7.4 ОЖИДАНИЕ ЗАВЕРШЕНИЯ ВЫПОЛНЕНИЯ ПРОЦЕССА
7.4 ОЖИДАНИЕ ЗАВЕРШЕНИЯ ВЫПОЛНЕНИЯ ПРОЦЕССА
Процесс может синхронизировать продолжение своего выполнения с моментом завершения потомка, если воспользуется системной функцией wait. Синтаксис вызова функции:
pid = wait(stat_addr);где pid - значение кода идентификации (PID) прекратившего свое существование потомка, stat_addr - адрес переменной целого типа, в которую будет помещено возвращаемое функцией exit значение, в пространстве задачи.
7.5 ВЫЗОВ ДРУГИХ ПРОГРАММ
7.5 ВЫЗОВ ДРУГИХ ПРОГРАММ
Системная функция exec дает возможность процессу запускать другую программу, при этом соответствующий этой программе исполняемый файл будет располагаться в пространстве памяти процесса. Содержимое пользовательского контекста после вызова функции становится недоступным, за исключением передаваемых функции параметров, которые переписываются ядром из старого адресного пространства в новое. Синтаксис вызова функции:
execve(filename,argv,envp)где filename - имя исполняемого файла, argv - указатель на массив параметров, которые передаются вызываемой программе, а envp - указатель на массив параметров, составляющих среду выполнения вызываемой программы. Вызов системной функции exec осуществляют несколько библиотечных функций, таких как execl, execv, execle и т.д. В том случае, когда программа использует параметры командной строки
main(argc,argv) ,массив argv является копией одноименного параметра, передаваемого функции exec. Символьные строки, описывающие среду выполнения вызываемой программы, имеют вид "имя=значение" и содержат полезную для программ информацию, такую как начальный каталог пользователя и путь поиска исполняемых программ. Процессы могут обращаться к параметрам описания среды выполнения, используя глобальную переменную environ, которую заводит начальная процедура Си-интерпретатора.
7.6 КОД ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ ПРОЦЕССА
7.6 КОД ИДЕНТИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ ПРОЦЕССА
Ядро связывает с процессом два кода идентификации пользователя, не зависящих от кода идентификации процесса: реальный (действительный) код идентификации пользователя и исполнительный код или setuid (от "set user ID" - установить код идентификации пользователя, под которым процесс будет исполняться). Реальный код идентифицирует пользователя, несущего ответственность за выполняющийся процесс. Исполнительный код используется для установки прав собственности на вновь создаваемые файлы, для проверки прав доступа к файлу и разрешения на посылку сигналов процессам через функцию kill. Процессы могут изменять исполнительный код, запуская с помощью функции exec программу setuid или запуская функцию setuid в явном виде.
Программа setuid представляет собой исполняемый файл, имеющий в поле режима доступа установленный бит setuid. Когда процесс запускает программу setuid на выполнение, ядро записывает в поля, содержащие реальные коды идентификации, в таблице процессов и в пространстве процесса код идентификации владельца файла. Чтобы как-то различать эти поля, назовем одно из них, которое хранится в таблице процессов, сохраненным кодом идентификации пользователя. Рассмотрим пример, иллюстрирующий разницу в содержимом этих полей.
Синтаксис вызова системной функции setuid:
setuid(uid)где uid - новый код идентификации пользователя. Результат выполнения функции зависит от текущего значения реального кода идентификации. Если реальный код идентификации пользователя процесса, вызывающего функцию, указывает на суперпользователя, ядро записывает значение uid в поля, хранящие реальный и исполнительный коды идентификации, в таблице процессов и в пространстве процесса. Если это не так, ядро записывает uid в качестве значения исполнительного кода идентификации в пространстве процесса и то только в том случае, если значение uid равно значению реального кода или значению сохраненного кода. В противном случае функция возвращает вызывающему процессу ошибку. Процесс наследует реальный и исполнительный коды идентификации у своего родителя (в результате выполнения функции fork) и сохраняет их значения после вызова функции exec.
На Рисунке 7.25 приведена программа, демонстрирующая использование функции setuid. Предположим, что исполняемый файл, полученный в результате трансляции исходного текста программы, имеет владельца с именем "maury" (код идентификации 8319) и установленный бит setuid; право его исполнения предоставлено всем пользователям. Допустим также, что пользователи "mjb" (код идентификации 5088) и "maury" являются владельцами файлов с теми же именами, каждый из которых доступен только для чтения и только своему владельцу. Во время исполнения программы пользователю "mjb" выводится следующая информация:
uid 5088 euid 8319 fdmjb -1 fdmaury 3 after setuid(5088): uid 5088 euid 5088 fdmjb 4 fdmaury -1 after setuid(8319): uid 5088 euid 8319Системные функции getuid и geteuid возвращают значения реального и исполнительного кодов идентификации пользователей процесса, для пользователя "mjb" это, соответственно, 5088 и 8319. Поэтому процесс не может открыть файл "mjb" (ибо он имеет исполнительный код идентификации пользователя (8319), не разрешающий производить чтение файла), но может открыть файл "maury". После вызова функции setuid, в результате выполнения которой в поле исполнительного кода идентификации пользователя ("mjb") заносится значение реального кода идентификации, на печать выводятся значения и того, и другого кода идентификации пользователя "mjb": оба равны 5088. Теперь процесс может открыть файл "mjb", поскольку он исполняется под кодом идентификации пользователя, имеющего право на чтение из файла, но не может открыть файл "maury". Наконец, после занесения в поле исполнительного кода идентификации значения, сохраненного функцией setuid (8319), на печать снова выводятся значения 5088 и 8319. Мы показали, таким образом, как с помощью программы setuid процесс может изменять значение кода идентификации пользователя, под которым он исполняется.
7.7 ИЗМЕНЕНИЕ РАЗМЕРА ПРОЦЕССА
7.7 ИЗМЕНЕНИЕ РАЗМЕРА ПРОЦЕССА
С помощью системной функции brk процесс может увеличивать и уменьшать размер области данных. Синтаксис вызова функции:
brk(endds);где endds - старший виртуальный адрес области данных процесса (адрес верхней границы). С другой стороны, пользователь может обратиться к функции следующим образом:
oldendds = sbrk(increment);где oldendds - текущий адрес верхней границы области, increment - число байт, на которое изменяется значение oldendds в результате выполнения функции. Sbrk - это имя стандартной библиотечной подпрограммы на Си, вызывающей функцию brk. Если размер области данных процесса в результате выполнения функции увеличивается, вновь выделяемое пространство имеет виртуальные адреса, смежные с адресами увеличиваемой области; таким образом, виртуальное адресное пространство процесса расширяется. При этом ядро проверяет, не превышает ли новый размер процесса максимально-допустимое значение, принятое для него в системе, а также не накладывается ли новая область данных процесса на виртуальное адресное пространство, отведенное ранее для других целей (Рисунок 7.26). Если все в порядке, ядро запускает алгоритм growreg, присоединяя к области данных внешнюю память (например, таблицы страниц) и увеличивая значение поля, описывающего размер процесса. В системе с замещением страниц ядро также отводит под новую область пространство основной памяти и обнуляет его содержимое; если свободной памяти нет, ядро освобождает память путем выгрузки процесса (более подробно об этом мы поговорим в главе 9). Если с помощью функции brk процесс уменьшает размер области данных, ядро освобождает часть ранее выделенного адресного пространства; когда процесс попытается обратиться к данным по виртуальным адресам, принадлежащим освобожденному пространству, он столкнется с ошибкой адресации.
7.8 КОМАНДНЫЙ ПРОЦЕССОР SHELL
7.8 КОМАНДНЫЙ ПРОЦЕССОР SHELL
Теперь у нас есть достаточно материала, чтобы перейти к объяснению принципов работы командного процессора shell. Сам командный процессор намного сложнее, чем то, что мы о нем здесь будем излагать, однако взаимодействие процессов мы уже можем рассмотреть на примере реальной программы. На Рисунке 7.28 приведен фрагмент основного цикла программы shell, демонстрирующий асинхронное выполнение процессов, переназначение вывода и использование каналов.
Shell считывает командную строку из файла стандартного ввода и интерпретирует ее в соответствии с установленным набором правил. Дескрипторы файлов стандартного ввода и стандартного вывода, используемые регистрационным shell'ом, как правило, указывают на терминал, с которого пользователь регистрируется в системе (см. главу 10). Если shell узнает во введенной строке конструкцию собственного командного языка (например, одну из команд cd, for, while и т.п.), он исполняет команду своими силами, не прибегая к созданию новых процессов; в противном случае команда интерпретируется как имя исполняемого файла.
Командные строки простейшего вида содержат имя программы и несколько параметров, например:
who grep -n include *.c ls -lShell "ветвится" (fork) и порождает новый процесс, который и запускает программу, указанную пользователем в командной строке. Родительский процесс (shell) дожидается завершения потомка и повторяет цикл считывания следующей команды.
7.9 ЗАГРУЗКА СИСТЕМЫ И НАЧАЛЬНЫЙ ПРОЦЕСС
7.9 ЗАГРУЗКА СИСТЕМЫ И НАЧАЛЬНЫЙ ПРОЦЕСС
Для того, чтобы перевести систему из неактивное состояние в активное, администратор выполняет процедуру "начальной загрузки". На разных машинах эта процедура имеет свои особенности, однако во всех случаях она реализует одну и ту же цель: загрузить копию операционной системы в основную память машины и запустить ее на исполнение. Обычно процедура начальной загрузки включает в себя несколько этапов. Переключением клавиш на пульте машины администратор может указать адрес специальной программы аппаратной загрузки, а может, нажав только одну клавишу, дать команду машине запустить процедуру загрузки, исполненную в виде микропрограммы. Эта программа может состоять из нескольких команд, подготавливающих запуск другой программы. В системе UNIX процедура начальной загрузки заканчивается считыванием с диска в память блока начальной загрузки (нулевого блока). Программа, содержащаяся в этом блоке, загружает из файловой системы ядро ОС (например, из файла с именем "/unix" или с другим именем, указанным администратором). После загрузки ядра системы в память управление передается по стартовому адресу ядра и ядро запускается на выполнение (алгоритм start, Рисунок 7.30).
Ядро инициализирует свои внутренние структуры данных. Среди прочих структур ядро создает связные списки свободных буферов и индексов, хеш-очереди для буферов и индексов, инициализирует структуры областей, точки входа в таблицы страниц и т.д. По окончании этой фазы ядро монтирует корневую файловую систему и формирует среду выполнения нулевого процесса, среди всего прочего создавая пространство процесса, инициализируя нулевую точку входа в таблице процесса и делая корневой каталог текущим для процесса.
Когда формирование среды выполнения процесса заканчивается, система исполняется уже в виде нулевого процесса. Нулевой процесс "ветвится", запуская алгоритм fork прямо из ядра, поскольку сам процесс исполняется в режиме ядра. Порожденный нулевым новый процесс, процесс 1, запускается в том же режиме и создает свой пользовательский контекст, формируя область данных и присоединяя ее к своему адресному пространству. Он увеличивает размер области до надлежащей величины и переписывает программу загрузки из адресного пространства ядра в новую область: эта программа теперь будет определять контекст процесса 1. Затем процесс 1 сохраняет регистровый контекст задачи, "возвращается" из режима ядра в режим задачи и исполняет только что переписанную программу. В отличие от нулевого процесса, который является процессом системного уровня, выполняющимся в режиме ядра, процесс 1 относится к пользовательскому уровню. Код, исполняемый процессом 1, включает в себя вызов системной функции exec, запускающей на выполнение программу из файла "/etc/init". Обычно процесс 1 именуется процессом init, поскольку он отвечает за инициализацию новых процессов.
7.10 ВЫВОДЫ
7.10 ВЫВОДЫ
В данной главе были рассмотрены системные функции, предназначенные для работы с контекстом процесса и для управления выполнением процесса. Системная функция fork создает новый процесс, копируя для него содержимое всех областей, подключенных к родительскому процессу. Особенность реализации функции fork состоит в том, что она выполняет инициализацию сохраненного регистрового контекста порожденного процесса, таким образом этот процесс начинает выполняться, не дожидаясь завершения функции, и уже в теле функции начинает осознавать свою предназначение как потомка. Все процессы завершают свое выполнение вызовом функции exit, которая отсоединяет области процесса и посылает его родителю сигнал "гибель потомка". Процесс-родитель может совместить момент продолжения своего выполнения с моментом завершения процесса-потомка, используя системную функцию wait. Системная функция exec дает процессу возможность запускать на выполнение другие программы, накладывая содержимое исполняемого файла на свое адресное пространство. Ядро отсоединяет области, ранее занимаемые процессом, и назначает процессу новые области в соответствии с потребностями исполняемого файла. Совместное использование областей команд и наличие режима "sticky-bit" дают возможность более рационально использовать память и экономить время, затрачиваемое на подготовку к запуску программ. Простым пользователям предоставляется возможность получать привилегии других пользователей, даже суперпользователя, благодаря обращению к услугам системной функции setuid и setuid-программ. С помощью функции brk процесс может изменять размер своей области данных. Функция signal дает процессам возможность управлять своей реакцией на поступающие сигналы. При получении сигнала производится обращение к специальной функции обработки сигнала с внесением соответствующих изменений в стек задачи и в сохраненный регистровый контекст задачи. Процессы могут сами посылать сигналы, используя системную функцию kill, они могут также контролировать получение сигналов, предназначенных группе процессов, прибегая к услугам функции setpgrp.
Командный процессор shell и процесс начальной загрузки init используют стандартные обращения к системным функциям, производя набор операций, в других системах обычно выполняемых ядром. Shell интерпретирует команды пользователя, переназначает стандартные файлы ввода-вывода данных и выдачи ошибок, порождает процессы, организует каналы между порожденными процессами, синхронизирует свое выполнение с этими процессами и формирует коды, возвращаемые командами. Процесс init тоже порождает различные процессы, в частности, управляющие работой пользователя за терминалом. Когда такой процесс завершается, init может породить для выполнения той же самой функции еще один процесс, если это вытекает из информации файла "/etc/inittab".
7.11 УПРАЖНЕНИЯ
7.11 УПРАЖНЕНИЯ
1. Запустите с терминала программу, приведенную на Рисунке 7.33. Переадресуйте стандартный вывод данных в файл и сравните результаты между собой.
8.1.1 Алгоритм
8.1.1 Алгоритм
Сразу после переключения контекста ядро запускает алгоритм планирования выполнения процессов (Рисунок 8.1), выбирая на выполнение процесс с наивысшим приоритетом среди процессов, находящихся в состояниях "резервирования" и "готовности к выполнению, будучи загруженным в память". Рассматривать процессы, не загруженные в память, не имеет смысла, поскольку не будучи загружен, процесс не может выполняться. Если наивысший приоритет имеют сразу несколько процессов, ядро, используя принцип кольцевого списка (карусели), выбирает среди них тот процесс, который находится в состоянии "готовности к выполнению" дольше остальных. Если ни один из процессов не может быть выбран для выполнения, ЦП простаивает до момента получения следующего прерывания, которое произойдет не позже чем через один таймерный тик; после обработки этого прерывания ядро снова запустит алгоритм планирования.
8.1.2 Параметры диспетчеризации
8.1.2 Параметры диспетчеризации
В каждой записи таблицы процессов есть поле приоритета, используемое планировщиком процессов. Приоритет процесса в режиме задачи зависит от того, как этот процесс перед этим использовал ресурсы ЦП. Можно выделить два класса приоритетов процесса (Рисунок 8.2): приоритеты выполнения в режиме ядра и приоритеты выполнения в режиме задачи. Каждый класс включает в себя ряд значений, с каждым значением логически ассоциирована некоторая очередь процессов. Приоритеты выполнения в режиме задачи оцениваются для процессов, выгруженных по возвращении из режима ядра в режим задачи, приоритеты выполнения в режиме ядра имеют смысл только в контексте алгоритма sleep. Приоритеты выполнения в режиме задачи имеют верхнее пороговое значение, приоритеты выполнения в режиме ядра имеют нижнее пороговое значение. Среди приоритетов выполнения в режиме ядра далее можно выделить высокие и низкие приоритеты: процессы с низким приоритетом возобновляются по получении сигнала, а процессы с высоким приоритетом продолжают оставаться в состоянии приостанова (см. раздел 7.2.1).
Пороговое значение между приоритетами выполнения в режимах ядра и задачи на Рисунке 8.2 отмечено двойной линией, проходящей между приоритетом ожидания завершения потомка (в режиме ядра) и нулевым приоритетом выполнения в режиме задачи. Приоритеты процесса подкачки, ожидания ввода-вывода, связанного с диском, ожидания буфера и индекса являются высокими, не допускающими прерывания системными приоритетами, с каждым из которых связана очередь из 1, 3, 2 и 1 процесса, соответственно, в то время как приоритеты ожидания ввода с терминала, вывода на терминал и завершения потомка являются низкими, допускающими прерывания системными приоритетами, с каждым из которых связана очередь из 4, 0 и 2 процессов, соответственно. На рисунке представлены также уровни приоритетов выполнения в режиме задачи (*).
Ядро вычисляет приоритет процесса в следующих случаях:
Непосредственно перед переходом процесса в состояние приостанова ядро назначает ему приоритет исходя из причины приостанова. Приоритет не зависит от динамических характеристик процесса (продолжительности ввода-вывода или времени счета), напротив, это постоянная величина, жестко устанавливаемая в момент приостанова и зависящая только от причины перехода процесса в данное состояние. Процессы, приостановленные алгоритмами низкого уровня, имеют тенденцию порождать тем больше узких мест в системе, чем дольше они находятся в этом состоянии; поэтому им назначается более высокий приоритет по сравнению с остальными процессами. Например, процесс, приостановленный в ожидании завершения ввода-вывода, связанного с диском, имеет более высокий приоритет по сравнению с процессом, ожидающим освобождения буфера, по нескольким причинам. Прежде всего, у первого процесса уже есть буфер, поэтому не исключена возможность, что когда он возобновится, он успеет освободить и буфер, и другие ресурсы. Чем больше ресурсов свободно, тем меньше шансов для возникновения взаимной блокировки процессов. Системе не придется часто переключать контекст, благодаря чему сократится время реакции процесса и увеличится производительность системы. Во-вторых, буфер, освобождения которого ожидает процесс, может быть занят процессом, ожидающим в свою очередь завершения ввода-вывода. По завершении ввода-вывода будут возобновлены оба процесса, поскольку они были приостановлены по одному и тому же адресу. Если первым запустить на выполнение процесс, ожидающий освобождения буфера, он в любом случае снова приостановится до тех пор, пока буфер не будет освобожден; следовательно, его приоритет должен быть ниже. По возвращении процесса из режима ядра в режим задачи ядро вновь вычисляет приоритет процесса. Процесс мог до этого находиться в состоянии приостанова, изменив свой приоритет на приоритет выполнения в режиме ядра, поэтому при переходе процесса из режима ядра в режим задачи ему должен быть возвращен приоритет выполнения в режиме задачи. Кроме того, ядро "штрафует" выполняющийся процесс в пользу остальных процессов, отбирая используемые им ценные системные ресурсы. Приоритеты всех процессов в режиме задачи с интервалом в 1 секунду (в версии V) пересчитывает программа обработки прерываний по таймеру, побуждая тем самым ядро выполнять алгоритм планирования, чтобы не допустить монопольного использования ресурсов ЦП одним процессом.8.1.3 Примеры диспетчеризации процессов
8.1.3 Примеры диспетчеризации процессов
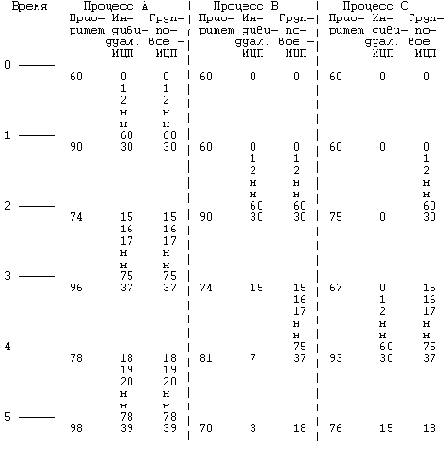
На Рисунке 8.4 показана динамика изменений приоритетов процессов A, B и C в версии V при следующих допущениях: все эти процессы были созданы с первоначальным приоритетом 60, который является наивысшим приоритетом выполнения в режиме задачи, прерывания по таймеру поступают 60 раз в секунду, процессы не используют вызов системных функций, в системе нет других процессов, готовых к выполнению. Ядро вычисляет полураспад показателя ИЦП по формуле:
ИЦП = decay(ИЦП) = ИЦП/2;а приоритет процесса по формуле:
приоритет = (ИЦП/2) + 60;Если предположить, что первым запускается процесс A и ему выделяется квант времени, он выполняется в течение 1 секунды: за это время таймер посылает системе 60 прерываний и столько же раз программа обработки прерываний увеличивает для процесса A значение поля, содержащего показатель ИЦП (с 0 до 60). По прошествии секунды ядро переключает контекст и, произведя пересчет приоритетов для всех процессов, выбирает для выполнения процесс B. В течение следующей секунды программа обработки прерываний по таймеру 60 раз повышает значение поля ИЦП для процесса B, после чего ядро пересчитывает параметры диспетчеризации для всех процессов и вновь переключает контекст. Процедура повторяется многократно, сопровождаясь поочередным запуском процессов на выполнение.
8.1.4 Управление приоритетами
8.1.4 Управление приоритетами
Процессы могут управлять своими приоритетами с помощью системной функции nice:
nice(value);где value - значение, в процессе пересчета прибавляемое к приоритету процесса:
приоритет = (ИЦП/константа) + (базовый приоритет) + (значение nice)Системная функция nice увеличивает или уменьшает значение поля nice в таблице процессов на величину параметра функции, при этом только суперпользователю дозволено указывать значения, увеличивающие приоритет процесса. Кроме того, только суперпользователь может указывать значения, лежащие ниже определенного порога. Пользователи, вызывающие системную функцию nice для того, чтобы понизить приоритет во время выполнения интенсивных вычислительных работ, "удобны, приятны" (nice) для остальных пользователей системы, отсюда название функции. Процессы наследуют значение nice у своего родителя при выполнении системной функции fork. Функция nice действует только для выполняющихся процессов; процесс не может сбросить значение nice у другого процесса. С практической точки зрения это означает, что если администратору системы понадобилось понизить приоритеты различных процессов, требующих для своего выполнения слишком много времени, у него не будет другого способа сделать это быстро, кроме как вызвать функцию удаления (kill) для всех них сразу.

8.1.5 Планирование на основе справедливого раздела
8.1.5 Планирование на основе справедливого раздела
Вышеописанный алгоритм планирования не видит никакой разницы между пользователями различных классов (категорий). Другими словами, невозможно выделить определенной совокупности процессов, например, половину сеанса работы с ЦП. Тем не менее, такая возможность имеет важное значение для организации работы в условиях вычислительного центра, где группа пользователей может пожелать купить только половину машинного времени на гарантированной основе и с гарантированным уровнем реакции. Здесь мы рассмотрим схему, именуемую "Планированием на основе справедливого раздела" (Fair Share Scheduler) и реализованную на вычислительном центре Indian Hill фирмы AT&T Bell Laboratories [Henry 84].
Принцип "планирования на основе справедливого раздела" состоит в делении совокупности пользователей на группы, являющиеся объектами ограничений, накладываемых обычным планировщиком на обработку процессов из каждой группы. При этом система выделяет время ЦП пропорционально числу групп, вне зависимости от того, сколько процессов выполняется в группе. Пусть, например, в системе имеются четыре планируемые группы, каждая из которых загружает ЦП на 25% и содержит, соответственно, 1, 2, 3 и 4 процесса, реализующих счетные задачи, которые никогда по своей воле не уступят ЦП. При условии, что в системе больше нет никаких других процессов, каждый процесс при использовании традиционного алгоритма планирования получил бы 10% времени ЦП (поскольку всего процессов 10 и между ними не делается никаких различий). При использовании алгоритма планирования на основе справедливого раздела процесс из первой группы получит в два раза больше времени ЦП по сравнению с каждым процессом из второй группы, в 3 раза больше по сравнению с каждым процессом из третьей группы и в 4 раза больше по сравнению с каждым процессом из четвертой. В этом примере всем процессам в группе выделяется равное время, поскольку продолжительность цикла, реализуемого каждым процессом, заранее не установлена.
Реализация этой схемы довольно проста, что и делает ее привлекательной. В формуле расчета приоритета процесса появляется еще один термин - "приоритет группы справедливого раздела". В пространстве процесса также появляется новое поле, описывающее продолжительность ИЦП на основе справедливого раздела, общую для всех процессов из группы. Программа обработки прерываний по таймеру увеличивает значение этого поля для текущего процесса и ежесекундно пересчитывает значения соответствующих полей для всех процессов в системе. Новая компонента формулы вычисления приоритета процесса представляет собой нормализованное значение ИЦП для каждой группы. Чем больше процессорного времени выделяется процессам группы, тем выше значение этого показателя и ниже приоритет.
В качестве примера рассмотрим две группы процессов (Рисунок 8.6), в одной из которых один процесс (A), в другой - два (B и C). Предположим, что ядро первым запустило на выполнение процесс A, в течение секунды увеличивая соответствующие этому процессу значения полей, описывающих индивидуальное и групповое ИЦП. В результате пересчета приоритетов по истечении секунды процессы B и C будут иметь наивысшие приоритеты. Допустим, что ядро выбирает на выполнение процесс B. В течение следующей секунды значение поля ИЦП для процесса B поднимается до 60, точно такое же значение принимает поле группового ИЦП для процессов B и C. Таким образом, по истечении второй секунды процесс C получит приоритет, равный 75 (сравните с Рисунком 8.4), и ядро запустит на выполнение процесс A с приоритетом 74. Дальнейшие действия можно проследить на рисунке: ядро по очереди запускает процессы A, B, A, C, A, B и т.д.
8.1.6 Работа в режиме реального времени
8.1.6 Работа в режиме реального времени
Режим реального времени подразумевает возможность обеспечения достаточной скорости реакции на внешние прерывания и выполнения отдельных процессов в темпе, соизмеримом с частотой возникновения вызывающих прерывания событий. Примером системы, работающей в режиме реального времени, может служить система управления жизнеобеспечением пациентов больниц, мгновенно реагирующая на изменение состояния пациента. Процессы, подобные текстовым редакторам, не считаются процессами реального времени: в них быстрая реакция на действия пользователя является желательной, но не необходимой (ничего страшного не произойдет, если пользователь, выполняющий редактирование текста, подождет ответа несколько лишних секунд, хотя у пользователя на этот счет могут быть и свои соображения). Вышеописанные алгоритмы планирования выполнения процессов предназначены специально для использования в системах разделения времени и не годятся для условий работы в режиме реального времени, поскольку не гарантируют запуск ядром каждого процесса в течение фиксированного интервала времени, позволяющего говорить о взаимодействии вычислительной системы с процессами в темпе, соизмеримом со скоростью протекания этих процессов. Другой помехой в поддержке работы в режиме реального времени является невыгружаемость ядра; ядро не может планировать выполнение процесса реального времени в режиме задачи, если оно уже исполняет другой процесс в режиме ядра, без внесения в работу существенных изменений. В настоящее время системным программистам приходится переводить процессы реального времени в режим ядра, чтобы обеспечить достаточную скорость реакции. Правильное решение этой проблемы - дать таким процессам возможность динамического протекания (другими словами, они не должны быть встроены в ядро) с предоставлением соответствующего механизма, с помощью которого они могли бы сообщать ядру о своих нуждах, вытекающих из особенностей работы в режиме реального времени. На сегодняшний день в стандартной системе UNIX такая возможность отсутствует.
8.1 ПЛАНИРОВАНИЕ ВЫПОЛНЕНИЯ ПРОЦЕССОВ
8.1 ПЛАНИРОВАНИЕ ВЫПОЛНЕНИЯ ПРОЦЕССОВ
Планировщик процессов в системе UNIX принадлежит к общему классу планировщиков, работающих по принципу "карусели с многоуровневой обратной связью". В соответствии с этим принципом ядро предоставляет процессу ресурсы ЦП на квант времени, по истечении которого выгружает этот процесс и возвращает его в одну из нескольких очередей, регулируемых приоритетами. Прежде чем процесс завершится, ему может потребоваться множество раз пройти через цикл с обратной связью. Когда ядро выполняет переключение контекста и восстанавливает контекст процесса, процесс возобновляет выполнение с точки приостанова.
8.2 СИСТЕМНЫЕ ОПЕРАЦИИ, СВЯЗАННЫЕ СО ВРЕМЕНЕМ
8.2 СИСТЕМНЫЕ ОПЕРАЦИИ, СВЯЗАННЫЕ СО ВРЕМЕНЕМ
Существует несколько системных функций, имеющих отношение к времени протекания процесса: stime, time, times и alarm. Первые две имеют дело с глобальным системным временем, последние две - с временем выполнения отдельных процессов.
Функция stime дает суперпользователю возможность заносить в глобальную переменную значение глобальной переменной. Выбирается время из этой переменной с помощью функции time:
time(tloc);где tloc - указатель на переменную, принадлежащую процессу, в которую заносится возвращаемое функцией значение. Функция возвращает это значение и из самой себя, например, команде date, которая вызывает эту функцию, чтобы определить текущее время.
Функция times возвращает суммарное время выполнения процесса и всех его потомков, прекративших существование, в режимах ядра и задачи. Синтаксис вызова функции:
times(tbuffer) struct tms *tbuffer;где tms - имя структуры, в которую помещаются возвращаемые значения и которая описывается следующим образом:
struct tms { /* time_t - имя структуры данных, в которой хранится время */ time_t tms_utime; /* время выполнения процесса в режиме задачи */ time_t tms_stime; /* время выполнения процесса в режиме ядра */ time_t tms_cutime; /* время выполнения потомков в режиме задачи */ time_t tms_cstime; /* время выполнения потомков в режиме ядра */ };Функция times возвращает время, прошедшее "с некоторого произвольного момента в прошлом", как правило, с момента загрузки системы.
8.3.1 Перезапуск часов
8.3.1 Перезапуск часов
В большинстве машин после получения прерывания по таймеру требуется программными средствами произвести перезапуск часов, чтобы они по прошествии интервала времени могли вновь прерывать работу процессора. Такие средства являются машинно-зависимыми и мы их рассматривать не будем.
8.3.2 Внутренние системные тайм-ауты
8.3.2 Внутренние системные тайм-ауты
Некоторым из процедур ядра, в частности драйверам устройств и сетевым протоколам, требуется вызов функций ядра в режиме реального времени. Например, процесс может перевести терминал в режим ввода без обработки символов, при котором ядро выполняет запросы пользователя на чтение с терминала через фиксированные промежутки времени, не дожидаясь, когда пользователь нажмет клавишу "возврата каретки" (см. раздел 10.3.3). Ядро хранит всю необходимую информацию в таблице ответных сигналов (Рисунок 8.9), в том числе имя функции, запускаемой по истечении интервала времени, параметр, передаваемый этой функции, а также продолжительность интервала (в таймерных тиках) до момента запуска функции.
Пользователь не имеет возможности напрямую контролировать записи в таблице ответных сигналов; для работы с ними существуют различные системные алгоритмы. Ядро сортирует записи в этой таблице в соответствии с величиной интервала до момента запуска функций. В связи с этим для каждой записи таблицы запоминается не общая продолжительность интервала, а только промежуток времени между моментами запуска данной и предыдущей функций. Общая продолжительность интервала до момента запуска функции складывается из промежутков времени между моментами запуска всех функций, начиная с первой и вплоть до текущей.

8.3.3 Построение профиля
8.3.3 Построение профиля
Построение профиля ядра включает в себя измерение продолжительности выполнения системы в режиме задачи против режима ядра, а также продолжительности выполнения отдельных процедур ядра. Драйвер параметров ядра следит за относительной эффективностью работы модулей ядра, замеряя параметры работы системы в момент прерывания по таймеру. Драйвер параметров имеет список адресов ядра (главным образом, функций ядра); эти адреса ранее были загружены процессом путем обращения к драйверу параметров. Если построение профиля ядра возможно, программа обработки прерывания по таймеру запускает подпрограмму обработки прерываний, принадлежащую драйверу параметров, которая определяет, в каком из режимов - ядра или задачи - работал процессор в момент прерывания. Если процессор работал в режиме задачи, система построения профиля увеличивает значение параметра, описывающего продолжительность выполнения в режиме задачи, если же процессор работал в режиме ядра, система увеличивает значение внутреннего счетчика, соответствующего счетчику команд. Пользовательские процессы могут обращаться к драйверу параметров, чтобы получить значения параметров ядра и различную статистическую информацию.
8.3.4 Учет и статистика
8.3.4 Учет и статистика
В момент поступления прерывания по таймеру система может выполняться в режиме ядра или задачи, а также находиться в состоянии простоя (бездействия). Состояние простоя означает, что все процессы приостановлены в ожидании наступления события. Для каждого состояния процессора ядро имеет внутренние счетчики, устанавливаемые при каждом прерывании по таймеру. Позже пользовательские процессы могут проанализировать накопленную ядром статистическую информацию.
В пространстве каждого процесса имеются два поля для записи продолжительности времени, проведенного процессом в режиме ядра и задачи. В ходе обработки прерываний по таймеру ядро корректирует значение поля, соответствующего текущему режиму выполнения процесса. Процессы-родители собирают статистику о своих потомках при выполнении функции wait, беря за основу информацию, поступающую от завершающих свое выполнение потомков.
В пространстве каждого процесса имеется также одно поле для ведения учета использования памяти. В ходе обработки прерывания по таймеру ядро вычисляет общий объем памяти, занимаемый текущим процессом, исходя из размера частных областей процесса и его долевого участия в использовании разделяемых областей памяти. Если, например, процесс использует области данных и стека размером 25 и 40 Кбайт, соответственно, и разделяет с четырьмя другими процессами одну область команд размером 50 Кбайт, ядро назначает процессу 75 Кбайт памяти (50К/5 + 25К + 40К). В системе с замещением страниц ядро вычисляет объем используемой памяти путем подсчета числа используемых в каждой области страниц. Таким образом, если прерываемый процесс имеет две частные области и еще одну область разделяет с другим процессом, ядро назначает ему столько страниц памяти, сколько содержится в этих частных областях, плюс половину страниц, принадлежащих разделяемой области. Вся указанная информация отражается в учетной записи при завершении процесса и может быть использована для расчетов с заказчиками машинного времени.
8.3.5 Поддержание времени в системе
8.3.5 Поддержание времени в системе
Ядро увеличивает показание системных часов при каждом прерывании по таймеру, измеряя время в таймерных тиках от момента загрузки системы. Это значение возвращается процессу через системную функцию time и дает возможность определять общее время выполнения процесса. Время первоначального запуска процесса сохраняется ядром в адресном пространстве процесса при исполнении системной функции fork, в момент завершения процесса это значение вычитается из текущего времени, результат вычитания и составляет реальное время выполнения процесса. В другой переменной таймера, устанавливаемой с помощью системной функции stime и корректируемой раз в секунду, хранится календарное время.
8.3 ТАЙМЕР
8.3 ТАЙМЕР
В функции программы обработки прерываний по таймеру входит:
перезапуск часов, вызов на исполнение функций ядра, использующих встроенные часы, поддержка возможности профилирования выполнения процессов в режимах ядра и задачи; сбор статистики о системе и протекающих в ней процессах, слежение за временем, посылка процессам сигналов "будильника" по запросу, периодическое возобновление процесса подкачки (см. следующую главу), управление диспетчеризацией процессов.Некоторые из функций реализуются при каждом прерывании по таймеру, другие - по прошествии нескольких таймерных тиков. Программа обработки прерываний по таймеру запускается с высоким приоритетом обращения к процессору, не допуская во время работы возникновения других внешних событий (таких как прерывания от периферийных устройств). Поэтому программа обработки прерываний по таймеру работает очень быстро, за максимально-короткое время пробегая свои критические отрезки, которые должны выполняться без прерываний со стороны других процессов. Алгоритм обработки прерываний по таймеру приведен на Рисунке 8.9.
8.4 ВЫВОДЫ
8.4 ВЫВОДЫ
В настоящей главе был описан основной алгоритм диспетчеризации процессов в системе UNIX. С каждым процессом в системе связывается приоритет планирования, значение которого появляется в момент перехода процесса в состояние приостанова и периодически корректируется программой обработки прерываний по таймеру. Приоритет, присваиваемый процессу в момент перехода в состояние приостанова, имеет значение, зависящее от того, какой из алгоритмов ядра исполнялся процессом в этот момент. Значение приоритета, присваиваемое процессу во время выполнения программой обработки прерываний по таймеру (или в тот момент, когда процесс возвращается из режима ядра в режим задачи), зависит от того, сколько времени процесс занимал ЦП: процесс получает низкий приоритет, если он обращался к ЦП, и высокий - в противном случае. Системная функция nice дает процессу возможность влиять на собственный приоритет путем добавления параметра, участвующего в пересчете приоритета. В главе были также рассмотрены системные функции, связанные с временем выполнения системы и протекающих в ней процессов: с установкой и получением системного времени, получением времени выполнения процессов и установкой сигналов "будильника". Кроме того, описаны функции программы обработки прерываний по таймеру, которая следит за временем в системе, управляет таблицей ответных сигналов, собирает статистику, а также подготавливает запуск планировщика процессов, программы подкачки и "сборщика" страниц. Программа подкачки и "сборщик" страниц являются объектами рассмотрения в следующей главе.
8.5 УПРАЖНЕНИЯ
8.5 УПРАЖНЕНИЯ
При переводе процессов в состояние приостанова ядро назначает процессу, ожидающему снятия блокировки с индекса, более высокий приоритет по сравнению с процессом, ожидающим освобождения буфера. Точно так же, процессы, ожидающие ввода с терминала, получают более высокий приоритет по сравнению с процессами, ожидающими возможности производить вывод на терминал. Объясните причины такого поведения ядра. * В алгоритме обработки прерываний по таймеру предусмотрен пересчет приоритетов и перезапуск процессов на выполнение с интервалом в 1 секунду. Придумайте алгоритм, в котором интервал перезапуска динамически меняется в зависимости от степени загрузки системы. Перевесит ли выигрыш усилия по усложнению алгоритма? В шестой редакции системы UNIX для расчета продолжительности ИЦП текущим процессом используется следующая формула: decay(ИЦП) = max (пороговый приоритет, ИЦП-10);
а в седьмой редакции:
decay(ИЦП) = .8 * ИЦП;
Приоритет процесса в обеих редакциях вычисляется по формуле:
Повторите пример на Рисунке 8.4, используя приведенные формулы.
Напишите на языке Си программу, реализующую команду nice.
указав аргумент, например: date mmddhhmmyy
(супер)пользователь может установить текущую дату в системе (соответственно, месяц, число, часы, минуты и год). Так,
устанавливает в качестве текущего времени 11 сентября 1984 года 8:50 пополудни.
с помощью которой выполнение программы приостанавливается на указанное число секунд. Разработайте ее алгоритм, в котором используйте системные функции alarm и pause. Что произойдет, если процесс вызовет функцию alarm раньше функции sleep? Рассмотрите две возможности: 1) действие ранее вызванной функции alarm истекает в то время, когда процесс находится в состоянии приостанова, 2) действие ранее вызванной функции alarm истекает после завершения функции sleep.
9.1.1 Управление пространством на устройстве выгрузки
9.1.1 Управление пространством на устройстве выгрузки
Устройство выгрузки является устройством блочного типа, которое представляет собой конфигурируемый раздел диска. Тогда как обычно ядро выделяет место для файлов по одному блоку за одну операцию, на устройстве выгрузки пространство выделяется группами смежных блоков. Пространство, выделяемое для файлов, используется статическим образом; поскольку схема назначения пространства под файлы действует в течение длительного периода времени, ее гибкость понимается в смысле сокращения числа случаев фрагментации и, следовательно, объемов неиспользуемого пространства в файловой системе. Выделение пространства на устройстве выгрузки, напротив, является временным, в сильной степени зависящим от механизма диспетчеризации процессов. Процесс, размещаемый на устройстве выгрузки, в конечном итоге вернется в основную память, освобождая место на внешнем устройстве. Поскольку время является решающим фактором и с учетом того, что ввод-вывод данных за одну мультиблочную операцию происходит быстрее, чем за несколько одноблочных операций, ядро выделяет на устройстве выгрузки непрерывное пространство, не беря во внимание возможную фрагментацию.
Так как схема выделения пространства на устройстве выгрузки отличается от схемы, используемой для файловых систем, структуры данных, регистрирующие свободное пространство, должны также отличаться. Пространство, свободное в файловых системах, описывается с помощью связного списка свободных блоков, доступ к которому осуществляется через суперблок файловой системы, информация о свободном пространстве на устройстве выгрузки собирается в таблицу, именуемую "карта памяти устройства". Карты памяти, помимо устройства выгрузки, используются и другими системными ресурсами (например, драйверами некоторых устройств), они дают возможность распределять память устройства (в виде смежных блоков) по методу первого подходящего.
Каждая строка в карте памяти состоит из адреса распределяемого ресурса и количества доступных единиц ресурса; ядро интерпретирует элементы строки в соответствии с типом карты. В самом начале карта памяти состоит из одной строки, содержащей адрес и общее количество ресурсов. Если карта описывает распределение памяти на устройстве выгрузки, ядро трактует каждую единицу ресурса как группу дисковых блоков, а адрес - как смещение в блоках от начала области выгрузки. Первоначальный вид карты памяти для устройства выгрузки, состоящего из 10000 блоков с начальным адресом, равным 1, показан на Рисунке 9.1. Выделяя и освобождая ресурсы, ядро корректирует карту памяти, заботясь о том, чтобы в ней постоянно содержалась точная информация о свободных ресурсах в системе.
На Рисунке 9.2 представлен алгоритм выделения пространства с помощью карт памяти (malloc). Ядро просматривает карту в поисках первой строки, содержащей количество единиц ресурса, достаточное для удовлетворения запроса. Если запрос покрывает все количество единиц, содержащееся в строке, ядро удаляет строку и уплотняет карту (то есть в карте становится на одну строку меньше). В противном случае ядро переустанавливает адрес и число оставшихся единиц в строке в соответствии с числом единиц, выделенных по запросу. На Рисунке 9.3 показано, как меняется вид карты памяти для устройства выгрузки после выделения 100, 50 и вновь 100 единиц ресурса. В конечном итоге карта памяти принимает вид, показывающий, что первые 250 единиц ресурса выделены по запросам, и что теперь остались свободными 9750 единиц, начиная с адреса 251.
9.1.2 Выгрузка процессов
9.1.2 Выгрузка процессов
Ядро выгружает процесс, если испытывает потребность в свободной памяти, которая может возникнуть в следующих случаях:
Произведено обращение к системной функции fork, которая должна выделить место в памяти для процесса-потомка. Произведено обращение к системной функции brk, увеличивающей размер процесса. Размер процесса увеличился в результате естественного увеличения стека процесса. Ядру нужно освободить в памяти место для подкачки ранее выгруженных процессов.Обращение к системной функции fork выделено в особую ситуацию, поскольку это единственный случай, когда пространство памяти, ранее занятое процессом (родителем), не освобождается.
Когда ядро принимает решение о том, что процесс будет выгружен из основной памяти, оно уменьшает значение счетчика ссылок, ассоциированного с каждой областью процесса, и выгружает те области, у которых счетчик ссылок стал равным 0. Ядро выделяет место на устройстве выгрузки и блокирует процесс в памяти (в случаях 1-3), запрещая его выгрузку (см. упражнение 9.12) до тех пор, пока не закончится текущая операция выгрузки. Адрес места выгрузки областей ядро сохраняет в соответствующих записях таблицы областей.
За одну операцию ввода-вывода, в которой участвуют устройство выгрузки и адресное пространство задачи и которая осуществляется через буферный кеш, ядро выгружает максимально-возможное количество данных. Если аппаратура не в состоянии передать за одну операцию содержимое нескольких страниц памяти, перед программами ядра встает задача осуществить передачу содержимого памяти за несколько шагов по одной странице за каждую операцию. Таким образом, точная скорость и механизм передачи данных определяются, помимо всего прочего, возможностями дискового контроллера и стратегией распределения памяти. Например, если используется страничная организация памяти, существует вероятность, что выгружаемые данные занимают несмежные участки физической памяти. Ядро обязано собирать информацию об адресах страниц с выгружаемыми данными, которую впоследствии использует дисковый драйвер, осуществляющий управление процессом ввода-вывода. Перед тем, как выгрузить следующую порцию данных, программа подкачки (выгрузки) ждет завершения предыдущей операции ввода-вывода.
При этом перед ядром не встает задача переписать на устройство выгрузки содержимое виртуального адресного пространства процесса полностью. Вместо этого ядро копирует на устройство выгрузки содержимое физической памяти, отведенной процессу, игнорируя неиспользуемые виртуальные адреса. Когда ядро подкачивает процесс обратно в память, оно имеет у себя карту виртуальных адресов процесса и может переназначить процессу новые адреса. Ядро считывает копию процесса из буферного кеша в физическую память, в те ячейки, для которых установлено соответствие с виртуальными адресами процесса.
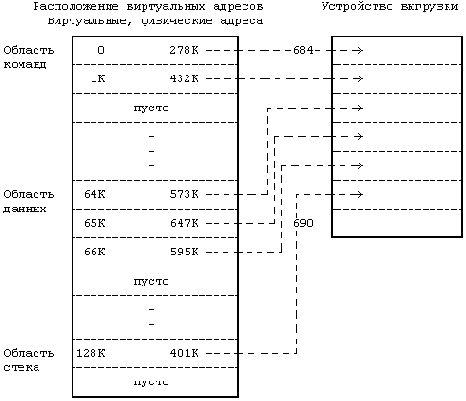
На Рисунке 9.6 приведен пример отображения образа процесса в памяти на адресное пространство устройства выгрузки (*). Процесс располагает тремя областями: команд, данных и стека. Область команд заканчивается на виртуальном адресе 2К, а область данных начинается с адреса 64К, таким образом в виртуальном адресном пространстве образовался пропуск в 62 Кбайта. Когда ядро выгружает процесс, оно выгружает содержимое страниц памяти с адресами 0, 1К, 64К, 65К, 66К и 128К; на устройстве выгрузки не будет отведено место под пропуск в 62 Кбайта между областями команд и данных, как и под пропуск в 61 Кбайт между областями данных и стека, ибо пространство на устройстве выгрузки заполняется непрерывно. Когда ядро загружает процесс обратно в память, оно уже знает из карты памяти процесса о том, что процесс имеет в своем пространстве неиспользуемый участок размером 62К, и с учетом этого соответственно выделяет физическую память. Этот случай проиллюстрирован с помощью Рисунка 9.7. Сравнение Рисунков 9.6 и 9.7 показывает, что физические адреса, занимаемые процессом до и после выгрузки, не совпадают между собой; однако, на пользовательском уровне процесс не обращает на это никакого внимания, поскольку содержимое его виртуального пространства осталось тем же самым.
Теоретически все пространство памяти, занятое процессом, в том числе его личное адресное пространство и стек ядра, может быть выгружено, хотя ядро и может временно заблокировать область в памяти на время выполнения критической операции. Однако практически, ядро не выгружает содержимое адресного пространства процесса, если в нем находятся таблицы преобразования адресов (адресные таблицы) процесса. Практическими соображениями так же диктуются условия, при которых процесс может выгрузить самого себя или потребовать своей выгрузки другим процессом (см. упражнение 9.4).
9.1.3 Загрузка (подкачка) процессов
9.1.3 Загрузка (подкачка) процессов
Нулевой процесс (процесс подкачки) является единственным процессом, загружающим другие процессы в память с устройств выгрузки. Процесс подкачки начинает работу по выполнению этой своей единственной функции по окончании инициализации системы (как уже говорилось в разделе 7.9). Он загружает процессы в память и, если ему не хватает места в памяти, выгружает оттуда некоторые из процессов, находящихся там. Если у процесса подкачки нет работы (например, отсутствуют процессы, ожидающие загрузки в память) или же он не в состоянии выполнить свою работу (ни один из процессов не может быть выгружен), процесс подкачки приостанавливается; ядро периодически возобновляет его выполнение. Ядро планирует запуск процесса подкачки точно так же, как делает это в отношении других процессов, ориентируясь на более высокий приоритет, при этом процесс подкачки выполняется только в режиме ядра. Процесс подкачки не обращается к функциям операционной системы, а использует в своей работе только внутренние функции ядра; он является архетипом всех процессов ядра.
Как уже вкратце говорилось в главе 8, программа обработки прерываний по таймеру измеряет время нахождения каждого процесса в памяти или в состоянии выгрузки. Когда процесс подкачки возобновляет свою работу по загрузке процессов в память, он просматривает все процессы, находящиеся в состоянии "готовности к выполнению, будучи выгруженными", и выбирает из них один, который находится в этом состоянии дольше остальных (см. Рисунок 9.9). Если имеется достаточно свободной памяти, процесс подкачки загружает выбранный процесс, выполняя операции в последовательности, обратной выгрузке процесса. Сначала выделяется физическая память, затем с устройства выгрузки считывается нужный процесс и освобождается место на устройстве.
Если процесс подкачки выполнил процедуру загрузки успешно, он вновь просматривает совокупность выгруженных, но готовых к выполнению процессов в поисках следующего процесса, который предполагается загрузить в память, и повторяет указанную последовательность действий. В конечном итоге возникает одна из следующих ситуаций:
На устройстве выгрузки больше нет ни одного процесса, готового к выполнению. Процесс подкачки приостанавливает свою работу до тех пор, пока не возобновится процесс на устройстве выгрузки или пока ядро не выгрузит процесс, готовый к выполнению. (Вспомним диаграмму состояний на Рисунке 6.1). Процесс подкачки обнаружил процесс, готовый к загрузке, но в системе недостаточно памяти для его размещения. Процесс подкачки пытается загрузить другой процесс и в случае успеха перезапускает алгоритм подкачки, продолжая поиск загружаемых процессов.Если процессу подкачки нужно выгрузить процесс, он просматривает все процессы в памяти. Прекратившие свое существование процессы не подходят для выгрузки, поскольку они не занимают физическую память; также не могут быть выгружены процессы, заблокированные в памяти, например, выполняющие операции над областями. Ядро предпочитает выгружать приостановленные процессы, поскольку процессы, готовые к выполнению, имеют больше шансов быть вскоре выбранными на выполнение. Решение о выгрузке процесса принимается ядром на основании его приоритета и продолжительности его пребывания в памяти. Если в памяти нет ни одного приостановленного процесса, решение о том, какой из процессов, готовых к выполнению, следует выгрузить, зависит от значения, присвоенного процессу функцией nice, а также от продолжительности пребывания процесса в памяти.
Процесс, готовый к выполнению, должен быть резидентным в памяти в течение по меньшей мере 2 секунд до того, как уйти из нее, а процесс, загружаемый в память, должен по меньшей мере 2 секунды пробыть на устройстве выгрузки. Если процесс подкачки не может найти ни одного процесса, подходящего для выгрузки, или ни одного процесса, подходящего для загрузки, или ни одного процесса, перед выгрузкой не менее 2 секунд (**) находившегося в памяти, он приостанавливает свою работу по причине того, что ему нужно загрузить процесс в память, а в памяти нет места для его размещения. В этой ситуации таймер возобновляет выполнение процесса подкачки через каждую секунду. Ядро также возобновляет работу процесса подкачки в том случае, когда один из процессов переходит в состояние приостанова, так как последний может оказаться более подходящим для выгрузки процессом по сравнению с ранее рассмотренными. Если процесс подкачки расчистил место в памяти или если он был приостановлен по причине невозможности сделать это, он возобновляет свою работу с перезапуска алгоритма подкачки (с самого его начала), вновь предпринимая попытку загрузить ожидающие выполнения процессы.
9.1 СВОПИНГ
9.1 СВОПИНГ
Описание алгоритма свопинга можно разбить на три части: управление пространством на устройстве выгрузки, выгрузка процессов из основной памяти и подкачка процессов в основную память.
9.2.1 Структуры данных, используемые
9.2.1 Структуры данных, используемые подсистемой замещения страниц
Для поддержки функций управления памятью на машинном (низком) уровне и для реализации механизма замещения страниц ядро использует 4 основные структуры данных: записи таблицы страниц, дескрипторы дисковых блоков, таблицу содержимого страничных блоков (page frame data table - сокращенно: pfdata) и таблицу использования области подкачки. Место для таблицы pfdata выделяется один раз на все время жизни системы, для других же структур страницы памяти выделяются динамически.
Из главы 6 нам известно, что каждая область располагает своими таблицами страниц, с помощью которых осуществляется доступ к физической памяти. Каждая запись таблицы страниц (Рисунок 9.13) состоит из физического адреса страницы, кода защиты, в разрядах которого описываются права доступа процесса к странице (на чтение, запись и исполнение), а также следующих двоичных полей, используемых механизмом замещения страниц:
бит доступности бит упоминания бит модификации бит копирования при записи "возраст" страницыУстановка бита доступности свидетельствует о правильности содержимого страницы памяти, однако из того, что бит доступности выключен, не следует с необходимостью то, что ссылка на страницу недопустима, в чем мы убедимся позже. Бит упоминания устанавливается в том случае, если процесс делает ссылку на страницу, а бит модификации - в том случае, если процесс скорректировал содержимое страницы. Установка бита копирования при записи, производимая во время выполнения системной функции fork, свидетельствует о том, что ядру в случае, когда процесс корректирует содержимое страницы, следует создавать ее новую копию. Наконец, "возраст" страницы говорит о продолжительности ее пребывания в составе рабочего множества процесса. Биты доступности, копирования при записи и "возраст" страницы устанавливаются ядром, биты упоминания и модификации - аппаратным путем; в разделе 9.2.4 рассматриваются конфигурации, в которых эти возможности не поддерживаются аппаратурой.

9.2.2 "Сборщик" страниц
9.2.2 "Сборщик" страниц
"Сборщик" страниц (page stealer) является процессом, принадлежащим ядру операционной системы и выполняющим выгрузку из памяти тех страниц, которые больше не входят в состав рабочего множества пользовательского процесса. Этот процесс создается ядром во время инициализации системы и запускается в любой момент, когда в нем возникает необходимость. Он просматривает все активные незаблокированные области и увеличивает значение "возраста" каждой принадлежащей им страницы (заблокированные области пропускаются, но впоследствии, по снятии блокировки, тоже будут учтены). Когда процесс при работе со страницей, принадлежащей области, получает ошибку, ядро блокирует область, чтобы "сборщик" не смог выгрузить страницу до тех пор, пока ошибка не будет обработана.
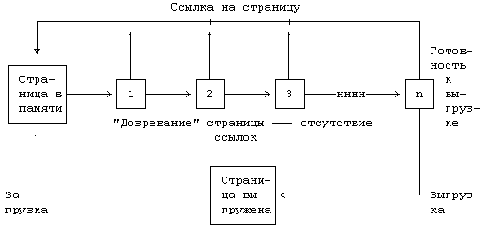
Страница в памяти может находиться в двух состояниях: либо "дозревать", не будучи еще готовой к выгрузке, либо быть готовой к выгрузке и доступной для привязки к другим виртуальным страницам. Первое состояние означает, что процесс обратился к странице и поэтому страница включена в его рабочее множество. При обращении к странице в некоторых машинах аппаратно устанавливается бит упоминания, если же эта операция не выполняется, соответственно, и программные методы скорее всего используются другие (раздел 9.2.4). Если страница находится в первом состоянии, "сборщик" сбрасывает бит упоминания в ноль, но запоминает количество просмотров множества страниц, выполненных с момента последнего обращения к странице со стороны пользовательского процесса. Таким образом, первое состояние распадается на несколько подсостояний в соответствии с тем, сколько раз "сборщик" страниц обратился к странице до того, как страница стала готовой для выгрузки (см. Рисунок 9.18). Когда это число превышает некоторое пороговое значение, ядро переводит страницу во второе состояние - состояние готовности к выгрузке. Максимальная продолжительность пребывания страницы в первом состоянии зависит от условий конкретной реализации и ограничивается числом отведенных для этого поля разрядов в записи таблицы страниц.
На Рисунке 9.19 показано взаимодействие между процессами, работающими со страницей, и "сборщиком" страниц. Цифры обозначают номер обращения "сборщика" к странице с того момента, как страница была загружена в память. Процесс, обратившийся к странице после второго просмотра страниц "сборщиком", сбросил ее "возраст" в 0. После каждого просмотра пользовательский процесс обращался к странице вновь, но в конце концов "сборщик" страниц осуществил три просмотра страницы с момента последнего обращения к ней со стороны пользовательского процесса и выгрузил ее из памяти.
9.2.3 Отказы при обращениях к страницам
9.2.3 Отказы при обращениях к страницам
В системе встречаются два типа отказов при обращении к странице: отказы из-за отсутствия (недоступности) данных и отказы системы защиты. Поскольку программы обработки прерываний по отказу могут приостанавливать свое выполнение на время считывания страницы с диска в память, эти программы являются исключением из общего правила, утверждающего невозможность приостанова обработчиков прерываний. Тем не менее, поскольку программа обработки прерываний по отказу приостанавливается в контексте процесса, породившего фатальную ошибку памяти, отказ относится к текущему процессу; следовательно, процессы приостанавливаются не произвольным образом.
9.2.3.1 Обработка прерываний по отказу из-за недоступности данных
Если процесс пытается обратиться к странице, бит доступности для которой не установлен, он получает отказ из-за отсутствия (недоступности) данных и ядро запускает программу обработки прерываний по отказу данного типа (Рисунок 9.21). Бит доступности не устанавливается ни для тех страниц, которые располагаются за пределами виртуального адресного пространства процесса, ни для тех, которые входят в состав этого пространства, но не имеют в настоящий момент физического аналога в памяти. Фатальная ошибка памяти произошла в результате обращения ядра по виртуальному адресу страницы, поэтому ядро выходит на соответствующую этой странице запись в таблице страниц и дескриптор дискового блока. Чтобы предотвратить взаимную блокировку, которая может произойти, если "сборщик" попытается выгрузить страницу из памяти, ядро фиксирует в памяти область с соответствующей записью таблицы страниц. Если в дескрипторе дискового блока отсутствует информация о странице, сделанная ссылка на страницу является недопустимой и ядро посылает процессу-нарушителю сигнал о "нарушении сегментации" (см. Рисунок 7.25). Такой порядок действий совпадает с тем порядком, которого придерживается ядро, когда процесс обратился по неверному адресу, если не принимать во внимание то обстоятельство, что ядро узнает об ошибке немедленно, так как все "доступные" страницы являются резидентными в памяти. Если ссылка на страницу сделана правильно, ядро выделяет физическую страницу в памяти и считывает в нее содержимое виртуальной страницы с устройства выгрузки или из исполняемого файла.
Страница, вызвавшая отказ, находится в одном из пяти состояний:
На устройстве выгрузки вне памяти. В списке свободных страниц в памяти. В исполняемом файле. С пометкой "обнуляемая при обращении". С пометкой "заполняемая при обращении".Рассмотрим каждый случай в подробностях.
Если страница находится на устройстве выгрузки, вне памяти (случай 1), это означает, что она когда-то располагалась в памяти, но была выгружена оттуда "сборщиком" страниц. Обратившись к дескриптору дискового блока, ядро узнает из него номера устройства выгрузки и блока, где расположена страница, и проверяет, не осталась ли страница в кэше. Ядро корректирует запись таблицы страниц так, чтобы она указывала на страницу, которую предполагается считать в память, включает соответствующую запись таблицы pfdata в хеш-очередь (облегчая последующую обработку отказа) и считывает страницу с устройства выгрузки. Допустивший ошибку процесс приостанавливается до момента завершения ввода-вывода; вместе с ним будут возобновлены все процессы, ожидавшие загрузки содержимого страницы.
Обратимся к Рисунку 9.22 и в качестве примера рассмотрим запись таблицы страниц, связанную с виртуальным адресом 66К. Если при обращении к странице процесс получает отказ из-за недоступности данных, программа обработки отказа обращается к дескриптору дискового блока и обнаруживает то, что страница находится на устройстве выгрузки в блоке с номером 847 (если предположить, что в системе только одно устройство выгрузки): следовательно, виртуальный адрес указан верно. Затем программа обработки отказа обращается к кэшу, но не находит информации о дисковом блоке с номером 847. Таким образом, копия виртуальной страницы в памяти отсутствует и программа обработки отказа должна загрузить ее с устройства выгрузки. Ядро отводит физическую страницу с номером 1776 (Рисунок 9.23), считывает в нее с устройства выгрузки содержимое виртуальной страницы и перенастраивает запись таблицы страниц на страницу с номером 1776. В завершение ядро корректирует дескриптор дискового блока, делая указание о том, что страница загружена, а также запись таблицы pfdata, отмечая, что на устройстве выгрузки в блоке с номером 847 содержится дубликат виртуальной страницы.
9.2.4 Замещение страниц на менее сложной технической базе
9.2.4 Замещение страниц на менее сложной технической базе
Наибольшая действенность алгоритмов замещения страниц по запросу (обращению) достигается в том случае, если биты упоминания и модификации устанавливаются аппаратным путем и тем же путем вызывается отказ системы защиты при попытке записи в страницу, имеющую признак "копирования при записи". Тем не менее, указанные алгоритмы вполне применимы даже тогда, когда аппаратура распознает только бит доступности и код защиты. Если бит доступности, устанавливаемый аппаратно, дублируется программно-устанавливаемым битом, показывающим, действительно ли страница доступна или нет, ядро могло бы отключить аппаратно-устанавливаемый бит и проимитировать установку остальных битов программным путем. Так, например, в машине VAX-11 бит упоминания отсутствует (см. [Levy 82]). Ядро может отключить аппаратно-устанавливаемый бит доступности для страницы и дальше работать по следующему плану. Если процесс ссылается на страницу, он получает отказ, поскольку бит доступности сброшен, и в игру вступает программа обработки отказа, исследующая страницу. Поскольку "программный" бит доступности установлен, ядро знает, что страница действительно доступна и находится в памяти; оно устанавливает "программный" бит упоминания и "аппаратный" бит доступности, но ему еще предстоит узнать о том, что на страницу была сделана ссылка. Последующие ссылки на страницу уже не встретят отказ, ибо "аппаратный" бит доступности установлен. Когда с ней будет работать "сборщик" страниц, он вновь сбросит "аппаратный" бит доступности, вызывая тем самым от казы на все последующие обращения к странице и возвращая систему к началу цикла. Этот случай показан на Рисунке 9.28.
9.2 ПОДКАЧКА ПО ЗАПРОСУ
9.2 ПОДКАЧКА ПО ЗАПРОСУ
Алгоритм подкачки страниц памяти поддерживается на машинах со страничной организацией памяти и с ЦП, имеющим прерываемые команды (***). В системах с подкачкой страниц отсутствуют ограничения на размер процесса, связанные с объемом доступной физической памяти. Например, в машинах с объемом физической памяти 1 и 2 Мбайта могут исполняться процессы размером 4 или 5 Мбайт. Ограничение на виртуальный размер процесса, связанное с объемом адресуемой виртуальной памяти, остается в силе и здесь. Поскольку процесс может не поместиться в физической памяти, ядру приходится динамически загружать в память отдельные его части и исполнять их, несмотря на отсутствие остальных частей. В механизме подкачки страниц все открыто для пользовательских программ, за исключением разрешенного процессу виртуального размера.
Процессы стремятся исполнять команды небольшими порциями, которые именуются программными циклами или подпрограммами, используемые ими указатели группируются в небольшие поднаборы, располагаемые в информационном пространстве процесса. В этом состоит суть так называемого принципа "локальности". Деннингом [Denning 68] было сформулировано понятие рабочего множества процесса как совокупности страниц, использованных процессом в последних n ссылках на адресное пространство памяти; число n называется окном рабочего множества. Поскольку рабочее множество процесса является частью от целого, в основной памяти может поместиться больше процессов по сравнению с теми системами, где управление памятью базируется на подкачке процессов, что в конечном итоге приводит к увеличению производительности системы. Когда процесс обращается к странице, отсутствующей в его рабочем множестве, возникает ошибка, при обработке которой ядро корректирует рабочее множество процесса, в случае необходимости подкачивая страницы с внешнего устройства.
На Рисунке 9.12 приведена последовательность используемых процессом указателей страниц, описывающих рабочие множества с окнами различных размеров при условии соблюдения алгоритма замещения "стариков" (замещения страниц путем откачки тех, к которым наиболее долго не было обращений). По мере выполнения процесса его рабочее множество видоизменяется в соответствии с используемыми процессом указателями страниц; увеличение размера окна влечет за собой увеличение рабочего множества и, с другой стороны, сокращение числа ошибок в выполнении процесса. Использование неизменного рабочего множества не практикуется, поскольку запоминание очередности следования указателей страниц потребовало бы слишком больших затрат. Приблизительное соответствие между изменяемым рабочим множеством и пространством процесса достигается путем установки бита упоминания (reference bit) при обращении к странице памяти, а также периодическим опросом указателей страниц. Если на страницу была сделана ссылка, эта страница включается в рабочее множество; в противном случае она "дозревает" в памяти в ожидании своей очереди.
В случае возникновения ошибки из-за обращения к странице, отсутствующей в рабочем множестве, ядро приостанавливает выполнение процесса до тех пор, пока страница не будет считана в память и не станет доступной процессу. Когда страница будет загружена, процесс перезапустит ту команду, на которой выполнение процесса было приостановлено из-за ошибки. Таким образом, работа подсистемы замещения страниц распадается на две части: откачка редко используемых страниц на устройство выгрузки и обработка ошибок из-за отсутствия нужной страницы. Такое общее толкование механизма замещения страниц, конечно же, выходит за пределы одной конкретной системы. Оставшуюся часть главы мы посвятим более детальному рассмотрению особенностей реализации этого механизма в версии V системы UNIX.
9.3 СИСТЕМА СМЕШАННОГО ТИПА СО
9.3 СИСТЕМА СМЕШАННОГО ТИПА СО СВОПИНГОМ И ПОДКАЧКОЙ ПО ЗАПРОСУ
Несмотря на то, что в системах с замещением страниц по запросу обращение с памятью отличается большей гибкостью по сравнению с системами подкачки процессов, возможно возникновение ситуаций, в которых "сборщик" страниц и программа обработки отказов из-за недоступности данных начинают мешать друг другу из-за нехватки памяти. Если сумма рабочих множеств всех процессов превышает объем физической памяти в машине, программа обработки отказов обычно приостанавливается, поскольку выделять процессам страницы памяти дальше становится невозможным. "Сборщик" страниц не сможет достаточно быстро освободить место в памяти, ибо все страницы принадлежат рабочему множеству. Производительность системы падает, поскольку ядро тратит слишком много времени на верхнем уровне, с безумной скоростью перестраивая память.
Ядро в версии V манипулирует алгоритмами подкачки процессов и замещения страниц так, что проблемы соперничества перестают быть неизбежными. Когда ядро не может выделить процессу страницы памяти, оно возобновляет работу процесса подкачки и переводит пользовательский процесс в состояние, эквивалентное состоянию "готовности к запуску, будучи зарезервированным". В этом состоянии одновременно могут находиться несколько процессов. Процесс подкачки выгружает один за другим целые процессы, пока объем доступной памяти в системе не превысит верхнюю отметку. На каждый выгруженный процесс приходится один процесс, загруженный в память из состояния "готовности к выполнению, будучи зарезервированным". Ядро загружает эти процессы не с помощью обычного алгоритма подкачки, а путем обработки отказов при обращении к соответствующим страницам. На последующих итерациях процесса подкачки при условии наличия в системе достаточного объема свободной памяти будут обработаны отказы, полученные другими пользовательскими процессами. Применение такого метода ведет к снижению частоты возникновения системных отказов и устранению соперничества: по идеологии он близок к методам, используемым в операционной системе VAX/VMS ([Levy 82]).
9.4 ВЫВОДЫ
9.4 ВЫВОДЫ
Прочитанная глава была посвящена рассмотрению алгоритмов подкачки процессов и замещения страниц, используемых в версии V системы UNIX. Алгоритм подкачки процессов реализует перемещение процессов целиком между основной памятью и устройством выгрузки. Ядро выгружает процессы из памяти, если их размер поглощает всю свободную память в системе (в результате выполнения функций fork, exec и sbrk или в результате естественного увеличения стека), или в том случае, если требуется освободить память для загрузки процесса. Загрузку процессов выполняет специальный процесс подкачки (процесс 0), который запускается всякий раз, как на устройстве выгрузки появляются процессы, готовые к выполнению. Процесс подкачки не прекращает своей работы до тех пор, пока на устройстве выгрузки не останется ни одного такого процесса или пока в основной памяти не останется свободного места. В последнем случае процесс подкачки пытается выгрузить что-нибудь из основной памяти, но в его обязанности входит также слежение за соблюдением требования минимальной продолжительности пребывания выгружаемых процессов в памяти (в целях предотвращения холостой перекачки); по этой причине процесс подкачки не всегда достигает успеха в своей работе. Возобновление процесса подкачки в случае возникновения необходимости в нем производит с интервалом в одну секунду программа обработки прерываний по таймеру.
В системе с замещением страниц по запросу процессы могут исполняться, даже если их виртуальное адресное пространство загружено в память не полностью; поэтому виртуальный размер процесса может превышать объем доступной физической памяти в системе. Когда ядро испытывает потребность в свободных страницах, "сборщик" страниц просматривает все активные страницы в каждой области, помечая для выгрузки те из них, которые достаточно "созрели" для этого, и в конечном итоге откачивает их на устройство выгрузки. Когда процесс обращается к виртуальной странице, которая в настоящий момент выгружена из памяти, он получает отказ из-за недоступности данных. Ядро запускает программу обработки отказа, которая назначает области новую физическую страницу памяти и копирует в нее содержимое виртуальной страницы.
Повысить производительность системы при использовании алгоритма замещения страниц по запросу можно несколькими способами. Во-первых, если процесс вызывает функцию fork, ядро использует бит копирования при записи, тем самым в большинстве случаев снимая необходимость в физическом копировании страниц. Во-вторых, ядро может запросить содержимое страницы исполняемого файла прямо из файловой системы, устраняя потребность в вызове функции exec для незамедлительного считывания файла в память. Это способствует повышению производительности, поскольку не исключена возможность того, что подобные страницы так никогда и не потребуются процессу, и устраняет излишнюю холостую перекачку, имеющую место в том случае, если "сборщик" страниц выгружает эти страницы из памяти до того, как в них возникает потребность.
9.5 УПРАЖНЕНИЯ
9.5 УПРАЖНЕНИЯ
Набросайте схему реализации алгоритма mfree, который освобождает пространство памяти и возвращает его таблице свободного пространства. В разделе 9.1.2 утверждается, что система блокирует перемещаемый процесс, чтобы другие процессы не могли его трогать с места до момента окончания операции. Что произошло бы, если бы система не делала этого? Предположим, что в адресном пространстве процесса располагаются таблицы используемых процессом сегментов и страниц. Каким образом ядро может выгрузить это пространство из памяти? Если стек ядра находится внутри адресного пространства процесса, почему процесс не может выгружать себя сам? Какой на Ваш взгляд должна быть системная программа выгрузки процессов, как она должна запускаться? *Предположим, что ядро пытается выгрузить процесс, чтобы освободить место в памяти для других процессов, загружаемых с устройства выгрузки. Если ни на одном из устройств выгрузки для данного процесса нет места, процесс подкачки приостанавливает свою работу до тех пор, пока место не появится. Возможна ли ситуация, при которой все процессы, находящиеся в памяти, приостановлены, а все готовые к выполнению процессы находятся на устройстве выгрузки? Что нужно предпринять ядру для того, чтобы исправить это положение? Рассмотрите еще раз пример, приведенный на Рисунке 9.10, при условии, что в памяти есть место только для 1 процесса. Обратимся к примеру, приведенному на Рисунке 9.11. Составьте подобный пример, в котором процессу постоянно требуется для работы центральный процессор. Существует ли какой-нибудь способ снятия подобной напряженности?
| main() { f(); g(); } f() { vfork(); } g() { int blast[100],i; for (i = 0; i < 100; i++) blast[i] = i; } |
Рисунок 9.29
Что произойдет в результате выполнения программы, приведенной на Рисунке 9.29, в системе BSD 4.2? Каким будет стек процесса-родителя? Почему после выполнения функции fork процесса-потомка предпочтительнее запускать впереди процесса-родителя, если на разделяемых страницах биты копирования при записи установлены? Каким образом ядро может заставить потомка запуститься первым? *Алгоритм обработки отказа из-за недоступности данных, изложенный в тексте, загружает страницы поодиночке. Его эффективность можно повысить, если подготовить к загрузке помимо страницы, вызвавшей отказ, и все соседние с ней страницы. Переработайте исходный алгоритм с учетом указанной операции. В алгоритмах работы "сборщика" страниц и программы обработки отказов из-за недоступности данных предполагается, что размер страницы равен размеру дискового блока. Что нужно изменить в этих алгоритмах для того, чтобы они работали и в тех случаях, когда указанное равенство не соблюдается? *Когда процесс вызывает функцию fork (ветвится), значение счетчика ссылок на каждую разделяемую страницу (в таблице pfdata) увеличивается. Предположим, что "сборщик" страниц выгружает разделяемую страницу на устройство выгрузки, и один из процессов (скажем, родитель) впоследствии получает отказ при обращении к ней. Содержимое виртуальной страницы теперь располагается на физической странице. Объясните, почему процесс-потомок всегда имеет возможность получить верную копию страницы, даже после того, как процесс-родитель что-то запишет на нее. Почему, когда процесс-родитель ведет запись на страницу, он должен немедленно порвать связь с ее дисковой копией? Что следует предпринять программе обработки отказов в том случае, если в системе исчерпаны страницы памяти? *Составьте алгоритм выгрузки редко используемых компонент ядра. Какие из компонент нельзя выгружать и как их в таком случае следует обозначить? Придумайте алгоритм, отслеживающий выделение пространства на устройстве выгрузки, используя вместо карт памяти, описанных в настоящей главе, битовый массив. Сравните эффективность обоих методов. Предположим, что в машине нет аппаратно-устанавливаемого бита доступности, но есть код защиты, устанавливающий права доступа на чтение, запись и "исполнение" содержимого страницы. Смоделируйте работу с помощью программно-устанавливаемого бита доступности. В машине VAX-11 перед проверкой наличия отказов из-за недоступности данных выполняется аппаратная проверка наличия отказов системы защиты. Как это отражается на алгоритмах обработки отказов? Системная функция plock дает суперпользователю возможность устанавливать и снимать блокировку (в памяти) на областях команд и данных вызывающего процесса. Процесс подкачки и "сборщик" страниц не могут выгружать заблокированные страницы из памяти. Процессам, использующим эту системную функцию, не приходится дожидаться загрузки страниц, поэтому им гарантирован более быстрый ответ по сравнению с другими процессами. Следует ли иметь также возможность блокировки в памяти и области стека? Что произойдет в том случае, если суммарный объем заблокированных областей превысит размер доступной памяти в машине? Что делает программа, приведенная на Рисунке 9.30? Подумайте над альтернативной стратегией замещения страниц, в соответствии с которой в рабочее множество каждого процесса включается максимально-возможное число страниц.| struct fourmeg { int page[512]; /* пусть int занимает 4 байта */ } fourmeg[2048]; main() { for (;;) { switch(fork()) { case -1: /* процесс-родитель не может выполнить * fork --- слишком много потомков */ case 0: /* потомок */ func(); default: continue; } } } func() { int i; for (;;) { printf("процесс %d повторяет цикл\n",getpid()); for (i = 0; i < 2048; i++) fourmeg[i]290ge[0] = i; } } |
Рисунок 9.30
10.1.1 Конфигурация системы
10.1.1 Конфигурация системы
Задание конфигурации системы это процедура указания администраторами значений параметров, с помощью которых производится настройка системы. Некоторые из параметров указывают размеры таблиц ядра, таких как таблица процессов, таблица индексов и таблица файлов, а также сколько буферов помещается в буферном пуле. С помощью других параметров указывается конфигурация устройств, то есть производятся конкретные указания ядру, какие устройства включаются в данную системную реализацию и их "адрес". Например, в конфигурации может быть указано, что терминальная плата вставлена в соответствующий разъем на аппаратной панели.
Существует три стадии, на которых может быть указана конфигурация устройств. Во-первых, администраторы могут кодировать информацию о конфигурации в файлах, которые транслируются и компонуются во время построения ядра. Информация о конфигурации обычно указывается в простом формате, и программа конфигурации преобразует ее в файл, готовый для трансляции. Во-вторых, администраторы могут указывать информацию о конфигурации после того, как система уже запущена; ядро динамически корректирует внутренние таблицы конфигурации. Наконец, самоидентифицирующиеся устройства дают ядру возможность узнать, какие из устройств включены. Ядро считывает аппаратные ключи для самонастройки. Подробности задания системной конфигурации выходят за пределы этой книги, однако во всех случаях результатом процедуры задания конфигурации является генерация или заполнение таблиц, составляющих основу программ ядра.
Интерфейс "ядро - драйвер" описывается в таблице ключей устройств ввода-вывода блоками и в таблице ключей устройств посимвольного ввода-вывода (Рисунок 10.1). Каждый тип устройства имеет в таблице точки входа, которые при выполнении системных функций адресуют ядро к соответствующему драйверу. Функции open и close, вызываемые файлом устройства, "пропускаются" через таблицы ключей устройств в соответствии с типом файла. Функции mount и umount так же вызывают выполнение процедур открытия и закрытия устройств, но для устройств ввода-вывода блоками. Функции read и write, вызываемые устройствами ввода-вывода блоками и файлами в смонтированных файловых системах, запускают алгоритмы работы с буферным кешем, инициирующие реализацию стратегической процедуры работы с устройствами. Некоторые из драйверов запускают эту процедуру изнутри из процедур чтения и записи. Более подробно взаимодействие с каждым драйвером рассматривается в следующем разделе.
Интерфейс "аппаратура - драйвер" состоит из машинно-зависимых управляющих регистров или команд ввода-вывода для управления устройствами и векторами прерываний: когда происходит прерывание от устройства, система идентифицирует устройство, вызвавшее прерывание, и запускает программу обработки соответствующего прерывания. Очевидно, что "программные устройства", такие как драйвер системы построения профиля ядра (глава 8) не имеют аппаратного интерфейса, однако программы обработки других прерываний могут обращаться к "обработчику программного прерывания" непосредственно. Например, программа обработки прерывания по таймеру обращается к программе обработки прерывания системы построения профиля ядра.
Администраторы устанавливают специальные файлы устройств командой mknod, в которой указывается тип файла (блочный или символьный), старший и младший номера устройства. Команда mknod запускает выполнение системной функции с тем же именем, создающей файл устройства. Например, в командной строке
mknod /dev/tty13 c 2 13"/dev/tty13" - имя файла устройства, "c" указывает, что тип файла - "символьный специальный" ("b", соответственно, блочный), "2" - старший номер устройства, "13" - младший номер устройства. Старший номер устройства показывает его тип, которому соответствует точка входа в таблице ключей устройств, младший номер устройства - это порядковый номер единицы устройства данного типа. Если процесс открывает специальный блочный файл с именем "/dev/dsk1" и кодом 0, ядро запускает программу gdopen в точке 0 таблицы ключей устройств блочного ввода-вывода (Рисунок 10.2); если процесс читает специальный символьный файл с именем "/dev/mem" и кодом 3, ядро запускает программу mmread в точке 3 таблицы ключей устройств посимвольного ввода-вывода. Программа nulldev - это "пустая" программа, используемая в тех случаях, когда отсутствует необходимость в конкретной функции драйвера. С одним старшим номером устройства может быть связано множество периферийных устройств; младший номер устройства позволяет отличить их одно от другого. Не нужно создавать специальные файлы устройств при каждой загрузке системы; их только нужно корректировать, если изменилась конфигурация системы, например, если к установленной конфигурации были добавлены устройства.

10.1.2 Системные функции и взаимодействие с драйверами
10.1.2 Системные функции и взаимодействие с драйверами
В этом разделе рассматривается взаимодействие ядра с драйверами устройств. При выполнении тех системных функций, которые используют дескрипторы файлов, ядро, следуя за указателями, хранящимися в пользовательском дескрипторе файла, обращается к таблице файлов ядра и к индексу, где оно проверяет тип файла, и переходит к таблице ключей устройств ввода-вывода блоками или символами. Ядро извлекает из индекса старший и младший номера устройства, использует старший номер в качестве указателя на точку входа в соответствующей таблице и вызывает выполнение функции драйвера в соответствии с выполняемой системной функцией, передавая младший номер в качестве параметра. Важным различием в реализации системных функций для файлов устройств и для файлов обычного типа является то, что индекс специального файла не блокируется в то время, когда ядро выполняет программу драйвера. Драйверы часто приостанавливают свою работу, ожидая связи с аппаратными средствами или поступления данных, поэтому ядро не в состоянии определить, на какое время процесс будет приостановлен. Если индекс заблокирован, другие процессы, обратившиеся к индексу (например, посредством системной функции stat), приостановятся на неопределенное время, поскольку один процесс приостановил драйвер.
10.1.3 Программы обработки прерываний
Как уже говорилось выше (раздел 6.4.1), возникновение прерывания побуждает ядро запускать программу обработки прерываний, в основе алгоритма которой лежит соотношение между устройством, вызвавшим прерывание, и смещением в таблице векторов прерываний. Ядро запускает программу обработки прерываний для данного типа устройства, передавая ей номер устройства или другие параметры для того, чтобы идентифицировать единицу устройства, вызвавшую прерывание. Например, в таблице векторов прерываний на Рисунке 10.6 показаны две точки входа для обработки прерываний от терминалов ("ttyintr"), каждая из которых используется для обработки прерываний, поступивших от 8 терминалов. Если устройство tty09 прервало работу системы, система вызывает программу обработки прерывания, ассоциированную с местом аппаратного подключения устройства. Поскольку с одной записью в таблице векторов прерываний может быть связано множество физических устройств, драйвер должен уметь распознавать устройство, вызвавшее прерывание. На рисунке записи в таблице векторов прерываний, соответствующие прерываниям от терминалов, имеют метки 0 и 1, чтобы система различала их между собой при вызове программы обработки прерываний, используя к примеру этот номер в качестве передаваемого программе параметра. Программа обработки прерываний использует этот номер и другую информацию, переданную механизмом прерывания, для того, чтобы удостовериться, что именно устройство tty09, а не tty12, прервало работу системы. Этот пример в упрощенном виде показывает то, что имеет место в реальных системах, где на самом деле существует несколько уровней контроллеров и соответствующих программ обработки прерываний, но он иллюстрирует общие принципы.
Если подвести итог, можно сказать, что номер устройства, используемый программой обработки прерываний, идентифицирует единицу аппаратуры, а младший номер в файле устройства идентифицирует устройство для ядра. Драйвер устройства устанавливает соответствие между младшим номером устройства и номером единицы аппаратуры.
(*) И наоборот, системная функция fcntl обеспечивает контроль над действиями, производимыми на уровне дескриптора файла, но не на уровне устройства. В других реализациях функция ioctl применима для файлов всех типов.
(**) На практике вывод на печать обычно управляется специальными процессами буферизации, и права доступа устанавливаются таким образом, чтобы только система буферизации могла обращаться к принтеру.
10.1 ВЗАИМОДЕЙСТВИЕ ДРАЙВЕРОВ
10.1 ВЗАИМОДЕЙСТВИЕ ДРАЙВЕРОВ С ПРОГРАММНОЙ И АППАРАТНОЙ СРЕДОЙ
В системе UNIX имеется два типа устройств - устройства ввода/вывода блоками и устройства неструктурированного или посимвольного ввода-вывода. Как уже говорилось в главе 2, устройства ввода-вывода блоками, такие как диски и ленты, для остальной части системы выглядят как запоминающие устройства с произвольной выборкой; к устройствам посимвольного ввода-вывода относятся все другие устройства, в том числе терминалы и сетевое оборудование. Устройства ввода-вывода блоками могут иметь интерфейс и с устройствами посимвольного ввода-вывода.
Пользователь взаимодействует с устройствами через посредничество файловой системы (см. Рисунок 2.1). Каждое устройство имеет имя, похожее на имя файла, и пользователь обращается к нему как к файлу. Специальный файл устройства имеет индекс и занимает место в иерархии каталогов файловой системы. Файл устройства отличается от других файлов типом файла, хранящимся в его индексе, либо "блочный", либо "символьный специальный", в зависимости от устройства, которое этот файл представляет. Если устройство имеет как блочный, так и символьный интерфейс, его представляют два файла: специальный файл устройства ввода-вывода блоками и специальный файл устройства посимвольного ввода-вывода. Системные функции для обычных файлов, такие как open, close, read и write, имеют то же значение и для устройств, в чем мы убедимся позже. Системная функция ioctl предоставляет процессам возможность управлять устройствами посимвольного ввода-вывода, но не применима в отношении к файлам обычного типа (*). Тем не менее, драйверам устройств нет необходимости поддерживать полный набор системных функций. Например, вышеупомянутый драйвер трассировки дает процессам возможность читать записи, созданные другими драйверами, но не позволяет создавать их.
10.2 ДИСКОВЫЕ ДРАЙВЕРЫ
10.2 ДИСКОВЫЕ ДРАЙВЕРЫ
Так сложилось исторически, что дисковые устройства в системах UNIX разбивались на разделы, содержащие различные файловые системы, что означало "деление [дискового] пакета на несколько управляемых по-своему частей" (см. [System V 84b]). Например, если на диске располагаются четыре файловые системы, администратор может оставить одну из них несмонтированной, одну смонтировать только для чтения, а две других только для записи. Несмотря на то, что все файловые системы сосуществуют на одном физическом устройстве, пользователи не могут ни обращаться к файлам немонтированной файловой системы, используя методы доступа, описанные в главах 4 и 5, ни записывать файлы в файловые системы, смонтированные только для чтения. Более того, так как каждый раздел (и, следовательно, файловая система) занимает на диске смежные дорожки и цилиндры, скопировать всю файловую систему легче, чем в том случае, если бы раздел занимал участки, разбросанные по всему дисковому тому.
Дисковый драйвер транслирует адрес файловой системы, состоящий из логического номера устройства и номера блока, в точный номер дискового сектора. Драйвер получает адрес одним из следующих путей: либо стратегическая процедура использует буфер из буферного пула, заголовок которого содержит номера устройства и блока, либо процедуры чтения и записи передают логический (младший) номер устройства в качестве параметра; они преобразуют адрес смещения в байтах, хранящийся в пространстве задачи, в адрес соответствующего блока. Дисковый драйвер использует номер устройства для идентификации физического устройства и указания используемого раздела, обращаясь при этом к внутренним таблицам для поиска сектора, отмечающего начало раздела на диске. Наконец, он добавляет номер блока в файловой системе к номеру блока, с которого начинается каждый сектор, чтобы идентифицировать сектор, используемый для ввода-вывода.
10.3.1 Символьные списки
10.3.1 Символьные списки
Строковый интерфейс обрабатывает данные в символьных списках. Символьный список (clist) представляет собой переменной длины список символьных блоков с использованием указателей и с подсчетом количества символов в списке. Символьный блок (cblock) содержит указатель на следующий блок в списке, небольшой массив хранимой в символьном виде информации и адреса смещений, показывающие место расположения внутри блока корректной информации (Рисунок 10.10). Смещение до начала показывает первую позицию расположения корректной информации в массиве, смещение до конца показывает первую позицию расположения некорректной информации.

10.3.2 Терминальный драйвер в каноническом режиме
10.3.2 Терминальный драйвер в каноническом режиме
Структуры данных, с которыми работают терминальные драйверы, связаны с тремя символьными списками: списком для хранения данных, выводимых на терминал, списком для хранения неструктурированных вводных данных, поступивших в результате выполнения программы обработки прерывания от терминала, вызванного попыткой пользователя ввести данные с клавиатуры, и списком для хранения обработанных входных данных, поступивших в результате преобразования строковым интерфейсом специальных символов (таких как символы стирания и удаления) в неструктурированном списке.
Когда процесс ведет запись на терминал (Рисунок 10.13), терминальный драйвер запускает строковый интерфейс. Строковый интерфейс в цикле считывает символы из адресного пространства процесса и помещает их в символьный список для хранения выводных данных до тех пор, пока поток данных не будет исчерпан. Строковый интерфейс обрабатывает выводимые символы, например, заменяя символы табуляции на последовательности пробелов. Если количество символов в списке для хранения выводных данных превысит верхнюю отметку, строковый интерфейс вызывает процедуры драйвера, пересылающие данные из символьного списка на терминал и после этого приостанавливающие выполнение процесса, ведущего запись. Когда объем информации в списке для хранения выводных данных падает за нижнюю отметку, программа обработки прерываний возобновляет выполнение всех процессов, приостановленных до того момента, когда терминал сможет принять следующую порцию данных. Строковый интерфейс завершает цикл обработки, скопировав всю выводимую информацию из адресного пространства задачи в соответствующий символьный список, и вызывает выполнение процедур драйвера, пересылающих данные на терминал, о которых уже было сказано выше.
10.3.3 Терминальный драйвер в режиме без обработки символов
10.3.3 Терминальный драйвер в режиме без обработки символов
Пользователи устанавливают параметры терминала, такие как символы стирания и удаления, и извлекают значения текущих установок с помощью системной функции ioctl. Сходным образом они устанавливают необходимость эхо-сопровождения ввода данных с терминала, задают скорость передачи информации в бодах, заполняют очереди символов ввода и вывода или вручную запускают и останавливают выводной поток символов. В информационной структуре терминального драйвера хранятся различные управляющие установки (см. [SVID 85], стр.281), и строковый интерфейс получает параметры функции ioctl и устанавливает или считывает значения соответствующих полей структуры данных. Когда процесс устанавливает значения параметров терминала, он делает это для всех процессов, использующих терминал. Установки терминала не сбрасываются автоматически при выходе из процесса, сделавшего изменения в установках.
Процессы могут также перевести терминал в режим без обработки символов, в котором строковый интерфейс передает символы в точном соответствии с тем, как пользователь ввел их: обработка вводного потока полностью отсутствует. Однако, ядро должно знать, когда выполнить вызванную пользователем системную функцию read, поскольку символ возврата каретки трактуется как обычный введенный символ. Оно выполняет функцию read после того, как с терминала будет введено минимальное число символов или по прохождении фиксированного промежутка времени от момента получения с терминала любого набора символов. В последнем случае ядро хронометрирует ввод символов с терминала, помещая записи в таблицу ответных сигналов (глава 8). Оба критерия (минимальное число символов и фиксированный промежуток времени) задаются в вызове функции ioctl. Когда соответствующие критерии удовлетворены, программа обработки прерываний строкового интерфейса возобновляет выполнение всех приостановленных процессов. Драйвер пересылает все символы из списка для хранения неструктурированных вводных данных в канонический список и выполняет запрос процесса на чтение, следуя тому же самому алгоритму, что и в случае работы в каноническом режиме. Режим без обработки символов особенно важен в экранно-ориентированных приложениях, таких как экранный редактор vi, многие из команд которого не заканчиваются символом возврата каретки. Например, команда dw удаляет слово в текущей позиции курсора.
На Рисунке 10.17 приведена программа, использующая функцию ioctl для сохранения текущих установок терминала для файла с дескриптором 0, что соответствует значению дескриптора файла стандартного ввода. Функция ioctl с командой TCGETA приказывает драйверу извлечь установки и сохранить их в структуре с именем savetty в адресном пространстве задачи. Эта команда часто используется для того, чтобы определить, является ли файл терминалом или нет, поскольку она ничего не изменяет в системе: если она завершается неудачно, процессы предполагают, что файл не является терминалом. Здесь же, процесс вторично вызывает функцию ioctl для того, чтобы перевести терминал в режим без обработки: он отключает эхо-сопровождение ввода символов и готовится к выполнению операций чтения с терминала по получении с терминала 5 символов, как минимум, или по прохождении 10 секунд с момента ввода первой порции символов. Когда процесс получает сигнал о прерывании, он сбрасывает первоначальные параметры терминала и завершается.
10.3.4 Опрос терминала
10.3.4 Опрос терминала
Иногда удобно производить опрос устройства, то есть считывать с него данные, если они есть, или продолжать выполнять обычную работу - в противном случае. Программа на Рисунке 10.18 иллюстрирует этот случай: после открытия терминала с параметром "no delay" (без задержки) процессы, ведущие чтение с него, не приостановят свое выполнение в случае отсутствия данных, а вернут управление немедленно (см. алгоритм terminal_read, Рисунок 10.15). Этот метод работает также, если процесс следит за множеством устройств: он может открыть каждое устройство с параметром "no delay" и опросить всех из них, ожидая поступления информации с каждого. Однако, этот метод растрачивает вычислительные мощности системы.
В системе BSD есть системная функция select, позволяющая производить опрос устройства. Синтаксис вызова этой функции:
select(nfds,rfds,wfds,efds,timeout)где nfds - количество выбираемых дескрипторов файлов, а rfds, wfds и efds указывают на двоичные маски, которыми "выбирают" дескрипторы открытых файлов. То есть, бит 1 << fd (сдвиг на 1 разряд влево значения дескриптора файла) соответствует установке на тот случай, если пользователю нужно выбрать этот дескриптор файла. Параметр timeout (тайм-аут) указывает, на какое время следует приостановить выполнение функции select, ожидая поступления данных, например; если данные поступают для любых дескрипторов и тайм-аут не закончился, select возвращает управление, указывая в двоичных масках, какие дескрипторы были выбраны. Например, если пользователь пожелал приостановиться до момента получения данных по дескрипторам 0, 1 или 2, параметр rfds укажет на двоичную маску 7; когда select возвратит управление, двоичная маска будет заменена маской, указывающей, по каким из дескрипторов имеются готовые данные. Двоичная маска wfds выполняет похожую функцию в отношении записи дескрипторов, а двоичная маска efds указывает на существование исключительных условий, связанных с конкретными дескрипторами, что бывает полезно при работе в сети.
10.3.5 Назначение операторского терминала
10.3.5 Назначение операторского терминала
Операторский терминал - это терминал, с которого пользователь регистрируется в системе, он управляет процессами, запущенными пользователем с терминала. Когда процесс открывает терминал, драйвер терминала открывает строковый интерфейс. Если процесс возглавляет группу процессов как результат выполнения системной функции setpgrp и если процесс не связан с одним из операторских терминалов, строковый интерфейс делает открываемый терминал операторским. Он сохраняет старший и младший номера устройства для файла терминала в адресном пространстве, выделенном процессу, а номер группы процессов, связанной с открываемым процессом, в структуре данных терминального драйвера. Открываемый процесс становится управляющим процессом, обычно входным (начальным) командным процессором, что мы увидим далее.
Операторский терминал играет важную роль в обработке сигналов. Когда пользователь нажимает клавиши "delete" (удаления), "break" (прерывания), стирания или выхода, программа обработки прерываний загружает строковый интерфейс, который посылает соответствующий сигнал всем процессам в группе. Подобно этому, когда пользователь "зависает", программа обработки прерываний от терминала получает информацию о "зависании" от аппаратуры, и строковый интерфейс посылает соответствующий сигнал всем процессам в группе. Таким образом, все процессы, запущенные с конкретного терминала, получают сигнал о "зависании"; реакцией по умолчанию для большинства процессов будет выход из программы по получении сигнала; это похоже на то, как при завершении работы пользователя с терминалом из системы удаляются побочные процессы. После посылки сигнала о "зависании" программа обработки прерываний от терминала разъединяет терминал с группой процессов, чтобы процессы из этой группы не могли больше получать сигналы, возникающие на терминале.
10.3.6 Драйвер косвенного терминала
10.3.6 Драйвер косвенного терминала
Зачастую процессам необходимо прочитать ил записать данные непосредственно на операторский терминал, хотя стандартный ввод и вывод могут быть переназначены в другие файлы. Например, shell может посылать срочные сообщения непосредственно на терминал, несмотря на то, что его стандартный файл вывода и стандартный файл ошибок, возможно, переназначены в другое место. В версиях системы UNIX поддерживается "косвенный" доступ к терминалу через файл устройства "/dev/tty", в котором для каждого процесса определен управляющий (операторский) терминал. Пользователи, прошедшие регистрацию на отдельных терминалах, могут обращаться к файлу "/dev/tty", но они получат доступ к разным терминалам.
Существует два основных способа поиска ядром операторского терминала по имени файла "/dev/tty". Во-первых, ядро может специально указать номер устройства для файла косвенного терминала с отдельной точкой входа в таблицу ключей устройств посимвольного ввода-вывода. При запуске косвенного терминала драйвер этого терминала получает старший и младший номера операторского терминала из адресного пространства, выделенного процессу, и запускает драйвер реального терминала, используя данные таблицы ключей устройств посимвольного ввода-вывода. Второй способ, обычно используемый для поиска операторского терминала по имени "/dev/tty", связан с проверкой соответствия старшего номера устройства номеру косвенного терминала перед вызовом процедуры open, определяемой типом данного драйвера. В случае совпадения номеров освобождается индекс файла "/dev/tty", выделяется индекс операторскому терминалу, точка входа в таблицу файлов переустанавливается так, чтобы указывать на индекс операторского терминала, и вызывается процедура open, принадлежащая терминальному драйверу. Дескриптор файла, возвращенный после открытия файла "/dev/tty", указывает непосредственно на операторский терминал и его драйвер.
10.3.7 Вход в систему
10.3.7 Вход в систему
Как показано в главе 7, процесс начальной загрузки, имеющий номер 1, выполняет бесконечный цикл чтения из файла "/etc/inittab" инструкций о том, что нужно делать, если загружаемая система определена как "однопользовательская" или "многопользовательская". В многопользовательском режиме самой первой обязанностью процесса начальной загрузки является предоставление пользователям возможности регистрироваться в системе с терминалов (Рисунок 10.19). Он порождает процессы, именуемые getty-процессами (от "get tty" - получить терминал), и следит за тем, какой из процессов открывает какой терминал; каждый getty-процесс устанавливает свою группу процессов, используя вызов системной функции setpgrp, открывает отдельную терминальную линию и обычно приостанавливается во время выполнения функции open до тех пор, пока машина не получит аппаратную связь с терминалом. Когда функция open возвращает управление, getty-процесс исполняет программу login (регистрации в системе), которая требует от пользователей, чтобы они идентифицировали себя указанием регистрационного имени и пароля. Если пользователь зарегистрировался успешно, программа login наконец запускает командный процессор shell и пользователь приступает к работе. Этот вызов shell'а именуется "login shell" (регистрационный shell, регистрационный интерпретатор команд). Процесс, связанный с shell'ом, имеет тот же идентификатор, что и начальный getty-процесс, поэтому login shell является процессом, возглавляющим группу процессов. Если пользователь не смог успешно зарегистрироваться, программа регистрации завершается через определенный промежуток времени, закрывая открытую терминальную линию, а процесс начальной загрузки порождает для этой линии следующий getty-процесс. Процесс начальной загрузки делает паузу до получения сигнала об окончании порожденного ранее процесса. После возобновления работы он выясняет, был ли прекративший существование процесс регистрационным shell'ом и если это так, порождает еще один getty-процесс, открывающий терминал, вместо прекратившего существование.
10.3 ТЕРМИНАЛЬНЫЕ ДРАЙВЕРЫ
10.3 ТЕРМИНАЛЬНЫЕ ДРАЙВЕРЫ
Терминальные драйверы выполняют ту же функцию, что и остальные драйверы: управление передачей данных от и на терминалы. Однако, терминалы имеют одну особенность, связанную с тем, что они обеспечивают интерфейс пользователя с системой. Обеспечивая интерактивное использование системы UNIX, терминальные драйверы имеют свой внутренний интерфейс с модулями, интерпретирующими ввод и вывод строк. В каноническом режиме интерпретаторы строк преобразуют неструктурированные последовательности данных, введенные с клавиатуры, в каноническую форму (то есть в форму, соответствующую тому, что пользователь имел ввиду на самом деле) прежде, чем послать эти данные принимающему процессу; строковый интерфейс также преобразует неструктурированные последовательности выходных данных, созданных процессом, в формат, необходимый пользователю. В режиме без обработки строковый интерфейс передает данные между процессами и терминалом без каких-либо преобразований.
Программисты, например, работают на клавиатуре терминала довольно быстро, но с ошибками. На этот случай терминалы имеют клавишу стирания ("erase"; клавиша может быть обозначена таким образом), чтобы пользователь имел возможность стирать часть введенной строки и вводить коррективы. Терминалы пересылают машине всю введенную последовательность, включая и символы стирания (****). В каноническом режиме строковый интерфейс буферизует информацию в строки (набор символов, заканчивающийся символом возврата каретки (*****)) и процессы стирают символы у себя, прежде чем переслать исправленную последовательность считывающему процессу.
В функции строкового интерфейса входят:
построчный разбор введенных последовательностей; обработка символов стирания; обработка символов "удаления", отменяющих все остальные символы, введенные до того в текущей строке; отображение символов, полученных терминалом; расширение выходных данных, например, преобразование символов табуляции в последовательности пробелов; сигнализирование процессам о зависании терминалов и прерывании строк или в ответ на нажатие пользователем клавиши удаления; предоставление возможности не обрабатывать специальные символы, такие как символы стирания, удаления и возврата каретки.Функционирование без обработки подразумевает использование асинхронного терминала, поскольку процессы могут считывать символы в том виде, в каком они были введены, вместо того, чтобы ждать, когда пользователь нажмет клавишу ввода или возврата каретки.
Ричи отметил, что первые строковые интерфейсы, используемые еще при разработке системы в начале 70-х годов, работали в составе программ командного процессора и редактора, но не в ядре (см. [Ritchie 84], стр.1580). Однако, поскольку в их функциях нуждается множество программ, их место в составе ядра. Несмотря на то, что строковый интерфейс выполняет такие функции, из которых логически вытекает его место между терминальным драйвером и остальной частью ядра, ядро не запускает строковый интерфейс иначе, чем через терминальный драйвер. На Рисунке 10.9 показаны поток данных, проходящий через терминальный драйвер и строковый интерфейс, и соответствующие ему управляющие воздействия, проходящие через терминальный драйвер. Пользователи могут указать, какой строковый интерфейс используется посредством вызова системной функции ioctl, но реализовать схему, по которой одно устройство использовало бы несколько строковых интерфейсов одновременно, при чем каждый интерфейсный модуль, в свою очередь, успешно вызывал бы следующий модуль для обработки данных, довольно трудно.
10.4.1 Более детальное рассмотрение потоков
10.4.1 Более детальное рассмотрение потоков
Пайк описывает реализацию мультиплексных виртуальных терминалов, использующую потоки (см. [Pike 84]). Пользователь видит несколько виртуальных терминалов, каждый из которых занимает отдельное окно на экране физического терминала. Хотя в статье Пайка рассматривается схема для интеллектуальных графических терминалов, она работала бы и для терминалов ввода-вывода тоже; каждое окно занимало бы целый экран и пользователь для переключения виртуальных окон набирал бы последовательность управляющих клавиш.

10.4.2 Анализ потоков
10.4.2 Анализ потоков
Ричи упоминает о том, что им была предпринята попытка создания потоков только с процедурами "вывода" или только с процедурами обслуживания. Однако, процедура обслуживания необходима для управления потоками данных, так как модули должны иногда ставить данные в очередь, если соседние модули на время закрыты для приема данных. Процедура "вывода" так же необходима, поскольку данные должны иногда доставляться в соседние модули незамедлительно. Например, строковому интерфейсу терминала нужно вести эхо-сопровождение ввода данных на терминале в темпе с процессом. Системная функция write могла бы запускать процедуру "вывода" для следующей очереди непосредственно, та, в свою очередь, вызывала бы процедуру "вывода" для следующей очереди и так далее, не нуждаясь в механизме диспетчеризации. Процесс приостановился бы в случае переполнения очередей для вывода. Однако, со стороны ввода модули не могут приостанавливаться, поскольку их выполнение вызывается программой обработки прерываний, иначе был бы приостановлен совершенно безобидный процесс. Связь между модулями не должна быть симметричной в направлениях ввода и вывода, хотя это и делает схему менее изящной.
Также было бы желательно реализовать каждый модуль в виде отдельного процесса, но использование большого количества модулей привело бы к переполнению таблицы процессов. Модули наделяются специальным механизмом диспетчеризации - программным прерыванием, независимым от обычного планировщика процессов. По этой причине модули не могут приостанавливать свое выполнение, так как они приостанавливали бы тем самым произвольный процесс (тот, который прерван). Модули должны хранить внутри себя информацию о своем состоянии, что делает лежащие в их основе программы более громоздкими, чем если бы приостановка выполнения была разрешена.
В реализации потоков можно выделить несколько отклонений или несоответствий:
Учет ресурсов процесса в потоках затрудняется, поскольку модулям необязательно выполняться в контексте процесса, использующего поток. Ошибочно предполагать, что все процессы одинаково используют модули потоков, поскольку одним процессам может потребоваться использование сложных сетевых протоколов, тогда как другие могут использовать простые строковые интерфейсы. Пользователи имеют возможность переводить терминальный драйвер в режим без обработки, в котором функция read возвращает управление через короткий промежуток времени в случае отсутствия данных (например, если newtty.c_cc[VMIN] = 0 на Рисунке 10.17). Эту особенность сложно реализовать в потоковой среде без подключения специальной программы на уровне заголовка потока. Потоки выступают средствами линейной связи и не могут позволить производить с легкостью мультиплексирование на уровне ядра. В примере использования окон, рассмотренном в предыдущем разделе, выполнялось мультиплексирование на уровне пользовательского процесса.Несмотря на эти несоответствия, с потоками связываются большие надежды в совершенствовании разработки модулей драйвера.