хранения подразумевают следующее: данные должны быть корректно сохранены на диск (или иной носитель), т.е. система всегда должна считывать именно те данные, которые были записаны; данные, которые считываются несколько раз, всегда должны считываться одинаковым образом; и при сбое должна быть возможность восстановить исходные данные в том виде, в котором они сохранялись.
Кроме того, при проектировании систем важно учитывать требуемую емкость носителей данных с тем, чтобы по мере накопления данных им хватало места в течение всей жизни системы.
Корректность сохранения данных на носитель и неизменность их состояния между считываниями (разумеется, при условии, что данные не требуют модификации) обеспечивается операционной системой. В случае, если носитель исправен, никаких дополнительных действий, связанных с обеспечением этих свойств данных, системный администратор предпринимать не должен.
Здесь уместно заметить, что системному администратору или проектировщику системы следует полагаться только на проверенные решения. Следующие несколько абзацев предназначены тем, кто планирует эксплуатировать Solaris на платформе x86, поскольку платформа Sun SPARC представляет собой более чем проверенное решение, за качество которого единственный его производитель, Sun Microsystems, ручается головой. Случаев жалоб на фирменное оборудование Sun в России мне слышать не приходилось. Коллеги из московского представительства: поправьте меня, если я не прав!
Настройка DHCP-клиента
Для того чтобы система полагала некий сетевой интерфейс динамически настраиваемым через DHCP, достаточно команды
ifconfig имя_интерфейса dhcp start
После этого программа ifconfig автоматически вызовет демона dhcpagent, который занимается отправкой DHCP-запросов и настройкой интерфейса в соответствии с полученным ответом. Посмотреть параметры, полученные через dhcp, можно с помощью команды
ifconfig имя_интерфейса dhcp status
При настройке DHCP-клиента надо помнить, что параметры настройки выделяются на определенное время и по истечении этого времени будут автоматически запрошены у сервера заново.
Настройка DHCP-сервера
DHCP-сервер, т.е. программа, которая принимает запросы от DHCP-клиентов и отвечает им, в Solaris носит название in.dhcpd. Для настройки параметров DHCP-сервера следует модифицировать таблицы dhcptab и dhcp_network. Первая определяет группы различных параметров (например, совокупность диапазона назначаемых адресов, адреса шлюза и сервера имен), вторая устанавливает соответствие между определенными клиентами DHCP и IP-адресами. Эту таблицу можно использовать для задания явно указанных адресов отдельным компьютерам в сети. Подробнее формат файлов таблиц описан в руководстве по dhcptab(4) и dhcp_network(4) .
В Solaris DHCP-сервер выполняет также функции BOOTP-сервера (если это требуется) или может быть настроен как BOOTP-посредник (BOOTP-relay). Например, при старте программы dhcpmgr последняя спрашивает, хотим ли мы настроить BOOTP-relay или DHCP-сервер:
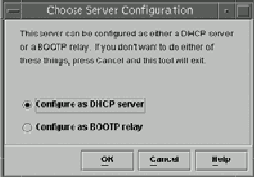
Рис. 13.2. Окно dhcpmgr сразу после запуска
Для комплексной настройки DHCP-сервера можно применять графическую программу dhcpmgr (/usr/sadm/admin/bin/dhcpmgr), которая предоставляет доступ ко всем необходимым параметрам DHCP-сервера и обладает функциональностью трех утилит управления DHCP-сервером: dhcpconfig, dhtadm и pntadm:

Рис. 13.3. Рабочее окно dhcpmgr
Настройка доступа к некоторым службам через PAM
Конфигурационный файл /etc/pam.conf определяет соответствие между приложением и PAM-модулями, которые выполняют аутентификацию.
При обращении приложения к PAM для аутентификации, происходит инициализация соединения приложения с PAM API. При этом читается файл конфигурации /etc/pam.conf.
Файл конфигурации содержит список модулей PAM, которые будут использоваться для аутентификации. Рассмотрим файл конфигурации /etc/pam.conf:
# #ident "@(#)pam.conf 1.20 02/01/23 SMI" # # Copyright 1996-2002 Sun Microsystems, Inc. All rights # reserved. Use is subject to license terms. # # PAM configuration # # Unless explicitly defined, all services use the modules # defined in the "other" section. # # Modules are defined with relative pathnames, i.e., # they are relative to /usr/lib/security/$ISA. # Absolute path names, as present in this file in previous # releases are still acceptable. # # Authentication management # # login service (explicit because of pam_dial_auth) # login auth requisite pam_authtok_get.so.1 login auth required pam_dhkeys.so.1 login auth required pam_unix_auth.so.1 login auth required pam_dial_auth.so.1 # # rlogin service (explicit because of pam_rhost_auth) # rlogin auth sufficient pam_rhosts_auth.so.1 rlogin auth requisite pam_authtok_get.so.1 rlogin auth required pam_dhkeys.so.1 rlogin auth required pam_unix_auth.so.1 # # rsh service (explicit because of pam_rhost_auth, # and pam_unix_auth for meaningful pam_setcred) # rsh auth sufficient pam_rhosts_auth.so.1 rsh auth required pam_unix_auth.so.1 # # PPP service (explicit because of pam_dial_auth) # ppp auth requisite pam_authtok_get.so.1 ppp auth required pam_dhkeys.so.1 ppp auth required pam_unix_auth.so.1 ppp auth required pam_dial_auth.so.1 # # Default definitions for Authentication management # Used when service name is not explicitly mentioned for # authenctication # other auth requisite pam_authtok_get.so.1 other auth required pam_dhkeys.so.1 other auth required pam_unix_auth.so.1 # # passwd command (explicit because of a different # authentication module) # passwd auth required pam_passwd_auth.so.1 # # cron service (explicit because of non-usage of # pam_roles.so.1) # cron account required pam_projects.so.1 cron account required pam_unix_account.so.1 # # Default definition for Account management # Used when service name is not explicitly mentioned for # account management # other account requisite pam_roles.so.1 other account required pam_projects.so.1 other account required pam_unix_account.so.1 # # Default definition for Session management # Used when service name is not explicitly mentioned for # session management # other session required pam_unix_session.so.1 # # Default definition for Password management # Used when service name is not explicitly mentioned for # password management # other password required pam_dhkeys.so.1 other password requisite pam_authtok_get.so.1 other password requisite pam_authtok_check.so.1 other password required pam_authtok_store.so.1 # # Support for Kerberos V5 authentication # (uncomment to use Kerberos) # #rlogin auth optional pam_krb5.so.1 try_first_pass #login auth optional pam_krb5.so.1 try_first_pass #other auth optional pam_krb5.so.1 try_first_pass #cron account optional pam_krb5.so.1 #other account optional pam_krb5.so.1 #other session optional pam_krb5.so.1 #other password optional pam_krb5.so.1 try_first_pass
Файл /etc/pam.conf состоит из правил - по одному правилу в строке. Если правило не помещается на одну строку, то в ее конце следует поставить символ "\", для экранирования следующего за ним перевода строки.
Комментарии начинаются знаком "#" и продолжаются до конца строки (обратите внимание на то, что в вышеприведенном файле, поставляющемся по умолчанию, конфигурация Kerberos закомментирована).
Каждое правило состоит из пяти полей, которые отделяются друг от друга пробелами, первые три поля нечувствительны к регистру букв:
приложение задача управление путь/к/модулю аргументы_вызова_модуля
Имя приложения other зарезервировано для указания модулей аутентификации по умолчанию, то есть для тех приложений, о которых в файле конфигурации ничего не сказано явным образом.
Несколько правил могут быть организованы в стек для последовательной аутентификации несколькими PAM-модулями. Поле "задача" характеризует ту задачу, которая решается модулем. Это может быть account, auth, password или session.
"Управление" определяет поведение PAM в случае, если модуль примет решение об отказе в аутентификации1) (допустим, сочтет пароль неверным). Возможные варианты действий:
requisite - отказ приводит к немедленному прекращению аутентификации; required - отказ приводит к тому, что PAM API возвращает ошибку, но только после того, как будут вызваны все оставшиеся в стеке модули (для этого приложения); sufficient - успешная аутентификация достаточна для удовлетворения требований по аутентификации стека модулей (если предыдущий модуль в стеке выдал отказ в аутентификации, то успех аутентификации текущего модуля игнорируется); optional - успех или отказ в аутентификации с использованием данного модуля имеет значение, только если это единственный модуль в стеке, ассоциированном с данным приложением и типом аутентификации (т.е. нет других optional модулей).
Путь к модулю - полное имя файла PAM-модуля для вызова приложением.
Аргументы модуля - разделенные пробелами аргументы, которые могут использоваться для изменения поведения модуля.
Могут быть у любого модуля и определяются в документации на конкретный модуль.
Некоторые модули ограничиваются только поддержкой задачи auth. В то же время ряд приложений требуют не только этого при выполнении аутентификации, но и выполнения задачи account. Тогда приходится подставлять для выполнения второй задачи модуль pam_permit.so, который все разрешает без проверки. Если указать только одну задачу (auth), аутентификация может не заработать вообще, если приложение так устроено.
 |
|
|
1) Термин "отказ" мы употребляем в описании действий PAM в смысле "отказ в результате ошибки пользователя при аутентификации", например, указания неверного пароля.
НАЗАД ВПЕРЕД
|
Настройка главного сервера NIS
Для настройки необходимо выполнить следующие действия:
Убедиться, что в файлах passwd, netgroup и др. содержится верная информация, в самом деле подлежащая разделению в сети. Перейти в каталог /var/yp. Запустить команду domainname имя_домена_NIS (для присвоения домену NIS желаемого имени). Запустить команду ypinit -m для инициализации домена NIS и создания всех необходимых карт NIS. Ключ -m означает master, главный сервер. Запустить необходимые демоны (как минимум, ypserv).
В Solaris компьютер автоматически настроится на работу с NIS, если будет найден файл /etc/defaultdomain. Эту работу выполнит программа ypstart, которая при старте системы проверяет, установлено ли имя домена в этом файле.
Демон ypserv запускается автоматически, если соблюдаются все следующие условия:
указано имя домена в файле /etc/defaultdomain или в переменной среды окружения $domain; существует каталог /var/yp/имя_домена; существует переменная YPDIR, и в каталоге $YPDIR (т.е. в каталоге, имя которого совпадает со значением этой переменной) есть доступный для выполнения файл ypserv.
Демон ypbind запускается автоматически, если соблюдаются все следующие условия:
указано имя домена в файле /etc/defaultdomain или в переменной среды окружения $domain; существует каталог /var/yp/binding/имя_домена; существует переменная YPDIR, и в каталоге $YPDIR (т.е. в каталоге, имя которого совпадает со значением этой переменной) есть доступный для выполнения файл ypbind.
Серверы NIS одновременно являются и клиентами NIS, поэтому кроме серверных демонов, на них запускается и клиентский демон ypbind, который посылает запросы демону ypserv. По умолчанию демон ypbind пытается найти в сети сервер NIS своего домена, рассылая широковещательный запрос. Для того чтобы данный компьютер использовал строго определенный сервер NIS для получения информации с него, либо в случае, если сервер NIS находится в другом сегменте сети и широковещательный запрос до него не может дойти через маршрутизатор, следует запускать ypbind без ключа broadcast. Для настройки клиента для работы с определенным сервером NIS следует использовать команду ypset, а для настройки клиента NIS в целом используется ypinit с ключом с. Поэтому обе эти задачи вместе решаются так:
ypinit -c имя_сервера ypset имя_сервера
Это настраивает запуск ypbind так, чтобы не происходило поиска сервера NIS в сети. В таком случае на клиенте NIS обязательно должен быть минимальный файл /etc/hosts, чтобы при запуске ypbind была возможность обратиться хотя бы к серверу NIS по имени.
Для изменения сценария запуска сервера NIS в Solaris следует модифицировать файл /etc/init.d/inetinit.
Настройка графической среды
К настройкам среды следует отнести настройки X-сервера, настройки оболочки, составляющей суть интерфейса CDE, и настройки каждого из X-клиентов. Естественно, мы коротко обсудим каждый из этих типов настроек, но в отношении X-клиентов будут рассмотрены только общие параметры, которые могут быть им переданы, так как индивидуальные особенности X-клиентов зависят от их функциональности.
| Solaris 10 | SunOS 5.10 | |
| Solaris 9 | SunOS 5.9 | |
| Solaris 8 | SunOS 5.8 | OpenWindows 3.6.2 / CDE 1.4 |
| Solaris 7 | SunOS 5.7 | OpenWindows 3.6.1 / CDE 1.3 |
| Solaris 2.7 | SunOS 5.7 | OpenWindows 3.6.1 / CDE 1.3 |
| Solaris 2.6 | SunOS 5.6 | OpenWindows 3.6 / CDE 1.2 |
| Solaris 2.5.1 | SunOS 5.5.1 | OpenWindows 3.5.1 |
| Solaris 2.5 | SunOS 5.5 | OpenWindows 3.5 |
| Solaris 2.4 | SunOS 5.4 | OpenWindows 3.4 |
| Solaris 2.3 | SunOS 5.3 | OpenWindows 3.3 |
| Solaris 2.2 | SunOS 5.2 | OpenWindows 3.2 |
| Solaris 2.1 | SunOS 5.1 | OpenWindows 3.1 |
| Solaris 1.1.2 | SunOS 4.1.4 | |
| Solaris 1.1.1B | SunOS 4.1.3_U1 |
таблица 25.1 взята из открытого источника по адресу http://members.jcom.home.ne.jp/newtype-shira/home/solaris/index-j.html.
Настройка клиента DNS
Настройка клиента DNS чрезвычайно проста - следует лишь указать верные значения в /etc/nsswitch.conf и /etc/resolv.conf. В последнем файле надо указывать IP-адрес, а не имя сервера имен, ибо нельзя обратиться к серверу имен по имени - ведь это он должен преобразовывать имена в IP-адреса.
Вот выдержка из файла /etc/nsswitch.conf:
# # /etc/nsswitch.dns: # # An example file that could be copied over to # /etc/nsswitch.conf; it uses # DNS for hosts lookups, otherwise it does not use any # other naming service. # # "hosts:" and "services:" in this file are used only if the # /etc/netconfig file has a "-" for nametoaddr_libs of # "inet" transports. passwd: files group: files # You must also set up the /etc/resolv.conf file for # DNS name server lookup. See resolv.conf(4). hosts: files dns ipnodes: files networks: files protocols: files
Файл resolv.conf при этом выглядит так:
domain eu.spb.ru nameserver 192.168.5.63 search eu.spb.ru
Настройка клиента печати
Клиент печати настраивается сходным образом: в файле /etc/printers.conf на клиенте печати будет указано, что принтер по умолчанию находится на компьютере, который выполняет роль сервера печати. В настройках клиента печати не обязательно определять права доступа к удаленному принтеру: это уже сделано в настройках сервера печати. Таким образом, минимальный файл /etc/printers.conf на клиенте печати, чьи задания на печать должны отправляться принтеру hplj на компьютере с именем printserver, будет выглядеть так:
_default | lp: :use=printserver: :bsdaddr=printserver,hplj
В этом файле, как видим, указано, что принтером по умолчанию для данного компьютера будет принтер hplj на компьютере printserver. В файле /etc/printers.conf на компьютере printserver должен быть определен принтер hplj, т.е. должно присутствовать описание вида:
hplj:\ :use=/dev/lp0:\ bsdaddr=printserver,hplj,Solaris:
Это описание появляется при добавлении принтера в систему сервера печати. Пример такого добавления с помощью lpadmin показан выше.
Настройка клиента удаленного доступа
При настройке клиента удаленного доступа нужно добавить несколько строк в файл параметров, чтобы заставить pppd посылать удаленному серверу провайдера имя и пароль по запросу.
Если мы звоним на сервер удаленного доступа , организованный по типу 1, то options может, например, выглядеть так:
/dev/cuaa0 57600 crtscts modem debug defaultroute passive -detach lock connect "chat -f /etc/ppp/chat.x"
Файл /etc/ppp/chat.x при этом может быть, например, таким:
'' ATDT3200000 CONNECT \r name:-BREAK-name: pppfil ssword: e.67FGq1
Здесь в скрипте соединения указан номер телефона (3258752), по которому мы дозваниваемся. Это - телефон провайдера или сервера удаленного доступа в нашей организации (можно использовать PPP-соединения как для подключения к Интернету, так и для соединения двух площадок одной компании между собой). Помните, что команда ATDT означает тоновый набор, для набора в импульсном режиме, который обычно используется на городских АТС в России, следует применить команду ATDP. В данном примере предполагается, что имя пользователя для соединения с удаленным сервером - pppfil, а пароль (незашифрованный) - e.67FGq1.
Если сервер, на который мы звоним, организован по типу 2, то файл options выглядит примерно так:
/dev/cuaa0 57600 crtscts modem debug defaultroute passive -detach lock user myname
Поскольку здесь мы явным образом указываем имя пользователя, которое следует использовать для аутентификации на удаленном сервере, в файле /etc/ppp/pap-secrets на нашем компьютере (который звонит удаленному серверу) должна быть строка
myname * mypassword *
Если соединение с удаленной системой должно быть постоянным (например, нам нужно постоянное соединение с провайдером по модему), можно написать простой скрипт, который будет запускать pppd снова, если он почему-то завершится:
#!/bin/sh while sleep 3 do /usr/sbin/pppd done
"Засыпание" на три секунды нужно на всякий случай. Чтобы дать проблеме, из-за которой завершился pppd, время на то, чтобы самоустраниться. Цикл бесконечный, прервать его можно только посылкой сигнала KILL. Такой цикл удобно оформить в виде скрипта, запускающегося при старте системы.
Вместо такого "вечного" цикла можно воспользоваться параметром demand. Он запускает дозвонку pppd в случае прихода пакета, который нужно отправить по dial-up каналу.
Кроме того, надо помнить о возможности запускать pppd из файла /etc/inittab, указав тип запуска respawn (запустить заново в случае завершения). Следует выбрать только один из рассмотренных способов поддержания постоянного соединения с помощью pppd - одновременно их использовать не рекомендуется во избежание путаницы и запуска "лишних" копий программы.
Настройка клиентов NIS
Клиент не должен абсолютно во всем полагаться на сервер NIS. Следует иметь локальные файлы /etc/passwd, /etc/group и /etc/hosts. В файле passwd должны быть указаны основные предопределенные пользователи и, возможно, личная учетная запись системного администратора для экстренных случаев.
Помните о необходимости проверять порядок опроса служб имен (вначале NIS, затем локальные файлы) в /etc/nsswitch.conf. При переходе от аутентификации через локальные файлы к NIS или обратно не забывайте изменять файл /etc/nsswitch.conf в согласии с принятым решением о схеме аутентификации.
Настройка маршрутизации
Маршрутизацией называется передача пакетов между интерфейсами. Базовые функции маршрутизации в UNIX поддерживаются в ядре. Кроме того, для поддержки протоколов динамической маршрутизации можно использовать специализированные программы маршрутизации, например, демон gated.
Ядро хранит таблицу маршрутизации, которая формируется при загрузке системы. Посмотреть таблицу маршрутизации можно с помощью команды netstat -nr:
Routing Table: IPv4 Destination Gateway Flags Ref Use Interface ------------- ------------- ------ ----- ------ --------- 192.168.5.0 192.168.5.33 U 1 4 elxl0 224.0.0.0 192.168.5.33 U 1 0 elxl0 default 192.168.5.1 UG 1 0 127.0.0.1 127.0.0.1 UH 54 5063 lo0
Настройка NFS-сервера
Для настройки NFS сервера нам потребуется выполнить настройку как минимум трех приложений: rpcbind, mountd и nfsd. Прежде всего, создадим файл /etc/dfs/dfstab, в котором опишем экспортируемые каталоги; в отличие от других систем UNIX, Solaris требует указать здесь не просто список каталогов с параметрами монтирования, а набор команд share, которые фактически и запускают экспорт каталогов. Таким образом, получается, что /etc/dfs/dfstab - это скрипт, который выполняется для того, чтобы сделать общие каталоги доступными для монтирования через сеть.
Настройка параметров файловой системы
Чтобы оценить загрузку файловых систем, имеет смысл запустить команду
iostat -x 5
в тот момент, когда интенсивность ввода-вывода будет наиболее близка к обычному (или пиковому, в зависимости от того, как вы хотите настроить файловую систему) уровню:
... device r/s w/s kr/s kw/s wait actv svc_t %w %b cmdk0 17.6 2.9 138.4 53.1 1.1 0.2 60.1 3 13 fd0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 sd0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 nfs1 0.0 0.0 0.0 0.0 0.0 0.0 9.3 0 0 extended device statistics device r/s w/s kr/s kw/s wait actv svc_t %w %b cmdk0 307.7 0.2 766.1 2.0 0.0 0.9 2.9 0 89 fd0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 sd0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 nfs1 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 extended device statistics device r/s w/s kr/s kw/s wait actv svc_t %w %b cmdk0 253.4 0.7 768.0 6.0 0.0 0.9 3.6 0 88 fd0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 sd0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 nfs1 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0 ...
Средние значения загрузки можно получить из колонок kr/s и kw/s, в более ранних версиях системы для получения таких значений приходилось делить содержимое колонок "K/r" и "K/w" на "r/s" и "w/s" соответственно для получения средних показателей "прочитано килобайт в секунду" и "записано килобайт в секунду".
Для получения информации о распределении файлов по размеру можно использовать команду:
quot -c file_system
Например, вот каково распределение в моей тестовой системе:
quot -c /export/home ... 1128 1 165156 1136 1 166292 1160 1 167452 1176 1 168628 1184 1 169812 1192 1 171004 1224 1 172228 1232 1 173460 1240 1 174700 1264 1 175964 1360 1 177324 1376 1 178700 1440 1 180140 1488 1 181628 1536 1 183164 1608 1 184772 1648 1 186420 1704 1 188124 1768 1 189892 1792 1 191684 1832 1 193516 2047 40 437396 ...
Первая колонка вывода - это размер файла в блоках, вторая - число файлов такого размера, третья - общее число блоков, занятых файлами такого размера и меньшими.
Настройка подчиненных серверов NIS
Настройка подчиненного сервера NIS всегда выполняется только после настройки главного. Отличие в этих настройках невелико, так как состоит только в том, что программе ypinit надо передать ключ -s (slave) вместо -m. Разумеется, инспектировать локальные копии файлов passwd и прочих на подчиненном сервере не требуется, ибо его задача - только принимать реплицированные карты NIS с главного сервера. Итак, для настройки подчиненного сервера следует:
Перейти в каталог /var/yp. Запустить команду ypinit -s. Запустить необходимые демоны (как минимум, ypserv).
Передачу карт NIS с главного сервера на подчиненные должны инициировать сами подчиненные серверы с помощью запуска процесса ypxfr. Следует запланировать запуск этого процесса из cron так, чтобы раз в сутки (или чаще, если файлы конфигураций обновляются очень часто) свежие карты запрашивались с главного сервера NIS. При наличии нескольких подчиненных серверов в сети имеет смысл для равномерного распределения нагрузки на главный сервер по времени запрашивать карты не со всех серверов одновременно, а поочереди.
Настройка сервера DNS
Программа, которая является сервером имен и реализует службу DNS в Solaris, называется in.named (/usr/sbin/in.named). С системой Solaris 9 поставляется пакет BIND версии 8.2.4, в который входит эта программа.
Конфигурационный файл этой программы называется /etc/named.conf. Сервер имен всегда имеет рабочий каталог, где он хранит базу данных информации о доменах .
Этот каталог указывается в инструкции directory в файле конфигурации named.conf, и довольно часто администраторы выбирают в качестве такого каталога /var/named/.
В файле /etc/named.conf кроме имени рабочего каталога указываются все домены , за которые отвечает данный сервер имен, и названия файлов с описаниями этих доменов ; каждому домену соответствует свой файл описания. Один сервер имен может хранить информацию о нескольких доменах .
Правила регистрации доменов требуют, чтобы за каждый домен отвечали, как минимум, два сервера имен в разных IP-сетях; это правило ввели для страховки на случай непредвиденного отключения маршрутизации к одной из сетей.
Прежде чем начать подробное изучение файлов данных и файла конфигурации сервера имен, сделаем важное замечание: во всех этих файлах в Solaris 9 поставляемый с системой in.named ожидал в качестве разделителей полей знаки табуляции, а не пробелы! Если сервер имен при загрузке сообщает, что не смог найти информацию в файле конфигурации или файлах данных, следует:
Уточнить, действительно ли вы строго следовали синтаксису файлов. Наиболее распространенными ошибками являются: отсутствие точки с запятой после инструкции в named.conf, отсутствие точки с запятой перед фигурной скобкой в named.conf, использование не тех скобок (круглых в named.conf или фигурных при описании домена в файле данных домена в записи SOA), непарные скобки (часто появляются в результате редактирования ранее созданного файла); Проверить, не являются ли символы-разделители полей в записях в файлах чем-либо, кроме табуляции (такое может возникнуть при переносе файлов откуда-либо методом cut-and-paste).
Если не уверены в том, что там верные символы, лучше заменить их на табуляцию.
Рассмотрим файл /etc/named.conf в нашей системе. Положим, наш сервер имен обслуживает два домена : klava.net и macro.ru, причем для последнего домена наш сервер будет выполнять роль вторичного сервера имен.
options { // это комментарий, раз строка начинается с // directory "/var/named"; }; // дальше идет описание зон. // эти - корневая и обратная локальная - обязательны zone "." { type hint; file "named.root"; }; zone "0.0.127.IN-ADDR.ARPA" { type master; file "127.0.0"; }; // дальше - описания зон, за которые мы отвечаем zone "klava.net" { type master; file "klava.net"; }; // а это - те зоны, для которых наш сервер - вторичный zone "macro.ru" { type slave; file "sec/macro.ru"; masters { 194.220.38.65; }; };
Файл описания корневого домена named.root (фактически, список серверов имен корневого домена ) может быть уже установлен в системе. Если это не так, то его можно получить из самого надежного источника - по адресу ftp://ftp.rs.internic.net/domain/.
Каталог, в котором будут храниться файлы описаний доменов , для которых наш сервер имен является вторичным, должен быть доступен демону in.named для записи. Обычно это каталог /var/named/sec.
Файл описания домена состоит из записей, по одной на строку, называемых записями о ресурсах (RR - resource records). Каждый из ресурсов имеет класс и тип. В сети Интернет используется только класс IN, но DNS позволяет описывать ресурсы и других классов. Мы не будем рассматривать никакие классы, кроме IN. Типы ресурса бывают такими:
A - указание адреса компьютера с определенным именем (для поиска адреса по имени); PTR - указание имени компьютера с определенным адресом (для поиска имени по адресу); MX - указание почтового сервера для ресурса (домена или компьютера); CNAME - псевдоним другого ресурса; HINFO - текстовое описание ресурса; SOA (starting of authority) - служебная информация о домене в целом. NS - указание имени сервера имен для домена .
Каждая запись имеет определенный формат, а именно:
имя ресурса класс тип информация
Изучим файлы описания доменов , на которые ссылались инструкции из файла /etc/named.conf:
klava.net: $TTL 3600 @ IN SOA sunny.eu.spb.ru. hostmaster.sunny.eu.spb.ru. ( 2004060101 3600 1200 3600000 3600 ) IN NS sunny.eu.spb.ru. IN MX 5 mail.eu.spb.ru. IN MX 10 sunny.eu.spb.ru. mail IN A 194.221.15.1 127.0.0: $TTL 3600 @ IN SOA sunny.eu.spb.ru. hostmaster.sunny.eu.spb.ru. ( 2004060100 3600 1200 3600000 3600 ) IN NS sunny.eu.spb.ru. 1 IN PTR localhost.
Тип SOA - это единственный тип, который предполагает многострочную запись. В записи SOA указывается имя домена (символ @ - это макроопределение, вместо которого подставляется имя домена из файла named.conf), полное имя авторитетного name-сервера домена , адрес персоны, ответственной за домен , времена и тайм-ауты обновления сведений о домене :
sunny.eu.spb.ru. - это имя авторитетного сервера имен. Авторитетным называется такой сервер имен, ответы которого не подвергаются сомнению. Дело в том, что на запрос о домене может ответить не только сервер имен, отвечающий за этот домен , но и любой другой сервер имен, если он получил эту информацию по запросу. Авторитетный ответ (autoritative answer) может быть получен только с сервера имен, непосредственно отвечающего за интересующий нас домен ; hostmaster.sunny.eu.spb.ru. - это адрес e-mail персоны, ответственной за домен ; так как символ @ уже используется в описании домена в другом значении, то здесь он заменен на точку; когда вы будете писать письма ответственному лицу, делайте обратную замену и пишите по адресу hostmaster@sunny.eu.spb.ru.
Обратите внимание на то, что в конце адреса и в конце имени сервера стоит знак "точка" (.) - это для того, чтобы явно указать, что мы имеем дело с полностью определенным доменным именем . Если точку в конце имени не поставить, то после написанного в файле имени будет подставлено имя домена , например, если написать вместо "sunny.eu.spb.ru." то же самое, но без точки - "sunny.eu.spb.ru", фактически сервер имен поймет это как sunny.eu.spb.ru.klava.net. (если мы говорим об описании домена klava.net).
После открывающей круглой скобки следует указывать серийный номер версии файла данных домена . Этот номер необходимо изменять каждый раз, когда меняется хоть что-то в описании домена . Если забыть об этом, информация на вторичных серверах имен не обновится.
Серийный номер удобно указывать в формате YYYYMMDDVV, где YYYY - год, MM - месяц, DD - число месяца, VV - версия описания домена за этот день. Как видите, этот стандартный формат ограничивает нас в количестве изменений за день - не более ста. Постарайтесь унять торопливость и вносите изменения, только когда это действительно понадобится, а не раз в пять минут, пожалуйста!
Числа на следующих строках обозначают, соответственно, в секундах:
3600 - период опроса главного сервера имен вторичными серверами; 1200 - период повторных попыток опроса главного сервера имен вторичными серверами в случае неудачи при первой попытке опроса; 3600000 - время устаревания информации на вторичном сервере (т.е. время, через которое вторичный сервер должен считать, что информация потеряла актуальность, и, если не удается получить обновление с главного сервера, перестать отвечать на запросы о домене ); 3600 - время жизни негативного ответа (т.е. ответа "нет такого компьютера у нас в домене !"). Это время, в течение которого сервер, запросивший информацию от нашего сервера, не будет посылать вторичный запрос, если на первый запрос пришел отрицательный ответ.
Инструкция $TTL в начале файла указывает, что серверы, получающие от нас ответы на свои вопросы, должны кэшировать эти ответы на время TTL (в секундах).
Записи типа NS содержат имена серверов имен домена , причем здесь не делается различия между главными и вторичными серверами имен, порядок следования записей в файле домена сам по себе ничего не означает.
Записи MX описывают правила маршрутизации почты. Каждая запись указывает на один из почтовых серверов, принимающих почту для данного домена (или компьютера):
IN MX 5 mail.eu.spb.ru. IN MX 10 sunny.eu.spb.ru.
В приведенном выше примере почта для домена klava.net принимается одним из двух почтовых серверов - mail.eu.spb.ru или sunny.eu.spb.ru.
Число, следующее за ключевым словом MX в записях о маршрутизации почты, называется показателем предпочтительности (preference). Это число показывает, насколько предпочтительно посылать почту на указанный почтовый сервер по сравнению с другими почтовыми серверами. Если для домена или компьютера указаны несколько записей MX с различными показателями предпочтительности, то почта направляется на первый доступный почтовый сервер с минимальным значением показателя предпочтительности.
Алгоритм отправки почты любым почтовым сервером таков:
Почтовый сервер отправителя запрашивает свой сервер имен (тот, что указан в /etc/resolv.conf), куда надо отправить письмо для указанного в заголовке письма адресата. Сервер имен выдает ему список записей MX для адресата. Почтовый сервер выбирает запись с наименьшим значением показателя предпочтительности и пытается отправить почту указанному в этой записи почтовому серверу. Если это не удается, выбирается следующая запись с минимальным (из оставшихся) показателем предпочтительности и делается попытка отправить почту через указанный в ней почтовый сервер.
Попытки отправки почты повторяются до тех пор, пока почтовое сообщение не будет успешно отправлено либо время, прошедшее с начала первой попытки, не превысит установленный тайм-аут. В последнем случае отправитель получит уведомление о невозможности доставить письмо. По умолчанию большинство почтовых серверов пытаются доставить письмо в течение 5 суток.
Все временно неотправленные письма накапливаются в очереди сообщений, и почтовый сервер регулярно обрабатывает очередь, вновь и вновь пытаясь отправить письма согласно вышеописанному алгоритму.
Настройка сервера печати
Сервер печати не предоставляет доступ к принтеру всем подряд - доступ предоставляется на основании строгих правил. Для того чтобы принять решение о предоставлении доступа к принтеру тому или иному компьютеру, сервер печати использует какую-либо службу имен (DNS, NIS, LDAP) для определения имени обращающегося компьютера. Если на сервере печати не используется ни одна из служб имен, следует в файл /etc/inet/hosts внести записи о каждом из компьютеров-клиентов печати.
Сервер печати должен иметь свободное дисковое пространство для хранения очереди заданий на печать, его объем зависит от характера и количества заданий, одновременно отправляемых на печать, и обычно колеблется от 25 до 500 Мбайт. Такая область диска, предназначенная для хранения очереди печати, называется областью буферизации или спулом (spool - System Peripheral Operation OffLine). Помните, что размер файла в формате PS или PCL, подготовленного драйвером принтера для загрузки в принтер, может сильно отличаться от размера исходного файла, например, документа OpenOffice. Это связано с необходимостью загрузки шрифтов, растеризации изображений и т.п.
Рекомендуется, чтобы объем памяти системы под управлением Solaris, которая выполняет роль сервера печати, был не менее 96 Мбайт.
Для того чтобы сервер печати мог обеспечивать доступ к принтеру, следует указать, какие принтеры вообще доступны в системе и какой принтер надлежит использовать по умолчанию. Стало быть, надо иметь список доступных принтеров с указанием их имен и типов. Такой список содержится в файле /etc/printers.conf. Это отличает Solaris от других систем UNIX, поскольку в большинстве из них настройки принтеров хранятся в /etc/printcap. Такого файла в Solaris нет.
Кроме того, для каждого из типов принтеров требуется описание свойств принтера, такое, как указание оптического разрешения печати, кодов загрузки графики и т.п. Эта информация хранится в той же структуре каталогов, где содержится информация об управляющих кодах терминалов - /usr/share/lib/terminfo.
В подкаталогах этого каталога в алфавитном порядке собраны файлы, описывающие терминалы и принтеры. Так, описание принтеров HewlettPackard Laser Jet содержится в файле /usr/share/lib/terminfo/h/hplaser. Эти файлы - двоичные, а не текстовые, поэтому их не следует редактировать напрямую. Вместо этого при необходимости модифицировать или добавить новое описание принтера или терминала следует создать исходный (текстовый) файл описания устройства и затем воспользоваться командой tic, которая превращает (компилирует) текстовый файл описания в стандартный двоичный файл, размещая последний в структуре каталогов /usr/share/lib/terminfo.
Формат файла описания принтера приведен в terminfo (4), следовательно, для изучения этой информации надо воспользоваться командой
man terminfo
или
man 4 terminfo
Для обратного превращения двоичного файла описания устройства - терминала или принтера - в исходный текстовый файл описания устройства следует выполнить команду infocmp. Этой команде следует указывать в качестве аргумента имя устройства, а не путь к файлу описания, т.е. правильной командой будет
infocmp hplaser
а не
infocmp /usr/share/lib/terminfo/h/hplaser
Последний вариант останется непонятым: программа infocmp ищет указанный ей файл в стандартной структуре каталогов или там, где указано переменной среды окружения TERMINFO.
Для редактирования настроек системы печати как на сервере печати, так и на клиентах печати следует использовать программы printmgr (/usr/sadm/admin/bin/printmgr) и lpset.
Вместо этого можно также редактировать вручную файл /etc/printers.conf: все равно вышеупомянутые программы вносят изменения именно в этот файл.
Другие настройки локальных принтеров, в частности, физический порт, к которому подключен принтер (например, /dev/lp0), указываются в структуре каталогов /etc/lp/printers, в которой для каждого принтера есть свой подкаталог с настройками. Эти настройки можно редактировать вручную, но удобнее воспользоваться для этого командой lpadmin или программой Solaris Print Manager (printmgr).
Например, для того чтобы добавить новый принтер hplj на сервере печати, достаточно выполнить команду lpadmin. Команда lpadmin может выглядеть, например, так:
lpadmin -p hplj -v /dev/lp0
По этой команде в систему добавится локальный принтер с именем hplj. Все обращения к этому принтеру будут выполняться через устройство /dev/lp0 (первый параллельный порт).
Настройка серверов и клиентов NIS
Сервер NIS хранит всю информацию о доменах NIS в подкаталогах каталога /var/yp. На главном сервере NIS должны быть запущены процессы ypserv (отвечает на запросы клиентов), ypxfrd (обслуживает запросы от подчиненных серверов NIS для репликации информации), yppasswdd (демон изменения пароля пользователя).
Настройка сетевых интерфейсов
Для того чтобы через сетевой интерфейс можно было принимать и передавать данные, системе следует сообщить его параметры, а именно IP-адрес и маску сети. Но прежде необходимо выполнить специфичную для Solaris команду для активации интерфейса:
ifconfig if_name plumb
После этого надо назначить адрес и маску:
ifconfig if_name IP-address broadcast broadcast-address netmask netmask
Здесь if_name - это имя интерфейса (например, eri0), IP-address - адрес, который следует назначить этому интерфейсу, а необязательные параметры broadcast-address и netmask задают широковещательный адрес сети, к которой подключен интерфейс, и маску сети.
ifconfig if_name up
Все эти команды можно объединить в одну, указав таким образом, что следует выполнить низкоуровневую инициализацию интерфейса, назначить ему адрес и маску, после чего включить (сделать возможным получение и отправку IP-пакетов через него):
ifconfig if_name IP-address broadcast broadcast-address netmask netmask plumb up
Как создать "ip alias" - несколько адресов на одном интерфейсе
Для присвоения одному интерфейсу нескольких сетевых адресов в Solaris используются псевдонимы. В отличие от других вариантов UNIX здесь не работает конструкция ifconfig alias. Вместо этого следует воспользоваться командами
ifconfig if_name:0 IP-address netmask netmask up ifconfig if_name:1 IP-address netmask netmask up
Следует помнить, что if_name:0 обозначает сам оригинальный интерфейс, т.е. elxl0:0 - это то же самое, что elxl0. Кроме того, перед выполнением команд, назначающих адрес и другие параметры такому "виртуальному" интерфейсу, например, elxl0:1, следует создать этот виртуальный интерфейс командой
ifconfig if_name:1 plumb
Удаление такого интерфейса выполняется командой
ifconfig if_name:1 down
Например,
ifconfig le0:1 down
В Solaris до версии 7 не требуется выполнять команду
ifconfig if_name:1 plumb
для создания интерфейса. Для удаления интерфейса также можно применить
ifconfig if_name:1 unplumb
Это означает удаление интерфейса и связанных с ним структур данных из памяти, в то время как
ifconfig le0:1 down
обеспечивает только отключение интерфейса и "забывание" его настроек.
Для добавления постоянного виртуального (его иногда еще называют "логическим") интерфейса- псевдонима следует создать соответствующий файл /etc/hostname:
echo IP-адрес-псевдоним >/etc/hostname.if_name:1
Например,
echo 194.125.5.6 >/etc/hostname.le0:1
Для изменения параметров настройки сети можно использовать программу ndd. Она служит для изменения параметров некоторых драйверов в ядре. Обычно ndd используется для назначения параметров драйверов сети. Например, команда
ndd -set /dev/ip ip_forwarding 0
позволяет отключить пересылку сетевых пакетов между интерфейсами системы.
За более детальной информацией о ndd следует обратиться к руководству ndd(1M).
Интерфейс-псевдоним может использоваться для организации "виртуальной маршрутизации", когда в одном физическом сегменте сети устанавливаются компьютеры с адресами из разных сетей, и пакеты друг другу они могут пересылать через систему, сетевой адаптер которой имеет два адреса из разных сетей:
ifconfig -a lo0: flags=1000849<UP,LOOPBACK,RUNNING,MU<ICAST,IPv4> mtu 8232 index 1 inet 127.0.0.1 netmask ff000000 elxl0: flags=1000843<UP,BROADCAST,RUNNING,MU<ICAST,IPv4> mtu 1500 index 2 inet 192.168.5.33 netmask ffffff00 broadcast 192.168.5.255 ether 0:60:8:cb:3b:c0 elxl0:2: flags=1000842<BROADCAST,RUNNING,MU<ICAST,IPv4> mtu 1500 index 2 inet 198.16.1.1 netmask ffffff00 broadcast 198.16.1.255
Настройка syslogd
Демон syslogd (файл конфигурации /etc/syslog.conf) протоколирует события, информацию о которых ему поставляют другие процессы, вызывая функцию syslogd (). В файле /etc/syslog.conf определяется, какие события нужно протоколировать и как.
Синтаксис записи в /etc/syslog.conf таков:
источник.уровень действие
Источник - это условное название процесса или группы процессов, которые могут генерировать сообщения о событиях. Уровень - это степень серьезности сообщения (ошибка, фатальный сбой, предупреждение, информационное сообщение и т.п.). Источник в оригинальной документации называется facility , в переводной литературе используют понятие "средство". Однако мы будем использовать термин "источник ", так как речь идет именно об источнике сообщений. Два этих поля (источник.уровень и действие) отделяются друг от друга табуляцией.
Общими для большинства систем UNIX являются источники , перечисленные в табл. 16.1. Полный перечень источников и уровней для вашей системы приведен в man syslog.conf.
| user | сообщения от пользовательских процессов |
| kern | ядро |
| почтовые программы | |
| daemon | демоны, например, in.ftpd |
| auth | login, su, getty и другие, связанные с аутентификацией |
| lpr | подсистема печати, в т.ч. lpr, lpc |
| news | зарезервировано для программ телеконференций типа inn |
| cron | cron, crontab, at (в настоящее время в Solaris не используется) |
| local0-local7 | зарезервировано для других программ |
| mark | специальный источник для добавления меток времени в файл протокола демоном syslogd |
Если в поле источника стоит знак "звездочка"(*), например *.info, это означает все события всех источников уровня info, за исключением событий источника mark.
Уровень сообщения соответствует степени его серьезности, в таблице 16.2 уровни расположены в порядке убывания серьезности:
| emerg | Состояние совершенного ужаса, надо сообщить всем пользователям, что дело - табак |
| alert | Нехорошее состояние; надо срочно исправлять положение, иначе быть беде, например, испортился важный системный файл |
| crit | Сообщение о критической ошибке, например сбоит жесткий диск |
| err | Прочие ошибочные состояния |
| warning | Предупреждение (например, место на диске заканчивается, но дело еще не пахнет керосином) |
| notice | Предупреждение о какой-то проблеме, это не рассматривается как ошибка |
| info | Информационное сообщение - так, чтобы мы были в курсе дел |
| debug | Сообщение при отладке программы (или её файла конфигурации) |
| none | Требование не выполнять действий в отношении сообщений от указанного источника ; например, *.debug;mail.none означает, "выполнить действие в отношении всех сообщений уровня debug, кроме сообщений от источника mail:" |
Если в поле уровня стоит знак "звездочка" (*), например, mail. *, это означает события всех уровней данного источника . Такое указание не имеет смысла, поскольку при указании некоего уровня разрешается передача всех сообщений этого уровня и более серьезных, т.е. уровень info фактически означает "info и все остальные".
С сообщением могут быть выполнены следующие действия:
запись информации о событии в файл; пересылка сообщения другому компьютеру (демону syslogd на нем); отправка сообщения по почте; вывод сообщения на экран вошедшим в систему пользователям.
Обычно информация записывается в файл. Принято файлы протоколов держать в /var/log или /var/adm. Имя файла, записанное в поле "действие", приводит к записи информации в этот файл.
Для активации изменений, внесенных в файл конфигурации /etc/syslog.conf, требуется послать сигнал HUP демону syslogd. За размером файлов протокола надо следить, иначе они займут все свободное место на разделе. Уровень протоколирования следует выбирать из соображений разумной достаточности. Незачем протоколировать все события с уровнем info или notice: если сервер уже настроен, вполне достаточно протоколировать события большинства источников с уровнем error.
Указанный в строке /etc/syslog.conf уровень - это минимальный уровень, который должно иметь событие, чтобы быть занесенным в протокол. Стало быть, если вы указали уровень событий info, то все более серьезные уровни (warning, error и т.д.) тоже будут отвечать этой же строке syslog.conf и события будут записаны туда же, куда и сообщения о событиях уровня info.
Пример минимального файла syslog.conf:
# Log all kernel messages to the console. # Logging much else clutters up the screen. #kern.* /dev/console # Log anything (except mail) of level info or higher. # Don't log private authentication messages! *.info;mail.none;authpriv.none /var/log/messages # The authpriv file has restricted access. auth.* /var/log/secure # Log all the mail messages in one place.mail.* /var/log/maillog # Everybody gets emergency messages, plus log them on another # machine. *.emerg * # Save mail and news errors of level err and higher in a # special file. mail,news.crit /var/log/spooler #All Other #*.* /var/log/all
Настройки среды CDE
Настройки среды включают состав меню рабочей панели, количество рабочих столов (workspaces), запускающиеся в начале и конце сессии программы и различные параметры сессии (например, время простоя, через которое экран автоматически блокируется и требует пароля для разблокирования).
Среда CDE фактически является набором X-клиентов и библиотек. В каждой среде есть специализированный клиент, который называется оконным менеджером (window manager). Это программа, обеспечивающая переключение между окнами различных программ, работу с несколькими рабочими областями (это описано в лекции 2) и т.п. В среде CDE эту роль играет программа dtwm, а в среде GNOME - sawfish.
Файлом настроек dtwm является файл /etc/dt, в домашнем каталоге пользователя также могут храниться файлы типа .dt, о содержании которых можно узнать с помощью man dtwm.
Настройки X-клиентов
Если дать команду
ps -ef | grep dt
можно увидеть значительное количество программ, являющихся X-клиентами и работающих в стандартной среде Solaris 9 CDE:
root 832 831 0 23:37:58 ?? 0:00 /usr/dt/bin/dtterm -C -ls root 831 435 0 23:37:57 ? 0:00 /usr/dt/bin/dtexec -open 0 -ttprocid 2.10xPgI 01 427 1289637086 1 1 0 192.168.5 root 348 314 0 23:03:25 ? 0:00 /usr/dt/bin/dtlogin -daemon root 314 1 0 23:03:20 ? 0:00 /usr/dt/bin/dtlogin -daemon root 346 314 1 23:03:22 ? 0:44 /usr/openwin/bin/Xsun :0 - nobanner -auth /var/dt/A:0-tMaqNa root 369 348 0 23:03:44 ? 0:00 /bin/ksh /usr/dt/bin/Xsession root 427 1 0 23:03:47 pts/3 0:00 /usr/dt/bin/ttsession root 436 428 0 23:03:53 ? 0:01 dtfile -session dtPBay3a root 415 412 0 23:03:45 pts/3 0:00 -sh -c unset DT; DISPLAY=:0; /usr/dt/bin/dtsession_res -merge root 412 369 0 23:03:45 pts/3 0:00 /usr/dt/bin/sdt_shell -c unset DT; DISPLAY=:0; /usr/dt/bin/dt root 413 1 0 23:03:45 ? 0:00 /usr/dt/bin/dsdm root 428 415 0 23:03:47 pts/3 0:00 /usr/dt/bin/dtsession root 435 428 0 23:03:49 ? 0:02 dtwm root 437 428 0 23:03:53 ? 0:00 /usr/dt/bin/sdtperfmeter - f -H -t cpu -t disk -s 1 -name fpperfmeter root 439 1 0 23:03:53 ? 0:00 /bin/ksh /usr/dt/bin/sdtvolcheck -d -z 5 cdrom,zip,jaz,dvdrom,rmdisk root 476 436 0 23:07:23 ? 0:00 dtfile -session dtPBay3a root 477 436 0 23:07:29 ? 0:00 /usr/dt/bin/dtexec -open 0 -ttprocid 3.10xPgI 01 427 1289637086 1 1 0 192.168.5 root 785 435 0 23:32:46 ? 0:00 /usr/dt/bin/dtexec -open 0 -ttprocid 2.10xPgI 01 427 1289637086 1 1 0 192.168.5
Большинство этих программ имеет индивидуальные настройки, описанные в man по ним. Общие ключи, с которыми можно запускать X-клиентов, описаны выше в начале раздела.
Настройки X-сервера
Для каждого типа видеоплаты требуется свой X-сервер, так как в него встроен драйвер, умеющий обращаться только со "своей" видеоплатой. Это кажется не слишком эффективным, но имеет несколько объяснений.
Позволяет оптимизировать X-сервер по скорости вывода графики, что бывает очень важно. Не влияет существенно на переносимость системы, так как сама операционная система превосходно может работать без X-сервера и без графики вообще. Только в последнее время системы UNIX (в том числе и Solaris) стали устанавливаться на компьютеры с непредсказуемой конфигурацией, причем возможное количество сочетаний в конфигурации выросло в тысячи раз, как только системы UNIX шагнули в мир персональных компьютеров архитектуры x86.
Действительно, представьте себе продукцию компании Sun: несмотря на широкий ассортимент, компания устанавливает в свои серверы и рабочие станции всего несколько модификаций видеоплат. Естественно, заранее никто не побеспокоился о том, что X-серверу лучше быть совместимым со всем миром и любым производителем видеоплат вообще. Нам остается только принять это как данность и внимательно изучать Hardware Compatibility List, если мы не желаем в одночасье остаться у пустого экрана из-за того, что система не поддерживает нашу замечательную видеоплату.
Там, где Х-сервер не удается запустить из /etc/init, для запуска сервера используется программа xinit. Для нее важен файл $HOME/.xinitrc.
Для более подробного изучения возможных настроек своего X-сервера или X-клиентов следует обратиться к man X и man X11.
Некоторые настраиваемые параметры ядра
Здесь мы рассмотрим параметры, влияющие на максимальное количество процессов, которые можно запустить в системе, и на максимальное количество процессов, которые может запустить один пользователь.
Основным параметром является maxusers, который влияет на значения параметров max_nprocs и maxuprc.
Параметр maxusers в прошлом определял максимальное разрешенное количество одновременно работающих в системе пользователей. Размер многих таблиц в ядре вычислялся с использованием этого параметра. В настоящее время старое значение этого параметра утратило смысл, но некоторые параметры ядра продолжают базироваться на maxusers. Это максимально допустимое количество процессов в системе, размер структур квотирования в системе и размер кэша имен каталогов (directory name lookup cache - DNLC). По умолчанию maxusers равно меньшему из двух чисел - объему памяти системы в мегабайтах или 2048. Может принимать любое значение от 1 до 2048, при явной установке в /etc/system - от 1 до 4096, но следует указывать разумные значения. Значение maxusers явно мало, если система выдает сообщения
out of processes
Значение maxusers по умолчанию скорее всего будет велико для систем с малым количеством запущенных процессов и большим объемом памяти - серверов баз данных, вычислительных серверов и т.п.
Еще одним важным параметром является max_nprocs: он ограничивает максимальное количество процессов, которые можно одновременно запустить в системе. Влияет на вычисление значения maxuprc. Кроме того, значение max_nprocs влияет на:
вычисление размеров кэша имен каталогов (DNLC); резервирование структур, обеспечивающих квотирование дискового пространства (если не указано явно значение ndquot); проверку того, что объем памяти, занятый под семафоры, не превышает системных ограничений; настройку подсистемы Hardware Address Translation для систем x86 и sun4m.
Значение max_nprocs по умолчанию - 10 + (16 x maxusers), диапазон значений - от 266 до максимально возможного идентификатора процесса (maxpid). Изменение этого параметра понадобится, если потребуется запускать более 30 000 процессов одновременно.
Кроме ограничения на общее количество одновременно запущенных процессов, существует ограничение на количество процессов, запускаемых одним пользователем. Это количество контролируется параметром maxuprc.
По умолчанию этот параметр равен разности max_nprocs и reserved_procs, где reserved_procs - это параметр, отвечающий за резервирование некоторого количества идентификаторов процессов для пользователя root (даже если вся таблица процессов заполнена процессами пользователей, для процессов root оставляется резерв строк в этой таблице). По умолчанию reserved_procs устанавливается равным 5.
Количество процессов, которое имеет право запустить один пользователь, можно только уменьшить - сделать его большим, чем max_nprocs - reserved_procs, нельзя.
Превышение пользователем ограничения, установленного параметром maxuprc, приводит к выдаче сообщения
out of per-user processes for uid N
Для более детального изучения параметров ядра, доступных для настройки, имеет смысл ознакомиться с Solaris Tunable Reference Manual, размещенным на http://docs.sun.com/.
NIS: полезные программы
Некоторые утилиты помогают в администрировании NIS:
yppush - команда с главного сервера, требующая от всех подчиненных обновить свои копии карт NIS (дается при необходимости немедленного внесения изменений);
makedbm - создает хэшированную базу данных из текстового файла;
yppoll - выдает версию карты сервера;
yppasswd - меняет пароль пользователя.
ypcat ypservers - выводит список имен NIS-серверов домена;
ypcat -x - выводит карты NIS (аналогично ypwhich -x).
Обратная зона
Обратной зоной в терминах системы доменных имен называется домен специального вида. Как мы помним, DNS - это индексированная база данных информации о компьютерах, где индексом служит доменное имя. В некоторых случаях требуется как раз определить это доменное имя - по известному адресу. В этом случае индексом к информации о компьютере (а конкретно - его имени) должен служить IP-адрес. Поэтому потребовалось создать еще один, параллельный доменному имени , индекс. Для этого был создан домен in-addr.arpa. Этот домен используется исключительно для поиска соответствия между известным IP-адресом и (искомым) доменным именем . Реальный IP-адрес преобразуется в доменное имя в домене in-addr.arpa посредством переиначивания: так, компьютер с адресом 192.177.16.43 представляется в домене in-addr.arpa как 43.16.177.192.in-addr.arpa. Таким образом, все компьютеры в Интернете могут иметь (и в большинстве своем имеют) доменные имена в домене in-addr.arpa. Это не мешает им иметь доменные имена в других доменах , например, компьютер с адресом 192.177.16.43 вполне может также относиться к домену example.ru и иметь там имя mailhost.example.ru.
Чтобы запись о компьютере появилась в домене in-addr.arpa, поддомен этого домена должен быть делегирован тому провайдеру или той организации, которая владеет соответствующим диапазоном IP-адресов, например, компания Russian Example, владеющая, среди прочих сетей, сетью класса С 192.177.16/24, может "оформить на себя", т.е. просить делегировать ей домен 16.177.192.in-addr.arpa. После этого системный администратор компании создаст файл с описанием соответствия адресов компьютеров в example.ru их доменным именам в этом домене . Обратная зона готова.
Как используют данные обратной зоны ? Наиболее востребованный способ состоит в проверке подлинности отправителя почтового сообщения. Сейчас практически все почтовые серверы в Интернете при обработке соединения с ними выполняют следующую операцию: вначале они требуют от соединяющегося с ними почтового сервера представиться.
Тот, допустим, говорит, что его имя - mail.relays.org. Пакет с ответом, разумеется, содержит обратный IP-адрес отправителя, и почтовый сервер запрашивает обратную зону DNS, чтобы выяснить, какое имя в ней числится у компьютера с таким IP-адресом. Если пришедший ответ и то, что удаленый сервер сообщил о себе (mail.relays.org), не совпадает, то соединение считается нелегальным и письмо не принимается.
На любом компьютере, где запущен сервер имен named, обязательно должен присутствовать файл, описывающий обратную зону самого компьютера (т.е. соответствие имени localhost адресу 127.0.0.1). Этот файл часто носит имя localhost.rev или 127.0.0. Естественно, этот файл описания локальной обратной зоны обязан быть упомянут в конфигурации сервера имен named.conf:
cat 127.0.0 @ IN SOA ns.example.ru. hostmaster.example.ru. ( 1.2 ; Serial 3600 ; Refresh 300 ; Retry 3600000 ; Expire 3600 ) ; Minimum IN NS ns.example.ru. 1 IN PTR localhost.
Файл обратной зоны не обязательно является копией файла прямой зоны с "переставленными" столбцами, поскольку в одном домене могут присутствовать компьютеры из разных IP-сетей, а одна IP-сеть может объединять компьютеры из разных доменов .
В качестве базового примера можно рассмотреть ситуацию, когда все компьютеры домена входят в одну IP-сеть.
Еще раз отметим, что выделение IP-сети не обеспечивает автоматического делегирования соответствующей обратной зоны . Чтобы получить право администрирования обратной зоны сети, адреса из которой назначены вашим компьютерам, следует написать заявку о делегировании обратной зоны по стандартной форме. Имеет смысл проконсультироваться у своего провайдера, как это сделать, или просто заказать ему выполнение этой работы.
Имя обратной зоны всегда пишется как адрес IP-сети "наоборот", а за ним добавляется суффикс in-addr.arpa. Такая "запись наоборот" была введена с учетом иерархической структуры DNS : левая часть имени обозначает компьютер, правая - домен . В случае с IP-адресами все наоборот.
В адресе номер сети идет слева, а номер компьютера в сети - справа. Для встраивания в DNS это не годилось, и адреса сетей "подогнали" под стандарт DNS .
Рассмотрим в качестве примера файл обратной зоны сети 192.177.16/24:
; $ORIGIN 16.177.192.IN-ADDR.ARPA. ; 16.177.192.IN-ADDR.ARPA. - это имя обратной зоны @ IN SOA qwe.example.ru. hostmaster.example.ru. ( 2001021501 ; Serial 21600 ; Refresh 3 hours 7200 ; Retry 1 hour 7200000 ; Expire 2000 hours 86400 ) ; Negative TTL 24 hours IN NS qwe.example.ru. IN NS ns.ussr.eu.net. IN NS ns.spb.su. ; ; 31 IN PTR qwe.example.ru. 67 IN PTR qwe.example.ru. 134 IN PTR post.example.ru. 236 IN PTR margo.example.ru. 239 IN PTR annas.example.ru.
В этом файле есть запись SOA, описывающая обратную зону в целом, записи NS, указывающие на серверы имен этой зоны, и записи PTR, которые и описывают соответствие имен компьютеров из домена example.ru адресам IP-сети.
Файл example.ru описывает домен example.ru:
; example.ru ; $ORIGIN ru. example IN SOA ns.example.ru. hostmaster.imc.example.ru. ( 2002072401 ; Serial 21600 ; Refresh 3 hour 7200 ; Retry 1 hour 360000 ; Expire 100 hours 86400) ; Minimum 1 hours IN NS ns.example.ru. ; Secondary servers IN NS ns.olly.ru. IN NS ns.qq.ru. ; Domain mail address IN MX 3 post.example.ru. IN MX 10 relay.qq.ru. $ORIGIN example.ru. ; ns IN A 192.177.16.31 ; ; Aliases ; ftp IN CNAME qwe.example.ru. www IN CNAME qwe.example.ru. mail IN CNAME post.example.ru. ; Computers ; qwe IN A 192.177.16.31 qwe IN A 192.177.16.67 post IN A 192.177.16.134 margo IN A 192.177.16.236 annas IN A 192.177.16.239 annas IN HINFO AT-486, WGR ; Don't forget increase Serial, please.
Обратите внимание на то, что часть записей - это записи CNAME. Они создают удобные псевдонимы. Если роль, скажем, почтового сервера mail.example.ru будет передана от post.example.ru другому компьютеру, будет достаточно всего лишь изменить имя в записи CNAME. Думать о том, какой у нового почтового сервера IP-адрес, не придется.
Один компьютер может иметь несколько IP-адресов (принадлежащих одному или - чаще - нескольким сетевым интерфейсам).Один IP-адрес может соответствовать нескольким именам компьютера, потому что компьютер может иметь несколько имен.
Помните, что если в файле описания домена встретятся имена доменов или компьютеров, не заканчивающиеся точкой, то они будут восприняты как неполностью определенные, и к ним будет дописан суффикс по умолчанию. Так, если в описании зоны вместо
qwe IN A 192.177.16.67
написать
qwe.example.ru IN A 192.177.16.67
то сервер имен воспримет эту запись как
qwe.example.ru.example.ru. IN A 192.177.16.67
Это не совсем то, что мы хотели, верно? Если мы хотим явно указать полное имя, следует написать так (обратите внимание на завершающую точку!):
qwe.example.ru. IN A 192.177.16.67
Общие соображения
В большинстве систем UNIX для резервного копирования файловых систем на ленту и восстановления файлов с ленты применяются программы dump и restore. В Solaris для этой же цели используют собственные программы ufsdump и ufsrestore. Принципиальной разницы между общепринятым вариантом и специфичным для Solaris нет, программы dump, ufsdump занимаются резервным копированием данных, а restore и ufsrestore - восстановлением данных (т.е. переписыванием файлов с ленты на диск). Программы, применяющиеся в Solaris, обладают несколько большей функциональностью, например, позволяют выполнять копирование файлов на дискету (ключ D), в то время как dump/restore работают только с ленточными накопителями.
В данном разделе мы рассмотрим только общие особенности этих программ, поэтому материал раздела применим не только к системе Solaris, но и к другим системам UNIX.
По умолчанию ufsdump и ufsrestore работают с первым стримером в системе. Несмотря на это, хорошим тоном считается явное указание устройства, на которое мы хотим выполнить резервное копирование. Это гарантирует нас от неприятных сюрпризов, таких, как неожиданная перемотка ленты в конце копирования или попытка копирования на носитель, который не вставлен в стример.
Программа ufsdump выполняет копирование файловой системы целиком, ее можно (но не следует) применять для копирования отдельных каталогов.
Она может выполнять копирование не только на ленту, но и в файл на диске, а также на дискету. При копировании информации на жесткий диск более разумно использовать обычные утилиты копирования типа cp или специализированные типа tar или rsync (если нужно выполнить копирование на удаленный компьютер).
Следует обязательно указывать уровень копирования при копировании на ленту. Программа ufsdump позволяет задать 10 уровней с 0 до 9. Уровень 0 - это копирование всей файловой системы целиком.
При копировании уровня n копируются все файлы, которые были изменены с момента последнего копирования уровня n или уровня с меньшим номером.
Уровни копирования введены для того, чтобы инкрементное копирование, т.е. копирование только измененных файлов, было легче организовать. Оно экономит место на ленте и время, затрачиваемое на резервное копирование. Обратной стороной медали в данном случае является большее время восстановления данных, так как если файловая система была сохранена полностью три дня назад, а вчера и позавчера выполнялось инкрементное копирование, при восстановлении придется задействовать три кассеты - чтобы восстановить файловую систему по состоянию на момент последнего резервного копирования. Если время позволяет, а свободное место на ленте заведомо превышает объем копируемых данных, удобнее всегда делать полное копирование выбранной файловой системы. В таком случае, когда бы ни произошел сбой, всегда хватит одной единственной кассеты - самой свежей - чтобы полностью восстановить файловую систему.
Планируя схему резервного копирования, помните, что при инкрементном копировании для восстановления после сбоя придется последовательно считывать все ленты, начиная с последнего дампа нулевого уровня. Кроме затрат времени и кассет на такое копирование, после восстановления возникнут уже удаленные файлы, которые удалялись после дампа нулевого уровня: программа восстановления файлов не имеет информации о том, что какие-то файлы были удалены, потому что резервное копирование выполнялось до удаления этих файлов.
При нехватке места на ленте или диске, на которые производится резервное копирование, ufsdump предупредит об этом и попросит вставить в используемое для копирования устройство новый носитель (кассету с лентой). Конец ленты вызывает передачу сигнала от накопителя системе. Если стример не умеет выдавать этот сигнал, следует указать команде ufsdump размер носителя в килобайтах явным образом.
Программа ufsdump позволяет задавать плотность записи на ленту. Плотность записи зависит только от типа и модели стримера и указана в его описании. Используйте только те кассеты, что указаны в руководстве к стримеру! Вообще, это неплохая идея - почитать руководство к устройству, от правильной работы которого всецело зависит надежность резервирования данных всей сети.
За многие годы существования многопользовательских операционных систем было разработано множество схем резервного копирования, направленных на оптимизацию времени восстановления файловой системы, времени выполнения резервного копирования, количества используемых в цикле копирования лент и, наконец, всех этих параметров одновременно. Описание этих схем лежит вне рамок наших лекций, с теорией резервного копирования можно легко познакомиться в Интернете, если это понадобится. На практике следует уметь выполнять основные действия, связанные с резервным копированием файловых систем.
Весьма часто применяется регулярное полное (уровня 0) резервное копирование раздела с важной информацией, что требует ее размещения на одном разделе.
Однозначно НЕ СЛЕДУЕТ выполнять резервное копирование разделов, где расположены временные файлы, файлы протоколов (если только протоколы не представляют ценности для вашей организации), дистрибутив системы или файлы приложений, которые легко установить из дистрибутива.
Резервные копии всегда следует хранить отдельно от пустых (чистых) кассет, и лучше всего - в надежном месте за пределами здания организации - по соображениям пожарной безопасности в том числе.
Обзор протокола TCP/IP
Мы предполагаем, что читатель знает, что такое семиуровневая модель межсетевого взаимодействия ISO/OSI, или хотя бы представляет себе, что такое протокол сетевого и транспортного уровня. Однако, чтобы освежить это в памяти, мы рассмотрим, какое отношение к TCP/IP имеют эти понятия.
Модель межсетевого взаимодействия описывает семь уровней абстракции, которым соответствуют реальные сетевые протоколы передачи и обработки данных. Чтобы эти уровни обрели для нас смысл, рассмотрим вначале, как одни программы передают другим данные по сети. Допустим, что приложение А хочет получить данные от приложения В. Для этого приложение А оформляет свой запрос к приложению В в соответствии с некими правилами, которые хорошо известны обоим приложениям. Так, например, происходит при просмотре web-страниц. Браузер пользователя посылает запрос web-серверу и ожидает от него ответ. Для посылки запроса приложение А должно не только оформить этот запрос в соответствии с правилами, известными приложению В, но и потребовать от своей системы передачи данного запроса. Для этого должен быть установлен сеанс связи, в котором произойдет передача пакета с запросом, получение подтверждения об успешном прохождении пакета, и затем сеанс связи может быть завершен. Отметим, что пакет может передаваться через сети различной природы, например, браузер пользователя, подключенного к Интернету по технологии ADSL в Москве, может обратиться к web-серверу Yahoo, подключенному к Интернету через канал АТМ.
На самом деле все еще сложнее, поскольку запрос и ответ на него будут передаваться, скорее всего, не одним пакетом, а несколькими, и по ходу дела надо будет выбрать наилучший маршрут между системами, в которых запущены приложения А и В и т.д.
Чтобы разработчик программ, системный администратор и пользователь не мучались, пытаясь реализовать этот сложный алгоритм самостоятельно, каждая система имеет так называемый стек протоколов, представляющий собой набор программных модулей, которые умеют общаться друг с другом, передавать данные друг другу в ожидаемом формате .
Именно этот стек протоколов и является реальным воплощением идеальной модели межсетевого взаимодействия (рис. 13.1).
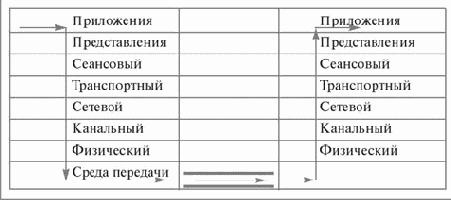
Рис. 13.1. Модель OSI/ISO
Уровень приложения этой модели описывает правила передачи данных от приложения к приложению. В случае браузера и web-сервера этому уровню соответствует протокол HTTP.
Уровень представления описывает представление данных (например, в случае с HTTP символы национальных алфавитов кодируются последовательностями типа %E20; это легко видеть, когда вы делаете запрос в поисковой системе по-русски, и в строке адреса этот запрос отображается такими последовательностями). Протокол уровня представления может зависеть от смысла передаваемых данных, используемой ОС и т.п.
Сеансовый уровень определяет правила управления сеансом связи (как начать сеанс, какие команды можно использовать для согласования параметров сеанса, как передать данные и как завершить сеанс - все это в примере с браузером определяется протоколом HTTP, который, как видно, охватывает целых три уровня модели межсетевого взаимодействия).
Транспортный уровень задает правила передачи пакетов и гарантирует их доставку. Существуют два типа протоколов транспортного уровня - с гарантией доставки и без гарантии. Например, протокол UDP (User Datagram Protocol) - это протокол транспортного уровня без гарантии доставки пакета, а TCP (Transmission Control Protocol) - с гарантией доставки. Если протокол транспортного уровня не обеспечивает гарантии доставки, то эту функцию берут на себя протоколы более высоких уровней.
Сетевой уровень определяет правила адресации и форматы пакетов для передачи по сетям любой природы, независимо от того, какие каналы связи используются. В сети Интернет применяется протокол сетевого уровня IP (Internet Protocol).
Канальный уровень служит для определения правил передачи данных по каналу связи, при этом он делится на уровень управления логическим каналом (LLC - logical link control) и уровень управления доступом к среде передачи (MAC - media access control).
Примером протокола канального уровня является протокол Ethernet, широко используемый в локальных сетях или для быстрого доступа к провайдеру Интернет. В протоколах канального уровня, предполагающих связь нескольких сетевых интерфейсов, определяются адреса каждого из интерфейсов. Так, согласно протоколу Ethernet, каждый сетевой интерфейс должен иметь уникальный MAC-адрес, по которому можно отправить пакет.
Физический уровень определяет правила передачи данных по физическому каналу связи, такие как последовательность бит, четность, наличие стартовых и стоповых битов и т.п. протокол Ethernet может быть отнесен к тем протоколам, которые фактически объединяют в себе протоколы физического и канального уровня.
Кроме того, различают еще один уровень модели межсетевого взаимодействия - "нулевой". Это - уровень среды передачи. Протоколы этого уровня описывают физические параметры сигналов, специфичные для конкретной среды передачи данных. Для медного провода это - уровень сигналов (например, +5В, 0В), допустимое сопротивление провода и т.п.
Протоколы TCP и IP постоянно используются вместе, в связке друг с другом. Поэтому все семейство протоколов, которые базируются на их совместном использовании, часто называют семейством протоколов TCP/IP , а саму связку - протоколом TCP/IP . Действительно, хотя протоколы TCP и IP - это два разных протокола, фактически ТСР не используется ни с каким иным протоколом, кроме IP.
Приложение, которое работает с сетью, может реализовывать один или несколько протоколов, каждый из которых относится к своему уровню представленной модели. Например, программа ftp самостоятельно реализует протоколы, относящиеся к трем уровням: сессионному, представления и приложения.
При передаче через сеть данные претерпевают изменения, которых требуют протоколы всех перечисленных уровней.
Протокол или группа протоколов реализуются подпрограммами операционной системы или самим сетевым приложением. При передаче данных между подпрограммами, от высокоуровневых подпрограмм (уровень приложения) к низкоуровневым (например, реализующим протокол канального уровня), данные разделяются на пакеты и снабжаются служебными заголовками, специфичными для каждого протокола.Когда данные доберутся до места назначения, они пройдут обратный путь снизу вверх по стеку протоколов. Вначале драйверы и подпрограммы операционной системы соберут разрозненные пакеты данных, удалят из них служебные заголовки, затем данными займутся подпрограммы приложения-получателя.
Оценка необходимого размера оперативной памяти
Для оценки памяти, занимаемой каждым из процессов, можно использовать как уже известные команды top и ps, так и команду pmap (последняя дает более подробное распределение памяти процесса по типам - разделяемая память и т.п.):
pmap -х
Вообще говоря, в Sоlaris существует целое семейство так называемых процессных утилит (proc tools) или p-команд, работающих с файловой системой /proc, в которую отображаются многие структуры ядра, в частности, таблица процессов. Эти программы позволяют получать самую разную информацию о процессах, а некоторые из них могут также проанализировать завершившийся аварийно процесс, если от него остался файл core1).
Не следует забывать, что память потребляется не только процессами, но и кэшем файловой системы, тесно разделяемой памятью и ядром! Если в системе не запускается СУБД Oracle или другое подобное приложение, скорее всего, тесно разделяемая память в системе не используется. В Solaris 8 и Solaris 9 для ядра и обязательно запускающихся системных приложений следует заранее предусмотреть не менее 32 Mбайт памяти и еще 16 Mбайт, если CDE тоже запускается. Рекомендованным для Solaris 9 объемом памяти (не считая память, которая требуется для специфических приложений - СУБД, почтового сервера и т.п.) считается 64 Мбайт, но оптимальным для системы, в которой работают с графическим интерфейсом, считается 128 Мбайт. Если планируется одноврменно запускать несколько ресурсоемких графических приложений, например, Mozilla и OpenOffice, следует, по крайней мере, удвоить этот рекомендованный объем.
Если пользователи обращаются только к нескольким сотням мегабайт данных, но делают это часто, то для кэширования всех этих данных должно хватать оперативной памяти. Это радикально ускорит работу.
Оценка ситуации: программы надзора за системой
Для оценки производительности системы мы можем задействовать несколько утилит, которые помогут выяснить, насколько загружены различные компоненты компьютера. Исходя из показателей загрузки и наших знаний о реальных потребностях запущенных процессов, мы сможем решить, изменить ли конфигурацию компьютера, настройки системы или же иначе распределить задачи между компьютерами в сети.
Прежде всего, следует выяснить, есть ли в системе узкие места. Например, постоянная загрузка процессора на 100% может говорить о том, что в системе запущено слишком много конкурирующих процессов, или о работе вычислительного процесса, который постоянно требует процессорное время (что вполне нормально, если только ваш сервер не используют хакеры для подбора или расшифровки паролей), или же о том, что мощности процессора недостаточно для решения задач возложенных на него, и этот компьютер требует модернизации (начальство против? - попробуйте распределить нагрузку в сети или поменять работу - что сейчас легче сделать?)
Если одновременно запущенные процессы мешают друг другу, непрерывно требуя процессорное время, увеличивая нагрузку на планировщик задач и отнимая время на постоянное переключение контекстов, следует подумать об их последовательном запуске - на однопроцессорном компьютере это может привести даже к увеличению скорости их выполнения. Если же при этом процессы конкурируют не только за процессорное время, но и за оперативную память, вызывая активный пейджинг, то их последовательный запуск совершенно точно будет более эффективным, чем параллельный: задачи выполнятся быстрее и нагрузка на систему будет меньше.
Для оценки загрузки процессора и состояния памяти (достаточно ли оперативной памяти, не перегружена ли дисковая подсистема свопингом и т.п.) служат программы top и sar. Конкретные примеры применения этих программ даны ниже, в разделе "Эффективное использование памяти и свопинга". Программа top выводит информацию о процессах, которые наиболее активно занимают процессор:
top last pid: 501; load averages: 0.08, 0.34, 0.40 19:12:00 59 processes: 58 sleeping, 1 on cpu CPU states: 96.2% idle, 0.8% user, 1.0% kernel, 2.0% iowait, 0.0% swap Memory: 128M real, 3596K free, 132M swap in use, 466M swap free PID USERNAME LWP PRI NICE SIZE RES STATE TIME CPU COMMAND 345 root 1 59 0 24M 9972K sleep 0:11 1.14% Xsun 470 root 4 49 0 128M 71M sleep 0:52 1.01% soffice.bin 501 root 1 59 0 2228K 1336K cpu 0:00 0.55% top 461 root 1 59 0 15M 3184K sleep 0:00 0.37% dtterm 467 root 1 49 0 4708K 832K sleep 0:00 0.00% bash 435 root 1 49 0 16M 1760K sleep 0:00 0.00% dtfile 434 root 5 59 0 22M 6304K sleep 0:01 0.00% dtwm 427 root 1 49 0 18M 0K sleep 0:00 0.00% dtsession 436 root 1 59 0 14M 3292K sleep 0:00 0.00% sdtperfmeter 265 root 26 59 0 5480K 1456K sleep 0:00 0.00% htt_server 460 root 1 59 0 3064K 1372K sleep 0:00 0.00% dtexec 315 root 1 59 0 6900K 1324K sleep 0:00 0.00% dtlogin 411 root 1 59 0 3784K 1300K sleep 0:00 0.00% sdt_shell 183 root 3 59 0 5832K 1188K sleep 0:00 0.00% automountd 195 root 13 59 0 5660K 1100K sleep 0:00 0.00% syslogd
Программа sar подобна vmstat и выдает статистику по работе системы, ее можно запустить для выдачи определенных параметров одномоментно или для периодического вывода сведений, например, для десятикратного измерения значений стандартного набора параметров с периодом 5 секунд:
sar 5 10 SunOS sunny 5.9 Generic_112234-03 i86pc 07/03/2004 19:12:34 %usr %sys %wio %idle 19:12:39 0 1 0 99 19:12:44 0 0 0 100 19:12:49 0 1 0 99 19:12:54 4 1 0 95 19:12:59 0 0 0 100 19:13:04 0 1 0 99 19:13:09 5 1 0 94 19:13:14 1 24 66 8 19:13:19 2 35 38 25 19:13:24 3 20 17 60
Ограничение доступа к сетевым службам
Для ограничения доступа к сетевым службам прежде всего следует отменить запуск всех служб, доступ к которым вы предоставлять не намерены. Для служб, запускаемых по запросу, это можно сделать, просто поставив знак комментария # (решетка) перед строкой, в которой указана соответствующая служба. Службы (демоны), запускаемые в начале работы системы, выключаются тоже довольно просто - достаточно удалить запускающий их скрипт из каталога /etc/rc?.d. Если они запускаются напрямую из /etc/inittab, закомментируйте соответствующую строку в этом файле.
После того, как мы гарантировали запуск только требуемых нам служб, приходит время определить специфические права доступа к этим службам. Мы можем ограничить доступ к ним из тех или иных источников. Можно сделать это посредством фильтра пакетов, как описано в лекции 13, либо внеся изменения в файл /etc/hosts.allow, в случае использования TCP wrapper - программы tcpd. Для включения механизма TCP wrapper при работе через inetd следует в файле /etc/default/inetd параметру ENABLE_TCPWRAPPERS присвоить значение YES (по умолчанию установлено NO, что означает "не использовать TCP wrapper>).
Ограничения при работе с growfs
С помощью growfs можно расширять только файловые системы UFS (не важно, смонтированные они или несмонтированные). Расширенная файловая система не может быть уменьшена. Расширение файловой системы невозможно, если:
на задействованном в ней устройстве находится файл учета запущенной системы acct, или включена система безопасности на уровне C2 и файл журналирования находится на расширяемом устройстве, или на ней находится локальный файл свопинга, или эта файловая система монтируется в каталог /usr или корневой каталог или является активным разделом свопинга.
Описание NFS
Служба NFS позволяет серверу обеспечить разделяемый доступ к указанным каталогам его локальной файловой системы, а клиенту - монтировать эти каталоги так же, как если бы они были локальными каталогами клиента.
Оптимизация пейджинга и свопинга посредством настройки ядра
Алгоритм пейджинга и свопинга в Solaris предусматривает возможность явного указания границ свободной памяти в системе, по достижении которых вначале происходит активный пейджинг (выгрузка отдельных страниц), а при дальнейшем уменьшении свободной памяти - свопинг (выгрузка всех страниц процесса сразу). Более подробно эти возможности настройки рассматриваются в лекции 17.
 |
|
|
1) Файл core записывается в текущий каталог процесса в случае аварийного завершения; слу- чаи прерывания процесса по сигналам KILL, TERM и HUP к этому не относятся. Имя файла - всегда core, независимо от имени файла, который был запущен для порождения аварийного процесса. Файл core представляет собой дамп памяти (всех сегментов) процесса, поэтому его можно проанализировать так же, как и запущенный процесс, это - моментальный снимок памяти процесса на момент аварийного завершения (прим. авт.).
ВПЕРЕД
|
Оптимизация производительности
Для оптимизации производительности NFS используется несколько средств.
Во-первых, чем быстрее работают диски сервера NFS, тем быстрее информация будет передана через сеть. Современные сети часто строятся на основе высокоскоростных (как минимум, 100-мегабитных) коммутаторов, поэтому диски даже чаще оказываются узким местом в производительности, чем сеть. Если говорить об архитектуре x86, то предпочтительнее использовать в серверах современные жесткие диски с поддержкой UltraDMA-100, которые позволяют отдавать данные приложению с диска со скоростью порядка 50 Мбайт/с.
Во-вторых, используется кэширование файлов на стороне сервера (поскольку любые операции чтения и записи кэшируются, имеет смысл увеличить объем памяти сервера NFS для того, чтобы кэш мог занимать больше памяти). Старайтесь избегать совмещения функций сервера NFS и сервера приложений, требовательного к объему памяти, типа сервера баз данных, на одном и том же компьютере.
В-третьих, может использоваться локальное кэширование посредством создания кэширующей файловой системы cachefs, как говорилось выше.
В SunOS 4.x для кэширования запросов к удаленной файловой системе NFS использовался процесс biod, но в SunOS 5.x (т.е. с самых ранних версий Solaris - см. таблица 19.1) применяется автоматическое кэширование всех операций чтения и записи, в том числе и для файлов, расположенных на удаленных серверах NFS. Поэтому в специальном процессе biod (в некоторых системах UNIX аналогичный по смыслу процесс называется nfsiod) нет необходимости в Solaris.
| 4.x | 1.x |
| 5.6 | 2.6 |
| 5.7 | 7 |
| 5.8 | 8 |
| 5.9 | 9 |
| 5.10 | 10 |
Выполним еще один эксперимент - сервером NFS будет компьютер ixy (Linux), а клиентом - компьютер под управлением Solaris. Все команды даются на компьютере-клиенте:
showmount -e ixy export list for ixy: /usr/home/filip/nfst (everyone)
Посмотрим, где можно создать подходящий пустой каталог, чтобы в него смонтировать удаленную файловую систему.
Создадим каталог nfsc в корневом каталоге:
cd / ls devices lost+ found opt TT_DB bin etc mnt platform tuition boot export named.run proc usr cdrom home net sbin var core kernel nfst test vol dev lib nsmail tmp xfn mkdir nfsc mount ixy:/usr/home/filip/nfst /nfsc
Проверим, получилось ли:
mount / on /dev/dsk/c0d0s0 read/write/setuid/intr/largefiles/xattr/onerror=panic/dev= 1980000 on Сбт Июл 3 18:59:13 2004 /boot on /dev/dsk/c0d0p0:boot read/write/setuid/nohidden/nofoldcase/dev=19a3010 on Сбт Июл 3 18:59:11 2004 /proc on /proc read/write/setuid/dev=2d80000 on Сбт Июл 3 18:59:12 2004 /etc/mnttab on mnttab read/write/setuid/dev=2e40000 on Сбт Июл 3 18:59:12 2004 /dev/fd on fd read/write/setuid/dev=2e80000 on Сбт Июл 3 18:59:14 2004 /var/run on swap read/write/setuid/xattr/dev=1 on Сбт Июл 3 18:59:17 2004 /tmp on swap read/write/setuid/xattr/dev=2 on Сбт Июл 3 18:59:18 2004 /export/home on /dev/dsk/c0d0s7 read/write/setuid/intr/largefiles/xattr/onerror=panic/dev= 1980007 on Сбт Июл 3 18:59:18 2004 /nfsc on ixy:/usr/home/filip/nfst remote/read/write/setuid/ xattr/dev=2fc0002 on Сбт Июл 3 21:23:45 2004
Последняя строка вывода mount говорит о том, что все прошло успешно. Попробуем скопировать файл на сервер NFS:
cp /etc/dfs/dfstab /nfsc cp: cannot create /nfsc/dfstab: Read-only file system
Это означает, что данная файловая система экспортируется сервером NFS только для чтения. Демонтирование удаленной файловой системы производится аналогично демонтированию файловых систем других типов:
umount /nfsc
При экспорте файловых систем могут быть использованы параметры, указывающие, в каком режиме экспортируется файловая система. Они рассмотрены в лекции 18 в разделе "Параметры экспорта в /etc/dfs/dfstab".
При монтировании файловых систем с сервера NFS клиентом под управлением Solaris могут быть использованы другие параметры монтирования, указывающие уже клиенту, как именно следует смонтировать удаленную файловую систему.
Основные параметры для клиента NFS приведены в таблица 19.2.
Их следует указывать в файле /etc/dfs/vfstab в поле параметров монтирования (последнее поле строки dfstab). Пример /etc/dfs/vfstab приведен ниже.
| rw | монтировать в режиме чтения и записи ( действует только если сервер экспортирует указанный каталог в режиме чтения и записи) |
| ro | смонтировать только для чтения |
| hard | если сервер станет недоступен, повторять обращение к файлу на удаленной файловой системе до тех пор, пока сервер снова окажется доступен; приводит к зависанию приложения, обращающегося к недоступной файловой системе |
| soft | если сервер станет недоступен, повторять обращение к файлу на удаленной файловой системе столько раз, сколько указано в параметре retrans; обычно приводит к ошибке приложения, обращающегося к недоступной файловой системе (подобно тому, как будет вести себя приложение при попытке чтения с неисправного жесткого диска, например) |
| retrans=n | количество повторений запроса до принятия решения об ошибке, см. soft, таймаут задается параметром timeo |
| timeo=n | n - таймаут между запросами в десятых долях секунды |
| intr | позволяет прервать (послать сигнал INTR, Ctrl-C) обращение к недоступной файловой системе |
| nointr | не позволяет прерывать обращения к недоступной файловой системе |
| proto=(tcp|udp) | выбор протокола, по умолчанию - первый доступный из /etc/netconfig |
| rsize=n | размер буфера чтения в байтах |
| wsize=n | размер буфера записи в байтах |
#device device mount FS fsck mount mount #to mount to fsck point type pass at boot option /proc - /proc proc - no - fd - /dev/fd fd - no - swap - /tmp tmpfs - yes - pxy.gu.ru:/exprt - /home nfs - yes rw,noquota
Основной шлюз
Адрес 0.0.0.0 зарезервирован для указания "всех остальных адресатов". Если пакет не удается соотнести с конкретной строкой таблицы маршрутизации, он отправляется в шлюз согласно указывающей на него строке таблицы маршрутизации. Например, таблица маршрутизации нашего хоста выглядит так:
# netstat -rn Routing Table: IPv4 Destination Gateway Flags Ref Use Interface 192.168.5.0 192.168.5.33 U 1 2 elxl0 224.0.0.0 192.168.5.33 U 1 0 elxl0 default 192.168.5.1 UG 1 0 127.0.0.1 127.0.0.1 UH 61 1013 lo0
Адрес нашего компьютера в этой сети - 192.168.5.33. Предположим, нам надо отправить пакет по адресу 192.168.5.30. Для этого система посмотрит в таблицу маршрутизации и обнаружит там маршрут 192.168.5.0, для которого указан шлюз (gateway) 192.168.5.33 - наш собственный интерфейс. Стало быть, компьютер 192.168.5.30 находится в непосредственно присоединенной к нам сети и ему надо послать пакет напрямую.
Ситуация изменится, если адресатом будет, скажем, компьютер 192.168.10.1. Тогда в таблице маршрутизации вначале не найдется подходящего маршрута - ведь там нет отдельной строки для сети 192.168.10.1, верно? Тогда пакет будет отправлен в основной шлюз, "шлюз по умолчанию", тот, что в выводе netstat обозначен словом default. Адрес назначения пакетов "во все остальные сети", тех самых, которые отправляются в шлюз, в таблице маршрутизации в ядре обозначается как 0.0.0.0.
Пакеты, предназначенные для отправки "всем остальным", направляются в основной шлюз. Основной шлюз (default gateway) - это такое место, куда любой компьютер сети отправляет пакет, если не знает, в какую сторону его лучше отправить. Действие такого шлюза подобно действию почтальона. Если вы хотите сделать сюрприз девушке, которая живет с вами в одном подъезде, вы можете положить нежное письмо ей прямо в почтовый ящик. Если же адресат живет в другом городе, вы положите конверт в другой почтовый ящик, тот, из которого почтальон вынимает почту для отправки. Основной шлюз имеет сетевой интерфейс, который работает таким "почтовым ящиком" для пакетов, адресованных за пределы локальной сети.
Особенности NFS в системах Solaris
В Solaris NFS организован не так, как в других системах UNIX, и это следует иметь в виду при настройке систем в гетерогенных сетях:
файл /etc/dfs/dfstab в других системах называется /etc/exports; в других системах файл /etc/exports является файлом конфигурации, а не скриптом, вызывающим программу share; в Solaris после изменения параметров монтирования в файле /etc/dfs/dfstab нужно дать команду shareall для вступления изменений в силу; в других системах следует перезапустить mountd и nfsd, обычно для этого можно использовать сценарий, как и в Solaris; Solaris автоматически становится NFS-сервером при загрузке, если в файле /etc/dfs/dfstab указаны экспортированнные каталоги.
Помните, что команда shareall просто выполняет подряд все команды share, содержащиеся в файле /etc/dfs/dfstab. Если этот файл был модифицирован и некоторые команды экспорта каких-то файловых систем были удалены, действие старых команд share, запущенных до модификации файла, продолжится и после выполнения shareall.
Поэтому следует перезапустить mountd для того, чтобы изменения возымели эффект. Внимание: нельзя перезапускать mountd, когда пользователи работают с файловой системой сервера NFS, так как это может вызвать потери данных и зависание систем - клиентов NFS.
Если требуется разрешить доступ к разделяемой файловой системе только определенной группе машин, следует указать их список команде share:
share -F nfs -o rw=host1:host2 /home/host12
были добавлены некоторые расширения
В Solaris 9 были добавлены некоторые расширения поддержки NFS, которые улучшили производительность:
сняты ограничения на размер пакета; остались только ограничения, налагаемые транспортным протоколом, поэтому для NFS через UDP максимальный размер пакета составляет 32 Кбайт, а для TCP - 1 Мбайт; клиент NFS теперь не занимает большое количество портов UDP. Ранее NFS использовала отдельный порт UDP для каждого запроса. Начиная с Solaris 9, клиент NFS по умолчанию использует только один заранее определенный порт. Однако эта функция настраивается: можно попытаться увеличить число портов, так как это может привести к увеличению производительности; изменен алгоритм выполнения последовательных записей: ранее все запросы на запись выполнялись последовательно клиентом, затем сервером. Введена возможность (для клиента NFS) разрешить приложению выполнять одновременную запись (равно и одновременное чтение и запись) в один и тот же файл. Разрешить такое поведение можно с помощью параметра forcedirectio при монтировании файловой системы. Этот параметр распространяется на все файлы смонтированной файловой системы. Существует возможность разрешить такой режим работы с единственным файлом с помощью функции directio(). По умолчанию (без указания параметра при монтировании) запись в файл производится так же, как и раньше.
Параметры ядра и пейджинг
physmem: общее количество страниц в оперативной памяти.
lotsfree: сканер страниц начинает работать, когда количество свободной оперативной памяти становится меньше lotsfree.
Значение по умолчанию - physmem/64, но оно может быть изменено в /etc/system. Сканер страниц по умолчанию запускается в режиме пейджинга. Частота сканирования (scan rate, столбик sr в выводе vmstat) устанавливается равной параметру slowscan , который по умолчанию равен fastscan/10.
minfree: пока объем свободной памяти находится между lotsfree и minfree, частота сканирования страниц растет линейно от slowscan к fastscan по мере уменьшения размера свободной памяти (рис. 20.1). Значение minfree по умолчанию - desfree/2, значение fastscan по умолчанию - physmem/4. Если свободной памяти становится меньше, чем desfree (что по умолчанию равно lotsfree/2), сканер страниц начинает запускаться с частотой 100 раз в секунду. За каждый свой запуск сканер страниц проверяет desscan страниц. Этот параметр изменяется динамически вместе с частотой сканирования.
maxpgio: этот параметр (в зависимости от конкретной аппаратуры он имеет значение 40 или 60) по умолчанию ограничивает частоту ввода-вывода на устройство пейджинга. Для современных дисков с частотой вращения больше 7200 оборотов в минуту можно установить значение maxpgio в сто раз больше количества жестких дисков, задействованных в свопинге.
throttlefree: когда свободной оперативной памяти становится меньше, чем определено в throttlefree (по умолчанию этот параметр равен minfree), запросы процессов на выделение им новых страниц памяти переводятся в состояние ожидания до тех пор, пока не появятся свободные страницы.
cachefree: имеет значение для систем Solaris 7 (или систем 2.5.1 и 2.6 с установленными самыми свежими обновлениями); если в этих системах параметр priority_paging установлен равным 1 (т.е. priority paging включен), то пока свободной памяти больше, чем lotsfree, освобождаются только страницы файлового кэша в памяти, а страницы процессов не затрагиваются.
Значение по умолчанию - удвоенное lotsfree. Системы Solaris более поздних версий, начиная с 8-й, имеют другой алгоритм освобождения оперативной памяти, и в них НЕ следует включать priority paging и устанавливать значение cachefree.
В системах Solaris до версии 7 включительно сканер страниц работает так: для выбранных сканером страниц обнуляется флаг "используемости" страницы, выбор страниц происходит со скоростью, которую можно посмотреть с помощью vmstat или sar -g (scan rate). После обработки handspreadpages страниц сканер проверяет, установлен ли флаг "используемости". Фактически, сканер состоит из двух процессов, один из которых идет по памяти и очищает флаги встреченных страниц, а второй следует за ним на некотором расстоянии и проверяет,не было ли новых обращений к этой странице (не установился ли снова этот флаг). Если флаг не установлен (обращений к странице за то время, пока сканер отмечал handspreadpages страниц, не произошло), то страница отправляется в своп. Параметр handspreadpages по умолчанию равен physmem/4.
Рис. 17.1. Зависимость частоты запуска сканера страниц от объема свободной памяти
В системах Solaris 8 и более новых алгоритм освобождения памяти иной (он называется cyclical page cache). Он рассчитан на то, что при нехватке памяти выгружаются прежде всего страницы файлового кэша, и только затем - страницы процессов. Этот алгоритм разработан для тех же целей, что и priority paging в Solaris 7. Новый алгоритм использует два списка свободных страниц. Один - для помещения в него освобождающихся страниц файлового кэша, другой - для помещения прочих освобождающихся страниц (разделяемой памяти, процессов и т.п.). При таком подходе файловый кэш ни с кем не соперничает за место в памяти.
В результате этих изменений в системах Solaris, начиная с версии 8, vmstat сообщает иные цифры, чем в той же ситуации в более старых системах, а именно:
скорость возврата страниц выше; весь файловый кэш показывается как свободная память; скорость сканирования страниц (scan rate) низкая (даже близка к нулю), за исключением ситуаций, когда в системе ощущается острая нехватка памяти для приложений.
Для получения отдельного отчета по пейджингу страниц приложений (executables), данных (anonymous) и файловой системы используйте команду
vmstat -p
Параметры экспорта в /etc/dfs/dfstab
При экспорте файловых систем можно передавать командам share ряд параметров, указывающих, в каком режиме следует экспортировать те или иные каталоги. Наиболее важные параметры сведены в табл. 18.2:
| ro | только для чтения - для всех |
| ro=host1, host2 | только для чтения и только указанным компьютерам |
| rw | для чтения и записи - для всех |
| rw=host1, host2 | для чтения и записи, но только указанным компьютерам |
| root=host1, host2 | с указанных компьютеров пользователь root получает доступ к файлам на сервере NFS от имени root (иначе - от имени nobody или указанного в параметре anon) |
| anon=uid | идентификатор пользователя, от имени которого сможет работать с файлами на сервере NFS пользователь root удаленного (клиентского) компьютера, по умолчанию - nobody |
| nosub | запрещается монтировать подкаталоги экспортируемого каталога |
| nosuid | запрещается создавать в экспортируемой файловой системе файлы с установленными битами suid и sgid |
Например, файл /etc/dfs/dfstab может иметь такой вид для экспорта двух файловых систем:
share -F nfs -o rw=@212.231.110, ro=@192.168.4 /home share -F nfs -o ro=212.231.110@,root=212.231.110.112\ /usr/share/man
Печать документов, просмотр и отмена заданий на печать
Для печати документа можно выбрать в меню функцию Print, если соответствующее меню имеется в задействованном приложении. При работе в командной строке для печати файла дайте команду
lp имя_файла
или
lpr имя_файла
Для просмотра очереди печати используют команду lpq:
bash-2.05# cat >> lptest lptest bash-2.05# lp lptest request id is hplj-2 (1 file) bash-2.05# lpq Port Name PS-1426 ============================== [Total Status] Job 41 Sizes (KBytes) 10546 Timeouts 0 ------------------------------ [Current Job] Printer Status On line Index 0 Protocol Name Spooling Bytes 0 Printing Bytes 0 ==============================
Отмена задания выполняется командой lprm:
lp filename request id is hplj-4 (1 file) lprm hplj-4
Команда lprm без параметров удаляет текущее (выполняемое) задание на печать.
Все эти команды принимают имя принтера (то, которым принтер назван в /etc/printers.conf или в базе данных NIS) с ключом -Р:
lprm -P hplj
Существует возможность активировать или деактивировать принтер, описанный в /etc/printers.conf. Это делается командами enable и disable соответственно. Более того, можно временно приостановить принятие запросов на печать для определенного принтера командой
reject имя_принтера
и затем восстановить прием заданий командой
accept имя_принтера
В некоторых командных процессорах команды accept, reject, enable и disable могут быть встроенными командами командного процессора, и тогда следует найти команды подсистемы печати, используя find или whereis, а затем запускать их, указывая полное имя команд.
/td>

|
Планирование установки
Наиболее важные моменты, которые следует помнить при планировании, это - архитектура компьютеров, на которые будет устанавливаться система (SPARC или x86) и требуемая конфигурация (какие наборы ПО будут устанавливаться - Entire Distribution или другой) для каждого компьютера. Чтобы избежать вопросов программы установки при выполнении установки системы, следует заранее ответить на них с помощью создания файла sysidcfg. Затем следует создать профили установки, файл rules с описаниями профилей, который нужен для того, чтобы программа установки выбрала из него нужный профиль, а также приготовить сервер установки, с которого и будет происходить установка.
Технически возможно обойтись и без сервера установки, если речь идет об установке системы на компьютеры, не присоединенные к сети, но это довольно редкий случай. В такой ситуации понадобится компакт-диск с дистрибутивом, файлы rules и файл(ы) профиля установки.
Подготовка сервера к установке всех клиентов установки
Теперь следует на сервере установки указать, какие именно системы будут установлены, с помощью команды add_install_client:
cd /export/install/sparc/Solaris_9/Tools ./add_install_client -c servername:/jumpstart hostname sun4u
Здесь указывается имя сервера установки (servername) и каталог jumpstart, разделяемый в сети через NFS, имя компьютера, на который будет производиться установка с использованием сервера установки, и платформа/модель этого компьютера (в нашем случае sun4u обозначает систему Sun Ultra-5). Эту команду надо выполнить для каждого компьютера!
Аналогичную процедуру надо проделать и с добавлением в список устанавливаемых компьютеров тех, что имеют архитектуру x86:
cd /export/install/intel/Solaris_9/Tools ./add_install_client -c servername:/jumpstart hostname i86pc
Если при этом надо обеспечить загрузку этих компьютеров по сети, следует на сервере загрузки выполнить команду
cd /export/install/intel/Solaris_9/Tools ./add_install_client -d -s bootserver:/export/install/intel \ -c installserver:/jumpstart SUNW.i86pc i86pc
Ключ -d объясняет, что клиент сервера загрузки использует DHCP, - s указывает путь к серверу с дистрибутивом, - c - путь к серверу с каталогом jumpstart (в общем случае это могут быть разные серверы).
SUNW.i86pc - это класс DHCP для всех клиентов архитектуры x86, i86pc - название платформы для всех компьютеров x86.
Подключение нового оборудования
Задача подключения нового оборудования сводится к двум шагам: загрузке соответствующего драйвера нового устройства в ядро и созданию файла устройства в каталоге /dev. Это справедливо для всех систем UNIX. В Solaris все немного сложнее: как уже говорилось, сначала надо создать файл устройства в /devices, а затем - соответствующие символические ссылки на него в /dev.
К счастью, эти задачи можно решать автоматизированно: в Solaris есть утилита devfsadm, которая автоматически распознает вновь подключенные устройства и создает необходимые файлы в /devices и /dev.
Для получения информации об уже установленных устройствах следует пользоваться программами prtconf, sysdef и dmesg.
Программа prtconf выдает информацию о конфигурации системы в том виде, в котором она иерархически представлена в системе; с помощью prtconf можно выяснить, "увидела" ли система то или иное устройство.
Программа sysdef дает больше информации о системе, она выводит не только список аппаратуры в системе, но и перечень псевдоустройств и загруженных модулей, параметры ядра, информацию о разделяемой памяти, семафорах и т.п.
Программа dmesg выдает сообщения из файла протокола и список устройств, обнаруженных при последней перезагрузке системы. Эти сообщения можно также посмотреть в файле /var/adm/messages.
При загрузке ядро системы в состоянии выполнить автоматическую самонастройку, определяя, какие именно устройства подключены к системе. Если вы подключили любое новое устройство к компьютеру (например, новый накопитель), и оно в настоящее время не видно ядру, следует создать файл /reconfigure и перезапустить систему:
touch reconfigure; reboot
После перезагрузки система увидит новое устройство, если только оно вообще поддерживается данной версией системы.
Вместо создания файла /reconfigure и перезапуска допустимо при загрузке системы дать команду из строки начального загрузчика:
boot -r
Этот способ менее предпочтителен, потому что не позволяет запланировать перезапуск на более поздний срок и требует интерактивного вмешательства администратора.
Начиная с версии Solaris 8 можно добавлять и удалять устройства из системы без ее перезагрузки, для этого служит утилита devfsadm. Ее можно запускать интерактивно, но если запущен демон автоконфигурации devfsadmd, то в этом нет надобности - изменения будут сделаны автоматически. Программы devfsadm и devfsadmd работают с файлом /etc/path_to_inst, в котором находится список устройств в системе. При добавлении новых устройств записи в файле не перенумеруются - к старым посто добавляются новые.
В случае, если файл /etc/path_to_inst был удален или неверно отредактирован, система не сможет загрузиться. В этом случае можно загрузиться с CD-ROM и переписать файл с дистрибутивного диска.
Еще одним важным файлом в контексте разговора об устройствах в Solaris является файл /etc/name_to_major, который служит для отображения имен устройств в major номера файлов устройств; этот файл создается при формировании содержимого каталога /devices, например, при работе devfsadmd.
Полностью определенное доменное имя
Каждый компьютер в сети имеет имя. Например, компьютер, на котором я пишу эту книгу, называется sunny. Это его собственное имя, но по такому имени его можно отыскать только в моем локальном домене , но не в Интернете. Для получения доступа к компьютерам в других доменах следует указывать их полные имена. Это похоже на то, как мы обращаемся к файлам. Если я хочу посмотреть файл text в текущем каталоге, я дам команду
cat text
Если же этот файл лежит в другом каталоге, например, /usr/share/, то я дам команду
cat /usr/share/text
Аналогично для обращения через ssh к моему компьютеру из другого домена надо набрать что-то вроде
ssh sunny.eu.spb.ru
Некоторым (весьма редким) программам важно указать, что это полное имя компьютера. Для этого надо в конце имени поставить точку - она показывает, что слева от нее стоит имя домена верхнего уровня, т.к. сама точка обозначает корневой домен . Такое полное имя называют полностью определенным доменным именем (FQDN - fully qualified domain name).
Почему же точек в имени несколько, спросите вы, - ведь корневой домен всего один? На самом деле корневой домен имеет невидимое имя, и это имя - пустая строка! Это действительно так, за самой правой точкой в полностью определенном имени есть имя корневого домена - эта самая пустая строка. А символ точки - это всего лишь разделитель имен доменов и поддоменов. В тех случаях, когда на корневой домен все-таки надо как-то сослаться, используется его полное имя - символ точка (.). Не обозначать же его просто пустой строкой - тогда его никто не увидит!
Пользователи
Пользователи - это те самые обычные пользователи, о которых рассказывалось в лекциях 1, 2 и 4. Они имеют самые обычные учетные записи. Пользователям может быть дано право играть ту или иную роль, согласно записям в файле /etc/security/user_attr.
Понятие "проект" в Solaris
Проектом в Solaris называется единица администрирования, предназначенная для оптимального управления ресурсами системы. К проекту могут относиться любые пользователи и группы, и каждый пользователь или группа могут входить в несколько проектов. В большой системе удобно определить ряд проектов в базе проектов (файле /etc/project или соответствующем файле базы NIS).
Проект характеризуется уникальным идентификатором проекта (PROJID). Каждый пользователь обязательно относится к некоему проекту по умолчанию, и какой именно это проект, определяется при входе пользователя в систему. Пользователь обязательно имеет главный проект (по аналогии с главной группой), но может участвовать в нескольких проектах.
Каждый процесс также обязательно ассоциируется с каким-нибудь проектом. Это не обязательно главный проект пользователя, запустившего процесс, так как пользователь волен отнести запущенный им процесс к любому из проектов, участником которых он является. Отнести пользователя или группу к проекту можно либо в описании пользователя в файле /etc/user_attr, либо в файле проектов /etc/project. Для тех случаев, когда администратор не позаботился о том, чтобы отнести пользователей к определенным проектам, в системе имеется предопределенный проект default, к которому относятся все пользователи, группы и процессы, для которых явным образом не указано иное.
Главный проект пользователя определяется при входе в систему следующим образом:
если в файле /etc/user_attr запись об этом пользователе имеет атрибут project, то в качестве главного проекта пользователю назначается указанный таким образом проект; если в /etc/project имется проект с именем user.UID, где UID совпадает с UID пользователя, то он назначается главным проектом пользователя; если в /etc/project есть проект group.groupname и groupname совпадает с именем главной группы пользователя, то этот проект назначается главным пользователю; если в базе проектов есть проект с именем default, то главным назначается он.
Проверка перечисленных условий производится в указанном выше порядке.
В качестве базы данных проектов может использоваться не только файл /etc/project, но и база данных NIS или LDAP. Порядок обращения к службам имен (файлу, NIS или LDAP) определяется в файле /etc/nsswitch.conf:
project: files nis ldap
При использовании PAM может оказаться полезным также изучить страницу руководства pam_projects(5).
Если при входе для пользователя не удалось определить главный проект, вход пользователю запрещается.
При внесении изменений в базу данных проектов изменения коснутся только процессов, которые будут запущены после этого, и тех пользователей, которые войдут в систему после сохранения изменений. На уже запущенные процессы и уже работающих пользователей изменения не повлияют.
Файл /etc/project имеет следующий формат:
projname:projid:comment:user-list:group-list:attributes
где:
projname - это имя проекта (в нем не должно быть точек, запятых или двоеточий), то есть уникальный идентификатор проекта;
projid - неотрицательное целое число не большее 2147483647;
comment - описание проекта;
user-list - список пользователей, входящих в проект, имена через запятую;
group-list - список групп, входящих в проект, имена групп через запятую;
attributes - атрибуты проекта в формате имя=значение.
Везде, где указано "список", может стоять звездочка (подразумевает "все"), имя может быть предварено восклицательным знаком, что означает "кроме этого" (!groupname - все указанные группы, кроме groupname).
По умолчанию файл /etc/project выглядит так:
system:0:::: user.root:1:::: noproject:2:::: default:3:::: group.staff:10::::
Помимо редактирования файла вручную вы можете пользоваться программами projadd, projmod и projdel для добавления, изменения или удаления проектов. Для получения информации о соответствии процессов проектам следует запускать программы ps, id, pgrep, prstat:
ps -o user,pid,uid,projid USER PID UID PROJID root 672 0 1 root 625 0 1 root 654 0 1 root 652 0 1 root 808 0 1
id -p uid=0(root) gid=1(other) projid=1(user.root)
Синтаксис вызова pgrep:
pgrep -J projidlist
например:
pgrep -J 1 | more 347 460 461 345 368 426 435 378 427 411 412 414 434 436 438 459 463 467 469 470 649 650
prstat -J PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP 345 root 63M 14M sleep 59 0 0:01:35 0,8% Xsun/1 622 root 15M 2532K sleep 59 0 0:00:02 0,6% dtterm/1 470 root 141M 55M sleep 49 0 0:02:07 0,5% soffice.bin/4 820 root 7624K 4576K cpu0 59 0 0:00:00 0,3% prstat/1 672 root 4728K 696K sleep 49 0 0:00:00 0,0% bash/1 652 root 24M 3784K sleep 49 0 0:00:01 0,0% sdtimage/1 654 root 79M 10M sleep 19 10 0:00:08 0,0% java/15 195 root 5660K 0K sleep 59 0 0:00:00 0,0% syslogd/13 175 root 2160K 0K sleep 59 0 0:00:00 0,0% lockd/2 170 root 3028K 0K sleep 59 0 0:00:00 0,0% in.named/1 237 root 1348K 0K sleep 59 0 0:00:00 0,0% powerd/2 183 root 6108K 644K sleep 59 0 0:00:00 0,0% automountd/3 322 root 4360K 0K sleep 59 0 0:00:00 0,0% snmpdx/1 347 root 8632K 0K sleep 59 0 0:00:00 0,0% dtlogin/1 158 root 2412K 0K sleep 59 0 0:00:00 0,0% inetd/1
PROJID NPROC SIZE RSS MEMORY TIME CPU PROJECT 1 30 480M 99M 84% 0:04:00 2,3% user.root 0 38 135M 5788K 4,8% 0:00:00 0,0% system
Total: 68 processes, 185 lwps, load averages: 0,04, 0,14, 0,14 Пример 11.1. Результаты работы программы pgrep
Эта программа выполняется как интерактивная на полном экране (подобно top).
Приоритеты процессов, настройка таблиц диспетчера
Настройка таблиц диспетчера памяти (о них речь шла в лекции 7) производится в три этапа:
вывод существующей таблицы в текстовый файл; редактирование этого файла; загрузка новой таблицы диспетчера в ядро.
Работа по выводу и загрузке таблиц осуществляется с помощью программы dispadmin.
Попробуем модифицировать таблицу диспетчера для класса разделения времени так, чтобы ни один процесс не получил приоритета 59 и ни один процесс не лишился этого приоритета, если мы его присвоим. Это может быть полезно в тех случаях, когда какие-то задачи надлежит вручную запускать с повышенным приоритетом. Конечно, это привнесет несправедливость в таблицу приоритетов нашей системы, и слепо следовать нашему тестовому примеру не стоит.
Посмотрим, как сейчас себя ведут наши процессы:
top last pid: 825; load averages: 0.05, 0.11, 0.12 20:35:24 68 processes: 67 sleeping, 1 on cpu CPU states: 99.8% idle, 0.2% user, 0.0% kernel, 0.0% iowait, 0.0% swap Memory: 128M real, 12M free, 206M swap in use, 387M swap free PID USERNAME LWP PRI NICE SIZE RES STATE TIME CPU COMMAND 825 root 1 59 0 2260K 1340K cpu 0:00 0.61% top 345 root 1 59 0 57M 8648K sleep 1:37 0.35% Xsun 470 root 4 49 0 141M 55M sleep 2:11 0.28% soffice.bin 622 root 1 59 0 15M 2928K sleep 0:02 0.03% dtterm 461 root 1 49 0 15M 1864K sleep 0:03 0.00% dtterm 654 root 15 19 10 79M 10M sleep 0:08 0.00% java 434 root 5 59 0 22M 4060K sleep 0:04 0.00% dtwm 652 root 1 49 0 24M 3784K sleep 0:01 0.00% sdtimage 435 root 1 49 0 16M 1216K sleep 0:00 0.00% dtfile 672 root 1 49 0 4728K 740K sleep 0:00 0.00% bash 427 root 1 49 0 18M 0K sleep 0:00 0.00% dtsession 467 root 1 49 0 4728K 0K sleep 0:00 0.00% bash 650 root 1 49 0 3460K 0K sleep 0:00 0.00% more 649 root 1 49 0 3356K 0K sleep 0:00 0.00% sh 634 root 1 49 0 3304K 0K sleep 0:00 0.00% man Пример 11.2. Таблица приоритетов
Теперь пусть приоритет 59 может получить только та программа, которой мы это разрешим, а все остальные по умолчанию не могут.
Для этого предварительно модифицируем таблицу диспетчера так, чтобы ни один процесс не получил приоритета 59.
Вначале выведем текущую таблицу приоритетов:
dispadmin -c TS -g > prior
Файл prior выглядит так:
# Time Sharing Dispatcher Configuration RES=1000 # ts_quantum ts_tqexp ts_slpret ts_maxwait ts_lwait PRIORITY LEVEL 200 0 50 0 50 # 0 200 0 50 0 50 # 1 200 0 50 0 50 # 2 200 0 50 0 50 # 3 200 0 50 0 50 # 4 200 0 50 0 50 # 5 200 0 50 0 50 # 6 200 0 50 0 50 # 7 200 0 50 0 50 # 8 200 0 50 0 50 # 9 160 0 51 0 51 # 10 160 1 51 0 51 # 11 160 2 51 0 51 # 12 160 3 51 0 51 # 13 160 51 0 51 # 14 160 5 51 0 51 # 15 160 6 51 0 51 # 16 160 7 51 0 51 # 17 160 8 51 0 51 # 18 160 9 51 0 51 # 19 120 10 52 0 52 # 20 120 11 52 0 52 # 21 120 12 52 0 52 # 22 120 13 52 0 52 # 23 120 14 52 0 52 # 24 120 15 52 0 52 # 25 120 116 52 0 52 # 26 120 117 52 0 52 # 27 120 118 52 0 52 # 28 120 19 52 0 52 # 29 80 20 53 0 53 # 30 80 21 53 0 53 # 31 80 22 53 0 53 # 32 80 23 53 0 53 # 33 80 24 53 0 53 # 34 80 25 54 0 54 # 35 80 26 54 0 54 # 36 80 27 54 0 54 # 37 80 28 54 0 54 # 38 80 29 54 0 54 # 39 40 30 55 0 55 # 40 40 31 55 0 55 # 41 40 32 55 0 55 # 42 40 33 55 0 55 # 43 40 34 55 0 55 # 44 40 35 56 0 56 # 45 40 36 57 0 57 # 46 40 37 58 0 58 # 47 40 38 58 0 58 # 48 40 39 58 0 59 # 49 40 40 58 0 59 # 50 40 41 58 0 59 # 51 40 42 58 0 59 # 52 40 43 58 0 59 # 53 40 44 58 0 59 # 54 40 45 58 0 59 # 55 40 46 58 0 59 # 56 40 47 58 0 59 # 57 40 48 58 0 59 # 58 20 49 59 32000 59 # 59 Пример 11.3. Файл prior
Теперь мы его изменяем так, как нам надо, и он становится иным (показаны только измененные последние две строки):
# ts_quantum ts_tqexp ts_slpret ts_maxwait ts_lwait PRIORITY LEVEL 40 48 58 32000 58 # 58 20 59 59 0 59 # 59
Загружаем этот файл, запустив
dispadmin -c TS -s prior
Смотрим вывод top:
last pid: 836; load averages: 0.14, 0.14, 0.13 20:43:48 68 processes: 66 sleeping, 1 running, 1 on cpu CPU states: 94.8% idle, 5.0% user, 0.2% kernel, 0.0% iowait, 0.0% swap Memory: 128M real, 10M free, 204M swap in use, 389M swap free PID USERNAME LWP PRI NICE SIZE RES STATE TIME CPU COMMAND 470 root 4 49 0 141M 57M sleep 2:34 7.64% soffice.bin 345 root 1 59 0 56M 7228K sleep 1:46 0.86% Xsun 836 root 1 59 0 2260K 1336K cpu 0:00 0.77% top 622 root 1 59 0 15M 2972K sleep 0:02 0.03% dtterm 672 root 1 48 0 4728K 1176K sleep 0:00 0.03% bash 654 root 15 49 0 79M 11M run 0:08 0.02% java 461 root 1 49 0 15M 1924K sleep 0:03 0.02% dtterm 434 root 5 59 0 22M 4084K sleep 0:04 0.00% dtwm 652 root 1 49 0 24M 3784K sleep 0:01 0.00% sdtimage 435 root 1 49 0 16M 1216K sleep 0:00 0.00% dtfile 427 root 1 49 0 18M 0K sleep 0:00 0.00% dtsession 467 root 1 49 0 4728K 0K sleep 0:00 0.00% bash 650 root 1 49 0 3460K 0K sleep 0:00 0.00% more 649 root 1 49 0 3356K 0K sleep 0:00 0.00% sh 634 root 1 49 0 3304K 0K sleep 0:00 0.00% man Пример 11.4.
Вывод команды top
Те процессы, которые по- прежнему имеют приоритет 59, можно перезапустить. Выявим их по команде
ps -ecL | grep 59
остановим и перезапустим. Кроме того, можно регулировать приоритет процесса напрямую с помощью команды priocntl, как показано ниже. Понизим на 20 единиц приоритет всех процессов в классе разделения времени:
priocntl -s -c TS -p -20
Снова запускаем top:
last pid: 987; load averages: 0.00, 0.03, 0.07 21:00:41 66 processes: 65 sleeping, 1 on cpu CPU states: 99.4% idle, 0.0% user, 0.6% kernel, 0.0% iowait, 0.0% swap Memory: 128M real, 6188K free, 202M swap in use, 391M swap free PID USERNAME LWP PRI NICE SIZE RES STATE TIME CPU COMMAND 984 root 1 58 0 2260K 1336K cpu 0:00 0.11% top 345 root 1 58 0 56M 7184K sleep 1:52 0.07% Xsun 622 root 1 58 0 15M 3500K sleep 0:03 0.02% dtterm 470 root 4 48 0 141M 57M sleep 2:40 0.00% soffice.bin 654 root 15 58 0 79M 13M sleep 0:08 0.00% java 434 root 5 58 0 22M 4360K sleep 0:04 0.00% dtwm 461 root 1 58 0 15M 2628K sleep 0:03 0.00% dtterm 652 root 1 58 0 24M 5312K sleep 0:01 0.00% sdtimage 349 root 7 39 6 4532K 704K sleep 0:00 0.00% mibiisa 212 root 18 49 3 2872K 720K sleep 0:00 0.00% nscd 435 root 1 58 0 16M 1908K sleep 0:00 0.00% dtfile 436 root 1 58 0 16M 1864K sleep 0:00 0.00% sdtperfmeter 427 root 1 58 0 18M 1368K sleep 0:00 0.00% dtsession 672 root 1 58 0 4732K 1196K sleep 0:00 0.00% bash 276 root 1 58 0 2068K 580K sleep 0:00 0.00% xntpd Пример 11.5. Вывод команды top
Настройку диспетчерских таблиц следует проводить с осторожностью. Неверные действия могут привести к потере устойчивости и неполадкам в работе производственной системы. Тестируйте внимательно!
Приостановка записи (write throttle) в файловой системе UFS
Одной из проблем в системах, где происходит частая запись больших объемов данных в файлы на диске, является использование слишком больших объемов оперативной памяти для буферов файлов. Пока запись в файл не завершена, буфер занимает место в памяти, и это снижает общую производительность системы. В Solaris придуман механизм борьбы с этим явлением.
Переменная ядра ufs:ufs_WRITESотвечает за включение механизма write throttling (приостановки записи в файл). Если эта переменная равна 1, то приостановка записи разрешена. По умолчанию это именно так.
Приостановка означает, что когда объем данных, ожидающих записи в один файл, превышает верхний предел ufs:ufs_HW, запись в этот файл блокируется до момента, пока объем данных в буфере не снизится до ufs:ufs_LW. Соответственно, пока запись в файл блокирована, пополнение буфера не осуществляется, зато данные из буфера записываются на диск, за счет чего буфер освобождается.
Настройка этих параметров ядра может понадобиться, если количество приостановок постоянно растет. Это можно заметить, изучив с помощью отладчика счетчик ядра ufs_throttles. Его значение увеличивается на единицу при каждой приостановке записи, и постоянное увеличение этого значения говорит о том, что пределы ufs:ufs_LW и ufs:ufs_HW следует увеличить.
Такое увеличение вполне допустимо и даже полезно при использовании метаустройств с расщеплением (striping metadevices), когда данные одного файла поблочно пишутся на несколько устройств одновременно (первый блок - на первый диск, следующий - на второй и т.д.), так как совокупная пропускная способность метаустройства выше, чем у одного физического диска. То же относится и к массивам RAID. Значения ufs:ufs_LW и ufs:ufs_HW не должны быть слишком близкими, но и не должны очень сильно отличаться. Если они слишком близки, то приостановки записи будут случаться очень часто: как только объем буфера окажется у нижнего предела и запись будет разрешена, буфер сразу превысит верхний предел и запись приостановится. Большая разница между значениями приведет к тому, что запись в файл будет заблокирована при превышении верхнего предела, и после этого пройдет значительное время до разблокировки записи, так как буфер не может быть мгновенно "сброшен" на диск, и до достижения нижнего предела придется ждать относительно долго.
Рекомендуется нижний предел устанавливать равным 1/32 объема оперативной памяти, а верхний - 1/16 этого объема.
Приостановка записи производится на пофайловой основе, т.е. блокировка записи в один файл, буфер которого заполнен более чем ufs:ufs_HW байтами, не влияет на запись в другие файлы.
Проблема: много коллизий в сегменте
Если netstat сообщает о большом количестве коллизий на интерфейсе, это может говорить о перегрузке сегмента сети. Вспомните, не генерирует ли какая-нибудь программа излишний или паразитный трафик, нельзя ли избежать передачи каких-то данных через сеть? Для тщательного изучения ситуации пригодится программа tcpdump, которая выводит на экран (перенаправьте вывод в файл для последующего анализа!) заголовки каждого пакета, проходящего мимо вашего сетевого интерфейса. Большое число коллизий также может говорить о том, что давно пора сменить старый дешевый концентратор (hub) на новый коммутатор (switch) - ведь сегодня коммутатор стоит дешевле, чем концентратор в свое время!
Проблема: ошибки на интерфейсе
Некоторое число ошибок на интерфейсе допустимо, но если оно явно пропорционально трафику через интерфейс и превышает 1% от общего числа пересылок (это видно по выводу netstat), стоит изучить состояние кабелей. Может быть, на одном из них стоит стул? Или его жестоко зажали между стойками? Нет? Тогда наверное кто-то завязал на нем несколько узелков на память... Помните также, что плохо обжатые, небрежно подсоединенные или сильно запыленные вилки на кабеле, временные патч-корды, ставшие постоянными, также могут быть причиной проблем в сети. Значительное число ошибок на интерфейсе (10% и более) может сигнализировать о неисправности сетевого адаптера.
Проблема: в сети все в порядке, кроме скорости
Бывает и так: сеть в полном порядке, netstat бодро сообщает, что ошибок и коллизий не имеется, новенькое сетевое оборудование цинично смотрит на нас матовым боком, а скорость передачи через сеть оставляет желать лучшего. В этом, кроме оборудования, могут быть виноваты неверно настроенные драйверы (например, вы ожидаете full-duplex на интерфейсе, но сообщает ли вам о нем ifconfig или коммутатор, к которому подсоединен ваш быстрый компьютер?) или медленная дисковая подсистема получателя или отправителя данных.
 |
|
|
1) TTL - время жизни пакета, измеряется в секундах. Этот показатель определяет, какое максимальное время пакет может провести в очередях маршрутизаторов на отправку. В большинстве маршрутизаторов пакет не задерживается дольше чем на одну секунду, но согласно RFC791 маршрутизатор должен уменьшить TTL, проходящего через него пакета не менее чем на одну секунду, поэтому поле TTL фактически определяет максимально допустимое число пересылок пакета от одного маршрутизатора к другому. Такая пересылка называется "hop".
НАЗАД ВПЕРЕД
|
Процедура монтирования общего каталога через NFS
Прежде чем мы перейдем к описанию настроек сервера и клиентов NFS, следует понять, как осуществляется монтирование удаленных файловых систем в принципе.
Клиент NFS посылает запрос на монтирование удаленному компьютеру, который предоставляет свою файловую систему (обычно - некоторую ее часть) для общего пользования. При этом говорят, что сервер NFS "экспортирует" тот или иной каталог (подразумевается - с подкаталогами). Запрос от клиента NFS попадает на обработку демону mountd. Тот выдает клиенту NFS специальный ключ. Этот ключ является идентификатором, который однозначно идентифицирует каталог, смонтированный по сети.
По NFS можно смонтировать как целые файловые системы, так и отдельные каталоги. Из соображений безопасности запрещено монтировать каталоги "через раздел". Это означает, что если каталог /var расположен на одном разделе диска, а каталог /var/adm - на другом, то при монтировании каталога /var каталог /var/adm не будет автоматически смонтирован. Если требуется монтировать те подкаталоги экспортируемого каталога, которые расположены в другой файловой системе (на другом разделе), следует экспортировать их отдельно и указывать в /etc/dfs/dfstab еще один разделяемый каталог - тот самый подкаталог с другого раздела.
Ключ, выданный клиенту при монтировании и идентифицирующий сеанс работы с данным удаленным каталогом, сохраняется при перезагрузке NFS-сервера, чтобы после восстановления его работы клиенты, замершие в ожидании, продолжили работу с удаленным сервером как ни в чем ни бывало. При демонтировании и новом монтировании файловой системы через NFS ключ обычно изменяется. На практике перезагрузка NFS-сервера все-таки может привести к сбою в работе клиентского приложения, особенно, если приложение читает или записывает файл в удаленный каталог во время перезагрузки.
После монтирования файловой системы через NFS клиент посылает серверу запросы на передачу и прием файлов, эти запросы обрабатывает демон nfsd.
Демонтирование файловой системы NFS выполняется так же, как и демонтирование любой другой файловой системы - командой umount.
Ниже будут обсуждены следующие аспекты настройки службы NFS в сети:
определение списка каталогов на сервере, которые должны быть общими; определение прав доступа к этим каталогам; аутентификация и назначение прав доступа в NFS; настройка сервера NFS , запуск необходимых программ; настройка клиентов NFS, монтирование удаленных каталогов;
Процесс inetd
Демон inetd выполняет функцию привратника: как только пакет приходит к воротам системы, inetd определяет, какой процесс надо запустить, чтобы пакет смог добраться по назначению - к этому процессу. Программа inetd сверяет номер порта назначения в пакете с номером порта назначения в файле /etc/inetd.conf - там этот номер в мнемоническом виде указан в первой колонке. Для выяснения соответствия между номерами портов и их мнемоническими обозначениями служит файл /etc/services. Ниже приводится сокращенный пример файла /etc/inetd.conf:
time stream tcp6 nowait root internal time dgram udp6 wait root internal # # Echo, discard, daytime, and chargen are used primarily for testing. # echo stream tcp6 nowait root internal echo dgram udp6 wait root internal discard stream tcp6 nowait root internal discard dgram udp6 wait root internal daytime stream tcp6 nowait root internal daytime dgram udp6 wait root internal chargen stream tcp6 nowait root internal chargen dgram udp6 wait root internal # # # RPC services syntax: # <rpc_prog>/<vers> <endpoint-type> rpc/<proto> <flags> <user> \ # <pathname> <args> # # <endpoint-type> can be either "tli" or "stream" or "dgram". # For "stream" and "dgram" assume that the endpoint is a # socket descriptor. <proto> can be either a nettype or a # netid or a "*". The value is first treated as a nettype. If # it is not a valid nettype then it is treated as a netid. The # "*" is a short-hand way of saying all the transports # supported by this system, ie. it equates to the "visible" # nettype. The syntax for <proto> is: # *|<nettype|netid>|<nettype|netid>{[,<nettype|netid>]} # For example: # dummy/1 tli rpc/circuit_v,udp wait root /tmp/test_svc test_svc # # Solstice system and network administration class agent server # 100232/10 tli rpc/udp wait root /usr/sbin/sadmind sadmind # # rpc.cmsd is a data base daemon which manages calendar # data backed by files in /var/spool/calendar # # # Sun ToolTalk Database Server # 100083/1 tli rpc/tcp wait root /usr/dt/bin/rpc.ttdbserverd rpc.ttdbse # # Sun KCMS Profile Server # 100221/1 tli rpc/tcp wait root /usr/openwin/bin/kcms_server kcms_server # # Sun Font Server # fs stream tcp wait nobody /usr/openwin/lib/fs.auto fs # # CacheFS Daemon # 100235/1 tli rpc/ticotsord wait root /usr/lib/fs/cachefs/cachefsd cachefsd 100068/2-5 dgram rpc/udp wait root /usr/dt/bin/rpc.cmsd rpc.cmsd # METAD - SLVM metadb Daemon 100229/1 tli rpc/tcp wait root /usr/sbin/rpc.metad rpc.metad # METAMHD - SLVM HA Daemon 100230/1 tli rpc/tcp wait root /usr/sbin/rpc.metamhd rpc.metamhd # METAMEDD - SLVM Mediator Daemon 100242/1 tli rpc/tcp wait root /usr/sbin/rpc.metamedd rpc.metamedd # LPD - Print Protocol Adaptor (BSD listener) printer stream tcp6 nowait root /usr/lib/print/in.lpd in.lpd # RSHD - rsh daemon (BSD protocols) shell stream tcp nowait root /usr/sbin/in.rshd in.rshd shell stream tcp6 nowait root /usr/sbin/in.rshd in.rshd # RLOGIND - rlogin daemon (BSD protocols) login stream tcp6 nowait root /usr/sbin/in.rlogind in.rlogind # REXECD - rexec daemon (BSD protocols) exec stream tcp nowait root /usr/sbin/in.rexecd in.rexecd exec stream tcp6 nowait root /usr/sbin/in.rexecd in.rexecd # COMSATD - comsat daemon (BSD protocols) comsat dgram udp wait root /usr/sbin/in.comsat in.comsat # TALKD - talk daemon (BSD protocols) talk dgram udp wait root /usr/sbin/in.talkd in.talkd # FINGERD - finger daemon finger stream tcp6 nowait nobody /usr/sbin/in.fingerd in.fingerd
Профили прав
Профиль в данном контексте - это набор свойств, который можно назначить той или иной роли. В англоязычной литературе профиль, используемый в RBAC, называется профилем прав (Rights Profile). Профиль прав объединяет различные авторизации с тем, чтобы можно было назначить той или иной роли логически связанный набор авторизаций (например, профиль Operator может быть назначен роли, которая нужна для выполнения простых задач администрирования: выполнения резервных копий, управления доступом к принтеру и свойствами принтера). Информация о профилях хранится в файле /etc/security/prof_attr, поля в котором имеют следующие значения:
profname:res1:res2:desc:attr
profname - это имя профиля; регистр букв в имени имеет значение;
res1, res2 - зарезервированные поля;
desc - описание профиля, в котором указывается смысл данного профиля; это описание должно быть пригодно в качестве пояснения назначения профиля для пользователей приложений высокого уровня (типа Solaris Management Console);
attr - атрибуты в таком же виде, как и в других файлах RBAC, допустимые атрибуты - это auths и help. Значением атрибута auths является список наборов прав (авторизаций) из числа определенных в файле /etc/security/auth_attr. Атрибут help требует указания страницы в формате HTML, содержащей справку по данному профилю.
В нижеследующем примере файла /etc/security/prof_attr опущены некоторые строки, каждый профиль прав описан отдельным абзацем, поскольку в реальном файле он описывается одной длинной строкой, которая не умещается на книжной странице:
# # Copyright (c) 1999-2001 by Sun Microsystems, Inc. # All rights reserved. # # /etc/security/prof_attr # # profiles attributes. see prof_attr(4) # #ident "@(#)prof_attr 1.1 01/10/23 SMI" # iPlanet Directory Management:::Manage the iPlanet directory server:help=RtiDSMngmnt.html
Media Restore:::Restore files and file systems from backups:help=RtMediaRestore.html
Name Service Security:::Security related name service scripts/commands:help=RtNameServiceSecure.html
Device Management:::Control Access to Removable Media:auths=solaris.device.*,solaris.admin.serialmgr.*; help=RtDeviceMngmnt.html
Media Backup:::Backup files and file systems:help=RtMediaBkup.html
User Security:::Manage passwords, clearances:auths=solaris.role.*,solaris.profmgr.*, solaris.admin.usermgr.*;help=RtUserSecurity.html
Audit Control:::Configure BSM auditing:auths=solaris.audit.config,solaris.jobs.admin, solaris.admin.logsvc.purge,solaris.admin.logsvc.read; help=RtAuditCtrl.html
User Management:::Manage users, groups, home directory:auths=solaris.profmgr.read, solaris.admin.usermgr.write,solaris.admin.usermgr.read; help=RtUserMngmnt.html
Mail Management:::Manage sendmail & queues:help=RtMailMngmnt.html Printer Management:::Manage printers, daemons, spooling:help=RtPrntAdmin.html;auths=solaris.admin.printer.read, solaris.admin.printer.modify,solaris.admin.printer.delete
Log Management:::Manage log files:help=RtLogMngmnt.html Audit Review:::Review BSM auditing logs:auths=solaris.audit.read;help=RtAuditReview.html
Software Installation::: Add application software to the system:help=RtSoftwareInstall.html;auths=solaris.admin. prodreg.read,solaris.admin.prodreg.modify,solaris.admin. prodreg.delete,solaris.admin.dcmgr.admin,solaris.admin. dcmgr.read,solaris.admin.patchmgr.*
Network Security:::Manage network and host security:help=RtNetSecure.html;auths=solaris.network.*
Operator:::Can perform simple administrative tasks: profiles=Printer Management,Media Backup,All; help=RtOperator.html
FTP Management:::Manage the FTP server:help=RtFTPMngmnt.html
Project Management:::Manage Solaris projects:auths=solaris.project.read,solaris.project.write; help=RtProjManagement.html
DHCP Management:::Manage the DHCP service:auths=solaris.dhcpmgr.*;help=RtDHCPMngmnt.html
System Administrator:::Can perform most non-security administrative tasks:profiles=Audit Review,Printer Management,Cron Management,Device Management,File System Management,Mail Management,Maintenance and Repair,Media Backup,Media Restore,Name Service Management,Network Management,Object Access Management,Process Management,Software Installation,User Management,All;help=RtSysAdmin.html
Basic Solaris User:::Automatically assigned rights:auths=solaris.profmgr.read,solaris.jobs.users,solaris. mail.mailq,solaris.admin.usermgr.read,solaris.admin.logsvc.read, solaris.admin.fsmgr.read,solaris.admin.serialmgr.read, solaris.admin.diskmgr.read,solaris.admin.procmgr.user, solaris.compsys.read,solaris.admin.printer.read,solaris.admin. prodreg.read,solaris.admin.dcmgr.read,solaris.snmp.read, solaris.project.read,solaris.admin.patchmgr.read,,solaris. network.hosts.read,solaris.admin.volmgr.read;profiles=All; help=RtDefault.html
Программа aspppd
В системах Solaris, начиная с Solaris 2.4 и до Solaris 8 включительно, для обеспечения связи по протоколу PPP использовалась утилита aspppd, вызывавшая нарекания из-за сложности настройки и использования. В Solaris 9 она заменена на более стандартную и удобную программу pppd, которая может служить как сервером, так и клиентом PPP . Для настройки aspppd в более старых системах Solaris следует обратиться к FAQ на эту тему. Например, можно найти одно из них по адресу http://solaris.opennet.ru/docs/RUS/solaris_x86/index.html.
Программа pppd
Сейчас для установления соединений через PPP в UNIX-системах используют сервер pppd , причем он есть в поставке как новых коммерческих, так и некоммерческих вариантов UNIX.
Программа pppd может работать в качестве сервера удаленнго доступа , т.е. принимать входящие звонки, а может выполнять роль клиента, дозваниваясь до сервера удаленного доступа .
При соединении двух компьютеров по протоколу PPP каждый из них рассматривается как равноправный участник соединения. Любой участник может предъявить к соединению свои требования: запросить определенный IP-адрес для себя или другого участника, потребовать аутентификацию и т.д. Если второй участник соглашается с требованием или его собственные требования не противоречат запрошенным, соединение устанавливается. Если требования участников противоречивы, то соединение не устанавливается.
Настройки программы pppd находятся в каталоге /etc/ppp. Основной файл настроек pppd - это /etc/ppp/options.
Синтаксис вызова pppd:
pppd параметры
Параметры должны включать имя_устройства и скорость.
Программа Solaris Print Manager
Для настройки подсистемы печати в Solaris можно использовать утилиту Solaris Print Manager. Она предоставляет простой графический интерфейс для добавления, удаления или изменения настроек принтера в системе.
Важно отметить, что с точки зрения Solaris принтер должен уметь работать с языком PostScript. Использовать такой принтер с Solaris, равно как и с любой другой системой UNIX, намного легче, чем принтер, не понимающий PostScript.
Вызов программы Solaris Print Manager выполняется командой
/usr/sadm/admin/bin/printmgr &
При запуске Solaris Print Manager вас спросят, какую службу имен следует использовать (рис. 22.3).
Рис. 22.3. Первый вопрос программы Solaris Print Manager
Это связано с тем, что при подключении сетевых принтеров требуется определить их имена или имена хостов, к которым они подключены. Для подключения к таким принтерам с помощью Solaris Print Manager следует указать их IP-адреса в файле /etc/inet/hosts, в NIS или DNS.
На рис. 22.4 представлено главное меню Solaris Print Manager.

Рис. 22.4. Главное меню Solaris Print Manager
Программа предоставляет весьма скромный сервис, как видно из рис. 22.5 и рис. 22.6.

Рис. 22.5. Окно "добавить принтер" в Solaris Print Manager

Рис. 22.6. Окно "изменить свойства принтера" в Solaris Print Manager
Программные средства хранения с избыточностью
Для экономии средств вы можете отказаться от приобретения аппаратуры RAID. Solaris предоставляет возможность организовать полноценный RAID-массив программно, с использованием нескольких жестких дисков и программы Solstice Disksuite. Эта программа дает возможность выполнять зеркалирование (RAID уровня 1), также как и расслоение с избыточностью (запись блоков данных и блоков четности на разные диски - RAID уровня 5).
В Solaris, начиная с версии 8, Disksuite включен в состав системы. Ранее его надо было устанавливать как отдельный пакет. Этот пакет - не единственный, позволяющий реализовать программный RAID в Solaris, но он пользуется популярностью у администраторов Solaris.
Solstice Disksuite был переименован в Solaris Volume Manager при переходе от Solaris 8 к Solaris 9 и стал еще более тесно интегрирован в систему. Вызвать графическую оболочку Solaris Volume Manager можно из Solaris Management Console. Самостоятельно она не вызывается.
Для создания зеркала или программного массива RAID 5 используйте команду metainit. Для проверки - metastat.
Подробное описание работы с SVM можно найти, например, по адресу http://sysunconfig.net/unixtips/soft-partitions.html.
Кроме SVM есть еще широко известный продукт Veritas Volume Manager (от компании Veritas Software), c ним можно познакомиться по адресу http://www.intuit.ru/department/os/adminsolaris/13/www.veritas.com.
Программы для запросов к серверам имен
Чтобы получить информацию о чужом домене или проверить настройки собственного сервера имен, можно использовать несколько утилит, опрашивающих серверы DNS .
Прежде всего, это программа nslookup. Проверим наши настройки:
nslookup Default Server: localhost Address: 127.0.0.1 > set typ=soa > klava.net. Server: localhost Address: 127.0.0.1 klava.net: kir.spb.ru origin = gate.co.spb.ru mail addr = milu.co.spb.ru serial = 2001012301 refresh = 21600 (6H) retry = 3600 (1H) expire = 864000 (1w3d) minimum ttl = 3600 (1H) kir.spb.ru nameserver = gate.co.spb.ru kir.spb.ru nameserver = imc.example.ru gate.co.spb.ru internet address = 192.168.5.19 imc.example.ru internet address = 193.114.38.33 imc.example.ru internet address = 193.114.38.65 imc.example.ru internet address = 195.70.192.166
А вот так можно получить всю информацию о конкретной зоне или компьютере:
> set typ=any > www.rbc.ru Server: localhost Address: 127.0.0.1 Non-authoritative answer: www.rbc.ru internet address = 62.118.249.16 www.rbc.ru internet address = 62.118.249.66 www.rbc.ru internet address = 194.186.36.138 www.rbc.ru internet address = 194.186.36.175 www.rbc.ru preference = 10, mail exchanger = mail.rbc.ru www.rbc.ru preference = 20, mail exchanger = relay.rbc.ru www.rbc.ru preference = 30, mail exchanger = relay2.rbc.ru Authoritative answers can be found from: rbc.ru nameserver = ns2.rbc.ru rbc.ru nameserver = ns3.rbc.ru mail.rbc.ru internet address = 80.68.240.91 relay.rbc.ru internet address = 80.68.240.103 relay2.rbc.ru internet address = 194.186.36.142 ns2.rbc.ru internet address = 62.118.249.100 ns3.rbc.ru internet address = 194.186.36.186
Выход из программы nslookup - "Ctrl-D".
С программой host работать еще проще, но она не входит в стандартную поставку Solaris, поэтому привыкшим к ней администраторам Linux и FreeBSD следует использовать dig:
dig @localhost klava.net ; <<>> DiG 8.3 <<>> @localhost klava.net ; (1 server found) ;; res options: init recurs defnam dnsrch ;; got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 6 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0 ;; QUERY SECTION: ;; klava.net, type = A, class = IN ;; AUTHORITY SECTION: klava.net. 1H IN SOA sunny.eu.spb.ru.
hostmaster.sunny.eu.spb.ru. ( 2004060101 ; serial 1H ; refresh 20M ; retry 5w6d16h ; expiry 1H ) ; minimum ;; Total query time: 1 msec ;; FROM: sunny to SERVER: localhost 127.0.0.1 ;; WHEN: Tue Jun 1 12:58:55 2004 ;; MSG SIZE sent: 27 rcvd: 89
dig yandex.ru ; <<>> DiG 8.3 <<>> yandex.ru ;; res options: init recurs defnam dnsrch ;; got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 4 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 4, ADDITIONAL: 4 ;; QUERY SECTION: ;; yandex.ru, type = A, class = IN ;; ANSWER SECTION: yandex.ru. 1h58m12s IN A 213.180.216.200 ;; AUTHORITY SECTION: yandex.ru. 23h3m57s IN NS ns2.yandex.ru. yandex.ru. 23h3m57s IN NS ns3.yandex.ru. yandex.ru. 23h3m57s IN NS ns.ispm.ru. yandex.ru. 23h3m57s IN NS ns1.yandex.ru. ;; ADDITIONAL SECTION: ns2.yandex.ru. 23h30m16s IN A 213.180.199.34 ns3.yandex.ru. 23h30m16s IN A 213.180.193.2 ns.ispm.ru. 15h4m39s IN A 80.244.228.2 ns1.yandex.ru. 23h30m16s IN A 213.180.193.1 ;; Total query time: 8 msec ;; FROM: sunny to SERVER: default -- 192.168.5.18 ;; WHEN: Tue Jun 1 17:34:51 2004 ;; MSG SIZE sent: 27 rcvd: 185
Для получения информации о домене , ответственной за него организации и его регистрационных данных служит программа whois:
whois -h whois.ripn.net rambler.ru % By submitting a query to RIPN's Whois Service % you agree to abide by the following terms of use: % http://www.ripn.net/about/servpol.html#3.2 (in Russian) % http://www.ripn.net/about/en/servpol.html#3.2 (in English). domain: RAMBLER.RU type: CORPORATE nserver: ns.park.rambler.ru. 81.19.67.2 nserver: ns.rambler.ru. 81.19.66.49 state: REGISTERED, DELEGATED org: Rambler Internet Holdings, LLC phone: +7 095 7453619 fax-no: +7 095 7453619 e-mail: dns@rambler-co.ru e-mail: denis@rambler-co.ru registrar: RUCENTER-REG-RIPN created: 1996.09.26 paid-till: 2004.08.01 source: RIPN Last updated on 2004.06.01 17:46:29 MSK/MSD whois -h whois.ripe.net PT30-RIPE % This is the RIPE Whois server. % The objects are in RPSL format. % % Rights restricted by copyright. % See http://www.ripe.net/ripencc/pub-services/db/copyright.html person: Philip I Torchinsky address: Institute of Macromolecular Compounds address: Bolshoi pr., 31 address: St.Petersburg 199004 address: Russia phone: +7 812 218 56 01 fax-no: +7 812 218 68 69 e-mail: filip@macro.lgu.spb.su e-mail: root@filip.stud.pu.ru nic-hdl: PT30-RIPE changed: filip@macro.lgu.spb.su 19960125 source: RIP
Как видим, программа whois может помочь узнать не только информацию о зарегистрировавшей домен организации, но и о персоне, отвечающей за тот или иной домен .
Если программы whois нет под рукой или соединения с портом 43 запрещены фильтром пакетов, можно воспользоваться "чужой" программой whois через доступный всем web-интерфейс (например, http://www.intuit.ru/department/os/adminsolaris/5/www.internic.net/whois.html или http://www.intuit.ru/department/os/adminsolaris/5/www.ripn.net/nic/whois/index.html).
 |
|
|
1) Тут уж ничего не поделаешь! Действительно, доменная система имен больше всего похожа на систему имен в файловой системе, а на генеалогическое древо, например, не похожа.
НАЗАД ВПЕРЕД
|
Производительность сети
Производительность сети в большей степени зависит от используемого сетевого оборудования, чем от настроек системы. Фактически, некоторую оптимизацию может дать изменение параметра MTU (maximum transmission unit) с помощью ifconfig, если трафик через сеть однороден и можно точно определить превалирующие размеры пакетов.
Однако с помощью ряда инструметов можно оценить, как идут дела в сети.
Используйте
netstat -i
для получения статистики по интерфейсам системы:
netstat -i Name Mtu Net/Dest Address Ipkts Ierrs Opkts Oerrs Collis Queue lo0 8232 loopback localhost 21456 0 21456 0 0 0 elxl0 1500 sunny sunny 12728 0 2331 0 0 0
Протокол DHCP
Протокол DHCP (dynamic host configuration protocol) используется для динамического назначения параметров настройки подсистемы IP в любых операционных системах. Этот протокол организован по принципу клиент-сервер: клиент запрашивает информацию, делая широковещательный запрос в сеть, а сервер сообщает ее клиенту в ответ. Серверы DHCP используются для динамического назначения IP-адресов, а также для сообщения клиентам DHCP такой настроечной информации, как маска сети, адрес сервера имен и т.д. Обязательно назначается только адрес и маска, все остальное может быть назначено в зависимости от настроек сервера и клиента DHCP.
Протокол динамической настройки параметров системы имеет смысл использовать в сетях, где мы имеем дело с большим количеством компьютеров. Если у вас всего три компьютера, проще дать им фиксированные IP-адреса, чем заниматься настройкой DHCP. Дело в том, что DHCP имеет неоспоримые плюсы и столь же неоспоримые минусы:
| Не надо настраивать каждый компьютер в отдельности, системы Windows по умолчанию настраиваются как клиенты DHCP, при установке систем UNIX указать, что они - клиенты DHCP тоже очень просто | Если сервер DHCP не доступен, многие из компьютеров сети вообще не смогут начать работу, и через определенное время, связанное с политикой назначения адресов, вес компьютеры окажутся "отрезанными" от сети |
| Все настройки делаются централизованно, при изменении одной настройки (например, адреса основного шлюза сети), нет нужды менять настройки на каждом компьютере | Сбои DHCP труднее диагностировать, т.к. они проявляются в виде жалоб пользователей (причем не одновременных), на невозможность войти в сеть, а это может быть вызвано дюжинами причин |
| Можно забыть о настройке параметров сети всех компьютеров, кроме DHCP-сервера, навсегда о них позаботиться сервер DHCP | Использование DHCP усложняет учет событий в сети: ведь в файлы протоколов заносятся IP-адреса компьютеров. Там, где адреса компьютерам выдаются динамически, один и тот же адрес может принадлежать разным компьютерам в разное время |
Зная это, мы можем решать, будем ли мы экономить свое рабочее время (ставим DHCP) или же будем бояться сбоев и руками настраивать компьютеры. Конечно, мелкая сеть (несколько компьютеров) легко проживет и без DHCP, но как только количество компьютеров превысит семь штук, возникнет явная необходимость в динамической настройке.
Что касается сложности учета событий, то учет можно вести и по MAC-адресам сетевых карт. Это требует работы с командой arp и знания, в каких компьютерах какие сетевые адаптеры (в смысле - с какими именно MAC-адресами) установлены. Думаете, это легко? Вспомните, когда вас последний раз интересовал MAC-адрес чьей-нибудь машины? Если в последнюю неделю хоть один из них попался вам на глаза, то вы - везунчик. Расскажите об этом подруге, она будет удивлена, что кому-то интересны эти дурацкие адреса.
Основное внимание в настройке DHCP-сервера следует уделить диапазону адресов, из которого они будут назначаться клиентам DHCP (адресов должно хватить всем!), и доступности DHCP-сервера (этот компьютер не должен оказаться выключенным тогда, когда клиент хочет получить IP-адрес).