10.4 ПОТОКИ
10.4 ПОТОКИ
Схема реализации драйверов устройств, хотя и отвечает заложенным требованиям, страдает некоторыми недостатками, которые с годами стали заметнее. Разные драйверы имеют тенденцию дублировать свои функции, в частности драйверы, которые реализуют сетевые протоколы и которые обычно включают в себя секцию управления устройством и секцию протокола. Несмотря на то, что секция протокола должна быть общей для всех сетевых устройств, на практике это не так, поскольку ядро не имеет адекватных механизмов для общего использования. Например, символьные списки могли бы быть полезными благодаря своим возможностям в буферизации, но они требуют больших затрат ресурсов на посимвольную обработку. Попытки обойти этот механизм, чтобы повысить производительность системы, привели к нарушению модульности подсистемы управления вводом-выводом. Отсутствие общности на уровне драйверов распространяется вплоть до уровня команд пользователя, на котором несколько команд могут выполнять общие логические функции, но различными средствами. Еще один недостаток построения драйверов заключается в том, что сетевые протоколы требуют использования средства, подобного строковому интерфейсу, в котором каждая дисциплина реализует одну из частей протокола и составные части соединяются гибким образом. Однако, соединить традиционные строковые интерфейсы довольно трудно.
Ричи недавно разработал схему, получившую название "потоки" (streams), для повышения модульности и гибкости подсистемы управления вводом-выводом. Нижеследующее описание основывается на его работе [Ritchie 84b], хотя реализация этой схемы в версии V слегка отличается. Поток представляет собой полнодуплексную связь между процессом и драйвером устройства. Он состоит из совокупности линейно связанных между собой пар очередей, каждая из которых (пара) включает одну очередь для ввода и другую - для вывода. Когда процесс записывает данные в поток, ядро посылает данные в очереди для вывода; когда драйвер устройства получает входные данные, он пересылает их в очереди для ввода к процессу, производящему чтение. Очереди обмениваются сообщениями с соседними очередями, используя четко определенный интерфейс. Каждая пара очередей связана с одним из модулей ядра, таким как драйвер, строковый интерфейс или протокол, и модули ядра работают с данными, прошедшими через соответствующие очереди.
Каждая очередь представляет собой структуру данных, состоящую из следующих элементов:
процедуры открытия, вызываемой во время выполнения системной функции open процедуры закрытия, вызываемой во время выполнения системной функции close процедуры "вывода", вызываемой для передачи сообщения в очередь процедуры "обслуживания", вызываемой, когда очередь запланирована к исполнению указателя на следующую очередь в потоке указателя на список сообщений, ожидающих обслуживания указателя на внутреннюю структуру данных, с помощью которой поддерживается рабочее состояние очереди флагов, а также верхней и нижней отметок, используемых для управления потоками данных, диспетчеризации и поддержания рабочего состояния очереди.Ядро выделяет пары очередей, соседствующие в памяти; следовательно, очередь легко может отыскать своего партнера по паре.
10.5 ВЫВОДЫ
10.5 ВЫВОДЫ
Данная глава представляет собой обзор драйверов устройств в системе UNIX. Устройства могут быть либо блочного, либо символьного типа; интерфейс между устройствами и остальной частью ядра определяется типом устройств. Интерфейсом для устройств блочного типа выступает таблица ключей устройств ввода-вывода блоками, состоящая из точек входа, соответствующих процедурам открытия и закрытия устройств и стратегической процедуре. Стратегическая процедура управляет передачей данных от и к устройству блочного типа. Интерфейсом для устройств символьного типа выступает таблица ключей устройств посимвольного ввода-вывода, которая состоит из точек входа, соответствующих процедурам открытия и закрытия устройства, чтения, записи и процедуре ioctl. Системная функция ioctl использует при обращении к устройствам символьного типа свой собственный интерфейс, который позволяет осуществлять передачу управляющей информации между процессами и устройствами. По получении прерывания от устройства ядро вызывает программу обработки соответствующего прерывания, опираясь на информацию, хранящуюся в таблице векторов прерываний, и на параметры, сообщенные устройством, от которого поступило прерывание.
Дисковые драйверы превращают номера логических блоков, используемые файловой системой, в физические адреса на диске. Блочный интерфейс дает возможность ядру буферизовать данные. Взаимодействие без обработки ускоряет ввод-вывод на диск, но игнорирует буферный кеш, увеличивая тем самым шансы разрушить файловую систему.
Терминальные драйверы осуществляют непосредственное взаимодействие с пользователями. Ядро связывает с каждым терминалом три символьных списка, один для неструктурированного ввода с клавиатуры, один для ввода с обработкой символов стирания, удаления и возврата каретки и один для вывода. Системная функция ioctl дает процессам возможность следить за тем, как ядро обрабатывает вводимые данные, переводя терминал в канонический режим или устанавливая значения различных параметров для режима без обработки символов. Getty-процесс открывает терминальные линии и ждет связи: он формирует группу процессов во главе с регистрационным shell'ом, инициализирует с помощью функции ioctl параметры терминала и обращается к пользователю с предложением зарегистрироваться. Установленный таким образом операторский терминал посылает процессам в группе сигналы в ответ на возникновение таких событий, как "зависание" пользователя или нажатие им клавиши прерывания.
Потоки выступают средством повышения модульности построения драйверов устройств и протоколов. Поток - это полнодуплексная связь между процессами и драйверами устройств, которая может включать в себя строковые интерфейсы и протоколы для промежуточной обработки данных. Модули потоков характеризуются четко определенным взаимодействием и гибкостью, позволяющей использовать их в сочетании с другими модулями. Эта гибкость имеет особое значение для сетевых протоколов и драйверов.
10.6 УПРАЖНЕНИЯ
10.6 УПРАЖНЕНИЯ
* Предположим, что в системе имеются два файла устройств с одними и теми же старшим и младшим номерами, при том, что оба устройства - символьного типа. Если два процесса желают одновременно открыть физическое устройство, не будет никакой разницы, открывают ли они один и тот же файл устройства или же разные файлы. Что произойдет, когда они станут закрывать устройство? * Вспомним из главы 5, что системной функции mknod требуется разрешение суперпользователя на создание нового специального файла устройства. Если доступ к устройству управляется правами доступа к файлу, почему функции mknod нужно разрешение суперпользователя? Напишите программу, которая проверяет, что файловые системы на диске не перекрываются. Этой программе потребовались бы два аргумента: файл устройства, представляющий дисковый том, и дескриптор файла, откуда берутся номера секторов и их размер для диска данного типа. Для проверки отсутствия перекрытий этой программе понадобилась бы информация из суперблоков. Будет ли такая программа всегда правильной? Программа mkfs инициализирует файловую систему на диске путем создания суперблока, выделения места для списка индексов, включения всех информационных блоков в связанный список и создания корневого каталога. Как бы вы написали программу mkfs? Как изменится эта программа при наличии таблицы содержимого тома? Каким образом следует инициализировать таблицу содержимого тома? Программы mkfs и fsck (глава 5) являются программами пользовательского уровня, а не частью ядра. Прокомментируйте это. Предположим, что программисту нужно разработать базу данных, работающую в среде ОС UNIX. Программы базы данных выполняются на пользовательском уровне, а не в составе ядра. Как система управления базой данных будет взаимодействовать с диском? Подумайте над следующими вопросами: Использование стандартного интерфейса файловой системы вместо непосредственной работы с неструктурированными данными на диске, Потребность в быстродействии, Необходимость знать, когда фактически данные располагаются на диске, Размер базы данных: должна ли она помещаться в одной файловой системе, занимать собой весь дисковый том или же располагаться на нескольких дисковых томах? Ядро системы UNIX по умолчанию предполагает, что файловая система располагается на идеальных дисках. Однако, диски могут содержать ошибки, которые делают непригодными и выводят из строя определенные сектора, несмотря на то, что остальная часть диска осталась "пригодной". Как дисковому драйверу (или интеллектуальному контроллеру диска) следует учитывать небольшое количество плохих секторов. Как это отразилось бы на производительности системы? При монтировании файловой системы ядро запускает процедуру открытия для данного драйвера, но позже освобождает индекс специального файла устройства по завершении выполнения вызова системной функции mount. При демонтировании файловой системы ядро обращается к индексу специального файла устройства, запускает процедуру закрытия для данного драйвера и вновь освобождает индекс. Сравните эту последовательность операций над индексом, а также обращений к процедурам открытия и закрытия драйвера, с последовательностью действий, совершаемых при открывании и закрывании устройства блочного типа. Прокомментируйте результаты сравнения. Выполните программу, приведенную на Рисунке 10.14, но направьте вывод данных в файл. Сравните содержимое файла с содержимым выводного потока, когда вывод идет на терминал. Вам придется прервать процессы, чтобы остановить их; только прежде пусть они получат достаточно большое количество данных. Что произойдет, если вызов функции write в программе заменить на printf(output); Что произойдет, если пользователь попытается выполнить редактирование текста на фоне программы: ed file &
Обоснуйте ответ.
при входе пользователя в систему. То есть, чтение и запись разрешаются пользователю с именем "mjb", а остальным пользователям разрешена только запись. Почему?
11.1 ТРАССИРОВКА ПРОЦЕССОВ
11.1 ТРАССИРОВКА ПРОЦЕССОВ
В системе UNIX имеется простейшая форма взаимодействия процессов, используемая в целях отладки, - трассировка процессов. Процесс-отладчик, например sdb, порождает трассируемый процесс и управляет его выполнением с помощью системной функции ptrace, расставляя и сбрасывая контрольные точки, считывая и записывая данные в его виртуальное адресное пространство. Трассировка процессов, таким образом, включает в себя синхронизацию выполнения процесса-отладчика и трассируемого процесса и управление выполнением последнего.
11.2.1 Сообщения
11.2.1 Сообщения
С сообщениями работают четыре системных функции: msgget, которая возвращает (и в некоторых случаях создает) дескриптор сообщения, определяющий очередь сообщений и используемый другими системными функциями, msgctl, которая устанавливает и возвращает связанные с дескриптором сообщений параметры или удаляет дескрипторы, msgsnd, которая посылает сообщение, и msgrcv, которая получает сообщение.
Синтаксис вызова системной функции msgget:
msgqid = msgget(key,flag);где msgqid - возвращаемый функцией дескриптор, а key и flag имеют ту же семантику, что и в системной функции типа "get". Ядро хранит сообщения в связном списке (очереди), определяемом значением дескриптора, и использует значение msgqid в качестве указателя на массив заголовков очередей. Кроме вышеуказанных полей, описывающих общие для всего механизма права доступа, заголовок очереди содержит следующие поля:
Указатели на первое и последнее сообщение в списке; Количество сообщений и общий объем информации в списке в байтах; Максимальная емкость списка в байтах; Идентификаторы процессов, пославших и принявших сообщения последними; Поля, указывающие время последнего выполнения функций msgsnd, msgrcv и msgctl.Когда пользователь вызывает функцию msgget для того, чтобы создать новый дескриптор, ядро просматривает массив очередей сообщений в поисках существующей очереди с указанным идентификатором. Если такой очереди нет, ядро выделяет новую очередь, инициализирует ее и возвращает идентификатор пользователю. В противном случае ядро проверяет наличие необходимых прав доступа и завершает выполнение функции.
Для посылки сообщения процесс использует системную функцию msgsnd:
msgsnd(msgqid,msg,count,flag);где msgqid - дескриптор очереди сообщений, обычно возвращаемый функцией msgget, msg - указатель на структуру, состоящую из типа в виде назначаемого пользователем целого числа и массива символов, count - размер информационного массива, flag - действие, предпринимаемое ядром в случае переполнения внутреннего буферного пространства.
11.2.2 Разделение памяти
11.2.2 Разделение памяти
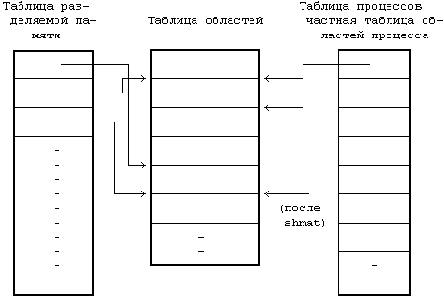
Процессы могут взаимодействовать друг с другом непосредственно путем разделения (совместного использования) участков виртуального адресного пространства и обмена данными через разделяемую память. Системные функции для работы с разделяемой памятью имеют много сходного с системными функциями для работы с сообщениями. Функция shmget создает новую область разделяемой памяти или возвращает адрес уже существующей области, функция shmat логически присоединяет область к виртуальному адресному пространству процесса, функция shmdt отсоединяет ее, а функция shmctl имеет дело с различными параметрами, связанными с разделяемой памятью. Процессы ведут чтение и запись данных в области разделяемой памяти, используя для этого те же самые машинные команды, что и при работе с обычной памятью. После присоединения к виртуальному адресному пространству процесса область разделяемой памяти становится доступна так же, как любой участок виртуальной памяти; для доступа к находящимся в ней данным не нужны обращения к каким-то дополнительным системным функциям.
Синтаксис вызова системной функции shmget:
shmid = shmget(key,size,flag);где size - объем области в байтах. Ядро использует key для ведения поиска в таблице разделяемой памяти: если подходящая запись обнаружена и если разрешение на доступ имеется, ядро возвращает вызывающему процессу указанный в записи дескриптор. Если запись не найдена и если пользователь установил флаг IPC_CREAT, указывающий на необходимость создания новой области, ядро проверяет нахождение размера области в установленных системой пределах и выделяет область по алгоритму allocreg (раздел 6.5.2). Ядро записывает установки прав доступа, размер области и указатель на соответствующую запись таблицы областей в таблицу разделяемой памяти (Рисунок 11.9) и устанавливает флаг, свидетельствующий о том, что с областью не связана отдельная память. Области выделяется память (таблицы страниц и т.п.) только тогда, когда процесс присоединяет область к своему адресному пространству. Ядро устанавливает также флаг, говорящий о том, что по завершении последнего связанного с областью процесса область не должна освобождаться. Таким образом, данные в разделяемой памяти остаются в сохранности, даже если она не принадлежит ни одному из процессов (как часть виртуального адресного пространства последнего).
11.2.3 Семафоры
11.2.3 Семафоры
Системные функции работы с семафорами обеспечивают синхронизацию выполнения параллельных процессов, производя набор действий единственно над группой семафоров (средствами низкого уровня). До использования семафоров, если процессу нужно было заблокировать некий ресурс, он прибегал к созданию с помощью системной функции creat специального блокирующего файла. Если файл уже существовал, функция creat завершалась неудачно, и процесс делал вывод о том, что ресурс уже заблокирован другим процессом. Главные недостатки такого подхода заключались в том, что процесс не знал, в какой момент ему следует предпринять следующую попытку, а также в том, что блокирующие файлы случайно оставались в системе в случае ее аварийного завершения или перезагрузки.
Дийкстрой был опубликован алгоритм Деккера, описывающий реализацию семафоров как целочисленных объектов, для которых определены две элементарные операции: P и V (см. [Dijkstra 68]). Операция P заключается в уменьшении значения семафора в том случае, если оно больше 0, операция V - в увеличении этого значения (и там, и там на единицу). Поскольку операции элементарные, в любой момент времени для каждого семафора выполняется не более одной операции P или V. Связанные с семафорами системные функции являются обобщением операций, предложенных Дийкстрой, в них допускается одновременное выполнение нескольких операций, причем операции уменьшения и увеличения выполняются над значениями, превышающими 1. Ядро выполняет операции комплексно; ни один из посторонних процессов не сможет переустанавливать значения семафоров, пока все операции не будут выполнены. Если ядро по каким-либо причинам не может выполнить все операции, оно не выполняет ни одной; процесс приостанавливает свою работу до тех пор, пока эта возможность не будет предоставлена.
Семафор в версии V системы UNIX состоит из следующих элементов:
Значение семафора, Идентификатор последнего из процессов, работавших с семафором, Количество процессов, ожидающих увеличения значения семафора, Количество процессов, ожидающих момента, когда значение семафора станет равным 0.Для создания набора семафоров и получения доступа к ним используется системная функция semget, для выполнения различных управляющих операций над набором - функция semctl, для работы со значениями семафоров - функция semop.
11.2.4 Общие замечания
11.2.4 Общие замечания
Механизм функционирования файловой системы и механизмы взаимодействия процессов имеют ряд общих черт. Системные функции типа "get" похожи на функции creat и open, функции типа "control" предоставляют возможность удалять дескрипторы из системы, чем похожи на функцию unlink. Тем не менее, в механизмах взаимодействия процессов отсутствуют операции, аналогичные операциям, выполняемым системной функцией close. Следовательно, ядро не располагает сведениями о том, какие процессы могут использовать механизм IPC, и, действительно, процессы могут прибегать к услугам этого механизма, если правильно угадывают соответствующий идентификатор и если у них имеются необходимые права доступа, даже если они не выполнили предварительно функцию типа "get". Ядро не может автоматически очищать неиспользуемые структуры механизма взаимодействия процессов, поскольку ядру неизвестно, какие из этих структур больше не нужны. Таким образом, завершившиеся вследствие возникновения ошибки процессы могут оставить после себя ненужные и неиспользуемые структуры, перегружающие и засоряющие систему. Несмотря на то, что в структурах механизма взаимодействия после завершения существования процесса ядро может сохранить информацию о состоянии и данные, лучше все-таки для этих целей использовать файлы.
Вместо традиционных, получивших широкое распространение файлов механизмы взаимодействия процессов используют новое пространство имен, состоящее из ключей (keys). Расширить семантику ключей на всю сеть довольно трудно, поскольку на разных машинах ключи могут описывать различные объекты. Короче говоря, ключи в основном предназначены для использования в одномашинных системах. Имена файлов в большей степени подходят для распределенных систем (см. главу 13). Использование ключей вместо имен файлов также свидетельствует о том, что средства взаимодействия процессов являются "вещью в себе", полезной в специальных приложениях, но не имеющей тех возможностей, которыми обладают, например, каналы и файлы. Большая часть функциональных возможностей, предоставляемых данными средствами, может быть реализована с помощью других системных средств, поэтому включать их в состав ядра вряд ли следовало бы. Тем не менее, их использование в составе пакетов прикладных программ тесного взаимодействия дает лучшие результаты по сравнению со стандартными файловыми средствами (см. Упражнения).
11.2 ВЗАИМОДЕЙСТВИЕ ПРОЦЕССОВ В ВЕРСИИ V СИСТЕМЫ
11.2 ВЗАИМОДЕЙСТВИЕ ПРОЦЕССОВ В ВЕРСИИ V СИСТЕМЫ
Пакет IPC (interprocess communication) в версии V системы UNIX включает в себя три механизма. Механизм сообщений дает процессам возможность посылать другим процессам потоки сформатированных данных, механизм разделения памяти позволяет процессам совместно использовать отдельные части виртуального адресного пространства, а семафоры - синхронизировать свое выполнение с выполнением параллельных процессов. Несмотря на то, что они реализуются в виде отдельных блоков, им присущи общие свойства.
С каждым механизмом связана таблица, в записях которой описываются все его детали. В каждой записи содержится числовой ключ (key), который представляет собой идентификатор записи, выбранный пользователем. В каждом механизме имеется системная функция типа "get", используемая для создания новой или поиска существующей записи; параметрами функции являются идентификатор записи и различные флаги (flag). Ядро ведет поиск записи по ее идентификатору в соответствующей таблице. Процессы могут с помощью флага IPC_PRIVATE гарантировать получение еще неиспользуемой записи. С помощью флага IPC_CREAT они могут создать новую запись, если записи с указанным идентификатором нет, а если еще к тому же установить флаг IPC_EXCL, можно получить уведомление об ошибке в том случае, если запись с таким идентификатором существует. Функция возвращает некий выбранный ядром дескриптор, предназначенный для последующего использования в других системных функциях, таким образом, она работает аналогично системным функциям creat и open. В каждом механизме ядро использует следующую формулу для поиска по дескриптору указателя на запись в таблице структур данных: указатель = значение дескриптора по модулю от числа записей в таблице Если, например, таблица структур сообщений состоит из 100 записей, дескрипторы, связанные с записью номер 1, имеют значения, равные 1, 101, 201 и т.д. Когда процесс удаляет запись, ядро увеличивает значение связанного с ней дескриптора на число записей в таблице: полученный дескриптор станет новым дескриптором этой записи, когда к ней вновь будет произведено обращение при помощи функции типа "get". Процессы, которые будут пытаться обратиться к записи по ее старому дескриптору, потерпят неудачу. Обратимся вновь к предыдущему примеру. Если с записью 1 связан дескриптор, имеющий значение 201, при его удалении ядро назначит записи новый дескриптор, имеющий значение 301. Процессы, пытающиеся обратиться к дескриптору 201, получат ошибку, поскольку этого дескриптора больше нет. В конечном итоге ядро произведет перенумерацию дескрипторов, но пока это произойдет, может пройти значительный промежуток времени. Каждая запись имеет некую структуру данных, описывающую права доступа к ней и включающую в себя пользовательский и групповой коды идентификации, которые имеет процесс, создавший запись, а также пользовательский и групповой коды идентификации, установленные системной функцией типа "control" (об этом ниже), и двоичные коды разрешений чтения-записи-исполнения для владельца, группы и прочих пользователей, по аналогии с установкой прав доступа к файлам. В каждой записи имеется другая информация, описывающая состояние записи, в частности, идентификатор последнего из процессов, внесших изменения в запись (посылка сообщения, прием сообщения, подключение разделяемой памяти и т.д.), и время последнего обращения или корректировки. В каждом механизме имеется системная функция типа "control", запрашивающая информацию о состоянии записи, изменяющая эту информацию или удаляющая запись из системы. Когда процесс запрашивает информацию о состоянии записи, ядро проверяет, имеет ли процесс разрешение на чтение записи, после чего копирует данные из записи таблицы по адресу, указанному пользователем. При установке значений принадлежащих записи параметров ядро проверяет, совпадают ли между собой пользовательский код идентификации процесса и идентификатор пользователя (или создателя), указанный в записи, не запущен ли процесс под управлением суперпользователя; одного разрешения на запись недостаточно для установки параметров. Ядро копирует сообщенную пользователем информацию в запись таблицы, устанавливая значения пользовательского и группового кодов идентификации, режимы доступа и другие параметры (в зависимости от типа механизма). Ядро не изменяет значения полей, описывающих пользовательский и групповой коды идентификации создателя записи, поэтому пользователь, создавший запись, сохраняет управляющие права на нее. Пользователь может удалить запись, либо если он является суперпользователем, либо если идентификатор процесса совпадает с любым из идентификаторов, указанных в структуре записи. Ядро увеличивает номер дескриптора, чтобы при следующем назначении записи ей был присвоен новый дескриптор. Следовательно, как уже ранее говорилось, если процесс попытается обратиться к записи по старому дескриптору, вызванная им функция получит отказ.11.3 ВЗАИМОДЕЙСТВИЕ В СЕТИ
11.3 ВЗАИМОДЕЙСТВИЕ В СЕТИ
Программы, поддерживающие межмашинную связь, такие, как электронная почта, программы дистанционной пересылки файлов и удаленной регистрации, издавна используются в качестве специальных средств организации подключений и информационного обмена. Так, например, стандартные программы, работающие в составе электронной почты, сохраняют текст почтовых сообщений пользователя в отдельном файле (для пользователя "mjb" этот файл имеет имя "/usr/mail/mjb"). Когда один пользователь посылает другому почтовое сообщение на ту же машину, программа mail (почта) добавляет сообщение в конец файла адресата, используя в целях сохранения целостности различные блокирующие и временные файлы. Когда адресат получает почту, программа mail открывает принадлежащий ему почтовый файл и читает сообщения. Для того, чтобы послать сообщение на другую машину, программа mail должна в конечном итоге отыскать на ней соответствующий почтовый файл. Поскольку программа не может работать с удаленными файлами непосредственно, процесс, протекающий на другой машине, должен действовать в качестве агента локального почтового процесса; следовательно, локальному процессу необходим способ связи со своим удаленным агентом через межмашинные границы. Локальный процесс является клиентом удаленного обслуживающего (серверного) процесса.
Поскольку в системе UNIX новые процессы создаются с помощью системной функции fork, к тому моменту, когда клиент попытается выполнить подключение, обслуживающий процесс уже должен существовать. Если бы в момент создания нового процесса удаленное ядро получало запрос на подключение (по каналам межмашинной связи), возникла бы несогласованность с архитектурой системы. Чтобы избежать этого, некий процесс, обычно init, порождает обслуживающий процесс, который ведет чтение из канала связи, пока не получает запрос на обслуживание, после чего в соответствии с некоторым протоколом выполняет установку соединения. Выбор сетевых средств и протоколов обычно выполняют программы клиента и сервера, основываясь на информации, хранящейся в прикладных базах данных; с другой стороны, выбранные пользователем средства могут быть закодированы в самих программах.
В качестве примера рассмотрим программу uucp, которая обслуживает пересылку файлов в сети и исполнение команд на удалении (см. [Nowitz 80]). Процесс-клиент запрашивает в базе данных адрес и другую маршрутную информацию (например, номер телефона), открывает автокоммутатор, записывает или проверяет информацию в дескрипторе открываемого файла и вызывает удаленную машину. Удаленная машина может иметь специальные линии, выделенные для использования программой uucp; выполняющийся на этой машине процесс init порождает getty-процессы - серверы, которые управляют линиями и получают извещения о подключениях. После выполнения аппаратного подключения процесс-клиент регистрируется в системе в соответствии с обычным протоколом регистрации: getty-процесс запускает специальный интерпретатор команд, uucico, указанный в файле "/etc/passwd", а процесс-клиент передает на удаленную машину последовательность команд, тем самым заставляя ее исполнять процессы от имени локальной машины.
Сетевое взаимодействие в системе UNIX представляет серьезную проблему, поскольку сообщения должны включать в себя как информационную, так и управляющую части. В управляющей части сообщения может располагаться адрес назначения сообщения. В свою очередь, структура адресных данных зависит от типа сети и используемого протокола. Следовательно, процессам нужно знать тип сети, а это идет вразрез с тем принципом, по которому пользователи не должны обращать внимания на тип файла, ибо все устройства для пользователей выглядят как файлы. Традиционные методы реализации сетевого взаимодействия при установке управляющих параметров в сильной степени полагаются на помощь системной функции ioctl, однако в разных типах сетей этот момент воплощается по-разному. Отсюда возникает нежелательный побочный эффект, связанный с тем, что программы, разработанные для одной сети, в других сетях могут не заработать.
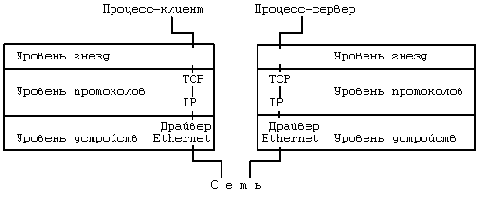
Чтобы разработать сетевые интерфейсы для системы UNIX, были предприняты значительные усилия. Реализация потоков в последних редакциях версии V располагает элегантным механизмом поддержки сетевого взаимодействия, обеспечивающим гибкое сочетание отдельных модулей протоколов и их согласованное использование на уровне задач. Следующий раздел посвящен краткому описанию метода решения данных проблем в системе BSD, основанного на использовании гнезд.
11.4 ГНЕЗДА
11.4 ГНЕЗДА
В предыдущем разделе было показано, каким образом взаимодействуют между собой процессы, протекающие на разных машинах, при этом обращалось внимание на то, что способы реализации взаимодействия могут быть различаться в зависимости от используемых протоколов и сетевых средств. Более того, эти способы не всегда применимы для обслуживания взаимодействия процессов, выполняющихся на одной и той же машине, поскольку в них предполагается существование обслуживающего (серверного) процесса, который при выполнении системных функций open или read будет приостанавливаться драйвером. В целях создания более универсальных методов взаимодействия процессов на основе использования многоуровневых сетевых протоколов для системы BSD был разработан механизм, получивший название "sockets" (гнезда) (см. [Berkeley 83]). В данном разделе мы рассмотрим некоторые аспекты применения гнезд (на пользовательском уровне представления).
11.5 ВЫВОДЫ
11.5 ВЫВОДЫ
Мы рассмотрели несколько форм взаимодействия процессов. Первой формой, положившей начало обсуждению, явилась трассировка процессов - взаимодействие двух процессов, выступающее в качестве полезного средства отладки программ. При всех своих преимуществах трассировка процессов с помощью функции ptrace все же достаточно дорогостоящее и примитивное мероприятие, поскольку за один сеанс функция способна передать строго ограниченный объем данных, требуется большое количество переключений контекста, взаимодействие ограничивается только формой отношений родитель-потомок, и наконец, сама трассировка производится только по обоюдному согласию участвующих в ней процессов. В версии V системы UNIX имеется пакет взаимодействия процессов (IPC), включающий в себя механизмы обмена сообщениями, работы с семафорами и разделения памяти. К сожалению, все эти механизмы имеют узкоспециальное назначение, не имеют хорошей стыковки с другими элементами операционной системы и не действуют в сети. Тем не менее, они используются во многих приложениях и по сравнению с другими схемами отличаются более высокой эффективностью.
Система UNIX поддерживает широкий спектр вычислительных сетей. Традиционные методы согласования протоколов в сильной степени полагаются на помощь системной функции ioctl, однако в разных типах сетей они реализуются по-разному. В системе BSD имеются системные функции для работы с гнездами, поддерживающие более универсальную структуру сетевого взаимодействия. В будущем в версию V предполагается включить описанный в главе 10 потоковый механизм, повышающий согласованность работы в сети.
11.6 УПРАЖНЕНИЯ
11.6 УПРАЖНЕНИЯ
1. Что произойдет в том случае, если в программе debug будет отсутствовать вызов функции wait (Рисунок 11.3)? (Намек: возможны два исхода.)
2. С помощью функции ptrace отладчик считывает данные из пространства трассируемого процесса по одному слову за одну операцию. Какие изменения следует произвести в ядре операционной системы для того, чтобы увеличить количество считываемых слов? Какие изменения при этом необходимо сделать в самой функции ptrace?
3. Расширьте область действия функции ptrace так, чтобы в качестве параметра pid можно было указывать идентификатор процесса, не являющегося потомком текущего процесса. Подумайте над вопросами, связанными с защитой информации: При каких обстоятельствах процессу может быть позволено читать данные из адресного пространства другого, произвольного процесса? При каких обстоятельствах разрешается вести запись в адресное пространство другого процесса?
4. Организуйте из функций работы с сообщениями библиотеку пользовательского уровня с использованием обычных файлов, поименованных каналов и элементов блокировки. Создавая очередь сообщений, откройте управляющий файл для записи в него информации о состоянии очереди; защитите файл с помощью средств захвата файлов и других удобных для вас механизмов. Посылая сообщение данного типа, создавайте поименованный канал для всех сообщений этого типа, если такого канала еще не было, и передавайте сообщение через него (с подсчетом переданных байт). Управляющий файл должен соотносить тип сообщения с именем поименованного канала. При чтении сообщений управляющий файл направляет процесс к соответствующему поименованному каналу. Сравните эту схему с механизмом, описанным в настоящей главе, по эффективности, сложности реализации и функциональным возможностям.
5. Какие действия пытается выполнить программа, представленная на Рисунке 11.22?
*6. Напишите программу, которая подключала бы область разделяемой памяти слишком близко к вершине стека задачи и позволяла бы стеку при увеличении пересекать границу разделяемой области. В какой момент произойдет фатальная ошибка памяти?
7. Используйте в программе, представленной на Рисунке 11.14, флаг IPC_NOWAIT, реализуя условный тип семафора. Продемонстрируйте, как за счет этого можно избежать возникновения взаимных блокировок.
8. Покажите, как операции над семафорами типа P и V реализуются при работе с поименованными каналами. Как бы вы реализовали операцию P условного типа?
9. Составьте программы захвата ресурсов, использующие (а) поименованные каналы, (б) системные функции creat и unlink, (в) функции обмена сообщениями. Проведите сравнительный анализ их эффективности.
10. На практических примерах работы с поименованными каналами сравните эффективность использования функций обмена сообщениями, с одной стороны, с функциями read и write, с другой.
11. Сравните на конкретных программах скорость передачи данных при работе с разделяемой памятью и при использовании механизма обмена сообщениями. Программы, использующие разделяемую память, для синхронизации завершения операций чтения-записи должны опираться на семафоры.
. Адреса некоторых алгоритмов ядра
Рисунок 8.11. Адреса некоторых алгоритмов ядра

На Рисунке 8.11 приведены гипотетические адреса некоторых процедур ядра. Пусть в результате 10 измерений, проведенных в моменты поступления прерываний по таймеру, были получены следующие значения счетчика команд: 110, 330, 145, адрес в пространстве задачи, 125, 440, 130, 320, адрес в пространстве задачи и 104. Ядро сохранит при этом те значения, которые показаны на рисунке. Анализ этих значений показывает, что система провела 20% своего времени в режиме задачи (user) и 50% времени потратила на выполнение алгоритма bread в режиме ядра.
Если измерение параметров ядра выполняется в течение длительного периода времени, результаты измерений приближаются к истинной картине использования системных ресурсов. Тем не менее, описываемый механизм не учитывает время, потраченное на обработку прерываний по таймеру и выполнение процедур, блокирующих поступление прерываний данного типа, поскольку таймер не может прерывать выполнение критических отрезков программ и, таким образом, не может в это время обращаться к подпрограмме обработки прерываний драйвера параметров. В этом недостаток описываемого механизма, ибо критические отрезки программ ядра чаще всего наиболее важны для измерений. Следовательно, результаты измерения параметров ядра содержат определенную долю приблизительности. Уайнбергер [Weinberger 84] описал механизм включения счетчиков в главных блоках программы, таких как "if-then" и "else", с целью повышения точности измерения частоты их выполнения. Однако, данный механизм увеличивает время счета программ на 50-200%, поэтому его использование в качестве постоянного механизма измерения параметров ядра нельзя признать рациональным.
На пользовательском уровне для измерения параметров выполнения процессов можно использовать системную функцию profil:
profil(buff,bufsize,offset,scale);где buff - адрес массива в пространстве задачи, bufsize - размер массива, offset - виртуальный адрес подпрограммы пользователя (обычно, первой по счету), scale - способ отображения виртуальных адресов задачи на адрес массива. Ядро трактует аргумент "scale" как двоичную дробь с фиксированной точкой слева. Так, например, значение аргумента в шестнадцатиричной системе счисления, равное Oxffff, соответствует однозначному отображению счетчика команд на адреса массива, значение, равное Ox7fff, соответствует размещению в одном слове массива buff двух адресов программы, Ox3fff - четырех адресов программы и т.д. Ядро хранит параметры, передаваемые при вызове системной функции, в пространстве процесса. Если таймер прерывает выполнение процесса тогда, когда он находится в режиме задачи, программа обработки прерываний проверяет значение счетчика команд в момент прерывания, сравнивает его со значением аргумента offset и увеличивает содержимое ячейки памяти, адрес которой является функцией от bufsize и scale.
Рассмотрим в качестве примера программу, приведенную на Рисунке 8.12, измеряющую продолжительность выполнения функций f и g. Сначала процесс, используя системную функцию signal, делает указание при получении сигнала о прерывании вызывать функцию theend, затем он вычисляет диапазон адресов программы, в пределах которых будет производиться измерение продолжительности (начиная с адреса функции main и кончая адресом функции theend), и, наконец, запускает функцию profil, сообщая ядру о том, что он собирается начать измерение. В результате выполнения программы в течение 10 секунд на несильно загруженной машине AT&T 3B20 были получены данные, представленные на Рисунке 8.13. Адрес функции f превышает адрес начала профилирования на 204 байта; поскольку текст функции f имеет размер 12 байт, а размер целого числа в машине AT&T 3B20 равен 4 байтам, адреса функции f отображаются на элементы массива buf с номерами 51, 52 и 53. По такому же принципу адреса функции g отображаются на элементы buf c номерами 54, 55 и 56. Элементы buf с номерами 46, 48 и 49 предназначены для адресов, принадлежащих циклу функции main. В обычном случае диапазон адресов, в пределах которого выполняется измерение параметров, определяется в результате обращения к таблице идентификаторов для данной программы, где указываются адреса программных секций. Пользователи сторонятся функции profil из-за того, что она кажется им слишком сложной; вместо нее они используют при компиляции программ на языке Си параметр, сообщающий компилятору о необходимости сгенерировать код, следящий за ходом выполнения процессов.
Адресация физической памяти по страницам
Рисунок 6.3. Адресация физической памяти по страницам
| 58432 | |
| 0101 1000 0100 0011 0010 | |
| 01 0110 0001 | 00 0011 0010 |
| 161 | 32 |
. Адресация страниц, участвующих
Рисунок 9.15. Адресация страниц, участвующих в процессе выполнения функции fork
В ходе выполнения функции fork в системе BSD создается физическая копия страниц родительского процесса. Однако, учитывая наличие ситуаций, в которых создание физической копии не является обязательным, в системе BSD существует также функция vfork, которая используется в том случае, если процесс сразу по завершении функции fork собирается запустить функцию exec. Функция vfork не копирует таблицы страниц, поэтому она работает быстрее, чем функция fork в версии V системы UNIX. Однако процесс-потомок при этом исполняется в тех же самых физических адресах, что и его родитель, и может поэтому затереть данные и стек родительского процесса. Если программист использует функцию vfork неверно, может возникнуть опасная ситуация, поэтому вся ответственность за ее использование возлагается на программиста. Различие в подходах к рассматриваемому вопросу в системах UNIX и BSD имеет философский характер, они дают разный ответ на один и тот же вопрос: следует ли ядру скрывать особенности реализации своих функций, превращая их в тайну для пользователей, или же стоит дать опытным пользователям возможность повысить эффективность выполнения системных операций?
. Алгоритм чтения блока с продвижением
Рисунок 3.14. Алгоритм чтения блока с продвижением
| алгоритм breada /* чтение блока с продвижением */ входная информация: (1) в файловой системе номер блока для немедленного считывания (2) в файловой системе номер блока для асинхронного считывания выходная информация: буфер с данными, считанными немедленно { если (первый блок отсутствует в кеше) { получить буфер для первого блока (алгоритм getblk); если (данные в буфере неверные) приступить к чтению с диска; } если (второй блок отсутствует в кеше) { получить буфер для второго блока (алгоритм getblk); если (данные в буфере верные) освободить буфер (алгоритм brelse); в противном случае приступить к чтению с диска; } если (первый блок первоначально находился в кеше) { считать первый блок (алгоритм bread); возвратить буфер; } приостановиться (до того момента, когда первый буфер будет содержать верные данные); возвратить буфер; } |
Могут возникнуть ситуации, и это будет показано в следующих двух главах, когда ядро не записывает данные немедленно на диск. Если запись "откладывается", ядро соответствующим образом помечает буфер, освобождая его по алгоритму brelse, и продолжает работу без планирования ввода-вывода. Ядро записывает блок на диск перед тем, как другой процесс сможет переназначить буфер другому блоку, как показано в алгоритме getblk (случай 3). Между тем, ядро надеется на то, что процесс получает доступ до того, как буфер будет переписан на диск; если этот процесс впоследствии изменит содержимое буфера, ядро произведет дополнительную операцию по сохранению изменений на диске.
. Алгоритм чтения дискового блока
Рисунок 3.13. Алгоритм чтения дискового блока
| алгоритм bread /* чтение блока */ входная информация: номер блока в файловой системе выходная информация: буфер, содержащий данные { получить буфер для блока (алгоритм getblk); если (данные в буфере правильные) возвратить буфер; приступить к чтению с диска; приостановиться (до завершения операции чтения); возвратить (буфер); } |
Алгоритм записи содержимого буфера в дисковый блок (Рисунок 3.15) похож на алгоритм чтения. Ядро информирует дисковод о том, что есть буфер, содержимое которого должно быть выведено, и дисковод планирует операцию ввода-вывода блока. Если запись производится синхронно, вызывающий процесс приостанавливается, ожидая ее завершения и освобождая буфер в момент возобновления своего выполнения. Если запись производится асинхронно, ядро запускает операцию записи на диск, но не ждет ее завершения. Ядро освободит буфер, когда завершится ввод-вывод.
Алгоритм чтения из файла
Рисунок 5.5. Алгоритм чтения из файла
| алгоритм read входная информация: пользовательский дескриптор файла адрес буфера в пользовательском про- цессе количество байт, которые нужно прочи- тать выходная информация: количество байт, скопированных в поль- зовательское пространство { обратиться к записи в таблице файлов по значению пользо- вательского дескриптора файла; проверить доступность файла; установить параметры в адресном пространстве процесса, указав адрес пользователя, счетчик байтов, параметры ввода-вывода для пользователя; получить индекс по записи в таблице файлов; заблокировать индекс; установить значение смещения в байтах для адресного пространства процесса по значению смещения в таблице файлов; выполнить (пока значение счетчика байтов не станет удов- летворительным) { превратить смещение в файле в номер дискового блока (алгоритм bmap); вычислить смещение внутри блока и количество байт, которые будут прочитаны; если (количество байт для чтения равно 0) /* попытка чтения конца файла */ прерваться; /* выход из цикла */ прочитать блок (алгоритм breada, если производится чтение с продвижением, и алгоритм bread - в против- ном случае); скопировать данные из системного буфера по адресу пользователя; скорректировать значения полей в адресном простран- стве процесса, указывающие смещение в байтах внутри файла, количество прочитанных байт и адрес для пе- редачи в пространство пользователя; освободить буфер; /* заблокированный в алгоритме bread */ } разблокировать индекс; скорректировать значение смещения в таблице файлов для следующей операции чтения; возвратить (общее число прочитанных байт); } |
. Алгоритм чтения с терминала
Рисунок 10.15. Алгоритм чтения с терминала
| алгоритм terminal_read { если (в каноническом символьном списке отсутствуют дан- ные) { выполнить (пока в списке для неструктурированных вводных данных отсутствует информация) { если (терминал открыт с параметром "no delay" (без задержки)) возвратить управление; если (терминал в режиме без обработки с использо- ванием таймера и таймер не активен) предпринять действия к активизации таймера (таблица ответных сигналов); приостановиться (до поступления данных с термина- ла); } /* в списке для неструктурированных вводных данных есть информация */ если (терминал в режиме без обработки) скопировать все данные из списка для неструктури- рованных вводных данных в канонический список; в противном случае /* терминал в каноническом ре- жиме */ { выполнить (пока в списке для неструктурированных вводных данных есть символы) { копировать по одному символу из списка для неструктурированных вводных данных в кано- нический список: выполнить обработку символов стирания и уда- ления; если (символ - "возврат каретки" или "конец файла") прерваться; /* выход из цикла */ } } } выполнить (пока в каноническом списке еще есть символы и не исчерпано количество символов, указанное в вызове функции read) копировать символы из символьных блоков канонического списка в адресное пространство задачи; } |
Обработка символов в направлении ввода и в направлении вывода асимметрична, что видно из наличия двух символьных списков для ввода и одного - для вывода. Строковый интерфейс выводит данные из пространства задачи, обрабатывает их и помещает их в список для хранения выводных данных. Для симметрии следовало бы иметь только один список для вводных данных. Однако, в таком случае потребовалось бы использование программы обработки прерываний для интерпретации символов стирания и удаления, что сделало бы процедуру более сложной и длительной и запретило бы возникновение других прерываний на все критическое время. Использование двух символьных списков для ввода подразумевает, что программа обработки прерываний может просто сбросить символы в список для неструктурированных вводных данных и возобновить выполнение процесса, осуществляющего чтение, который собственно и возьмет на себя работу по интерпретации вводных данных. При этом программа обработки прерываний немедленно помещает введенные символы в список для хранения выводных данных, так что пользователь испытывает лишь минимальную задержку при просмотре введенных символов на терминале.
. Алгоритм демонтирования файловой системы
Рисунок 5.27. Алгоритм демонтирования файловой системы
| алгоритм umount входная информация: имя специального файла, соответствую- щего демонтируемой файловой системе выходная информация: отсутствует { если (пользователь не является суперпользователем) возвратить (ошибку); получить индекс специального файла (алгоритм namei); извлечь старший и младший номера демонтируемого устрой- ства; получить в таблице монтирования запись для демонтируе- мой системы, исходя из старшего и младшего номеров; освободить индекс специального файла (алгоритм iput); удалить из таблицы областей записи с разделяемым текс- том для файлов, принадлежащих файловой системе; /* глава 7ххх */ скорректировать суперблок, индексы, выгрузить буферы на диск; если (какие-то файлы из файловой системы все еще ис- пользуются) возвратить (ошибку); получить из таблицы монтирования корневой индекс монти- рованной файловой системы; заблокировать индекс; освободить индекс (алгоритм iput); /* iget был при монтировании */ запустить процедуру закрытия для специального устрой- ства; сделать недействительными (отменить) в пуле буферы из демонтируемой файловой системы; получить из таблицы монтирования индекс точки монтиро- вания; заблокировать индекс; очистить флаг, помечающий индекс как "точку монтирова- ния"; освободить индекс (алгоритм iput); /* iget был при монтировании */ освободить буфер, используемый под суперблок; освободить в таблице монтирования место, занятое ранее; } |
Алгоритм fork
Рисунок 7.2. Алгоритм fork
| алгоритм fork входная информация: отсутствует выходная информация: для родительского процесса - идентифи- катор (PID) порожденного процесса для порожденного процесса - 0 { проверить доступность ресурсов ядра; получить свободное место в таблице процессов и уникаль- ный код идентификации (PID); проверить, не запустил ли пользователь слишком много процессов; сделать пометку о том, что порождаемый процесс находится в состоянии "создания"; скопировать информацию в таблице процессов из записи, соответствующей родительскому процессу, в запись, соот- ветствующую порожденному процессу; увеличить значения счетчиков ссылок на текущий каталог и на корневой каталог (если он был изменен); увеличить значение счетчика открытий файла в таблице файлов; сделать копию контекста родительского процесса (адресное пространство, команды, данные, стек) в памяти; поместить в стек фиктивный уровень системного контекста над уровнем системного контекста, соответствующим по- рожденному процессу; фиктивный контекстный уровень содержит информацию, необходимую порожденному процессу для того, чтобы знать все о себе и будучи выбранным для исполнения запускаться с этого места; если (в данный момент выполняется родительский процесс) { перевести порожденный процесс в состояние "готовности к выполнению"; возвратить (идентификатор порожденного процесса); /* из системы пользователю */ } в противном случае /* выполняется порожденный процесс */ { записать начальные значения в поля синхронизации ад- ресного пространства процесса; возвратить (0); /* пользователю */ } } |
Затем ядро присваивает начальные значения различным полям записи таблицы процессов, соответствующей порожденному процессу, копируя в них значения полей из записи родительского процесса. Например, порожденный процесс "наследует" у родительского процесса коды идентификации пользователя (реальный и тот, под которым исполняется процесс), группу процессов, управляемую родительским процессом, а также значение, заданное родительским процессом в функции nice и используемое при вычислении приоритета планирования. В следующих разделах мы поговорим о назначении этих полей. Ядро передает значение поля идентификатора родительского процесса в запись порожденного, включая последний в древовидную структуру процессов, и присваивает начальные значения различным параметрам планирования, таким как приоритет планирования, использование ресурсов центрального процессора и другие значения полей синхронизации. Начальным состоянием процесса является состояние "создания" (см. Рисунок 6.1).
После того ядро устанавливает значения счетчиков ссылок на файлы, с которыми автоматически связывается порождаемый процесс. Во-первых, порожденный процесс размещается в текущем каталоге родительского процесса. Число процессов, обращающихся в данный момент к каталогу, увеличивается на 1 и, соответственно, увеличивается значение счетчика ссылок на его индекс. Во-вторых, если родительский процесс или один из его предков уже выполнял смену корневого каталога с помощью функции chroot, порожденный процесс наследует и новый корень с соответствующим увеличением значения счетчика ссылок на индекс корня. Наконец, ядро просматривает таблицу пользовательских дескрипторов для родительского процесса в поисках открытых файлов, известных процессу, и увеличивает значение счетчика ссылок, ассоциированного с каждым из открытых файлов, в глобальной таблице файлов. Порожденный процесс не просто наследует права доступа к открытым файлам, но и разделяет доступ к файлам с родительским процессом, так как оба процесса обращаются в таблице файлов к одним и тем же записям. Действие fork в отношении открытых файлов подобно действию алгоритма dup: новая запись в таблице пользовательских дескрипторов файла указывает на запись в глобальной таблице файлов, соответствующую открытому файлу. Для dup, однако, записи в таблице пользовательских дескрипторов файла относятся к одному процессу; для fork - к разным процессам.
После завершения всех этих действий ядро готово к созданию для порожденного процесса пользовательского контекста. Ядро выделяет память для адресного пространства процесса, его областей и таблиц страниц, создает с помощью алгоритма dupreg копии всех областей родительского процесса и присоединяет с помощью алгоритма attachreg каждую область к порожденному процессу. В системе с подкачкой процессов ядро копирует содержимое областей, не являющихся областями разделяемой памяти, в новую зону оперативной памяти. Вспомним из раздела 6.2.4 о том, что в пространстве процесса хранится указатель на соответствующую запись в таблице процессов. За исключением этого поля, во всем остальном содержимое адресного пространства порожденного процесса в начале совпадает с содержимым пространства родительского процесса, но может расходиться после завершения алгоритма fork. Родительский процесс, например, после выполнения fork может открыть новый файл, к которому порожденный процесс уже не получит доступ автоматически.
Итак, ядро завершило создание статической части контекста порожденного процесса; теперь оно приступает к созданию динамической части. Ядро копирует в нее первый контекстный уровень родительского процесса, включающий в себя сохраненный регистровый контекст задачи и стек ядра в момент вызова функции fork. Если в данной реализации стек ядра является частью пространства процесса, ядро в момент создания пространства порожденного процесса автоматически создает и системный стек для него. В противном случае родительскому процессу придется скопировать в пространство памяти, ассоциированное с порожденным процессом, свой системный стек. В любом случае стек ядра для порожденного процесса совпадает с системным стеком его родителя. Далее ядро создает для порожденного процесса фиктивный контекстный уровень (2), в котором содержится сохраненный регистровый контекст из первого контекстного уровня. Значения счетчика команд (регистр PC) и других регистров, сохраняемые в регистровом контексте, устанавливаются таким образом, чтобы с их помощью можно было "восстанавливать" контекст порожденного процесса, пусть даже последний еще ни разу не исполнялся, и чтобы этот процесс при запуске всегда помнил о том, что он порожденный. Например, если программа ядра проверяет значение, хранящееся в регистре 0, для того, чтобы выяснить, является ли данный процесс родительским или же порожденным, то это значение переписывается в регистровый контекст порожденного процесса, сохраненный в составе первого уровня. Механизм сохранения используется тот же, что и при переключении контекста (см. предыдущую главу).
. Алгоритм функции exec
Рисунок 7.19. Алгоритм функции exec
| алгоритм exec входная информация: (1) имя файла (2) список параметров (3) список переменных среды выходная информация: отсутствует { получить индекс файла (алгоритм namei); проверить, является ли файл исполнимым и имеет ли поль- зователь право на его исполнение; прочитать информацию из заголовков файла и проверить, является ли он загрузочным модулем; скопировать параметры, переданные функции, из старого адресного пространства в системное пространство; для (каждой области, присоединенной к процессу) отсоединить все старые области (алгоритм detachreg); для (каждой области, определенной в загрузочном модуле) { выделить новые области (алгоритм allocreg); присоединить области (алгоритм attachreg); загрузить область в память по готовности (алгоритм loadreg); } скопировать параметры, переданные функции, в новую об- ласть стека задачи; специальная обработка для setuid-программ, трассировка; проинициализировать область сохранения регистров задачи (в рамках подготовки к возвращению в режим задачи); освободить индекс файла (алгоритм iput); } |
На Рисунке 7.19 представлен алгоритм выполнения системной функции exec. Сначала функция обращается к файлу по алгоритму namei, проверяя, является ли файл исполнимым и отличным от каталога, а также проверяя наличие у пользователя права исполнять программу. Затем ядро, считывая заголовок файла, определяет размещение информации в файле (формат файла).
На Рисунке 7.20 изображен логический формат исполняемого файла в файловой системе, обычно генерируемый транслятором или загрузчиком. Он разбивается на четыре части:
Главный заголовок, содержащий информацию о том, на сколько разделов делится файл, а также содержащий начальный адрес исполнения процесса и некоторое "магическое число", описывающее тип исполняемого файла. Заголовки разделов, содержащие информацию, описывающую каждый раздел в файле: его размер, виртуальные адреса, в которых он располагается, и др. Разделы, содержащие собственно "данные" файла (например, текстовые), которые загружаются в адресное пространство процесса. Разделы, содержащие смешанную информацию, такую как таблицы идентификаторов и другие данные, используемые в процессе отладки.. Алгоритм функции exit
Рисунок 7.14. Алгоритм функции exit
| алгоритм exit входная информация: код, возвращаемый родительскому про- цессу выходная информация: отсутствует { игнорировать все сигналы; если (процесс возглавляет группу процессов, ассоцииро- ванную с операторским терминалом) { послать всем процессам, входящим в группу, сигнал о "зависании"; сбросить в ноль код группы процессов; } закрыть все открытые файлы (внутренняя модификация алго- ритма close); освободить текущий каталог (алгоритм iput); освободить области и память, ассоциированную с процессом (алгоритм freereg); создать запись с учетной информацией; прекратить существование процесса (перевести его в соот- ветствующее состояние); назначить всем процессам-потомкам в качестве родителя процесс init (1); если кто-либо из потомков прекратил существование, послать процессу init сигнал "гибель потомка"; послать сигнал "гибель потомка" родителю данного процес- са; переключить контекст; } |
Наконец, ядро освобождает всю выделенную задаче память вместе с соответствующими областями (по алгоритму detachreg) и переводит процесс в состояние прекращения существования. Ядро сохраняет в таблице процессов код возврата функции exit (status), а также суммарное время исполнения процесса и его потомков в режиме ядра и режиме задачи. В разделе 7.4 при рассмотрении функции wait будет показано, каким образом процесс получает информацию о времени выполнения своих потомков. Ядро также создает в глобальном учетном файле запись, которая содержит различную статистическую информацию о выполнении процесса, такую как код идентификации пользователя, использование ресурсов центрального процессора и памяти, объем потоков ввода-вывода, связанных с процессом. Пользовательские программы могут в любой момент обратиться к учетному файлу за статистическими данными, представляющими интерес с точки зрения слежения за функционированием системы и организации расчетов с пользователями. Ядро удаляет процесс из дерева процессов, а его потомков передает процессу 1 (init). Таким образом, процесс 1 становится законным родителем всех продолжающих существование потомков завершающегося процесса. Если кто-либо из потомков прекращает существование, завершающийся процесс посылает процессу init сигнал "гибель потомка" для того, чтобы процесс начальной загрузки мог удалить запись о потомке из таблицы процессов (см. раздел 7.9); кроме того, завершающийся процесс посылает этот сигнал своему родителю. В типичной ситуации родительский процесс синхронизирует свое выполнение с завершающимся потомком с помощью системной функции wait. Прекращая существование, процесс переключает контекст и ядро может теперь выбирать для исполнения следующий процесс; ядро с этих пор уже не будет исполнять процесс, прекративший существование.
В программе, приведенной на Рисунке 7.15, процесс создает новый процесс, который печатает свой код идентификации и вызывает системную функцию pause, приостанавливаясь до получения сигнала. Процесс-родитель печатает PID своего потомка и завершается, возвращая только что выведенное значение через параметр status. Если бы вызов функции exit отсутствовал, начальная процедура сделала бы его по выходе процесса из функции main. Порожденный процесс продолжает ожидать получения сигнала, даже если его родитель уже завершился.
. Алгоритм функции wait
Рисунок 7.16. Алгоритм функции wait
| алгоритм wait входная информация: адрес переменной для хранения значения status, возвращаемого завершающимся процессом выходная информация: идентификатор потомка и код возврата функции exit { если (процесс, вызвавший функцию wait, не имеет потом- ков) возвратить (ошибку); для (;;) /* цикл с внутренним циклом */ { если (процесс, вызвавший функцию wait, имеет потом- ков, прекративших существование) { выбрать произвольного потомка; передать его родителю информацию об использова- нии потомком ресурсов центрального процессора; освободить в таблице процессов место, занимае- мое потомком; возвратить (идентификатор потомка, код возврата функции exit, вызванной потомком); } если (у процесса нет потомков) возвратить ошибку; приостановиться с приоритетом, допускающим прерыва- ния (до завершения потомка); } } |
Например, если пользователь запускает программу, приведенную на Рисунке 7.17, с параметром и без параметра, он получит разные результаты. Сначала рассмотрим случай, когда пользователь запускает программу без параметра (единственный параметр - имя программы, то есть argc равно 1). Родительский процесс порождает 15 потомков, которые в конечном итоге завершают свое выполнение с кодом возврата i, номером процесса в порядке очередности создания. Ядро, исполняя функцию wait для родителя, находит потомка, прекратившего существование, и передает родителю его идентификатор и код возврата функции exit. При этом заранее не известно, какой из потомков будет обнаружен. Из текста программы, реализующей системную функцию exit, написанной на языке Си и включенной в библиотеку стандартных подпрограмм, видно, что программа запоминает код возврата функции exit в битах 8-15 поля ret_code и возвращает функции wait идентификатор процесса-потомка. Таким образом, в ret_code хранится значение, равное 256*i, где i - номер потомка, а в ret_val заносится значение идентификатора потомка.
Если пользователь запускает программу с параметром (то есть argc > 1), родительский процесс с помощью функции signal делает распоряжение игнорировать сигналы типа "гибель потомка". Предположим, что родительский процесс, выполняя функцию wait, приостановился еще до того, как его потомок произвел обращение к функции exit: когда процесс-потомок переходит к выполнению функции exit, он посылает своему родителю сигнал "гибель потомка"; родительский процесс возобновляется, поскольку он был приостановлен с приоритетом, допускающим прерывания. Когда так или иначе родительский процесс продолжит свое выполнение, он обнаружит, что сигнал сообщал о "гибели" потомка; однако, поскольку он игнорирует сигналы этого типа и не обрабатывает их, ядро удаляет из таблицы процессов запись, соответствующую прекратившему существование потомку, и продолжает выполнение функции wait так, словно сигнала и не было. Ядро выполняет эти действия всякий раз, когда родительский процесс получает сигнал типа "гибель потомка", до тех пор, пока цикл выполнения функции wait не будет завершен и пока не будет установлено, что у процесса больше потомков нет. Тогда функция wait возвращает значение, равное -1. Разница между двумя способами запуска программы состоит в том, что в первом случае процесс-родитель ждет завершения любого из потомков, в то время как во втором случае он ждет, пока завершатся все его потомки.
. Алгоритм изменения размера области
Рисунок 6.21. Алгоритм изменения размера области
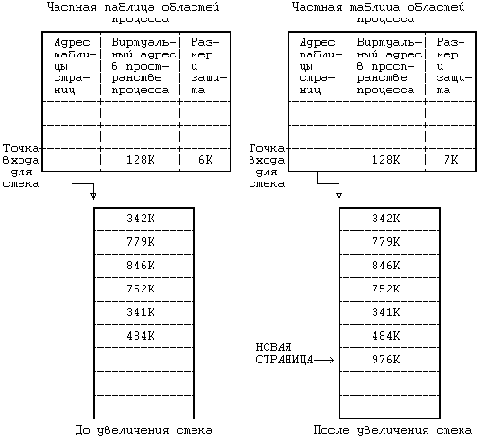
| алгоритм growreg /* изменение размера области */ входная информация: (1) указатель на точку входа в частной таблице областей процесса (2) величина, на которую нужно изме- нить размер области (может быть как положительной, так и отрица- тельной) выходная информация: отсутствует { если (размер области увеличивается) { проверить допустимость нового размера области; выделить вспомогательные таблицы (страниц); если (в системе не поддерживается замещение страниц по обращению) { выделить дополнительную память; проинициализировать при необходимости значения полей в дополнительных таблицах; } } в противном случае /* размер области уменьшается */ { освободить физическую память; освободить вспомогательные таблицы; } провести в случае необходимости инициализацию других вспомогательных таблиц; переустановить значение поля размера в таблице процес- сов; } |
При загрузке файла в область алгоритм loadreg (Рисунок 6.23) проверяет разрыв между виртуальным адресом, по которому область присоединяется к процессу, и виртуальным адресом, с которого располагаются данные области, и расширяет область в соответствии с требуемым объемом памяти. Затем область переводится в состояние "загрузки в память", при котором данные для области считываются из файла в память с помощью встроенной модификации алгоритма системной функции read.
. Алгоритм копирования содержимого существующей области
Рисунок 6.28. Алгоритм копирования содержимого существующей области
| алгоритм dupreg /* копирование содержимого существующей области */ входная информация: указатель на точку входа в таблице об- ластей выходная информация: указатель на область, являющуюся точ- ной копией существующей области { если (область разделяемая) /* в вызывающей программе счетчик ссылок на об- ласть будет увеличен, после чего будет испол- нен алгоритм attachreg */ возвратить (указатель на исходную область); выделить новую область (алгоритм allocreg); установить значения вспомогательных структур управления памятью в точном соответствии со значениями существую- щих структур исходной области; выделить для содержимого области физическую память; "скопировать" содержимое исходной области во вновь соз- данную область; возвратить (указатель на выделенную область); } |
. Алгоритм монтирования файловой системы
Рисунок 5.23. Алгоритм монтирования файловой системы
| алгоритм mount входная информация: имя блочного специального файла имя каталога точки монтирования опции ("только для чтения") выходная информация: отсутствует { если (пользователь не является суперпользователем) возвратить (ошибку); получить индекс для блочного специального файла (алго- ритм namei); проверить допустимость значений параметров; получить индекс для имени каталога, где производится монтирование (алгоритм namei); если (индекс не является индексом каталога или счетчик ссылок имеет значение > 1) { освободить индексы (алгоритм iput); возвратить (ошибку); } найти свободное место в таблице монтирования; запустить процедуру открытия блочного устройства для данного драйвера; получить свободный буфер из буферного кеша; считать суперблок в свободный буфер; проинициализировать поля суперблока; получить корневой индекс монтируемой системы (алгоритм iget), сохранить его в таблице монтирования; сделать пометку в индексе каталога о том, что каталог является точкой монтирования; освободить индекс специального файла (алгоритм iput); снять блокировку с индекса каталога точки монтирования; } |
На Рисунке 5.23 показан алгоритм монтирования файловой системы. Ядро позволяет монтировать и демонтировать файловые системы только тем процессам, владельцем которых является суперпользователь. Предоставление возможности выполнять функции mount и umount всем пользователям привело бы к внесению с их стороны хаоса в работу файловой системы, как умышленному, так и явившемуся результатом неосторожности. Суперпользователи могут разрушить систему только случайно.
Ядро находит индекс специального файла, представляющего файловую систему, подлежащую монтированию, извлекает старший и младший номера, которые идентифицируют соответствующий дисковый раздел, и выбирает индекс каталога, в котором файловая система будет смонтирована. Счетчик ссылок в индексе каталога должен иметь значение, не превышающее 1 (и меньше 1 он не должен быть - почему?), в связи с наличием потенциально опасных побочных эффектов (см. упражнение 5.27). Затем ядро назначает свободное место в таблице монтирования, помечает его для использования и присваивает значение полю номера устройства в таблице. Вышеуказанные назначения производятся немедленно, поскольку вызывающий процесс может приостановиться, следуя процедуре открытия устройства или считывая суперблок файловой системы, а другой процесс тем временем попытался бы смонтировать файловую систему. Пометив для использования запись в таблице монтирования, ядро не допускает использования в двух вызовах функции mount одной и той же записи таблицы. Запоминая номер устройства с монтируемой системой, ядро может воспрепятствовать повторному монтированию одной и той же системы другими процессами, которое, будь оно допущено, могло бы привести к непредсказуемым последствиям (см. упражнение 5.26).
Ядро вызывает процедуру открытия для блочного устройства, содержащего файловую систему, точно так же, как оно делает это при непосредственном открытии блочного устройства (глава 10). Процедура открытия устройства обычно проверяет существование такого устройства, иногда производя инициализацию структур данных драйвера и посылая команды инициализации аппаратуре. Затем ядро выделяет из буферного пула свободный буфер (вариант алгоритма getblk) для хранения суперблока монтируемой файловой системы и считывает суперблок, используя один из вариантов алгоритма read. Ядро сохраняет указатель на индекс каталога, в котором монтируется система, давая возможность маршрутам поиска файловых имен, содержащих имя "..", пересекать точку монтирования, как мы увидим дальше. Оно находит корневой индекс монтируемой файловой системы и запоминает указатель на индекс в таблице монтирования. С точки зрения пользователя, место (точка) монтирования и корень файловой системы логически эквивалентны, и ядро упрочивает эту эквивалентность благодаря их сосуществованию в одной записи таблицы монтирования. Процессы больше не могут обращаться к индексу каталога - точки монтирования.
Ядро инициализирует поля в суперблоке файловой системы, очищая поля для списка свободных блоков и списка свободных индексов и устанавливая число свободных индексов в суперблоке равным 0. Целью инициализации (задания начальных значений полей) является сведение к минимуму опасности разрушить файловую систему, если монтирование осуществляется после аварийного завершения работы системы. Если ядро заставить думать, что в суперблоке отсутствуют свободные индексы, то это приведет к запуску алгоритма ialloc, ведущего поиск на диске свободных индексов. К сожалению, если список свободных дисковых блоков испорчен, ядро не исправляет этот список изнутри (см. раздел 5.17 о сопровождении файловой системы). Если пользователь монтирует файловую систему только для чтения, запрещая проведение всех операций записи в системе, ядро устанавливает в суперблоке соответствующий флаг. Наконец, ядро помечает индекс каталога как "точку монтирования", чтобы другие процессы позднее могли ссылаться на нее. На Рисунке 5.24 представлен вид различных структур данных по завершении выполнения функции mount.
. Алгоритм назначения новых индексов
Рисунок 4.12. Алгоритм назначения новых индексов
| алгоритм ialloc /* выделение индекса */ входная информация: файловая система выходная информация: заблокированный индекс { выполнить { если (суперблок заблокирован) { приостановиться (пока суперблок не освободится); продолжить; /* цикл с условием продолжения */ } если (список индексов в суперблоке пуст) { заблокировать суперблок; выбрать запомненный индекс для поиска свободных индексов; искать на диске свободные индексы до тех пор, пока суперблок не заполнится, или пока не будут най- дены все свободные индексы (алгоритмы bread и brelse); снять блокировку с суперблока; возобновить выполнение процесса (как только супер- блок освободится); если (на диске отсутствуют свободные индексы) возвратить (нет индексов); запомнить индекс с наибольшим номером среди най- денных для последующих поисков свободных индек- сов; } /* список индексов в суперблоке не пуст */ выбрать номер индекса из списка индексов в супербло- ке; получить индекс (алгоритм iget); если (индекс после всего этого не свободен) /* !!! */ { переписать индекс на диск; освободить индекс (алгоритм iput); продолжить; /* цикл с условием продолжения */ } /* индекс свободен */ инициализировать индекс; переписать индекс на диск; уменьшить счетчик свободных индексов в файловой сис- теме; возвратить (индекс); } } |
На Рисунке 4.12 приведен алгоритм ialloc назначения новых индексов. По причинам, о которых пойдет речь ниже, ядро сначала проверяет, не заблокировал ли какой-либо процесс своим обращением список свободных индексов в суперблоке. Если список номеров индексов в суперблоке не пуст, ядро назначает номер следующего индекса, выделяет для вновь назначенного дискового индекса свободный индекс в памяти, используя алгоритм iget (читая индекс с диска, если необходимо), копирует дисковый индекс в память, инициализирует поля в индексе и возвращает индекс заблокированным. Затем ядро корректирует дисковый индекс, указывая, что к индексу произошло обращение. Ненулевое значение поля типа файла говорит о том, что дисковый индекс назначен. В простейшем случае с индексом все в порядке, но в условиях конкуренции делается необходимым проведение дополнительных проверок, на чем мы еще кратко остановимся. Грубо говоря, конкуренция возникает, когда несколько процессов вносят изменения в общие информационные структуры, так что результат зависит от очередности выполнения процессов, пусть даже все процессы будут подчиняться протоколу блокировки. Здесь предполагается, например, что процесс мог бы получить уже используемый индекс. Конкуренция связана с проблемой взаимного исключения, описанной в главе 2, с одним замечанием: различные схемы блокировки решают проблему взаимного исключения, но не могут сами по себе решить все проблемы конкуренции.
Если список свободных индексов в суперблоке пуст, ядро просматривает диск и помещает в суперблок как можно больше номеров свободных индексов. При этом ядро блок за блоком считывает индексы с диска и наполняет список номеров индексов в суперблоке до отказа, запоминая индекс с номером, наибольшим среди найденных. Назовем этот индекс "запомненным"; это последний индекс, записанный в суперблок. В следующий раз, когда ядро будет искать на диске свободные индексы, оно использует запомненный индекс в качестве стартовой точки, благодаря чему гарантируется, что ядру не придется зря тратить время на считывание дисковых блоков, в которых свободные индексы наверняка отсутствуют. После формирования нового набора номеров свободных индексов ядро запускает алгоритм назначения индекса с самого начала. Всякий раз, когда ядро назначает дисковый индекс, оно уменьшает значение счетчика свободных индексов, записанное в суперблоке.
Рассмотрим две пары массивов номеров свободных индексов (Рисунок 4.13). Если список свободных индексов в суперблоке имеет вид первого массива на Рисунке 4.13(а) при назначении индекса ядром, то значение указателя на следующий номер индекса уменьшается до 18 и выбирается индекс с номером 48. Если же список выглядит как первый массив на Рисунке 4.13(б), ядро заметит, что массив пуст и обратится в поисках свободных индексов к диску, при этом поиск будет производиться, начиная с индекса с номером 470, который был ранее запомнен. Когда ядро заполнит список свободных индексов в суперблоке до отказа, оно запомнит последний индекс в качестве начальной точки для последующих просмотров диска. Ядро производит назначение файлу только что выбранного с диска индекса (под номером 471 на рисунке) и продолжает прерванную обработку.
. Алгоритм обработки отказа из-за
Рисунок 9.21. Алгоритм обработки отказа из-за отсутствия (недоступности) данных
| алгоритм vfault /* обработка отказа из-за отсутствия (недоступности) данных */ входная информация: адрес, по которому получен отказ выходная информация: отсутствует { найти область, запись в таблице страниц, дескриптор дис- кового блока, связанные с адресом, по которому получен отказ, заблокировать область; если (адрес не принадлежит виртуальному адресному прост- ранству процесса) { послать сигнал (SIGSEGV: нарушение сегментации) про- цессу; перейти на out; } если (адрес указан неверно) /* возможно, процесс нахо- дился в состоянии при- останова */ перейти на out; если (страница имеется в кэше) { убрать страницу из кэша; поправить запись в таблице страниц; выполнять пока (содержимое страницы не станет доступ- ным) /* другой процесс получил такой же отказ, * но раньше */ приостановиться; } в противном случае /* страница отсутствует в кэше */ { назначить области новую страницу; поместить новую страницу в кэш, откорректировать за- пись в таблице pfdata; если (страница ранее не загружалась в память и имеет пометку "обнуляемая при обращении") очистить содержимое страницы; в противном случае { считать виртуальную страницу с устройства выгруз- ки или из исполняемого файла; приостановиться (до завершения ввода-вывода); } возобновить процессы (ожидающие загрузки содержимого страницы); } установить бит доступности страницы; сбросить бит модификации и "возраст" страницы; пересчитать приоритет процесса; out: снять блокировку с области; } |
При обработке отказов из-за недоступности данных ядро не всегда прибегает к выполнению операции ввода-вывода, даже когда из дескриптора дискового блока видно, что страница загружена (в случае 2). Может случиться так, что ядро после выгрузки содержимого физической страницы так и не переприсвоило ее или же какой-то иной процесс в результате отказа загрузил содержимое виртуальной страницы в другую физическую страницу. В любом случае программа обработки отказа обнаруживает страницу в кэше, в качестве ключа используя номер блока в дескрипторе дискового блока. Она перенастраивает соответствующую запись в таблице страниц на только что найденную страницу, увеличивает значение счетчика ссылок на страницу и в случае необходимости убирает страницу из списка свободных страниц. Предположим, к примеру, что процесс получил отказ при обращении к виртуальному адресу 64К (Рисунок 9.22). Просматривая кэш, ядро устанавливает, что страничный блок с номером 1861 связан с дисковым блоком 1206. Ядро перенастраивает запись таблицы страниц с виртуальным адресом 64К на страницу с номером 1861, устанавливает бит доступности и передает управление программе обработки отказа. Таким образом, номер дискового блока связывает вместе записи таблицы страниц и таблицы pfdata, чем и объясняется его запоминание в обеих таблицах.
. Алгоритм обработки отказа системы
Рисунок 9.25. Алгоритм обработки отказа системы защиты
. Алгоритм обработки прерываний
Рисунок 6.10. Алгоритм обработки прерываний
| алгоритм inthand /* обработка прерываний */ входная информация: отсутствует выходная информация: отсутствует { сохранить (поместить в стек) текущий контекстный уровень; установить источник прерывания; найти вектор прерывания; вызвать программу обработки прерывания; восстановить (извлечь из стека) предыдущий кон- текстный уровень; } |
На Рисунке 6.10 кратко изложено, каким образом ядро обрабатывает прерывания. С помощью использования в отдельных случаях последовательности машинных операций или микрокоманд на некоторых машинах достигается больший эффект по сравнению с тем, когда все операции выполняются программным обеспечением, однако имеются узкие места, связанные с числом сохраняемых контекстных уровней и скоростью выполнения машинных команд, реализующих сохранение контекста. По этой причине определенные операции, выполнения которых требует реализация системы UNIX, являются машинно-зависимыми.
На Рисунке 6.11 показан пример, в котором процесс запрашивает выполнение системной функции (см. следующий раздел) и получает прерывание от диска при ее выполнении. Запустив программу обработки прерывания от диска, система получает прерывание по таймеру и вызывает уже программу обработки прерывания по таймеру. Каждый раз, когда система получает прерывание (или вызывает системную функцию), она создает в стеке новый контекстный уровень и сохраняет регистровый контекст предыдущего уровня.
Алгоритм обработки прерываний по таймеру
Рисунок 8.9. Алгоритм обработки прерываний по таймеру
| алгоритм clock входная информация: отсутствует выходная информация: отсутствует { перезапустить часы; /* чтобы они снова посылали преры- вания */ если (таблица ответных сигналов не пуста) { установить время для ответных сигналов; запустить функцию callout, если время истекло; } если (профилируется выполнение в режиме ядра) запомнить значение счетчика команд в момент прерыва- ния; если (профилируется выполнение в режиме задачи) запомнить значение счетчика команд в момент прерыва- ния; собрать статистику о самой системе; собрать статистику о протекающих в системе процессах; выверить значение продолжительности ИЦП процессом; если (прошла 1 секунда или более и исполняется отрезок, не являющийся критическим) { для (всех процессов в системе) { установить "будильник", если он активен; выверить значение продолжительности ИЦП; если (процесс будет исполняться в режиме задачи) выверить приоритет процесса; } возобновить в случае необходимости выполнение про- цесса подкачки; } } |
Алгоритм обработки сигналов
Рисунок 7.8. Алгоритм обработки сигналов
| алгоритм psig /* обработка сигналов после проверки их существования */ входная информация: отсутствует выходная информация: отсутствует { выбрать номер сигнала из записи таблицы процессов; очистить поле с номером сигнала; если (пользователь ранее вызывал функцию signal, с по- мощью которой сделал указание игнорировать сигнал дан- ного типа) возвратить управление; если (пользователь указал функцию, которую нужно выпол- нить по получении сигнала) { из пространства процесса выбрать пользовательский виртуальный адрес функции обработки сигнала; /* следующий оператор имеет нежелательные побочные эффекты */ очистить поле в пространстве процесса, содержащее адрес функции обработки сигнала; внести изменения в пользовательский контекст: искусственно создать в стеке задачи запись, ими- тирующую обращение к функции обработки сигнала; внести изменения в системный контекст: записать адрес функции обработки сигнала в поле счетчика команд, принадлежащее сохраненному ре- гистровому контексту задачи; возвратить управление; } если (сигнал требует дампирования образа процесса в па- мяти) { создать в текущем каталоге файл с именем "core"; переписать в файл "core" содержимое пользовательско- го контекста; } немедленно запустить алгоритм exit; } |
Обрабатывая сигнал (Рисунок 7.8), ядро определяет тип сигнала и очищает (гасит) разряд в записи таблицы процессов, соответствующий данному типу сигнала и установленный в момент получения сигнала процессом. Если функции обработки сигнала присвоено значение по умолчанию, ядро в отдельных случаях перед завершением процесса сбрасывает на внешний носитель (дампирует) образ процесса в памяти (см. упражнение 7.7). Дампирование удобно для программистов тем, что позволяет установить причину завершения процесса и посредством этого вести отладку программ. Ядро дампирует состояние памяти при поступлении сигналов, которые сообщают о каких-нибудь ошибках в выполнении процессов, как например, попытка исполнения запрещенной команды или обращение к адресу, находящемуся за пределами виртуального адресного пространства процесса. Ядро не дампирует состояние памяти, если сигнал не связан с программной ошибкой. Например, прерывание, вызванное нажатием клавиш "delete" или "break" на терминале, имеет своим результатом посылку сигнала, который сообщает о том, что пользователь хочет раньше времени завершить процесс, в то время как сигнал о "зависании" является свидетельством нарушения связи с регистрационным терминалом. Эти сигналы не связаны с ошибками в протекании процесса. Сигнал о выходе (quit), однако, вызывает сброс состояния памяти, несмотря на то, что он возникает за пределами выполняемого процесса. Этот сигнал, обычно вызываемый одновременным нажатием клавиш <Ctrl/|>, дает программисту возможность получать дамп состояния памяти в любой момент после запуска процесса, что бывает необходимо, если процесс попадает в бесконечный цикл выполнения одних и тех же команд (зацикливается).
Если процесс получает сигнал, на который было решено не обращать внимание, выполнение процесса продолжается так, словно сигнала и не было. Поскольку ядро не сбрасывает значение соответствующего поля, свидетельствующего о необходимости игнорирования сигнала данного типа, то когда сигнал поступит вновь, процесс опять не обратит на него внимание. Если процесс получает сигнал, реагирование на который было признано необходимым, сразу по возвращении процесса в режим задачи выполняется заранее условленное действие, однако прежде чем перевести процесс в режим задачи, ядро еще должно предпринять следующие шаги:
Ядро обращается к сохраненному регистровому контексту задачи и выбирает значения счетчика команд и указателя вершины стека, которые будут возвращены пользовательскому процессу. Сбрасывает в пространстве процесса прежнее значение поля функции обработки сигнала и присваивает ему значение по умолчанию. Создает новую запись в стеке задачи, в которую, при необходимости выделяя дополнительную память, переписывает значения счетчика команд и указателя вершины стека, выбранные ранее из сохраненного регистрового контекста задачи. Стек задачи будет выглядеть так, как будто процесс произвел обращение к пользовательской функции (обработки сигнала) в той точке, где он вызывал системную функцию или где ядро прервало его выполнение (перед опознанием сигнала). Вносит изменения в сохраненный регистровый контекст задачи: устанавливает значение счетчика команд равным адресу функции обработки сигнала, а значение указателя вершины стека равным глубине стека задачи.Таким образом, по возвращении из режима ядра в режим задачи процесс приступит к выполнению функции обработки сигнала; после ее завершения управление будет передано на то место в программе пользователя, где было произведено обращение к системной функции или произошло прерывание, тем самым как бы имитируется выход из системной функции или прерывания.
В качестве примера можно привести программу (Рисунок 7.9), которая принимает сигналы о прерывании (SIGINT) и сама посылает их (в результате выполнения функции kill). На Рисунке 7.10 представлены фрагменты программного кода, полученные в результате дисассемблирования загрузочного модуля в операционной среде VAX 11/780. При выполнении процесса обращение к библиотечной процедуре kill имеет адрес (шестнадцатеричный) ee; эта процедура в свою очередь, прежде чем вызвать системную функцию kill, исполняет команду chmk (перевести процесс в режим ядра) по адресу 10a. Адрес возврата из системной функции - 10c. Во время исполнения системной функции ядро посылает процессу сигнал о прерывании. Ядро обращает внимание на этот сигнал тогда, когда процесс собирается вернуться в режим задачи, выбирая из сохраненного регистрового контекста адрес возврата 10c и помещая его в стек задачи. При этом адрес функции обработки сигнала, 104, ядро помещает в сохраненный регистровый контекст задачи. На Рисунке 7.11 показаны различные состояния стека задачи и сохраненного регистрового контекста.
В рассмотренном алгоритме обработки сигналов имеются некоторые несоответствия. Первое из них и наиболее важное связано с очисткой перед возвращением процесса в режим задачи того поля в пространстве процесса, которое содержит адрес пользовательской функции обработки сигнала. Если процессу снова понадобится обработать сигнал, ему опять придется прибегнуть к помощи системной функции signal. При этом могут возникнуть нежелательные последствия: например, могут создаться условия для конкуренции, если второй раз сигнал поступит до того, как процесс получит возможность запустить системную функцию. Поскольку процесс выполняется в режиме задачи, ядру следовало бы произвести переключение контекста, чтобы увеличить тем самым шансы процесса на получение сигнала до момента сброса значения поля функции обработки сигнала.
. Алгоритм обращения к системным функциям
Рисунок 6.12. Алгоритм обращения к системным функциям
| алгоритм syscall /* алгоритм запуска системной функции */ входная информация: номер системной функции выходная информация: результат системной функции { найти запись в таблице системных функций, соответствую- щую указанному номеру функции; определить количество параметров, передаваемых функции; скопировать параметры из адресного пространства задачи в пространство процесса; сохранить текущий контекст для аварийного завершения (см. раздел 6.44); запустить в ядре исполняемый код системной функции; если (во время выполнения функции произошла ошибка) { установить номер ошибки в нулевом регистре сохра- ненного регистрового контекста задачи; включить бит переноса в регистре PS сохраненного регистрового контекста задачи; } в противном случае занести возвращаемые функцией значения в регистры 0 и 1 в сохраненном регистровом контексте задачи; } |
В качестве примера рассмотрим программу, которая создает файл с разрешением чтения и записи в него для всех пользователей (режим доступа 0666) и которая приведена в верхней части Рисунка 6.13. Далее на рисунке изображен отредактированный фрагмент сгенерированного кода программы после компиляции и дисассемблирования (создания по объектному коду эквивалентной программы на языке ассемблера) в системе Motorola 68000. На Рисунке 6.14 изображена конфигурация стека для системной функции создания. Компилятор генерирует программу помещения в стек задачи двух параметров, один из которых содержит установку прав доступа (0666), а другой - переменную "имя файла" (**). Затем из адреса 64 процесс вызывает библиотечную функцию creat (адрес 7a), аналогичную соответствующей системной функции. Адрес точки возврата из функции 6a, этот адрес помещается процессом в стек. Библиотечная функция creat засылает в регистр 0 константу 8 и исполняет команду прерывания (trap), которая переключает процесс из режима задачи в режим ядра и заставляет его обратиться к системной функции. Заметив, что процесс вызывает системную функцию, ядро выбирает из регистра 0 номер функции (8) и определяет таким образом, что вызвана функция creat. Просматривая внутреннюю таблицу, ядро обнаруживает, что системной функции creat необходимы два параметра; восстанавливая регистровый контекст предыдущего уровня, ядро копирует параметры из пользовательского пространства в пространство процесса. Процедуры ядра, которым понадобятся эти параметры, могут найти их в определенных местах адресного пространства процесса. По завершении исполнения кода функции creat управление возвращается программе обработки обращений к операционной системе, которая проверяет, установлено ли поле ошибки в пространстве процесса (то есть имела ли место во время выполнения функции ошибка); если да, программа устанавливает в регистре PS бит переноса, заносит в регистр 0 код ошибки и возвращает управление ядру. Если ошибок не было, в регистры 0 и 1 ядро заносит код завершения. Возвращая управление из программы обработки обращений к операционной системе в режим задачи, библиотечная функция проверяет состояние бита переноса в регистре PS (по адресу 7): если бит установлен, управление передается по адресу 13c, из нулевого регистра выбирается код ошибки и помещается в глобальную переменную errno по адресу 20, в регистр 0 заносится -1, и управление возвращается на следующую после адреса 64 (где производится вызов функции) команду. Код завершения функции имеет значение -1, что указывает на ошибку в выполнении системной функции. Если же бит переноса в регистре PS при переходе из режима ядра в режим задачи имеет нулевое значение, процесс с адреса 7 переходит по адресу 86 и возвращает управление вызвавшей программе (адрес 64); регистр 0 содержит возвращаемое функцией значение.
Алгоритм опознания сигналов
Рисунок 7.7. Алгоритм опознания сигналов
| алгоритм issig /* проверка получения сигналов */ входная информация: отсутствует выходная информация: "истина", если процесс получил сигна- лы, которые его интересуют "ложь" - в противном случае { выполнить пока (поле в записи таблицы процессов, содер- жащее индикацию о получении сигнала, хранит ненулевое значение) { найти номер сигнала, посланного процессу; если (сигнал типа "гибель потомка") { если (сигналы данного типа игнорируются) освободить записи таблицы процессов, которые соответствуют потомкам, прекратившим существо- вание; в противном случае если (сигналы данного типа при- нимаются) возвратить (истину); } в противном случае если (сигнал не игнорируется) возвратить (истину); сбросить (погасить) сигнальный разряд, установленный в соответствующем поле таблицы процессов, хранящем индикацию получения сигнала; } возвратить (ложь); } |
. Алгоритм освобождения индекса
Рисунок 4.14. Алгоритм освобождения индекса
| алгоритм ifree /* освобождение индекса */ входная информация: номер индекса в файловой системе выходная информация: отсутствует { увеличить на 1 счетчик свободных индексов в файловой системе; если (суперблок заблокирован) возвратить управление; если (список индексов заполнен) { если (номер индекса меньше номера индекса, запом- ненного для последующего просмотра) запомнить для последующего просмотра номер введенного индекса; } в противном случае сохранить номер индекса в списке индексов; возвратить управление; } |
Алгоритм освобождения индекса построен значительно проще. Увеличив на единицу общее количество доступных в файловой системе индексов, ядро проверяет наличие блокировки у суперблока. Если он заблокирован, ядро, чтобы предотвратить конкуренцию, немедленно сообщает: номер индекса отсутствует в суперблоке, но индекс может быть найден на диске и доступен для переназначения. Если список не заблокирован, ядро проверяет, имеется ли место для новых номеров индексов и если да, помещает номер индекса в список и выходит из алгоритма. Если список полон, ядро не сможет в нем сохранить вновь освобожденный индекс. Оно сравнивает номер освобожденного индекса с номером запомненного индекса. Если номер освобожденного индекса меньше номера запомненного, ядро запоминает номер вновь освобожденного индекса, выбрасывая из суперблока номер старого запомненного индекса. Индекс не теряется, поскольку ядро может найти его, просматривая список индексов на диске. Ядро поддерживает структуру списка в суперблоке таким образом, что последний номер, выбираемый им из списка, и есть номер запомненного индекса. В идеале не должно быть свободных индексов с номерами, меньшими, чем номер запомненного индекса, но возможны и исключения.
Рассмотрим два примера освобождения индексов. Если в списке свободных индексов в суперблоке еще есть место для новых номеров свободных индексов (как на Рисунке 4.13(а)), ядро помещает в список новый номер, переставляет указатель на следующий свободный индекс и продолжает выполнение процесса. Но если список свободных индексов заполнен (Рисунок 4.15), ядро сравнивает номер освобожденного индекса с номером запомненного индекса, с которого начнется просмотр диска в следующий раз. Если вначале список свободных индексов имел вид, как на Рисунке 4.15(а), то когда ядро освобождает индекс с номером 499, оно запоминает его и выталкивает номер 535 из списка. Если затем ядро освобождает индекс с номером 601, содержимое списка свободных индексов не изменится. Когда позднее ядро использует все индексы из списка свободных индексов в суперблоке, оно обратится в поисках свободных индексов к диску, при этом, начав просмотр с индекса с номером 499, оно снова обнаружит индексы 535 и 601.
. Алгоритм освобождения области
Рисунок 6.25. Алгоритм освобождения области
| алгоритм freereg /* освобождение выделенной области */ входная информация: указатель на (заблокированную) область выходная информация: отсутствует { если (счетчик ссылок на область имеет ненулевое значе- ние) { /* область все еще используется одним из процессов */ снять блокировку с области; если (область ассоциирована с индексом) снять блокировку с индекса; возвратить управление; } если (область ассоциирована с индексом) освободить индекс (алгоритм iput); освободить связанную с областью физическую память; освободить связанные с областью вспомогательные таблицы; очистить поля области; включить область в список свободных областей; снять блокировку с области; } |
Алгоритм открытия файла
Рисунок 5.2. Алгоритм открытия файла
| алгоритм open входная информация: имя файла режим открытия права доступа (при создании файла) выходная информация: дескриптор файла { превратить имя файла в идентификатор индекса (алгоритм namei); если (файл не существует или к нему не разрешен доступ) возвратить (код ошибки); выделить для индекса запись в таблице файлов, инициали- зировать счетчик, смещение; выделить запись в таблице пользовательских дескрипторов файла, установить указатель на запись в таблице файлов; если (режим открытия подразумевает усечение файла) освободить все блоки файла (алгоритм free); снять блокировку (с индекса); /* индекс заблокирован выше, в алгоритме namei */ возвратить (пользовательский дескриптор файла); } |
Предположим, что процесс, открывая файл "/etc/passwd" дважды, один раз только для чтения и один раз только для записи, и однажды файл "local" для чтения и для записи (**), выполняет следующий набор операторов:
fd1 = open("/etc/passwd",O_RDONLY); fd2 = open("local",O_RDWR); fd3 = open("/etc/passwd",O_WRONLY);На Рисунке 5.3 показана взаимосвязь между таблицей индексов, таблицей файлов и таблицей пользовательских дескрипторов файла. Каждый вызов функции open возвращает процессу дескриптор файла, а соответствующая запись в таблице пользовательских дескрипторов файла указывает на уникальную запись в таблице файлов ядра, пусть даже один и тот же файл ("/etc/passwd") открывается дважды. Записи в таблице файлов для всех экземпляров одного и того же открытого файла указывают на одну запись в таблице индексов, хранящихся в памяти. Процесс может обращаться к файлу "/etc/passwd" с чтением или записью, но только через дескрипторы файла, имеющие значения 3 и 5 (см. Рисунок).Ядро запоминает разрешение на чтение или запись в файл в строке таблицы файлов, выделенной во время выполнения функции open. Предположим, что второй процесс выполняет следующий набор операторов:
(**) В описании вызова системной функции open содержатся три параметра (третий используется при открытии в режиме создания), но программисты обычно используют только первые два из них. Компилятор с языка Си не проверяет правильность количества параметров. В системе первые два параметра и третий (с любым "мусором", что бы ни произошло в стеке) передаются обычно ядру. Ядро не проверяет наличие третьего параметра, если только необходимость в нем не вытекает из значения второго параметра, что позволяет программистам указать только два параметра.
Алгоритм открытия устройства
Рисунок 10.3. Алгоритм открытия устройства
| алгоритм open /* для драйверов устройств */ входная информация: имя пути поиска режим открытия выходная информация: дескриптор файла { преобразовать имя пути поиска в индекс, увеличить значе- ние счетчика ссылок в индексе; выделить в таблице файлов место для пользовательского дескриптора файла, как при открытии обычного файла; выбрать из индекса старший и младший номера устройства; сохранить контекст (алгоритм setjmp) в случае передачи управления от драйвера; если (устройство блочного типа) { использовать старший номер устройства в качестве ука- зателя в таблице ключей устройств ввода-вывода бло- ками; вызвать процедуру открытия драйвера по данному индек- су: передать младший номер устройства, режимы откры- тия; } в противном случае { использовать старший номер устройства в качестве ука- зателя в таблице ключей устройств посимвольного вво- да-вывода; вызвать процедуру открытия драйвера по данному индек- су: передать младший номер устройства, режимы откры- тия; } если (открытие в драйвере не выполнилось) привести таблицу файлов к первоначальному виду, уменьшить значение счетчика в индексе; } |
10.1.2.1 Open
При открытии устройства ядро следует той же процедуре, что и при открытии файлов обычного типа (см. раздел 5.1), выделяя в памяти индексы, увеличивая значение счетчика ссылок и присваивая значение точки входа в таблицу файлов и пользовательского дескриптора файла. Наконец, ядро возвращает значение пользовательского дескриптора файла вызывающему процессу, так что открытие устройства выглядит так же, как и открытие файла обычного типа. Однако, перед тем, как вернуться в режим задачи, ядро запускает зависящую от устройства процедуру open (Рисунок 10.3). Для устройства ввода-вывода блоками запускается процедура open, закодированная в таблице ключей устройств ввода-вывода блоками, для устройств посимвольного ввода-вывода - процедура open, закодированная в соответствующей таблице. Если устройство имеет как блочный, так и символьный тип, ядро запускает процедуру open, соответствующую типу файла устройства, открытого пользователем: обе процедуры могут даже быть идентичны, в зависимости от конкретного драйвера.
Зависящая от типа устройства процедура open устанавливает связь между вызывающим процессом и открываемым устройством и инициализирует информационные структуры драйвера. Например, процедура open для терминала может приостановить процесс до тех пор, пока в машину не поступит сигнал (аппаратный) о том, что пользователь предпринял попытку зарегистрироваться. После этого инициализируются информационные структуры драйвера в соответствии с принятыми установками терминала (например, скоростью передачи информации в бодах). Для "программных устройств", таких как память системы, процедура open может не включать в себя инициализацию.
Если во время открытия устройства процессу пришлось приостановиться по какой-либо из внешних причин, может так случиться, что событие, которое должно было бы вызвать возобновление выполнения процесса, так никогда и не произойдет. Например, если на данном терминале еще не зарегистрировался ни один из пользователей, процесс getty, "открывший" терминал (раздел 7.9), приостанавливается до тех пор, пока пользователем не будет предпринята попытка регистрации, при этом может пройти достаточно большой промежуток времени. Ядро должно иметь возможность возобновить выполнение процесса и отменить вызов функции open по получении сигнала: ему следует сбросить индекс, отменить точку входа в таблице файлов и пользовательский дескриптор файла, которые были выделены перед входом в драйвер, поскольку открытие не произошло. Ядро сохраняет контекст процесса, используя алгоритм setjmp (раздел 6.4.4), прежде чем запустить процедуру open; если процесс возобновляется по сигналу, ядро восстанавливает контекст процесса в том состоянии, которое он имел перед обращением к драйверу, используя алгоритм longjmp (раздел 6.4.4), и возвращает системе все выделенные процедуре open структуры данных. Точно так же и драйвер может уловить сигнал и очистить доступные ему структуры данных, если это необходимо. Ядро также переустанавливает структуры данных файловой системы, когда драйвер сталкивается с исключительными ситуациями, такими, как попытка пользователя обратиться к устройству, отсутствующему в данной конфигурации. В подобных случаях функция open не выполняется.
Процессы могут указывать значения различных параметров, характеризующие особенности выполнения процедуры открытия. Из них наиболее часто используется "no delay" (без задержки), означающее, что процесс не будет приостановлен во время выполнения процедуры open, если устройство не готово. Системная функция open возвращает управление немедленно и пользовательский процесс не узнает, произошло ли аппаратное соединение или нет. Открытие устройства с параметром "no delay", кроме всего прочего, затронет семантику вызова функции read, что мы увидим далее (раздел 10.3.4).
Если устройство открывается многократно, ядро обрабатывает пользовательские дескрипторы файлов, индекс и записи в таблице файлов так, как это описано в главе 5, запуская определяемую типом устройства процедуру open при каждом вызове системной функции open. Таким образом, драйвер устройства может подсчитать, сколько раз устройство было "открыто", и прервать выполнение функции open, если количество открытий приняло недопустимое значение. Например, имеет смысл разрешить процессам многократно "открывать" терминал на запись для того, чтобы пользователи могли обмениваться сообщениями. Но при этом не следует допускать многократного "открытия" печатающего устройства для одновременной записи, так как процессы могут затереть друг другу информацию. Эти различия имеют смысл скорее на практике, нежели на стадии разработки: разрешение одновременной записи на терминалы способствует установлению взаимодействия между пользователями; запрещение одновременной записи на принтеры служит повышению читабельности машинограмм (**).
. Алгоритм отсоединения области
Рисунок 6.26. Алгоритм отсоединения области
| алгоритм detachreg /* отсоединить область от процесса */ входная информация: указатель на точку входа в частной таблице областей процесса выходная информация: отсутствует { обратиться к вспомогательным таблицам процесса, имеющим отношение к распределению памяти, освободить те из них, которые связаны с областью; уменьшить размер процесса; уменьшить значение счетчика ссылок на область; если (значение счетчика стало нулевым и область не явля- ется неотъемлемой частью процесса) освободить область (алгоритм freereg); в противном случае /* либо значение счетчика отлично от 0, либо область является не- отъемлемой частью процесса */ { снять блокировку с индекса (ассоциированного с об- ластью); снять блокировку с области; } } |
. Алгоритм переписи данных на терминал
Рисунок 10.13. Алгоритм переписи данных на терминал
| алгоритм terminal_write { выполнить (пока из пространства задачи еще поступают данные) { если (на терминал поступает информация) { приступить к выполнению операции записи данных из списка, хранящего выводные данные; приостановиться (до того момента, когда терми- нал будет готов принять следующую порцию дан- ных); продолжить; /* возврат к началу цикла */ } скопировать данные в объеме символьного блока из пространства задачи в список, хранящий выводные данные: строковый интерфейс преобразует символы табуляции и т.д.; } приступить к выполнению операции записи данных из спис- ка, хранящего выводные данные; } |
Если на терминал ведут запись несколько процессов, они независимо друг от друга следуют указанной процедуре. Выводимая информация может быть искажена; то есть на терминале данные, записываемые процессами, могут пересекаться. Это может произойти из-за того, что процессы ведут запись на терминал, используя несколько вызовов системной функции write. Ядро может переключать контекст, пока процесс выполняется в режиме задачи, между последовательными вызовами функции write, и вновь запущенные процессы могут вести запись на терминал, пока первый из процессов приостановлен. Выводимые данные могут быть также искажены и на терминале, поскольку процесс может приостановиться на середине выполнения системной функции write, ожидая завершения вывода на терминал из системы предыдущей порции данных. Ядро может запустить другие процессы, которые вели запись на терминал до того, как первый процесс был повторно запущен. По этой причине, ядро не гарантирует, что содержимое буфера данных, выводимое в результате вызова системной функции write, появится на экране терминала в непрерывном виде.
Алгоритм планирования выполнения процессов
Рисунок 8.1. Алгоритм планирования выполнения процессов
| алгоритм schedule_process входная информация: отсутствует выходная информация: отсутствует { выполнять пока (для запуска не будет выбран один из про- цессов) { для (каждого процесса в очереди готовых к выполнению) выбрать процесс с наивысшим приоритетом из загру- женных в память; если (ни один из процессов не может быть избран для выполнения) приостановить машину; /* машина выходит из состояния простоя по преры- /* ванию */ } удалить выбранный процесс из очереди готовых к выполне- нию; переключиться на контекст выбранного процесса, возобно- вить его выполнение; } |
Алгоритм подкачки
Рисунок 9.9. Алгоритм подкачки
| алгоритм swapper /* загрузка выгруженных процессов, * выгрузка других процессов с целью * расчистки места в памяти */ входная информация: отсутствует выходная информация: отсутствует { loop: для (всех выгруженных процессов, готовых к выполнению) выбрать процесс, находящийся в состоянии выгружен- ности дольше остальных; если (таких процессов нет) { приостановиться (до момента, когда возникнет необ- ходимость в загрузке процессов); перейти на loop; } если (в основной памяти достаточно места для размеще- ния процесса) { загрузить процесс; перейти на loop; } /* loop2: сюда вставляются исправления, внесенные в алго- * ритм */ для (всех процессов, загруженных в основную память, кроме прекративших существование и заблокированных в памяти) { если (есть хотя бы один приостановленный процесс) выбрать процесс, у которого сумма приоритета и продолжительности нахождения в памяти наи- большая; в противном случае /* нет ни одного приостанов- * ленного процесса */ выбрать процесс, у которого сумма продолжи- тельности нахождения в памяти и значения nice наибольшая; } если (выбранный процесс не является приостановленным или не соблюдены условия резидентности) приостановиться (до момента, когда появится воз- можность загрузить процесс); в противном случае выгрузить процесс; перейти на loop; /* на loop2 в исправленном алгорит- * ме */ } |
На Рисунке 9.10 показана динамика выполнения пяти процессов с указанием моментов их участия в реализации алгоритма подкачки. Положим для простоты, что все процессы интенсивно используют ресурсы центрального процессора и что они не производят обращений к системным функциям; следовательно, переключение контекста происходит только в результате возникновения прерываний по таймеру с интервалом в 1 секунду. Процесс подкачки исполняется с наивысшим приоритетом планирования, поэтому он всегда укладывается в секундный интервал, когда ему есть что делать. Предположим далее, что процессы имеют одинаковый размер и что в основной памяти могут одновременно поместиться только два процесса. Сначала в памяти находятся процессы A и B, остальные процессы выгружены. Процесс подкачки не может стронуть с места ни один процесс в течение первых двух секунд, поскольку этого требует условие нахождения перемещаемого процесса в течение этого интервала на одном месте (в памяти или на устройстве выгрузки), однако по истечении 2 секунд процесс подкачки выгружает процессы A и B и загружает на их место процессы C и D. Он пытается также загрузить и процесс E, но терпит неудачу, поскольку в основной памяти недостаточно места для этого. На 3-секундной отметке процесс E все еще годен для загрузки, поскольку он находился все 3 секунды на устройстве выгрузки, но процесс подкачки не может выгрузить из памяти ни один из процессов, ибо они находятся в памяти менее 2 секунд. На 4-секундной отметке процесс подкачки выгружает процессы C и D и загружает вместо них процессы E и A.
Процесс подкачки выбирает процессы для загрузки, основываясь на продолжительности их пребывания на устройстве выгрузки. В качестве другого критерия может применяться более высокий приоритет загружаемого процесса по сравнению с остальными, готовыми к выполнению процессами, поскольку такой процесс более предпочтителен для запуска. Практика показала, что такой подход "несколько" повышает пропускную способность системы в условиях сильной загруженности (см. [Peachey 84]).
Алгоритм выбора процесса для выгрузки из памяти с целью освобождения места требуемого объема имеет, однако, более серьезные изъяны. Во-первых, процесс подкачки производит выгрузку на основании приоритета, продолжительности нахождения в памяти и значения nice. Несмотря на то, что он производит выгрузку процесса с единственной целью - освободить в памяти место для загружаемого процесса, он может выгрузить и процесс, который не освобождает место требуемого размера. Например, если процесс подкачки пытается загрузить в память процесс размером 1 Мбайт, а в системе отсутствует свободная память, будет далеко не достаточно выгрузить процесс, занимающий только 2 Кбайта памяти. В качестве альтернативы может быть предложена стратегия выгрузки групп процессов при условии, что они освобождают место, достаточное для размещения загружаемых процессов.Эксперименты с использованием машины PDP 11/23 показали,что в условиях сильной загруженности такая стратегия может увеличить производительность системы почти на 10 процентов (см. [Peachey 84]).
Во-вторых, если процесс подкачки приостановил свою работу изза того, что в памяти не хватило места для загрузки процесса, после возобновления он вновь выбирает процесс для загрузки в память, несмотря на то, что ранее им уже был сделан выбор. Причина такого поведения заключается в том, что за прошедшее время в состояние готовности к выполнению могли перейти другие выгруженные процессы, более подходящие для загрузки в память по сравнению с ранее выбранным процессом. Однако от этого мало утешения для ранее выбранного процесса, все еще пытающегося загрузиться в память. В некоторых реализациях процесс подкачки стремится к тому, чтобы перед загрузкой в память одного крупного процесса выгрузить большое количество процессов маленького размера, это изменение в базовом алгоритме подкачки отражено в комментариях к алгоритму (Рисунок 9.9).
В-третьих, если процесс подкачки выбирает для выгрузки процесс, находящийся в состоянии "готовности к выполнению", не исключена возможность того, что этот процесс после загрузки в память ни разу не был запущен на исполнение. Этот случай показан на Рисунке 9.11, из которого видно, что ядро загружает процесс D на 2- секундной отметке, запускает процесс C, а затем на 3-секундной отметке процесс D выгружается в пользу процесса E (уступая последнему в значении nice), несмотря на то, что процессу D так и не был предоставлен ЦП. Понятно, что такая ситуация является нежелательной.
Следует упомянуть еще об одной опасности. Если при попытке выгрузить процесс на устройстве выгрузки не будет найдено свободное место, в системе может возникнуть тупиковая ситуация, при которой: все процессы в основной памяти находятся в состоянии приостанова, все готовые к выполнению процессы выгружены, для новых процессов на устройстве выгрузки уже нет места, нет свободного места и в основной памяти. Эта ситуация разбирается в упражнении 9.5. Интерес к проблемам, связанным с подкачкой процессов, в последние годы спал в связи с реализацией алгоритмов подкачки страниц памяти.
Алгоритм получения сообщения
Рисунок 11.7. Алгоритм получения сообщения
| алгоритм msgrcv /* получение сообщения */ входная информация: (1) дескриптор сообщения (2) адрес массива, в который заносится сообщение (3) размер массива (4) тип сообщения в запросе (5) флаги выходная информация: количество байт в полученном сообщении { проверить права доступа; loop: проверить правильность дескриптора сообщения; /* найти сообщение, нужное пользователю */ если (тип сообщения в запросе == 0) рассмотреть первое сообщение в очереди; в противном случае если (тип сообщения в запросе > 0) рассмотреть первое сообщение в очереди, имеющее данный тип; в противном случае /* тип сообщения в запросе < 0 */ рассмотреть первое из сообщений в очереди с наи- меньшим значением типа при условии, что его тип не превышает абсолютное значение типа, указанно- го в запросе; если (сообщение найдено) { переустановить размер сообщения или вернуть ошиб- ку, если размер, указанный пользователем слишком мал; скопировать тип сообщения и его текст из прост- ранства ядра в пространство задачи; разорвать связь сообщения с очередью; вернуть управление; } /* сообщений нет */ если (флаги не разрешают приостанавливать работу) вернуть управление с ошибкой; приостановиться (пока сообщение не появится в очере- ди); перейти на loop; } |
Процесс может получать сообщения определенного типа, если присвоит параметру type соответствующее значение. Если это положительное целое число, функция возвращает первое значение данного типа, если отрицательное, ядро определяет минимальное значение типа сообщений в очереди, и если оно не превышает абсолютное значение параметра type, возвращает процессу первое сообщение этого типа. Например, если очередь состоит из трех сообщений, имеющих тип 3, 1 и 2, соответственно, а пользователь запрашивает сообщение с типом -2, ядро возвращает ему сообщение типа 1. Во всех случаях, если условиям запроса не удовлетворяет ни одно из сообщений в очереди, ядро переводит процесс в состояние приостанова, разумеется если только в параметре flag не установлен бит IPC_NOWAIT (иначе процесс немедленно выходит из функции).
Рассмотрим программы, представленные на Рисунках 11.6 и 11.8. Программа на Рисунке 11.8 осуществляет общее обслуживание запросов пользовательских процессов (клиентов). Запросы, например, могут касаться информации, хранящейся в базе данных; обслуживающий процесс (сервер) выступает необходимым посредником при обращении к базе данных, такой порядок облегчает поддержание целостности данных и организацию их защиты от несанкционированного доступа. Обслуживающий процесс создает сообщение путем установки флага IPC _CREAT при выполнении функции msgget и получает все сообщения типа 1 - запросы от процессов-клиентов. Он читает текст сообщения, находит идентификатор процесса-клиента и приравнивает возвращаемое значение типа сообщения значению этого идентификатора. В данном примере обслуживающий процесс возвращает в тексте сообщения процессу-клиенту его идентификатор, и клиент получает сообщения с типом, равным идентификатору клиента. Таким образом, обслуживающий процесс получает сообщения только от клиентов, а клиент - только от обслуживающего процесса. Работа процессов реализуется в виде многоканального взаимодействия, строящегося на основе одной очереди сообщений.
Алгоритм посылки сообщения
Рисунок 11.4. Алгоритм посылки сообщения
| алгоритм msgsnd /* послать сообщение */ входная информация: (1) дескриптор очереди сообщений (2) адрес структуры сообщения (3) размер сообщения (4) флаги выходная информация: количество посланных байт { проверить правильность указания дескриптора и наличие соответствующих прав доступа; выполнить пока (для хранения сообщения не будет выделено место) { если (флаги не разрешают ждать) вернуться; приостановиться (до тех пор, пока место не освобо- дится); } получить заголовок сообщения; считать текст сообщения из пространства задачи в прост- ранство ядра; настроить структуры данных: выстроить очередь заголовков сообщений, установить в заголовке указатель на текст сообщения, заполнить поля, содержащие счетчики, время последнего выполнения операций и идентификатор процес- са; вывести из состояния приостанова все процессы, ожидающие разрешения считать сообщение из очереди; } |
Ядро проверяет (Рисунок 11.4), имеется ли у посылающего сообщение процесса разрешения на запись по указанному дескриптору, не выходит ли размер сообщения за установленную системой границу, не содержится ли в очереди слишком большой объем информации, а также является ли тип сообщения положительным целым числом. Если все условия соблюдены, ядро выделяет сообщению место, используя карту сообщений (см. раздел 9.1 ), и копирует в это место данные из пространства пользователя. К сообщению присоединяется заголовок, после чего оно помещается в конец связного списка заголовков сообщений. В заголовке сообщения записывается тип и размер сообщения, устанавливается указатель на текст сообщения и производится корректировка содержимого различных полей заголовка очереди, содержащих статистическую информацию (количество сообщений в очереди и их суммарный объем в байтах, время последнего выполнения операций и идентификатор процесса, пославшего сообщение). Затем ядро выводит из состояния приостанова все процессы, ожидающие пополнения очереди сообщений. Если размер очереди в байтах превышает границу допустимости, процесс приостанавливается до тех пор, пока другие сообщения не уйдут из очереди. Однако, если процессу было дано указание не ждать (флаг IPC_NOWAIT), он немедленно возвращает управление с уведомлением об ошибке. На Рисунке 11.5 показана очередь сообщений, состоящая из заголовков сообщений, организованных в связные списки, с указателями на область текста.
. Алгоритм превращения имени пути поиска в индекс
Рисунок 4.11. Алгоритм превращения имени пути поиска в индекс
| алгоритм namei /* превращение имени пути поиска в индекс */ входная информация: имя пути поиска выходная информация: заблокированный индекс { если (путь поиска берет начало с корня) рабочий индекс = индексу корня (алгоритм iget); в противном случае рабочий индекс = индексу текущего каталога (алгоритм iget); выполнить (пока путь поиска не кончился) { считать следующую компоненту имени пути поиска; проверить соответствие рабочего индекса каталогу и права доступа; если (рабочий индекс соответствует корню и компо- нента имени "..") продолжить; /* цикл с условием продолжения */ считать каталог (рабочий индекс), повторяя алго- ритмы bmap, bread и brelse; если (компонента соответствует записи в каталоге (рабочем индексе)) { получить номер индекса для совпавшей компонен- ты; освободить рабочий индекс (алгоритм iput); рабочий индекс = индексу совпавшей компоненты (алгоритм iget); } в противном случае /* компонента отсутствует в каталоге */ возвратить (нет индекса); } возвратить (рабочий индекс); } |
Алгоритм namei использует при анализе составного имени пути поиска промежуточные индексы; назовем их рабочими индексами. Индекс каталога, откуда поиск берет начало, является первым рабочим индексом. На каждой итерации цикла алгоритма ядро проверяет совпадение рабочего индекса с индексом каталога. В противном случае, нарушилось бы утверждение, что только файлы, не являющиеся каталогами, могут быть листьями дерева файловой системы. Процесс также должен иметь право производить поиск в каталоге (разрешения на чтение недостаточно). Код идентификации пользователя для процесса должен соответствовать коду индивидуального или группового владельца файла и должно быть предоставлено право исполнения, либо поиск нужно разрешить всем пользователям. В противном случае, поиск не получится.
Ядро выполняет линейный поиск файла в каталоге, ассоциированном с рабочим индексом, пытаясь найти для компоненты имени пути поиска подходящую запись в каталоге. Исходя из адреса смещения в байтах внутри каталога (начиная с 0), оно определяет местоположение дискового блока в соответствии с алгоритмом bmap и считывает этот блок, используя алгоритм bread. По имени компоненты ядро производит в блоке поиск, представляя содержимое блока как последовательность записей каталога. При обнаружении совпадения ядро переписывает номер индекса из данной точки входа, освобождает блок (алгоритм brelse) и старый рабочий индекс (алгоритм iput), и переназначает индекс найденной компоненты (алгоритм iget). Новый индекс становится рабочим индексом. Если ядро не находит в блоке подходящего имени, оно освобождает блок, прибавляет к адресу смещения число байтов в блоке, превращает новый адрес смещения в номер дискового блока (алгоритм bmap) и читает следующий блок. Ядро повторяет эту процедуру до тех пор, пока имя компоненты пути поиска не совпадет с именем точки входа в каталоге, либо до тех пор, пока не будет достигнут конец каталога.
Предположим, например, что процессу нужно открыть файл "/etc/ passwd". Когда ядро начинает анализировать имя файла, оно наталкивается на наклонную черту ("/") и получает индекс корня системы. Сделав корень текущим рабочим индексом, ядро наталкивается на строку "etc". Проверив соответствие текущего индекса каталогу ("/") и наличие у процесса права производить поиск в каталоге, ядро ищет в корневом каталоге файл с именем "etc". Оно просматривает корневой каталог блок за блоком и исследует каждую запись в блоке, пока не обнаружит точку входа для файла "etc". Найдя эту точку входа, ядро освобождает индекс, отведенный для корня (алгоритм iput), и выделяет индекс файлу "etc" (алгоритм iget) в соответствии с номером индекса в обнаруженной записи. Удостоверившись в том, что "etc" является каталогом, а также в том, что имеются необходимые права производить поиск, ядро просматривает каталог "etc" блок за блоком в поисках записи, соответствующей файлу "passwd". Если посмотреть на Рисунок 4.10, можно увидеть, что запись о файле "passwd" является девятой записью в каталоге. Обнаружив ее, ядро освобождает индекс, выделенный файлу "etc", и выделяет индекс файлу "passwd", после чего - поскольку имя пути поиска исчерпано - возвращает этот индекс процессу.
Естественно задать вопрос об эффективности линейного поиска в каталоге записи, соответствующей компоненте имени пути поиска. Ричи показывает (см. [Ritchie 78b], стр.1968), что линейный поиск эффективен, поскольку он ограничен размером каталога. Более того, ранние версии системы UNIX не работали еще на машинах с большим объемом памяти, поэтому значительный упор был сделан на простые алгоритмы, такие как алгоритмы линейного поиска. Более сложные схемы поиска потребовали бы отличной, более сложной, структуры каталога, и возможно работали бы медленнее даже в небольших каталогах по сравнению со схемой линейного поиска.
(**) Чтобы изменить для себя корневой каталог файловой системы, процесс может запустить системную операцию chroot. Новое значение корня сохраняется в рабочей области процесса.
. Алгоритм приостанова процесса
Рисунок 6.31. Алгоритм приостанова процесса
| алгоритм sleep входная информация: (1) адрес приостанова (2) приоритет выходная информация: 1, если процесс возобновляется по сиг- налу, который ему удалось уловить; вызов алгоритма longjump, если процесс возобновляется по сигналу, который ему не удалось уловить; 0 - во всех остальных случаях; { поднять приоритет работы процессора таким образом, чтобы заблокировать все прерывания; перевести процесс в состояние приостанова; включить процесс в хеш-очередь приостановленных процес- сов, базирующуюся на адресах приостанова; сохранить адрес приостанова в таблице процессов; сделать ввод для процесса приоритетным; если (приостанов процесса НЕ допускает прерываний) { выполнить переключение контекста; /* с этого места процесс возобновляет выполнение, когда "пробуждается" */ снизить приоритет работы процессора так, чтобы вновь разрешить прерывания (как было до приостанова про- цесса); возвратить (0); } /* приостанов процесса принимает прерывания, вызванные сигналами */ если (к процессу не имеет отношения ни один из сигналов) { выполнить переключение контекста; /* с этого места процесс возобновляет выполнение, когда "пробуждается" */ если (к процессу не имеет отношения ни один из сигна- лов) { восстановить приоритет работы процессора таким, каким он был в момент приостанова процесса; возвратить (0); } } удалить процесс из хеш-очереди приостановленных процес- сов, если он все еще находится там; восстановить приоритет работы процессора таким, каким он был в момент приостанова процесса; если (приоритет приостановленного процесса позволяет принимать сигналы) возвратить (1); запустить алгоритм longjump; } |
. Алгоритм присоединения области
Рисунок 6.19. Алгоритм присоединения области
| алгоритм attachreg /* присоединение области к процессу */ входная информация: (1) указатель на присоединяемую об- ласть (заблокированную) (2) процесс, к которому присоединяется область (3) виртуальный адрес внутри процесса, по которому будет присоединена об- ласть (4) тип области выходная информация: точка входа в частную таблицу областей процесса { выделить новую запись в частной таблице областей про- цесса; проинициализировать значения полей записи: установить указатель на присоединяемую область; установить тип области; установить виртуальный адрес области; проверить правильность указания виртуального адреса и размера области; увеличить значение счетчика ссылок на область; увеличить размер процесса с учетом присоединения облас- ти; записать начальные значения в новую группу аппаратных регистров; возвратить (точку входа в частную таблицу областей про- цесса); } |
. Алгоритм присоединения разделяемой памяти
Рисунок 11.10. Алгоритм присоединения разделяемой памяти
| алгоритм shmat /* подключить разделяемую память */ входная информация: (1) дескриптор области разделяемой памяти (2) виртуальный адрес для подключения области (3) флаги выходная информация: виртуальный адрес, по которому область подключена фактически { проверить правильность указания дескриптора, права до- ступа к области; если (пользователь указал виртуальный адрес) { округлить виртуальный адрес в соответствии с фла- гами; проверить существование полученного адреса, размер области; } в противном случае /* пользователь хочет, чтобы ядро * само нашло подходящий адрес */ ядро выбирает адрес: в случае неудачи выдается ошибка; присоединить область к адресному пространству процесса (алгоритм attachreg); если (область присоединяется впервые) выделить таблицы страниц и отвести память под нее (алгоритм growreg); вернуть (виртуальный адрес фактического присоединения области); } |
Ядро проверяет возможность размещения области разделяемой памяти в адресном пространстве процесса и присоединяет ее с помощью алгоритма attachreg. Если вызывающий процесс является первым процессом, который присоединяет область, ядро выделяет для области все необходимые таблицы, используя алгоритм growreg, записывает время присоединения в соответствующее поле таблицы разделяемой памяти и возвращает процессу виртуальный адрес, по которому область была им подключена фактически.
Отсоединение области разделяемой памяти от виртуального адресного пространства процесса выполняет функция
shmdt(addr)где addr - виртуальный адрес, возвращенный функцией shmat. Несмотря на то, что более логичной представляется передача идентификатора, процесс использует виртуальный адрес разделяемой памяти, поскольку одна и та же область разделяемой памяти может быть подключена к адресному пространству процесса несколько раз, к тому же ее идентификатор может быть удален из системы. Ядро производит поиск области по указанному адресу и отсоединяет ее от адресного пространства процесса, используя алгоритм detachreg (раздел 6.5.7). Поскольку в таблицах областей отсутствуют обратные указатели на таблицу разделяемой памяти, ядру приходится просматривать таблицу разделяемой памяти в поисках записи, указывающей на данную область, и записывать в соответствующее поле время последнего отключения области.
Рассмотрим программу, представленную на Рисунке 11.11. В ней описывается процесс, создающий область разделяемой памяти размером 128 Кбайт и дважды присоединяющий ее к своему адресному пространству по разным виртуальным адресам. В "первую" область он записывает данные, а читает их из "второй" области. На Рисунке 11.12 показан другой процесс, присоединяющий ту же область (он получает только 64 Кбайта, таким образом, каждый процесс может использовать разный объем области разделяемой памяти); он ждет момента, когда первый процесс запишет в первое принадлежащее области слово любое отличное от нуля значение, и затем принимается считывать данные из области. Первый процесс делает "паузу" (pause), предоставляя второму процессу возможность выполнения; когда первый процесс принимает сигнал, он удаляет область разделяемой памяти из системы.
Процесс запрашивает информацию о состоянии области разделяемой памяти и производит установку параметров для нее с помощью системной функции shmctl:
shmctl(id,cmd,shmstatbuf);Значение id идентифицирует запись таблицы разделяемой памяти, cmd определяет тип операции, а shmstatbuf является адресом пользовательской структуры, в которую помещается информация о состоянии области. Ядро трактует тип операции точно так же, как и при управлении сообщениями. Удаляя область разделяемой памяти, ядро освобождает соответствующую ей запись в таблице разделяемой памяти и просматривает таблицу областей: если область не была присоединена ни к одному из процессов, ядро освобождает запись таблицы и все выделенные области ресурсы, используя для этого алгоритм freereg (раздел 6.5.6). Если же область по-прежнему подключена к каким-то процессам (значение счетчика ссылок на нее больше 0), ядро только сбрасывает флаг, говорящий о том, что по завершении последнего связанного с нею процесса область не должна освобождаться. Процессы, уже использующие область разделяемой памяти, продолжают работать с ней, новые же процессы не могут присоединить ее. Когда все процессы отключат область, ядро освободит ее. Это похоже на то, как в файловой системе после разрыва связи с файлом процесс может вновь открыть его и продолжать с ним работу.
. Алгоритм регистрации
Рисунок 10.19. Алгоритм регистрации
| алгоритм login /* процедура регистрации */ { исполняется getty-процесс: установить группу процессов (вызов функции setpgrp); открыть терминальную линию; /* приостанов до завершения открытия */ если (открытие завершилось успешно) { исполнить программу регистрации: запросить имя пользователя; отключить эхо-сопровождение, запросить пароль; если (регистрация прошла успешно) /* найден соответствующий пароль в /etc/passwd */ { перевести терминал в канонический режим (ioctl); исполнить shell; } в противном случае считать количество попыток регистрации, пытаться зарегистрироваться снова до достижения опреде- ленной точки; } } |
(****) В этом разделе рассматривается использование терминалов ввода-вывода, которые передают все символы, введенные пользователем, без обработки.
(*****) В данной главе используется общий термин "возврат каретки" для обозначения символов возврата каретки и перевода строки.