ГЛАВА 7. УПРАВЛЕНИЕ ПРОЦЕССАМИ
ГЛАВА 7. УПРАВЛЕНИЕ ПРОЦЕССАМИ
В предыдущей главе был рассмотрен контекст процесса и описаны алгоритмы для работы с ним; в данной главе речь пойдет об использовании и реализации системных функций, управляющих контекстом процесса. Системная функция fork создает новый процесс, функция exit завершает выполнение процесса, а wait дает возможность родительскому процессу синхронизировать свое продолжение с завершением порожденного процесса. Об асинхронных событиях процессы информируются при помощи сигналов. Поскольку ядро синхронизирует выполнение функций exit и wait при помощи сигналов, описание механизма сигналов предваряет собой рассмотрение функций exit и wait. Системная функция exec дает процессу возможность запускать "новую" программу, накладывая ее адресное пространство на исполняемый образ файла. Системная функция brk позволяет динамически выделять дополнительную память; теми же самыми средствами ядро динамически наращивает стек задачи, выделяя в случае необходимости дополнительное пространство. В заключительной части главы дается краткое описание основных групп операций командного процессора shell и начального процесса init.
На Рисунке 7.1 показана взаимосвязь между системными функциями, рассматриваемыми в данной главе, с одной стороны, и алгоритмами, описанными в предыдущей главе, с другой. Почти во всех функциях используются алгоритмы sleep и wakeup, отсутствующие на рисунке. Функция exec, кроме того, взаимодействует с алгоритмами работы с файловой системой, речь о которых шла в главах 4 и 5.
ГЛАВА 8. ДИСПЕТЧЕРИЗАЦИЯ ПРОЦЕССОВ
ГЛАВА 8. ДИСПЕТЧЕРИЗАЦИЯ ПРОЦЕССОВ И ЕЕ ВРЕМЕННЫЕ ХАРАКТЕРИСТИКИ
В системе разделения времени ядро предоставляет процессу ресурсы центрального процессора (ЦП) на интервал времени, называемый квантом, по истечении которого выгружает этот процесс и запускает другой, периодически переупорядочивая очередь процессов. Алгоритм планирования процессов в системе UNIX использует время выполнения в качестве параметра. Каждый активный процесс имеет приоритет планирования; ядро переключает контекст на процесс с наивысшим приоритетом. При переходе выполняющегося процесса из режима ядра в режим задачи ядро пересчитывает его приоритет, периодически и в режиме задачи переустанавливая приоритет каждого процесса, готового к выполнению.
Информация о времени, связанном с выполнением, нужна также и некоторым из пользовательских процессов: используемая ими, например, команда time позволяет узнать, сколько времени занимает выполнение другой команды, команда date выводит текущую дату и время суток. С помощью различных системных функций процессы могут устанавливать или получать временные характеристики выполнения в режиме ядра, а также степень загруженности центрального процессора. Время в системе поддерживается с помощью аппаратных часов, которые посылают ЦП прерывания с фиксированной, аппаратно-зависимой частотой, обычно 50-100 раз в секунду. Каждое поступление прерывания по таймеру (часам) именуется таймерным тиком. В настоящей главе рассматриваются особенности реализации процессов во времени, включая планирование процессов в системе UNIX, описание связанных со временем системных функций, а также функций, выполняемых программой обработки прерываний по таймеру.
ГЛАВА 9. АЛГОРИТМЫ УПРАВЛЕНИЯ ПАМЯТЬЮ
ГЛАВА 9. АЛГОРИТМЫ УПРАВЛЕНИЯ ПАМЯТЬЮ
Алгоритм планирования использования процессорного времени, рассмотренный в предыдущей главе, в сильной степени зависит от выбранной стратегии управления памятью. Процесс может выполняться, если он хотя бы частично присутствует в основной памяти; ЦП не может исполнять процесс, полностью выгруженный во внешнюю память. Тем не менее, основная память - чересчур дефицитный ресурс, который зачастую не может вместить все активные процессы в системе. Если, например, в системе имеется основная память объемом 8 Мбайт, то девять процессов размером по 1 Мбайту каждый уже не смогут в ней одновременно помещаться. Какие процессы в таком случае следует размещать в памяти (хотя бы частично), а какие нет, решает подсистема управления памятью, она же управляет участками виртуального адресного пространства процесса, не резидентными в памяти. Она следит за объемом доступного пространства основной памяти и имеет право периодически переписывать процессы на устройство внешней памяти, именуемое устройством выгрузки, освобождая в основной памяти дополнительное место. Позднее ядро может вновь поместить данные с устройства выгрузки в основную память.
В ранних версиях системы UNIX процессы переносились между основной памятью и устройством выгрузки целиком и, за исключением разделяемой области команд, отдельные независимые части процесса не могли быть объектами перемещения. Такая стратегия управления памятью называется свопингом (подкачкой). Такую стратегию имело смысл реализовывать на машине типа PDP-11, где максимальный размер процесса составлял 64 Кбайта. При использовании этой стратегии размер процесса ограничивается объемом физической памяти, доступной в системе. Система BSD (версия 4.0) явилась главным полигоном для применения другой стратегии, стратегии "подкачки по обращению" (demand paging), в соответствии с которой основная память обменивается с внешней не процессами, а страницами памяти; эта стратегия поддерживается и в последних редакциях версии V системы UNIX. Держать в основной памяти весь выполняемый процесс нет необходимости, и ядро загружает в память только отдельные страницы по запросу выполняющегося процесса, ссылающегося на них. Преимущество стратегии подкачки по обращению состоит в том, что благодаря ей отображение виртуального адресного пространства процесса на физическую память машины становится более гибким: допускается превышение размером процесса объема доступной физической памяти и одновременное размещение в основной памяти большего числа процессов. Преимущество стратегии свопинга состоит в простоте реализации и облегчении "надстроечной" части системы. Обе стратегии управления памятью рассматриваются в настоящей главе.
ГЛАВА 10. ПОДСИСТЕМА УПРАВЛЕНИЯ ВВОДОМ-ВЫВОДОМ
ГЛАВА 10. ПОДСИСТЕМА УПРАВЛЕНИЯ ВВОДОМ-ВЫВОДОМ
Подсистема управления вводом-выводом позволяет процессам поддерживать связь с периферийными устройствами, такими как накопители на магнитных дисках и лентах, терминалы, принтеры и сети, с одной стороны, и с модулями ядра, которые управляют устройствами и именуются драйверами устройств, с другой. Между драйверами устройств и типами устройств обычно существует однозначное соответствие: в системе может быть один дисковый драйвер для управления всеми дисководами, один терминальный драйвер для управления всеми терминалами и один ленточный драйвер для управления всеми ленточными накопителями. Если в системе имеются однотипные устройства, полученные от разных изготовителей - например, две марки ленточных накопителей, - в этом случае можно трактовать однотипные устройства как устройства двух различных типов и иметь для них два отдельных драйвера, поскольку таким устройствам для выполнения одних и тех же операций могут потребоваться разные последовательности команд. Один драйвер управляет множеством физических устройств данного типа. Например, один терминальный драйвер может управлять всеми терминалами, подключенными к системе. Драйвер различает устройства, которыми управляет: выходные данные, предназначенные для одного терминала, не должны быть посланы на другой.
Система поддерживает "программные устройства", с каждым из которых не связано ни одно конкретное физическое устройство. Например, как устройство трактуется физическая память, чтобы позволить процессу обращаться к ней извне, пусть даже память не является периферийным устройством. Команда ps обращается к информационным структурам ядра в физической памяти, чтобы сообщить статистику процессов. Еще один пример: драйверы могут вести трассировку записей в удобном для отладки виде, а драйвер трассировки дает возможность пользователям читать эти записи. Наконец, профиль ядра, рассмотренный в главе 8, выполнен как драйвер: процесс записывает адреса программ ядра, обнаруженных в таблице идентификаторов ядра, и читает результаты профилирования.
В этой главе рассматривается взаимодействие между процессами и подсистемой управления вводом-выводом, а также между машиной и драйверами устройств. Исследуется общая структура и функционирование драйверов и в качестве примеров общего взаимодействия рассматриваются дисковые и терминальные драйверы. Завершает главу описание нового метода реализации драйверов потоковых устройств.
ГЛАВА 11. ВЗАИМОДЕЙСТВИЕ ПРОЦЕССОВ
ГЛАВА 11. ВЗАИМОДЕЙСТВИЕ ПРОЦЕССОВ
Наличие механизмов взаимодействия дает произвольным процессам возможность осуществлять обмен данными и синхронизировать свое выполнение с другими процессами. Мы уже рассмотрели несколько форм взаимодействия процессов, такие как канальная связь, использование поименованных каналов и посылка сигналов. Каналы (непоименованные) имеют недостаток, связанный с тем, что они известны только потомкам процесса, вызвавшего системную функцию pipe: не имеющие родственных связей процессы не могут взаимодействовать между собой с помощью непоименованных каналов. Несмотря на то, что поименованные каналы позволяют взаимодействовать между собой процессам, не имеющим родственных связей, они не могут использоваться ни в сети (см. главу 13), ни в организации множественных связей между различными группами взаимодействующих процессов: поименованный канал не поддается такому мультиплексированию, при котором у каждой пары взаимодействующих процессов имелся бы свой выделенный канал. Произвольные процессы могут также связываться между собой благодаря посылке сигналов с помощью системной функции kill, однако такое "сообщение" состоит из одного только номера сигнала.
В данной главе описываются другие формы взаимодействия процессов. В начале речь идет о трассировке процессов, о том, каким образом один процесс следит за ходом выполнения другого процесса, затем рассматривается пакет IPC: сообщения, разделяемая память и семафоры. Делается обзор традиционных методов сетевого взаимодействия процессов, выполняющихся на разных машинах, и, наконец, дается представление о "гнездах", применяющихся в системе BSD. Вопросы сетевого взаимодействия, имеющие специальный характер, такие как протоколы, адресация и др., не рассматриваются, поскольку они выходят за рамки настоящей работы.
ГЛАВА 12. МНОГОПРОЦЕССОРНЫЕ СИСТЕМЫ
ГЛАВА 12. МНОГОПРОЦЕССОРНЫЕ СИСТЕМЫ
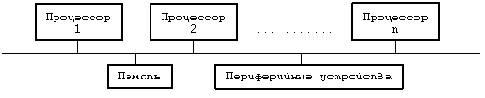
В классической постановке для системы UNIX предполагается использование однопроцессорной архитектуры, состоящей из одного ЦП, памяти и периферийных устройств. Многопроцессорная архитектура, напротив, включает в себя два и более ЦП, совместно использующих общую память и периферийные устройства (Рисунок 12.1), располагая большими возможностями в увеличении производительности системы, связанными с одновременным исполнением процессов на разных ЦП. Каждый ЦП функционирует независимо от других, но все они работают с одним и тем же ядром операционной системы. Поведение процессов в такой системе ничем не отличается от поведения в однопроцессорной системе - с сохранением семантики обращения к каждой системной функции - но при этом они могут открыто перемещаться с одного процессора на другой. Хотя, к сожалению, это не приводит к снижению затрат процессорного времени, связанного с выполнением процесса. Отдельные многопроцессорные системы называются системами с присоединенными процессорами, поскольку в них периферийные устройства доступны не для всех процессоров. За исключением особо оговоренных случаев, в настоящей главе не проводится никаких различий между системами с присоединенными процессорами и остальными классами многопроцессорных систем.
Параллельная работа нескольких процессоров в режиме ядра по выполнению различных процессов создает ряд проблем, связанных с сохранением целостности данных и решаемых благодаря использованию соответствующих механизмов защиты. Ниже будет показано, почему классический вариант системы UNIX не может быть принят в многопроцессорных системах без внесения необходимых изменений, а также будут рассмотрены два варианта, предназначенные для работы в указанной среде.
. Иллюстрация к отказу из-за недоступности данных
Рисунок 9.22. Иллюстрация к отказу из-за недоступности данных
Как и ядру, программе обработки отказа не нужно считывать страницу в память, если какой-то иной процесс уже получил отказ по той же самой странице, но еще не полностью загрузил ее. Программа находит область с записью таблицы страниц, которую она уже ранее заблокировала. Она дожидается, пока будет закончен цикл обработки предыдущего отказа, после чего обнаруживает, что страница стала доступной, и завершает свою работу. Эта процедура прослеживается на Рисунке 9.24.
. Имитация установки "аппаратного"
Рисунок 9.28. Имитация установки "аппаратного" бита модификации программными средствами
(***) Если при исполнении команды возникает ошибка, связанная с отсутствием страницы, после обработки ошибки ЦП обязан перезапустить команду, поскольку промежуточные результаты, полученные к моменту возникновения ошибки, могут быть утрачены.
(****) Функция exit используется в варианте _exit, потому что она "очищает" структуры данных, передаваемые через стандартный ввод-вывод (на пользовательском уровне), для обоих процессов, так что оператор printf, используемый родителем, не даст правильный результат - еще один нежелательный побочный эффект от применения функции vfork.
. Индексы для файловых систем различных типов
Рисунок 5.34. Индексы для файловых систем различных типов

Индекс выступает интерфейсом между абстрактной файловой системой и отдельной файловой системой. Общая копия индекса в памяти содержит информацию, не зависящую от отдельной файловой системы, а также указатель на частный индекс файловой системы, который уже содержит информацию, специфичную для нее. Частный индекс файловой системы содержит такую информацию, как права доступа и расположение блоков, а общий индекс содержит номер устройства, номер индекса на диске, тип файла, размер, информацию о владельце и счетчик ссылок. Другая частная информация, описывающая отдельную файловую систему, содержится в суперблоке и структуре каталогов. На Рисунке 5.34 изображены таблица общих индексов в памяти и две таблицы частных индексов отдельных файловых систем, одна для структур файловой системы версии V, а другая для индекса удаленной (сетевой) системы. Предполагается, что последний индекс содержит достаточно информации для того, чтобы идентифицировать файл, находящийся в удаленной системе. У файловой системы может отсутствовать структура, подобная индексу; но исходный текст программ отдельной файловой системы позволяет создать объектный код, удовлетворяющий семантическим требованиям файловой системы UNIX и назначающий свой "индекс", который соответствует общему индексу, назначаемому ядром.
Файловая система каждого типа имеет некую структуру, в которой хранятся адреса функций, реализующих абстрактные действия. Когда ядру нужно обратиться к файлу, оно вызывает косвенную функцию в зависимости от типа файловой системы и абстрактного действия (см. Рисунок 5.34). Примерами абстрактных действий являются: открытие и закрытие файла, чтение и запись данных, возвращение индекса для компоненты имени файла (подобно namei и iget), освобождение индекса (подобно iput), коррекция индекса, проверка прав доступа, установка атрибутов файла (прав доступа к нему), а также монтирование и демонтирование файловых систем. В главе 13 будет проиллюстрировано использование системных абстракций при рассмотрении распределенной файловой системы.
Информационные структуры для процессов
Рисунок 2.5. Информационные структуры для процессов

Каждому процессу соответствует точка входа в таблице процессов ядра, кроме того, каждому процессу выделяется часть оперативной памяти, отведенная под задачу пользователя. Таблица процессов включает в себя указатели на промежуточную таблицу областей процессов, точки входа в которую служат в качестве указателей на собственно таблицу областей. Областью называется непрерывная зона адресного пространства, выделяемая процессу для размещения текста, данных и стека. Точки входа в таблицу областей описывают атрибуты области, как например, хранятся ли в области текст программы или данные, закрытая ли эта область или же совместно используемая, и где конкретно в памяти размещается содержимое области. Внешний уровень косвенной адресации (через промежуточную таблицу областей, используемых процессами, к собственно таблице областей) позволяет независимым процессам совместно использовать области. Когда процесс запускает системную операцию exec, ядро системы выделяет области под ее текст, данные и стек, освобождая старые области, которые использовались процессом. Если процесс запускает операцию fork, ядро удваивает размер адресного пространства старого процесса, позволяя процессам совместно использовать области, когда это возможно, и, с другой стороны, производя физическое копирование. Если процесс запускает операцию exit, ядро освобождает области, которые использовались процессом. На Рисунке 2.5 изображены информационные структуры, связанные с запуском процесса. Таблица процессов ссылается на промежуточную таблицу областей, используемых процессом, в которой содержатся указатели на записи в собственно таблице областей, соответствующие областям для текста, данных и стека процесса.
Запись в таблице процессов и часть адресного пространства задачи, выделенная процессу, содержат управляющую информацию и данные о состоянии процесса. Это адресное пространство является расширением соответствующей записи в таблице процессов, различия между данными объектами будут рассмотрены в главе 6. В качестве полей в таблице процессов, которые рассматриваются в последующих разделах, выступают:
поле состояния, идентификаторы, которые характеризуют пользователя, являющегося владельцем процесса (код пользователя или UID), значение дескриптора события, когда процесс приостановлен (находится в состоянии "сна").Адресное пространство задачи, выделенное процессу, содержит описывающую процесс информацию, доступ к которой должен обеспечиваться только во время выполнения процесса. Важными полями являются:
указатель на позицию в таблице процессов, соответствующую текущему процессу, параметры текущей системной операции, возвращаемые значения и коды ошибок, дескрипторы файла для всех открытых файлов, внутренние параметры ввода-вывода, текущий каталог и текущий корень (см. главу 5), границы файлов и процесса.Ядро системы имеет непосредственный доступ к полям адресного пространства задачи, выделенного выполняемому процессу, но не имеет доступ к соответствующим полям других процессов. С точки зрения внутреннего алгоритма, при обращении к адресному пространству задачи, выделенному выполняемому процессу, ядро ссылается на структурную переменную u, и, когда запускается на выполнение другой процесс, ядро перенастраивает виртуальные адреса таким образом, чтобы структурная переменная u указывала бы на адресное пространство задачи для нового процесса. В системной реализации предусмотрено облегчение идентификации текущего процесса благодаря наличию указателя на соответствующую запись в таблице процессов из адресного пространства задачи.
2.2.2.1 Контекст процесса
Контекстом процесса является его состояние, определяемое текстом, значениями глобальных переменных пользователя и информационными структурами, значениями используемых машинных регистров, значениями, хранимыми в позиции таблицы процессов и в адресном пространстве задачи, а также содержимым стеков задачи и ядра, относящихся к данному процессу. Текст операций системы и ее глобальные информационные структуры совместно используются всеми процессами, но не являются составной частью контекста процесса.
Говорят, что при запуске процесса система исполняется в контексте процесса. Когда ядро системы решает запустить другой процесс, оно выполняет переключение контекста с тем, чтобы система исполнялась в контексте другого процесса. Ядро осуществляет переключение контекста только при определенных условиях, что мы увидим в дальнейшем. Выполняя переключение контекста, ядро сохраняет информацию, достаточную для того, чтобы позднее переключиться вновь на первый процесс и возобновить его выполнение. Аналогичным образом, при переходе из режима задачи в режим ядра, ядро системы сохраняет информацию, достаточную для того, чтобы позднее вернуться в режим задачи и продолжить выполнение с прерванного места. Однако, переход из режима задачи в режим ядра является сменой режима, но не переключением контекста. Если обратиться еще раз к Рисунку 1.5, можно сказать, что ядро выполняет переключение контекста, когда меняет контекст процесса A на контекст процесса B; оно меняет режим выполнения с режима задачи на режим ядра и наоборот, оставаясь в контексте одного процесса, например, процесса A.
Ядро обрабатывает прерывания в контексте прерванного процесса, пусть даже оно и не вызывало никакого прерывания. Прерванный процесс мог при этом выполняться как в режиме задачи, так и в режиме ядра. Ядро сохраняет информацию, достаточную для того, чтобы можно было позже возобновить выполнение прерванного процесса, и обрабатывает прерывание в режиме ядра. Ядро не порождает и не планирует порождение какого-то особого процесса по обработке прерываний.
2.2.2.2 Состояния процесса
Время жизни процесса можно разделить на несколько состояний, каждое из которых имеет определенные характеристики, описывающие процесс. Все состояния процесса рассматриваются в главе 6, однако представляется существенным для понимания перечислить некоторые из состояний уже сейчас:
Процесс выполняется в режиме задачи. Процесс выполняется в режиме ядра. Процесс не выполняется, но готов к выполнению и ждет, когда планировщик выберет его. В этом состоянии может находиться много процессов, и алгоритм планирования устанавливает, какой из процессов будет выполняться следующим. Процесс приостановлен ("спит"). Процесс "впадает в сон", когда он не может больше продолжать выполнение, например, когда ждет завершения ввода-вывода.Поскольку процессор в каждый момент времени выполняет только один процесс, в состояниях 1 и 2 может находиться самое большее один процесс. Эти два состояния соответствуют двум режимам выполнения, режиму задачи и режиму ядра.
2.2.2.3 Переходы из состояния в состояние
Состояния процесса, перечисленные выше, дают статическое представление о процессе, однако процессы непрерывно переходят из состояния в состояние в соответствии с определенными правилами. Диаграмма переходов представляет собой ориентированный граф, вершины которого представляют собой состояния, в которые может перейти процесс, а дуги - события, являющиеся причинами перехода процесса из одного состояния в другое. Переход между двумя состояниями разрешен, если существует дуга из первого состояния во второе. Несколько дуг может выходить из одного состояния, однако процесс переходит только по одной из них в зависимости от того, какое событие произошло в системе. На Рисунке 2.6 представлена диаграмма переходов для состояний, перечисленных выше.
Как уже говорилось выше, в режиме разделения времени может выполняться одновременно несколько процессов, и все они могут одновременно работать в режиме ядра. Если им разрешить свободно выполняться в режиме ядра, то они могут испортить глобальные информационные структуры, принадлежащие ядру. Запрещая произвольное переключение контекстов и управляя возникновением событий, ядро защищает свою целостность.
Ядро разрешает переключение контекста только тогда, когда процесс переходит из состояния "запуск в режиме ядра" в состояние "сна в памяти". Процессы, запущенные в режиме ядра, не могут быть выгружены другими процессами; поэтому иногда говорят, что ядро не выгружаемо, при этом процессы, находящиеся в режиме задачи, могут выгружаться системой. Ядро поддерживает целостность своих информационных структур, поскольку оно не выгружаемо, таким образом решая проблему "взаимного исключения" - обеспечения того, что критические секции программы выполняются в каждый момент времени в рамках самое большее одного процесса.
В качестве примера рассмотрим программу (Рисунок 2.7) включения информационной структуры, чей адрес содержится в указателе bp1, в список с использованием указателей после структуры, чей адрес содержится в bp. Если система разрешила переключение контекста при выполнении ядром фрагмента программы, возможно возникновение следующей ситуации. Предположим, ядро выполняет программу до комментариев и затем осуществляет переключение контекста. Список с использованием сдвоенных указателей имеет противоречивый вид: структура bp1 только наполовину входит в этот список. Если процесс следует за передними указателями, он обнаружит bp1 в данном списке, но если он последует за фоновыми указателями, то вообще не найдет структуру bp1 (Рисунок 2.8). Если другие процессы будут обрабатывать указатели в списке до момента повторного запуска первого процесса, структура списка может постоянно разрушаться. Система UNIX предупреждает возникновение подобных ситуаций, запрещая переключение контекстов на время выполнения процесса в режиме ядра. Если процесс переходит в состояние "сна", делая допустимым переключение контекста, алгоритмы ядра обеспечивают защиту целостности информационных структур системы.
Исходный текст программы приема сигналов
Рисунок 7.9. Исходный текст программы приема сигналов
| #include <signal.h> main() { extern catcher(); signal(SIGINT,catcher); kill(0,SIGINT); } catcher() { } |
Использование функций pipe, dup и fork
Рисунок 7.5. Использование функций pipe, dup и fork
| #include <string.h> char string[] = "hello world"; main() { int count,i; int to_par[2],to_chil[2]; /* для каналов родителя и потомка */ char buf[256]; pipe(to_par); pipe(to_chil); if (fork() == 0) { /* выполнение порожденного процесса */ close(0); /* закрытие прежнего стандартного ввода */ dup(to_chil[0]); /* дублирование дескриптора чтения из канала в позицию стандартного ввода */ close(1); /* закрытие прежнего стандартного вывода */ dup(to_par[0]); /* дублирование дескриптора записи в канал в позицию стандартного вывода */ close(to_par[1]); /* закрытие ненужных дескрипторов close(to_chil[0]); канала */ close(to_par[0]); close(to_chil[1]); for (;;) { if ((count = read(0,buf,sizeof(buf))) == 0) exit(); write(1,buf,count); } } /* выполнение родительского процесса */ close(1); /* перенастройка стандартного ввода-вывода */ dup(to_chil[1]); close(0); dup(to_par[0]); close(to_chil[1]); close(to_par[0]); close(to_chil[0]); close(to_par[1]); for (i = 0; i < 15; i++) { write(1,string,strlen(string)); read(0,buf,sizeof(buf)); } } |
Результаты этой программы не зависят от того, в какой очередности процессы выполняют свои действия. Таким образом, нет никакой разницы, возвращается ли управление родительскому процессу из функции fork раньше или позже, чем порожденному процессу. И так же безразличен порядок, в котором процессы вызывают системные функции перед тем, как войти в свой собственный цикл, ибо они используют идентичные структуры ядра. Если процесс-потомок исполняет функцию read раньше, чем его родитель выполнит write, он будет приостановлен до тех пор, пока родительский процесс не произведет запись в канал и тем самым не возобновит выполнение потомка. Если родительский процесс записывает в канал до того, как его потомок приступит к чтению из канала, первый процесс не сможет в свою очередь считать данные из стандартного ввода, пока второй процесс не прочитает все из своего стандартного ввода и не произведет запись данных в стандартный вывод. С этого места порядок работы жестко фиксирован: каждый процесс завершает выполнение функций read и write и не может выполнить следующую операцию read до тех пор, пока другой процесс не выполнит пару read-write. Родительский процесс после 15 итераций завершает работу; порожденный процесс наталкивается на конец файла ("end-of-file"), поскольку канал не связан больше ни с одним из записывающих процессов, и тоже завершает работу. Если порожденный процесс попытается произвести запись в канал после завершения родительского процесса, он получит сигнал о том, что канал не связан ни с одним из процессов чтения.
Мы упомянули о том, что хорошей традицией в программировании является закрытие ненужных файловых дескрипторов. В пользу этого говорят три довода. Во-первых, дескрипторы файлов постоянно находятся под контролем системы, которая накладывает ограничение на их количество. Во-вторых, во время исполнения порожденного процесса присвоение дескрипторов в новом контексте сохраняется (в чем мы еще убедимся). Закрытие ненужных файлов до запуска процесса открывает перед программами возможность исполнения в "стерильных" условиях, свободных от любых неожиданностей, имея открытыми только файлы стандартного ввода-вывода и ошибок. Наконец, функция read для канала возвращает признак конца файла только в том случае, если канал не был открыт для записи ни одним из процессов. Если считывающий процесс будет держать дескриптор записи в канал открытым, он никогда не узнает, закрыл ли записывающий процесс работу на своем конце канала или нет. Вышеприведенная программа не работала бы надлежащим образом, если бы перед входом в цикл выполнения процессом-потомком не были закрыты дескрипторы записи в канал.
Карта памяти пространства процесса в ядре
Рисунок 6.7. Карта памяти пространства процесса в ядре
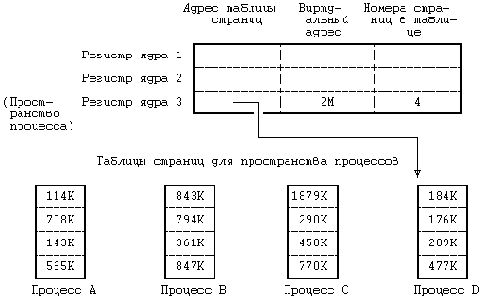
Предположим, например, что пространство процесса имеет размер 4 Кбайта и помещается по виртуальному адресу 2М. На Рисунке 6.7 показана карта памяти, где первые два регистра из группы относятся к программам и данным ядра (адреса и указатели не показаны), а третий регистр адресует к пространству процесса D. Если ядру нужно обратиться к пространству процесса A, оно копирует связанную с этим пространством информацию из соответствующей таблицы страниц в третий регистр. В любой момент третий регистр ядра описывает пространство текущего процесса, но ядро может сослаться на пространство другого процесса, переписав записи в таблице страниц с новым адресом. Информация в регистрах 1 и 2 для ядра неизменна, поскольку все процессы совместно используют программы и данные ядра.
. Каталог, создание которого не завершено
Рисунок 5.37. Каталог, создание которого не завершено
| main(argc,argv) int argc; char *argv[]; { if (argc != 2) { printf("введите: команда имя каталога\n"); exit(); } /* права доступа к каталогу: запись, чтение и ис- полнение разрешены для всех */ /* только суперпользователь может делать следую- щее */ if (mknod(argv[1],040777,0) == -1) printf("mknod завершилась неудачно\n"); } |
*14. Рассмотрим программу (Рисунок 5.37), которая создает каталог с неверным форматом (в каталоге отсутствуют записи с именами "." и ".."). Попробуйте, находясь в этом каталоге, выполнить несколько команд, таких как ls -l, ls -ld, или cd. Что произойдет при этом?
15. Напишите программу, которая выводит для файлов, имена которых указаны в качестве параметров, информацию о владельце, типе файла, правах доступа и времени доступа. Если файл (параметр) является каталогом, программа должна читать записи из каталога и выводить вышеуказанную информацию для всех файлов в каталоге.
16. Предположим, что у пользователя есть разрешение на чтение из каталога, но нет разрешения на исполнение. Что произойдет, если каталог использовать в качестве параметра команды ls, заданной с опцией "-i"? Что будет, если указана опция "-l"? Поясните свои ответы. Ответьте на вопрос, сформулированный для случая, когда есть разрешение на исполнение, но нет разрешения на чтение из каталога.
17. Сравните права доступа, которые должны быть у процесса для выполнения следующих действий, и прокомментируйте:
Для создания нового файла требуется разрешение на запись в каталог. Для "создания" существующего файла требуется разрешение на запись в файл. Для удаления связи файла с каталогом требуется разрешение на запись в каталог, а не в файл.*18. Напишите программу, которая навещает все каталоги, начиная с текущего. Как она должна управлять циклами в иерархии каталогов?
19. Выполните программу, приведенную на Рисунке 5.38, и объясните, что при этом происходит в ядре. (Намек: выполните команду pwd, когда программа закончится).
20. Напишите программу, которая заменяет корневой каталог указанным каталогом, и исследуйте дерево каталогов, доступное для этой программы.
21. Почему процесс не может отменить предыдущий вызов функции chroot? Измените конкретную реализацию процесса таким образом, чтобы он мог менять текущее значение корня на предыдущее. Какие у этой возможности преимущества и неудобства?
22. Рассмотрим простой пример канала (Рисунок 5.19), когда процесс записывает в канал строку "hello" и затем считывает ее. Что произошло бы, если бы массив для записи данных в канал имел размер 1024 байта вместо 6 (а объем считываемых за одну операцию данных оставался равным 6)? Что произойдет, если порядок вызова функций read и write в программе изменить, поменяв функции местами?
Компоненты контекста процесса
Рисунок 6.8. Компоненты контекста процесса
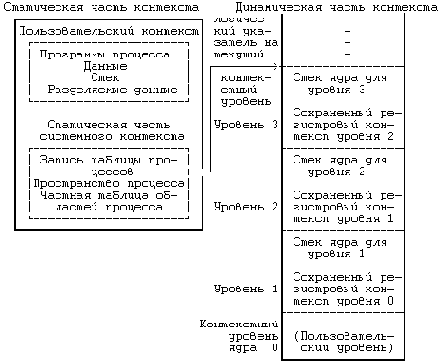
Процесс выполняется в рамках своего контекста или, если говорить более точно, в рамках своего текущего контекстного уровня. Количество контекстных уровней ограничивается числом поддерживаемых в машине уровней прерывания. Например, если в машине поддерживаются разные уровни прерываний для программ, терминалов, дисков, всех остальных периферийных устройств и таймера, то есть 5 уровней прерывания, то, следовательно, у процесса может быть не более 7 контекстных уровней: по одному на каждый уровень прерывания, 1 для системных функций и 1 для пользовательского контекста. 7 уровней будет достаточно, даже если прерывания будут поступать в "наихудшем" из возможных порядков, поскольку прерывание данного уровня блокируется (то есть его обработка откладывается центральным процессором) до тех пор, пока ядро не обработает все прерывания этого и более высоких уровней.
Несмотря на то, что ядро всегда исполняет контекст какого-нибудь процесса, логическая функция, которую ядро реализует в каждый момент, не всегда имеет отношение к данному процессу. Например, если возвращая данные, дисковое запоминающее устройство посылает прерывание, то прерывается выполнение текущего процесса и ядро обрабатывает прерывание на новом контекстном уровне этого процесса, даже если данные относятся к другому процессу. Программы обработки прерываний обычно не обращаются к статическим составляющим контекста процесса и не видоизменяют их, так как эти части не связаны с прерываниями.
. Конфигурация стека для системной функции creat
Рисунок 6.14. Конфигурация стека для системной функции creat
Несколько библиотечных функций могут отображаться на одну точку входа в список системных функций. Каждая точка входа определяет точные синтаксис и семантику обращения к системной функции, однако более удобный интерфейс обеспечивается с помощью библиотек. Существует, например, несколько конструкций системной функции exec, таких как execl и execle, выполняющих одни и те же действия с небольшими отличиями. Библиотечные функции, соответствующие этим конструкциям, при обработке параметров реализуют заявленные свойства, но в конечном итоге, отображаются на одну и ту же функцию ядра.
(**) Очередность, в которой компилятор вычисляет и помещает в стек параметры функции, зависит от реализации системы.
. Конкуренция в назначении индексов
Рисунок 4.16. Конкуренция в назначении индексов

В предыдущем параграфе описывались простые случаи работы алгоритмов. Теперь рассмотрим случай, когда ядро назначает новый индекс и затем копирует его в память. В алгоритме предполагается, что ядро может и обнаружить, что индекс уже назначен. Несмотря на редкость такой ситуации, обсудим этот случай (с помощью Рисунков 4.16 и 4.17). Пусть у нас есть три процесса, A, B и C, и пусть ядро, действуя от имени процесса A (***), назначает индекс I, но приостанавливает выполнение процесса перед тем, как скопировать дисковый индекс в память. Алгоритмы iget (вызванный алгоритмом ialloc) и bread (вызванный алгоритмом iget) дают процессу A достаточно возможностей для приостановления своей работы. Предположим, что пока процесс A приостановлен, процесс B пытается назначить новый индекс, но обнаруживает, что список свободных индексов в суперблоке пуст. Процесс B просматривает диск в поисках свободных индексов, и начинает это делать с индекса, имеющего меньший номер по сравнению с индексом, назначенным процессом A. Возможно, что процесс B обнаружит индекс I на диске свободным, так как процесс A все еще приостановлен, а ядро еще не знает, что этот индекс собираются назначить. Процесс B, не осознавая опасности, заканчивает просмотр диска, заполняет суперблок свободными (предположительно) индексами, назначает индекс и уходит со сцены. Однако, индекс I остается в списке номеров свободных индексов в суперблоке. Когда процесс A возобновляет выполнение, он заканчивает назначение индекса I. Теперь допустим, что процесс C затем затребовал индекс и случайно выбрал индекс I из списка в суперблоке. Когда он обратится к копии индекса в памяти, он обнаружит из установки типа файла, что индекс уже назначен. Ядро проверяет это условие и, обнаружив, что этот индекс назначен, пытается назначить другой. Немедленная перепись скорректированного индекса на диск после его назначения в соответствии с алгоритмом ialloc снижает опасность конкуренции, поскольку поле типа файла будет содержать пометку о том, что индекс использован.
. Конкуренция в назначении индексов (продолжение)
Рисунок 4.17. Конкуренция в назначении индексов (продолжение)

Блокировка списка индексов в суперблоке при чтении с диска устраняет другие возможности для конкуренции. Если суперблок не заблокирован, процесс может обнаружить, что он пуст, и попытаться заполнить его с диска, время от времени приостанавливая свое выполнение до завершения операции ввода-вывода. Предположим, что второй процесс так же пытается назначить новый индекс и обнаруживает, что список пуст. Он тоже попытается заполнить список с диска. В лучшем случае, оба процесса продублируют друг друга и потратят энергию центрального процессора. В худшем, участится конкуренция, подобная той, которая описана в предыдущем параграфе. Сходным образом, если процесс, освобождая индекс, не проверил наличие блокировки списка, он может затереть номера индексов уже в списке свободных индексов, пока другой процесс будет заполнять этот список информацией с диска. И опять участится конкуренция вышеописанного типа. Несмотря на то, что ядро более или менее удачно управляется с ней, производительность системы снижается. Установка блокировки для списка свободных индексов в суперблоке устраняет такую конкуренцию.
(***) Как и в предыдущей главе, здесь под "процессом" имеется ввиду "ядро, действующее от имени процесса".
. Конкуренция за данные, вводимые с терминала
Рисунок 10.16. Конкуренция за данные, вводимые с терминала
| char input[256]; main() { register int i; for (i = 0; i < 18; i++) { switch (fork()) { case -1: /* ошибка */ printf("операция fork не выполнена из-за ошибки\n"); exit(); default: /* родительский процесс */ break; case 0: /* порожденный процесс */ for (;;) { read(0,input,256); /* чтение строки */ printf("%d чтение %s\n",i,input); } } } } |
На Рисунке 10.16 приведена программа, в которой родительский процесс порождает несколько процессов, осуществляющих чтение из файла стандартного ввода, конкурируя за получение данных, вводимых с терминала. Ввод с терминала обычно осуществляется слишком медленно для того, чтобы удовлетворить все процессы, ведущие чтение, поэтому процессы большую часть времени находятся в приостановленном состоянии в соответствии с алгоритмом terminal_read, ожидая ввода данных. Когда пользователь вводит строку данных, программа обработки прерываний от терминала возобновляет выполнение всех процессов, ведущих чтение; поскольку они были приостановлены с одним и тем же уровнем приоритета, они выбираются для запуска с одинаковым уровнем приоритета. Пользователь не в состоянии предугадать, какой из процессов выполняется и считывает строку данных; успешно созданный процесс печатает значение переменной i в момент его создания. Все другие процессы в конце концов будут запущены, но вполне возможно, что они не обнаружат введенной информации в списках для хранения вводных данных и их выполнение снова будет приостановлено. Вся процедура повторяется для каждой введенной строки; нельзя дать гарантию, что ни один из процессов не захватит все введенные данные.
Одновременному чтению с терминала несколькими процессами присуща неоднозначность, но ядро справляется с ситуацией наилучшим образом. С другой стороны, ядро обязано позволять процессам одновременно считывать данные с терминала, иначе порожденные командным процессором shell процессы, читающие из стандартного ввода, никогда не будут работать, поскольку shell тоже обращается к стандартному вводу. Короче говоря, процессы должны синхронизировать свои обращения к терминалу на пользовательском уровне.
Когда пользователь вводит символ "конец файла" (Ctrl-d в ASCII), строковый интерфейс передает функции read введенную строку до символа конца файла, но не включая его. Он не передает данные (код возврата 0) функции read, если в символьном списке встретился только символ "конец файла"; вызывающий процесс сам распознает, что обнаружен конец файла и больше не следует считывать данные с терминала. Если еще раз обратиться к примерам программ по shell'у, приведенным в главе 7, можно отметить, что цикл работы shell'а завершается, когда пользователь нажимает <Ctrl-d>: функция read возвращает 0 и производится выход из shell'а.
В этом разделе рассмотрена работа терминалов ввода-вывода, которые передают данные на машину по одному символу за одну операцию, в точности как пользователь их вводит с клавиатуры. Интеллектуальные терминалы подготавливают свой вводной поток на внешнем устройстве, освобождая центральный процессор для другой работы. Структура драйверов для таких терминалов походит на структуру драйверов для терминалов ввода-вывода, несмотря на то, что функции строкового интерфейса различаются в зависимости от возможностей внешних устройств.
. Копирование содержимого области
Рисунок 6.27. Копирование содержимого области
. Логическая схема чтения и записи в канал
Рисунок 5.17. Логическая схема чтения и записи в канал

Рассмотрим первый случай, в котором процесс ведет запись в канал, имеющий место для ввода данных: сумма количества записываемых байт с числом байт, уже находящихся в канале, меньше или равна емкости канала. Ядро следует алгоритму записи данных в обычный файл, за исключением того, что оно увеличивает размер канала автоматически после каждого выполнения функции write, поскольку по определению объем данных в канале растет с каждой операцией записи. Иначе происходит увеличение размера обычного файла: процесс увеличивает размер файла только тогда, когда он при записи данных переступает границу конца файла. Если следующее смещение в канале требует использования блока косвенной адресации, ядро устанавливает значение смещения в пространстве процесса таким образом, чтобы оно указывало на начало канала (смещение в байтах, равное 0). Ядро никогда не затирает данные в канале; оно может сбросить значение смещения в 0, поскольку оно уже установило, что данные не будут переполнять емкость канала. Когда процесс запишет в канал все свои данные, ядро откорректирует значение указателя записи (в индексе) канала таким образом, что следующий процесс продолжит запись в канал с того места, где остановилась предыдущая операция write. Затем ядро возобновит выполнение всех других процессов, приостановленных в ожидании считывания данных из канала.
Когда процесс запускает функцию чтения из канала, он проверяет, пустой ли канал или нет. Если в канале есть данные, ядро считывает их из канала так, как если бы канал был обычным файлом, выполняя соответствующий алгоритм. Однако, начальным смещением будет значение указателя чтения, хранящегося в индексе и показывающего протяженность прочитанных ранее данных. После считывания каждого блока ядро уменьшает размер канала в соответствии с количеством считанных данных и устанавливает значение смещения в пространстве процесса так, чтобы при достижении конца канала оно указывало на его начало. Когда выполнение системной функции read завершается, ядро возобновляет выполнение всех приостановленных процессов записи и запоминает текущее значение указателя чтения в индексе (а не в записи таблицы файлов).
Если процесс пытается считать больше информации, чем фактически есть в канале, функция read завершится успешно, возвратив все данные, находящиеся в данный момент в канале, пусть даже не полностью выполнив запрос пользователя. Если канал пуст, процесс обычно приостанавливается до тех пор, пока какой-нибудь другой процесс не запишет данные в канал, после чего все приостановленные процессы, ожидающие ввода данных, возобновят свое выполнение и начнут конкурировать за чтение из канала. Если, однако, процесс открывает поименованный канал с параметром "no delay" (без задержки), функция read возвратит управление немедленно, если в канале отсутствуют данные. Операции чтения и записи в канал имеют ту же семантику, что и аналогичные операции для терминальных устройств (глава 10), она позволяет процессам игнорировать тип тех файлов, с которыми эти программы имеют дело.
Если процесс ведет запись в канал и в канале нет места для всех данных, ядро помечает индекс и приостанавливает выполнение процесса до тех пор, пока канал не начнет очищаться от данных. Когда впоследствии другой процесс будет считывать данные из канала, ядро заметит существование процессов, приостановленных в ожидании очистки канала, и возобновит их выполнение подобно тому, как это было объяснено выше. Исключением из этого утверждения является ситуация, когда процесс записывает в канал данные, объем которых превышает емкость канала (то есть, объем данных, которые могут храниться в блоках прямой адресации); в этом случае ядро записывает в канал столько данных, сколько он может вместить в себя, и приостанавливает процесс до тех пор, пока не освободится дополнительное место. Таким образом, возможно положение, при котором записываемые данные не будут занимать непрерывное место в канале, если другие процессы ведут запись в канал в то время, на которое первый процесс прервал свою работу.
Анализируя реализацию каналов, можно заметить, что интерфейс процессов согласуется с интерфейсом обычных файлов, но его воплощение отличается, так как ядро запоминает смещения для чтения и записи в индексе вместо того, чтобы делать это в таблице файлов. Ядро вынуждено хранить значения смещений для поименованных каналов в индексе для того, чтобы процессы могли совместно использовать эти значения: они не могли бы совместно использовать значения, хранящиеся в таблице файлов, так как процесс получает новую запись в таблице файлов по каждому вызову функции open. Тем не менее, совместное использование смещений чтения и записи в индексе наблюдалось и до реализации поименованных каналов. Процессы, обращающиеся к непоименованным каналам, разделяют доступ к каналу через общие точки входа в таблицу файлов, поэтому они могли бы по умолчанию хранить смещения записи и чтения в таблице файлов, как это принято для обычных файлов. Это не было сделано, так как процедуры низкого уровня, работающие в ядре, больше не имеют доступа к записям в таблице файлов: программа упростилась за счет того, что процессы совместно используют значения смещений, хранящиеся в индексе.
Многократная приостановка выполнения
Рисунок 2.9. Многократная приостановка выполнения процессов, вызванная блокировкой

Многопроцессорная конфигурация
Рисунок 12.1. Многопроцессорная конфигурация
. Модель с использованием гнезд
Рисунок 11.18. Модель с использованием гнезд
Структура ядра имеет три уровня: гнезд, протоколов и устройств (Рисунок 11.18). Уровень гнезд выполняет функции интерфейса между обращениями к операционной системе (системным функциям) и средствами низких уровней, уровень протоколов содержит модули, обеспечивающие взаимодействие процессов (на рисунке упомянуты протоколы TCP и IP), а уровень устройств содержит драйверы, управляющие сетевыми устройствами. Допустимые сочетания протоколов и драйверов указываются при построении системы (в секции конфигурации); этот способ уступает по гибкости вышеупомянутому потоковому механизму. Процессы взаимодействуют между собой по схеме клиент-сервер: сервер ждет сигнала от гнезда, находясь на одном конце дуплексной линии связи, а процессы-клиенты взаимодействуют с сервером через гнездо, находящееся на другом конце, который может располагаться на другой машине. Ядро обеспечивает внутреннюю связь и передает данные от клиента к серверу.
Гнезда, обладающие одинаковыми свойствами, например, опирающиеся на общие соглашения по идентификации и форматы адресов (в протоколах), группируются в домены (управляемые одним узлом). В системе BSD 4.2 поддерживаются домены: "UNIX system" - для взаимодействия процессов внутри одной машины и "Internet" (межсетевой) - для взаимодействия через сеть с помощью протокола DARPA (Управление перспективных исследований и разработок Министерства обороны США) (см. [Postel 80] и [Postel 81]). Гнезда бывают двух типов: виртуальный канал (потоковое гнездо, если пользоваться терминологией Беркли) и дейтаграмма. Виртуальный канал обеспечивает надежную доставку данных с сохранением исходной последовательности. Дейтаграммы не гарантируют надежную доставку с сохранением уникальности и последовательности, но они более экономны в смысле использования ресурсов, поскольку для них не требуются сложные установочные операции; таким образом, дейтаграммы полезны в отдельных случаях взаимодействия. Для каждой допустимой комбинации типа домен-гнездо в системе поддерживается умолчание на используемый протокол. Так, например, для домена "Internet" услуги виртуального канала выполняет протокол транспортной связи (TCP), а функции дейтаграммы - пользовательский дейтаграммный протокол (UDP).
Существует несколько системных функций работы с гнездами. Функция socket устанавливает оконечную точку линии связи.
sd = socket(format,type,protocol);Format обозначает домен ("UNIX system" или "Internet"), type - тип связи через гнездо (виртуальный канал или дейтаграмма), а protocol - тип протокола, управляющего взаимодействием. Дескриптор гнезда sd, возвращаемый функцией socket, используется другими системными функциями. Закрытие гнезд выполняет функция close.
Функция bind связывает дескриптор гнезда с именем:
bind(sd,address,length);где sd - дескриптор гнезда, address - адрес структуры, определяющей идентификатор, характерный для данной комбинации домена и протокола (в функции socket). Length - длина структуры address; без этого параметра ядро не знало бы, какова длина структуры, поскольку для разных доменов и протоколов она может быть различной. Например, для домена "UNIX system" структура содержит имя файла. Процессы-серверы связывают гнезда с именами и объявляют о состоявшемся присвоении имен процессам-клиентам.
С помощью системной функции connect делается запрос на подключение к существующему гнезду:
connect(sd,address,length);Семантический смысл параметров функции остается прежним (см. функцию bind), но address указывает уже на выходное гнездо, образующее противоположный конец линии связи. Оба гнезда должны использовать одни и те же домен и протокол связи, и тогда ядро удостоверит правильность установки линии связи. Если тип гнезда - дейтаграмма, сообщаемый функцией connect ядру адрес будет использоваться в последующих обращениях к функции send через данное гнездо; в момент вызова никаких соединений не производится.
Пока процесс-сервер готовится к приему связи по виртуальному каналу, ядру следует выстроить поступающие запросы в очередь на обслуживание. Максимальная длина очереди задается с помощью системной функции listen:
listen(sd,qlength)где sd - дескриптор гнезда, а qlength - максимально-допустимое число запросов, ожидающих обработки.
. Модификация алгоритма получения доступа к индексу
Рисунок 5.25. Модификация алгоритма получения доступа к индексу
| алгоритм iget входная информация: номер индекса в файловой системе выходная информация: заблокированный индекс { выполнить { если (индекс в индексном кеше) { если (индекс заблокирован) { приостановиться (до освобождения индекса); продолжить; /* цикл с условием продолжения */ } /* специальная обработка для точек монтирования */ если (индекс является индексом точки монтирования) { найти запись в таблице монтирования для точки мон- тирования; получить новый номер файловой системы из таблицы монтирования; использовать номер индекса корня для просмотра; продолжить; /* продолжение цикла */ } если (индекс в списке свободных индексов) убрать из списка свободных индексов; увеличить счетчик ссылок для индекса; | возвратить (индекс); } /* индекс отсутствует в индексном кеше */ убрать новый индекс из списка свободных индексов; сбросить номер индекса и файловой системы; убрать индекс из старой хеш-очереди, поместить в новую; считать индекс с диска (алгоритм bread); инициализировать индекс (например, установив счетчик ссылок в 1); возвратить (индекс); } } |
Для второго случая пересечения точки монтирования в направлении из файловой системы, которая монтируется, в файловую систему, где выполняется монтирование, рассмотрим модификацию алгоритма namei (Рисунок 5.26). Она похожа на версию алгоритма, приведенную на Рисунке 4.11. Однако, после обнаружения в каталоге номера индекса для данной компоненты пути поиска ядро проверяет, не указывает ли номер индекса на то, что это корневой индекс файловой системы. Если это так и если текущий рабочий индекс так же является корневым, а компонента пути поиска, в свою очередь, имеет имя "..", ядро идентифицирует индекс как точку монтирования. Оно находит в таблице монтирования запись, номер устройства в которой совпадает с номером устройства для последнего из найденных индексов, получает индекс для каталога, в котором производится монтирование, и продолжает поиск компоненты с именем "..", используя только что полученный индекс в качестве рабочего. В корне файловой системы, тем не менее, корневым каталогом является ".."
. Модификация алгоритма синтаксического анализа имени файла
Рисунок 5.26. Модификация алгоритма синтаксического анализа имени файла
| алгоритм namei /* превращение имени пути поиска в индекс */ входная информация: имя пути поиска выходная информация: заблокированный индекс { если (путь поиска берет начало с корня) рабочий индекс = индексу корня (алгоритм iget); в противном случае рабочий индекс = индексу текущего каталога (алгоритм iget); выполнить (пока путь поиска не кончился) { считать следующую компоненту имени пути поиска; проверить соответствие рабочего индекса каталогу и права доступа; если (рабочий индекс соответствует корню и компо- нента имени "..") продолжить; /* цикл с условием продолжения */ поиск компоненты: считать каталог (рабочий индекс), повторяя алго- ритмы bmap, bread и brelse; если (компонента соответствует записи в каталоге (рабочем индексе)) { получить номер индекса для совпавшей компонен- ты; если (найденный индекс является индексом кор- ня и рабочий индекс является индексом корня и имя компоненты "..") | { /* пересечение точки монтирования */ получить запись в таблице монтирования для рабочего индекса; освободить рабочий индекс (алгоритм iput); рабочий индекс = индексу точки монтирования; заблокировать индекс точки монтирования; увеличить значение счетчика ссылок на рабо- чий индекс; перейти к поиску компоненты (для ".."); } освободить рабочий индекс (алгоритм iput); рабочий индекс = индексу с новым номером (алгоритм iget); } в противном случае /* компонента отсутствует в каталоге */ возвратить (нет индекса); } возвратить (рабочий индекс); } |
В вышеприведенном примере (cd "../../..") предполагается, что в начале процесс имеет текущий каталог с именем "/usr/src/uts". Когда имя пути поиска подвергается анализу в алгоритме namei, начальным рабочим индексом является индекс текущего каталога. Ядро меняет текущий рабочий индекс на индекс каталога с именем "/usr/src" в результате расшифровки первой компоненты ".." в имени пути поиска. Затем ядро анализирует вторую компоненту ".." в имени пути поиска, находит корневой индекс смонтированной (перед этим) файловой системы - индекс каталога "usr" - и делает его рабочим индексом при анализе имени с помощью алгоритма namei. Наконец, оно расшифровывает третью компоненту ".." в имени пути поиска. Ядро обнаруживает, что номер индекса для ".." совпадает с номером корневого индекса, рабочим индексом является корневой индекс, а ".." является текущей компонентой имени пути поиска. Ядро находит запись в таблице монтирования, соответствующую точке монтирования "usr", освобождает текущий рабочий индекс (корень файловой системы, смонтированной в каталоге "usr") и назначает индекс точки монтирования (каталога "usr" в корневой файловой системе) в качестве нового рабочего индекса. Затем оно просматривает записи в каталоге точки монтирования "/usr" в поисках имени ".." и находит номер индекса для корня файловой системы ("/"). После этого системная функция chdir завершается как обычно, вызывающий процесс не обращает внимания на тот факт, что он пересек точку монтирования.
Объем файла в байтах при размере блока 1 Кбайт
Рисунок 4.7. Объем файла в байтах при размере блока 1 Кбайт
| 10 блоков прямой адресации по 1 Кбайту каждый = 10 Кбайт 1 блок косвенной адресации с 256 блоками прямой адресации = 256 Кбайт 1 блок двойной косвенной адресации с 256 блоками косвенной адресации = 64 Мбайта 1 блок тройной косвенной адресации с 256 блоками двойной косвенной адресации = 16 Гбайт |
. Образ исполняемого файла
Рисунок 7.20. Образ исполняемого файла
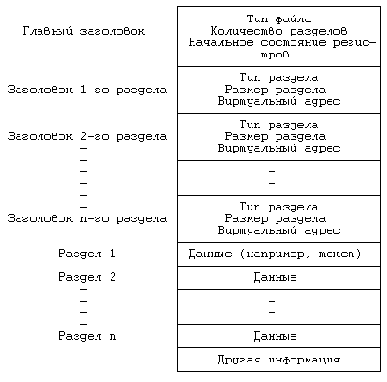
Указанные составляющие с развитием самой системы видоизменяются, однако во всех исполняемых файлах обязательно присутствует главный заголовок с полем типа файла.
Тип файла обозначается коротким целым числом (представляется в машине полусловом), которое идентифицирует файл как загрузочный модуль, давая тем самым ядру возможность отслеживать динамические характеристики его выполнения. Например, в машине PDP 11/70 определение типа файла как загрузочного модуля свидетельствует о том, что процесс, исполняющий файл, может использовать до 128 Кбайт памяти вместо 64 Кбайт (**), тем не менее в системах с замещением страниц тип файла все еще играет существенную роль, в чем нам предстоит убедиться во время знакомства с главой 9.
Вернемся к алгоритму. Мы остановились на том, что ядро обратилось к индексу файла и установило, что файл является исполнимым. Ядру следовало бы освободить память, занимаемую пользовательским контекстом процесса. Однако, поскольку в памяти, подлежащей освобождению, располагаются передаваемые новой программе параметры, ядро первым делом копирует их из адресного пространства в промежуточный буфер на время, пока не будут отведены области для нового пространства памяти.
Поскольку параметрами функции exec выступают пользовательские адреса массивов символьных строк, ядро по каждой строке сначала копирует в системную память адрес строки, а затем саму строку. Для хранения строки в разных версиях системы могут быть выбраны различные места. Чаще принято хранить строки в стеке ядра (локальная структура данных, принадлежащая программе ядра), на нераспределяемых участках памяти (таких как страницы), которые можно занимать только временно, а также во внешней памяти (на устройстве выгрузки).
С точки зрения реализации проще всего для копирования параметров в новый пользовательский контекст обратиться к стеку ядра. Однако, поскольку размер стека ядра, как правило, ограничивается системой, а также поскольку параметры функции exec могут иметь произвольную длину, этот подход следует сочетать с другими подходами. При рассмотрении других вариантов обычно останавливаются на способе хранения, обеспечивающем наиболее быстрый доступ к строкам. Если доступ к страницам памяти в системе реализуется довольно просто, строки следует размещать на страницах, поскольку обращение к оперативной памяти осуществляется быстрее, чем к внешней (устройству выгрузки).
После копирования параметров функции exec в системную память ядро отсоединяет области, ранее присоединенные к процессу, используя алгоритм detachreg. Несколько позже мы еще поговорим о специальных действиях, выполняемых в отношении областей команд. К рассматриваемому моменту процесс уже лишен пользовательского контекста и поэтому возникновение в дальнейшем любой ошибки неизбежно будет приводить к завершению процесса по сигналу. Такими ошибками могут быть обращение к пространству, не описанному в таблице областей ядра, попытка загрузить программу, имеющую недопустимо большой размер или использующую области с пересекающимися адресами, и др. Ядро выделяет и присоединяет к процессу области команд и данных, загружает в оперативную память содержимое исполняемого файла (алгоритмы allocreg, attachreg и loadreg, соответственно). Область данных процесса изначально поделена на две части: данные, инициализация которых была выполнена во время компиляции, и данные, не определенные компилятором ("bss"). Область памяти первоначально выделяется для проинициализированных данных. Затем ядро увеличивает размер области данных для размещения данных типа "bss" (алгоритм growreg) и обнуляет их значения. Напоследок ядро выделяет и присоединяет к процессу область стека и отводит пространство памяти для хранения параметров функции exec. Если параметры функции размещаются на страницах, те же страницы могут быть использованы под стек. В противном случае параметры функции размещаются в стеке задачи.
В пространстве процесса ядро стирает адреса пользовательских функций обработки сигналов, поскольку в новом пользовательском контексте они теряют свое значение. Однако и в новом контексте рекомендации по игнорированию тех или иных сигналов остаются в силе. Ядро устанавливает в регистрах для режима задачи значения из сохраненного регистрового контекста, в частности первоначальное значение указателя вершины стека (sp) и счетчика команд (pc): первоначальное значение счетчика команд было занесено загрузчиком в заголовок файла. Для setuid-программ и для трассировки процесса ядро предпринимает особые действия, на которых мы еще остановимся во время рассмотрения глав 8 и 11, соответственно. Наконец, ядро запускает алгоритм iput, освобождая индекс, выделенный по алгоритму namei в самом начале выполнения функции exec. Алгоритмы namei и iput в функции exec выполняют роль, подобную той, которую они выполняют при открытии и закрытии файла; состояние файла во время выполнения функции exec похоже на состояние открытого файла, если не принимать во внимание отсутствие записи о файле в таблице файлов. По выходе из функции процесс исполняет текст новой программы. Тем не менее, процесс остается тем же, что и до выполнения функции; его идентификатор не изменился, как не изменилось и его место в иерархии процессов. Изменению подвергся только пользовательский контекст процесса.
Обслуживающий процесс (сервер)
Рисунок 11.8. Обслуживающий процесс (сервер)
| #include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> #define MSGKEY 75 struct msgform { long mtype; char mtext[256]; }msg; int msgid; main() { int i,pid,*pint; extern cleanup(); for (i = 0; i < 20; i++) signal(i,cleanup); msgid = msgget(MSGKEY,0777IPC_CREAT); for (;;) { msgrcv(msgid,&msg,256,1,0); pint = (int *) msg.mtext; pid = *pint; printf("сервер: получил от процесса с pid %d\n", pid); msg.mtype = pid; *pint = getpid(); msgsnd(msgid,&msg,sizeof(int),0); } } cleanup() { msgctl(msgid,IPC_RMID,0); exit(); } |
Сообщения имеют форму "тип - текст", где текст представляет собой поток байтов. Указание типа дает процессам возможность выбирать сообщения только определенного рода, что в файловой системе не так легко сделать. Таким образом, процессы могут выбирать из очереди сообщения определенного типа в порядке их поступления, причем эта очередность гарантируется ядром. Несмотря на то, что обмен сообщениями может быть реализован на пользовательском уровне средствами файловой системы, представленный вашему вниманию механизм обеспечивает более эффективную организацию передачи данных между процессами.
С помощью системной функции msgctl процесс может запросить информацию о статусе дескриптора сообщения, установить этот статус или удалить дескриптор сообщения из системы. Синтаксис вызова функции:
msgctl(id,cmd,mstatbuf)где id - дескриптор сообщения, cmd - тип команды, mstatbuf - адрес пользовательской структуры, в которой будут храниться управляющие параметры или результаты обработки запроса. Более подробно об аргументах функции пойдет речь в Приложении.
Вернемся к примеру, представленному на Рисунке 11.8. Обслуживающий процесс принимает сигналы и с помощью функции cleanup удаляет очередь сообщений из системы. Если же им не было поймано ни одного сигнала или был получен сигнал SIGKILL, очередь сообщений остается в системе, даже если на нее не ссылается ни один из процессов. Дальнейшие попытки исключительно создания новой очереди сообщений с данным ключом (идентификатором) не будут иметь успех до тех пор, пока старая очередь не будет удалена из системы.
. Операции установки и снятия блокировки
Рисунок 11.14. Операции установки и снятия блокировки
| #include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h> #define SEMKEY 75 int semid; unsigned int count; /* определение структуры sembuf в файле sys/sem.h * struct sembuf { * unsigned shortsem_num; * short sem_op; * short sem_flg; }; */ struct sembuf psembuf,vsembuf; /* операции типа P и V */ main(argc,argv) int argc; char *argv[]; { int i,first,second; short initarray[2],outarray[2]; extern cleanup(); if (argc == 1) { for (i = 0; i < 20; i++) signal(i,cleanup); semid = semget(SEMKEY,2,0777IPC_CREAT); initarray[0] = initarray[1] = 1; semctl(semid,2,SETALL,initarray); semctl(semid,2,GETALL,outarray); printf("начальные значения семафоров %d %d\n", outarray[0],outarray[1]); pause(); /* приостанов до получения сигнала */ } /* продолжение на следующей странице */ |
. Опрос терминала
Рисунок 10.18. Опрос терминала
| #include <fcntl.h> main() { register int i,n; int fd; char buf[256]; /* открытие терминала только для чтения с опцией "no delay" */ if((fd = open("/dev/tty",O_RDONLYO_NDELAY)) == -1) exit(); n = 1; for(;;) /* всегда */ { for(i = 0; i < n; i++) ; if(read(fd,buf,sizeof(buf)) > 0) { printf("чтение с номера %d\n",n); n--; } else /* ничего не прочитано; возврат вследствие "no delay" */ n++; } } |
. Основной цикл программы shell
Рисунок 7.28. Основной цикл программы shell
| /* чтение командной строки до символа конца файла */ while (read(stdin,buffer,numchars)) { /* синтаксический разбор командной строки */ if (/* командная строка содержит & */) amper = 1; else amper = 0; /* для команд, не являющихся конструкциями командного языка shell */ if (fork() == 0) { /* переадресация ввода-вывода? */ if (/* переадресация вывода */) { fd = creat(newfile,fmask); close(stdout); dup(fd); close(fd); /* stdout теперь переадресован */ } if (/* используются каналы */) { pipe(fildes); |
. Основной цикл программы shell (продолжение)
Рисунок 7.28. Основной цикл программы shell (продолжение)
| if (fork() == 0) { /* первая компонента командной строки */ close(stdout); dup(fildes[1]); close(fildes[1]); close(fildes[0]); /* стандартный вывод направляется в ка- нал */ /* команду исполняет порожденный про- цесс */ execlp(command1,command1,0); } /* вторая компонента командной строки */ close(stdin); dup(fildes[0]); close(fildes[0]); close(fildes[1]); /* стандартный ввод будет производиться из канала */ } execve(command2,command2,0); } /* с этого места продолжается выполнение родительского * процесса... * процесс-родитель ждет завершения выполнения потомка, * если это вытекает из введенной строки * / if (amper == 0) retid = wait(&status); } |
Если процесс запускается асинхронно (на фоне основной программы), как в следующем примере
nroff -mm bigdocument &shell анализирует наличие символа амперсанд (&) и заносит результат проверки во внутреннюю переменную amper. В конце основного цикла shell обращается к этой переменной и, если обнаруживает в ней признак наличия символа, не выполняет функцию wait, а тут же повторяет цикл считывания следующей команды.
Из рисунка видно, что процесс-потомок по завершении функции fork получает доступ к командной строке, принятой shell'ом. Для того, чтобы переадресовать стандартный вывод в файл, как в следующем примере
nroff -mm bigdocument > outputпроцесс-потомок создает файл вывода с указанным в командной строке именем; если файл не удается создать (например, не разрешен доступ к каталогу), процесс-потомок тут же завершается. В противном случае процесс-потомок закрывает старый файл стандартного вывода и переназначает с помощью функции dup дескриптор этого файла новому файлу. Старый дескриптор созданного файла закрывается и сохраняется для запускаемой программы. Подобным же образом shell переназначает и стандартный ввод и стандартный вывод ошибок.
Освобождение индекса
Рисунок 4.4. Освобождение индекса
| алгоритм iput /* разрешение доступа к индексу в памяти */ входная информация: указатель на индекс в памяти выходная информация: отсутствует { заблокировать индекс если он еще не заблокирован; уменьшить на 1 счетчик ссылок для индекса; если (значение счетчика ссылок == 0) { если (значение счетчика связей == 0) { освободить дисковые блоки для файла (алгоритм free, раздел 4.7); установить тип файла равным 0; освободить индекс (алгоритм ifree, раздел 4.6); } если (к файлу обращались или изменился индекс или изменилось содержимое файла) скорректировать дисковый индекс; поместить индекс в список свободных индексов; } снять блокировку с индекса; } |
Освобождение пространства на устройстве выгрузки
Рисунок 9.4. Освобождение пространства на устройстве выгрузки

. Отказ системы защиты из-за установки
Рисунок 9.27. Взаимодействие отказа системы защиты и отказа из-за недоступности данных
. Отображение файла на область
Рисунок 9.17. Отображение файла на область
Отображение логических номеров страниц на физические
Рисунок 6.4. Отображение логических номеров страниц на физические
| 0 | 177 |
| 1 | 54 |
| 2 | 209 |
| 3 | 17 |
Ядро устанавливает соотношение между виртуальными адресами области и машинными физическими адресами посредством отображения логических номеров страниц в области на физические номера страниц в машине, как это показано на Рисунке 6.4. Поскольку область это непрерывное пространство виртуальных адресов программы, логический номер страницы служит указателем на элемент массива физических номеров страниц. Запись таблицы областей содержит указатель на таблицу физических номеров страниц, именуемую таблицей страниц. Записи таблицы страниц содержат машинно-зависимую информацию, такую как права доступа на чтение или запись страницы. Ядро поддерживает таблицы страниц в памяти и обращается к ним так же, как и ко всем остальным структурам данных ядра.
На Рисунке 6.5 приведен пример отображения процесса в физические адреса памяти. Пусть размер страницы составляет 1 Кбайт и пусть процессу нужно обратиться к объекту в памяти, имеющему виртуальный адрес 68432. Из таблицы областей видно, что виртуальный адрес начала области стека - 65536 (64К), если предположить, что стек растет в направлении увеличения адресов. После вычитания этого адреса из адреса 68432 получаем смещение в байтах внутри области, равное 2896. Так как каждая страница имеет размер 1 Кбайт, адрес указывает со смещением 848 на 2-ю (начиная с 0) страницу области, расположенной по физическому адресу 986К. В разделе 6.5.5 (где идет речь о загрузке области) рассматривается случай, когда запись таблицы страниц помечается "пустой".
В современных машинах используются разнообразные аппаратные регистры и кеши, которые повышают скорость выполнения вышеописанной процедуры трансляции адресов и без которых пересылки в памяти и адресные вычисления чересчур бы замедлились. Возобновляя выполнение процесса, ядро посредством загрузки соответствующих регистров сообщает техническим средствам управления памятью о том, в каких физических адресах выполняется процесс и где располагаются таблицы страниц. Поскольку такие операции являются машинно-зависимыми и в разных версиях реализуются по-разному, здесь мы их рассматривать не будем. Часть вопросов, связанных с архитектурой вычислительных систем, затрагивается в упражнениях.
Отображение пространства процесса на устройство выгрузки
Рисунок 9.6. Отображение пространства процесса на устройство выгрузки
Отображение в памяти ввода-вывода
Рисунок 10.5. Отображение в памяти ввода-вывода с использованием контроллера VAX DZ11
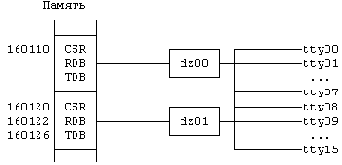
Конкретный метод взаимодействия драйвера с устройством определяется особенностями аппаратуры. Некоторые из машин обеспечивают отображение ввода-вывода в памяти, подразумевающее, что конкретные адреса в адресном пространстве ядра являются не номерами ячеек в физической памяти, а специальными регистрами, контролирующими соответствующие устройства. Записывая в указанные регистры управляющие параметры в соответствии со спецификациями аппаратных средств, драйвер осуществляет управление устройством. Например, контроллер ввода-вывода для машины VAX-11 содержит специальные регистры для записи информации о состоянии устройства (регистры контроля и состояния) и для передачи данных (буферные регистры), которые формируются по специальным адресам в физической памяти. В частности, терминальный контроллер VAX DZ11 управляет 8 асинхронными линиями терминальной связи (см. [Levy 80], где более подробно объясняется архитектура машин VAX). Пусть регистр контроля и состояния (CSR) для конкретного терминала DZ11 имеет адрес 160120, передающий буферный регистр (TDB) - адрес 120126, а принимающий буферный регистр (RDB) - адрес 160122 (Рисунок 10.5). Для того, чтобы передать символ на терминал "/dev/tty09", драйвер терминала записывает единицу (1 = 9 по модулю 8) в указанный двоичный разряд регистра контроля и состояния и затем записывает символ в передающий буферный регистр. Запись в передающий буферный регистр является передачей данных. Контроллер DZ11 выставляет бит "выполнено" в регистре контроля и состояния, когда готов принять следующую порцию данных. Дополнительно драйвер может выставить бит "возможно прерывание передачи" в регистре контроля и состояния, что заставляет контроллер DZ11 прерывать работу системы, когда он готов принять следующую порцию данных. Чтение данных из DZ11 производится аналогично.
На других машинах имеется программируемый ввод-вывод, подразумевающий, что в машине имеются инструкции по управлению устройствами. Драйверы управляют устройствами, выполняя соответствующие инструкции. Например, в машине IBM 370 имеется инструкция "Start I/O" (Начать ввод-вывод), которая инициирует операцию ввода-вывода, связанную с устройством. Способ связи драйвера с периферийными устройствами незаметен для пользователя.
Поскольку интерфейс между драйверами устройств и соответствующими аппаратными средствами является машинно-зависимым, на этом уровне не существует стандартных интерфейсов. Как в случае вводавывода с отображением в памяти, так и в случае программируемого ввода-вывода драйвер может посылать на устройство управляющие последовательности с целью установления режима прямого доступа в память (ПДП) для устройства. Система позволяет осуществлять массовую передачу данных между устройством и памятью в режиме ПДП параллельно с работой центрального процессора, при этом устройство прерывает работу системы по завершении передачи данных. Драйвер организует управление виртуальной памятью таким образом, чтобы ячейки памяти с их действительными номерами использовались для ПДП.
Быстродействующие устройства могут иногда передавать данные непосредственно в адресное пространство задачи, без вмешательства буфера ядра. В результате повышается скорость передачи данных, поскольку при этом производится на одну операцию копирования меньше, и, кроме того, объем данных, передаваемых за одну операцию, не ограничивается размером буферов ядра. Драйверы, осуществляющие такую передачу данных без "обработки", обычно используют блочный интерфейс для процедур посимвольного чтения и записи, если у них имеется двойник блочного типа.
10.1.2.4 Стратегический интерфейс
Ядро использует стратегический интерфейс для передачи данных между буферным кешем и устройством, хотя, как уже говорилось ранее, процедуры чтения и записи для устройств посимвольного вводавывода иногда пользуются процедурой strategy (их двойника блочного типа) для непосредственной передачи данных между устройством и адресным пространством задачи. Процедура strategy может управлять очередностью выполнения заданий на ввод-вывод, связанный с устройством, или выполнять более сложные действия по планированию выполнения подобных заданий. Драйверы в состоянии привязывать передачу данных к одному физическому адресу или ко многим. Ядро передает адрес заголовка буфера стратегической процедуре драйвера; в заголовке содержится список адресов (страниц памяти) и размеры данных, передаваемых на или с устройства. Аналогичное действие имеет место при работе механизма свопинга, описанного в главе 9. При работе с буферным кешем ядро передает данные с одного адреса; во время свопинга ядро передает данные, расположенные по нескольким адресам (страницы памяти). Если данные копируются из или в адресное пространство задачи, драйвер должен блокировать процесс (или по крайней мере, соответствующие страницы) в памяти до завершения передачи данных.
Например, после монтирования файловой системы ядро идентифицирует каждый файл в файловой системе по номеру устройства и номеру индекса. В номере устройства закодированы его старший и младший номера. Когда ядро обращается к блоку, который принадлежит файлу, оно копирует номер устройства и номер блока в заголовок буфера, как уже говорилось ранее в главе 3. Обращения к диску, использующие алгоритмы работы с буферным кешем (например, bread или bwrite), инициируют выполнение стратегической процедуры, определяемой старшим номером устройства. Стратегическая процедура использует значения полей младшего номера и номера блока из заголовка буфера для идентификации места расположения данных на устройстве, а адрес буфера - для идентификации места назначения передаваемых данных. Точно так же, когда процесс обращается к устройству ввода-вывода блоками непосредственно (например, открывая устройство и читая или записывая на него), он использует алгоритмы работы с буферным кешем, и интерфейс при этом функционирует вышеописанным образом.
10.1.2.5 Ioctl
Системная функция ioctl является обобщением специфичных для терминала функций stty (задать установки терминала) и gtty (получить установки терминала), имевшихся в ранних версиях системы UNIX. Она выступает в качестве общей точки входа для всех связанных с типом устройства команд и позволяет процессам задавать аппаратные параметры, ассоциированные с устройством, и программные параметры, ассоциированные с драйвером. Специальные действия, выполняемые функцией ioctl для разных устройств различны и определяются типом драйвера. Программы, использующие вызов ioctl, должны должны знать, с файлом какого типа они работают, так как они являются аппаратно-зависимыми. Исключение из общего правила сделано для системы, которая не видит различий между файлами разных типов. Более подробно использование функции ioctl для терминалов рассмотрено в разделе 10.3.3.
Синтаксис командной строки, содержащей вызов системной функции:
ioctl(fd,command,arg);где fd - дескриптор файла, возвращаемый предварительно вызванной функцией open, command - действие (команда), которое необходимо выполнить драйверу, arg - параметр команды (может быть указателем на структуру). Команды специфичны для различных драйверов; следовательно, каждый драйвер интерпретирует команды в соответствии со своими внутренними спецификациями, от команды, в свою очередь, зависит формат структуры данных, описываемой передаваемым параметром. Драйверы могут считывать структуру данных arg из пространства задачи в соответствии с предопределенным форматом или записывать установки устройства в пространство задачи по адресу указанной структуры. Например, наличие интерфейса, предоставляемого функцией ioctl, дает возможность пользователям устанавливать для терминала скорость передачи информации в бодах, перематывать магнитную ленту, и, наконец, выполнять сетевые операции, задавая номера виртуальных каналов и сетевые адреса.
10.1.2.6 Другие функции, имеющие отношение к файловой системе
Такие функции работы с файловой системой, как stat и chmod, выполняются одинаково, как для обычных файлов, так и для устройств; они манипулируют с индексом, не обращаясь к драйверу. Даже системная функция lseek работает для устройств. Например, если процесс подводит головку на лентопротяжном устройстве к указанному адресу смещения в байтах с помощью функции lseek, ядро корректирует смещение в таблице файлов но не выполняет никаких действий, специфичных для данного типа драйвера. Когда позднее процесс выполняет чтение (read) или запись (write), ядро пересылает адрес смещения из таблицы файлов в адресное пространство задачи, подобно тому, как это имеет место при работе с файлами обычного типа, и устройство физически перемещает головку к соответствующему смещению, указанному в пространстве задачи. Этот случай иллюстрируется на примере в разделе 10.3.
. Отображение виртуальных окон
Рисунок 10.23. Отображение виртуальных окон на экране физического терминала
На Рисунке 10.23 показана схема расположения процессов и модулей ядра. Пользователь вызывает процесс mpx, контролирующий работу физического терминала. Mpx читает данные из линии физического терминала и ждет объявления об управляющих событиях, таких как создание нового окна, переключение управления на другое окно, удаление окна и т.п.
Когда mpx получает уведомление о том, что пользователю нужно создать новое окно, он создает процесс, управляющий новым окном, и поддерживает связь с ним через псевдотерминал. Псевдотерминал - это программное устройство, работающее по принципу пары: выходные данные, направляемые к одной составляющей пары, посылаются на вход другой составляющей; входные данные посылаются тому модулю потока, который расположен выше по течению. Для того, чтобы открыть окно (Рисунок 10.24), mpx назначает псевдотерминальную пару и открывает одну из составляющих пары, направляя поток к ней (открытие драйвера служит гарантией того, что псевдотерминальная пара не была выбрана раньше). Mpx ветвится и новый процесс открывает другую составляющую псевдотерминальной пары. Mpx выдвигает модуль управления сообщениями в псевдотерминальный поток, чтобы преобразовывать управляющие сообщения в информационные (об этом в следующем параграфе), а порожденный процесс помещает в псевдотерминальный поток модуль строкового интерфейса перед запуском shell'а. Этот shell теперь выполняется на виртуальном терминале; для пользователя виртуальный терминал неотличим от физического.
Параметры ввода-вывода, хранящиеся в пространстве процесса
Рисунок 5.6. Параметры ввода-вывода, хранящиеся в пространстве процесса
| mode чтение или запись count количество байт для чтения или записи offset смещение в байтах внутри файла address адрес места, куда будут копироваться данные, в памяти пользователя или ядра flag отношение адреса к памяти пользователя или к памяти ядра |
Затем в алгоритме начинается цикл, выполняющийся до тех пор, пока операция чтения не будет произведена до конца. Ядро преобразует смещение в байтах внутри файла в номер блока, используя алгоритм bmap, и вычисляет смещение внутри блока до места, откуда следует начать ввод-вывод, а также количество байт, которые будут прочитаны из блока. После считывания блока в буфер, возможно, с продвижением (алгоритмы bread и breada) ядро копирует данные из блока по назначенному адресу в пользовательском процессе. Оно корректирует параметры ввода-вывода в адресном пространстве процесса в соответствии с количеством прочитанных байт, увеличивая значение смещения в байтах внутри файла и адрес места в пользовательском процессе, куда будет доставлена следующая порция данных, и уменьшая число байт, которые необходимо прочитать, чтобы выполнить запрос пользователя. Если запрос пользователя не удовлетворен, ядро повторяет весь цикл, преобразуя смещение в байтах внутри файла в номер блока, считывая блок с диска в системный буфер, копируя данные из буфера в пользовательский процесс, освобождая буфер и корректируя значения параметров ввода-вывода в адресном пространстве процесса. Цикл завершается, либо когда ядро выполнит запрос пользователя полностью, либо когда в файле больше не будет данных, либо если ядро обнаружит ошибку при чтении данных с диска или при копировании данных в пространство пользователя. Ядро корректирует значение смещения в таблице файлов в соответствии с количеством фактически прочитанных байт; поэтому успешное выполнение операций чтения выглядит как последовательное считывание данных из файла. Системная операция lseek (раздел 5.6) устанавливает значение смещения в таблице файлов и изменяет порядок, в котором процесс читает или записывает данные в файле.
. Передача данных через стандартный вывод
Рисунок 10.14. Передача данных через стандартный вывод
| char form[]="это пример вывода строки из порожденного процесса" main() { char output[128]; int i; for (i = 0; i < 18; i++) { switch (fork()) { case -1: /* ошибка --- превышено максимальное чис- ло процессов */ exit(); default: /* родительский процесс */ break; case 0: /* порожденный процесс */ /* формат вывода строки в переменной output */ sprintf(output,"%%d\n%s%d\n",form,i,form,i); for (;;) write(1,output,sizeof(output)); } } } |
Рассмотрим программу, приведенную на Рисунке 10.14. Родительский процесс создает до 18 порожденных процессов; каждый из порожденных процессов записывает строку (с помощью библиотечной функции sprintf) в массив output, который включает сообщение и значение счетчика i в момент выполнения функции fork, и затем входит в цикл пошаговой переписи строки в файл стандартного вывода. Если стандартным выводом является терминал, терминальный драйвер регулирует поток поступающих данных. Выводимая строка имеет более 64 символов в длину, то есть слишком велика для того, чтобы поместиться в символьном блоке (длиной 64 байта) в версии V системы. Следовательно, терминальному драйверу требуется более одного символьного блока для каждого вызова функции write, иначе выводной поток может стать искаженным. Например, следующие строки были частью выводного потока, полученного в результате выполнения программы на машине AT&T 3B20:
this is a sample output string from child 1 this is a sample outthis is a sample output string from child 0Чтение данных с терминала в каноническом режиме более сложная операция. В вызове системной функции read указывается количество байт, которые процесс хочет считать, но строковый интерфейс выполняет чтение по получении символа перевода каретки, даже если количество символов не указано. Это удобно с практической точки зрения, так как процесс не в состоянии предугадать, сколько символов пользователь введет с клавиатуры, и, с другой стороны, не имеет смысла ждать, когда пользователь введет большое число символов. Например, пользователи вводят командные строки для командного процессора shell и ожидают ответа shell'а на команду по получении символа возврата каретки. При этом нет никакой разницы, являются ли введенные строки простыми командами, такими как "date" или "who", или же это более сложные последовательности команд, подобные следующей:
pic file* | tbl | eqn | troff -mm -Taps | apsendТерминальный драйвер и строковый интерфейс ничего не знают о синтаксисе командного процессора shell, и это правильно, поскольку другие программы, которые считывают информацию с терминалов (например, редакторы), имеют различный синтаксис команд. Поэтому строковый интерфейс выполняет чтение по получении символа возврата каретки.
На Рисунке 10.15 показан алгоритм чтения с терминала. Предположим, что терминал работает в каноническом режиме; в разделе 10.3.3 будет рассмотрена работа в режиме без обработки. Если в настоящий момент в любом из символьных списков для хранения вводной информации отсутствуют данные, процесс, выполняющий чтение, приостанавливается до поступления первой строки данных. Когда данные поступают, программа обработки прерывания от терминала запускает "программу обработки прерывания" строкового интерфейса, которая помещает данные в список для хранения неструктурированных вводных данных для передачи процессам, осуществляющим чтение, и в список для хранения выводных данных, передаваемых в качестве эхосопровождения на терминал. Если введенная строка содержит символ возврата каретки, программа обработки прерывания возобновляет выполнение всех приостановленных процессов чтения. Когда процесс, осуществляющий чтение, выполняется, драйвер выбирает символы из списка для хранения неструктурированных вводных данных, обрабатывает символы стирания и удаления и помещает символы в канонический символьный список. Затем он копирует строку символов в адресное пространство задачи до символа возврата каретки или до исчерпания числа символов, указанного в вызове системной функции read, что встретится раньше. Однако, процесс может обнаружить, что данных, ради которых он возобновил свое выполнение, больше не существует: другие процессы считали данные с терминала и удалили их из списка для неструктурированных вводных данных до того, как первый процесс был запущен вновь. Такая ситуация похожа на ту, которая имеет место, когда из канала считывают данные несколько процессов.
Переход процесса из одной очереди в другую
Рисунок 8.3. Переход процесса из одной очереди в другую
Переключение режима работы с непривилегированного
Рисунок 6.6. Переключение режима работы с непривилегированного (режима задачи) на привилегированный (режим ядра)
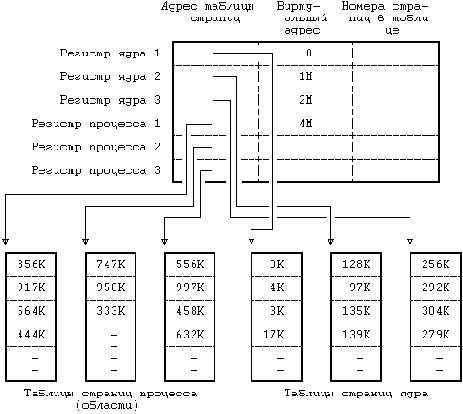
Перенастройка карты памяти в случае выгрузки с расширением
Рисунок 9.8. Перенастройка карты памяти в случае выгрузки с расширением
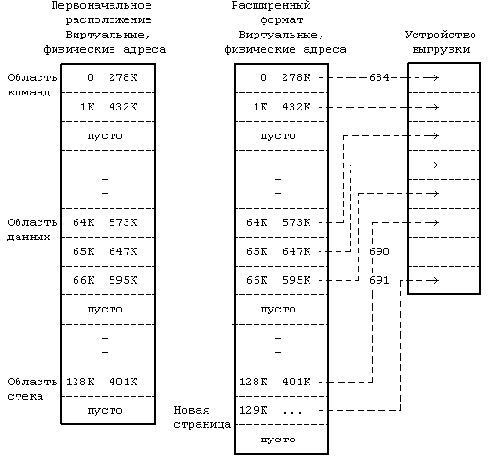
. Пересылка данных из пространства
Рисунок 6.17. Пересылка данных из пространства задачи в пространство ядра в системе VAX
| fubyte: # пересылка байта из # пространства задачи prober $3,$1,*4(ap) # байт доступен? beql eret # нет movzbl *4(ap),r0 ret eret: mnegl $1,r0 # возврат ошибки (-1) ret |
На Рисунке 6.17 показан пример реализованной в системе VAX программы пересылки символа из адресного пространства задачи в адресное пространство ядра. Команда prober проверяет, может ли байт по адресу, равному (регистр указателя аргумента + 4), быть считан в режиме задачи (режиме 3), и если нет, ядро передает управление по адресу eret, сохраняет в нулевом регистре -1 и выходит из программы; при этом пересылки символа не происходит. В противном случае ядро пересылает один байт, находящийся по указанному адресу, в регистр 0 и возвращает его в вызывающую программу. Пересылка 1 символа потребовала пяти команд (включая вызов функции с именем fubyte).
(***) Эти алгоритмы не следует путать с имеющими те же названия библиотечными функциями, которые могут вызываться непосредственно из пользовательских программ (см. [SVID 85]). Однако действие этих функций похоже.
Первоначальный вид карты памяти для устройства выгрузки
Рисунок 9.1. Первоначальный вид карты памяти для устройства выгрузки

. Пятый случай выделения буфера
Рисунок 3.11. Пятый случай выделения буфера

Можно также представить себе ситуацию, когда процесс "зависает" в ожидании получения доступа к буферу. В четвертом случае, например, если несколько процессов приостанавливаются, ожидая освобождения буфера, ядро не гарантирует, что они получат доступ к буферу в той очередности, в которой они запросили доступ. Процесс может приостановить и возобновить свое выполнение, когда буфер станет свободным, только для того, чтобы приостановиться вновь из -за того, что другой процесс получил управление над буфером первым. Теоретически, так может продолжаться вечно, но практически такой проблемы не возникает в связи с тем, что в системе обычно заложено большое количество буферов.
(**) Из предыдущей главы напомним, что все операции ядра производятся в контексте процесса, выполняемого в режиме ядра. Таким образом, слова "другие процессы" относятся к процессам, тоже выполняющимся в режиме ядра. Эти слова мы будем использовать и тогда, когда будем говорить о взаимодействии нескольких процессов, работающих в режиме ядра; и будем говорить "ядро", когда взаимодействие между процессами будет отсутствовать.
(***) Исключением является системная операция mount, которая захватывает буфер до тех пор, пока не будет исполнена операция umount. Это исключение не является существенным, поскольку общее количество буферов намного превышает число активных монтированных файловых систем.
Планирование на основе кольцевого
Рисунок 8.5. Планирование на основе кольцевого списка и приоритеты процессов
Поиск буфера - случай 1: буфер в хеш-очереди
Рисунок 3.5. Поиск буфера - случай 1: буфер в хеш-очереди

Пользовательский процесс
Рисунок 11.6. Пользовательский процесс
| #include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> #define MSGKEY 75 struct msgform { long mtype; char mtext[256]; }; main() { struct msgform msg; int msgid,pid,*pint; msgid = msgget(MSGKEY,0777); pid = getpid(); pint = (int *) msg.mtext; *pint = pid; /* копирование идентификатора * процесса в область текста * сообщения */ msg.mtype = 1; msgsnd(msgid,&msg,sizeof(int),0); msgrcv(msgid,&msg,256,pid,0); /* идентификатор * процесса используется в * качестве типа сообщения */ printf("клиент: получил от процесса с pid %d\n", *pint); } |
Последовательность обращений и
Рисунок 10.9. Последовательность обращений и поток данных через строковый интерфейс