. Последовательность операций
Рисунок 9.10. Последовательность операций, выполняемых процессом подкачки
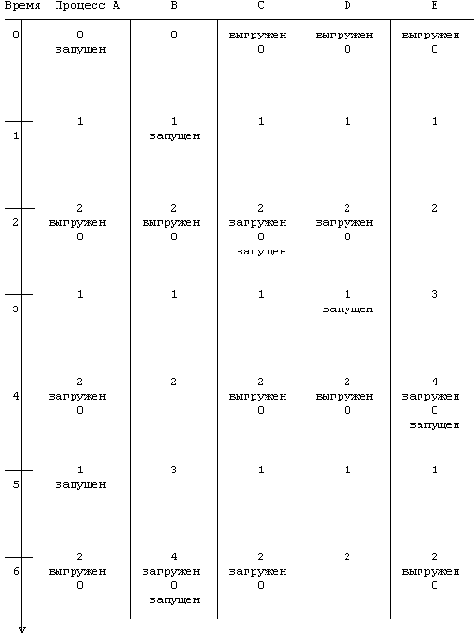
. Последовательность шагов, выполняемых
Рисунок 6.15. Последовательность шагов, выполняемых при переключении контекста
| 1. Принять решение относительно необходимости переклю- чения контекста и его допустимости в данный момент. 2. Сохранить контекст "прежнего" процесса. 3. Выбрать процесс, наиболее подходящий для исполнения, используя алгоритм диспетчеризации процессов, приве- денный в главе 8. 4. Восстановить его контекст. |
Текст программы, реализующей переключение контекста в системе UNIX, из всех программ операционной системы самый трудный для понимания, ибо при рассмотрении обращений к функциям создается впечатление, что они в одних случаях не возвращают управление, а в других - возникают непонятно откуда. Причиной этого является то, что ядро во многих системных реализациях сохраняет контекст процесса в одном месте программы, но продолжает работу, выполняя переключение контекста и алгоритмы диспетчеризации в контексте "прежнего" процесса. Когда позднее ядро восстанавливает контекст процесса, оно возобновляет его выполнение в соответствии с ранее сохраненным контекстом. Чтобы различать между собой те случаи, когда ядро восстанавливает контекст нового процесса, и когда оно продолжает исполнять ранее сохраненный контекст, можно варьировать значения, возвращаемые критическими функциями, или устанавливать искусственным образом текущее значение счетчика команд.
На Рисунке 6.16 приведена схема переключения контекста. Функция save_context сохраняет информацию о контексте исполняемого процесса и возвращает значение 1. Кроме всего прочего, ядро сохраняет текущее значение счетчика команд (в функции save_context) и значение 0 в нулевом регистре при выходе из функции. Ядро продолжает исполнять контекст "прежнего" процесса (A), выбирая для выполнения следующий процесс (B) и вызывая функцию resume_context для восстановления его контекста. После восстановления контекста система выполняет процесс B; прежний процесс (A) больше не исполняется, но он оставил после себя сохраненный контекст. Позже, когда будет выполняться переключение контекста, ядро снова изберет процесс A (если только, разумеется, он не был завершен). В результате восстановления контекста A ядро присвоит счетчику команд то значение, которое было сохранено процессом A ранее в функции save_context, и возвратит в регистре 0 значение 0. Ядро возобновляет выполнение процесса A из функции save_context, пусть даже при выполнении программы переключения контекста оно не добралось еще до функции resume_context. В конечном итоге, процесс A возвращается из функции save_context со значением 0 (в нулевом регистре) и возобновляет выполнение после строки комментария "возобновление выполнение процесса начинается отсюда".
. Последовательность состояний
Рисунок 11.17. Последовательность состояний списка структур восстановления
Ядро создает структуру восстановления всякий раз, когда процесс уменьшает значение семафора, а удаляет ее, когда процесс увеличивает значение семафора, поскольку установочное значение структуры равно 0. На Рисунке 11.17 показана последовательность состояний списка структур при выполнении программы с параметром 'a'. После первой операции процесс имеет одну структуру, состоящую из идентификатора semid, номера семафора, равного 0, и установочного значения, равного 1, а после второй операции появляется вторая структура с номером семафора, равным 1, и установочным значением, равным 1. Если процесс неожиданно завершается, ядро проходит по всем структурам и прибавляет к каждому семафору по единице, восстанавливая их значения в 0. В частном случае ядро уменьшает установочное значение для семафора 1 на третьей операции, в соответствии с увеличением значения самого семафора, и удаляет всю структуру целиком, поскольку установочное значение становится нулевым. После четвертой операции у процесса больше нет структур восстановления, поскольку все установочные значения стали нулевыми.
Векторные операции над семафорами позволяют избежать взаимных блокировок, как было показано выше, однако они представляют известную трудность для понимания и реализации, и в большинстве приложений полный набор их возможностей не является обязательным. Программы, испытывающие потребность в использовании набора семафоров, сталкиваются с возникновением взаимных блокировок на пользовательском уровне, и ядру уже нет необходимости поддерживать такие сложные формы системных функций.
Синтаксис вызова системной функции semctl:
semctl(id,number,cmd,arg);Параметр arg объявлен как объединение типов данных:
union semunion { int val; struct semid_ds *semstat; /* описание типов см. в При- * ложении */ unsigned short *array; } arg;Ядро интерпретирует параметр arg в зависимости от значения параметра cmd, подобно тому, как интерпретирует команды ioctl (глава 10). Типы действий, которые могут использоваться в параметре cmd: получить или установить значения управляющих параметров (права доступа и др.), установить значения одного или всех семафоров в наборе, прочитать значения семафоров. Подробности по каждому действию содержатся в Приложении. Если указана команда удаления, IPC_RMID, ядро ведет поиск всех процессов, содержащих структуры восстановления для данного семафора, и удаляет соответствующие структуры из системы. Затем ядро инициализирует используемые семафором структуры данных и выводит из состояния приостанова все процессы, ожидающие наступления некоторого связанного с семафором события: когда процессы возобновляют свое выполнение, они обнаруживают, что идентификатор семафора больше не является корректным, и возвращают вызывающей программе ошибку.
. Поток после открытия
Рисунок 10.20. Поток после открытия
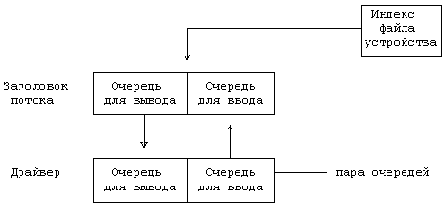
Устройство с потоковым драйвером является устройством посимвольного ввода-вывода; оно имеет в таблице ключей устройств соответствующего типа специальное поле, которое указывает на структуру инициализации потока, содержащую адреса процедур, а также верхнюю и нижнюю отметки, упомянутые выше. Когда ядро выполняет системную функцию open и обнаруживает, что файл устройства имеет тип "специальный символьный", оно проверяет наличие нового поля в таблице ключей устройств посимвольного ввода-вывода. Если в таблице отсутствует соответствующая точка входа, то драйвер не является потоковым, и ядро выполняет процедуру, обычную для устройств посимвольного ввода-вывода. Однако, при первом же открытии потокового драйвера ядро выделяет две пары очередей одну для заголовка потока и другую для драйвера. У всех открытых потоков модуль заголовка имеет идентичную структуру: он содержит общую процедуру "вывода" и общую процедуру "обслуживания" и имеет интерфейс с модулями ядра более высокого уровня, выполняющими функции read, write и ioctl. Ядро инициализирует структуру очередей драйвера, назначая значения указателям каждой очереди и копируя адреса процедур драйвера из структуры инициализации драйвера, и запускает процедуру открытия. Процедура открытия драйвера выполняет обычную инициализацию, но при этом сохраняет информацию, необходимую для повторного обращения к ассоциированной с этой процедурой очереди. Наконец, ядро отводит специальный указатель в копии индекса в памяти для ссылки на заголовок потока (Рисунок 10.20). Когда еще один процесс открывает устройство, ядро обнаруживает назначенный ранее поток с помощью этого указателя и запускает процедуру открытия для всех модулей потока.
Модули поддерживают связь со своими соседями по потоку путем передачи сообщений. Сообщение состоит из списка заголовков блоков, содержащих информацию сообщения; каждый заголовок блока содержит ссылку на место расположения начала и конца информации блока. Существует два типа сообщений - управляющее и информационное, которые определяются указателями типа в заголовке сообщения. Управляющие сообщения могут быть результатом выполнения системной функции ioctl или результатом особых условий, таких как зависание терминала, а информационные сообщения могут возникать в результате выполнения системной функции write или в результате поступления данных от устройства.
ПРЕДИСЛОВИЕ
ПРЕДИСЛОВИЕ
Впервые система UNIX была описана в 1974 году в статье Кена Томпсона и Дэнниса Ричи в журнале "Communications of the ACM" [Thompson 74]. С этого времени она получила широкое распространение и завоевала широкую популярность среди производителей ЭВМ, которые все чаще стали оснащать ею свои машины. Особой популярностью она пользуется в университетах, где довольно часто участвует в исследовательском и учебном процессе.
Множество книг и статей посвящено описанию отдельных частей системы; среди них два специальных выпуска "Bell System Technical Journal" за 1978 год [BSTJ 78] и за 1984 год [BSTJ 84]. Во многих книгах описывается пользовательский интерфейс, в частности использование электронной почты, подготовка документации, работа с командным процессором Shell; в некоторых книгах, таких как "The UNIX Programming Environment" [Kernighan 84] и "Advanced UNIX Programming" [Rochkind 85], описывается программный интерфейс. Настоящая книга посвящена описанию внутренних алгоритмов и структур, составляющих основу операционной системы (т.н. "ядро"), и объяснению их взаимосвязи с программным интерфейсом. Таким образом, она будет полезна для работающих в различных операционных средах. Во-первых, она может использоваться в качестве учебного пособия по курсу "Операционные системы" как для студентов последнего курса, так и для аспирантов первого года обучения. При работе с книгой было бы гораздо полезнее обращаться непосредственно к исходному тексту системных программ, но книгу можно читать и независимо от него. Во-вторых, эта книга может служить в качестве справочного руководства для системных программистов, из которого последние могли бы лучше уяснить себе механизм работы ядра операционной системы и сравнить между собой алгоритмы, используемые в UNIX, и алгоритмы, используемые в других операционных системах. Наконец, программисты, работающие в среде UNIX, могут углубить свое понимание механизма взаимодействия программ с операционной системой и посредством этого прийти к написанию более эффективных и совершенных программ.
Содержание и порядок построения материала в книге соответствуют курсу лекций, подготовленному и прочитанному мной для сотрудников фирмы Bell
Laboratories, входящей в состав корпорации AT&T, между 1983 и 1984 гг. Несмотря на то, что главное внимание в курсе лекций обращалось на исходный текст системных программ, я обнаружил, что понимание исходного текста облегчается, если пользователь имеет представление о системных алгоритмах. В книге я пытался изложить описание алгоритмов как можно проще, чтобы и в малом отразить простоту и изящество рассматриваемой операционной системы. Таким образом, книга представляет собой не только подробное истолкование особенностей системы на английском языке; это изображение общего механизма работы различных алгоритмов, и что гораздо важнее, это отражение процесса их взаимодействия между собой. Алгоритмы представлены на псевдокоде, похожем на язык Си, поскольку читателю легче воспринимать описание на естественном языке; наименования алгоритмов соответствуют именам процедур, составляющих ядро операционной системы. Рисунки описывают взаимодействие различных информационных структур под управлением операционной системы. В последних главах многие системные понятия иллюстрируются с помощью небольших программ на языке Си. В целях экономии места и обеспечения ясности изложения из этих примеров исключен контроль возникновения ошибок, который обычно предусматривается при написании программ. Эти примеры прогонялись мною под управлением версии V; за исключением программ, иллюстрирующих особенности, присущие версии V, их можно выполнять под управлением других версий операционной системы.
Большое число упражнений, подготовленных первоначально для курса лекций, приведено в конце каждой главы, они составляют ключевую часть книги. Отдельные упражнения, иллюстрирующие основные понятия, размещены непосредственно в тексте книги. Другая часть упражнений отличается большей сложностью, поскольку их предназначение состоит в том, чтобы помочь читателю углубить свое понимание особенностей системы. И, наконец, часть упражнений является по природе исследовательской, предназначенной для изучения отдельных проблем. Упражнения повышенной сложности помечены звездочками.
Системное описание базируется на особенностях операционной системы UNIX версия V редакция 2, распространением которой занимается корпорация AT&T, с учетом отдельных особенностей редакции 3. Это та система, с которой я наиболее знаком, однако я постарался отразить и интересные детали других разновидностей операционных систем, в частности систем, распространяемых через "Berkeley Software Distribution" (BSD). Я не касался вопросов, связанных с характеристиками отдельных аппаратных средств, стараясь только в общих чертах охватить процесс взаимодействия ядра операционной системы с аппаратными средствами и игнорируя характерные особенности физической конфигурации. Тем не менее, там, где вопросы, связанные с машинными особенностями, представились мне важными с точки зрения понимания механизма функционирования ядра, оказалось уместным и углубление в детали. По крайней мере, беглый просмотр затронутых в книге вопросов ясно указывает те составные части операционной системы, которые являются наиболее машинно-зависимыми.
Общение с книгой предполагает наличие у читателя опыта программирования на одном из языков высокого уровня и желательно на языке ассемблера. Читателю рекомендуется приобрести опыт работы с операционной системой UNIX и познакомиться с языком программирования Си [Kernighan 78]. Тем не менее, я старался изложить материал в книге таким образом, чтобы читатель смог овладеть им даже при отсутствии требуемых навыков. В приложении к книге приведено краткое описание обращений к операционной системе, которого будет достаточно для того, чтобы получить представление о содержании книги, но которое не может служить в качестве полного справочного руководства.
Материал в книге построен следующим образом. Глава 1 служит введением, содержащим краткое, общее описание системных особенностей с точки зрения пользователя и объясняющим структуру системы. В главе 2 дается общее представление об архитектуре ядра и поясняются некоторые основные понятия. В остальной части книги освещаются вопросы, связанные с общей архитектурой системы и описанием ее различных компонент как блоков единой конструкции. В ней можно выделить три раздела: файловая система, управление процессами и вопросы, связанные с развитием. Файловая система представлена первой, поскольку ее понимание легче по сравнению с управлением процессами. Так, глава 3 посвящена описанию механизма функционирования системного буфера сверхоперативной памяти (кеша), составляющего основу файловой системы. Глава 4 описывает информационные структуры и алгоритмы, используемые файловой системой. В этих алгоритмах используются методы, объясняемые в главе 3, для ведения внутренней "бухгалтерии", необходимой для управления пользовательскими файлами. Глава 5 посвящена описанию обращений к операционной системе, обслуживающих интерфейс пользователя с файловой системой; для обеспечения доступа к пользовательским файлам используются алгоритмы главы 4.
Основное внимание в главе 6 уделяется управлению процессами. В ней определяется понятие контекста процесса и исследуются внутренние составляющие ядра операционной системы, управляющие контекстом процесса. В частности, рассматривается обращение к операционной системе, обработка прерываний и переключение контекста. В главе 7 анализируются те системные операции, которые управляют контекстом процесса. Глава 8 касается планирования процессов, глава 9 - распределения памяти, включая системы подкачки и замещения страниц.
В главе 10 дается обзор общих особенностей взаимодействия, которое обеспечивают драйверы устройств, особое внимание уделяется дисковым и терминальным драйверам. Несмотря на то, что устройства логически входят в состав файловой системы, их рассмотрение до этого момента откладывалось в связи с возникновением вопросов, связанных с управлением процессами, при обсуждении терминальных драйверов. Эта глава также служит мостиком к вопросам, связанным с развитием системы, которые рассматриваются в конце книги. Глава 11 касается взаимодействия процессов и организации сетей, в том числе сообщений, используемых в версии V, разделения памяти, семафоров и пакетов BSD. Глава 12 содержит компактное изложение особенностей двухпроцессорной системы UNIX, в главе 13 исследуются двухмашинные распределенные вычислительные системы.
Материал, представленный в первых девяти главах, может быть прочитан в процессе изучения курса "Операционные системы" в течение одного семестра, материал остальных глав следует изучать на опережающих семинарах с параллельным выполнением практических заданий.
Теперь мне бы хотелось предупредить читателя о следующем. Я не пытался оценить производительность системы в абсолютном выражении, не касался и параметров конфигурации, необходимых для инсталляции системы. Эти данные меняются в зависимости от типа машины, конфигурации комплекса технических средств, версии и реализации системы, состава задач. Кроме того, я сознательно избегал любых предсказаний по поводу дальнейшего развития операционной системы UNIX. Изложение вопросов, связанных с развитием, не подкреплено обязательством корпорации AT&T обеспечить соответствующие характеристики, даже не гарантируется то, что соответствующие области являются объектом исследования.
Мне приятно выразить благодарность многим друзьям и коллегам за помощь при написании этой книги и за конструктивные критические замечания, высказанные при ознакомлении с рукописью. Я должен выразить глубочайшую признательность Яну Джонстону, который посоветовал мне написать эту книгу, оказал мне поддержку на начальном этапе и просмотрел набросок первых глав. Ян открыл мне многие секреты ремесла и я всегда буду в долгу перед ним. Дорис Райан также поддерживала меня с самого начала, и я всегда буду ценить ее доброту и внимательность. Дэннис Ричи добровольно ответил на многочисленные вопросы, касающиеся исторического и технического аспектов системы. Множество людей пожертвовали своим временем и силами на ознакомление с вариантами рукописи, появление этой книги во многом обязано высказанным ими подробным замечаниям. Среди них Дебби Бэч, Дуг Байер, Лэнни Брэндвейн, Стив Барофф, Том Батлер, Рон Гомес, Месат Гандак, Лаура Изрейел, Дин Джегелс, Кейт Келлеман, Брайан Керниган, Боб Мартин, Боб Митц, Дейв Новиц, Майкл Попперс, Мэрилин Сэфран, Курт Шиммель, Зуи Спитц, Том Вэден, Билл Вебер, Лэрри Вэр и Боб Зэрроу. Мэри Фрустак помогала подготовить рукопись к набору. Я хотел бы также поблагодарить мое руководство за постоянную поддержку, которую я ощущал на всем протяжении работы, и коллег за атмосферу, способствовавшую мне в работе, и за замечательные условия, предоставленные фирмой AT&T Bell Laboratories. Джон Вейт и персонал издательства Prentice-Hall оказали самую разнообразную помощь в придании книге ее окончательного вида. Последней по списку, но не по величине явилась помощь моей жены, Дебби, оказавшей мне эмоциональную поддержку, без которой я бы не достиг успеха.
Оглавление
| Следующая глава
Преобразование адреса смещения
Рисунок 4.8. Преобразование адреса смещения в номер блока в файловой системе
| алгоритм bmap /* отображение адреса смещения в байтах от начала логического файла на адрес блока в файловой системе */ входная информация: (1) индекс (2) смещение в байтах выходная информация: (1) номер блока в файловой системе (2) смещение в байтах внутри блока (3) число байт ввода-вывода в блок (4) номер блока с продвижением { вычислить номер логического блока в файле исходя из заданного смещения в байтах; вычислить номер начального байта в блоке для ввода- вывода; /* выходная информация 2 */ вычислить количество байт для копирования пользова- телю; /* выходная информация 3 */ проверить возможность чтения с продвижением, пометить индекс; /* выходная информация 4 */ определить уровень косвенности; выполнить (пока уровень косвенности другой) { определить указатель в индексе или блок косвенной адресации исходя из номера логического блока в файле; получить номер дискового блока из индекса или из блока косвенной адресации; освободить буфер от данных, полученных в резуль- тате выполнения предыдущей операции чтения с диска (алгоритм brelse); если (число уровней косвенности исчерпано) возвратить (номер блока); считать дисковый блок косвенной адресации (алго- ритм bread); установить номер логического блока в файле исходя из уровня косвенности; } } |
Рассмотрим формат файла в блоках (Рисунок 4.9) и предположим, что дисковый блок занимает 1024 байта. Если процессу нужно обратиться к байту, имеющему смещение от начала файла, равное 9000, в результате вычислений ядро приходит к выводу, что этот байт располагается в блоке прямой адресации с номером 8 (начиная с 0). Затем ядро обращается к блоку с номером 367; 808-й байт в этом блоке (если вести отсчет с 0) и является 9000-м байтом в файле. Если процессу нужно обратиться по адресу, указанному смещением 350000 байт от начала файла, он должен считать блок двойной косвенной адресации, который на рисунке имеет номер 9156. Так как блок косвенной адресации имеет место для 256 номеров блоков, первым байтом, к которому будет получен доступ в результате обращения к блоку двойной косвенной адресации, будет байт с номером 272384 (256К + 10К); таким образом, байт с номером 350000 будет иметь в блоке двойной косвенной адресации номер 77616. Поскольку каждый блок одинарной косвенной адресации позволяет обращаться к 256 Кбайтам, байт с номером 350000 должен располагаться в нулевом блоке одинарной косвенной адресации для блока двойной косвенной адресации, а именно в блоке 331. Так как в каждом блоке прямой адресации для блока одинарной косвенной адресации хранится 1 Кбайт, байт с номером 77616 находится в 75-м блоке прямой адресации для блока одинарной косвенной адресации, а именно в блоке 3333. Наконец, байт с номером в файле 350000 имеет в блоке 3333 номер 816.
Преобразование виртуальных адресов в физические
Рисунок 6.5. Преобразование виртуальных адресов в физические

Организацию управления памятью попробуем пояснить на следующем простом примере. Пусть память разбита на страницы размером 1 Кбайт каждая, обращение к которым осуществляется через описанные ранее таблицы страниц. Регистры управления памятью в системе группируются по три; первый регистр в тройке содержит адрес таблицы страниц в физической памяти, второй регистр содержит первый виртуальный адрес, отображаемый с помощью тройки регистров, третий регистр содержит управляющую информацию, такую как номера страниц в таблице страниц и права доступа к страницам (только чтение, чтение и запись). Такая модель соответствует вышеописанной модели области. Когда ядро готовит процесс к выполнению, оно загружает тройки регистров соответствующей информацией из записей частной таблицы областей процесса.
Если процесс обращается к ячейкам памяти, расположенным за пределами принадлежащего ему виртуального пространства, создается исключительная ситуация. Например, если область команд имеет размер 16 Кбайт (Рисунок 6.5), а процесс обращается к виртуальному адресу 26К, создается исключительная ситуация, обрабатываемая операционной системой. То же самое происходит, если процесс пытается обратиться к памяти, не имея соответствующих прав доступа, например, пытается записать адрес в защищенную от записи область команд. И в том, и в другом примере процесс обычно завершается (более подробно об этом в следующей главе).
Прерывания от устройств
Рисунок 10.6. Прерывания от устройств
. Прием вызова сервером
Рисунок 11.19. Прием вызова сервером
Системная функция accept принимает запросы на подключение, поступающие на вход процесса-сервера:
nsd = accept(sd,address,addrlen);где sd - дескриптор гнезда, address - указатель на пользовательский массив, в котором ядро возвращает адрес подключаемого клиента, addrlen - размер пользовательского массива. По завершении выполнения функции ядро записывает в переменную addrlen размер пространства, фактически занятого массивом. Функция возвращает новый дескриптор гнезда (nsd), отличный от дескриптора sd. Процесс-сервер может продолжать слежение за состоянием объявленного гнезда, поддерживая связь с клиентом по отдельному каналу (Рисунок 11.19).
Функции send и recv выполняют передачу данных через подключенное гнездо. Синтаксис вызова функции send:
count = send(sd,msg,length,flags);где sd - дескриптор гнезда, msg - указатель на посылаемые данные, length размер данных, count - количество фактически переданных байт. Параметр flags может содержать значение SOF_OOB (послать данные out-of-band - "через таможню"), если посылаемые данные не учитываются в общем информационном обмене между взаимодействующими процессами. Программа удаленной регистрации, например, может послать out-of-band сообщение, имитирующее нажатие на клавиатуре терминала клавиши "delete". Синтаксис вызова системной функции recv:
count = recv(sd,buf,length,flags);где buf - массив для приема данных, length - ожидаемый объем данных, count количество байт, фактически переданных пользовательской программе. Флаги (flags) могут быть установлены таким образом, что поступившее сообщение после чтения и анализа его содержимого не будет удалено из очереди, или настроены на получение данных out-of-band. В дейтаграммных версиях указанных функций, sendto и recvfrom, в качестве дополнительных параметров указываются адреса. После выполнения подключения к гнездам потокового типа процессы могут вместо функций send и recv использовать функции read и write. Таким образом, согласовав тип протокола, серверы могли бы порождать процессы, работающие только с функциями read и write, словно имеют дело с обычными файлами.
Функция shutdown закрывает гнездовую связь:
shutdown(sd,mode)где mode указывает, какой из сторон (посылающей, принимающей или обеим вместе) отныне запрещено участие в процессе передачи данных. Функция сообщает используемому протоколу о завершении сеанса сетевого взаимодействия, оставляя, тем не менее, дескрипторы гнезд в неприкосновенности. Освобождается дескриптор гнезда только в результате выполнения функции close.
Системная функция getsockname получает имя гнездовой связи, установленной ранее с помощью функции bind:
getsockname(sd,name,length);Функции getsockopt и setsockopt получают и устанавливают значения различных связанных с гнездом параметров в соответствии с типом домена и протокола.
Рассмотрим обслуживающую программу, представленную на Рисунке 11.20. Процесс создает в домене "UNIX system" гнездо потокового типа и присваивает ему имя sockname. Затем с помощью функции listen устанавливается длина очереди поступающих сообщений и начинается цикл ожидания поступления запросов. Функция accept приостанавливает свое выполнение до тех пор, пока протоколом не будет зарегистрирован запрос на подключение к гнезду с означенным именем; после этого функция завершается, возвращая поступившему запросу новый дескриптор гнезда. Процесс-сервер порождает потомка, через которого будет поддерживаться связь с процессом-клиентом; родитель и потомок при этом закрывают свои дескрипторы, чтобы они не становились помехой для коммуникационного траффика другого процесса. Процесс-потомок ведет разговор с клиентом и завершается после выхода из функции read. Процесс-сервер возвращается к началу цикла и ждет поступления следующего запроса на подключение.
Пример дискового индекса
Рисунок 4.2. Пример дискового индекса
| владелец mjb группа os тип - обычный файл права доступа rwxr-xr-x последнее обращение 23 Окт 1984 13:45 последнее изменение 22 Окт 1984 10:30 коррекция индекса 23 Окт 1984 13:30 размер 6030 байт дисковые адреса |
На Рисунке 4.2 показан дисковый индекс некоторого файла. Этот индекс принадлежит обычному файлу, владелец которого - "mjb" и размер которого 6030 байт. Система разрешает пользователю "mjb" производить чтение, запись и исполнение файла; членам группы "os" и всем остальным пользователям разрешается только читать или исполнять файл, но не записывать в него данные. Последний раз файл был прочитан 23 октября 1984 года в 13:45, запись последний раз производилась 22 октября 1984 года в 10:30. Индекс изменялся последний раз 23 октября 1984 года в 13:30, хотя никакая информация в это время в файл не записывалась. Ядро кодирует все вышеперечисленные данные в индексе. Обратите внимание на различие в записи на диск содержимого индекса и содержимого файла. Содержимое файла меняется только тогда, когда в файл производится запись. Содержимое индекса меняется как при изменении содержимого файла, так и при изменении владельца файла, прав доступа и набора указателей. Изменение содержимого файла автоматически вызывает коррекцию индекса, однако коррекция индекса еще не означает изменения содержимого файла.
Копия индекса в памяти, кроме полей дискового индекса, включает в себя и следующие поля:
Состояние индекса в памяти, отражающее заблокирован ли индекс, ждет ли снятия блокировки с индекса какой-либо процесс, отличается ли представление индекса в памяти от своей дисковой копии в результате изменения содержимого индекса, отличается ли представление индекса в памяти от своей дисковой копии в результате изменения содержимого файла, находится ли файл в верхней точке (см. раздел 5.15). Логический номер устройства файловой системы, содержащей файл. Номер индекса. Так как индексы на диске хранятся в линейном массиве (см. раздел 2.2.1), ядро идентифицирует номер дискового индекса по его местоположению в массиве. В дисковом индексе это поле не нужно. Указатели на другие индексы в памяти. Ядро связывает индексы в хеш-очереди и включает их в список свободных индексов подобно тому, как связывает буферы в буферные хеш-очереди и включает их в список свободных буферов. Хеш-очередь идентифицируется в соответствии с логическим номером устройства и номером индекса. Ядро может располагать в памяти не более одной копии данного дискового индекса, но индексы могут находиться одновременно как в хеш-очереди, так и в списке свободных индексов. Счетчик ссылок, означающий количество активных экземпляров файла (таких, которые открыты).Многие поля в копии индекса, с которой ядро работает в памяти, аналогичны полям в заголовке буфера, и управление индексами похоже на управление буферами. Индекс так же блокируется, в результате чего другим процессам запрещается работа с ним; эти процессы устанавливают в индексе специальный флаг, возвещающий о том, что выполнение обратившихся к индексу процессов следует возобновить, как только блокировка будет снята. Установкой других флагов ядро отмечает противоречия между дисковым индексом и его копией в памяти. Когда ядру нужно будет записать изменения в файл или индекс, ядро перепишет копию индекса из памяти на диск только после проверки этих флагов.
Наиболее разительным различием между копией индекса в памяти и заголовком буфера является наличие счетчика ссылок, подсчитывающего количество активных экземпляров файла. Индекс активен, когда процесс выделяет его, например, при открытии файла. Индекс находится в списке свободных индексов, только если значение его счетчика ссылок равно 0, и это значит, что ядро может переназначить свободный индекс в памяти другому дисковому индексу. Таким образом, список свободных индексов выступает в роли кеша для неактивных индексов. Если процесс пытается обратиться к файлу, чей индекс в этот момент отсутствует в индексном пуле, ядро переназначает свободный индекс из списка для использования этим процессом. С другой стороны, у буфера нет счетчика ссылок; он находится в списке свободных буферов тогда и только тогда, когда он разблокирован.
Пример диспетчеризации процессов
Рисунок 8.4. Пример диспетчеризации процессов
Теперь рассмотрим процессы с приоритетами, приведенными на Рисунке 8.5, и предположим, что в системе имеются и другие процессы. Ядро может выгрузить процесс A, оставив его в состоянии "готовности к выполнению", после того, как он получит подряд несколько квантов времени для работы с ЦП и снизит таким образом свой приоритет выполнения в режиме задачи (Рисунок 8.5а). Через некоторое время после запуска процесса A в состояние "готовности к выполнению" может перейти процесс B, приоритет которого в тот момент окажется выше приоритета процесса A (Рисунок 8.5б). Если ядро за это время не запланировало к выполнению любой другой процесс (из тех, что не показаны на рисунке), оба процесса (A и B) при известных обстоятельствах могут на некоторое время оказаться на одном уровне приоритетности, хотя процесс B попадет на этот уровень первым из-за того, что его первоначальный приоритет был ближе (Рисунок 8.5в и 8.5г). Тем не менее, ядро запустит процесс A впереди процесса B, поскольку процесс A находился в состоянии "готовности к выполнению" более длительное время (Рисунок 8.5д) - это решающее условие, если выбор производится из процессов с одинаковыми приоритетами.
В разделе 6.4.3 уже говорилось о том, что ядро запускает процесс на выполнение после переключения контекста: прежде чем перейти в состояние приостанова или завершить свое выполнение процесс должен переключить контекст, кроме того он имеет возможность переключать контекст в момент перехода из режима ядра в режим задачи. Ядро выгружает процесс, который собирается перейти в режим задачи, если имеется готовый к выполнению процесс с более высоким приоритетом. Такая ситуация возникает, если ядро вывело из состояния приостанова процесс с приоритетом, превышающим приоритет текущего процесса, или если в результате обработки прерывания по таймеру изменились приоритеты всех готовых к выполнению процессов. В первом случае текущий процесс не может выполняться в режиме задачи, поскольку имеется процесс с более высоким приоритетом выполнения в режиме ядра. Во втором случае программа обработки прерываний по таймеру решает, что процесс использовал выделенный ему квант времени, и поскольку множество процессов при этом меняют свои приоритеты, ядро выполняет переключение контекста.
Пример древовидной структуры файловой системы
Рисунок 1.2. Пример древовидной структуры файловой системы

Файловая система организована в виде дерева с одной исходной вершиной, которая называется корнем (записывается: "/"); каждая вершина в древовидной структуре файловой системы, кроме листьев, является каталогом файлов, а файлы, соответствующие дочерним вершинам, являются либо каталогами, либо обычными файлами, либо файлами устройств. Имени файла предшествует указание пути поиска, который описывает место расположения файла в иерархической структуре файловой системы. Имя пути поиска состоит из компонент, разделенных между собой наклонной чертой (/); каждая компонента представляет собой набор символов, составляющих имя вершины (файла), которое является уникальным для каталога (предыдущей компоненты), в котором оно содержится. Полное имя пути поиска начинается с указания наклонной черты и идентифицирует файл (вершину), поиск которого ведется от корневой вершины дерева файловой системы с обходом тех ветвей дерева файлов, которые соответствуют именам отдельных компонент. Так, пути "/etc/passwd", "/bin/who" и "/usr/src/cmd/who.c" указывают на файлы, являющиеся вершинами дерева, изображенного на Рисунке 1.2, а пути "/bin/passwd" и "/usr/ src/date.c" содержат неверный маршрут. Имя пути поиска необязательно должно начинаться с корня, в нем следует указывать маршрут относительно текущего для выполняемого процесса каталога, при этом предыдущие символы "наклонная черта" в имени пути опускаются. Так, например, если мы находимся в каталоге "/dev", то путь "tty01" указывает файл, полное имя пути поиска для которого "/dev /tty01".
Программы, выполняемые под управлением системы UNIX, не содержат никакой информации относительно внутреннего формата, в котором ядро хранит файлы данных, данные в программах представляются как бесформатный поток байтов. Программы могут интерпретировать поток байтов по своему желанию, при этом любая интерпретация никак не будет связана с фактическим способом хранения данных в операционной системе. Так, синтаксические правила, определяющие задание метода доступа к данным в файле, устанавливаются системой и являются едиными для всех программ, однако семантика данных определяется конкретной программой. Например, программа форматирования текста troff ищет в конце каждой строки текста символы перехода на новую строку, а программа учета системных ресурсов acctcom работает с записями фиксированной длины. Обе программы пользуются одними и теми же системными средствами для осуществления доступа к данным в файле как к потоку байтов, и внутри себя преобразуют этот поток по соответствующему формату. Если любая из программ обнаружит, что формат данных неверен, она принимает соответствующие меры.
Каталоги похожи на обычные файлы в одном отношении; система представляет информацию в каталоге набором байтов, но эта информация включает в себя имена файлов в каталоге в объявленном формате для того, чтобы операционная система и программы, такие как ls (выводит список имен и атрибутов файлов), могли их обнаружить.
Права доступа к файлу регулируются установкой специальных битов разрешения доступа, связанных с файлом. Устанавливая биты разрешения доступа, можно независимо управлять выдачей разрешений на чтение, запись и выполнение для трех категорий пользователей: владельца файла, группового пользователя и прочих. Пользователи могут создавать файлы, если разрешен доступ к каталогу. Вновь созданные файлы становятся листьями в древовидной структуре файловой системы.
Для пользователя система UNIX трактует устройства так, как если бы они были файлами. Устройства, для которых назначены специальные файлы устройств, становятся вершинами в структуре файловой системы. Обращение программ к устройствам имеет тот же самый синтаксис, что и обращение к обычным файлам; семантика операций чтения и записи по отношению к устройствам в большой степени совпадает с семантикой операций чтения и записи обычных файлов. Способ защиты устройств совпадает со способом защиты обычных файлов: путем соответствующей установки битов разрешения доступа к ним (файлам). Поскольку имена устройств выглядят так же, как и имена обычных файлов, и поскольку над устройствами и над обычными файлами выполняются одни и те же операции, большинству программ нет необходимости различать внутри себя типы обрабатываемых файлов.
Например, рассмотрим программу на языке Си (Рисунок 1.3), в которой создается новая копия существующего файла. Предположим, что исполняемая версия программы имеет наименование copy. Для запуска программы пользователь вводит с терминала:
copy oldfile newfileгде oldfile - имя существующего файла, а newfile - имя создаваемого файла. Система выполняет процедуру main, присваивая аргументу argc значение количества параметров в списке argv, а каждому элементу массива argv значение параметра, сообщенного пользователем. В приведенном примере argc имеет значение 3, элемент argv[0] содержит строку символов "copy" (имя программы условно является нулевым параметром), argv[1] - строку символов "oldfile", а argv[2] - строку символов "newfile". Затем программа проверяет, правильное ли количество параметров было указано при ее запуске. Если это так, запускается операция open (открыть) для файла oldfile с параметром "read-only" (только для чтения), в случае успешного выполнения которой запускается операция creat (открыть) для файла newfile. Режим доступа к вновь созданному файлу описывается числом 0666 (в восьмеричном коде), что означает разрешение доступа к файлу для чтения и записи для всех пользователей. Все обращения к операционной системе в случае неудачи возвращают код -1; если же неудачно завершаются операции open и creat, программа выдает сообщение и запускает операцию exit (выйти) с возвращением кода состояния, равного 1, завершая свою работу и указывая на возникновение ошибки.
Операции open и creat возвращают целое значение, являющееся дескриптором файла и используемое программой в последующих ссылках на файлы. После этого программа вызывает подпрограмму copy, выполняющую в цикле операцию read (читать), по которой производится чтение в буфер порции символов из существующего файла, и операцию write (писать) для записи информации в новый файл. Операция read каждый раз возвращает количество прочитанных байтов (0 - если достигнут конец файла). Цикл завершается, если достигнут конец файла или если произошла ошибка при выполнении операции read (отсутствует контроль возникновения ошибок при выполнении операции write). Затем управление из подпрограммы copy возвращается в основную программу и запускается операция exit с кодом состояния 0 в качестве параметра, что указывает на успешное завершение выполнения программы.
Программа копирует любые файлы, указанные при ее вызове в качестве аргументов, при условии, что разрешено открытие существующего файла и создание нового файла. Файл может включать в себя как текст, который может быть выведен на печатающее устройство, например, исходный текст программы, так и символы, не выводимые на печать, даже саму программу. Таким образом, оба вызова:
copy copy.c newcopy.c copy copy newcopyявляются допустимыми. Существующий файл также может быть каталогом. Например, по вызову:
copy . dircontentsкопируется содержимое текущего каталога, обозначенного символом ".", в обычный файл "dircontents"; информация в новом файле совпадает, вплоть до каждого байта, с содержимым каталога, только этот файл обычного типа (для создания нового каталога предназначена операция mknod). Наконец, любой из файлов может быть файлом устройства. Например, программа, вызванная следующим образом:
copy /dev/tty terminalreadчитает символы, вводимые с терминала (файл /dev/tty соответствует терминалу пользователя), и копирует их в файл terminalread, завершая работу только в том случае, если пользователь нажмет <Ctrl/d>. Похожая форма запуска программы:
copy /dev/tty /dev/ttyвызывает чтение символов с терминала и их копирование обратно на терминал.
. Пример использования функции
Рисунок 7.17. Пример использования функции wait и игнорирования сигнала "гибель потомка"
| #include <signal.h> main(argc,argv) int argc; char *argv[]; { int i,ret_val,ret_code; if (argc >= 1) signal(SIGCLD,SIG_IGN); /* игнорировать гибель потомков */ for (i = 0; i < 15; i++) if (fork() == 0) { /* процесс-потомок */ printf("процесс-потомок %x\n",getpid()); exit(i); } ret_val = wait(&ret_code); printf("wait ret_val %x ret_code %x\n",ret_val,ret_code); } |
В ранних версиях системы UNIX функции exit и wait не использовали и не рассматривали сигнал типа "гибель потомка". Вместо посылки сигнала функция exit возобновляла выполнение родительского процесса. Если родительский процесс при выполнении функции wait приостановился, он возобновляется, находит потомка, прекратившего существование, и возвращает управление. В противном случае возобновления не происходит; процесс-родитель обнаружит "погибшего" потомка при следующем обращении к функции wait. Точно так же и процесс начальной загрузки (init) может приостановиться, используя функцию wait, и завершающиеся по exit процессы будут возобновлять его, если он имеет усыновленных потомков, прекращающих существование.
В такой реализации функций exit и wait имеется одна нерешенная проблема, связанная с тем, что процессы, прекратившие существование, нельзя убирать из системы до тех пор, пока их родитель не исполнит функцию wait. Если процесс создал множество потомков, но так и не исполнил функцию wait, может произойти переполнение таблицы процессов из-за наличия потомков, прекративших существование с помощью функции exit. В качестве примера рассмотрим текст программы планировщика процессов, приведенный на Рисунке 7.18. Процесс производит считывание данных из файла стандартного ввода до тех пор, пока не будет обнаружен конец файла, создавая при каждом исполнении функции read нового потомка. Однако, процесс-родитель не дожидается завершения каждого потомка, поскольку он стремится запускать процессы на выполнение как можно быстрее, тем более, что может пройти довольно много времени, прежде чем процесс-потомок завершит свое выполнение. Если, обратившись к функции signal, процесс распорядился игнорировать сигналы типа "гибель потомка", ядро будет очищать записи, соответствующие прекратившим существование процессам, автоматически. Иначе в конечном итоге из-за таких процессов может произойти переполнение таблицы.
. Пример использования функции exec
Рисунок 7.21. Пример использования функции exec
| main() { int status; if (fork() == 0) execl("/bin/date","date",0); wait(&status); } |
В качестве примера можно привести программу (Рисунок 7.21), в которой создается процесс-потомок, запускающий функцию exec. Сразу по завершении функции fork процесс-родитель и процесс-потомок начинают исполнять независимо друг от друга копии одной и той же программы. К моменту вызова процессом-потомком функции exec в его области команд находятся инструкции этой программы, в области данных располагаются строки "/bin/date" и "date", а в стеке - записи, которые будут извлечены по выходе из exec. Ядро ищет файл "/bin/date" в файловой системе, обнаружив его, узнает, что его может исполнить любой пользователь, а также то, что он представляет собой загрузочный модуль, готовый для исполнения. По условию первым параметром функции exec, включаемым в список параметров argv, является имя исполняемого файла (последняя компонента имени пути поиска файла). Таким образом, процесс имеет доступ к имени программы на пользовательском уровне, что иногда может оказаться полезным (***). Затем ядро копирует строки "/bin/date" и "date" во внутреннюю структуру хранения и освобождает области команд, данных и стека, занимаемые процессом. Процессу выделяются новые области команд, данных и стека, в область команд переписывается командная секция файла "/bin/date", в область данных - секция данных файла. Ядро восстанавливает первоначальный список параметров (в данном случае это строка символов "date") и помещает его в область стека. Вызвав функцию exec, процесс-потомок прекращает выполнение старой программы и переходит к выполнению программы "date"; когда программа "date" завершится, процесс-родитель, ожидающий этого момента, получит код завершения функции exit.
Вплоть до настоящего момента мы предполагали, что команды и данные размещаются в разных секциях исполняемой программы и, следовательно, в разных областях текущего процесса. Такое размещение имеет два основных преимущества: простота организации защиты от несанкционированного доступа и возможность разделения областей различными процессами. Если бы команды и данные находились в одной области, система не смогла бы предотвратить затирание команд, поскольку ей не были бы известны адреса, по которым они располагаются. Если же команды и данные находятся в разных областях, система имеет возможность пользоваться механизмами аппаратной защиты области команд процесса. Когда процесс случайно попытается что-то записать в область, занятую командами, он получит отказ, порожденный системой защиты и приводящий обычно к аварийному завершению процесса.
. Пример использования функции exit
Рисунок 7.15. Пример использования функции exit
| main() { int child; if ((child = fork()) == 0) { printf("PID потомка %d\n",getpid()); pause(); /* приостанов выполнения до получения сигнала */ } /* родитель */ printf("PID потомка %d\n",child); exit(child); } |
Алгоритм функции wait приведен на Рисунке 7.16. Ядро ведет поиск потомков процесса, прекративших существование, и в случае их отсутствия возвращает ошибку. Если потомок, прекративший существование, обнаружен, ядро передает его код идентификации и значение, возвращаемое через параметр функции exit, процессу, вызвавшему функцию wait. Таким образом, через параметр функции exit (status) завершающийся процесс может передавать различные значения, в закодированном виде содержащие информацию о причине завершения процесса, однако на практике этот параметр используется по назначению довольно редко. Ядро передает в соответствующие поля, принадлежащие пространству родительского процесса, накопленные значения продолжительности исполнения процесса-потомка в режиме ядра и в режиме задачи и, наконец, освобождает в таблице процессов место, которое в ней занимал прежде прекративший существование процесс. Это место будет предоставлено новому процессу.
Если процесс, выполняющий функцию wait, имеет потомков, продолжающих существование, он приостанавливается до получения ожидаемого сигнала. Ядро не возобновляет по своей инициативе процесс, приостановившийся с помощью функции wait: такой процесс может возобновиться только в случае получения сигнала. На все сигналы, кроме сигнала "гибель потомка", процесс реагирует ранее рассмотренным образом. Реакция процесса на сигнал "гибель потомка" проявляется по-разному в зависимости от обстоятельств:
По умолчанию (то есть если специально не оговорены никакие другие действия) процесс выходит из состояния останова, в которое он вошел с помощью функции wait, и запускает алгоритм issig для опознания типа поступившего сигнала. Алгоритм issig (Рисунок 7.7) рассматривает особый случай поступления сигнала типа "гибель потомка" и возвращает "ложь". Поэтому ядро не выполняет longjump из функции sleep, а возвращает управление функции wait. Оно перезапускает функцию wait, находит потомков, прекративших существование (по крайней мере, одного), освобождает место в таблице процессов, занимаемое этими потомками, и выходит из функции wait, возвращая управление процессу, вызвавшему ее. Если процессы принимает сигналы данного типа, ядро делает все необходимые установки для запуска пользовательской функции обработки сигнала, как и в случае поступления сигнала любого другого типа. Если процесс игнорирует сигналы данного типа, ядро перезапускает функцию wait, освобождает в таблице процессов место, занимаемое потомками, прекратившими существование, и исследует оставшихся потомков.. Пример использования функции setpgrp
Рисунок 7.13. Пример использования функции setpgrp
| #include <signal.h> main() { register int i; setpgrp(); for (i = 0; i < 10; i++) { if (fork() == 0) { /* порожденный процесс */ if (i & 1) setpgrp(); printf("pid = %d pgrp = %d\n",getpid(),getpgrp()); pause(); /* системная функция приостанова вы- полнения */ } } kill(0,SIGINT); } |
(*) Использование сигналов в некоторых обстоятельствах позволяет обнаружить ошибки при выполнении программ, не проверяющих код завершения вызываемых системных функций (сообщил Д.Ричи).
. Пример модуля, содержащего вызов
Рисунок 7.33. Пример модуля, содержащего вызов функции fork и обращение к стандартному выводу
| main() { printf("hello\n"); if (fork() == 0) printf("world\n"); } |
2. Разберитесь в механизме работы программы, приведенной на Рисунке 7.34, и сравните ее результаты с результатами программы на Рисунке 7.4.
Пример планирования на основе
Рисунок 8.6. Пример планирования на основе справедливого раздела, в котором используются две группы с тремя процессами
(*) Наивысшим значением приоритета в системе является нулевое значение. Таким образом, нулевой приоритет выполнения в режиме задачи выше приоритета, имеющего значение, равное 1, и т.д.
. Пример присоединения существующей области команд
Рисунок 6.20. Пример присоединения существующей области команд
Чтобы разместить расширенную память, ядро выделяет новые таблицы страниц (или расширяет существующие) или отводит дополнительную физическую память в тех системах, где не поддерживается подкачка страниц по обращению. При выделении дополнительной физической памяти ядро проверяет ее наличие перед выполнением алгоритма growreg; если же памяти больше нет, ядро прибегает к другим средствам увеличения размера области (см. главу 9). Если процесс сокращает размер области, ядро просто освобождает память, отведенную под область. Во всех этих случаях ядро переопределяет размеры процесса и области и переустанавливает значения полей записи частной таблицы областей процесса и регистров управления памятью (так, чтобы они согласовались с новым отображением памяти).
Предположим, например, что область стека процесса начинается с виртуального адреса 128К и имеет размер 6 Кбайт и что ядру нужно расширить эту область на 1 Кбайт (1 страницу). Если размер процесса позволяет это делать и если виртуальные адреса в диапазоне от 134К до 135К - 1 не принадлежат какой-либо области, ранее присоединенной к процессу, ядро увеличивает размер стека. При этом ядро расширяет таблицу страниц, выделяет новую страницу памяти и инициализирует новую запись таблицы. Этот случай проиллюстрирован с помощью Рисунка 6.22.
Пример программы чтения из файла
Рисунок 5.7. Пример программы чтения из файла
| #include <fcntl.h> main() { int fd; char lilbuf[20],bigbuf[1024]; fd = open("/etc/passwd",O_RDONLY); read(fd,lilbuf,20); read(fd,bigbuf,1024); read(fd,lilbuf,20); } |
Рассмотрим программу, приведенную на Рисунке 5.7. Функция open возвращает дескриптор файла, который пользователь засылает в переменную fd и использует в последующих вызовах функции read. Выполняя функцию read, ядро проверяет, правильно ли задан параметр "дескриптор файла", а также был ли файл предварительно открыт процессом для чтения. Оно сохраняет значение адреса пользовательского буфера, количество считываемых байт и начальное смещение в байтах внутри файла (соответственно: lilbuf, 20 и 0), в пространстве процесса. В результате вычислений оказывается, что нулевое значение смещения соответствует нулевому блоку файла, и ядро возвращает точку входа в индекс, соответствующую нулевому блоку. Предполагая, что такой блок существует, ядро считывает полный блок размером 1024 байта в буфер, но по адресу lilbuf копирует только 20 байт. Оно увеличивает смещение внутри пространства процесса на 20 байт и сбрасывает счетчик данных в 0. Поскольку операция read выполнилась, ядро переустанавливает значение смещения в таблице файлов на 20, так что последующие операции чтения из файла с данным дескриптором начнутся с места, расположенного со смещением 20 байт от начала файла, а системная функция возвращает число байт, фактически прочитанных, т.е. 20.
При повторном вызове функции read ядро вновь проверяет корректность указания дескриптора и наличие соответствующего файла, открытого процессом для чтения, поскольку оно никак не может узнать, что запрос пользователя на чтение касается того же самого файла, существование которого было установлено во время последнего вызова функции. Ядро сохраняет в пространстве процесса пользовательский адрес bigbuf, количество байт, которые нужно прочитать процессу (1024), и начальное смещение в файле (20), взятое из таблицы файлов. Ядро преобразует смещение внутри файла в номер дискового блока, как раньше, и считывает блок. Если между вызовами функции read прошло непродолжительное время, есть шансы, что блок находится в буферном кеше. Однако, ядро не может полностью удовлетворить запрос пользователя на чтение за счет содержимого буфера, поскольку только 1004 байта из 1024 для данного запроса находятся в буфере. Поэтому оно копирует оставшиеся 1004 байта из буфера в пользовательскую структуру данных bigbuf и корректирует параметры в пространстве процесса таким образом, чтобы следующий шаг цикла чтения начинался в файле с байта 1024, при этом данные следует копировать по адресу байта 1004 в bigbuf в объеме 20 байт, чтобы удовлетворить запрос на чтение.
Теперь ядро переходит к началу цикла, содержащегося в алгоритме read. Оно преобразует смещение в байтах (1024) в номер логического блока (1), обращается ко второму блоку прямой адресации, номер которого хранится в индексе, и отыскивает точный дисковый блок, из которого будет производиться чтение. Ядро считывает блок из буферного кеша или с диска, если в кеше данный блок отсутствует. Наконец, оно копирует 20 байт из буфера по уточненному адресу в пользовательский процесс. Прежде чем выйти из системной функции, ядро устанавливает значение поля смещения в таблице файлов равным 1044, то есть равным значению смещения в байтах до места, куда будет производиться следующее обращение. В последнем вызове функции read из примера ядро ведет себя, как и в первом обращении к функции, за исключением того, что чтение из файла в данном случае начинается с байта 1044, так как именно это значение будет обнаружено в поле смещения той записи таблицы файлов, которая соответствует указанному дескриптору.
Пример показывает, насколько выгодно для запросов ввода-вывода работать с данными, начинающимися на границах блоков файловой системы и имеющими размер, кратный размеру блока. Это позволяет ядру избегать дополнительных итераций при выполнении цикла в алгоритме read и всех вытекающих последствий, связанных с дополнительными обращениями к индексу в поисках номера блока, который содержит данные, и с конкуренцией за использование буферного пула. Библиотека стандартных модулей ввода-вывода создана таким образом, чтобы скрыть от пользователей размеры буферов ядра; ее использование позволяет избежать потерь производительности, присущих процессам, работающим с небольшими порциями данных, из-за чего их функционирование на уровне файловой системы неэффективно (см. упражнение 5.4).
Выполняя цикл чтения, ядро определяет, является ли файл объектом чтения с продвижением: если процесс считывает последовательно два блока, ядро предполагает, что все очередные операции будут производить последовательное чтение, до тех пор, пока не будет утверждено обратное. На каждом шаге цикла ядро запоминает номер следующего логического блока в копии индекса, хранящейся в памяти, и на следующем шаге сравнивает номер текущего логического блока со значением, запомненным ранее. Если эти номера равны, ядро вычисляет номер физического блока для чтения с продвижением и сохраняет это значение в пространстве процесса для использования в алгоритме breada. Конечно же, пока процесс не считал конец блока, ядро не запустит алгоритм чтения с продвижением для следующего блока.
Обратившись к Рисунку 4.9, вспомним, что номера некоторых блоков в индексе или в блоках косвенной адресации могут иметь нулевое значение, пусть даже номера последующих блоков и ненулевые. Если процесс попытается прочитать данные из такого блока, ядро выполнит запрос, выделяя произвольный буфер в цикле read, очищая его содержимое и копируя данные из него по адресу пользователя. Этот случай не имеет ничего общего с тем случаем, когда процесс обнаруживает конец файла, говорящий о том, что после этого места запись информации никогда не производилась. Обнаружив конец файла, ядро не возвращает процессу никакой информации (см. упражнение 5.1).
Когда процесс вызывает системную функцию read, ядро блокирует индекс на время выполнения вызова. Впоследствии, этот процесс может приостановиться во время чтения из буфера, ассоциированного с данными или с блоками косвенной адресации в индексе. Если еще одному процессу дать возможность вносить изменения в файл в то время, когда первый процесс приостановлен, функция read может возвратить несогласованные данные. Например, процесс может считать из файла несколько блоков; если он приостановился во время чтения первого блока, а второй процесс собирался вести запись в другие блоки, возвращаемые данные будут содержать старые данные вперемешку с новыми. Таким образом, индекс остается заблокированным на все время выполнения вызова функции read для того, чтобы процессы могли иметь целостное видение файла, то есть видение того образа, который был у файла перед вызовом функции.
Ядро может выгружать процесс, ведущий чтение, в режим задачи на время между двумя вызовами функций и планировать запуск других процессов. Так как по окончании выполнения системной функции с индекса снимается блокировка, ничто не мешает другим процессам обращаться к файлу и изменять его содержимое. Со стороны системы было бы несправедливо держать индекс заблокированным все время от момента, когда процесс открыл файл, и до того момента, когда файл будет закрыт этим процессом, поскольку тогда один процесс будет держать все время файл открытым, тем самым не давая другим процессам возможности обратиться к файлу. Если файл имеет имя "/etc/ passwd", то есть является файлом, используемым в процессе регистрации для проверки пользовательского пароля, один пользователь может умышленно (или, возможно, неумышленно) воспрепятствовать регистрации в системе всех остальных пользователей. Чтобы предотвратить возникновение подобных проблем, ядро снимает с индекса блокировку по окончании выполнения каждого вызова системной функции, использующей индекс. Если второй процесс внесет изменения в файл между двумя вызовами функции read, производимыми первым процессом, первый процесс может прочитать непредвиденные данные, однако структуры данных ядра сохранят свою согласованность.
Предположим, к примеру, что ядро выполняет два процесса, конкурирующие между собой (Рисунок 5.8). Если допустить, что оба процесса выполняют операцию open до того, как любой из них вызывает системную функцию read или write, ядро может выполнять функции чтения и записи в любой из шести последовательностей: чтение1, чтение2, запись1, запись2, или чтение1, запись1, чтение2, запись2, или чтение1, запись1, запись2, чтение2 и т.д. Состав информации, считываемой процессом A, зависит от последовательности, в которой система выполняет функции, вызываемые двумя процессами; система не гарантирует, что данные в файле останутся такими же, какими они были после открытия файла. Использование возможности захвата файла и записей (раздел 5.4) позволяет процессу гарантировать сохранение целостности файла после его открытия.
. Пример программы, использующей
Рисунок 7.27. Пример программы, использующей функцию brk, и результаты ее контрольного прогона
| #include <signal.h> char *cp; int callno; main() { char *sbrk(); extern catcher(); signal(SIGSEGV,catcher); cp = sbrk(0); printf("original brk value %u\n",cp); for (;;) *cp++ = 1; } catcher(signo); int signo; { callno++; printf("caught sig %d %dth call at addr %u\n", signo,callno,cp); sbrk(256); signal(SIGSEGV,catcher); } |
| original brk value 140924 caught sig 11 1th call at addr 141312 caught sig 11 2th call at addr 141312 caught sig 11 3th call at addr 143360 ...(тот же адрес печатается до 10-го вызова подпрограммы sbrk) caught sig 11 10th call at addr 143360 caught sig 11 11th call at addr 145408 ...(тот же адрес печатается до 18-го вызова подпрограммы sbrk) caught sig 11 18th call at addr 145408 caught sig 11 19th call at addr 145408 - - |
Пример программы, использующей функцию times
Рисунок 8.7. Пример программы, использующей функцию times
| #include <sys/types.h> #include <sys/times.h> extern long times(); main() { int i; /* tms - имя структуры данных, состоящей из 4 элемен- тов */ struct tms pb1,pb2; long pt1,pt2; pt1 = times(&pb1); for (i = 0; i < 10; i++) if (fork() == 0) child(i); for (i = 0; i < 10; i++) wait((int*) 0); pt2 = times(&pb2); printf("процесс-родитель: реальное время %u в режиме задачи %u в режиме ядра %u потомки: в режиме задачи %u в режиме ядра %u\n", pt2 - pt1,pb2.tms_utime - pb1.tms_utime, pb2.tms_stime - pb1.tms_stime, pb2.tms_cutime - pb1.tms_cutime, pb2.tms_cstime - pb1.tms_cstime); } child(n); int n; { int i; struct tms cb1,cb2; long t1,t2; t1 = times(&cb1); for (i = 0; i < 10000; i++) ; t2 = times(&cb2); printf("потомок %d: реальное время %u в режиме задачи %u в режиме ядра %u\n",n,t2 - t1, cb2.tms_utime - cb1.tms_utime, cb2.tms_stime - cb1.tms_stime); exit(); } |
На Рисунке 8.7 приведена программа, в которой процесс-родитель создает 10 потомков, каждый из которых 10000 раз выполняет пустой цикл. Процесс-родитель обращается к функции times перед созданием потомков и после их завершения, в свою очередь потомки вызывают эту функцию перед началом цикла и после его завершения. Кто-то по наивности может подумать, что время выполнения потомков процесса в режимах задачи и ядра равно сумме соответствующих слагаемых каждого потомка, а реальное время процесса-родителя является суммой реального времени его потомков. Однако, время выполнения потомков не включает в себя время, затраченное на исполнение системных функций fork и exit, кроме того оно может быть искажено за счет обработки прерываний и переключений контекста.
С помощью системной функции alarm пользовательские процессы могут инициировать посылку сигналов тревоги ("будильника") через кратные промежутки времени. Например, программа на Рисунке 8.8 каждую минуту проверяет время доступа к файлу и, если к файлу было произведено обращение, выводит соответствующее сообщение. Для этого в цикле, с помощью функции stat, устанавливается момент последнего обращения к файлу и, если оно имело место в течение последней минуты, выводится сообщение. Затем процесс с помощью функции signal делает распоряжение принимать сигналы тревоги, с помощью функции alarm задает интервал между сигналами в 60 секунд и с помощью функции pause приостанавливает свое выполнение до момента получения сигнала. Через 60 секунд сигнал поступает, ядро подготавливает стек задачи к вызову функции обработки сигнала wakeup, функция возвращает управление на оператор, следующий за вызовом функции pause, и процесс исполняет цикл вновь.
Все перечисленные функции работы с временем протекания процесса объединяет то, что они опираются на показания системных часов (таймера). Обрабатывая прерывания по таймеру, ядро обращается к различным таймерным счетчикам и инициирует соответствующее действие.
. Пример программы, использующей подпрограмму sbrk
Рисунок 7.39. Пример программы, использующей подпрограмму sbrk
| main() { int i; char *cp; extern char *sbrk(); cp = sbrk(10); for (i = 0; i < 10; i++) *cp++ = 'a' + i; sbrk(-10); cp = sbrk(10); for (i = 0; i < 10; i++) printf("char %d = '%c'\n",i,*cp++); } |
30. Каким образом командный процессор shell узнает о том, что файл исполняемый, когда для выполнения команды создает новый процесс? Если файл исполняемый, то как узнать, создан ли он в результате трансляции исходной программы или же представляет собой набор команд языка shell? В каком порядке следует выполнять проверку указанных условий?
31. В командном языке shell символы ">>" используются для направления вывода данных в файл с указанной спецификацией, например, команда: run >>outfile открывает файл с именем "outfile" (а в случае отсутствия файла с таким именем создает его) и записывает в него данные. Напишите программу, в которой используется эта команда.
. Пример программы с использованием функции chdir
Рисунок 5.38. Пример программы с использованием функции chdir
| main(argc,argv) int argc; char *argv[]; { if (argc != 2) { printf("нужен 1 аргумент - имя каталога\n"); exit(); } if (chdir(argv[1]) == -1) printf("%s файл не является каталогом\n",argv[1]); } |
23. Что произойдет при выполнении программы, иллюстрирующей использование поименованных каналов (Рисунок 5.19), если функция mknod обнаружит, что канал с таким именем уже существует? Как этот момент реализуется ядром? Что произошло бы, если бы вместо подразумеваемых в тексте программы одного считывающего и одного записывающего процессов связь между собой через канал попытались установить несколько считывающих и записывающих процессов? Как в этом случае гарантировалась бы связь одного считывающего процесса с одним записывающим процессом?
24. Открывая поименованный канал для чтения, процесс приостанавливается до тех пор, пока еще один процесс не откроет канал для записи. Почему? Не мог бы процесс успешно пройти функцию open, продолжить работу до того момента, когда им будет предпринята попытка чтения данных из канала, и приостановиться при выполнении функции read?
25. Как бы вы реализовали алгоритм выполнения системной функции dup2 (из версии 7), вызываемой следующим образом: dup2(oldfd,newfd); где oldfd - файловый дескриптор, который дублируется дескриптором newfd? Что произошло бы, если бы дескриптор newfd уже принадлежал открытому файлу?
*26. Какие последствия имело бы решение ядра позволить двум процессам одновременно смонтировать одну и ту же файловую систему в двух точках монтирования?
27. Предположим, что один процесс меняет свой текущий каталог на каталог "/mnt/a/b/c", после чего другой процесс в каталоге "/mnt" монтирует файловую систему. Завершится ли функция mount успешно? Что произойдет, если первый процесс выполнит команду pwd? Ядро не позволит функции mount успешно завершиться, если значение счетчика ссылок в индексе каталога "/mnt" превышает 1. Прокомментируйте этот момент.
28. При исполнении алгоритма пересечения точки монтирования по имени ".." в маршруте поиска файла ядро проверяет выполнение трех условий, связанных с точкой монтирования: что номер обнаруженного индекса совпадает с номером корневого индекса, что рабочий индекс является корнем файловой системы и что имя компоненты маршрута поиска - "..". Почему необходимо проверять выполнение всех трех условий? Докажите, что проверки любых двух условий недостаточно для того, чтобы разрешить процессу пересечь точку монтирования.
29. Если пользователь монтирует файловую систему только для чтения, ядро устанавливает соответствующий флаг в суперблоке. Как ядро может воспрепятствовать выполнению операций записи в функциях write, creat, link, unlink, chown и chmod? Какого рода информацию записывают в файловую систему все перечисленные функции?
*30. Предположим, что один процесс пытается демонтировать файловую систему, в то время как другой процесс пытается создать в файловой системе новый файл. Только одна из функций umount и creat выполнится успешно. Подробно рассмотрите возникшую конкуренцию.
*31. Когда функция umount проверяет отсутствие в файловой системе активных файлов, возникает одна проблема, связанная с тем, что корневой индекс файловой системы, назначаемый при выполнении функции mount с помощью алгоритма iget, имеет счетчик ссылок с положительным значением. Как функция umount сможет убедиться в отсутствии активных файлов и отчитаться перед корнем файловой системы? Рассмотрите два случая:
функция umount освобождает корневой индекс по алгоритму iput перед проверкой активных индексов. (Как функции вернуть этот индекс обратно, если будут обнаружены активные файлы?) функция umount проверяет отсутствие активных файлов до того, как освободить корневой индекс, и разрешая корневому индексу оставаться активным. (Насколько активным может быть корневой индекс?)32. Обратите внимание на то, что при выполнении команды ls -ld количество связей с каталогом никогда не равно 1. Почему?
33. Как работает команда mkdir (создать новый каталог)? (Наводящий вопрос: какие номера по завершении выполнения команды имеют индексы для файлов "." и ".."?)
*34. Понятие "символические связи" имеет отношение к возможности указания с помощью функции link связей между файлами, принадлежащими к различным файловым системам. С файлом символической связи ассоциирован указатель нового типа; содержимым файла является имя пути поиска того файла, с которым он связан. Опишите реализацию символических связей.
*35. Что произойдет, если процесс вызовет функцию unlink("."); Каким будет текущий каталог процесса? Предполагается, что процесс обладает правами суперпользователя.
36. Разработайте системную функцию, которая усекает существующий файл до произвольных размеров, указанных в качестве аргумента, и опишите ее работу. Реализуйте системную функцию, которая позволяла бы пользователю удалять сегмент файла, расположенный между двумя адресами, заданными в виде смещений, и сжимать файл. Напишите программу, которая не вызывала бы эти функции, но обладала бы теми же функциональными возможностями.
37. Опишите все условия, при которых счетчик ссылок в индексе может превышать значение 1.
38. Затрагивая тему абстрактных обращений к файловым системам, ответьте на вопрос: следует ли файловой системе каждого типа иметь личную операцию блокирования, вызываемую из общей программы, или же достаточно общей операции блокирования?
Пример программы, создающей список
Рисунок 2.7. Пример программы, создающей список с двунаправленными указателями
| struct queue { } *bp, *bp1; bp1 - > forp = bp - > forp; bp1 - > backp = bp; bp - > forp = bp1; /* здесь рассмотрите возможность переключения контекста */ bp1 - > forp - > backp = bp1; |
. Пример программы, в которой
Рисунок 7.34. Пример программы, в которой процесс-родитель и процесс-потомок не разделяют доступ к файлу
| #include <fcntl.h> int fdrd,fdwt; char c; main(argc,argv) int argc; char *argv[]; { if (argc != 3) exit(1); fork(); if ((fdrd = open(argv[1],O_RDONLY)) == -1) exit(1); if (((fdwt = creat(argv[2],0666)) == -1) && ((fdwt = open(argv[2],O_WRONLY)) == -1)) exit(1); rdwrt(); } rdwrt() { for (;;) { if (read(fdrd,&c,1) != 1) return; write(fdwt,&c,1); } } |
3. Еще раз обратимся к программе, приведенной на Рисунке 7.5 и показывающей, как два процесса обмениваются сообщениями, используя спаренные каналы. Что произойдет, если они попытаются вести обмен сообщениями, используя один канал?
4. Возможна ли потеря информации в случае, когда процесс получает несколько сигналов прежде чем ему предоставляется возможность отреагировать на них надлежащим образом? (Рассмотрите случай, когда процесс подсчитывает количество полученных сигналов о прерывании.) Есть ли необходимость в решении этой проблемы?
5. Опишите механизм работы системной функции kill.
6. Процесс в программе на Рисунке 7.35 принимает сигналы типа "гибель потомка" и устанавливает функцию обработки сигналов в исходное состояние. Что происходит при выполнении программы?
. Пример программы, ведущей запись в область команд
Рисунок 7.22. Пример программы, ведущей запись в область команд
| #include <signal.h> main() { int i,*ip; extern f(),sigcatch(); ip = (int *)f; /* присвоение переменной ip значения ад- реса функции f */ for (i = 0; i < 20; i++) signal(i,sigcatch); *ip = 1; /* попытка затереть адрес функции f */ printf("после присвоения значения ip\n"); f(); } f() { } sigcatch(n) int n; { printf("принят сигнал %d\n",n); exit(1); } |
В качестве примера можно привести программу (Рисунок 7.22), которая присваивает переменной ip значение адреса функции f и затем делает распоряжение принимать все сигналы. Если программа скомпилирована так, что команды и данные располагаются в разных областях, процесс, исполняющий программу, при попытке записать что-то по адресу в ip встретит порожденный системой защиты отказ, поскольку область команд защищена от записи. При работе на компьютере AT&T 3B20 ядро посылает процессу сигнал SIGBUS, в других системах возможна посылка других сигналов. Процесс принимает сигнал и завершается, не дойдя до выполнения команды вывода на печать в процедуре main. Однако, если программа скомпилирована так, что команды и данные располагаются в одной области (в области данных), ядро не поймет, что процесс пытается затереть адрес функции f. Адрес f станет равным 1. Процесс исполнит команду вывода на печать в процедуре main, но когда запустит функцию f, произойдет ошибка, связанная с попыткой выполнения запрещенной команды. Ядро пошлет процессу сигнал SIGILL и процесс завершится.
Расположение команд и данных в разных областях облегчает поиск и предотвращение ошибок адресации. Тем не менее, в ранних версиях системы UNIX команды и данные разрешалось располагать в одной области, поскольку на машинах PDP размер процесса был сильно ограничен: программы имели меньший размер и существенно меньшую сегментацию, если команды и данные занимали одну и ту же область. В последних версиях системы таких строгих ограничений на размер процесса нет и в дальнейшем возможность загрузки команд и данных в одну область компиляторами не будет поддерживаться.
Второе преимущество раздельного хранения команд и данных состоит в возможности совместного использования областей процессами. Если процесс не может вести запись в область команд, команды процесса не претерпевают никаких изменений с того момента, как ядро загрузило их в область команд из командной секции исполняемого файла. Если один и тот же файл исполняется несколькими процессами, в целях экономии памяти они могут иметь одну область команд на всех. Таким образом, когда ядро при выполнении функции exec отводит область под команды процесса, оно проверяет, имеется ли возможность совместного использования процессами команд исполняемого файла, что определяется "магическим числом" в заголовке файла. Если да, то с помощью алгоритма xalloc ядро ищет существующую область с командами файла или назначает новую в случае ее отсутствия (см. Рисунок 7.23).
Исполняя алгоритм xalloc, ядро просматривает список активных областей в поисках области с командами файла, индекс которого совпадает с индексом исполняемого файла. В случае ее отсутствия ядро выделяет новую область (алгоритм allocreg), присоединяет ее к процессу (алгоритм attachreg), загружает ее в память (алгоритм loadreg) и защищает от записи (read-only). Последний шаг предполагает, что при попытке процесса записать что-либо в область команд будет получен отказ, вызванный системой защиты памяти. В случае обнаружения области с командами файла в списке активных областей осуществляется проверка ее наличия в памяти (она может быть либо загружена в память, либо выгружена из памяти) и присоединение ее к процессу. В завершение выполнения алгоритма xalloc ядро снимает с области блокировку, а позднее, следуя алгоритму detachreg при выполнении функций exit или exec, уменьшает значение счетчика областей. В традиционных реализациях системы поддерживается таблица команд, к которой ядро обращается в случаях, подобных описанному. Таким образом, совокупность областей команд можно рассматривать как новую версию этой таблицы.
Напомним, что если область при выполнении алгоритма allocreg (Раздел 6.5.2) выделяется впервые, ядро увеличивает значение счетчика ссылок на индекс, ассоциированный с областью, при этом значение счетчика ссылок нами уже было увеличено в самом начале выполнения функции exec (алгоритм namei). Поскольку ядро уменьшает значение счетчика только один раз в завершение выполнения функции exec (по алгоритму iput), значение счетчика ссылок на индекс файла, ассоциированного с разделяемой областью команд и исполняемого в настоящий момент, равно по меньшей мере 1. Поэтому когда процесс разрывает связь с файлом (функция unlink), содержимое файла остается нетронутым (не претерпевает изменений). После загрузки в память сам файл ядру становится ненужен, ядро интересует только указатель на копию индекса файла в памяти, содержащийся в таблице областей; этот указатель и будет идентифицировать файл, связанный с областью. Если бы значение счетчика ссылок стало равным 0, ядро могло бы передать копию индекса в памяти другому файлу, тем самым делая сомнительным значение указателя на индекс в записи таблицы областей: если бы пользователю пришлось исполнить новый файл, используя функцию exec, ядро по ошибке связало бы его с областью команд старого файла. Эта проблема устраняется благодаря тому, что ядро при выполнении алгоритма allocreg увеличивает значение счетчика ссылок на индекс, предупреждая тем самым переназначение индекса в памяти другому файлу. Когда процесс во время выполнения функций exit или exec отсоединяет область команд, ядро уменьшает значение счетчика ссылок на индекс (по алгоритму freereg), если только связь индекса с областью не помечена как "неотъемлемая".
. Пример результатов выполнения
Рисунок 8.13. Пример результатов выполнения программы, использующей системную функцию profil
| смещение до начала 212 до конца 440 длина текста 57 f 416 g 428 fdiff 204 gdiff 216 buf[46] = 50 buf[48] = 8585216 buf[49] = 151 buf[51] = 12189799 buf[53] = 65 buf[54] = 10682455 buf[56] = 67 |
. Пример "созревания" страницы
Рисунок 9.19. Пример "созревания" страницы
Когда "сборщик" страниц принимает решение выгрузить страницу из памяти, он проверяет возможность нахождения копии этой страницы на устройстве выгрузки. При этом могут иметь место три случая:
Если на устройстве выгрузки есть копия страницы, ядро "планирует" выгрузку страницы: "сборщик" страниц помещает ее в список выгруженных страниц и переходит дальше; выгрузка считается логически завершившейся. Когда число страниц в списке превысит ограничение (определяемое возможностями дискового контроллера), ядро переписывает страницы на устройство выгрузки. Если на устройстве выгрузки уже есть копия страницы и ее содержимое ничем не отличается от содержимого страницы в памяти (бит модификации в записи таблицы страниц не установлен), ядро сбрасывает в ноль бит доступности (в той же записи таблицы), уменьшает значение счетчика ссылок в таблице pfdata и помещает запись в список свободных страниц для будущего переназначения. Если на устройстве выгрузки есть копия страницы, но процесс изменил содержимое ее оригинала в памяти, ядро планирует выгрузку страницы и освобождает занимаемое ее копией место на устройстве выгрузки."Сборщик" страниц копирует страницу на устройство выгрузки, если имеют место случаи 1 и 3.
Чтобы проиллюстрировать различия между последними двумя случаями, предположим, что страница находится на устройстве выгрузки и загружается в основную память после того, как процесс столкнулся с отсутствием необходимых данных. Допустим, ядро не стало автоматически удалять копию страницы на диске. В конце концов, "сборщик" страниц вновь примет решение выгрузить страницу. Если с момента загрузки в память в страницу не производилась запись данных, содержимое страницы в памяти идентично содержимому ее дисковой копии и в переписи страницы на устройство выгрузки необходимости не возникает. Однако, если процесс успел что-то записать на страницу, старый и новый ее варианты будут различаться, поэтому ядру следует переписать страницу на устройство выгрузки, освободив предварительно место, занимаемое на устройстве старым вариантом. Ядро не сразу использует освобожденное пространство на устройстве выгрузки, поэтому оно имеет возможность поддерживать непрерывное размещение занятых участков, что повышает эффективность использования области выгрузки.
"Сборщик" страниц заполняет список выгруженных страниц, которые в принципе могут принадлежать разным областям, и по заполнении списка откачивает их на устройство выгрузки. Нет необходимости в том, чтобы все страницы одного процесса непременно выгружались: к примеру, некоторые из страниц, возможно, недостаточно "созрели" для этого. В этом видится различие со стратегией выгрузки процессов, согласно которой из памяти выгружаются все страницы одного процесса, вместе с тем метод переписи данных на устройство выгрузки идентичен тому методу, который описан для системы с замещением процессов в разделе 9.1.2. Если на устройстве выгрузки недостаточно непрерывного пространства, ядро выгружает страницы по отдельности (по одной странице за операцию), что в конечном итоге обходится недешево. В системе с замещением страниц фрагментация на устройстве выгрузки выше, чем в системе с замещением процессов, поскольку ядро выгружает блоки страниц, но загружает в память каждую страницу в отдельности.
Когда ядро переписывает страницу на устройство выгрузки, оно сбрасывает бит доступности в соответствующей записи таблицы страниц и уменьшает значение счетчика ссылок в соответствующей записи таблицы pfdata. Если значение счетчика становится равным 0, запись таблицы pfdata помещается в конец списка свободных страниц и запоминается для последующего переназначения. Если значение счетчика отлично от 0, это означает, что страница (в результате выполнения функции fork) используется совместно несколькими процессами, но ядро все равно выгружает ее. Наконец, ядро выделяет пространство на устройстве выгрузки, сохраняет его адрес в дескрипторе дискового блока и увеличивает значение счетчика ссылок на страницу в таблице использования области подкачки. Если в то время, пока страница находится в списке свободных страниц, процесс обнаружил ее отсутствие, получив соответствующую ошибку, ядро может восстановить ее в памяти, не обращаясь к устройству выгрузки. Однако, страница все равно будет считаться выгруженной, если она попала в список "сборщика" страниц.
Предположим, к примеру, что "сборщик" страниц выгружает 30, 40, 50 и 20 страниц из процессов A, B, C и D, соответственно, и что за одну операцию выгрузки на дисковое устройство откачиваются 64 страницы. На Рисунке 9.20 показана последовательность имеющих при этом место операций выгрузки при условии, что "сборщик" страниц осуществляет просмотр страниц процессов в очередности: A, B, C, D. "Сборщик" выделяет на устройстве выгрузки место для 64 страниц и выгружает 30 страниц процесса A и 34 страницы процесса B. Затем он выделяет место для следующих 64 страниц и выгружает оставшиеся 6 страниц процесса B, 50 страниц процесса C и 8 страниц процесса D. Выделенные для размещения страниц за две операции участки области выгрузки могут быть и несмежными. "Сборщик" сохраняет оставшиеся 12 страниц процесса D в списке выгружаемых страниц, но не выгружает их до тех пор, пока список не будет заполнен до конца. Как только у процессов возникает потребность в подкачке страниц с устройства выгрузки или если страницы больше не нужны использующим их процессам (процессы завершились), в области выгрузки освобождается место.
Чтобы подвести итог, выделим в процессе откачки страницы из памяти две фазы. На первой фазе "сборщик" страниц ищет страницы, подходящие для выгрузки, и помещает их номера в список выгружаемых страниц. На второй фазе ядро копирует страницу на устройство выгрузки (если на нем имеется место), сбрасывает в ноль бит допустимости в соответствующей записи таблицы страниц, уменьшает значение счетчика ссылок в соответствующей записи таблицы pfdata и если оно становится равным 0, помещает эту запись в конец списка свободных
страниц. Содержимое физической страницы в памяти не изменяется до тех пор,
пока страница не будет переназначена другому процессу.
. Пример указания причины появления
Рисунок 7.18. Пример указания причины появления сигнала "гибель потомков"
| #include <signal.h> main(argc,argv) { char buf[256]; if (argc != 1) signal(SIGCLD,SIG_IGN); /* игнорировать гибель потомков */ while (read(0,buf,256)) if (fork() == 0) { /* здесь процесс-потомок обычно выполняет какие-то операции над буфером (buf) */ exit(0); } } |
Пример векторов прерывания
Рисунок 6.9. Пример векторов прерывания
| Номер прерывания Программа обработки прерывания 0 clockintr 1 diskintr 2 ttyintr 3 devintr 4 softintr 5 otherintr |
Вызов программы обработки прерывания. Стек ядра для нового контекстного уровня, если рассуждать логически, должен отличаться от стека ядра предыдущего контекстного уровня. В некоторых разработках стек ядра текущего процесса используется для хранения элементов, соответствующих программам обработки прерываний, в других разработках эти элементы хранятся в глобальном стеке прерываний, благодаря чему обеспечивается возврат из программы без переключения контекста.
Программа завершает свою работу и возвращает управление ядру. Ядро исполняет набор машинных команд по сохранению регистрового контекста и стека ядра предыдущего контекстного уровня в том виде, который они имели в момент прерывания, после чего возобновляет выполнение восстановленного контекстного уровня. Программа обработки прерываний может повлиять на поведение процесса, поскольку она может внести изменения в глобальные структуры данных ядра и возобновить выполнение приостановленных процессов. Однако, обычно процесс продолжает выполняться так, как если бы прерывание никогда не происходило.
. Пример выполнения программы setuid
Рисунок 7.25. Пример выполнения программы setuid
| #include <fcntl.h> main() { int uid,euid,fdmjb,fdmaury; uid = getuid(); /* получить реальный UID */ euid = geteuid(); /* получить исполнительный UID */ printf("uid %d euid %d\n",uid,euid); fdmjb = open("mjb",O_RDONLY); fdmaury = open("maury",O_RDONLY); printf("fdmjb %d fdmaury %d\n",fdmjb,fdmaury); setuid(uid); printf("after setuid(%d): uid %d euid %d\n",uid, getuid(),geteuid()); fdmjb = open("mjb",O_RDONLY); fdmaury = open("maury",O_RDONLY); printf("fdmjb %d fdmaury %d\n",fdmjb,fdmaury); setuid(uid); printf("after setuid(%d): uid %d euid %d\n",euid, getuid(),geteuid()); } |
Во время выполнения программы пользователем "maury" на печать выводится следующая информация:
uid 8319 euid 8319 fdmjb -1 fdmaury 3 after setuid(8319): uid 8319 euid 8319 fdmjb -1 fdmaury 4 after setuid(8319): uid 8319 euid 8319Реальный и исполнительный коды идентификации пользователя во время выполнения программы остаются равны 8319: процесс может открыть файл "maury", но не может открыть файл "mjb". Исполнительный код, хранящийся в пространстве процесса, занесен туда в результате последнего исполнения функции или программы setuid; только его значением определяются права доступа процесса к файлу. С помощью функции setuid исполнительному коду может быть присвоено значение сохраненного кода (из таблицы процессов), т.е. то значение, которое исполнительный код имел в самом начале.
Примером программы, использующей вызов системной функции setuid, может служить программа регистрации пользователей в системе (login). Параметром функции setuid при этом является код идентификации суперпользователя, таким образом, программа login исполняется под кодом суперпользователя из корня системы. Она запрашивает у пользователя различную информацию, например, имя и пароль, и если эта информация принимается системой, программа запускает функцию setuid, чтобы установить значения реального и исполнительного кодов идентификации в соответствии с информацией, поступившей от пользователя (при этом используются данные файла "/etc/passwd"). В заключение программа login инициирует запуск командного процессора shell, который будет исполняться под указанными пользовательскими кодами идентификации.
Примером setuid-программы является программа, реализующая команду mkdir. В разделе 5.8 уже говорилось о том, что создать каталог может только процесс, выполняющийся под управлением суперпользователя. Для того, чтобы предоставить возможность создания каталогов простым пользователям, команда mkdir была выполнена в виде setuid-программы, принадлежащей корню системы и имеющей права суперпользователя. На время исполнения команды mkdir процесс получает права суперпользователя, создает каталог, используя функцию mknod, и предоставляет права собственности и доступа к каталогу истинному пользователю процесса.
Пример заполнения таблиц ключей
Рисунок 10.2. Пример заполнения таблиц ключей устройств ввода-вывода блоками и символами
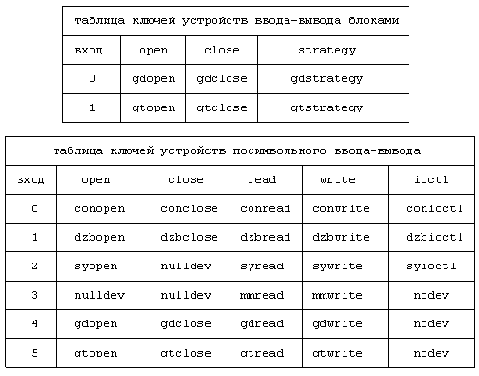
Драйвер устройства интерпретирует параметры вызова системной функции в отношении устройства. Драйвер поддерживает структуры данных, описывающие состояние каждой контролируемой единицы данного типа устройства; функции драйвера и программы обработки прерываний реализуются в соответствии с состоянием драйвера и с тем, какое действие выполняется в этот момент (например, данные вводятся или выводятся). Теперь рассмотрим каждый интерфейс более подробно.
. Примеры прерываний
Рисунок 6.11. Примеры прерываний
Обрабатывая внутреннее прерывание операционной системы, ядро по номеру системной функции ведет в таблице поиск адреса соответствующей процедуры ядра, то есть точки входа системной функции, и количества передаваемых функции параметров (Рисунок 6.12). Ядро вычисляет адрес (пользовательский) первого параметра функции, прибавляя (или вычитая, в зависимости от направления увеличения стека) смещение к указателю вершины стека задачи (аналогично для всех параметров функции). Наконец, ядро копирует параметры задачи в пространство процесса и вызывает соответствующую процедуру, которая выполняет системную функцию. После исполнения процедуры ядро выясняет, не было ли ошибки. Если ошибка была, ядро делает соответствующие установки в сохраненном регистровом контексте задачи, при этом в регистре PS обычно устанавливается бит переноса, а в нулевой регистр заносится номер ошибки. Если при выполнении системной функции не было ошибок, ядро очищает в регистре PS бит переноса и заносит возвращаемые функцией значения в регистры 0 и 1 в сохраненном регистровом контексте задачи. Когда ядро возвращается после обработки внутреннего прерывания операционной системы в режим задачи, оно попадает в следующую библиотечную инструкцию после прерывания. Библиотечная функция интерпретирует возвращенные ядром значения и передает их программе пользователя.
. Присоединение процессом одной
Рисунок 11.11. Присоединение процессом одной и той же области разделяемой памяти дважды
| #include <sys/types.h> #include <sys/ipc.h> #include <sys/shm.h> #define SHMKEY 75 #define K 1024 int shmid; main() { int i, *pint; char *addr1, *addr2; extern char *shmat(); extern cleanup(); for (i = 0; i < 20; i++) signal(i,cleanup); shmid = shmget(SHMKEY,128*K,0777IPC_CREAT); addr1 = shmat(shmid,0,0); addr2 = shmat(shmid,0,0); printf("addr1 Ox%x addr2 Ox%x\n",addr1,addr2); pint = (int *) addr1; for (i = 0; i < 256, i++) *pint++ = i; pint = (int *) addr1; *pint = 256; pint = (int *) addr2; for (i = 0; i < 256, i++) printf("index %d\tvalue %d\n",i,*pint++); pause(); } cleanup() { shmctl(shmid,IPC_RMID,0); exit(); } |
. Процесс-клиент в домене "UNIX system"
Рисунок 11.21. Процесс-клиент в домене "UNIX system"
| #include <sys/types.h> #include <sys/socket.h> main() { int sd,ns; char buf[256]; struct sockaddr sockaddr; int fromlen; sd = socket(AF_UNIX,SOCK_STREAM,0); /* имя в запросе на подключение не может включать /* пустой символ */ if (connect(sd,"sockname",sizeof("sockname") - 1) == -1) exit(); write(sd,"hi guy",6); } |
На Рисунке 11.21 показан пример процесса-клиента, ведущего общение с сервером. Клиент создает гнездо в том же домене, что и сервер, и посылает запрос на подключение к гнезду с именем sockname. В результате подключения процесс-клиент получает виртуальный канал связи с сервером. В рассматриваемом примере клиент передает одно сообщение и завершается.
Если сервер обслуживает процессы в сети, указание о том, что гнездо принадлежит домену "Internet", можно сделать следующим образом:
socket(AF_INET,SOCK_STREAM,0);и связаться с сетевым адресом, полученным от сервера. В системе BSD имеются библиотечные функции, выполняющие эти действия. Второй параметр вызываемой клиентом функции connect содержит адресную информацию, необходимую для идентификации машины в сети (или адреса маршрутов посылки сообщений через промежуточные машины), а также дополнительную информацию, идентифицирующую приемное гнездо машины-адресата. Если серверу нужно одновременно следить за состоянием сети и выполнением локальных процессов, он использует два гнезда и с помощью функции select определяет, с каким клиентом устанавливается связь в данный момент.
. Процесс-сервер в домене "UNIX system"
Рисунок 11.20. Процесс-сервер в домене "UNIX system"
| #include <sys/types.h> #include <sys/socket.h> main() { int sd,ns; char buf[256]; struct sockaddr sockaddr; int fromlen; sd = socket(AF_UNIX,SOCK_STREAM,0); /* имя гнезда - не может включать пустой символ */ bind(sd,"sockname",sizeof("sockname") - 1); listen(sd,1); for (;;) { ns = accept(sd,&sockaddr,&fromlen); if (fork() == 0) { /* потомок */ close(sd); read(ns,buf,sizeof(buf)); printf("сервер читает '%s'\n",buf); exit(); } close(ns); } } |
Процессы и области
Рисунок 6.2. Процессы и области
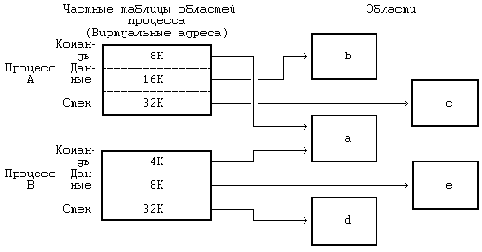
B читает ячейку с адресом 4К, то они читают одну и ту же ячейку в области 'a'. Область данных и область стека у каждого процесса свои.
Область является понятием, не зависящим от способа реализации управления памятью в операционной системе. Управление памятью представляет собой совокупность действий, выполняемых ядром с целью повышения эффективности совместного использования оперативной памяти процессами. Примерами способов управления памятью могут служить рассматриваемые в главе 9 замещение страниц памяти и подкачка по обращению. Понятие области также не зависит и от собственно распределения памяти: например, от того, делится ли память на страницы или на сегменты. С тем, чтобы заложить фундамент для перехода к описанию алгоритмов подкачки по обращению (глава 9), все приводимые здесь рассуждения относятся, в первую очередь, к организации памяти, базирующейся на страницах, однако это не предполагает, что система управления памятью основывается на указанных алгоритмах.
Процессы и режимы их выполнения
Рисунок 1.5. Процессы и режимы их выполнения
Проще говоря, любое взаимодействие с аппаратурой описывается в терминах режима ядра и режима задачи и протекает одинаково для всех пользовательских программ, выполняющихся в этих режимах. Операционная система хранит внутренние записи о каждом процессе, выполняющемся в системе. На Рисунке 1.5 показано это разделение: ядро делит процессы A, B, C и D, расположенные вдоль горизонтальной оси, аппаратные средства вводят различия между режимами выполнения, расположенными по вертикали.
Несмотря на то, что система функционирует в одном из двух режимов, ядро действует от имени пользовательского процесса. Ядро не является какой-то особой совокупностью процессов, выполняющихся параллельно с пользовательскими, оно само выступает составной частью любого пользовательского процесса. Сделанный вывод будет скорее относиться к "ядру", распределяющему ресурсы, или к "ядру", производящему различные операции, и это будет означать, что процесс, выполняемый в режиме ядра, распределяет ресурсы и производит соответствующие операции. Например, командный процессор shell считывает вводной поток с терминала с помощью запроса к операционной системе. Ядро операционной системы, выступая от имени процессора shell, управляет функционированием терминала и передает вводимые символы процессору shell. Shell переходит в режим задачи, анализирует поток символов, введенных пользователем и выполняет заданную последовательность действий, которые могут потребовать выполнения и других системных операций.
. Процессы, приостановленные до
Рисунок 6.30. Процессы, приостановленные до наступления событий, и отображение событий на конкретные адреса
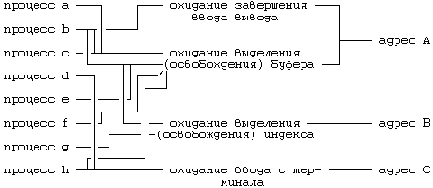
Еще одно противоречие связано с тем, что на один и тот же адрес могут отображаться несколько событий. На Рисунке 6.30, например, события "освобождение буфера" и "завершение ввода-вывода" отображаются на адрес буфера ("адрес A"). Когда ввод-вывод в буфер завершается, ядро возобновляет выполнение всех процессов, приостановленных в ожидании наступления как того, так и другого события. Поскольку процесс, ожидающий завершения ввода-вывода, удерживает буфер заблокированным, другие процессы, которые ждали освобождения буфера, вновь приостановятся, ибо буфер все еще занят. Функционирование системы было бы более эффективным, если бы отображение событий на адреса было однозначным. Однако на практике такого рода противоречие на производительности системы не отражается, поскольку отображение на один адрес более одного события имеет место довольно редко, а также поскольку выполняющийся процесс обычно освобождает заблокированные ресурсы до того, как начнут выполняться другие процессы. Стилистически, тем не менее, механизм функционирования ядра стал бы более понятен, если бы отображение было однозначным.
Процессы, ведущие чтение и запись файла
Рисунок 5.8. Процессы, ведущие чтение и запись файла
| #include <fcntl.h> /* процесс A */ main() { int fd; char buf[512]; fd = open("/etc/passwd",O_RDONLY); read(fd,buf,sizeof(buf)); /* чтение1 */ read(fd,buf,sizeof(buf)); /* чтение2 */ | } /* процесс B */ main() { int fd,i; char buf[512]; for (i = 0; i < sizeof(buf); i++) buf[i] = 'a'; fd = open("/etc/passwd",O_WRONLY); write(fd,buf,sizeof(buf)); /* запись1 */ write(fd,buf,sizeof(buf)); /* запись2 */ } |
Наконец, программа на Рисунке 5.9 показывает, как процесс может открывать файл более одного раза и читать из него, используя разные файловые дескрипторы. Ядро работает со значениями смещений в таблице файлов, ассоциированными с двумя файловыми дескрипторами, независимо, и поэтому массивы buf1 и buf2 будут по завершении выполнения процесса идентичны друг другу при условии, что ни один процесс в это время не производил запись в файл "/etc/passwd".
. Продвижение модуля к потоку
Рисунок 10.22. Продвижение модуля к потоку
Процессы могут "продвигать" модули к открытому потоку, используя вызов системной функции ioctl. Ядро помещает выдвинутый модуль сразу под заголовком потока и связывает указатели очереди таким образом, чтобы сохранить двунаправленную структуру списка. Модули, расположенные в потоке ниже, не беспокоятся о том, связаны ли они с заголовком потока или же с выдвинутым модулем: интерфейсом выступает процедура "вывода" следующей очереди в потоке; а следующая очередь принадлежит только что выдвинутому модулю. Например, процесс может выдвинуть модуль строкового интерфейса в поток терминального драйвера с целью обработки символов стирания и удаления (Рисунок 10.22); модуль строкового интерфейса не имеет тех же составляющих, что и строковые интерфейсы, рассмотренные в разделе 10.3, но выполняет те же функции. Без модуля строкового интерфейса терминальный драйвер не обработает вводные символы и они поступят в заголовок потока в неизмененном виде. Сегмент программы, открывающий терминал и выдвигающий строковый интерфейс, может выглядеть следующим образом:
fd = open("/dev/ttyxy",O_RDWR); ioctl(fd,PUSH,TTYLD);где PUSH - имя команды, а TTYLD - число, идентифицирующее модуль строкового интерфейса. Не существует ограничения на количество модулей, могущих быть выдвинутыми в поток. Процесс может выталкивать модули из потока в порядке поступления, "первым пришел - первым вышел", используя еще один вызов системной функции ioctl
ioctl(fd,POP,0);При том, что модуль строкового интерфейса выполняет обычные функции по управлению терминалом, соответствующее ему устройство может быть средством сетевой связи вместо того, чтобы обеспечивать связь с одним-единственным терминалом. Модуль строкового интерфейса работает одинаково, независимо от того, какого типа модуль расположен ниже него. Этот пример наглядно демонстрирует повышение гибкости вследствие соединения модулей ядра.
Программа debug (трассирующий процесс)
Рисунок 11.3. Программа debug (трассирующий процесс)
| #define TR_SETUP 0 #define TR_WRITE 5 #define TR_RESUME 7 int addr; main(argc,argv) int argc; char *argv[]; { int i,pid; sscanf(argv[1],"%x",&addr); if ((pid = fork() == 0) { ptrace(TR_SETUP,0,0,0); execl("trace","trace",0); exit(); } for (i = 0; i < 32, i++) { wait((int *) 0); /* записать значение i в пространство процесса с * идентификатором pid по адресу, содержащемуся в * переменной addr */ if (ptrace(TR_WRITE,pid,addr,i) == -1) exit(); addr += sizeof(int); } /* трассируемый процесс возобновляет выполнение */ ptrace(TR_RESUME,pid,1,0); } |
Рассмотрим две программы, приведенные на Рисунках 11.2 и 11.3 и именуемые trace и debug, соответственно. При запуске программы trace с терминала массив data будет содержать нулевые значения; процесс выводит адрес массива и завершает работу. При запуске программы debug с передачей ей в качестве параметра значения, выведенного программой trace, происходит следующее: программа запоминает значение параметра в переменной addr, создает новый процесс, с помощью функции ptrace подготавливающий себя к трассировке, и запускает программу trace. На выходе из функции exec ядро посылает процессу-потомку (назовем его тоже trace) сигнал SIGTRAP (сигнал прерывания), процесс trace переходит в состояние трассировки, ожидая поступления команды от программы debug. Если процесс, реализующий программу debug, находился в состоянии приостанова, связанного с выполнением функции wait, он "пробуждается", обнаруживает наличие порожденного трассируемого процесса и выходит из функции wait. Затем процесс debug вызывает функцию ptrace, записывает значение переменной цикла i в пространство данных процесса trace по адресу, содержащемуся в переменной addr, и увеличивает значение переменной addr; в программе trace переменная addr хранит адрес точки входа в массив data. Последнее обращение процесса debug к функции ptrace вызывает запуск программы trace, и в этот момент массив data содержит значения от 0 до 31. Отладчики, подобные sdb, имеют доступ к таблице идентификаторов трассируемого процесса, из которой они получают информацию об адресах данных, используемых в качестве параметров функции ptrace.
Использование функции ptrace для трассировки процессов является обычным делом, но оно имеет ряд недостатков.
Для того, чтобы произвести передачу порции данных длиною в слово между процессом-отладчиком и трассируемым процессом, ядро должно выполнить четыре переключения контекста: оно переключает контекст во время вызова отладчиком функции ptrace, загружает и выгружает контекст трассируемого процесса и переключает контекст вновь на процесс-отладчик по получении ответа от трассируемого процесса. Все вышеуказанное необходимо, поскольку у отладчика нет иного способа получить доступ к виртуальному адресному пространству трассируемого процесса, отсюда замедленность протекания процедуры трассировки. Процесс-отладчик может вести одновременную трассировку нескольких процессов-потомков, хотя на практике эта возможность используется редко. Если быть более критичным, следует отметить, что отладчик может трассировать только своих ближайших потомков: если трассируемый процесс-потомок вызовет функцию fork, отладчик не будет иметь контроля над порождаемым, внучатым для него, процессом, что является серьезным препятствием в отладке многоуровневых программ. Если трассируемый процесс вызывает функцию exec, запускаемые образы задач тоже подвергаются трассировке под управлением ранее вызванной функции ptrace, однако отладчик может не знать имени исполняемого образа, что затрудняет проведение символьной отладки. Отладчик не может вести трассировку уже выполняющегося процесса, если отлаживаемый процесс не вызвал предварительно функцию ptrace, дав тем самым ядру свое согласие на трассировку. Это неудобно, так как в указанном случае выполняющийся процесс придется удалить из системы и перезапустить в режиме трассировки. Не разрешается трассировать setuid-программы, поскольку это может привести к нарушению защиты данных (ибо в результате выполнения функции ptrace в их адресное пространство производилась бы запись данных) и к выполнению недопустимых действий. Предположим, например, что setuid-программа запускает файл с именем "privatefile". Умелый пользователь с помощью функции ptrace мог бы заменить имя файла на "/bin/sh", запустив на выполнение командный процессор shell (и все программы, исполняемые shell'ом), не имея на то соответствующих полномочий. Функция exec игнорирует бит setuid, если процесс подвергается трассировке, тем самым адресное пространство setuid-программ защищается от пользовательской записи.Киллиан [Killian 84] описывает другую схему трассировки процессов, основанную на переключении файловых систем (см. главу 5). Администратор монтирует файловую систему под именем "/proc"; пользователи идентифицируют процессы с помощью кодов идентификации и трактуют их как файлы, принадлежащие каталогу "/proc". Ядро дает разрешение на открытие файлов, исходя из кода идентификации пользователя процесса и кода идентификации группы. Пользователи могут обращаться к адресному пространству процесса путем чтения (read) файла и устанавливать точки прерываний путем записи (write) в файл. Функция stat сообщает различную статистическую информацию, касающуюся процесса. В данном подходе устранены три недостатка, присущие функции ptrace. Во-первых, эта схема работает быстрее, поскольку процесс-отладчик за одно обращение к указанным системным функциям может передавать больше информации, чем при работе с ptrace. Во-вторых, отладчик здесь может вести трассировку совершенно произвольных процессов, а не только своих потомков. Наконец, трассируемый процесс не должен предпринимать предварительно никаких действий по подготовке к трассировке; отладчик может трассировать и существующие процессы. Возможность вести отладку setuid-программ, предоставляемая только суперпользователю, реализуется как составная часть традиционного механизма защиты файлов.
. Программа, демонстрирующая возникновение
Рисунок 7.12. Программа, демонстрирующая возникновение соперничества между процессами в ходе обработки сигналов
| #include <signal.h> sigcatcher() { printf("PID %d принял сигнал\n",getpid()); /* печать PID */ signal(SIGINT,sigcatcher); } main() { int ppid; signal(SIGINT,sigcatcher); if (fork() == 0) { /* дать процессам время для выполнения установок */ sleep(5); /* библиотечная функция приостанова на 5 секунд */ ppid = getppid(); /* получить идентификатор родите- ля */ for (;;) if (kill(ppid,SIGINT) == -1) exit(); } /* чем ниже приоритет, тем выше шансы возникновения кон- куренции */ nice(10); for (;;) ; } |
В программе описывается именно такое поведение процессов, поскольку вызов родительским процессом функции nice приводит к тому, что ядро будет чаще запускать на выполнение порожденный процесс.
По словам Ричи (эти сведения были получены в частной беседе), сигналы были задуманы как события, которые могут быть как фатальными, так и проходящими незаметно, которые не всегда обрабатываются, поэтому в ранних версиях системы конкуренция процессов, связанная с посылкой сигналов, не фиксировалась. Тем не менее, она представляет серьезную проблему в тех программах, где осуществляется прием сигналов. Эта проблема была бы устранена, если бы поле описания сигнала не очищалось по его получении. Однако, такое решение породило бы новую проблему: если поступающий сигнал принимается, а поле очищено, вложенные обращения к функции обработки сигнала могут переполнить стек. С другой стороны, ядро могло бы сбросить значение функции обработки сигнала, тем самым делая распоряжение игнорировать сигналы данного типа до тех пор, пока пользователь вновь не укажет, что нужно делать по получении подобных сигналов. Такое решение предполагает потерю информации, так как процесс не в состоянии узнать, сколько сигналов им было получено. Однако, информации при этом теряется не больше, чем в том случае, когда процесс получает большое количество сигналов одного типа до того, как получает возможность их обработать. В системе BSD, наконец, процесс имеет возможность блокировать получение сигналов и снимать блокировку при новом обращении к системной функции; когда процесс снимает блокировку сигналов, ядро посылает процессу все сигналы, отложенные (повисшие) с момента установки блокировки. Когда процесс получает сигнал, ядро автоматически блокирует получение следующего сигнала до тех пор, пока функция обработки сигнала не закончит работу. В этих действиях ядра наблюдается аналогия с тем, как ядро реагирует на аппаратные прерывания: оно блокирует появление новых прерываний на время обработки предыдущих.
Второе несоответствие в обработке сигналов связано с приемом сигналов, поступающих во время исполнения системной функции, когда процесс приостановлен с допускающим прерывания приоритетом. Сигнал побуждает процесс выйти из приостанова (с помощью longjump), вернуться в режим задачи и вызвать функцию обработки сигнала. Когда функция обработки сигнала завершает работу, происходит то, что процесс выходит из системной функции с ошибкой, сообщающей о прерывании ее выполнения. Узнав об ошибке, пользователь запускает системную функцию повторно, однако более удобно было бы, если бы это действие автоматически выполнялось ядром, как в системе BSD.
Третье несоответствие проявляется в том случае, когда процесс игнорирует поступивший сигнал. Если сигнал поступает в то время, когда процесс находится в состоянии приостанова с допускающим прерывания приоритетом, процесс возобновляется, но не выполняет longjump. Другими словами, ядро узнает о том, что процесс проигнорировал поступивший сигнал только после возобновления его выполнения. Логичнее было бы оставить процесс в состоянии приостанова. Однако, в момент посылки сигнала к пространству процесса, в котором ядро хранит адрес функции обработки сигнала, может отсутствовать доступ. Эта проблема может быть решена путем запоминания адреса функции обработки сигнала в записи таблицы процессов, обращаясь к которой, ядро получало бы возможность решать вопрос о необходимости возобновления процесса по получении сигнала. С другой стороны, процесс может немедленно вернуться в состояние приостанова (по алгоритму sleep), если обнаружит, что в его возобновлении не было необходимости. Однако, пользовательские процессы не имеют возможности осознавать собственное возобновление, поскольку ядро располагает точку входа в алгоритм sleep внутри цикла с условием продолжения (см. главу 2), переводя процесс вновь в состояние приостанова, если ожидаемое процессом событие в действительности не имело места.
Ко всему сказанному выше следует добавить, что ядро обрабатывает сигналы типа "гибель потомка" не так, как другие сигналы. В частности, когда процесс узнает о получении сигнала "гибель потомка", он выключает индикацию сигнала в соответствующем поле записи таблицы процессов и по умолчанию действует так, словно никакого сигнала и не поступало. Назначение сигнала "гибель потомка" состоит в возобновлении выполнения процесса, приостановленного с допускающим прерывания приоритетом. Если процесс принимает такой сигнал, он, как и во всех остальных случаях, запускает функцию обработки сигнала. Действия, предпринимаемые ядром в том случае, когда процесс игнорирует поступивший сигнал этого типа, будут описаны в разделе 7.4. Наконец, когда процесс вызвал функцию signal с параметром "гибель потомка" (death of child), ядро посылает ему соответствующий сигнал, если он имеет потомков, прекративших существование. В разделе 7.4 на этом моменте мы остановимся более подробно.
Программа, использующая системную функцию alarm
Рисунок 8.8. Программа, использующая системную функцию alarm
| #include <sys/types.h> #include <sys/stat.h> #include <sys/signal.h> main(argc,argv) int argc; char *argv[]; { extern unsigned alarm(); extern wakeup(); struct stat statbuf; time_t axtime; if (argc != 2) { printf("только 1 аргумент\n"); exit(); } axtime = (time_t) 0; for (;;) { /* получение значения времени доступа к файлу */ if (stat(argv[1],&statbuf) == -1) { printf("файла с именем %s нет\n",argv[1]); exit(); } if (axtime != statbuf.st_atime) { printf("к файлу %s было обращение\n",argv[1]); axtime = statbuf.st_atime; } signal(SIGALRM,wakeup); /* подготовка к приему сигнала */ alarm(60); pause(); /* приостанов до получения сигнала */ } } wakeup() { } |
Программа копирования файла
Рисунок 1.3. Программа копирования файла
| #include <fcntl.h> char buffer[2048]; int version = 1; /* будет объяснено в главе 2 */ main(argc,argv) int argc; char *argv[]; { int fdold,fdnew; if (argc != 3) { printf("need 2 arguments for copy program\n); exit(1); } fdold = open(argv[1],O_RDONLY); /* открыть исходный файл только для чтения */ if (fdold == -1) { printf("cannot open file %s\n",argv[1]); exit(1); } fdnew = creat(argv[2],0666); /* создать новый файл с разрешением чтения и записи для всех поль- зователей */ if (fdnew == -1) { printf("cannot create file %s\n",argv[2]); exit(1); } copy(fdold,fdnew); exit(0); } copy(old,new) int old,new; { int count; while ((count = read(old,buffer,sizeof(buffer))) > 0) write(new,buffer,count); } |
. Программа на языке Си, иллюстрирующая
Рисунок 5.21. Программа на языке Си, иллюстрирующая использование функции dup
| #include <fcntl.h> main() { int i,j; char buf1[512],buf2[512]; i = open("/etc/passwd",O_RDONLY); j = dup(i); read(i,buf1,sizeof(buf1)); read(j,buf2,sizeof(buf2)); close(i); read(j,buf2,sizeof(buf2)); } |
Программа порождения нового процесса
Рисунок 1.4. Программа порождения нового процесса, выполняющего копирование файлов
| main(argc,argv) int argc; char *argv[]; { /* предусмотрено 2 аргумента: исходный файл и новый файл */ if (fork() == 0) execl("copy","copy",argv[1],argv[2],0); wait((int *)0) printf("copy done\n"); } |
Вообще использование обращений к операционной системе дает возможность пользователю создавать программы, выполняющие сложные действия, и как следствие, ядро операционной системы UNIX не включает в себя многие функции, являющиеся частью "ядра" в других системах. Такие функции, и среди них компиляторы и редакторы, в системе UNIX являются программами пользовательского уровня. Наиболее характерным примером подобной программы может служить командный процессор shell, с которым обычно взаимодействуют пользователи после входа в систему. Shell интерпретирует первое слово командной строки как имя команды: во многих командах, в том числе и в командах fork (породить новый процесс) и exec (выполнить порожденный процесс), сама команда ассоциируется с ее именем, все остальные слова в командной строке трактуются как параметры команды.
Shell обрабатывает команды трех типов. Во-первых, в качестве имени команды может быть указано имя исполняемого файла в объектном коде, полученного в результате компиляции исходного текста программы (например, программы на языке Си). Во-вторых, именем команды может быть имя командного файла, содержащего набор командных строк, обрабатываемых shell'ом. Наконец, команда может быть внутренней командой языка shell (в отличие от исполняемого файла). Наличие внутренних команд делает shell языком программирования в дополнение к функциям командного процессора; командный язык shell включает команды организации циклов (for-in-do-done и while-do-done), команды выполнения по условиям (if-then-else-fi), оператор выбора, команду изменения текущего для процесса каталога (cd) и некоторые другие. Синтаксис shell'а допускает сравнение с образцом и обработку параметров. Пользователям, запускающим команды, нет необходимости знать, какого типа эти команды.
Командный процессор shell ищет имена команд в указанном наборе каталогов, который можно изменить по желанию пользователя, вызвав shell. Shell обычно исполняет команду синхронно, с ожиданием завершения выполнения команды прежде, чем считать следующую командную строку. Тем не менее, допускается и асинхронное исполнение, когда очередная командная строка считывается и исполняется, не дожидаясь завершения выполнения предыдущей команды. О командах, выполняемых асинхронно, говорят, что они выполняются на фоне других команд. Например, ввод команды
whoвызывает выполнение системой программы, хранящейся в файле /bin/who (****) и осуществляющей вывод списка пользователей, которые в настоящий момент работают с системой. Пока команда who выполняется, командный процессор shell ожидает завершения ее выполнения и только затем запрашивает у пользователя следующую команду. Если же ввести команду
who &система выполнит программу who на фоне и shell готов немедленно принять следующую команду.
В среду выполнения каждого процесса в системе UNIX включается текущий каталог. Текущий для процесса каталог является начальным каталогом, имя которого присоединяется ко всем именам путей поиска, которые не начинаются с наклонной черты. Пользователь может запустить внутреннюю команду shell'а cd (изменить каталог) для перемещения по дереву файловой системы и для смены текущего каталога. Командная строка
cd /usr/src/utsделает текущим каталог "/usr/src/uts". Командная строка
cd ../..делает текущим каталог, который на две вершины "ближе" к корню (корневому каталогу): параметр ".." относится к каталогу, являющемуся родительским для текущего.
Поскольку shell является пользовательской программой и не входит в состав ядра операционной системы, его легко модифицировать и помещать в конкретные условия эксплуатации. Например, вместо командного процессора Баурна (называемого так по имени его создателя, Стива Баурна), являющегося частью версии V стандартной системы, можно использовать процессор команд Си, обеспечивающий работу механизма ведения истории изменений и позволяющий избегать повторного ввода только что использованных команд. В некоторых случаях при желании можно воспользоваться командным процессором shell с ограниченными возможностями, являющимся предыдущей версией обычного shell'а. Система может работать с несколькими командными процессорами одновременно. Пользователи имеют возможность запускать одновременно множество процессов, процессы же в свою очередь могут динамически порождать новые процессы и синхронизировать их выполнение. Все эти возможности обеспечиваются благодаря наличию мощных программных и аппаратных средств, составляющих среду выполнения процессов. Хотя привлекательность shell'а в наибольшей степени определяется его возможностями как языка программирования и его возможностями в обработке аргументов, в данном разделе основное внимание концентрируется на среде выполнения процессов, управление которой в системе возложено на командный процессор shell. Другие важные особенности shell'а выходят за рамки настоящей книги (подробное описание shell'а см. в [Bourne 78]).
. Программа, содержащая вызов системной функции lseek
Рисунок 5.10. Программа, содержащая вызов системной функции lseek
| #include <fcntl.h> main(argc,argv) int argc; char *argv[]; { int fd,skval; char c; if(argc != 2) exit(); fd = open(argv[1],O_RDONLY); if (fd == -1) exit(); while ((skval = read(fd,&c,1)) == 1) { printf("char %c\n",c); skval = lseek(fd,1023L,1); printf("new seek val %d\n",skval); } } | |
На Рисунке 5.11, например, показаны записи из таблиц, приведенных на Рисунке 5.4, после того, как второй процесс закрывает соответствующие им файлы. Записи, соответствующие дескрипторам 3 и 4 в таблице пользовательских дескрипторов файлов, пусты. Счетчики в записях таблицы файлов теперь имеют значение 0, а сами записи пусты. Счетчики ссылок на файлы "/etc/passwd" и "private" в индексах также уменьшились. Индекс для файла "private" находится в списке свободных индексов, поскольку счетчик ссылок на него равен 0, но запись о нем не пуста. Если еще какой-нибудь процесс обратится к файлу "private", пока индекс еще находится в списке свободных индексов, ядро востребует индекс обратно, как показано в разделе 4.1.2.
Программа trace (трассируемый процесс)
Рисунок 11.2. Программа trace (трассируемый процесс)
| int data[32]; main() { int i; for (i = 0; i < 32; i++) printf("data[%d] = %d\n@,i,data[i]); printf("ptrace data addr Ox%x\n",data); } |
. Программа, в которой процесс
Рисунок 7.35. Программа, в которой процесс принимает сигналы типа "гибель потомка"
| #include <signal.h> main() { extern catcher(); signal(SIGCLD,catcher); if (fork() == 0) exit(); /* пауза до момента получения сигнала */ pause(); } catcher() { printf("процесс-родитель получил сигнал\n"); signal(SIGCLD,catcher); } |
7. Когда процесс получает сигналы определенного типа и не обрабатывает их, ядро дампирует образ процесса в том виде, который был у него в момент получения сигнала. Ядро создает в текущем каталоге процесса файл с именем "core" и копирует в него пространство процесса, области команд, данных и стека. Впоследствии пользователь может тщательно изучить дамп образа процесса с помощью стандартных средств отладки. Опишите алгоритм, которому на Ваш взгляд должно следовать ядро в процессе создания файла "core". Что нужно предпринять в том случае, если в текущем каталоге файл с таким именем уже существует? Как должно вести себя ядро, когда в одном и том же каталоге дампируют свои образы сразу несколько процессов?
8. Еще раз обратимся к программе (Рисунок 7.12), описывающей, как один процесс забрасывает другой процесс сигналами, которые принимаются их адресатом. Подумайте, что произошло бы в том случае, если бы алгоритм обработки сигналов был переработан в любом из следующих направлений:
ядро не заменяет функцию обработки сигналов до тех пор, пока пользователь явно не потребует этого; ядро заставляет процесс игнорировать сигналы до тех пор, пока пользователь не обратится к функции signal вновь.9. Переработайте алгоритм обработки сигналов так, чтобы ядро автоматически перенастраивало процесс на игнорирование всех последующих поступлений сигналов по возвращении из функции, обрабатывающей их. Каким образом ядро может узнать о завершении функции обработки сигналов, выполняющейся в режиме задачи? Такого рода перенастройка приблизила бы нас к трактовке сигналов в системе BSD.
*10. Если процесс получает сигнал, находясь в состоянии приостанова во время выполнения системной функции с допускающим прерывания приоритетом, он выходит из функции по алгоритму longjump. Ядро производит необходимые установки для запуска функции обработки сигнала; когда процесс выйдет из функции обработки сигнала, в версии V это будет выглядеть так, словно он вернулся из системной функции с признаком ошибки (как бы прервав свое выполнение). В системе BSD системная функция в этом случае автоматически перезапускается. Каким образом можно реализовать этот момент в нашей системе?
11. В традиционной реализации команды mkdir для создания новой вершины в дереве каталогов используется системная функция mknod, после чего дважды вызывается системная функция link, привязывающая точки входа в каталог с именами "." и ".." к новой вершине и к ее родительскому каталогу. Без этих трех операций каталог не будет иметь надлежащий формат. Что произойдет, если во время исполнения команды mkdir процесс получит сигнал? Что если при этом будет получен сигнал SIGKILL, который процесс не распознает? Эту же проблему рассмотрите применительно к реализации системной функции mkdir.
12. Процесс проверяет наличие сигналов в моменты перехода в состояние приостанова и выхода из него (если в состоянии приостанова процесс находился с приоритетом, допускающим прерывания), а также в момент перехода в режим задачи из режима ядра по завершении исполнения системной функции или после обработки прерывания. Почему процесс не проверяет наличие сигналов в момент обращения к системной функции?
*13. Предположим, что после исполнения системной функции процесс готовится к возвращению в режим задачи и не обнаруживает ни одного необработанного сигнала. Сразу после этого ядро обрабатывает прерывание и посылает процессу сигнал. (Например, пользователем была нажата клавиша "break".) Что делает процесс после того, как ядро завершает обработку прерывания?
*14. Если процессу одновременно посылается несколько сигналов, ядро обрабатывает их в том порядке, в каком они перечислены в описании. Существуют три способа реагирования на получение сигнала - прием сигналов, завершение выполнения со сбросом на внешний носитель (дампированием) образа процесса в памяти и завершение выполнения без дампирования. Можно ли указать наилучший порядок обработки одновременно поступающих сигналов? Например, если процесс получает сигнал о выходе (вызывающий дампирование образа процесса в памяти) и сигнал о прерывании (выход без дампирования), то какой из этих сигналов имело бы смысл обработать первым?
15. Запомните новую системную функцию newpgrp(pid,ngrp); которая включает процесс с идентификатором pid в группу процессов с номером ngrp (устанавливает для процесса новую группу). Подумайте, для каких целей она может использоваться и какие опасности таит в себе ее вызов.
16. Прокомментируйте следующее утверждение: по алгоритму wait процесс может приостановиться до наступления какого-либо события и это не отразилось бы на работе всей системы.
17. Рассмотрим новую системную функцию
nowait(pid);где pid - идентификатор процесса, являющегося потомком того процесса, который вызывает функцию. Вызывая функцию, процесс тем самым сообщает ядру о том, что он не собирается дожидаться завершения выполнения своего потомка, поэтому ядро может по окончании существования потомка сразу же очистить занимаемое им место в таблице процессов. Каким образом это реализуется на практике? Оцените достоинства новой функции и сравните ее использование с использованием сигналов типа "гибель потомка".
18. Загрузчик модулей на Си автоматически подключает к основному модулю начальную процедуру (startup), которая вызывает функцию main, принадлежащую программе пользователя. Если в пользовательской программе отсутствует вызов функции exit, процедура startup сама вызывает эту функцию при выходе из функции main. Что произошло бы в том случае, если бы и в процедуре startup отсутствовал вызов функции exit (из-за ошибки загрузчика)?
19. Какую информацию получит процесс, выполняющий функцию wait, если его потомок запустит функцию exit без параметра? Имеется в виду, что процесс-потомок вызовет функцию в формате exit() вместо exit(n). Если программист постоянно использует вызов функции exit без параметра, то насколько предсказуемо значение, ожидаемое функцией wait? Докажите свой ответ.
20. Объясните, что произойдет, если процесс, исполняющий программу на Рисунке 7.36 запустит с помощью функции exec самого себя. Как в таком случае ядро сможет избежать возникновения тупиковых ситуаций, связанных с блокировкой индексов?
Программа, в которой родительский
Рисунок 7.4. Программа, в которой родительский и порожденный процессы разделяют доступ к файлу
| #include <fcntl.h> int fdrd, fdwt; char c; main(argc, argv) int argc; char *argv[]; { if (argc != 3) exit(1); if ((fdrd = open(argv[1],O_RDONLY)) == -1) exit(1); if ((fdwt = creat(argv[2],0666)) == -1) exit(1); fork(); /* оба процесса исполняют одну и ту же программу */ rdwrt(); exit(0); } rdwrt(); { for(;;) { if (read(fdrd,&c,1) != 1) return; write(fdwt,&c,1); } } |
Теперь перейдем к программе, представленной на Рисунке 7.5, в которой процесс-потомок наследует от своего родителя файловые дескрипторы 0 и 1 (соответствующие стандартному вводу и стандартному выводу). При каждом выполнении системной функции pipe производится назначение двух файловых дескрипторов в массивах to_par и to_chil. Процесс вызывает функцию fork и делает копию своего контекста: каждый из процессов имеет доступ только к своим собственным данным, так же как и в предыдущем примере. Родительский процесс закрывает файл стандартного вывода (дескриптор 1) и дублирует дескриптор записи, возвращаемый в канал to_chil. Поскольку первое свободное место в таблице дескрипторов родительского процесса образовалось в результате только что выполненной операции закрытия (close) файла вывода, ядро переписывает туда дескриптор записи в канал и этот дескриптор становится дескриптором файла стандартного вывода для to_chil. Те же самые действия родительский процесс выполняет в отношении дескриптора файла стандартного ввода, заменяя его дескриптором чтения из канала to_par. И порожденный процесс закрывает файл стандартного ввода (дескриптор 0) и так же дублирует дескриптор чтения из канала to_chil. Поскольку первое свободное место в таблице дескрипторов файлов прежде было занято файлом стандартного ввода, его дескриптором становится дескриптор чтения из канала to_chil. Аналогичные действия выполняются и в отношении дескриптора файла стандартного вывода, заменяя его дескриптором записи в канал to_par. И тот, и другой процессы закрывают файлы, дескрипторы которых возвратила функция pipe - хорошая традиция, в чем нам еще предстоит убедиться. В результате, когда родительский процесс переписывает данные в стандартный вывод, запись ведется в канал to_chil и данные поступают к порожденному процессу, который считывает их через свой стандартный ввод. Когда же порожденный процесс пишет данные в стандартный вывод, запись ведется в канал to_par и данные поступают к родительскому процессу, считывающему их через свой стандартный ввод. Так через два канала оба процесса обмениваются сообщениями.
. Псевдопрограмма мультиплексирования окон
Рисунок 10.24. Псевдопрограмма мультиплексирования окон
| /* предположим, что дескрипторы файлов 0 и 1 уже относятся к физическому терминалу */ для(;;) /* цикл */ { выбрать(ввод); /* ждать ввода из какой-либо линии */ прочитать данные, введенные из линии; переключить(линию с вводимыми данными) { если выбран физический терминал: /* данные вводятся по ли- нии физического терми- нала */ если(считана управляющая команда) /* например, создание нового окна */ { открыть свободный псевдотерминал; пойти по ветви нового процесса: если(процесс родительский) { выдвинуть интерфейс сообщений в сторону mpx; продолжить; /* возврат в цикл "для" */ } /* процесс-потомок */ закрыть ненужные дескрипторы файлов; открыть другой псевдотерминал из пары, выбрать stdin, stdout, stderr; выдвинуть строковый интерфейс терминала; запустить shell; /* подобно виртуальному терминалу */ } /* "обычные" данные, появившиеся через виртуальный терминал */ демультиплексировать считывание данных с физического тер- минала, снять заголовки и вести запись на соответствую- щий псевдотерминал; продолжить; /* возврат в цикл "для" */ если выбран логический терминал: /* виртуальный терминал связан с окном */ закодировать заголовок, указывающий назначение информации окна; переписать заголовок и информацию на физический терминал; продолжить; /* возврат в цикл "для" */ } } |
Процесс mpx является мультиплексором, направляющим вывод данных с виртуальных терминалов на физический терминал и демультиплексирующим ввод данных с физического терминала на подходящий виртуальный. Mpx ждет поступления данных по любой из линий, используя системную функцию select. Когда данные поступают от физического терминала, mpx решает вопрос, являются ли поступившие данные управляющим сообщением, извещающим о необходимости создания нового окна или удаления старого, или же это информационное сообщение, которое необходимо разослать процессам, считывающим информацию с виртуального терминала. В последнем случае данные имеют заголовок, идентифицирующий тот виртуальный терминал, к которому они относятся; mpx стирает заголовок с сообщения и переписывает данные в соответствующий псевдотерминальный поток. Драйвер псевдотерминала отправляет данные через строковый интерфейс терминала процессам, осуществляющим чтение. Обратная процедура имеет место, когда процесс ведет запись на виртуальный терминал; mpx присоединяет заголовок к данным, информируя физический терминал, для вывода в какое из окон предназначены эти данные.
Если процесс вызывает функцию ioctl с виртуального терминала, строковый интерфейс терминала задает необходимые установки терминала для его виртуальной линии; для каждого из виртуальных терминалов установки могут быть различными. Однако, на физический терминал должна быть послана и кое-какая информация, зависящая от типа устройства. Модуль управления сообщениями преобразует управляющие сообщения, генерируемые функцией ioctl, в информационные сообщения, предназначенные для чтения и записи их процессом mpx, и эти сообщения передаются на физическое устройство.
. Псевдопрограмма переключения контекста
Рисунок 6.16. Псевдопрограмма переключения контекста
| if (save_context()) /* сохранение контекста выполняющегося процесса */ { /* выбор следующего процесса для выполнения */ - - - resume_context(new_process); /* сюда программа не попадает ! */ } /* возобновление выполнение процесса начинается отсюда */ |