. Алгоритм смены текущего каталога
Рисунок 5.14. Алгоритм смены текущего каталога
| алгоритм смены каталога входная информация: имя нового каталога выходная информация: отсутствует { получить индекс для каталога с новым именем (алгоритм namei); если (индекс не является индексом каталога или же про- цессу не разрешен доступ к файлу) { освободить индекс (алгоритм iput); возвратить (ошибку); } снять блокировку с индекса; освободить индекс прежнего текущего каталога (алгоритм iput); поместить новый индекс в позицию для текущего каталога в пространстве процесса; } |
. Алгоритм создания файла
Рисунок 5.12. Алгоритм создания файла
| алгоритм creat входная информация: имя файла установки прав доступа к файлу выходная информация: дескриптор файла { получить индекс для данного имени файла (алгоритм namei); если (файл уже существует) { если (доступ не разрешен) { освободить индекс (алгоритм iput); возвратить (ошибку); } } в противном случае /* файл еще не существует */ { назначить свободный индекс из файловой системы (алго- ритм ialloc); создать новую точку входа в родительском каталоге: включить имя нового файла и номер вновь назначенного индекса; } выделить для индекса запись в таблице файлов, инициализи- ровать счетчик; если (файл существовал к моменту создания) освободить все блоки файла (алгоритм free); снять блокировку (с индекса); возвратить (пользовательский дескриптор файла); } |
Ядро проводит синтаксический анализ имени пути поиска, используя алгоритм namei и следуя этому алгоритму буквально, когда речь идет о разборе имен каталогов. Однако, когда дело касается последней компоненты имени пути поиска, а именно идентификатора создаваемого файла, namei отмечает смещение в байтах до первой пустой позиции в каталоге и запоминает это смещение в пространстве процесса. Если ядро не обнаружило в каталоге компоненту имени пути поиска, оно в конечном счете впишет имя компоненты в только что найденную пустую позицию. Если в каталоге нет пустых позиций, ядро запоминает смещение до конца каталога и создает новую позицию там. Оно также запоминает в пространстве процесса индекс просматриваемого каталога и держит индекс заблокированным; каталог становится по отношению к новому файлу родительским каталогом. Ядро не записывает пока имя нового файла в каталог, так что в случае возникновения ошибок ядру приходится меньше переделывать. Оно проверяет наличие у процесса разрешения на запись в каталог. Поскольку процесс будет производить запись в каталог в результате выполнения функции creat, наличие разрешения на запись в каталог означает, что процессам дозволяется создавать файлы в каталоге.
Предположив, что под данным именем ранее не существовало файла, ядро назначает новому файлу индекс, используя алгоритм ialloc (раздел 4.6). Затем оно записывает имя нового файла и номер вновь выделенного индекса в родительский каталог, а смещение в байтах сохраняет в пространстве процесса. Впоследствии ядро освобождает индекс родительского каталога, удерживаемый с того времени, когда в каталоге производился поиск имени файла. Родительский каталог теперь содержит имя нового файла и его индекс. Ядро записывает вновь выделенный индекс на диск (алгоритм bwrite), прежде чем записать на диск каталог с новым именем. Если между операциями записи индекса и каталога произойдет сбой системы, в итоге окажется, что выделен индекс, на который не ссылается ни одно из имен путей поиска в системе, однако система будет функционировать нормально. Если, с другой стороны, каталог был записан раньше вновь выделенного индекса и сбой системы произошел между ними, файловая система будет содержать имя пути поиска, ссылающееся на неверный индекс (более подробно об этом см. в разделе 5.16.1).
Если данный файл уже существовал до вызова функции creat, ядро обнаруживает его индекс во время поиска имени файла. Старый файл должен позволять процессу производить запись в него, чтобы можно было создать "новый" файл с тем же самым именем, так как ядро изменяет содержимое файла при выполнении функции creat: оно усекает файл, освобождая все информационные блоки по алгоритму free, так что файл будет выглядеть как вновь созданный. Тем не менее, владелец и права доступа к файлу остаются прежними: ядро не передает право собственности на файл владельцу процесса и игнорирует права доступа, указанные процессом в вызове функции. Наконец, ядро не проверяет наличие разрешения на запись в каталог, являющийся родительским для существующего файла, поскольку оно не меняет содержимого каталога.
Функция creat продолжает работу, выполняя тот же алгоритм, что и функция open. Ядро выделяет созданному файлу запись в таблице файлов, чтобы процесс мог читать из файла, а также запись в таблице пользовательских дескрипторов файла, и в конце концов возвращает указатель на последнюю запись в виде пользовательского дескриптора файла.
(***) Системная функция open имеет два флага, O_CREAT (создание) и O_TRUNC (усечение). Если процесс устанавливает в вызове функции флаг O_CREAT и файл не существует, ядро создаст файл. Если файл уже существует, он не будет усечен, если только не установлен флаг O_TRUNC.
. Алгоритм создания каналов (непоименованных)
Рисунок 5.16. Алгоритм создания каналов (непоименованных)
| алгоритм pipe входная информация: отсутствует выходная информация: дескриптор файла для чтения дескриптор файла для записи { назначить новый индекс из устройства канала (алгоритм ialloc); выделить одну запись в таблице файлов для чтения, одну - для переписи; инициализировать записи в таблице файлов таким образом, чтобы они указывали на новый индекс; выделить один пользовательский дескриптор файла для чте- ния, один - для записи, проинициализировать их таким образом, чтобы они указывали на соответствующие точки входа в таблице файлов; установить значение счетчика ссылок в индексе равным 2; установить значение счетчика числа процессов, производя- щих чтение, и процессов, производящих запись, равным 1; } |
На Рисунке 5.16 показан алгоритм создания непоименованных каналов. Ядро назначает индекс для канала из файловой системы, обозначенной как "устройство канала", используя алгоритм ialloc. Устройство канала - это именно та файловая система, из которой ядро может назначать каналам индексы и выделять блоки для данных. Администраторы системы указывают устройство канала при конфигурировании системы и эти устройства могут совпадать у разных файловых систем. Пока канал активен, ядро не может переназначить индекс канала и информационные блоки канала другому файлу.
Затем ядро выделяет в таблице файлов две записи, соответствующие дескрипторам для чтения и записи в канал, и корректирует "бухгалтерскую" информацию в копии индекса в памяти. В каждой из выделенных записей в таблице файлов хранится информация о том, сколько экземпляров канала открыто для чтения или записи (первоначально 1), а счетчик ссылок в индексе указывает, сколько раз канал был "открыт" (первоначально 2 - по одному для каждой записи таблицы файлов). Наконец, в индексе записываются смещения в байтах внутри канала до места, где будет начинаться следующая операция записи или чтения. Благодаря сохранению этих смещений в индексе имеется возможность производить доступ к данным в канале в порядке их поступления в канал ("первым пришел первым вышел"); этот момент является особенностью каналов, поскольку для обычных файлов смещения хранятся в таблице файлов. Процессы не могут менять эти смещения с помощью системной функции lseek и поэтому произвольный доступ к данным канала невозможен.
. Алгоритм создания новой вершины
Рисунок 5.13. Алгоритм создания новой вершины
| алгоритм создания новой вершины входная информация: вершина (имя файла) тип файла права доступа старший, младший номера устройства (для блочных и символьных специальных файлов) выходная информация: отсутствует { если (новая вершина не является поименованным каналом и пользователь не является суперпользователем) возвратить (ошибку); получить индекс вершины, являющейся родительской для новой вершины (алгоритм namei); если (новая вершина уже существует) { освободить родительский индекс (алгоритм iput); возвратить (ошибку); } назначить для новой вершины свободный индекс из файловой системы (алгоритм ialloc); создать новую запись в родительском каталоге: включить имя новой вершины и номер вновь назначенного индекса; освободить индекс родительского каталога (алгоритм iput); если (новая вершина является блочным или символьным спе- циальным файлом) записать старший и младший номера в структуру индек- са; освободить индекс новой вершины (алгоритм iput); } |
Ядро просматривает файловую систему в поисках имени файла, который оно собирается создать. Если файл еще пока не существует, ядро назначает ему новый индекс на диске и записывает имя нового файла и номер индекса в родительский каталог. Оно устанавливает значение поля типа файла в индексе, указывая, что файл является каналом, каталогом или специальным файлом. Наконец, если файл является специальным файлом устройства блочного или символьного типа, ядро записывает в индекс старший и младший номера устройства. Если функция mknod создает каталог, он будет существовать по завершении выполнения функции, но его содержимое будет иметь неверный формат (в каталоге будут отсутствовать записи с именами "." и ".."). В упражнении 5.33 рассматриваются шаги, необходимые для преобразования содержимого каталога в правильный формат.
. Алгоритм связывания файлов
Рисунок 5.29. Алгоритм связывания файлов
| алгоритм link входная информация: существующее имя файла новое имя файла выходная информация: отсутствует { получить индекс для существующего имени файла (алгоритм namei); если (у файла слишком много связей или производится связывание каталога без разрешения суперпользователя) { освободить индекс (алгоритм iput); возвратить (ошибку); } увеличить значение счетчика связей в индексе; откорректировать дисковую копию индекса; снять блокировку с индекса; получить индекс родительского каталога для включения но- вого имени файла (алгоритм namei); если (файл с новым именем уже существует или существую- щий файл и новый файл находятся в разных файловых сис- темах) { отменить корректировку, сделанную выше; возвратить (ошибку); } создать запись в родительском каталоге для файла с но- вым именем: включить в нее новое имя и номер индекса существую- щего файла; освободить индекс родительского каталога (алгоритм iput); освободить индекс существующего файла (алгоритм iput); } |
На Рисунке 5.29 показан алгоритм функции link. Сначала ядро, используя алгоритм namei, определяет местонахождение индекса исходного файла, увеличивает значение счетчика связей в индексе, корректирует дисковую копию индекса (для обеспечения согласованности) и снимает с индекса блокировку. Затем ядро ищет файл с новым именем; если он существует, функция link завершается неудачно и ядро восстанавливает прежнее значение счетчика связей, измененное ранее. В противном случае ядро находит в родительском каталоге свободную запись для файла с новым именем, записывает в нее новое имя и номер индекса исходного файла и освобождает индекс родительского каталога, используя алгоритм iput. Поскольку файл с новым именем ранее не существовал, освобождать еще какой-нибудь индекс не нужно. Ядро, освобождая индекс исходного файла, делает заключение: счетчик связей в индексе имеет значение, на 1 большее, чем то значение, которое счетчик имел перед вызовом функции, и обращение к файлу теперь может производиться по еще одному имени в файловой системе. Счетчик связей хранит количество записей в каталогах, которые (записи) указывают на файл, и тем самым отличается от счетчика ссылок в индексе. Если по завершении выполнения функции link к файлу нет обращений со стороны других процессов, счетчик ссылок в индексе принимает значение, равное 0, а счетчик связей - значение, большее или равное 2.
Например, выполняя функцию, вызванную как:
link("source","/dir/target");ядро обнаруживает индекс для файла "source", увеличивает в нем значение счетчика связей, запоминает номер индекса, скажем 74, и снимает с индекса блокировку. Ядро также находит индекс каталога "dir", являющегося родительским каталогом для файла "target", ищет свободное место в каталоге "dir" и записывает в него имя файла "target" и номер индекса 74. По окончании этих действий оно освобождает индекс файла "source" по алгоритму iput. Если значение счетчика связей файла "source" раньше было равно 1, то теперь оно равно 2.
Стоит упомянуть о двух тупиковых ситуациях, явившихся причиной того, что процесс снимает с индекса исходного файла блокировку после увеличения значения счетчика связей. Если бы ядро не снимало с индекса блокировку, два процесса, выполняющие одновременно следующие функции:
процесс A: link("a/b/c/d","e/f/g"); процесс B: link("e/f","a/b/c/d/ee");зашли бы в тупик (взаимная блокировка). Предположим, что процесс A обнаружил индекс файла "a/b/c/d" в тот самый момент, когда процесс B обнаружил индекс файла "e/f". Фраза "в тот же самый момент" означает, что системой достигнуто состояние, при котором каждый процесс получил искомый индекс. (Рисунок 5.30 иллюстрирует стадии выполнения процессов.) Когда же теперь процесс A попытается получить индекс файла "e/f", он приостановит свое выполнение до тех пор, пока индекс файла "f" не освободится. В то же время процесс B пытается получить индекс каталога "a/b/c/d" и приостанавливается в ожидании освобождения индекса файла "d". Процесс A будет удерживать заблокированным индекс, нужный процессу B, а процесс B, в свою очередь, будет удерживать заблокированным индекс, нужный процессу A. На практике этот классический пример взаимной блокировки невозможен благодаря тому, что ядро освобождает индекс исходного файла после увеличения значения счетчика связей. Поскольку первый из ресурсов (индекс) свободен при обращении к следующему ресурсу, взаимная блокировка не происходит.
Следующий пример показывает, как два процесса могут зайти в тупик, если с индекса не была снята блокировка. Одиночный процесс может также заблокировать самого себя. Если он вызывает функцию:
link("a/b/c","a/b/c/d");то в начале алгоритма он получает индекс для файла "c"; если бы ядро не снимало бы с индекса блокировку, процесс зашел бы в тупик, запросив индекс "c" при поиске файла "d". Если бы два процесса, или даже один процесс, не могли продолжать свое выполнение из-за взаимной блокировки (или самоблокировки), что в результате произошло бы в системе? Поскольку индексы являются теми ресурсами, которые предоставляются системой за конечное время, получение сигнала не может быть причиной возобновления процессом своей работы (глава 7). Следовательно, система не может выйти из тупика без перезагрузки. Если к файлам, заблокированным процессами, нет обращений со стороны других процессов, взаимная блокировка не затрагивает остальные процессы в системе. Однако, любые процессы, обратившиеся к этим файлам (или обратившиеся к другим файлам через заблокированный каталог), непременно зайдут в тупик. Таким образом, если заблокированы файлы "/bin" или "/usr/bin" (обычные хранилища команд) или файл "/bin/sh" (командный процессор shell), последствия для системы будут гибельными.
. Алгоритм удаления связи файла с каталогом
Рисунок 5.31. Алгоритм удаления связи файла с каталогом
| алгоритм unlink входная информация: имя файла выходная информация: отсутствует { получить родительский индекс для файла с удаляемой связью (алгоритм namei); /* если в качестве файла выступает текущий каталог... */ если (последней компонентой имени файла является ".") увеличить значение счетчика ссылок в индексе; в противном случае получить индекс для файла с удаляемой связью (алго- ритм iget); если (файл является каталогом, но пользователь не явля- ется суперпользователем) { освободить индексы (алгоритм iput); возвратить (ошибку); } если (файл имеет разделяемый текст и текущее значение счетчика связей равно 1) удалить записи из таблицы областей; в родительском каталоге: обнулить номер индекса для уда- ляемой связи; освободить индекс родительского каталога (алгоритм iput); уменьшить число связей файла; освободить индекс файла (алгоритм iput); /* iput проверяет, равно ли число связей 0, если * да, * освобождает блоки файла (алгоритм free) и * освобождает индекс (алгоритм ifree); */ } |
. Алгоритм возобновления приостановленного процесса
Рисунок 6.32. Алгоритм возобновления приостановленного процесса
| алгоритм wakeup /* возобновление приостановленного про- цесса */ входная информация: адрес приостанова выходная информация: отсутствует { повысить приоритет работы процессора таким образом, что- бы заблокировать все прерывания; найти хеш-очередь приостановленных процессов с указанным адресом приостанова; для (каждого процесса, приостановленного по указанному адресу) { удалить процесс из хеш-очереди; сделать пометку о том, что процесс находится в состо- янии "готовности к запуску"; включить процесс в список процессов, готовых к запус- ку (для планировщика процессов); очистить поле, содержащее адрес приостанова, в записи таблицы процессов; если (процесс не загружен в память) возобновить выполнение программы подкачки (нуле- вой процесс); в противном случае если (возобновляемый процесс более подходит для ис- полнения, чем ныне выполняющийся) установить соответствующий флаг для планировщи- ка; } восстановить первоначальный приоритет работы процессора; } |
Чтобы возобновить выполнение приостановленных процессов, ядро обращается к алгоритму wakeup (Рисунок 6.32), причем делает это как во время исполнения алгоритмов реализации стандартных системных функций, так и в случае обработки прерываний. Алгоритм iput, например, освобождает заблокированный индекс и возобновляет выполнение всех процессов, ожидающих снятия блокировки. Точно так же и программа обработки прерываний от диска возобновляет выполнение процессов, ожидающих завершения ввода-вывода. В алгоритме wakeup ядро сначала повышает приоритет работы процессора, чтобы заблокировать прерывания. Затем для каждого процесса, приостановленного по указанному адресу, выполняются следующие действия: делается пометка в поле, описывающем состояние процесса, о том, что процесс готов к запуску; процесс удаляется из списка приостановленных процессов и помещается в список процессов, готовых к запуску; поле в записи таблицы процессов, содержащее адрес приостанова, очищается. Если возобновляемый процесс не загружен в память, ядро запускает процесс подкачки, обеспечивающий подкачку возобновляемого процесса в память (подразумевается система, в которой подкачка страниц по обращению не поддерживается); в противном случае, если возобновляемый процесс более подходит для исполнения, чем ныне выполняющийся, ядро устанавливает для планировщика специальный флаг, сообщающий о том, что процессу по возвращении в режим задачи следует пройти через алгоритм планирования (глава 8). Наконец, ядро восстанавливает первоначальный приоритет работы процессора. При этом на ядро не оказывается никакого давления: "пробуждение" (wakeup) процесса не вызывает его немедленного исполнения; благодаря "пробуждению", процесс становится только доступным для запуска.
Все, о чем говорилось выше, касается простейшего случая выполнения алгоритмов sleep и wakeup, поскольку предполагается, что процесс приостанавливается до наступления соответствующего события. Во многих случаях процессы приостанавливаются в ожидании событий, которые "должны" наступить, например, в ожидании освобождения ресурса (индексов или буферов) или в ожидании завершения ввода-вывода, связанного с диском. Уверенность процесса в неминуемом возобновлении основана на том, что подобные ресурсы могут быть предоставлены только во временное пользование. Тем не менее, иногда процесс может приостановиться в ожидании события, не будучи уверенным в неизбежном наступлении последнего, в таком случае у процесса должна быть возможность в любом случае вернуть себе управление и продолжить выполнение. В подобных ситуациях ядро немедленно нарушает "сон" приостановленного процесса, посылая ему сигнал. Более подробно о сигналах мы поговорим в следующей главе; здесь же примем допущение, что ядро может (выборочно) возобновлять приостановленные процессы по сигналу и что процесс может распознавать получаемые сигналы.
Например, если процесс обратился к системной функции чтения с терминала, ядро не будет в состоянии выполнить запрос процесса до тех пор, пока пользователь не введет данные с клавиатуры терминала (глава 10). Тем не менее, пользователь, запустивший процесс, может оставить терминал на весь день, при этом процесс останется приостановленным в ожидании ввода, а терминал может понадобиться другому пользователю. Если другой пользователь прибегнет к решительным мерам (таким как выключение терминала), ядро должно иметь возможность восстановить отключенный процесс: в качестве первого шага ядру следует возобновить приостановленный процесс по сигналу. В том, что процессы могут приостановиться на длительное время, нет ничего плохого. Приостановленный процесс занимает позицию в таблице процессов и может поэтому удлинять время поиска (ожидания) путем выполнения определенных алгоритмов, которые не занимают время центрального процессора и поэтому выполняются практически незаметно.
Чтобы как-то различать между собой состояния приостанова, ядро устанавливает для приостанавливаемого процесса (при входе в это состояние) приоритет планирования на основании соответствующего параметра алгоритма sleep. То есть ядро запускает алгоритм sleep с параметром "приоритет", в котором отражается наличие уверенности в неизбежном наступлении ожидаемого события. Если приоритет превышает пороговое значение, процесс не будет преждевременно выходить из приостанова по получении сигнала, а будет продолжать ожидать наступления события. Если же значение приоритета ниже порогового, процесс будет немедленно возобновлен по получении сигнала (****).
Проверка того, имеет ли процесс уже сигнал при входе в алгоритм sleep, позволяет выяснить, приостанавливался ли процесс ранее. Например, если значение приоритета в вызове алгоритма sleep превышает пороговое значение, процесс приостанавливается в ожидании выполнения алгоритма wakeup. Если же значение приоритета ниже порогового, выполнение процесса не приостанавливается, но на сигнал процесс реагирует точно так же, как если бы он был приостановлен. Если ядро не проверит наличие сигналов перед приостановом, возможна опасность, что сигнал больше не поступит вновь и в этом случае процесс никогда не возобновится.
Когда процесс "пробуждается" по сигналу (или когда он не переходит в состояние приостанова из-за наличия сигнала), ядро может выполнить алгоритм longjump (в зависимости от причины, по которой процесс был приостановлен). С помощью алгоритма longjump ядро восстанавливает ранее сохраненный контекст, если нет возможности завершить выполняемую системную функцию. Например, если из-за того, что пользователь отключил терминал, было прервано чтение данных с терминала, функция read не будет завершена, но возвратит признак ошибки. Это касается всех системных функций, которые могут быть прерваны во время приостанова. После выхода из приостанова процесс не сможет нормально продолжаться, поскольку ожидаемое событие не наступило. Перед выполнением большинства системных функций ядро сохраняет контекст процесса, используя алгоритм setjump и вызывая тем самым необходимость в последующем выполнении алгоритма longjump.
Встречаются ситуации, когда ядро требует, чтобы процесс возобновился по получении сигнала, но не выполняет алгоритм longjump. Ядро запускает алгоритм sleep со специальным значением параметра "приоритет", подавляющим исполнение алгоритма longjump и заставляющим алгоритм sleep возвращать код, равный 1. Такая мера более эффективна по сравнению с немедленным выполнением алгоритма setjump перед вызовом sleep и последующим выполнением алгоритма longjump для восстановления первоначального контекста процесса. Задача заключается в том, чтобы позволить ядру очищать локальные структуры данных. Драйвер устройства, например, может выделить свои частные структуры данных и приостановиться с приоритетом, допускающим прерывания; если по сигналу его работа возобновляется, он освобождает выделенные структуры, а затем выполняет алгоритм longjump, если необходимо. Пользователь не имеет возможности проконтролировать, выполняет ли процесс алгоритм longjump; выполнение этого алгоритма зависит от причины приостановки процесса, а также от того, требуют ли структуры данных ядра внесения изменений перед выходом из системной функции.
(****) Словами "выше" и "ниже" мы заменяем термины "высокий приоритет" и "низкий приоритет". Однако на практике приоритет может измеряться числами, более низкие значения которых подразумевают более высокий приоритет.
Алгоритм выделения буфера
Рисунок 3.4. Алгоритм выделения буфера
| алгоритм getblk входная информация: номер файловой системы номер блока выходная информация: буфер, который можно использовать для блока { выполнить если (буфер не найден) { если (блок в хеш-очереди) { если (буфер занят) /* случай 5 */ { приостановиться (до освобождения буфера); продолжить; /* цикл с условием продолжения */ } пометить буфер занятым; /* случай 1 */ удалить буфер из списка свободных буферов; вернуть буфер; } в противном случае /* блока нет в хеш-очереди */ { если (в списке нет свободных буферов) /*случай 4*/ { приостановиться (до освобождения любого буфера); продолжить; /* цикл с условием продолжения */ } удалить буфер из списка свободных буферов; если (буфер помечен для отложенной переписи) /* случай 3 */ { асинхронная перепись содержимого буфера на диск; продолжить; /* цикл с условием продолжения */ } /* случай 2 -- поиск свободного буфера */ удалить буфер из старой хеш-очереди; включить буфер в новую хеш-очередь; вернуть буфер; } } } |
. Алгоритм выделения дискового блока
Рисунок 4.19. Алгоритм выделения дискового блока
| алгоритм alloc /* выделение блока файловой системы */ входная информация: номер файловой системы выходная информация: буфер для нового блока { выполнить (пока суперблок заблокирован) приостановиться (до того момента, когда с суперблока будет снята блокировка); удалить блок из списка свободных блоков в суперблоке; если (из списка удален последний блок) { заблокировать суперблок; прочитать блок, только что взятый из списка свобод- ных (алгоритм bread); скопировать номера блоков, хранящиеся в данном бло- ке, в суперблок; освободить блочный буфер (алгоритм brelse); снять блокировку с суперблока; возобновить выполнение процессов (после снятия бло- кировки с суперблока); } получить буфер для блока, удаленного из списка (алго- ритм getblk); обнулить содержимое буфера; уменьшить общее число свободных блоков; пометить суперблок как "измененный"; возвратить буфер; } |
Алгоритмы назначения и освобождения индексов и дисковых блоков сходятся в том, что ядро использует суперблок в качестве кеша, хранящего указатели на свободные ресурсы - номера блоков и номера индексов. Оно поддерживает список номеров блоков с указателями, такой, что каждый номер свободного блока в файловой системе появляется в некотором элементе списка, но ядро не поддерживает такого списка для свободных индексов. Тому есть три причины.
Ядро устанавливает, свободен ли индекс или нет, проверяя: если поле типа файла очищено, индекс свободен. Ядро не нуждается в другом механизме описания свободных индексов. Тем не менее, оно не может определить, свободен ли блок или нет, только взглянув на него. Ядро не может уловить различия между маской, показывающей, что блок свободен, и информацией, случайно имеющей сходную маску. Следовательно, ядро нуждается во внешнем механизме идентификации свободных блоков, в качестве него в традиционных реализациях системы используется список с указателями. Сама конструкция дисковых блоков наводит на мысль об использовании списков с указателями: в дисковом блоке легко разместить большие списки номеров свободных блоков. Но индексы не имеют подходящего места для массового хранения списков номеров свободных индексов. Пользователи имеют склонность чаще расходовать дисковые блоки, нежели индексы, поэтому кажущееся запаздывание в работе при просмотре диска в поисках свободных индексов не является таким критическим, как если бы оно имело место при поисках свободных дисковых блоков.Алгоритм выделения индексов в памяти
Рисунок 4.3. Алгоритм выделения индексов в памяти
| алгоритм iget входная информация: номер индекса в файловой системе выходная информация: заблокированный индекс { выполнить { если (индекс в индексном кеше) { если (индекс заблокирован) { приостановиться (до освобождения индекса); продолжить; /* цикл с условием продолжения */ } /* специальная обработка для точек монтирования (глава 5) */ если (индекс в списке свободных индексов) убрать из списка свободных индексов; увеличить счетчик ссылок для индекса; возвратить (индекс); } /* индекс отсутствует в индексном кеше */ если (список свободных индексов пуст) возвратить (ошибку); убрать новый индекс из списка свободных индексов; сбросить номер индекса и файловой системы; убрать индекс из старой хеш-очереди, поместить в новую; считать индекс с диска (алгоритм bread); инициализировать индекс (например, установив счетчик ссылок в 1); возвратить (индекс); } } |
Если ядро знает номера устройства и дискового блока, оно читает блок, используя алгоритм bread (глава 2), затем вычисляет смещение индекса в байтах внутри блока по формуле:
((номер индекса - 1) модуль (число индексов в блоке)) * * размер дискового индексаНапример, если каждый дисковый индекс занимает 64 байта и в блоке помещаются 8 индексов, тогда индекс с номером 8 имеет адрес со смещением 448 байт от начала дискового блока. Ядро убирает индекс в памяти из списка свободных индексов, помещает его в соответствующую хеш-очередь и устанавливает значение счетчика ссылок равным 1. Ядро переписывает поля типа файла и владельца файла, установки прав доступа, число указателей на файл, размер файла и таблицу адресов из дискового индекса в память и возвращает заблокированный в памяти индекс.
Ядро манипулирует с блокировкой индекса и счетчиком ссылок независимо один от другого. Блокировка - это установка, которая действует на время выполнения системного вызова и имеет целью запретить другим процессам обращаться к индексу пока тот в работе (и возможно хранит противоречивые данные). Ядро снимает блокировку по окончании обработки системного вызова: блокировка индекса никогда не выходит за границы системного вызова. Ядро увеличивает значение счетчика ссылок с появлением каждой активной ссылки на файл. Например, в разделе 5.1 будет показано, как ядро увеличивает значение счетчика ссылок тогда, когда процесс открывает файл. Оно уменьшает значение счетчика ссылок только тогда, когда ссылка становится неактивной, например, когда процесс закрывает файл. Таким образом, установка счетчика ссылок сохраняется для множества системных вызовов. Блокировка снимается между двумя обращениями к операционной системе, чтобы позволить процессам одновременно производить разделенный доступ к файлу; установка счетчика ссылок действует между обращениями к операционной системе, чтобы предупредить переназначение ядром активного в памяти индекса. Таким образом, ядро может заблокировать и разблокировать выделенный индекс независимо от значения счетчика ссылок. Выделением и освобождением индексов занимаются и отличные от open системные операции, в чем мы и убедимся в главе 5.
Возвращаясь к алгоритму iget, заметим, что если ядро пытается взять индекс из списка свободных индексов и обнаруживает список пустым, оно сообщает об ошибке. В этом отличие от идеологии, которой следует ядро при работе с дисковыми буферами, где процесс приостанавливает свое выполнение до тех пор, пока буфер не освободится. Процессы контролируют выделение индексов на пользовательском уровне посредством запуска системных операций open и close и поэтому ядро не может гарантировать момент, когда индекс станет доступным. Следовательно, процесс, приостанавливающий свое выполнение в ожидании освобождения индекса, может никогда не возобновиться. Ядро скорее прервет выполнение системного вызова, чем оставит такой процесс в "зависшем" состоянии. Однако, процессы не имеют такого контроля над буферами. Поскольку процесс не может удержать буфер заблокированным в течение выполнения нескольких системных операций, ядро здесь может гарантировать скорое освобождение буфера, и процесс поэтому приостанавливается до того момента, когда он станет доступным.
В предшествующих параграфах рассматривался случай, когда ядро выделяет индекс, отсутствующий в индексном кеше. Если индекс находится в кеше, процесс (A) обнаружит его в хеш-очереди и проверит, не заблокирован ли индекс другим процессом (B). Если индекс заблокирован, процесс A приостанавливается и выставляет флаг у индекса в памяти, показывая, что он ждет освобождения индекса. Когда позднее процесс B разблокирует индекс, он "разбудит" все процессы (включая процесс A), ожидающие освобождения индекса. Когда же наконец процесс A сможет использовать индекс, он заблокирует его, чтобы другие процессы не могли к нему обратиться. Если первоначально счетчик ссылок имел значение, равное 0, индекс также появится в списке свободных индексов, поэтому ядро уберет его оттуда: индекс больше не является свободным. Ядро увеличивает значение счетчика ссылок и возвращает заблокированный индекс.
Если суммировать все вышесказанное, можно отметить, что алгоритм iget имеет отношение к начальной стадии системных вызовов, когда процесс впервые обращается к файлу. Этот алгоритм возвращает заблокированную индексную структуру со значением счетчика ссылок, на 1 большим, чем оно было раньше. Индекс в памяти содержит текущую информацию о состоянии файла. Ядро снимает блокировку с индекса перед выходом из системной операции, поэтому другие системные вызовы могут обратиться к индексу, если пожелают. В главе 5 рассматриваются эти случаи более подробно.
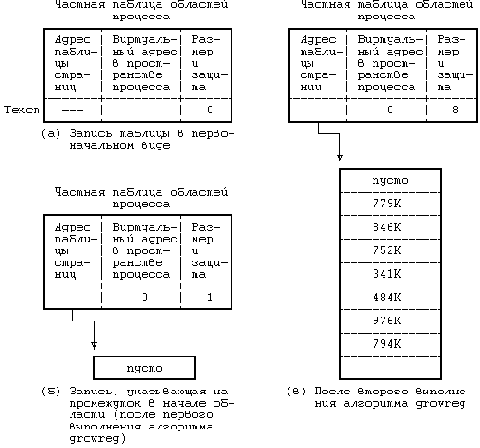
. Алгоритм выделения областей
h2>. Взаимосвязь между таблицей индексов и таблицей областей в случае совместного использования процессами одной области команд
| алгоритм xalloc /* выделение и инициализация области команд */ входная информация: индекс исполняемого файла выходная информация: отсутствует { если (исполняемый файл не имеет отдельной области команд) вернуть управление; если (уже имеется область команд, ассоциированная с ин- дексом исполняемого файла) { /* область команд уже существует ... подключиться к ней */ заблокировать область; выполнить пока (содержимое области еще не доступно) { /* операции над счетчиком ссылок, предохраняющие от глобального удаления области */ увеличить значение счетчика ссылок на область; снять с области блокировку; приостановиться (пока содержимое области не станет доступным); заблокировать область; уменьшить значение счетчика ссылок на область; } присоединить область к процессу (алгоритм attachreg); снять с области блокировку; вернуть управление; } /* интересующая нас область команд не существует -- соз- дать новую */ выделить область команд (алгоритм allocreg); /* область заблоки- рована */ если (область помечена как "неотъемлемая") отключить соответствующий флаг; подключить область к виртуальному адресу, указанному в заголовке файла (алгоритм attachreg); если (файл имеет специальный формат для системы с замеще- нием страниц) /* этот случай будет рассмотрен в главе 9 */ в противном случае /* файл не имеет специального фор- мата */ считать команды из файла в область (алгоритм loadreg); изменить режим защиты области в записи частной таблицы областей процесса на "read-only"; снять с области блокировку; } |
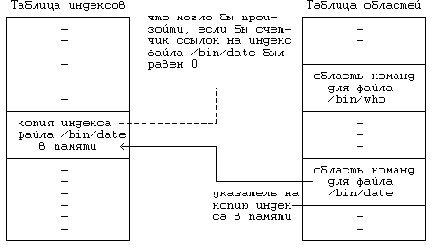
Рассмотрим в качестве примера ситуацию, приведенную на Рисунке 7.21, где показана взаимосвязь между структурами данных в процессе выполнения функции exec по отношению к файлу "/bin/date" при условии расположения команд и данных файла в разных областях. Когда процесс исполняет файл "/bin/date" первый раз, ядро назначает для команд файла точку входа в таблице областей (Рисунок 7.24) и по завершении выполнения функции exec оставляет счетчик ссылок на индекс равным 1. Когда файл "/bin/date" завершается, ядро запускает алгоритмы detachreg и freereg, сбрасывая значение счетчика ссылок в 0. Однако, если ядро в первом случае не увеличило значение счетчика, оно по завершении функции exec останется равным 0 и индекс на всем протяжении выполнения процесса будет находиться в списке свободных индексов. Предположим, что в это время свободный индекс понадобился процессу, запустившему с помощью функции exec файл "/bin/who", тогда ядро может выделить этому процессу индекс, ранее принадлежавший файлу "/ bin/date". Просматривая таблицу областей в поисках индекса файла "/bin/who", ядро вместо него выбрало бы индекс файла "/bin/date". Считая, что область содержит команды файла "/bin/who", ядро исполнило бы совсем не ту программу. Поэтому значение счетчика ссылок на индекс активного файла, связанного с разделяемой областью команд, должно быть не меньше единицы, чтобы ядро не могло переназначить индекс другому файлу.
Возможность совместного использования различными процессами одних и тех же областей команд позволяет экономить время, затрачиваемое на запуск программы с помощью функции exec. Администраторы системы могут с помощью системной функции (и команды) chmod устанавливать для часто исполняемых файлов режим "sticky-bit", сущность которого заключается в следующем. Когда процесс исполняет файл, для которого установлен режим "sticky-bit", ядро не освобождает область памяти, отведенную под команды файла, отсоединяя область от процесса во время выполнения функций exit или exec, даже если значение счетчика ссылок на индекс становится равным 0. Ядро оставляет область команд в первоначальном виде, при этом значение счетчика ссылок на индекс равно 1, пусть даже область не подключена больше ни к одному из процессов. Если же файл будет еще раз запущен на выполнение (уже другим процессом), ядро в таблице областей обнаружит запись, соответствующую области с командами файла. Процесс затратит на запуск файла меньше времени, так как ему не придется читать команды из файловой системы. Если команды файла все еще находятся в памяти, в их перемещении не будет необходимости; если же команды выгружены во внешнюю память, будет гораздо быстрее загрузить их из внешней памяти, чем из файловой системы (см. об этом в главе 9).
Ядро удаляет из таблицы областей записи, соответствующие областям с командами файла, для которого установлен режим "sticky-bit" (иными словами, когда область помечена как "неотъемлемая" часть файла или процесса), в следующих случаях:
Если процесс открыл файл для записи, в результате соответствующих операций содержимое файла изменится, при этом будет затронуто и содержимое области. Если процесс изменил права доступа к файлу (chmod), отменив режим "sticky-bit", файл не должен оставаться в таблице областей. Если процесс разорвал связь с файлом (unlink), он не сможет больше исполнять этот файл, поскольку у файла не будет точки входа в файловую систему; следовательно, и все остальные процессы не будут иметь доступа к записи в таблице областей, соответствующей файлу. Поскольку область с командами файла больше не используется, ядро может освободить ее вместе с остальными ресурсами, занимаемыми файлом. Если процесс демонтирует файловую систему, файл перестает быть доступным и ни один из процессов не может его исполнить. В остальном - все как в предыдущем случае. Если ядро использовало уже все пространство внешней памяти, отведенное под выгрузку задач, оно пытается освободить часть памяти за счет областей, имеющих пометку "sticky-bit", но не используемых в настоящий момент. Несмотря на то, что эти области могут вскоре понадобиться другим процессам, потребности ядра являются более срочными.В первых двух случаях область команд с пометкой "sticky-bit" должна быть освобождена, поскольку она больше не отражает текущее состояние файла. В остальных случаях это делается из практических соображений. Конечно же ядро освобождает область только при том условии, что она не используется ни одним из выполняющихся процессов (счетчик ссылок на нее имеет нулевое значение); в противном случае это привело бы к аварийному завершению выполнения системных функций open, unlink и umount (случаи 1, 3 и 4, соответственно).
Если процесс запускает с помощью функции exec самого себя, алгоритм выполнения функции несколько усложняется. По команде sh script командный процессор shell порождает новый процесс (новую ветвь), который инициирует запуск shell'а (с помощью функции exec) и исполняет команды файла "script". Если процесс запускает самого себя и при этом его область команд допускает совместное использование, ядру придется следить за тем, чтобы при обращении ветвей процесса к индексам и областям не возникали взаимные блокировки. Иначе говоря, ядро не может, не снимая блокировки со "старой" области команд, попытаться заблокировать "новую" область, поскольку на самом деле это одна и та же область. Вместо этого ядро просто оставляет "старую" область команд присоединенной к процессу, так как в любом случае ей предстоит повторное использование.
Обычно процессы вызывают функцию exec после функции fork; таким образом, во время выполнения функции fork процесс-потомок копирует адресное пространство своего родителя, но сбрасывает его во время выполнения функции exec и по сравнению с родителем исполняет образ уже другой программы. Не было бы более естественным объединить две системные функции в одну, которая бы загружала программу и исполняла ее под видом нового процесса? Ричи высказал предположение, что возникновение fork и exec как отдельных системных функций обязано тому, что при создании системы UNIX функция fork была добавлена к уже существующему образу ядра системы (см. [Ritchie 84a], стр.1584). Однако, разделение fork и exec важно и с функциональной точки зрения, поскольку в этом случае процессы могут работать с дескрипторами файлов стандартного ввода-вывода независимо, повышая тем самым "элегантность" использования каналов. Пример, показывающий использование этой возможности, приводится в разделе 7.8.
(**) В PDP 11 "магические числа" имеют значения, соответствующие командам перехода; при выполнении этих команд в ранних версиях системы управление передавалось в разные места программы в зависимости от размера заголовка и от типа исполняемого файла. Эта особенность больше не используется с тех пор, как система стала разрабатываться на языке Си.
(***) Например, в версии V стандартные программы переименования файла (mv), копирования файла (cp) и компоновки файла (ln), поскольку исполняют похожие действия, вызывают один и тот же исполняемый файл. По имени вызываемой программы процесс узнает, какие действия в настоящий момент требуются пользователю.
. Алгоритм выделения области
Рисунок 6.18. Алгоритм выделения области
| алгоритм allocreg /* разместить информационную структуру области */ входная информация: (1) указатель индекса (2) тип области выходная информация: заблокированная область { выбрать область из списка свободных областей; назначить области тип; присвоить значение указателю индекса; если (указатель индекса имеет ненулевое значение) увеличить значение счетчика ссылок на индекс; включить область в список активных областей; возвратить (заблокированную область); } |
Алгоритм выделения пространства с помощью карт памяти
Рисунок 9.2. Алгоритм выделения пространства с помощью карт памяти
| алгоритм malloc /* алгоритм выделения пространства с ис- пользованием карты памяти */ входная информация: (1) адрес /* указывает на тип ис- пользуемой карты */ (2) требуемое число единиц ресурса выходная информация: адрес - в случае успешного завершения 0 - в противном случае { для (каждой строки карты) { если (требуемое число единиц ресурса располагается в строке карты) { если (требуемое число == числу единиц в строке) удалить строку из карты; в противном случае отрегулировать стартовый адрес в строке; вернуть (первоначальный адрес строки); } } вернуть (0); } |
Освобождая ресурсы, ядро ищет для них соответствующее место в карте по адресу. При этом возможны три случая:
Освободившиеся ресурсы полностью закрывают пробел в карте памяти. Другими словами, они имеют смежные адреса с адресами ресурсов из строк, непосредственно предшествующей и следующей за данной. В этом случае ядро объединяет вновь освободившиеся ресурсы с ресурсами из указанных строк в одну строку карты памяти. Освободившиеся ресурсы частично закрывают пробел в карте памяти. Если они имеют адрес, смежный с адресом ресурсов из строки, непосредственно предшествующей или непосредственно следующей за данной (но не с адресами из обеих строк), ядро переустанавливает значение адреса и числа ресурсов в соответствующей строке с учетом вновь освободившихся ресурсов. Число строк в карте памяти остается неизменным. Освободившиеся ресурсы частично закрывают пробел в карте памяти, но их адреса не соприкасаются с адресами каких-либо других ресурсов карты. Ядро создает новую строку и вставляет ее в соответствующее место в карте.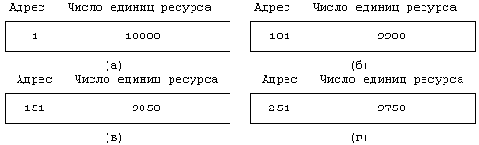
. Алгоритм выполнения функции brk
Рисунок 7.26. Алгоритм выполнения функции brk
| алгоритм brk входная информация: новый адрес верхней границы области данных выходная информация: старый адрес верхней границы области данных { заблокировать область данных процесса; если (размер области увеличивается) если (новый размер области имеет недопустимое зна- чение) { снять блокировку с области; вернуть (ошибку); } изменить размер области (алгоритм growreg); обнулить содержимое присоединяемого пространства; снять блокировку с области данных; } |
На Рисунке 7.27 приведен пример программы, использующей функцию brk, и выходные данные, полученные в результате ее прогона на машине AT&T 3B20. Вызвав функцию signal и распорядившись принимать сигналы о нарушении сегментации (segmentation violation), процесс обращается к подпрограмме sbrk и выводит на печать первоначальное значение адреса верхней границы области данных. Затем в цикле, используя счетчик символов, процесс заполняет область данных до тех пор, пока не обратится к адресу, расположенному за пределами области, тем самым давая повод для сигнала о нарушении сегментации. Получив сигнал, функция обработки сигнала вызывает подпрограмму sbrk для того, чтобы присоединить к области дополнительно 256 байт памяти; процесс продолжается с точки прерывания, заполняя информацией вновь выделенное пространство памяти и т.д. На машинах со страничной организацией памяти, таких как 3B20, наблюдается интересный феномен. Страница является наименьшей единицей памяти, с которой работают механизмы аппаратной защиты, поэтому аппаратные средства не в состоянии установить ошибку в граничной ситуации, когда процесс пытается записать информацию по адресам, превышающим верхнюю границу области данных, но принадлежащим т.н. "полулегальной" странице (странице, не полностью занятой областью данных процесса). Это видно из результатов выполнения программы, выведенных на печать (Рисунок 7.27): первый раз подпрограмма sbrk возвращает значение 140924, то есть адрес, не дотягивающий 388 байт до конца страницы, которая на машине 3B20 имеет размер 2 Кбайта. Однако процесс получит ошибку только в том случае, если обратится к следующей странице памяти, то есть к любому адресу, начиная с 141312. Функция обработки сигнала прибавляет к адресу верхней границы области 256, делая его равным 141180 и, таким образом, оставляя его в пределах текущей страницы. Следовательно, процесс тут же снова получит ошибку, выдав на печать адрес 141312. Исполнив подпрограмму sbrk еще раз, ядро выделяет под данные процесса новую страницу памяти, так что процесс получает возможность адресовать дополнительно 2 Кбайта памяти, до адреса 143360, даже если верхняя граница области располагается ниже. Получив ошибку, процесс должен будет восемь раз обратиться к подпрограмме sbrk, прежде чем сможет продолжить выполнение основной программы. Таким образом, процесс может иногда выходить за официальную верхнюю границу области данных, хотя это и нежелательный момент в практике программирования.
Когда стек задачи переполняется, ядро автоматически увеличивает его размер, выполняя алгоритм, похожий на алгоритм функции brk. Первоначально стек задачи имеет размер, достаточный для хранения параметров функции exec, однако при выполнении процесса этот стек может переполниться. Переполнение стека приводит к ошибке адресации, свидетельствующей о попытке процесса обратиться к ячейке памяти за пределами отведенного адресного пространства. Ядро устанавливает причину возникновения ошибки, сравнивая текущее значение указателя вершины стека с размером области стека. При расширении области стека ядро использует точно такой же механизм, что и для области данных. На выходе из прерывания процесс имеет область стека необходимого для продолжения работы размера.
. Алгоритм выполнения операций над семафором
Рисунок 11.15. Алгоритм выполнения операций над семафором
| алгоритм semop /* операции над семафором */ входная информация: (1) дескриптор семафора (2) список операций над семафором (3) количество элементов в списке выходная информация: исходное значение семафора { проверить корректность дескриптора семафора; start: считать список операций над семафором из простран- ства задачи в пространство ядра; проверить наличие разрешений на выполнение всех опера- ций; для (каждой операции в списке) { если (код операции имеет положительное значение) { прибавить код операции к значению семафора; если (для данной операции установлен флаг UNDO) скорректировать структуру восстановления для данного процесса; вывести из состояния приостанова все процессы, ожидающие увеличения значения семафора; } в противном случае если (код операции имеет отрица- тельное значение) { если (код операции + значение семафора >= 0) { прибавить код операции к значению семафо- ра; если (флаг UNDO установлен) скорректировать структуру восстанов- ления для данного процесса; если (значение семафора равно 0) /* продолжение на следующей страни- * це */ |
Ядро меняет значение семафора в зависимости от кода операции. Если код операции имеет положительное значение, ядро увеличивает значение семафора и выводит из состояния приостанова все процессы, ожидающие наступления этого события. Если код операции равен 0, ядро проверяет значение семафора: если оно равно 0, ядро переходит к выполнению других операций; в противном случае ядро увеличивает число приостановленных процессов, ожидающих, когда значение семафора станет нулевым, и "засыпает". Если код операции имеет отрицательное значение и если его абсолютное значение не превышает значение семафора, ядро прибавляет код операции (отрицательное число) к значению семафора. Если результат равен 0, ядро выводит из состояния приостанова все процессы, ожидающие обнуления значения семафора. Если результат меньше абсолютного значения кода операции, ядро приостанавливает процесс до тех пор, пока значение семафора не увеличится. Если процесс приостанавливается посреди операции, он имеет приоритет, допускающий прерывания; следовательно, получив сигнал, он выходит из этого состояния.
. Алгоритм выполнения процесса init
Рисунок 7.31. Алгоритм выполнения процесса init
| алгоритм init /* процесс init, в системе именуемый "процесс 1" */ входная информация: отсутствует выходная информация: отсутствует { fd = open("/etc/inittab",O_RDONLY); while (line_read(fd,buffer)) { /* читать каждую строку файлу */ if (invoked state != buffer state) continue; /* остаться в цикле while */ /* найден идентификатор соответствующего состояния */ if (fork() == 0) { execl("процесс указан в буфере"); exit(); } /* процесс init не дожидается завершения потомка */ /* возврат в цикл while */ } while ((id = wait((int*) 0)) != -1) { /* проверка существования потомка; * если потомок прекратил существование, рассматри- * вается возможность его перезапуска */ /* в противном случае, основной процесс просто про- * должает работу */ } } |
Алгоритм высвобождения буфера
Рисунок 3.6. Алгоритм высвобождения буфера
| алгоритм brelse входная информация: заблокированный буфер выходная информация: отсутствует { возобновить выполнение всех процессов при наступлении события, связанного с освобождением любого буфера; возобновить выполнение всех процессов при наступлении события, связанного с освобождением данного буфера; поднять приоритет прерывания процессора так, чтобы блокировать любые прерывания; если (содержимое буфера верно и буфер не старый) поставить буфер в конец списка свободных буферов в противном случае поставить буфер в начало списка свободных буферов понизить приоритет прерывания процессора с тем, чтобы вновь разрешить прерывания; разблокировать (буфер); } |
Перед тем, как перейти к остальным случаям, рассмотрим, что произойдет с буфером после того, как он будет выделен блоку. Ядро системы сможет читать данные с диска в буфер и обрабатывать их или же переписывать данные в буфер и при желании на диск. Ядро оставляет у буфера пометку "занят"; другие процессы не могут обратиться к нему и изменить его содержимое, пока он занят, таким образом поддерживается целостность информации в буфере. Когда ядро заканчивает работу с буфером, оно освобождает буфер в соответствии с алгоритмом brelse (Рисунок 3.6). Возобновляется выполнение тех процессов, которые были приостановлены из-за того, что буфер был занят, а также те процессы, которые были приостановлены из-за того, что список свободных буферов был пуст. Как в том, так и в другом случае, высвобождение буфера означает, что буфер становится доступным для приостановленных процессов несмотря на то, что первый процесс, получивший буфер, заблокировал его и запретил тем самым получение буфера другими процессами (см. раздел 2.2.2.4). Ядро помещает буфер в конец списка свободных буферов, если только перед этим не произошла ошибка ввода-вывода или если буфер не помечен как "старый" - момент, который будет пояснен далее; в остальных случаях буфер помещается в начало списка. Теперь буфер свободен для использования любым процессом.
Ядро выполняет алгоритм brelse в случае, когда буфер процессу больше не нужен, а также при обработке прерывания от диска для высвобождения буферов, используемых при асинхронном вводе-выводе с диска и на диск (см. раздел 3.4). Ядро повышает приоритет прерывания работы процессора так, чтобы запретить возникновение любых прерываний от диска на время работы со списком свободных буферов, предупреждая искажение указателей буфера в результате вложенного выполнения алгоритма brelse. Похожие последствия могут произойти, если программа обработки прерываний запустит алгоритм brelse во время выполнения процессом алгоритма getblk, поэтому ядро повышает приоритет прерывания работы процессора и в стратегических моментах выполнения алгоритма getblk. Более подробно эти случаи мы разберем с помощью упражнений.
При выполнении алгоритма getblk имеет место случай 2, когда ядро просматривает хеш-очередь, в которой должен был бы находиться блок, но не находит его там. Так как блок не может быть ни в какой другой хеш-очереди, поскольку он не должен "хешироваться" в другом месте, следовательно, его нет в буферном кеше. Поэтому ядро удаляет первый буфер из списка свободных буферов; этот буфер был уже выделен другому дисковому блоку и также находится в хеш-очереди. Если буфер не помечен для отложенной переписи, ядро помечает буфер занятым, удаляет его из хеш-очереди, где он находится, назначает в заголовке буфера номера устройства и блока, соответствующие данному дисковому блоку, и помещает буфер в хеш-очередь. Ядро использует буфер, не переписав информацию, которую буфер прежде хранил для другого дискового блока. Тот процесс, который будет искать прежний дисковый блок, не обнаружит его в пуле и получит для него точно таким же образом новый буфер из списка свободных буферов. Когда ядро заканчивает работу с буфером, оно освобождает буфер вышеописанным способом. На Рисунке 3.7, например, ядро ищет блок 18, но не находит его в хеш-очереди, помеченной как "блок 2 модуль 4". Поэтому ядро удаляет первый буфер из списка свободных буферов (блок 3), назначает его блоку 18 и помещает его в соответствующую хеш-очередь.
. Алгоритм загрузки данных области из файла
Рисунок 6.23. Алгоритм загрузки данных области из файла
| алгоритм loadreg /* загрузка части файла в область */ входная информация: (1) указатель на точку входа в частную таблицу областей процесса (2) виртуальный адрес загрузки (3) указатель индекса файла (4) смещение в байтах до начала считы- ваемой части файла (5) объем загружаемых данных в байтах выходная информация: отсутствует { увеличить размер области до требуемой величины (алгоритм growreg); записать статус области как "загружаемой в память"; снять блокировку с области; установить в пространстве процесса значения параметров чтения из файла: виртуальный адрес, по которому будут размещены счи- тываемые данные; смещение до начала считываемой части файла; объем данных, считываемых из файла, в байтах; загрузить файл в область (встроенная модификация алго- ритма read); заблокировать область; записать статус области как "полностью загруженной в па- мять"; возобновить выполнение всех процессов, ожидающих оконча- ния загрузки области; } |
. Алгоритм загрузки системы
Рисунок 7.30. Алгоритм загрузки системы
| алгоритм start /* процедура начальной загрузки системы */ входная информация: отсутствует выходная информация: отсутствует { проинициализировать все структуры данных ядра; псевдо-монтирование корня; сформировать среду выполнения процесса 0; создать процесс 1; { /* процесс 1 */ выделить область; подключить область к адресному пространству процесса init; увеличить размер области для копирования в нее ис- полняемого кода; скопировать из пространства ядра в адресное прост- ранство процесса код программы, исполняемой процес- сом; изменить режим выполнения: вернуться из режима ядра в режим задачи; /* процесс init далее выполняется самостоятельно -- * в результате выхода в режим задачи, * init исполняет файл "/etc/init" и становится * "обычным" пользовательским процессом, производя- * щим обращения к системным функциям */ } /* продолжение нулевого процесса */ породить процессы ядра; /* нулевой процесс запускает программу подкачки, управ- * ляющую распределением адресного пространства процес- * сов между основной памятью и устройствами выгрузки. * Это бесконечный цикл; нулевой процесс обычно приоста- * навливает свою работу, если необходимости в нем боль- * ше нет. */ исполнить программу, реализующую алгоритм подкачки; } |
Казалось бы, зачем ядру копировать программу, запускаемую с помощью функции exec, в адресное пространство процесса 1? Он мог бы обратиться к внутреннему варианту функции прямо из ядра, однако, по сравнению с уже описанным алгоритмом это было бы гораздо труднее реализовать, ибо в этом случае функции exec пришлось бы производить анализ имен файлов в пространстве ядра, а не в пространстве задачи. Подобная деталь, требующаяся только для процесса init, усложнила бы программу реализации функции exec и отрицательно отразилась бы на скорости выполнения функции в более общих случаях.
Процесс init (Рисунок 7.31) выступает диспетчером процессов, который порождает процессы, среди всего прочего позволяющие пользователю регистрироваться в системе. Инструкции о том, какие процессы нужно создать, считываются процессом init из файла "/etc/inittab". Строки файла включают в себя идентификатор состояния "id" (однопользовательский режим, многопользовательский и т. д.), предпринимаемое действие (см. упражнение 7.43) и спецификацию программы, реализующей это действие (см. Рисунок 7.32). Процесс init просматривает строки файла до тех пор, пока не обнаружит идентификатор состояния, соответствующего тому состоянию, в котором находится процесс, и создает процесс, исполняющий программу с указанной спецификацией. Например, при запуске в многопользовательском режиме (состояние 2) процесс init обычно порождает getty-процессы, управляющие функционированием терминальных линий, входящих в состав системы. Если регистрация пользователя прошла успешно, getty-процесс, пройдя через процедуру login, запускает на исполнение регистрационный shell (см. главу 10). Тем временем процесс init находится в состоянии ожидания (wait), наблюдая за прекращением существования своих потомков, а также "внучатых" процессов, оставшихся "сиротами" после гибели своих родителей.
Процессы в системе UNIX могут быть либо пользовательскими, либо управляющими, либо системными. Большинство из них составляют пользовательские процессы, связанные с пользователями через терминалы. Управляющие процессы не связаны с конкретными пользователями, они выполняют широкий спектр системных функций, таких как администрирование и управление сетями, различные периодические операции, буферизация данных для вывода на устройство построчной печати и т.д. Процесс init может порождать управляющие процессы, которые будут существовать на протяжении всего времени жизни системы, в различных случаях они могут быть созданы самими пользователями. Они похожи на пользовательские процессы тем, что они исполняются в режиме задачи и прибегают к услугам системы путем вызова соответствующих системных функций.
Системные процессы выполняются исключительно в режиме ядра. Они могут порождаться нулевым процессом (например, процесс замещения страниц vhand), который затем становится процессом подкачки. Системные процессы похожи на управляющие процессы тем, что они выполняют системные функции, при этом они обладают большими возможностями приоритетного выполнения, поскольку лежащие в их основе программные коды являются составной частью ядра. Они могут обращаться к структурам данных и алгоритмам ядра, не прибегая к вызову системных функций, отсюда вытекает их исключительность. Однако, они не обладают такой же гибкостью, как управляющие процессы, поскольку для того, чтобы внести изменения в их программы, придется еще раз перекомпилировать ядро.
Алгоритм закрытия устройства
Рисунок 10.4. Алгоритм закрытия устройства
| алгоритм close /* для устройств */ входная информация: дескриптор файла выходная информация: отсутствует { выполнить алгоритм стандартного закрытия (глава 5ххх); если (значение счетчика ссылок в таблице файлов не 0) перейти на finish; если (существует еще один открытый файл, старший и млад- ший номера которого совпадают с номерами закрываемого устройства) перейти на finish; /* не последнее закрытие */ если (устройство символьного типа) { использовать старший номер в качестве указателя в таблице ключей устройства посимвольного ввода-выво- да; вызвать процедуру закрытия, определяемую типом драй- вера и передать ей в качестве параметра младший но- мер устройства; } если (устройство блочного типа) { если (устройство монтировано) перейти на finish; переписать блоки устройства из буферного кеша на уст- ройство; использовать старший номер в качестве указателя в таблице ключей устройства ввода-вывода блоками; вызвать процедуру закрытия, определяемую типом драй- вера и передать ей в качестве параметра младший но- мер устройства; сделать недействительными блоки устройства, оставшие- ся в буферном кеше; } finish: освободить индекс; } |
10.1.2.2 Closе
Процесс разрывает связь с открытым устройством, закрывая его. Однако, ядро запускает определяемую типом устройства процедуру close только в последнем вызове функции close для этого устройства, и то только если не осталось процессов, которым устройство необходимо открытым, поскольку процедура закрытия устройства завершается разрывом аппаратного соединения; отсюда ясно, что ядру следует подождать, пока не останется ни одного процесса, обращающегося к устройству. Поскольку ядро запускает процедуру открытия устройства при каждом вызове системной функции open, а процедуру закрытия только один раз, драйверу устройства неведомо, сколько процессов используют устройство в данный момент. Драйверы могут легко выйти из строя, если при их написании не соблюдалась осторожность: когда при выполнении процедуры close они приостанавливают свою работу и какой-нибудь процесс открывает устройство до того, как завершится процедура закрытия, устройство может стать недоступным для работы, если в результате комбинации вызовов open и close сложилась нераспознаваемая ситуация.
Алгоритм закрытия устройства похож на алгоритм закрытия файла обычного типа (Рисунок 10.4). Однако, до того, как ядро освобождает индекс, в нем выполняются действия, специфичные для файлов устройств.
Просматривается таблица файлов для того, чтобы убедиться в том, что ни одному из процессов не требуется, чтобы устройство было открыто. Чтобы установить, что вызов функции close для устройства является последним, недостаточно положиться на значение счетчика ссылок в таблице файлов, поскольку несколько процессов могут обращаться к одному и тому же устройству, используя различные точки входа в таблице файлов. Так же недос таточно положиться на значение счетчика в таблице индексов, поскольку одному и тому же устройству могут соответствовать несколько файлов устройства. Например, команда ls -l покажет, что одному и тому же устройству символьного типа ("c" в начале строки) соответствуют два файла устройства, старший и младший номера у которых (9 и 1) совпадают. Значение счетчика связей для каждого файла, равное 1, говорит о том, что имеется два индекса. crw--w--w- 1 root vis 9, 1 Aug 6 1984 /dev/tty01 crw--w--w- 1 root unix 9, 1 May 3 15:02 /dev/tty01 Если процессы открывают оба файла независимо один от другого, они обратятся к разным индексам одного и того же устройства. Если устройство символьного типа, ядро запускает процедуру закрытия устройства и возвращает управление в режим задачи. Если устройство блочного типа, ядро просматривает таблицу результатов монтирования и проверяет, не располагается ли на устройстве смонтированная файловая система. Если такая система есть, ядро не сможет запустить процедуру закрытия устройства, поскольку не был сделан последний вызов функции close для устройства. Даже если на устройстве нет смонтированной файловой системы, в буферном кеше еще могут находиться блоки с данными, оставшиеся от смонтированной ранее файловой системы и не переписанные на устройство, поскольку имели пометку "отложенная запись". Поэтому ядро просматривает буферный кеш в поисках таких блоков и переписывает их на устройство перед запуском процедуры закрытия устройства. После закрытия устройства ядро вновь просматривает буферный кеш и делает недействительными все буферы, которые содержат блоки для только что закрытого устройства, в то же вре мя позволяя буферам с актуальной информацией остаться в кеше. Ядро освобождает индекс файла устройства. Короче говоря, процедура закрытия устройства разрывает связь с устройством и инициализирует заново информационные структуры драйвера и аппаратнуючасть устройства с тем, чтобы ядро могло бы позднее открыть устройство вновь.
10.1.2.3 Read и Writе
Алгоритмы чтения и записи ядром на устройстве похожи на аналогичные алгоритмы для файлов обычного типа. Если процесс производит чтение или запись на устройстве посимвольного ввода-вывода, ядро запускает процедуры read или write, определяемые типом драйвера. Несмотря на часто встречающиеся ситуации, когда ядро осуществляет передачу данных непосредственно между адресным пространством задачи и устройством, драйверы устройств могут буферизовать информацию внутри себя. Например, терминальные драйверы для буферизации данных используют символьные списки (раздел 10.3.1). В таких случаях драйвер устройства выделяет "буфер", копирует данные из пространства задачи при выполнении процедуры write и выводит их из "буфера" на устройство. Процедура записи, управляемая драйвером, регулирует объем выводимой информации (т.н. управление потоком данных): если процессы генерируют информацию быстрее, чем устройство выводит ее, процедура записи приостанавливает выполнение процессов до тех пор, пока устройство не будет готово принять следующую порцию данных. При чтении драйвер устройства помещает данные, полученные от устройства, в буфер и копирует их из буфера в пользовательские адреса, указанные в вызове системной функции.
. Алгоритм записи дискового блока
Рисунок 3.15. Алгоритм записи дискового блока
| алгоритм bwrite /* запись блока */ входная информация: буфер выходная информация: отсутствует { приступить к записи на диск; если (ввод-вывод синхронный) { приостановиться (до завершения ввода-вывода); освободить буфер (алгоритм brelse); } в противном случае если (буфер помечен для отложенной записи) пометить буфер для последующего размещения в "голове" списка свободных буферов; } |
Отложенная запись отличается от асинхронной записи. Выполняя асинхронную запись, ядро запускает дисковую операцию немедленно, но не дожидается ее завершения. Что касается отложенной записи, ядро отдаляет момент физической переписи на диск насколько возможно; затем по алгоритму getblk (случай 3) оно помечает буфер как "старый" и записывает блок на диск асинхронно. После этого контроллер диска прерывает работу системы и освобождает буфер, используя алгоритм brelse; буфер помещается в "голову" списка свободных буферов, поскольку он имеет пометку "старый". Благодаря наличию двух выполняющихся асинхронно операций ввода-вывода - чтения блока с продвижением и отложенной записи - ядро может запускать программу brelse из программы обработки прерываний. Следовательно, ядро вынуждено препятствовать возникновению прерываний при выполнении любой процедуры, работающей со списком свободных буферов, поскольку brelse помещает буферы в этот список.
Алгоритмы файловой системы
Рисунок 4.1. Алгоритмы файловой системы
Архитектура системы UNIX
Рисунок 1.1. Архитектура системы UNIX
программ. Поскольку программы не зависят от аппаратуры, их легко переносить из одной системы UNIX в другую, функционирующую на другом комплексе технических средств, если только в этих программах не подразумевается работа с конкретным оборудованием. Например, программы, рассчитанные на определенный размер машинного слова, гораздо труднее переводить на другие машины по сравнению с программами, не требующими подобных установлений.
Программы, подобные командному процессору shell и редакторам (ed и vi) и показанные на внешнем по отношению к ядру слое, взаимодействуют с ядром при помощи хорошо определенного набора обращений к операционной системе. Обращения к операционной системе понуждают ядро к выполнению различных операций, которых требует вызывающая программа, и обеспечивают обмен данными между ядром и программой. Некоторые из программ, приведенных на рисунке, в стандартных конфигурациях системы известны как команды, однако на одном уровне с ними могут располагаться и доступные пользователю программы, такие как программа a.out, стандартное имя для исполняемого файла, созданного компилятором с языка Си. Другие прикладные программы располагаются выше указанных программ, на верхнем уровне, как это показано на рисунке. Например, стандартный компилятор с языка Си, cc, располагается на самом внешнем слое: он вызывает препроцессор для Си, ассемблер и загрузчик (компоновщик), т.е. отдельные программы предыдущего уровня. Хотя на рисунке приведена двухуровневая иерархия прикладных программ, пользователь может расширить иерархическую структуру на столько уровней, сколько необходимо. В самом деле, стиль программирования, принятый в системе UNIX, допускает разработку комбинации программ, выполняющих одну и ту же, общую задачу.
Многие прикладные подсистемы и программы, составляющие верхний уровень системы, такие как командный процессор shell, редакторы, SCCS (система обработки исходных текстов программ) и пакеты программ подготовки документации, постепенно становятся синонимом понятия "система UNIX". Однако все они пользуются услугами программ нижних уровней и в конечном счете ядра с помощью набора обращений к операционной системе. В версии V принято 64 типа обращений к операционной системе, из которых немногим меньше половины используются часто. Они имеют несложные параметры, что облегчает их использование, предоставляя при этом большие возможности пользователю. Набор обращений к операционной системе вместе с реализующими их внутренними алгоритмами составляют "тело" ядра, в связи с чем рассмотрение операционной системы UNIX в этой книге сводится к подробному изучению и анализу обращений к системе и их взаимодействия между собой. Короче говоря, ядро реализует функции, на которых основывается выполнение всех прикладных программ в системе UNIX, и им же определяются эти функции. В книге часто употребляются термины "система UNIX", "ядро" или "система", однако при этом имеется ввиду ядро операционной системы UNIX, что и должно вытекать из контекста.
(***) В некоторых реализациях системы UNIX операционная система взаимодействует с собственной операционной системой, которая, в свою очередь, взаимодействует с аппаратурой и выполняет необходимые функции по обслуживанию системы. В таких реализациях допускается инсталляция других операционных систем с загрузкой под их управлением прикладных программ параллельно с системой UNIX. Классическим примером подобной реализации явилась система MERT [Lycklama 78a]. Более новым примером могут служить реализации для компьютеров серии IBM 370 [Felton 84] и UNIVAC 1100 [Bodenstab 84].
Блок-схема ядра операционной системы
Рисунок 2.1. Блок-схема ядра операционной системы
к типу запоминающих устройств с произвольной выборкой; их драйверы построены таким образом, что все остальные компоненты системы воспринимают эти устройства как запоминающие устройства с произвольной выборкой. Например, драйвер запоминающего устройства на магнитной ленте позволяет ядру системы воспринимать это устройство как запоминающее устройство с произвольной выборкой. Подсистема управления файлами также непосредственно взаимодействует с драйверами устройств "неструктурированного" ввода-вывода, без вмешательства буферного механизма. К устройствам неструктурированного ввода-вывода, иногда именуемым устройствами посимвольного ввода-вывода (текстовыми), относятся устройства, отличные от устройств ввода-вывода блоками.
Подсистема управления процессами отвечает за синхронизацию процессов, взаимодействие процессов, распределение памяти и планирование выполнения процессов. Подсистема управления файлами и подсистема управления процессами взаимодействуют между собой, когда файл загружается в память на выполнение (см. главу 7): подсистема управления процессами читает в память исполняемые файлы перед тем, как их выполнить.
Примерами обращений к операционной системе, используемых при управлении процессами, могут служить fork (создание нового процесса), exec (наложение образа программы на выполняемый процесс), exit (завершение выполнения процесса), wait (синхронизация продолжения выполнения основного процесса с моментом выхода из порожденного процесса), brk (управление размером памяти, выделенной процессу) и signal (управление реакцией процесса на возникновение экстраординарных событий). Глава 7 посвящена рассмотрению этих и других системных вызовов.
Модуль распределения памяти контролирует выделение памяти процессам. Если в какой-то момент система испытывает недостаток в физической памяти для запуска всех процессов, ядро пересылает процессы между основной и внешней памятью с тем, чтобы все процессы имели возможность выполняться. В главе 9 описываются два способа управления распределением памяти: выгрузка (подкачка) и замещение страниц. Программу подкачки иногда называют планировщиком, т.к. она "планирует" выделение памяти процессам и оказывает влияние на работу планировщика центрального процессора. Однако в дальнейшем мы будем стараться ссылаться на нее как на "программу подкачки", чтобы избежать путаницы с планировщиком центрального процессора.
Модуль "планировщик" распределяет между процессами время центрального процессора. Он планирует очередность выполнения процессов до тех пор, пока они добровольно не освободят центральный процессор, дождавшись выделения какого-либо ресурса, или до тех пор, пока ядро системы не выгрузит их после того, как их время выполнения превысит заранее определенный квант времени. Планировщик выбирает на выполнение готовый к запуску процесс с наивысшим приоритетом; выполнение предыдущего процесса (приостановленного) будет продолжено тогда, когда его приоритет будет наивысшим среди приоритетов всех готовых к запуску процессов. Существует несколько форм взаимодействия процессов между собой, от асинхронного обмена сигналами о событиях до синхронного обмена сообщениями.
Наконец, аппаратный контроль отвечает за обработку прерываний и за связь с машиной. Такие устройства, как диски и терминалы, могут прерывать работу центрального процессора во время выполнения процесса. При этом ядро системы после обработки прерывания может возобновить выполнение прерванного процесса. Прерывания обрабатываются не самими процессами, а специальными функциями ядра системы, перечисленными в контексте выполняемого процесса.
Блоки прямой и косвенной адресации в индексе
Рисунок 4.6. Блоки прямой и косвенной адресации в индексе

Буферы в хеш-очередях
Рисунок 3.3. Буферы в хеш-очередях

На Рисунке 3.3 изображены буферы в хеш-очередях: заголовки хеш-очередей показаны в левой части рисунка, а квадратиками в каждой строке показаны буферы в соответствующей хеш-очереди. Так, квадратики с числами 28, 4 и 64 представляют буферы в хеш-очереди для "блока 0 модуля 4". Пунктирным линиям между буферами соответствуют указатели вперед и назад вдоль хеш-очереди; для простоты на следующих рисунках этой главы данные указатели не показываются, но их присутствие подразумевается. Кроме того, на рисунке блоки идентифицируются только своими номерами и функция хеширования построена на использовании только номеров блоков; однако на практике также используется номер устройства.
Любой буфер всегда находится в хеш-очереди, но его положение в очереди не имеет значения. Как уже говорилось, никакая пара буферов не может одновременно содержать данные одного и того же дискового блока; поэтому каждый дисковый блок в буферном пуле существует в одной и только одной хеш-очереди и представлен в ней только один раз. Тем не менее, буфер может находиться в списке свободных буферов, если его статус "свободен". Поскольку буфер может быть одновременно в хеш-очереди и в списке свободных буферов, у ядра есть два способа его обнаружения. Ядро просматривает хеш-очередь, если ему нужно найти определенный буфер, и выбирает буфер из списка свободных буферов, если ему нужен любой свободный буфер. В следующем разделе будет показано, каким образом ядро осуществляет поиск определенных дисковых блоков в буферном кеше, а также как оно работает с буферами в хеш-очередях и в списке свободных буферов. Еще раз напомним: буфер всегда находится в хеш -очереди, а в списке свободных буферов может быть, но может и отсутствовать.
Четвертый случай выделения буфера
Рисунок 3.9. Четвертый случай выделения буфера

Процесс B также должен убедиться в том, что в буфере содержится первоначально затребованный дисковый блок, поскольку процесс C мог выделить данный буфер другому блоку, как в случае 2. При выполнении процесса B может обнаружиться, что он ждал освобождения буфера не с тем содержимым, поэтому процессу B придется вновь заниматься поисками блока. Если же его настроить на автоматическое выделение буфера из списка свободных буферов, он может упустить из виду возможность того, что какой-либо другой процесс уже выделил буфер для данного блока.
. Чтение большой порции данных в маленький буфер
Рисунок 5.36. Чтение большой порции данных в маленький буфер
| #include <fcntl.h> main() { int fd; char buf[256]; fd = open("/etc/passwd",O_RDONLY); if (read(fd,buf,1024) < 0) printf("чтение завершается неудачно\n"); } |
6. Рассмотрим программу, приведенную на Рисунке 5.36. Что произойдет в результате выполнения программы? Обоснуйте ответ. Что произошло бы, если бы объявление массива buf было вставлено между объявлениями двух других массивов размером 1024 элемента каждый? Каким образом ядро устанавливает, что прочитанная порция данных слишком велика для буфера?
*7. В файловой системе BSD разрешается фрагментировать последний блок файла в соответствии со следующими правилами:
Свободные фрагменты отслеживаются в структурах, подобных суперблоку; Ядро не поддерживает пул ранее выделенных свободных фрагментов, а разбивает на фрагменты в случае необходимости свободный блок; Ядро может назначать фрагменты блока только для последнего блока в файле; Если блок разбит на несколько фрагментов, ядро может назначить их различным файлам; Количество фрагментов в блоке не должно превышать величину, фиксированную для данной файловой системы; Ядро назначает фрагменты во время выполнения системной функции write.Разработайте алгоритм, присоединяющий к файлу фрагменты блока. Какие изменения должны быть сделаны в индексе, чтобы позволить использование фрагментов? Какие преимущества с системной точки зрения предоставляет использование фрагментов для тех файлов, которые используют блоки косвенной адресации? Не выгоднее ли было бы назначать фрагменты во время выполнения функции close вместо того, чтобы назначать их при выполнении функции write?
*8. Вернемся к обсуждению, начатому в главе 4 и касающемуся расположения данных в индексе файла. Для того случая, когда индекс имеет размер дискового блока, разработайте алгоритм, по которому остаток данных файла переписывается в индексный блок, если помещается туда. Сравните этот метод с методом, предложенным для решения предыдущей проблемы.
*9. В версии V системы функция fcntl используется для реализации механизма захвата файла и записи и имеет следующий формат: fcntl(fd,cmd,arg); где fd - дескриптор файла, cmd - тип блокирующей операции, а в arg указываются различные параметры, такие как тип блокировки (записи или чтения) и смещения в байтах (см. приложение). К блокирующим операциям относятся
Проверка наличия блокировок, принадлежащих другим процессам, с немедленным возвратом управления в случае обнаружения таких блокировок, Установка блокировки и приостанов до успешного завершения, Установка блокировки с немедленным возвратом управления в случае неудачи.Ядро автоматически снимает блокировки, установленные процессом, при закрытии файла. Опишите работу алгоритма, реализующего захват файла и записи. Если блокировки являются обязательными, другим процессам следует запретить доступ к файлу. Какие изменения следует сделать в операциях чтения и записи?
*10. Если процесс приостановил свою работу в ожидании снятия с файла блокировки, возникает опасность взаимной блокировки: процесс A может заблокировать файл "one" и попытаться заблокировать файл "two", а процесс B может заблокировать файл "two" и попытаться заблокировать файл "one". Оба процесса перейдут в состояние, при котором они не смогут продолжить свою работу. Расширьте алгоритм решения предыдущей проблемы таким образом, чтобы ядро могло обнаруживать ситуации взаимной блокировки и прерывать выполнение системных функций. Следует ли поручать обнаружение взаимных блокировок ядру?
11. До существования специальной системной функции захвата файла пользователям приходилось прибегать к услугам параллельно действующих процессов для реализации механизма захвата путем вызова системных функций, выполняющих элементарные действия. Какие из системных функций, описанных в этой главе, могли бы использоваться? Какие опасности подстерегают при использовании этих методов?
12. Ричи заявлял (см. [Ritchie 81]), что захвата файла недостаточно для того, чтобы предотвратить путаницу, вызываемую такими программами, как редакторы, которые создают копию файла при редактировании и переписывают первоначальный файл по окончании работы. Объясните, что он имел в виду, и прокомментируйте.
13. Рассмотрим еще один способ блокировки файлов, предотвращающий разрушительные последствия корректировки. Предположим, что в индексе содержится новая установка прав доступа, позволяющая только одному процессу в текущий момент открывать файл для записи и нескольким процессам открывать файл для чтения. Опишите реализацию этого способа.
Чтение данных с диска с использованием
Рисунок 10.8. Чтение данных с диска с использованием блочного интерфейса и без структурирования данных
| #include "fcntl.h" main() { char buf1[4096], buf2[4096] int fd1, fd2, i; if (((fd1 = open("/dev/dsk5/", O_RDONLY)) == -1) ((fd2 = open("/dev/rdsk5", O_RDONLY)) == -1)) { printf("ошибка при открытии\n"); exit(); } lseek(fd1, 8192L, 0); lseek(fd2, 8192L, 0); if ((read(fd1, buf1, sizeof(buf1)) == -1) (read(fd2, buf2, sizeof(buf2)) == -1)) { printf("ошибка при чтении\n"); exit(); } for (i = 0; i < sizeof(buf1); i++) if (buf1[i] != buf2[i]) { printf("различие в смещении %d\n", i); exit(); } printf("данные совпадают\n"); } |
Программы, осуществляющие чтение и запись на диск непосредственно, представляют опасность, поскольку манипулируют с чувствительной информацией, рискуя нарушить системную защиту. Администраторам следует защищать интерфейсы ввода-вывода путем установки прав доступа к файлам дисковых устройств. Например, дисковые файлы "/dev/dsk15" и "/dev/rdsk15" должны принадлежать пользователю с именем "root", и права доступа к ним должны быть определены таким образом, чтобы пользователю "root" было разрешено чтение, а всем остальным пользователям и чтение, и запись должны быть запрещены.
Программы, осуществляющие чтение и запись на диск непосредственно, могут также нарушить целостность данных в файловой системе. Алгоритмы файловой системы, рассмотренные в главах 3, 4 и 5, координируют выполнение операций ввода-вывода, связанных с диском, тем самым поддерживая целостность информационных структур на диске, в том числе списка свободных дисковых блоков и указателей из индексов на информационные блоки прямой и косвенной адресации. Процессы, обращающиеся к диску непосредственно, обходят эти алгоритмы. Пусть даже их программы написаны с большой осторожностью, проблема целостности все равно не исчезнет, если они выполняются параллельно с работой другой файловой системы. По этой причине программа fsck не должна выполняться при наличии активной файловой системы.
Два типа дискового интерфейса различаются между собой по использованию буферного кеша. При работе с блочным интерфейсом ядро пользуется тем же алгоритмом, что и для файлов обычного типа, исключение составляет тот момент, когда после преобразования адреса смещения логического байта в адрес смещения логического блока (см. алгоритм bmap в главе 4) оно трактует адрес смещения логического блока как физический номер блока в файловой системе. Затем, используя буферный кеш, ядро обращается к данным, и, в конечном итоге, к стратегическому интерфейсу драйвера. Однако, при обращении к диску через символьный интерфейс (без структурирования данных), ядро не превращает адрес смещения в адрес файла, а передает его немедленно драйверу, используя для передачи рабочее пространство задачи. Процедуры чтения и записи, входящие в состав драйвера, преобразуют смещение в байтах в смещение в блоках и копируют данные непосредственно в адресное пространство задачи, минуя буферы ядра.
Таким образом, если один процесс записывает на устройство блочного типа, а второй процесс затем считывает с устройства символьного типа по тому же адресу, второй процесс может не считать информацию, записанную первым процессом, так как информация может еще находиться в буферном кеше, а не на диске. Тем не менее, если второй процесс обратится к устройству блочного типа, он автоматически попадет на новые данные, находящиеся в буферном кеше.
При использовании символьного интерфейса можно столкнуться со странной ситуацией. Если процесс читает или пишет на устройство посимвольного ввода-вывода порциями меньшего размера, чем, к примеру, блок, результаты будут зависеть от драйвера. Например, если производить запись на ленту по 1 байту, каждый байт может попасть в любой из ленточных блоков.
Преимущество использования символьного интерфейса состоит в скорости, если не возникает необходимость в кешировании данных для дальнейшей работы. Процессы, обращающиеся к устройствам ввода -вывода блоками, передают информацию блоками, размер каждого из которых ограничивается размером логического блока в данной файловой системе. Например, если размер логического блока в файловой системе 1 Кбайт, за одну операцию ввода-вывода может быть передано не больше 1 Кбайта информации. При этом процессы, обращающиеся к диску с помощью символьного интерфейса, могут передавать за одну дисковую операцию множество дисковых блоков, в зависимости от возможностей дискового контроллера. С функциональной точки зрения, процесс получает тот же самый результат, но символьный интерфейс может работать гораздо быстрее. Если воспользоваться примером, приведенным на Рисунке 10.8, можно увидеть, что когда процесс считывает 4096 байт, используя блочный интерфейс для файловой системы с размером блока 1 Кбайт, ядро производит четыре внутренние итерации, на каждом шаге обращаясь к диску, прежде чем вызванная системная функция возвращает управление, но когда процесс использует символьный интерфейс, драйвер может закончить чтение за одну дисковую операцию. Более того, использование блочного интерфейса вызывает дополнительное копирование данных между адресным пространством задачи и буферами ядра, что отсутствует в символьном интерфейсе.
(***) Не существует иного способа установить, что символьный и блочный драйверы ссылаются на одно и то же устройство, кроме просмотра таблиц системной конфигурации и текста программ драйвера.
. Чтение и запись в поименованный канал
Рисунок 5.19. Чтение и запись в поименованный канал
| #include <fcntl.h> char string[] = "hello"; main(argc,argv) int argc; char *argv[]; { int fd; char buf[256]; /* создание поименованного канала с разрешением чтения и записи для всех пользователей */ mknod("fifo",010777,0); if(argc == 2) fd = open("fifo",O_WRONLY); else fd = open("fifo",O_RDONLY); for (;;) if(argc == 2) write(fd,string,6); else read(fd,buf,6); } |
Чтение из файла с использованием двух дескрипторов
Рисунок 5.9. Чтение из файла с использованием двух дескрипторов
| #include <fcntl.h> main() { int fd1,fd2; char buf1[512],buf2[512]; fd1 = open("/etc/passwd",O_RDONLY); fd2 = open("/etc/passwd",O_RDONLY); | read(fd1,buf1,sizeof(buf1)); read(fd2,buf2,sizeof(buf2)); | } |
Предположим, к примеру, что процесс записывает в файл байт с номером 10240, наибольшим номером среди уже записанных в файле. Обратившись к байту в файле по алгоритму bmap, ядро обнаружит, что в файле отсутствует не только соответствующий этому байту блок, но также и нужный блок косвенной адресации. Ядро назначает дисковый блок в качестве блока косвенной адресации и записывает номер блока в копии индекса, хранящейся в памяти. Затем оно выделяет дисковый блок под данные и записывает его номер в первую позицию вновь созданного блока косвенной адресации.
Так же, как в алгоритме read, ядро входит в цикл, записывая на диск по одному блоку на каждой итерации. При этом на каждой итерации ядро определяет, будет ли производиться запись целого блока или только его части. Если записывается только часть блока, ядро в первую очередь считывает блок с диска для того, чтобы не затереть те части, которые остались без изменений, а если записывается целый блок, ядру не нужно читать весь блок, так как в любом случае оно затрет предыдущее содержимое блока. Запись осуществляется поблочно, однако ядро использует отложенную запись (раздел 3.4) данных на диск, запоминая их в кеше на случай, если они понадобятся вскоре другому процессу для чтения или записи, а также для того, чтобы избежать лишних обращений к диску. Отложенная запись, вероятно, наиболее эффективна для каналов, так как другой процесс читает канал и удаляет из него данные (раздел 5.12). Но даже для обычных файлов отложенная запись эффективна, если файл создается временно и вскоре будет прочитан. Например, многие программы, такие как редакторы и электронная почта, создают временные файлы в каталоге "/tmp" и быстро удаляют их. Использование отложенной записи может сократить количество обращений к диску для записи во временные файлы.
. Чтение из канала и запись в канал
Рисунок 5.18. Чтение из канала и запись в канал
| char string[] = "hello"; main() { char buf[1024]; char *cp1,*cp2; int fds[2]; cp1 = string; cp2 = buf; while(*cp1) *cp2++ = *cp1++; pipe(fds); for (;;) { write(fds[1],buf,6); read(fds[0],buf,6); } } |
Процесс, выполняющий программу, которая приведена на Рисунке 5.19, создает поименованный канал с именем "fifo". Если этот процесс запущен с указанием второго (формального) аргумента, он постоянно записывает в канал строку символов "hello"; будучи запущен без второго аргумента, он ведет чтение из поименованного канала. Два процесса запускаются по одной и той же программе, тайно договорившись взаимодействовать между собой через поименованный канал "fifo", но им нет необходимости быть родственными процессами. Другие пользователи могут выполнять программу и участвовать в диалоге (или мешать ему).
. Дерево файловых систем до и после выполнения функции mount
Рисунок 5.22. Дерево файловых систем до и после выполнения функции mount

Ядро поддерживает таблицу монтирования с записями о каждой монтированной файловой системе. В каждой записи таблицы монтирования содержатся:
номер устройства, идентифицирующий монтированную файловую систему (упомянутый выше логический номер файловой системы); указатель на буфер, где находится суперблок файловой системы; указатель на корневой индекс монтированной файловой системы ("/" для файловой системы с именем "/dev/dsk1" на Рисунке 5.22); указатель на индекс каталога, ставшего точкой монтирования (на Рисунке 5.22 это каталог "usr", принадлежащий корневой файловой системе).Связь индекса точки монтирования с корневым индексом монтированной файловой системы, возникшая в результате выполнения системной функции mount, дает ядру возможность легко двигаться по иерархии файловых систем без получения от пользователей дополнительных сведений.
. Дерево процессов и совместное использование каналов
Рисунок 5.15. Дерево процессов и совместное использование каналов

Диаграмма переходов процесса из
Рисунок 7.6. Диаграмма переходов процесса из состояние в состояние с указанием моментов проверки и обработки сигналов
Диаграмма переходов процесса из состояния в состояние
Рисунок 6.1. Диаграмма переходов процесса из состояния в состояние
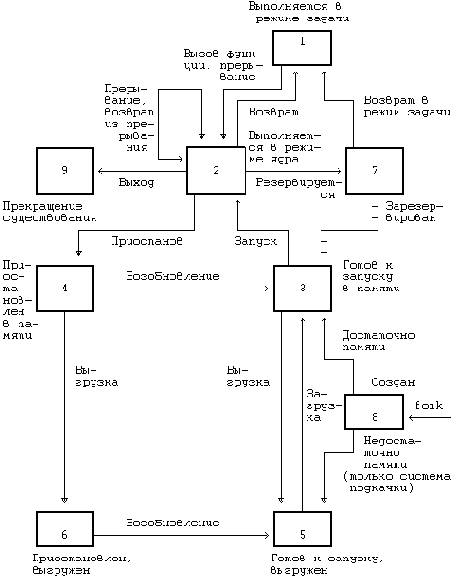
После всего этого процесс может перейти в состояние "выполнения в режиме задачи". По прохождении определенного периода времени может произойти прерывание работы процессора по таймеру и процесс снова перейдет в состояние "выполнения в режиме ядра". Как только программа обработки прерывания закончит работу, ядру может понадобиться подготовить к запуску другой процесс, поэтому первый процесс перейдет в состояние "резервирования", уступив дорогу второму процессу. Состояние "резервирования" в действительности не отличается от состояния "готовности к запуску в памяти" (пунктирная линия на рисунке, соединяющая между собой оба состояния, подчеркивает их эквивалентность), но они выделяются в отдельные состояния, чтобы подчеркнуть, что процесс, выполняющийся в режиме ядра, может быть зарезервирован только в том случае, если он собирается вернуться в режим задачи. Следовательно, ядро может при необходимости подкачивать процесс из состояния "резервирования". При известных условиях планировщик выберет процесс для исполнения и тот снова вернется в состояние "выполнения в режиме задачи".
Когда процесс выполняет вызов системной функции, он из состояния "выполнения в режиме задачи" переходит в состояние "выполнения в режиме ядра". Предположим, что системной функции требуется ввод-вывод с диска и поэтому процесс вынужден дожидаться завершения ввода-вывода. Он переходит в состояние "приостанова в памяти", в котором будет находиться до тех пор, пока не получит извещения об окончании ввода-вывода. Когда ввод-вывод завершится, произойдет аппаратное прерывание работы центрального процессора и программа обработки прерывания возобновит выполнение процесса, в результате чего он перейдет в состояние "готовности к запуску в памяти".
Предположим, что система выполняет множество процессов, которые одновременно никак не могут поместиться в оперативной памяти, и программа подкачки (нулевой процесс) выгружает один процесс, чтобы освободить место для другого процесса, находящегося в состоянии "готов к запуску, но выгружен". Первый процесс, выгруженный из оперативной памяти, переходит в то же состояние. Когда программа подкачки выбирает наиболее подходящий процесс для загрузки в оперативную память, этот процесс переходит в состояние "готовности к запуску в памяти". Планировщик выбирает процесс для исполнения и он переходит в состояние "выполнения в режиме ядра". Когда процесс завершается, он исполняет системную функцию exit, последовательно переходя в состояния "выполнения в режиме ядра" и, наконец, в состояние "прекращения существования".
Процесс может управлять некоторыми из переходов на уровне задачи. Во-первых, один процесс может создать другой процесс. Тем не менее, в какое из состояний процесс перейдет после создания (т.е. в состояние "готов к выполнению, находясь в памяти" или в состояние "готов к выполнению, но выгружен") зависит уже от ядра. Процессу эти состояния не подконтрольны. Во-вторых, процесс может обратиться к различным системным функциям, чтобы перейти из состояния "выполнения в режиме задачи" в состояние "выполнения в режиме ядра", а также перейти в режим ядра по своей собственной воле. Тем не менее, момент возвращения из режима ядра от процесса уже не зависит; в результате каких-то событий он может никогда не вернуться из этого режима и из него перейдет в состояние "прекращения существования" (см. раздел 7.2, где говорится о сигналах). Наконец, процесс может завершиться с помощью функции exit по своей собственной воле, но как указывалось ранее, внешние события могут потребовать завершения процесса без явного обращения к функции exit. Все остальные переходы относятся к жестко закрепленной части модели, закодированной в ядре, и являются результатом определенных событий, реагируя на них в соответствии с правилами, сформулированными в этой и последующих главах. Некоторые из правил уже упоминались: например, то, что процесс может выгрузить другой процесс, выполняющийся в ядре.
Две принадлежащие ядру структуры данных описывают процесс: запись в таблице процессов и пространство процесса. Таблица процессов содержит поля, которые должны быть всегда доступны ядру, а пространство процесса - поля, необходимость в которых возникает только у выполняющегося процесса. Поэтому ядро выделяет место для пространства процесса только при создании процесса: в нем нет необходимости, если записи в таблице процессов не соответствует конкретный процесс.
Запись в таблице процессов состоит из следующих полей:
Поле состояния, которое идентифицирует состояние процесса. Поля, используемые ядром при размещении процесса и его пространства в основной или внешней памяти. Ядро использует информацию этих полей для переключения контекста на процесс, когда процесс переходит из состояния "готов к выполнению, находясь в памяти" в состояние "выполнения в режиме ядра" или из состояния "резервирования" в состояние "выполнения в режиме задачи". Кроме того, ядро использует эту информацию при перекачки процессов из и в оперативную память (между двумя состояниями "в памяти" и двумя состояниями "выгружен"). Запись в таблице процессов содержит также поле, описывающее размер процесса и позволяющее ядру планировать выделение пространства для процесса. Несколько пользовательских идентификаторов (UID), устанавливающих различные привилегии процесса. Поля UID, например, описывают совокупность процессов, могущих обмениваться сигналами (см. следующую главу). Идентификаторы процесса (PID), указывающие взаимосвязь между процессами. Значения полей PID задаются при переходе процесса в состояние "создан" во время выполнения функции fork. Дескриптор события (устанавливается тогда, когда процесс приостановлен). В данной главе будет рассмотрено использование дескриптора события в алгоритмах функций sleep и wakeup. Параметры планирования, позволяющие ядру устанавливать порядок перехода процессов из состояния "выполнения в режиме ядра" в состояние "выполнения в режиме задачи". Поле сигналов, в котором перечисляются сигналы, посланные процессу, но еще не обработанные (раздел 7.2). Различные таймеры, описывающие время выполнения процесса и использование ресурсов ядра и позволяющие осуществлять слежение за выполнением и вычислять приоритет планирования процесса. Одно из полей является таймером, который устанавливает пользователь и который необходим для посылки процессу сигнала тревоги (раздел 8.3). Пространство процесса содержит поля, дополнительно характеризующие состояния процесса. В предыдущих главах были рассмотрены последние семь из приводимых ниже полей пространства процесса, которые мы для полноты вновь кратко перечислим: Указатель на таблицу процессов, который идентифицирует запись, соответствующую процессу. Пользовательские идентификаторы, устанавливающие различные привилегии процесса, в частности, права доступа к файлу (см. раздел 7.6). Поля таймеров, хранящие время выполнения процесса (и его потомков) в режиме задачи и в режиме ядра. Вектор, описывающий реакцию процесса на сигналы. Поле операторского терминала, идентифицирующее "регистрационный терминал", который связан с процессом. Поле ошибок, в которое записываются ошибки, имевшие место при выполнении системной функции. Поле возвращенного значения, хранящее результат выполнения системной функции. Параметры ввода-вывода: объем передаваемых данных, адрес источника (или приемника) данных в пространстве задачи, смещения в файле (которыми пользуются операции ввода-вывода) и т.д. Имена текущего каталога и текущего корня, описывающие файловую систему, в которой выполняется процесс. Таблица пользовательских дескрипторов файла, которая описывает файлы, открытые процессом. Поля границ, накладывающие ограничения на размерные характеристики процесса и на размер файла, в который процесс может вести запись. Поле прав доступа, хранящее двоичную маску установок прав доступа к файлам, которые создаются процессом. Пространство состояний процесса и переходов между ними рассматривалось в данном разделе на логическом уровне. Каждое состояние имеет также физические характеристики, управляемые ядром, в частности, виртуальное адресное пространство процесса. Следующий раздел посвящен описанию модели распределения памяти; в остальных разделах состояния процесса и переходы между ними рассматриваются на физическом уровне, особое внимание при этом уделяется состояниям "выполнения в режиме задачи", "выполнения в режиме ядра", "резервирования" и "приостанова (в памяти)". В следующей главе затрагиваются состояния "создания" и "прекращения существования", а в главе 8 - состояние "готовности к запуску в памяти". В главе 9 обсуждаются два состояния выгруженного процесса и организация подкачки по обращению.. Диаграмма состояний страницы
Рисунок 9.18. Диаграмма состояний страницы
Если область используется совместно не менее, чем двумя процессами, все они работают с битами упоминания в одном и том же наборе записей таблицы страниц. Таким образом, страницы могут включаться в рабочие множества нескольких процессов, но для "сборщика" страниц это не имеет никакого значения. Если страница включена в рабочее множество хотя бы одного из процессов, она остается в памяти; в противном случае она может быть выгружена. Ничего, что одна область, к примеру, имеет в памяти страниц больше, чем имеют другие: "сборщик" страниц не пытается выгрузить равное количество страниц из всех активных областей.
Ядро возобновляет работу "сборщика" страниц, когда доступная в системе свободная память имеет размер, не дотягивающий до нижней допустимой отметки, и тогда "сборщик" производит откачку страниц до тех пор, пока объем свободной памяти не превысит верхнюю отметку. При использовании двух отметок количество производимых операций сокращается, ибо если ядро использует только одно пороговое значение, оно будет выгружать достаточное число страниц для освобождения памяти свыше порогового значения, но в результате возвращения ошибочно выгруженных страниц в память размер свободного пространства вскоре вновь опустится ниже этого порога. Объем свободной памяти при этом постоянно бы поддерживался около пороговой отметки. Выгрузка страниц с освобождением памяти в объеме, превышающем верхнюю отметку, откладывает момент, когда объем свободной памяти в системе станет меньше нижней отметки, поэтому "сборщику" страниц не приходится уже так часто выполнять свою работу. Оптимальный выбор уровней верхней и нижней отметок администратором повышает производительность системы.

Диапазон приоритетов процесса
Рисунок 8.2. Диапазон приоритетов процесса
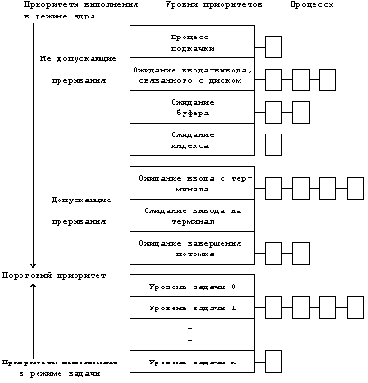
В течение кванта времени таймер может послать процессу несколько прерываний; при каждом прерывании программа обработки прерываний по таймеру увеличивает значение, хранящееся в поле таблицы процессов, которое описывает продолжительность использования ресурсов центрального процессора (ИЦП). В версии V каждую секунду программа обработки прерываний переустанавливает значение этого поля, используя функцию полураспада (decay):
decay(ИЦП) = ИЦП/2;После этого программа пересчитывает приоритет каждого процесса, находящегося в состоянии "зарезервирован, но готов к выполнению", по формуле
приоритет = (ИЦП/2) + (базовый уровень приоритета задачи)где под "базовым уровнем приоритета задачи" понимается пороговое значение, расположенное между приоритетами выполнения в режимах ядра и задачи. Высокому приоритету планирования соответствует количественно низкое значение. Анализ функций пересчета продолжительности использования ресурсов ЦП и приоритета процесса показывает: чем ниже скорость полураспада значения ИЦП, тем медленнее приоритет процесса достигает значение базового уровня; поэтому процессы в состоянии "готовности к выполнению" имеют тенденцию занимать большое число уровней приоритетов.
Результатом ежесекундного пересчета приоритетов является перемещение процессов, находящихся в режиме задачи, от одной очереди к другой, как показано на Рисунке 8.3. По сравнению с Рисунком 8.2 один процесс перешел из очереди, соответствующей уровню 1, в очередь, соответствующую нулевому уровню. В реальной системе все процессы, имеющие приоритеты выполнения в режиме задачи, поменяли бы свое местоположение в очередях. При этом следует указать на невозможность изменения приоритета процесса в режиме ядра, а также на невозможность пересечения пороговой черты процессами, выполняющимися в режиме задачи, до тех пор, пока они не обратятся к операционной системе и не перейдут в состояние приостанова.
Ядро стремится производить пересчет приоритетов всех активных процессов ежесекундно, однако интервал между моментами пересчета может слегка варьироваться. Если прерывание по таймеру поступило тогда, когда ядро исполняло критический отрезок программы (другими словами, в то время, когда приоритет работы ЦП был повышен, но, очевидно, не настолько, чтобы воспрепятствовать прерыванию данного типа), ядро не пересчитывает приоритеты, иначе ему пришлось бы надолго задержаться на критическом отрезке. Вместо этого ядро запоминает то, что ему следует произвести пересчет приоритетов, и делает это при первом же прерывании по таймеру, поступающем после снижения приоритета работы ЦП. Периодический пересчет приоритета процессов гарантирует проведение стратегии планирования, основанной на использовании кольцевого списка процессов, выполняющихся в режиме задачи. При этом конечно же ядро откликается на интерактивные запросы таких программ, как текстовые редакторы или программы форматного ввода: процессы, их реализующие, имеют высокий коэффициент простоя (отношение времени простоя к продолжительности использования ЦП) и поэтому естественно было бы повышать их приоритет, когда они готовы для выполнения (см. [Thompson 78], стр.1937). В других механизмах планирования квант времени, выделяемый процессу на работу с ресурсами ЦП, динамически изменяется в интервале между 0 и 1 сек. в зависимости от степени загрузки системы. При этом время реакции на запросы процессов может сократиться за счет того, что на ожидание момента запуска процессам уже не нужно отводить по целой секунде; однако, с другой стороны, ядру приходится чаще прибегать к переключению контекстов.
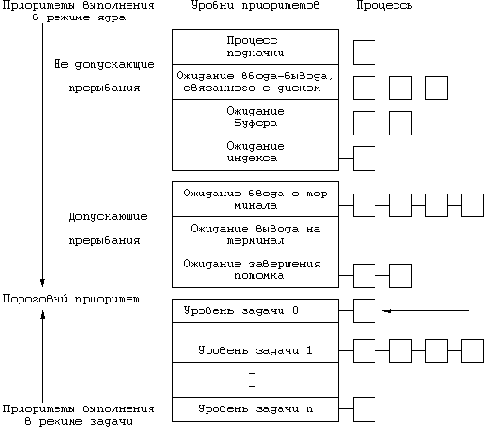
. Два массива номеров свободных индексов
Рисунок 4.13. Два массива номеров свободных индексов

. Два отказа на одной странице
Рисунок 9.24. Два отказа на одной странице
Если копия страницы находится не на устройстве выгрузки, а в исполняемом файле (случай 3), ядро загружает страницу из файла. Программа обработки отказа обращается к дескриптору дискового блока, ищет соответствующий номер логического блока внутри файла, содержащего страницу, и индекс, ассоциированный с записью таблицы областей. Номер логического блока используется программой в качестве смещения внутри списка номеров дисковых блоков, присоединенного к индексу во время выполнения функции exec. По номеру блока на диске программа считывает страницу в память. Так, например, дескриптор дискового блока, связанный с виртуальным адресом 1К, показывает, что содержимое страницы располагается в исполняемом файле, внутри логического блока с номером 3 (см. Рисунок 9.22).
Если процесс получил отказ при обращении к странице, имеющей пометку "заполняемая при обращении" или "обнуляемая при обращении" (случаи 4 и 5), ядро выделяет свободную страницу в памяти и корректирует соответствующую запись таблицы страниц. Если страница "обнуляемая при обращении", ядро также очищает ее содержимое. В завершение обработки флаги "заполняемая при обращении" и "обнуляемая при обращении" сбрасываются. Теперь страница находится в памяти, доступна процессам и ее содержимое не имеет аналогов ни на устройстве выгрузки, ни в файловой системе. Так происходит, если процесс обращается к страницам с виртуальными адресами 3К и 65К (см. Рисунок 9.22): ни один из процессов не обращался к этим страницам с тех пор, как файл был запущен на выполнение функцией exec.
В завершение своей работы программа обработки отказов из-за отсутствия (недоступности) данных устанавливает бит доступности страницы и сбрасывает бит модификации. Приоритет процесса при этом пересчитывается, ибо во время выполнения программы процесс мог приостановить свое выполнение на уровне ядра, получая тем самым по возвращении в режим задачи незаслуженное преимущество перед другими процессами. И, наконец, возвращаясь в режим задачи, программа проверяет, не было ли за время обработки отказа поступления каких-либо сигналов.
9.2.3.2 Обработка прерываний по отказу системы защиты
Вторым типом отказа, встречающегося при обращении к странице, является отказ системы защиты, который означает, что процесс обратился к существующей странице памяти, но судя по разрядам, описывающим права доступа к странице, доступ к ней со стороны текущего процесса не разрешен. (Вспомним пример, описывающий попытку процесса произвести запись данных в область команд; см. Рисунок 7.22). Отказ данного типа имеет место также тогда, когда процесс предпринимает попытку записать что-то на страницу, для которой во время выполнения системной функции fork был установлен бит копирования при записи. Ядро должно различать между собой ситуации, когда отказ произошел по причине того, что страница требует копирования при записи, и когда имело место действительно что-то недопустимое.
Программа обработки отказа системы защиты автоматически получает виртуальный адрес, по которому произошел отказ, и ведет поиск соответствующей области и записи таблицы страниц (Рисунок 9.25). Она блокирует область, чтобы "сборщик" страниц не мог выгрузить страницу, пока связанный с ней отказ не будет обработан. Если программа обработки отказа устанавливает, что причиной отказа послужила установка бита копирования при записи, и если страницу используют сразу несколько процессов, ядро выделяет в памяти новую страницу и копирует в нее содержимое старой страницы; ссылки других процессов на старую страницу сохраняют свое значение. После копирования и внесения в запись таблицы страниц нового номера страницы ядро уменьшает значение счетчика ссылок в записи таблицы pfdata, соответствующей старой странице. Вся процедура показана на Рисунке 9.26, где три процесса совместно используют физическую страницу с номером 828. Процесс B считывает страницу, но поскольку бит копирования при записи установлен, получает отказ системы защиты. Программа обработки отказа выделяет страницу с номером 786, копирует в нее содержимое страницы 828, уменьшает значение счетчика ссылок на скопированную страницу и перенастраивает соответствующую запись таблицы страниц на страницу с номером 786.
Если бит копирования при записи установлен, но страница используется только одним процессом, ядро дает процессу возможность воспользоваться физической страницей повторно. Оно отключает бит копирования при записи и разрывает связь страницы с ее копией на диске (если таковая существует), поскольку не исключена возможность того, что дисковой копией пользуются другие процессы. Затем ядро убирает запись таблицы pfdata из очереди страниц, ибо новая копия виртуальной страницы располагается не на устройстве выгрузки. Кроме того, ядро уменьшает значение счетчика ссылок на страницу в таблице использования области подкачки, и если это значение становится равным 0, освобождает место на устройстве (см. упражнение 9.11).
Если запись в таблице страниц указывает на то, что страница недоступна, и ее бит копирования при записи установлен, выступая поводом для отказа системы защиты, допустим, что система при обращении к странице сначала обрабатывает отказ из-за недоступности данных (обратная очередность рассматривается в упражнении 9.17). Несмотря на это, программа обработки отказа системы защиты все равно обязана убедиться в доступности страницы, поскольку при установке блокировки на область программа может приостановиться, а "сборщик" страниц тем временем может выгрузить страницу из памяти. Если страница недоступна (бит доступности сброшен), программа немедленно завершит работу и процесс получит отказ из-за недоступности данных. Ядро обработает этот отказ, но процесс вновь получит отказ системы защиты. Более чем вероятно, что заключительный отказ системы защиты будет обработан без каких-либо препятствий и помех, поскольку пройдет довольно значительный период времени, прежде чем страница достаточно "созреет" для выгрузки из памяти. Описанная последовательность событий показана на Рисунке 9.27.
. Файлы в дереве файловой системы
Рисунок 5.28. Файлы в дереве файловой системы, связанные с помощью функции link

Формат файловой системы
Рисунок 2.3. Формат файловой системы

Файловая система имеет следующую структуру (Рисунок 2.3).
Блок загрузки располагается в начале пространства, отведенного под файловую систему, обычно в первом секторе, и содержит программу начальной загрузки, которая считывается в машину при загрузке или инициализации операционной системы. Хотя для запуска системы требуется только один блок загрузки, каждая файловая система имеет свой (пусть даже пустой) блок загрузки. Суперблок описывает состояние файловой системы - какого она размера, сколько файлов может в ней храниться, где располагается свободное пространство, доступное для файловой системы, и другая информация. Список индексов в файловой системе располагается вслед за суперблоком. Администраторы указывают размер списка индексов при генерации файловой системы. Ядро операционной системы обращается к индексам, используя указатели в списке индексов. Один из индексов является корневым индексом файловой системы: это индекс, по которому осуществляется доступ к структуре каталогов файловой системы после выполнения системной операции mount (монтировать) (раздел 5.14). Информационные блоки располагаются сразу после списка индексов и содержат данные файлов и управляющие данные. Отдельно взятый информационный блок может принадлежать одному и только одному файлу в файловой системе.. Формат каталога /etc
Рисунок 4.10. Формат каталога /etc
| 0 | 83 | . |
| 16 | 2 | .. |
| 32 | 1798 | init |
| 48 | 1276 | fsck |
| 64 | 85 | clri |
| 80 | 1268 | motd |
| 96 | 1799 | mount |
| 112 | 88 | mknod |
| 128 | 2114 | passwd |
| 144 | 1717 | umount |
| 160 | 1851 | checklist |
| 176 | 92 | fsdbld |
| 192 | 84 | config |
| 208 | 1432 | getty |
| 224 | 0 | crash |
| 240 | 95 | mkfs |
| 256 | 188 | inittab |
На Рисунке 4.10 показан формат каталога "etc". В каждом каталоге имеются файлы, в качестве имен которых указаны точка и две точки ("." и "..") и номера индексов у которых совпадают с номерами индексов данного каталога и родительского каталога, соответственно. Номер индекса для файла "." в каталоге "/etc" имеет адрес со смещением 0 и значение 83. Номер индекса для файла ".." имеет адрес со смещением 16 от начала каталога и значение 2. Записи в каталоге могут быть пустыми, при этом номер индекса равен 0. Например, запись с адресом 224 в каталоге "/etc" пустая, несмотря на то, что она когда-то содержала точку входа для файла с именем "crash". Программа mkfs инициализирует файловую систему таким образом, что номера индексов для файлов "." и ".." в корневом каталоге совпадают с номером корневого индекса файловой системы.
Ядро хранит данные в каталоге так же, как оно это делает в файле обычного типа, используя индексную структуру и блоки с уровнями прямой и косвенной адресации. Процессы могут читать данные из каталогов таким же образом, как они читают обычные файлы, однако исключительное право записи в каталог резервируется ядром, благодаря чему обеспечивается правильность структуры каталога. Права доступа к каталогу имеют следующий смысл: право чтения дает процессам возможность читать данные из каталога; право записи позволяет процессу создавать новые записи в каталоге или удалять старые (с помощью системных операций creat, mknod, link и unlink), в результате чего изменяется содержимое каталога; право исполнения позволяет процессу производить поиск в каталоге по имени файла (поскольку "исполнять" каталог бессмысленно). На примере Упражнения 4.6 показана разница между чтением и поиском в каталоге.
. Фрагмент файла inittab
Рисунок 7.32. Фрагмент файла inittab
| Формат: идентификатор, состояние, действие, спецификация процесса Поля разделены между собой двоеточиями Комментарии в конце строки начинаются с символа '#' co::respawn:/etc/getty console console #Консоль в машзале 46:2:respawn:/etc/getty -t 60 tty46 4800H #комментарии |
Функции для работы с файловой
Рисунок 5.1. Функции для работы с файловой системой и их связь с другими алгоритмами
На Рисунке 5.1 показана взаимосвязь между системными функциями и алгоритмами, описанными ранее. Системные функции классифицируются на несколько категорий, хотя некоторые из функций присутствуют более, чем в одной категории:
Системные функции, возвращающие дескрипторы файлов для использования другими системными функциями; Системные функции, использующие алгоритм namei для анализа имени пути поиска; Системные функции, назначающие и освобождающие индекс с использованием алгоритмов ialloc и ifree; Системные функции, устанавливающие или изменяющие атрибуты файла; Системные функции, позволяющие процессу производить ввод-вывод данных с использованием алгоритмов alloc, free и алгоритмов выделения буфера; Системные функции, изменяющие структуру файловой системы; Системные функции, позволяющие процессу изменять собственное представление о структуре дерева файловой системы.. Функция vfork и искажение информации процесса
Рисунок 9.16. Функция vfork и искажение информации процесса
| int global; main() { int local; local = 1; if (vfork() == 0) { /* потомок */ global = 2; /* запись в область данных родителя */ local = 3; /* запись в стек родителя */ _exit(); } printf("global %d local %d\n",global,local); } |
В качестве примера рассмотрим программу, приведенную на Рисунке 9.16. После выполнения функции vfork процесс-потомок не запускает функцию exec, а переустанавливает значения переменных global и local и завершается (****). Система гарантирует, что процесс-родитель приостанавливается до того момента, когда потомок исполнит функции exec или exit. Возобновив в конечном итоге свое выполнение, процесс-родитель обнаружит, что значения двух его переменных не совпадают с теми значениями, которые были у них до обращения к функции vfork ! Еще больший эффект может произвести возвращение процесса-потомка из функции, вызвавшей функцию vfork (см. упражнение 9.8).
9.2.1.2 Функция exec в системе с замещением страниц
Как уже говорилось в главе 7, когда процесс обращается к системной функции exec, ядро считывает из файловой системы в память указанный исполняемый файл. Однако в системе с замещением страниц по запросу исполняемый файл, имеющий большой размер, может не уместиться в доступном пространстве основной памяти. Поэтому ядро не назначает ему сразу все пространство, а отводит место в памяти по мере надобности. Сначала ядро назначает файлу таблицы страниц и дескрипторы дисковых блоков, помечая страницы в записях таблиц как "заполняемые при обращении" (для всех данных, кроме имеющих тип bss) или "обнуляемые при обращении" (для данных типа bss). Считывая в память каждую страницу файла по алгоритму read, процесс получает ошибку из-за отсутствия (недоступности) данных. Подпрограмма обработки ошибок проверяет, является ли страница "заполняемой при обращении" (тогда ее содержимое будет немедленно затираться содержимым исполняемого файла и поэтому ее не надо очищать) или "обнуляемой при обращении" (тогда ее следует очистить). В разделе 9.2.3 мы увидим, как это происходит. Если процесс не может поместиться в памяти, "сборщик" страниц освобождает для него место, периодически откачивая из памяти неиспользуемые страницы.
В этой схеме видны явные недостатки. Во-первых, при чтении каждой страницы исполняемого файла процесс сталкивается с ошибкой из-за обращения к отсутствующей странице, пусть даже процесс никогда и не обращался к ней. Во-вторых, если после того, как "сборщик" страниц откачал часть страниц из памяти, была запущена функция exec, каждая только что выгруженная и вновь понадобившаяся страница потребует дополнительную операцию по ее загрузке. Чтобы повысить эффективность функции exec, ядро может востребовать страницу непосредственно из исполняемого файла, если данные в файле соответствующим образом настроены, что определяется значением т.н. "магического числа". Однако, использование стандартных алгоритмов доступа к файлу (например, bmap) потребовало бы при обращении к странице, состоящей из блоков косвенной адресации, больших затрат, связанных с многократным использованием буферного кэша для чтения каждого блока. Кроме того, функция bmap не является реентерабельной, отсюда возникает опасность нарушения целостности данных. Во время выполнения системной функции read ядро устанавливает в пространстве процесса значения различных параметров ввода-вывода. Если при попытке скопировать данные в пространство пользователя процесс столкнется с отсутствием нужной страницы, он, считывая страницу из файловой системы, может затереть содержащие эти параметры поля. Поэтому ядро не может прибегать к использованию обычных алгоритмов обработки ошибок данного рода. Конечно же алгоритмы должны быть в обычных случаях реентерабельными, поскольку у каждого процесса свое отдельное адресное пространство и процесс не может одновременно исполнять несколько системных функций.
Для того, чтобы считывать страницы непосредственно из исполняемого файла, ядро во время исполнения функции exec составляет список номеров дисковых блоков файла и присоединяет этот список к индексу файла. Работая с таблицами страниц такого файла, ядро находит дескриптор дискового блока, содержащего страницу, и запоминает номер блока внутри файла; этот номер позже используется при загрузке страницы из файла. На Рисунке 9.17 показан пример, в котором страница имеет адрес расположения в логическом блоке с номером 84 от начала файла. В области имеется указатель на индекс, в котором содержится номер соответствующего физического блока на диске (279).
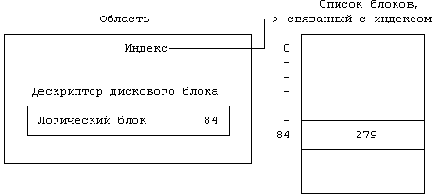
ГЛАВА 1. ОБЩИЙ ОБЗОР ОСОБЕННОСТЕЙ СИСТЕМЫ
ГЛАВА 1. ОБЩИЙ ОБЗОР ОСОБЕННОСТЕЙ СИСТЕМЫ
За время, прошедшее с момента ее появления в 1969 году, система UNIX стала довольно популярной и получила распространение на машинах с различной мощностью обработки, от микропроцессоров до больших ЭВМ, обеспечивая на них общие условия выполнения программ. Система делится на две части. Одну часть составляют программы и сервисные функции, то, что делает операционную среду UNIX такой популярной; эта часть легко доступна пользователям, она включает такие программы, как командный процессор, обмен сообщениями, пакеты обработки текстов и системы обработки исходных текстов программ. Другая часть включает в себя собственно операционную систему, поддерживающую эти программы и функции. В этой книге дается детальное описание собственно операционной системы. Основное внимание концентрируется на описании системы UNIX версии V, распространением которой занимается корпорация AT&T, при этом рассматриваются интересные особенности и других версий. Приводятся основные информационные структуры и алгоритмы, используемые в операционной системе и в конечном итоге создающие условия для функционирования стандартного пользовательского интерфейса.
Данная глава служит введением в систему UNIX. В ней делается обзор истории ее создания и намечаются контуры общей структуры системы. В следующей главе содержится более детальная вводная информация по операционной системе.
ГЛАВА 2. ВВЕДЕНИЕ В АРХИТЕКТУРУ ЯДРА ОПЕРАЦИОННОЙ СИСТЕМЫ
ГЛАВА 2. ВВЕДЕНИЕ В АРХИТЕКТУРУ ЯДРА ОПЕРАЦИОННОЙ СИСТЕМЫ
В предыдущей главе был сделан только поверхностный обзор особенностей операционной среды UNIX. В этой главе основное внимание уделяется ядру операционной системы, делается обзор его архитектуры и излагаются в общих чертах основные понятия и структуры, существенные для понимания всего последующего материала книги.
ГЛАВА 3. БУФЕР СВЕРХОПЕРАТИВНОЙ ПАМЯТИ (КЕШ)
ГЛАВА 3. БУФЕР СВЕРХОПЕРАТИВНОЙ ПАМЯТИ (КЕШ)
Как уже говорилось в предыдущей главе, ядро операционной системы поддерживает файлы на внешних запоминающих устройствах большой емкости, таких как диски, и позволяет процессам сохранять новую информацию или вызывать ранее сохраненную информацию. Если процессу необходимо обратиться к информации файла, ядро выбирает информацию в оперативную память, где процесс сможет просматривать эту информацию, изменять ее и обращаться с просьбой о ее повторном сохранении в файловой системе. Вспомним для примера программу copy, приведенную на Рисунке 1.3: ядро читает данные из первого файла в память и затем записывает эти данные во второй файл. Подобно тому, как ядро должно заносить данные из файла в память, оно так же должно считывать в память и вспомогательные данные для работы с ними. Например, суперблок файловой системы содержит помимо всего прочего информацию о свободном пространстве, доступном файловой системе. Ядро считывает суперблок в память для того, чтобы иметь доступ к его информации, и возвращает его опять файловой системе, когда желает сохранить его содержимое. Похожая вещь происходит с индексом, который описывает размещение файла. Ядро системы считывает индекс в память, когда желает получить доступ к информации файла, и возвращает индекс вновь файловой системе, когда желает скорректировать размещение файла. Ядро обрабатывает такую вспомогательную информацию, не будучи прежде знакома с ней и не требуя для ее обработки запуска каких-либо процессов.
Ядро могло бы производить чтение и запись непосредственно с диска и на диск при всех обращениях к файловой системе, однако время реакции системы и производительность при этом были бы низкими из-за низкой скорости передачи данных с диска. По этой причине ядро старается свести к минимуму частоту обращений к диску, заведя специальную область внутренних информационных буферов, именуемую буферным кешем (*). и хранящую содержимое блоков диска, к которым перед этим производились обращения.
На Рисунке 2.1 показано, что модуль буферного кеша занимает в архитектуре ядра место между подсистемой управления файлами и драйверами устройств (ввода-вывода блоками). Перед чтением информации с диска ядро пытается считать что-нибудь из буфера кеша. Если в этом буфере отсутствует информация, ядро читает данные с диска и заносит их в буфер, используя алгоритм, который имеет целью поместить в буфере как можно больше необходимых данных. Аналогично, информация, записываемая на диск, заносится в буфер для того, чтобы находиться там, если ядро позднее попытается считать ее. Ядро также старается свести к минимуму частоту выполнения операций записи на диск, выясняя, должна ли информация действительно запоминаться на диске или это промежуточные данные, которые будут вскоре затерты. Алгоритмы более высокого уровня позволяют производить предварительное занесение данных в буфер кеша или задерживать запись данных с тем, чтобы усилить эффект использования буфера. В этой главе рассматриваются алгоритмы, используемые ядром при работе с буферами в сверхоперативной памяти.
(*) Буферный кеш представляет собой программную структуру, которую не следует путать с аппаратными кешами, ускоряющими косвенную адресацию памяти.
ГЛАВА 4. ВНУТРЕННЕЕ ПРЕДСТАВЛЕНИЕ ФАЙЛОВ
ГЛАВА 4. ВНУТРЕННЕЕ ПРЕДСТАВЛЕНИЕ ФАЙЛОВ
Как уже было замечено в главе 2, каждый файл в системе UNIX имеет уникальный индекс. Индекс содержит информацию, необходимую любому процессу для того, чтобы обратиться к файлу, например, права собственности на файл, права доступа к файлу, размер файла и расположение данных файла в файловой системе. Процессы обращаются к файлам, используя четко определенный набор системных вызовов и идентифицируя файл строкой символов, выступающих в качестве составного имени файла. Каждое составное имя однозначно определяет файл, благодаря чему ядро системы преобразует это имя в индекс файла.
Эта глава посвящена описанию внутренней структуры файлов в операционной системе UNIX, в следующей же главе рассматриваются обращения к операционной системе, связанные с обработкой файлов. Раздел 4.1 касается индекса и работы с ним ядра, раздел 4.2 - внутренней структуры обычных файлов и некоторых моментов, связанных с чтением и записью ядром информации файлов. В разделе 4.3 исследуется строение каталогов - структур данных, позволяющих ядру организовывать файловую систему в виде иерархии файлов, раздел 4.4 содержит алгоритм преобразования имен пользовательских файлов в индексы. В разделе 4.5 дается структура суперблока, а в разделах 4.6 и 4.7 представлены алгоритмы назначения файлам дисковых индексов и дисковых блоков. Наконец, в разделе 4.8 идет речь о других типах файлов в системе, а именно о каналах и файлах устройств.
Алгоритмы, описанные в этой главе, уровнем выше по сравнению с алгоритмами управления буферным кешем, рассмотренными в предыдущей главе (Рисунок 4.1). Алгоритм iget возвращает последний из идентифицированных индексов с возможностью считывания его с диска, используя буферный кеш, а алгоритм iput освобождает индекс. Алгоритм bmap устанавливает параметры ядра, связанные с обращением к файлу. Алгоритм namei преобразует составное имя пользовательского файла в имя индекса, используя алгоритмы iget, iput и bmap. Алгоритмы alloc и free выделяют и освобождают дисковые блоки для файлов, алгоритмы ialloc и ifree назначают и освобождают для файлов индексы.
ГЛАВА 5. СИСТЕМНЫЕ ОПЕРАЦИИ ДЛЯ РАБОТЫ С ФАЙЛОВОЙ СИСТЕМОЙ
ГЛАВА 5. СИСТЕМНЫЕ ОПЕРАЦИИ ДЛЯ РАБОТЫ С ФАЙЛОВОЙ СИСТЕМОЙ
В последней главе рассматривались внутренние структуры данных для файловой системы и алгоритмы работы с ними. В этой главе речь пойдет о системных функциях для работы с файловой системой с использованием понятий, введенных в предыдущей главе. Рассматриваются системные функции, обеспечивающие обращение к существующим файлам, такие как open, read, write, lseek и close, затем функции создания новых файлов, а именно, creat и mknod, и, наконец, функции для работы с индексом или для передвижения по файловой системе: chdir, chroot, chown, stat и fstat. Исследуются более сложные системные функции: pipe и dup имеют важное значение для реализации каналов в shell'е; mount и umount расширяют видимое для пользователя дерево файловых систем; link и unlink изменяют иерархическую структуру файловой системы. Затем дается представление об абстракциях, связанных с файловой системой, в отношении поддержки различных файловых систем, подчиняющихся стандартным интерфейсам. В последнем разделе главы речь пойдет о сопровождении файловой системы. Глава знакомит с тремя структурами данных ядра: таблицей файлов, в которой каждая запись связана с одним из открытых в системе файлов, таблицей пользовательских дескрипторов файлов, в которой каждая запись связана с файловым дескриптором, известным процессу, и таблицей монтирования, в которой содержится информация по каждой активной файловой системе.
ГЛАВА 6. СТРУКТУРА ПРОЦЕССОВ
ГЛАВА 6. СТРУКТУРА ПРОЦЕССОВ
В главе 2 были сформулированы характеристики процессов. В настоящей главе на более формальном уровне определяется понятие "контекст процесса" и показывается, каким образом ядро идентифицирует процесс и определяет его местонахождение. В разделе 6.1 описаны модель состояний процессов для системы UNIX и последовательность возможных переходов из состояния в состояние. В ядре находится таблица процессов, каждая запись которой описывает состояние одного из активных процессов в системе. В пространстве процесса хранится дополнительная информация, используемая в управлении протеканием процесса. Запись в таблице процессов и пространство процесса составляют в совокупности контекст процесса. Аспектом контекста процесса, наиболее явно отличающим данный контекст от контекста другого процесса, без сомнения является содержимое адресного пространства процесса. В разделе 6.2 описываются принципы управления распределением памяти для процессов и ядра, а также взаимодействие операционной системы с аппаратными средствами при трансляции виртуальных адресов в физические. Раздел 6.3 посвящен рассмотрению составных элементов контекста процесса, а также описанию алгоритмов управления контекстом процесса. Раздел 6.4 демонстрирует, каким образом осуществляется сохранение контекста процесса ядром в случае прерывания, вызова системной функции или переключения контекста, а также каким образом возобновляется выполнение приостановленного процесса. В разделе 6.5 приводятся различные алгоритмы, используемые в тех системных функциях, которые работают с адресным пространством процесса и которые будут рассмотрены в следующей главе. И, наконец, в разделе 6.6 рассматриваются алгоритмы приостанова и возобновления выполнения процессов.