. Рабочее множество процесса
Рисунок 9.12. Рабочее множество процесса
. Разделение памяти между процессами
Рисунок 11.12. Разделение памяти между процессами
| #include <sys/types.h> #include <sys/ipc.h> #include <sys/shm.h> #define SHMKEY 75 #define K 1024 int shmid; main() { int i, *pint; char *addr; extern char *shmat(); shmid = shmget(SHMKEY,64*K,0777); addr = shmat(shmid,0,0); pint = (int *) addr; while (*pint == 0) ; for (i = 0; i < 256, i++) printf("%d\n",*pint++); } |
Разделы на диске RP07
Рисунок 10.7. Разделы на диске RP07

Исторически сложилось так, что размеры дисковых разделов устанавливаются в зависимости от типа диска. Например, диск DEC RP07 разбит на разделы, характеристика которых приведена на Рисунке 10.7. Предположим, что файлы "/dev/dsk0", "/dev/dsk1", "/dev/dsk2" и "/dev/dsk3" соответствуют разделам диска RP07, имеющим номера от 0 до 3, и имеют аналогичные младшие номера. Пусть размер логического блока в файловой системе совпадает с размером дискового блока. Если ядро пытается обратиться к блоку с номером 940 в файловой системе, хранящейся в "/dev/dsk3", дисковый драйвер переадресует запрос к блоку с номером 336940 (раздел 3 начинается с блока, имеющего номер 336000; 336000 + 940 = 336940) на диске.
Размеры разделов на диске варьируются и администраторы располагают файловые системы в разделах соответствующего размера: большие файловые системы попадают в разделы большего размера и т. д. Разделы на диске могут перекрываться. Например, разделы 0 и 1 на диске RP07 не пересекаются, но вместе они занимают блоки с номерами от 0 до 1008000, то есть весь диск. Раздел 7 так же занимает весь диск. Перекрытие разделов не имеет значения, поскольку файловые системы, хранящиеся в разделах, размещаются таким образом, что между ними нет пересечений. Иметь один раздел, включающий в себя все дисковое пространство, выгодно, поскольку весь том можно быстро скопировать.
Использование разделов фиксированного состава и размера ограничивает гибкость дисковой конфигурации. Информацию о разделах в закодированном виде не следует включать в дисковый драйвер, но нужно поместить в таблицу содержимого дискового тома. Однако, найти общее место на всех дисках для размещения таблицы содержимого дискового тома и сохранить тем самым совместимость с предыдущими версиями системы довольно трудно. В существующих реализациях версии V предполагается, что блок начальной загрузки первой из файловых систем на диске занимает первый сектор тома, хотя по логике это, казалось бы, самое подходящее место для таблицы содержимого тома. И все же дисковый драйвер должен иметь закодированную информацию о месте расположения таблицы содержимого тома для каждого диска, не препятствуя существованию дисковых разделов переменного размера.
В связи с тем, что для системы UNIX является типичным высокий уровень дискового трафика, драйвер диска должен максимизировать передачу данных с тем, чтобы обеспечить наилучшую производительность всей системы. Новейшие дисковые контроллеры осуществляют планирование выполнения заданий, требующих обращения к диску, позиционируют головку диска и обеспечивают передачу данных между диском и центральным процессором; иначе это приходится делать дисковому драйверу.
Сервисные программы могут непосредственно обращаться к диску в обход стандартного метода доступа к файловой системе, рассмотренного в главах 4 и 5, как пользуясь блочным интерфейсом, так и не прибегая к структурированию данных. Непосредственно работают с диском две важные программы - mkfs и fsck. Программа mkfs форматирует раздел диска для файловой системы UNIX, создавая при этом суперблок, список индексов, список свободных дисковых блоков с указателями и корневой каталог новой файловой системы. Программа fsck проверяет целостность существующей файловой системы и исправляет ошибки, как показано в главе 5.
Рассмотрим программу, приведенную на Рисунке 10.8, в применении к файлам "/dev/dsk15" и "/dev/rdsk15", и предположим, что команда ls выдала следующую информацию:
ls -1 /dev/dsk15 /dev/rdsk15 br-------- 2 root root 0,21 Feb 12 15:40 /dev/dsk15 crw-rw---- 2 root root 7,21 Mar 7 09:29 /dev/rdsk15Отсюда видно, что файл "/dev/dsk15" соответствует устройству блочного типа, владельцем которого является пользователь под именем "root", и только пользователь "root" может читать с него непосредственно. Его старший номер 0, младший - 21. Файл "/dev/rdsk15" соответствует устройству посимвольного ввода-вывода, владельцем которого является пользователь "root", однако права доступа к которому на запись и чтение есть как у владельца, так и у группы. Его старший номер - 7, младший - 21. Процесс, открывающий файлы, получает доступ к устройству через таблицу ключей устройств ввода-вывода блоками и таблицу ключей устройств посимвольного ввода-вывода, соответственно, а младший номер устройства 21 информирует драйвер о том, к какому разделу диска производится обращение, например, дисковод 2, раздел 1. Поскольку младшие номера у файлов совпадают, они ссылаются на один и тот же раздел диска, если предположить, что это одно устройство (***). Таким образом, процесс, выполняющий программу, открывает один и тот же драйвер дважды (используя различные интерфейсы), позиционирует головку к смещению с адресом 8192 и считывает данные с этого места. Результаты выполнения операций чтения должны быть идентичными при условии, что работает только одна файловая система.
Размещение блоков в файле и его индексе
Рисунок 4.9. Размещение блоков в файле и его индексе

При ближайшем рассмотрении Рисунка 4.9 обнаруживается, что несколько входов для блока в индексе имеют значение 0 и это значит, что в данных записях информация о логических блоках отсутствует. Такое имеет место, если в соответствующие блоки файла никогда не записывалась информация и по этой причине у номеров блоков остались их первоначальные нулевые значения. Для таких блоков пространство на диске не выделяется. Подобное расположение блоков в файле вызывается процессами, запускающими системные операции lseek и write (см. следующую главу). В следующей главе также объясняется, каким образом ядро обрабатывает системные вызовы операции read, с помощью которой производится обращение к блокам.
Преобразование адресов с большими смещениями, в частности с использованием блоков тройной косвенной адресации, является сложной процедурой, требующей от ядра обращения уже к трем дисковым блокам в дополнение к индексу и информационному блоку. Даже если ядро обнаружит блоки в буферном кеше, операция останется дорогостоящей, так как ядру придется многократно обращаться к буферному кешу и приостанавливать свою работу в ожидании снятия блокировки с буферов. Насколько эффективен этот алгоритм на практике? Это зависит от того, как используется система, а также от того, кто является пользователем и каков состав задач, вызывающий потребность в более частом обращении к большим или, наоборот, маленьким файлам. Однако, как уже было замечено [Mullender 84], большинство файлов в системе UNIX имеет размер, не превышающий 10 Кбайт и даже 1 Кбайта ! (*) Поскольку 10 Кбайт файла располагаются в блоках прямой адресации, к большей части данных, хранящихся в файлах, доступ может производиться за одно обращение к диску. Поэтому в отличие от обращения к большим файлам, работа с файлами стандартного размера протекает быстро.
В двух модификациях только что описанной структуры индекса предпринимается попытка использовать размерные характеристики файла. Основной принцип в реализации файловой системы BSD 4.2 [McKusick 84] состоит в том, что чем больше объем данных, к которым ядро может получить доступ за одно обращение к диску, тем быстрее протекает работа с файлом. Это свидетельствует в пользу увеличения размера логического блока на диске, поэтому в системе BSD разрешается иметь логические блоки размером 4 или 8 Кбайт. Однако, увеличение размера блоков на диске приводит к увеличению фрагментации блоков, при которой значительные участки дискового пространства остаются неиспользуемыми. Например, если размер логического блока 8 Кбайт, тогда файл размером 12 Кбайт занимает 1 полный блок и половину второго блока. Другая половина второго блока (4 Кбайта) фактически теряется; другие файлы не могут использовать ее для хранения данных. Если размеры файлов таковы, что число байт, попавших в последний блок, является равномерно распределенной величиной, то средние потери дискового пространства составляют полблока на каждый файл; объем теряемого дискового пространства достигает в файловой системе с логическими блоками размером 4 Кбайта 45% [McKusick 84]. Выход из этой ситуации в системе BSD состоит в выделении только части блока (фрагмента) для размещения оставшейся информации файла. Один дисковый блок может включать в себя фрагменты, принадлежащие нескольким файлам. Некоторые подробности этой реализации исследуются на примере упражнения в главе 5.
Второй модификацией рассмотренной классической структуры индекса является идея хранения в индексе информации файла (см. [Mullender 84]). Если увеличить размер индекса так, чтобы индекс занимал весь дисковый блок, небольшая часть блока может быть использована для собственно индексных структур, а оставшаяся часть - для хранения конца файла и даже во многих случаях для хранения файла целиком. Основное преимущество такого подхода заключается в том, что необходимо только одно обращение к диску для считывания индекса и всей информации, если файл помещается в индексном блоке.
(*) На примере 19978 файлов Маллендер и Танненбаум говорят, что приблизительно 85% файлов имеют размер менее 8 Кбайт и 48% - менее 1 Кбайта. Несмотря на то, что эти данные варьируются от одной реализации системы к другой, для многих реализаций системы UNIX они показательны.
Размещение непрерывных файлов
Рисунок 4.5. Размещение непрерывных файлов и фрагментация свободного пространства

Предположим, например, что пользователь создает три файла, A, B и C, каждый из которых занимает 10 дисковых блоков, а также что система выделила для размещения этих трех файлов непрерывное место. Если потом пользователь захочет добавить 5 блоков с информацией к среднему файлу, B, ядру придется скопировать файл B в то место в файловой системе, где найдется окно размером 15 блоков. В дополнение к затратам ресурсов на проведение этой операции дисковые блоки, занимаемые информацией файла B, станут неиспользуемыми, если только они не понадобятся файлам размером не более 10 блоков (Рисунок 4.5). Ядро могло бы минимизировать фрагментацию пространства памяти, периодически запуская процедуры чистки памяти, уплотняющие имеющуюся память, но это потребовало бы дополнительного расхода временных и системных ресурсов.
В целях повышения гибкости ядро присоединяет к файлу по одному блоку, позволяя информации файла быть разбросанной по всей файловой системе. Но такая схема размещения усложняет задачу поиска данных. Таблица адресов содержит список номеров блоков, содержащих принадлежащую файлу информацию, однако простые вычисления показывают, что линейным списком блоков файла в индексе трудно управлять. Если логический блок занимает 1 Кбайт, то файлу, состоящему из 10 Кбайт, потребовался бы индекс на 10 номеров блоков, а файлу, состоящему из 100 Кбайт, понадобился бы индекс на 100 номеров блоков. Либо пусть размер индекса будет варьироваться в зависимости от размера файла, либо пришлось бы установить относительно жесткое ограничение на размер файла.
Для того, чтобы небольшая структура индекса позволяла работать с большими файлами, таблица адресов дисковых блоков приводится в соответствие со структурой, представленной на Рисунке 4.6. Версия V системы UNIX работает с 13 точками входа в таблицу адресов индекса, но принципиальные моменты не зависят от количества точек входа. Блок, имеющий пометку "прямая адресация" на рисунке, содержит номера дисковых блоков, в которых хранятся реальные данные. Блок, имеющий пометку "одинарная косвенная адресация", указывает на блок, содержащий список номеров блоков прямой адресации. Чтобы обратиться к данным с помощью блока косвенной адресации, ядро должно считать этот блок, найти соответствующий вход в блок прямой адресации и, считав блок прямой адресации, обнаружить данные. Блок, имеющий пометку "двойная косвенная адресация", содержит список номеров блоков одинарной косвенной адресации, а блок, имеющий пометку "тройная косвенная адресация", содержит список номеров блоков двойной косвенной адресации.
В принципе, этот метод можно было бы распространить и на поддержку блоков четверной косвенной адресации, блоков пятерной косвенной адресации и так далее, но на практике оказывается достаточно имеющейся структуры. Предположим, что размер логического блока в файловой системе 1 Кбайт и что номер блока занимает 32 бита (4 байта). Тогда в блоке может храниться до 256 номеров блоков. Расчеты показывают (Рисунок 4.7), что максимальный размер файла превышает 16 Гбайт, если использовать в индексе 10 блоков прямой адресации и 1 одинарной косвенной адресации, 1 двойной косвенной адресации и 1 тройной косвенной адресации. Если же учесть, что длина поля "размер файла" в индексе - 32 бита, то размер файла в действительности ограничен 4 Гбайтами (2 в степени 32).
Процессы обращаются к информации в файле, задавая смещение в байтах. Они рассматривают файл как поток байтов и ведут подсчет байтов, начиная с нулевого адреса и заканчивая адресом, равным размеру файла. Ядро переходит от байтов к блокам: файл начинается с нулевого логического блока и заканчивается блоком, номер которого определяется исходя из размера файла. Ядро обращается к индексу и превращает логический блок, принадлежащий файлу, в соответствующий дисковый блок. На Рисунке 4.8 представлен алгоритм bmap пересчета смещения в байтах от начала файла в номер физического блока на диске.
. Размещение номеров свободных индексов в суперблоке
Рисунок 4.15. Размещение номеров свободных индексов в суперблоке

. Режим без обработки - чтение 5-символьных блоков
Рисунок 10.17. Режим без обработки - чтение 5-символьных блоков
| #include <signal.h> #include <termio.h> struct termio savetty; main() { extern sigcatch(); struct termio newtty; int nrd; char buf[32]; signal(SIGINT,sigcatch); if (ioctl(0,TCGETA,&savetty) == -1) { printf("ioctl завершилась неудачно: нет терминала\n"); exit(); } newtty = savetty; newtty.c_lflag &= ~ICANON;/* выход из канонического режима */ newtty.c_lflag &= ~ECHO; /* отключение эхо-сопровождения*/ newtty.c_cc[VMIN] = 5; /* минимум 5 символов */ newtty.c_cc[VTIME] = 100; /* интервал 10 секунд */ if (ioctl(0,TCSETAF,&newtty) == -1) { printf("не могу перевести тер-л в режим без обработки\n"); exit(); } for(;;) { nrd = read(0,buf,sizeof(buf)); buf[nrd] = 0; printf("чтение %d символов '%s'\n",nrd,buf); } } sigcatch() { ioctl(0,TCSETAF,&savetty); exit(); } |
. Результат дисассемблирования программы приема сигналов
Рисунок 7.10. Результат дисассемблирования программы приема сигналов
| **** VAX DISASSEMBLER **** _main() e4: e6: pushab Ox18(pc) ec: pushl $Ox2 # в следующей строке вызывается функция signal ee: calls $Ox2,Ox23(pc) f5: pushl $Ox2 f7: clrl -(sp) # в следующей строке вызывается библиотечная процеду- ра kill f9: calls $Ox2,Ox8(pc) 100: ret 101: halt 102: halt 103: halt _catcher() 104: 106: ret 107: halt _kill() 108: # в следующей строке вызывается внутреннее прерывание операционной системы 10a: chmk $Ox25 10c: bgequ Ox6 <Ox114> 10e: jmp Ox14(pc) 114: clrl r0 116: ret | |
. Результат загрузки страницы в память
Рисунок 9.23. Результат загрузки страницы в память

. Считывание нулей и конца файла
Рисунок 5.35. Считывание нулей и конца файла
| #include <fcntl.h> main() { int fd; char buf[1024]; fd = creat("junk",0666); lseek(fd,2000L,2); /* ищется байт с номером 2000 */ write(fd,"hello",5); close(fd); fd = open("junk",O_RDONLY); read(fd,buf,1024); /* читает нули */ read(fd,buf,1024); /* считывает нечто, отличное от 0 */ read(fd,buf,1024); } |
5. Если процесс читает данные из файла последовательно, ядро запоминает значение блока, прочитанного с продвижением, в индексе, хранящемся в памяти. Что произойдет, если несколько процессов будут одновременно вести последовательное считывание данных из одного и того же файла?
. Символьный блок
Рисунок 10.10. Символьный блок
Ядро обеспечивает ведение списка свободных символьных блоков и выполняет над символьными списками и символьными блоками шесть операций.
Ядро назначает драйверу символьный блок из списка свободных символьных блоков. Оно также возвращает символьный блок в список свободных символьных блоков. Ядро может выбирать первый символ из символьного списка: оно удаляет первый символ из первого символьного блока в списке и устанавливает значения счетчика символов в списке и указателей в блоке таким образом, чтобы последующие операции не выбирали один и тот же символ. Если в результате операции выбран последний символ блока, ядро помещает в список свободных символьных блоков пустой блок и переустанавливает указатели в символьном списке. Если в символьном списке отсутствуют символы, ядро возвращает пустой символ. Ядро может поместить символ в конец символьного списка путем поиска последнего символьного блока в списке, включения символа в него и переустановки адресов смещений. Если символьный блок заполнен, ядро выделяет новый символьный блок, включает его в конец символьного списка и помещает символ в новый блок. Ядро может удалять от начала списка группу символов по одному блоку за одну операцию, что эквивалентно удалению всех символов в блоке за один раз. Ядро может поместить блок с символами в конец символьного списка.Символьные списки позволяют создать несложный механизм буферизации, полезный при небольшом объеме передаваемых данных, типичном для медленных устройств, таких как терминалы. Они дают возможность манипулировать с данными с каждым символом в отдельности и с группой символьных блоков. Например, Рисунок 10.11 иллюстрирует удаление символов из символьного списка; ядро удаляет по одному символу из первого блока в списке (Рисунок 10.11а-в) до тех пор, пока в блоке не останется ни одного символа (Рисунок 10.11г); затем оно устанавливает указатель списка на следующий блок, который становится первым блоком в списке. Подобно этому на Рисунке 10.12 показано, как ядро включает символы в символьный список; при этом предполагается, что в одном блоке помещается до 8 символов и что ядро размещает новый блок в конце списка (Рисунок 10.12г).
. Системная функция creat и сгенерированная
Рисунок 6.13. Системная функция creat и сгенерированная программа ее выполнения в системе Motorola 68000
| char name[] = "file"; main() { int fd; fd = creat(name,0666); } |
| Фрагменты ассемблерной программы, сгенерированной в системе Motorola 68000 Адрес Команда - - # текст главной программы - 58: mov &Ox1b6,(%sp) # поместить код 0666 в стек 5e: mov &Ox204,-(%sp) # поместить указатель вершины # стека и переменную "имя файла" # в стек 64: jsr Ox7a # вызов библиотечной функции # создания файла - - # текст библиотечной функции создания файла 7a: movq &Ox8,%d0 # занести значение 8 в регистр 0 7c: trap &Ox0 # внутреннее прерывание операци- # онной системы 7e: bcc &Ox6 <86> # если бит переноса очищен, # перейти по адресу 86 80: jmp Ox13c # перейти по адресу 13c 86: rts # возврат из подпрограммы - - # текст обработки ошибок функции 13c: mov %d0,&Ox20e # поместить содержимое регистра # 0 в ячейку 20e (переменная # errno) 142: movq &-Ox1,%d0 # занести в регистр 0 константу # -1 144: mova %d0,%a0 146: rts # возврат из подпрограммы |
Системные функции управления процессом
Рисунок 7.1. Системные функции управления процессом и их связь с другими алгоритмами
| | Системные функции, имеющие | Системные функции, | Функции | | ющие дело с управлением па- | связанные с синхро- | смешанного | | мятью | низацией | типа | +-------+-------+-------+-----+--+----+------+----+-+-----+------+ | fork | exec | brk | exit |wait|signal|kill|setrgrр|setuid| +-------+-------+-------+--------+----+------+----+-------+------+ |dupreg |detach-|growreg| detach-| | |attach-| reg | | reg | | | reg |alloc- | | | | | | reg | | | | | |attach-| | | | | | reg | | | | | |growreg| | | | | |loadreg| | | | | |mapreg | | | | |
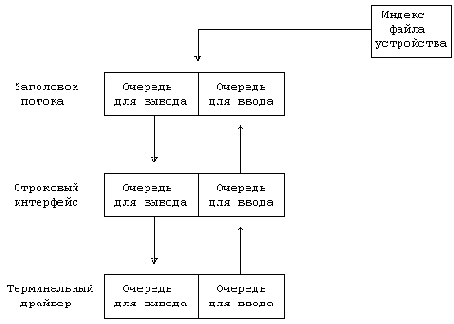
. Сообщения в потоках
Рисунок 10.21. Сообщения в потоках
Когда процесс производит запись в поток, ядро копирует данные из адресного пространства задачи в блоки сообщения, которые выделяются модулем заголовка потока. Модуль заголовка потока запускает процедуру "вывода" для модуля следующей очереди, которая обрабатывает сообщение, незамедлительно передает его в следующую очередь или ставит в эту же очередь для последующей обработки. В последнем случае модуль связывает заголовки блоков сообщения в список с указателями, формируя двунаправленный список (Рисунок 10.21). Затем он устанавливает в структуре данных очереди флаг, показывая тем самым, что имеются данные для обработки, и планирует собственное обслуживание. Модуль включает очередь в список очередей, требующих обслуживания и запускает механизм диспетчеризации; планировщик (диспетчер) вызывает процедуры обслуживания для каждой очереди в списке. Ядро может планировать обслуживание модулей по программному прерыванию, подобно тому, как оно вызывает функции в таблице ответных сигналов (см. главу 8); обработчик программных прерываний вызывает индивидуальные процедуры обслуживания.
. Соперничество процессов за индекс
Рисунок 5.32. Соперничество процессов за индекс при выполнении функции unlink

. Состязание за свободный буфер
Рисунок 3.10. Состязание за свободный буфер

В конце концов, процесс B найдет этот блок, при необходимости выбрав новый буфер из списка свободных буферов, как в случае 2. Пусть некоторый процесс, осуществляя поиск блока 99 (Рисунок 3.11), обнаружил этот блок в хеш-очереди, однако он оказался занятым. Процесс приостанавливается до момента освобождения блока, после чего он запускает весь алгоритм с самого начала. На Рисунке 3.12 показано содержимое занятого буфера.
Алгоритм выделения буфера должен быть надежным; процессы не должны "засыпать" навсегда и рано или поздно им нужно выделить буфер. Ядро гарантирует такое положение, при котором все процессы, ожидающие выделения буфера, продолжат свое выполнение, благодаря тому, что ядро распределяет буферы во время обработки обращений к операционной системе и освобождает их перед возвратом управления процессам (***). В режиме задачи процессы непосредственно не контролируют выделение буферов ядром системы, поэтому они не могут намеренно "захватывать" буферы. Ядро теряет контроль над буфером только тогда, когда ждет завершения операции ввода-вывода между буфером и диском. Было задумано так, что если дисковод испорчен, он не может прерывать работу центрального процессора, и тогда ядро никогда не освободит буфер. Дисковод должен следить за работой аппаратных средств в таких случаях и возвращать ядру код ошибки, сообщая о плохой работе диска. Короче говоря, ядро может гарантировать, что процессы, приостановленные в ожидании буфера, в конце концов возобновят свое выполнение.
Состояния процесса и переходы между ними
Рисунок 2.6. Состояния процесса и переходы между ними

Проблемой, которая может привести к нарушению целостности информации ядра, является обработка прерываний, могущая вносить изменения в информацию о состоянии ядра. Например, если ядро выполняло программу, приведенную на Рисунке 2.7, и получило прерывание по достижении комментариев, программа обработки прерываний может разрушить ссылки, если будет манипулировать указателями, как было показано ранее. Чтобы решить эту проблему, система могла бы запретить все прерывания на время работы в режиме ядра, но при этом затянулась бы обработка прерывания, что в конечном счете нанесло бы ущерб производительности системы. Вместо этого ядро повышает приоритет прерывания процессора, запрещая прерывания на время выполнения критических секций программы. Секция программы является критической, если в процессе ее выполнения запуск программ обработки произвольного прерывания может привести к возникновению проблем, имеющих отношение к нарушению целостности. Например, если программа обработки прерывания от диска работает с буферными очередями, то часть прерываемой программы, при выполнении которой ядро обрабатывает буферные очереди, является критической секцией по отношению к программе обработки прерывания от диска. Критические секции невелики по размеру и встречаются нечасто, поэтому их существование не оказывает практически никакого воздействия на производительность системы. В других операционных системах данный вопрос решается путем запрещения любых прерываний при работе в системных режимах или путем разработки схем блокировки, обеспечивающих целостность. В главе 12 мы еще вернемся к этому вопросу, когда будем говорить о многопроцессорных системах, где применения указанных мер для решения проблемы недостаточно.
Создание контекста нового процесса
Рисунок 7.3. Создание контекста нового процесса при выполнении функции fork
Если контекст порожденного процесса готов, родительский процесс завершает свою роль в выполнении алгоритма fork, переводя порожденный процесс в состояние "готовности к запуску, находясь в памяти" и возвращая пользователю его идентификатор. Затем, используя обычный алгоритм планирования, ядро выбирает порожденный процесс для исполнения и тот "доигрывает" свою роль в алгоритме fork. Контекст порожденного процесса был задан родительским процессом; с точки зрения ядра кажется, что порожденный процесс возобновляется после приостанова в ожидании ресурса. Порожденный процесс при выполнении функции fork реализует ту часть программы, на которую указывает счетчик команд, восстанавливаемый ядром из сохраненного на уровне 2 регистрового контекста, и по выходе из функции возвращает нулевое значение.
На Рисунке 7.3 представлена логическая схема взаимодействия родительского и порожденного процессов с другими структурами данных ядра сразу после завершения системной функции fork. Итак, оба процесса совместно пользуются файлами, которые были открыты родительским процессом к моменту исполнения функции fork, при этом значение счетчика ссылок на каждый из этих файлов в таблице файлов на единицу больше, чем до вызова функции. Порожденный процесс имеет те же, что и родительский процесс, текущий и корневой каталоги, значение же счетчика ссылок на индекс каждого из этих каталогов так же становится на единицу больше, чем до вызова функции. Содержимое областей команд, данных и стека (задачи) у обоих процессов совпадает; по типу области и версии системной реализации можно установить, могут ли процессы разделять саму область команд в физических адресах.
Рассмотрим приведенную на Рисунке 7.4 программу, которая представляет собой пример разделения доступа к файлу при исполнении функции fork. Пользователю следует передавать этой программе два параметра - имя существующего файла и имя создаваемого файла. Процесс открывает существующий файл, создает новый файл и - при условии отсутствия ошибок - порождает новый процесс. Внутри программы ядро делает копию контекста родительского процесса для порожденного, при этом родительский процесс исполняется в одном адресном пространстве, а порожденный - в другом. Каждый из процессов может работать со своими собственными копиями глобальных переменных fdrd, fdwt и c, а также со своими собственными копиями стековых переменных argc и argv, но ни один из них не может обращаться к переменным другого процесса. Тем не менее, при выполнении функции fork ядро делает копию адресного пространства первого процесса для второго, и порожденный процесс, таким образом, наследует доступ к файлам родительского (то есть к файлам, им ранее открытым и созданным) с правом использования тех же самых дескрипторов.
Родительский и порожденный процессы независимо друг от друга, конечно, вызывают функцию rdwrt и в цикле считывают по одному байту информацию из исходного файла и переписывают ее в файл вывода. Функция rdwrt возвращает управление, когда при считывании обнаруживается конец файла. Ядро перед тем уже увеличило значения счетчиков ссылок на исходный и результирующий файлы в таблице файлов, и дескрипторы, используемые в обоих процессах, адресуют к одним и тем же строкам в таблице. Таким образом, дескрипторы fdrd в том и в другом процессах указывают на запись в таблице файлов, соответствующую исходному файлу, а дескрипторы, подставляемые в качестве fdwt, - на запись, соответствующую результирующему файлу (файлу вывода). Поэтому оба процесса никогда не обратятся вместе на чтение или запись к одному и тому же адресу, вычисляемому с помощью смещения внутри файла, поскольку ядро смещает внутрифайловые указатели после каждой операции чтения или записи. Несмотря на то, что, казалось бы, из-за того, что процессы распределяют между собой рабочую нагрузку, они копируют исходный файл в два раза быстрее, содержимое результирующего файла зависит от очередности, в которой ядро запускает процессы. Если ядро запускает процессы так, что они исполняют системные функции попеременно (чередуя и спаренные вызовы функций read-write), содержимое результирующего файла будет совпадать с содержимым исходного файла. Рассмотрим, однако, случай, когда процессы собираются считать из исходного файла последовательность из двух символов "ab". Предположим, что родительский процесс считал символ "a", но не успел записать его, так как ядро переключилось на контекст порожденного процесса. Если порожденный процесс считывает символ "b" и записывает его в результирующий файл до возобновления родительского процесса, строка "ab" в результирующем файле будет иметь вид "ba". Ядро не гарантирует согласование темпов выполнения процессов.
. Список номеров свободных дисковых блоков с указателями
Рисунок 4.18. Список номеров свободных дисковых блоков с указателями

Алгоритм освобождения блока free - обратный алгоритму выделения блока. Если список в суперблоке не полон, номер вновь освобожденного блока включается в этот список. Если, однако, список полон, вновь освобожденный блок становится связным блоком; ядро переписывает в него список из суперблока и копирует блок на диск. Затем номер вновь освобожденного блока включается в список свободных блоков в суперблоке. Этот номер становится единственным номером в списке.
На Рисунке 4.20 показана последовательность операций alloc и free для случая, когда в исходный момент список свободных блоков содержал один элемент. Ядро освобождает блок 949 и включает номер блока в список. Затем оно выделяет этот блок и удаляет его номер из списка. Наконец, оно выделяет блок 109 и удаляет его номер из списка. Поскольку список свободных блоков в суперблоке теперь пуст, ядро снова наполняет список, копируя в него содержимое блока 109, являющегося следующей связью в списке с указателями. На Рисунке 4.20(г) показан заполненный список в суперблоке и следующий связной блок с номером 211.
Список с указателями, некорректный
Рисунок 2.8. Список с указателями, некорректный из-за переключения контекста

Чтобы подвести черту, еще раз скажем, что ядро защищает свою целостность, разрешая переключение контекста только тогда, когда процесс переходит в состояние "сна", а также препятствуя воздействию одного процесса на другой с целью изменения состояния последнего. Оно также повышает приоритет прерывания процессора на время выполнения критических секций программ, запрещая таким образом прерывания, которые в противном случае могут вызвать нарушение целостности. Планировщик процессов периодически выгружает процессы, выполняющиеся в режиме задачи, для того, чтобы процессы не могли монопольно использовать центральный процессор.
2.2.2.4 "Сон" и пробуждение
Процесс, выполняющийся в режиме ядра, имеет значительную степень автономии в решении того, как ему следует реагировать на возникновение системных событий. Процессы могут общаться между собой и "предлагать" различные альтернативы, но при этом окончательное решение они принимают самостоятельно. Мы еще увидим, что существует набор правил, которым подчиняется поведение процессов в различных обстоятельствах, но каждый процесс в конечном итоге следует этим правилам по своей собственной инициативе. Например, если процесс должен временно приостановить выполнение ("перейти ко сну"), он это делает по своей доброй воле. Следовательно, программа обработки прерываний не может приостановить свое выполнение, ибо если это случится, прерванный процесс должен был бы "перейти ко сну" по умолчанию.
Процессы приостанавливают свое выполнение, потому что они ожидают возникновения некоторого события, например, завершения ввода-вывода на периферийном устройстве, выхода, выделения системных ресурсов и т.д. Когда говорят, что процесс приостановился по событию, то имеется ввиду, что процесс находится в состоянии "сна" до наступления события, после чего он пробудится и перейдет в состояние "готовности к выполнению". Одновременно могут приостановиться по событию много процессов; когда событие наступает, все процессы, приостановленные по событию, пробуждаются, поскольку значение условия, связанного с событием, больше не является "истинным". Когда процесс пробуждается, он переходит из состояния "сна" в состояние "готовности к выполнению", находясь в котором он уже может быть выбран планировщиком; следует обратить внимание на то, что он не выполняется немедленно. Приостановленные процессы не занимают центральный процессор. Ядру системы нет надобности постоянно проверять то, что процесс все еще приостановлен, т.к. ожидает наступления события, и затем будить его.
Например, процесс, выполняемый в режиме ядра, должен иногда блокировать структуру данных на случай приостановки в будущем; процессы, пытающиеся обратиться к заблокированной структуре, обязаны проверить наличие блокировки и приостановить свое выполнение, если структура заблокирована другим процессом. Ядро выполняет блокировки такого рода следующим образом:
while (условие "истинно") sleep (событие: условие принимает значение "ложь"); set condition true;то есть:
пока (условие "истинно") приостановиться (до наступления события, при котором условие принимает значение "ложь"); присвоить условию значение "истина";Ядро снимает блокировку и "будит" все процессы, приостановленные из-за этой блокировки, следующим образом:
set condition false; wakeup (событие: условие "ложно");то есть:
присвоить условию значение "ложь"; перезапуститься (при наступлении события, при котором условие принимает значение "ложь");На Рисунке 2.9 приведен пример, в котором три процесса, A, B и C оспаривают заблокированный буфер. Переход в состояние "сна" вызывается заблокированностью буфера. Процессы, однажды запустившись, обнаруживают, что буфер заблокирован, и приостанавливают свое выполнение до наступления события, по которому буфер будет разблокирован. В конце концов блокировка с буфера снимается и все процессы "пробуждаются", переходя в состояние "готовности к выполнению". Ядро наконец выбирает один из процессов, скажем, B, для выполнения. Процесс B, выполняя цикл "while", обнаруживает, что буфер разблокирован, блокирует его и продолжает свое выполнение. Если процесс B в дальнейшем снова приостановится без снятия блокировки с буфера (например, ожидая завершения операции ввода-вывода), ядро сможет приступить к планированию выполнения других процессов. Если будет при этом выбран процесс A, этот процесс, выполняя цикл "while", обнаружит, что буфер заблокирован, и снова перейдет в состояние "сна"; возможно то же самое произойдет и с процессом C. В конце концов выполнение процесса B возобновится и блокировка с буфера будет снята, в результате чего процессы A и C получат доступ к нему. Таким образом, цикл "while-sleep" обеспечивает такое положение, при котором самое большее один процесс может иметь доступ к ресурсу.
Алгоритмы перехода в состояние "сна" и пробуждения более подробно будут рассмотрены в главе 6. Тем временем они будут считаться "неделимыми". Процесс переходит в состояние "сна" мгновенно и находится в нем до тех пор, пока не будет "разбужен". После того, как он приостанавливается, ядро системы начинает планировать выполнение следующего процесса и переключает контекст на него.
(*) Сокращение bss имеет происхождение от ассемблерного псевдооператора для машины IBM 7090 и расшифровывается как "block started by symbol" ("блок, начинающийся с символа").
Список свободных буферов
Рисунок 3.2. Список свободных буферов

Когда ядро обращается к дисковому блоку, оно сначала ищет буфер с соответствующей комбинацией номеров устройства и блока. Вместо того, чтобы просматривать всю область буферов, ядро организует из буферов особые очереди, хешированные по номеру устройства и номеру блока. В хеш-очереди ядро устанавливает для буферов циклическую связь в виде списка с двунаправленными указателями, структура которого похожа на структуру списка свободных буферов. Количество буферов в хеш-очереди варьируется в течение всего времени функционирования системы, в чем мы еще убедимся дальше. Ядро вынуждено прибегать к функции хеширования, чтобы единообразно распределять буферы между хеш-очередями, однако функция хеширования должна быть несложной, чтобы не пострадала производительность системы. Администраторы системы задают количество хеш-очередей при генерации операционной системы.
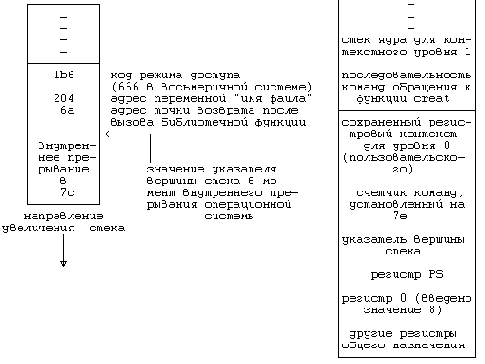
. Стандартные контекстные уровни приостановленного процесса
Рисунок 6.29. Стандартные контекстные уровни приостановленного процесса
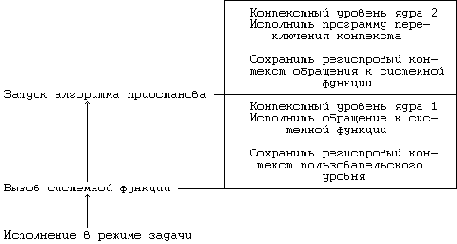
Выполнение процесса приостанавливается обычно во время исполнения запрошенной им системной функции: процесс переходит в режим ядра (контекстный уровень 1), исполняя внутреннее прерывание операционной системы, и приостанавливается в ожидании ресурсов. При этом процесс переключает контекст, запоминая в стеке свой текущий контекстный уровень и исполняясь далее в рамках системного контекстного уровня 2 (Рисунок 6.29). Выполнение процессов приостанавливается также и в том случае, когда оно наталкивается на отсутствие страницы в результате обращения к виртуальным адресам, не загруженным физически; процессы не будут выполняться, пока ядро не считает содержимое страниц.
Стандартные уровни прерываний
Рисунок 1.6. Стандартные уровни прерываний

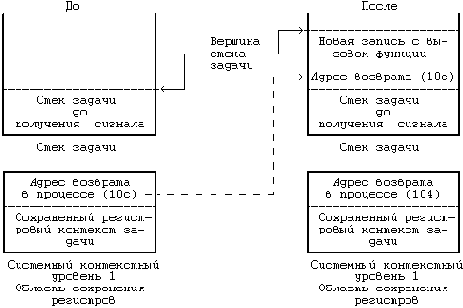
. Стек задачи и область сохранения
Рисунок 7.11. Стек задачи и область сохранения структур ядра до и после получения сигнала
Эту ситуацию можно разобрать на примере программы, представленной на Рисунке 7.12. Процесс обращается к системной функции signal для того, чтобы дать указание принимать сигналы о прерываниях и исполнять по их получении функцию sigcatcher. Затем он порождает новый процесс, запускает системную функцию nice, позволяющую сделать приоритет запуска процесса-родителя ниже приоритета его потомка (см. главу 8), и входит в бесконечный цикл. Порожденный процесс задерживает свое выполнение на 5 секунд, чтобы дать родительскому процессу время исполнить системную функцию nice и снизить свой приоритет. После этого порожденный процесс входит в цикл, в каждой итерации которого он посылает родительскому процессу сигнал о прерывании (посредством обращения к функции kill). Если в результате ошибки, например, из-за того, что родительский процесс больше не существует, kill завершается, то завершается и порожденный процесс. Вся идея состоит в том, что родительскому процессу следует запускать функцию обработки сигнала при каждом получении сигнала о прерывании. Функция обработки сигнала выводит сообщение и снова обращается к функции signal при очередном появлении сигнала о прерывании, родительский же процесс продолжает исполнять циклический набор команд.
Однако, возможна и следующая очередность наступления событий:
Порожденный процесс посылает родительскому процессу сигнал о прерывании. Родительский процесс принимает сигнал и вызывает функцию обработки сигнала, но резервируется ядром, которое производит переключение контекста до того, как функция signal будет вызвана повторно. Снова запускается порожденный процесс, который посылает родительскому процессу еще один сигнал о прерывании. Родительский процесс получает второй сигнал о прерывании, но перед тем он не успел сделать никаких распоряжений относительно способа обработки сигнала. Когда выполнение родительского процесса будет возобновлено, он завершится.Стеки задачи и ядра для программы копирования.
Рисунок 2.4. Стеки задачи и ядра для программы копирования.

Поскольку процесс в системе UNIX может выполняться в двух режимах, режиме ядра или режиме задачи, он пользуется в каждом из этих режимов отдельным стеком. Стек задачи содержит аргументы, локальные переменные и другую информацию относительно функций, выполняемых в режиме задачи. Слева на Рисунке 2.4 показан стек задачи для процесса, связанного с выполнением системной операции write в программе copy. Процедура запуска процесса (включенная в библиотеку) обратилась к функции main с передачей ей двух параметров, поместив в стек задачи запись 1; в записи 1 есть место для двух локальных переменных функции main. Функция main затем вызывает функцию copy с передачей ей двух параметров, old и new, и помещает в стек задачи запись 2; в записи 2 есть место для локальной переменной count. Наконец, процесс активизирует системную операцию write, вызвав библиотечную функцию с тем же именем. Каждой системной операции соответствует точка входа в библиотеке системных операций; библиотека системных операций написана на языке ассемблера и включает специальные команды прерывания, которые, выполняясь, порождают "прерывание", вызывающее переключение аппаратуры в режим ядра. Процесс ищет в библиотеке точку входа, соответствующую отдельной системной операции, подобно тому, как он вызывает любую из функций, создавая при этом для библиотечной функции запись активации. Когда процесс выполняет специальную инструкцию, он переключается в режим ядра, выполняет операции ядра и использует стек ядра.
Стек ядра содержит записи активации для функций, выполняющихся в режиме ядра. Элементы функций и данных в стеке ядра соответствуют функциям и данным, относящимся к ядру, но не к программе пользователя, тем не менее, конструкция стека ядра подобна конструкции стека задачи. Стек ядра для процесса пуст, если процесс выполняется в режиме задачи. Справа на Рисунке 2.4 представлен стек ядра для процесса выполнения системной операции write в программе copy. Подробно алгоритмы выполнения системной операции write будут описаны в последующих разделах.
Структура процесса отладки
Рисунок 11.1. Структура процесса отладки
| if ((pid = fork()) == 0) { /* потомок - трассируемый процесс */ ptrace(0,0,0,0); exec("имя трассируемого процесса"); } /* продолжение выполнения процесса-отладчика */ for (;;) { wait((int *) 0); read(входная информация для трассировки команд) ptrace(cmd,pid,...); if (условие завершения трассировки) break; } |
Псевдопрограмма, представленная на Рисунке 11.1, имеет типичную структуру отладочной программы. Отладчик порождает новый процесс, запускающий системную функцию ptrace, в результате чего в соответствующей процессу-потомку записи таблицы процессов ядро устанавливает бит трассировки. Процесс-потомок предназначен для запуска (exec) трассируемой программы. Например, если пользователь ведет отладку программы a.out, процесс-потомок запускает файл с тем же именем. Ядро отрабатывает функцию exec обычным порядком, но в финале замечает, что бит трассировки установлен, и посылает процессу-потомку сигнал прерывания. На выходе из функции exec, как и на выходе из любой другой функции, ядро проверяет наличие сигналов, обнаруживает только что посланный сигнал прерывания и исполняет программу трассировки процесса как особый случай обработки сигналов. Заметив установку бита трассировки, процесс-потомок выводит своего родителя из состояния приостанова, в котором последний находится вследствие исполнения функции wait, сам переходит в состояние трассировки, подобное состоянию приостанова (но не показанное на диаграмме состояний процесса, см. Рисунок 6.1), и выполняет переключение контекста.
Тем временем в обычной ситуации процесс-родитель (отладчик) переходит на пользовательский уровень, ожидая получения известия от трассируемого процесса. Когда соответствующее известие процессом-родителем будет получено, он выйдет из состояния ожидания (wait), прочитает (read) введенные пользователем команды и превратит их в серию обращений к функции ptrace, управляющих трассировкой процесса-потомка. Синтаксис вызова системной функции ptrace:
ptrace(cmd,pid,addr,data);где в качестве cmd указываются различные команды, например, чтения данных, записи данных, возобновления выполнения и т.п., pid - идентификатор трассируемого процесса, addr - виртуальный адрес ячейки в трассируемом процессе, где будет производиться чтение или запись, data - целое значение, предназначенное для записи. Во время исполнения системной функции ptrace ядро проверяет, имеется ли у отладчика потомок с идентификатором pid и находится ли этот потомок в состоянии трассировки, после чего заводит глобальную структуру данных, предназначенную для передачи данных между двумя процессами. Чтобы другие процессы, выполняющие трассировку, не могли затереть содержимое этой структуры, она блокируется ядром, ядро записывает в нее параметры cmd, addr и data, возобновляет процесс-потомок, переводит его в состояние "готовности к выполнению" и приостанавливается до получения от него ответа. Когда процесс-потомок продолжит свое выполнение (в режиме ядра), он исполнит соответствующую (трассируемую) команду, запишет результат в глобальную структуру и "разбудит" отладчика. В зависимости от типа команды потомок может вновь перейти в состояние трассировки и ожидать поступления новой команды или же выйти из цикла обработки сигналов и продолжить свое выполнение. При возобновлении работы отладчика ядро запоминает значение, возвращенное трассируемым процессом, снимает с глобальной структуры блокировку и возвращает управление пользователю.
Если в момент перехода процесса-потомка в состояние трассировки отладчик не находится в состоянии приостанова (wait), он не обнаружит потомка, пока не обратится к функции wait, после чего немедленно выйдет из функции и продолжит работу по вышеописанному плану.
Структуры данных, используемые при разделении памяти
Рисунок 11.9. Структуры данных, используемые при разделении памяти
Процесс присоединяет область разделяемой памяти к своему виртуальному адресному пространству с помощью системной функции shmat:
virtaddr = shmat(id,addr,flags);Значение id, возвращаемое функцией shmget, идентифицирует область разделяемой памяти, addr является виртуальным адресом, по которому пользователь хочет подключить область, а с помощью флагов (flags) можно указать, предназначена ли область только для чтения и нужно ли ядру округлять значение указанного пользователем адреса. Возвращаемое функцией значение, virtaddr, представляет собой виртуальный адрес, по которому ядро произвело подключение области и который не всегда совпадает с адресом, указанным пользователем.
В начале выполнения системной функции shmat ядро проверяет наличие у процесса необходимых прав доступа к области (Рисунок 11.10). Оно исследует указанный пользователем адрес; если он равен 0, ядро выбирает виртуальный адрес по своему усмотрению.
Область разделяемой памяти не должна пересекаться в виртуальном адресном пространстве процесса с другими областями; следовательно, ее выбор должен производиться разумно и осторожно. Так, например, процесс может увеличить размер принадлежащей ему области данных с помощью системной функции brk, и новая область данных будет содержать адреса, смежные с прежней областью; поэтому, ядру не следует присоединять область разделяемой памяти слишком близко к области данных процесса. Так же не следует размещать область разделяемой памяти вблизи от вершины стека, чтобы стек при своем последующем увеличении не залезал за ее пределы. Если, например, стек растет в направлении увеличения адресов, лучше всего разместить область разделяемой памяти непосредственно перед началом области стека.
Структуры данных, используемые в организации сообщений
Рисунок 11.5. Структуры данных, используемые в организации сообщений
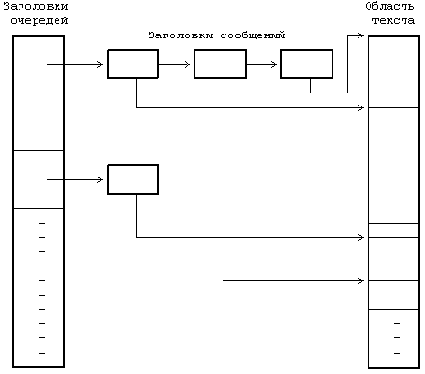
Рассмотрим программу, представленную на Рисунке 11.6. Процесс вызывает функцию msgget для того, чтобы получить дескриптор для записи с идентификатором MSGKEY. Длина сообщения принимается равной 256 байт, хотя используется только первое поле целого типа, в область текста сообщения копируется идентификатор процесса, типу сообщения присваивается значение 1, после чего вызывается функция msgsnd для посылки сообщения. Мы вернемся к этому примеру позже.
Процесс получает сообщения, вызывая функцию msgrcv по следующему формату:
count = msgrcv(id,msg,maxcount,type,flag);где id - дескриптор сообщения, msg - адрес пользовательской структуры, которая будет содержать полученное сообщение, maxcount - размер структуры msg, type - тип считываемого сообщения, flag - действие, предпринимаемое ядром в том случае, если в очереди сообщений нет. В переменной count пользователю возвращается число прочитанных байт сообщения.
Ядро проверяет (Рисунок 11.7), имеет ли пользователь необходимые права доступа к очереди сообщений. Если тип считываемого сообщения имеет нулевое значение, ядро ищет первое по счету сообщение в связном списке. Если его размер меньше или равен размеру, указанному пользователем, ядро копирует текст сообщения в пользовательскую структуру и соответствующим образом настраивает свои внутренние структуры: уменьшает счетчик сообщений в очереди и суммарный объем информации в байтах, запоминает время получения сообщения и идентификатор процесса-получателя, перестраивает связный список и освобождает место в системном пространстве, где хранился текст сообщения. Если какие-либо процессы, ожидавшие получения сообщения, находились в состоянии приостанова из-за отсутствия свободного места в списке, ядро выводит их из этого состояния. Если размер сообщения превышает значение maxcount, указанное пользователем, ядро посылает системной функции уведомление об ошибке и оставляет сообщение в очереди. Если, тем не менее, процесс игнорирует ограничения на размер (в поле flag установлен бит MSG_NOERROR), ядро обрезает сообщение, возвращает запрошенное количество байт и удаляет сообщение из списка целиком.
. Структуры данных, используемые в работе над семафорами
Рисунок 11.13. Структуры данных, используемые в работе над семафорами
Синтаксис вызова системной функции semget:
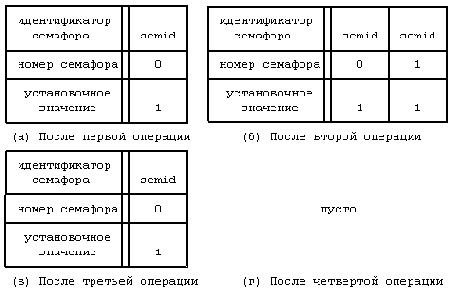
id = semget(key,count,flag);где key, flag и id имеют тот же смысл, что и в других механизмах взаимодействия процессов (обмен сообщениями и разделение памяти). В результате выполнения функции ядро выделяет запись, указывающую на массив семафоров и содержащую счетчик count (Рисунок 11.13). В записи также хранится количество семафоров в массиве, время последнего выполнения функций semop и semctl. Системная функция semget на Рисунке 11.14, например, создает семафор из двух элементов.
Синтаксис вызова системной функции semop:
oldval = semop(id,oplist,count);где id - дескриптор, возвращаемый функцией semget, oplist - указатель на список операций, count - размер списка. Возвращаемое функцией значение oldval является прежним значением семафора, над которым производилась операция. Каждый элемент списка операций имеет следующий формат:
номер семафора, идентифицирующий элемент массива семафоров, над которым выполняется операция, код операции, флаги.. Структуры данных после монтирования
Рисунок 5.24. Структуры данных после монтирования

Для случая пересечения точки монтирования в направлении из файловой системы, где производится монтирование, в файловую систему, которая монтируется, рассмотрим модификацию алгоритма iget (Рисунок 5.25), которая идентична версии алгоритма, приведенной на Рисунке 4.3, почти во всем, за исключением того, что в данной модификации производится проверка, является ли индекс индексом точки монтирования. Если индекс имеет соответствующую пометку, ядро соглашается, что это индекс точки монтирования. Оно обнаруживает в таблице монтирования запись с указанным индексом точки монтирования и запоминает номер устройства монтируемой файловой системы. Затем, используя номер устройства и номер индекса корня, общего для всех файловых систем, ядро обращается к индексу корня монтируемого устройства и возвращает при выходе из функции этот индекс. В первом примере смены каталога ядро обращается к индексу каталога "/usr" из файловой системы, в которой производится монтирование, обнаруживает, что этот индекс имеет пометку "точка монтирования", находит в таблице монтирования индекс корня монтируемой файловой системы и обращается к этому индексу.
Структуры данных после открытия
Рисунок 5.3. Структуры данных после открытия

fd1 = open("/etc/passwd",O_RDONLY); fd2 = open("private",O_RDONLY);
На Рисунке 5.4 показана взаимосвязь между соответствующими структурами данных, когда оба процесса (и больше никто) имеют открытые файлы. Снова результатом каждого вызова функции open является выделение уникальной точки входа в таблице пользовательских дескрипторов файла и в таблице файлов ядра, и ядро хранит не более одной записи на каждый файл в таблице индексов, размещенных в памяти.
Запись в таблице пользовательских дескрипторов файла по умолчанию хранит смещение в файле до адреса следующей операции ввода-вывода и указывает непосредственно на точку входа в таблице индексов для файла, устраняя необходимость в отдельной таблице файлов ядра. Вышеприведенные примеры показывают взаимосвязь между записями таблицы пользовательских дескрипторов файла и записями в таблице файлов ядра типа "один к одному". Томпсон, однако, отмечает, что им была реализована таблица файлов как отдельная структура, позволяющая совместно использовать один и тот же указатель смещения нескольким пользовательским дескрипторам файла (см. [Thompson 78], стр.1943). В системных функциях dup и fork, рассматриваемых в разделах 5.13 и 7.1, при работе со структурами данных допускается такое совместное использование.
Структуры данных после того, как
Рисунок 5.4. Структуры данных после того, как два процесса произвели открытие файлов

Первые три пользовательских дескриптора (0, 1 и 2) именуются дескрипторами файлов: стандартного ввода, стандартного вывода и стандартного файла ошибок. Процессы в системе UNIX по договоренности используют дескриптор файла стандартного ввода при чтении вводимой информации, дескриптор файла стандартного вывода при записи выводимой информации и дескриптор стандартного файла ошибок для записи сообщений об ошибках. В операционной системе нет никакого указания на то, что эти дескрипторы файлов являются специальными. Группа пользователей может условиться о том, что файловые дескрипторы, имеющие значения 4, 6 и 11, являются специальными, но более естественно начинать отсчет с 0 (как в языке Си). Принятие соглашения сразу всеми пользовательскими программами облегчит связь между ними при использовании каналов, в чем мы убедимся в дальнейшем, изучая главу 7. Обычно операторский терминал (см. главу 10) служит и в качестве стандартного ввода, и в качестве стандартного вывода и в качестве стандартного устройства вывода сообщений об ошибках.
. Структуры данных после выполнения функции dup
Рисунок 5.20. Структуры данных после выполнения функции dup

Возможно, dup - функция, не отличающаяся изяществом, поскольку она предполагает, что пользователь знает о том, что система возвратит свободную точку входа в таблице пользовательских дескрипторов, имеющую наименьший номер. Однако, она служит важной задаче конструирования сложных программ из более простых конструкционных блоков, что, в частности, имеет место при создании конвейеров, составленных из командных процессоров.
Рассмотрим программу, приведенную на Рисунке 5.21. В переменной i хранится дескриптор файла, возвращаемый в результате открытия файла "/etc/passwd", а в переменной j - дескриптор файла, возвращаемый системой в результате дублирования дескриптора i с помощью функции dup. В адресном пространстве процесса оба пользовательских дескриптора, представленные переменными i и j, ссылаются на одну и ту же запись в таблице файлов и поэтому используют одно и то же значение смещения внутри файла. Таким образом, первые два вызова процессом функции read реализуют последовательное считывание данных, и в буферах buf1 и buf2 будут располагаться разные данные. Совсем другой результат получается, когда процесс открывает один и тот же файл дважды и читает дважды одни и те же данные (раздел 5.2). Процесс может освободить с помощью функции close любой из файловых дескрипторов по своему желанию, и ввод-вывод получит нормальное продолжение по другому дескриптору, как показано на примере. В частности, процесс может "закрыть" дескриптор файла стандартного вывода (файловый дескриптор 1), снять с него копию, имеющую то же значение, и затем рассматривать новый файл в качестве файла стандартного вывода. В главе 7 будет представлен более реалистический пример использования функций pipe и dup при описании особенностей реализации командного процессора.
. Структуры восстановления семафоров
Рисунок 11.16. Структуры восстановления семафоров
Ядро выделяет структуры восстановления динамически, во время первого выполнения системной функции semop с установленным флагом SEM_UNDO. При последующих обращениях к функции с тем же флагом ядро просматривает структуры восстановления для процесса в поисках структуры с тем же самым идентификатором и порядковым номером семафора, что и в формате вызова функции. Если структура обнаружена, ядро вычитает значение произведенной над семафором операции из установочного значения. Таким образом, в структуре восстановления хранится результат вычитания суммы значений всех операций, произведенных над семафором, для которого установлен флаг SEM_UNDO. Если соответствующей структуры нет, ядро создает ее, сортируя при этом список структур по идентификаторам и номерам семафоров. Если установочное значение становится равным 0, ядро удаляет структуру из списка. Когда процесс завершается, ядро вызывает специальную процедуру, которая просматривает все связанные с процессом структуры восстановления и выполняет над указанным семафором все обусловленные действия.
Таблицы файлов, дескрипторов файла и индексов
Рисунок 2.2. Таблицы файлов, дескрипторов файла и индексов

Обычные файлы и каталоги хранятся в системе UNIX на устройствах ввода-вывода блоками, таких как магнитные ленты или диски. Поскольку существует некоторое различие во времени доступа к этим устройствам, при установке системы UNIX на лентах размещают файловые системы. С годами бездисковые автоматизированные рабочие места станут общим случаем, и файлы будут располагаться в удаленной системе, доступ к которой будет осуществляться через сеть (см. главу 13). Для простоты, тем не менее, в последующем тексте подразумевается использование дисков. В системе может быть несколько физических дисков, на каждом из которых может размещаться одна и более файловых систем. Разбивка диска на несколько файловых систем облегчает администратору управление хранимыми данными. На логическом уровне ядро имеет дело с файловыми системами, а не с дисками, при этом каждая система трактуется как логическое устройство, идентифицируемое номером. Преобразование адресов логического устройства (файловой системы) в адреса физического устройства (диска) и обратно выполняется дисковым драйвером. Термин "устройство" в этой книге используется для обозначения логического устройства, кроме специально оговоренных случаев.
Файловая система состоит из последовательности логических блоков длиной 512, 1024, 2048 или другого числа байт, кратного 512, в зависимости от реализации системы. Размер логического блока внутри одной файловой системы постоянен, но может варьироваться в разных файловых системах в данной конфигурации. Использование логических блоков большого размера увеличивает скорость передачи данных между диском и памятью, поскольку ядро сможет передать больше информации за одну дисковую операцию, и сокращает количество продолжительных операций. Например, чтение 1 Кбайта с диска за одну операцию осуществляется быстрее, чем чтение 512 байт за две. Однако, если размер логического блока слишком велик, полезный объем памяти может уменьшиться, это будет показано в главе 5. Для простоты термин "блок" в этой книге будет использоваться для обозначения логического блока, при этом подразумевается логический блок размером 1 Кбайт, кроме специально оговоренных случаев.
. Таблицы после закрытия файла
Рисунок 5.11. Таблицы после закрытия файла

Точки входа для драйверов
Рисунок 10.1. Точки входа для драйверов
Третий случай выделения буфера
Рисунок 3.8. Третий случай выделения буфера

. Удаление символов из символьного списка
Рисунок 10.11. Удаление символов из символьного списка
. Удаление связи с открытым файлом
Рисунок 5.33. Удаление связи с открытым файлом
| #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> main(argc,argv) int argc; char *argv[]; { int fd; char buf[1024]; struct stat statbuf; if (argc != 2) /* нужен параметр */ exit(); fd = open(argv[1],O_RDONLY); if (fd == -1) /* open завершилась неудачно */ exit(); if (unlink(argv[1]) == -1) /* удалить связь с только что открытым файлом */ exit(); if (stat(argv[1],&statbuf) == -1) /* узнать состоя- ние файла по имени */ printf("stat %s завершилась неудачно\n",argv[1]); /* как и следовало бы */ else printf("stat %s завершилась успешно!\n",argv[1]); if (fstat(fd,&statbuf) == -1) /* узнать состояние файла по идентификатору */ printf("fstat %s сработала неудачно!\n",argv[1]); else printf("fstat %s завершилась успешно\n",argv[1]); /* как и следовало бы */ while (read(fd,buf,sizeof(buf)) > 0) /* чтение откры- того файла с удаленной связью */ printf("%1024s",buf); /* вывод на печать поля размером 1 Кбайт */ } |
Процесс может удалить связь файла в то время, как другому процессу нужно, чтобы файл оставался открытым. (Даже процесс, удаляющий связь, может быть процессом, выполнившим это открытие). Поскольку ядро снимает с индекса блокировку по окончании выполнения функции open, функция unlink завершится успешно. Ядро будет выполнять алгоритм unlink точно так же, как если бы файл не был открыт, и удалит из каталога запись о файле. Теперь по имени удаленной связи к файлу не сможет обратиться никакой другой процесс. Однако, так как системная функция open увеличила значение счетчика ссылок в индексе, ядро не очищает содержимое файла при выполнении алгоритма iput перед завершением функции unlink. Поэтому процесс, открывший файл, может производить над файлом все обычные действия по его дескриптору, включая чтение из файла и запись в файл. Но когда процесс закрывает файл, значение счетчика ссылок в алгоритме iput становится равным 0, и ядро очищает содержимое файла. Короче говоря, процесс, открывший файл, продолжает работу так, как если бы функция unlink не выполнялась, а unlink, в свою очередь, работает так, как если бы файл не был открыт. Другие системные функции также могут продолжать выполняться в процессе, открывшем файл.
В приведенном на Рисунке 5.33 примере процесс открывает файл, указанный в качестве параметра, и затем удаляет связь только что открытого файла. Функция stat завершится неудачно, поскольку первоначальное имя после unlink больше не указывает на файл (предполагается, что тем временем никакой другой процесс не создал файл с тем же именем), но функция fstat завершится успешно, так как она выбирает индекс по дескриптору файла. Процесс выполняет цикл, считывая на каждом шаге по 1024 байта и пересылая файл в стандартный вывод. Когда при чтении будет обнаружен конец файла, процесс завершает работу: после завершения процесса файл перестает существовать. Процессы часто создают временные файлы и сразу же удаляют связь с ними; они могут продолжать ввод-вывод в эти файлы, но имена файлов больше не появляются в иерархии каталогов. Если процесс по какой-либо причине завершается аварийно, он не оставляет от временных файлов никакого следа.
. Увеличение области стека на 1 Кбайт
Рисунок 6.22. Увеличение области стека на 1 Кбайт
Если ядро загружает область команд, которая может разделяться несколькими процессами, возможна ситуация, когда процесс попытается воспользоваться областью до того, как ее содержимое будет полностью загружено, так как процесс загрузки может приостановиться во время чтения файла. Подробно о том, как это происходит и почему при этом нельзя использовать блокировки, мы поговорим, когда будем вести речь о функции exec в следующей главе и в главе 9. Чтобы устранить эту проблему, ядро проверяет статус области и не разрешает к ней доступ до тех пор, пока загрузка области не будет закончена. По завершении реализации алгоритма loadreg ядро возобновляет выполнение всех процессов, ожидающих окончания загрузки области, и изменяет статус области ("готова, загружена в память").
Предположим, например, что ядру нужно загрузить текст размером 7K в область, присоединенную к процессу по виртуальному адресу 0, но при этом оставить промежуток размером 1 Кбайт от начала области (Рисунок 6.24). К этому времени ядро уже выделило запись в таблице областей и присоединило область по адресу 0 с помощью алгоритмов allocreg и attachreg. Теперь же ядро запускает алгоритм loadreg, в котором действия алгоритма growreg выполняются дважды - во-первых, при выделении в начале области промежутка в 1 Кбайт, и во-вторых, при выделении места для содержимого области - и алгоритм growreg назначает для области таблицу страниц. Затем ядро заносит в соответствующие поля пространства процесса установочные значения для чтения данных из файла: считываются 7 Кбайт, начиная с адреса, указанного в виде смещения внутри файла (параметр алгоритма), и записываются в виртуальное пространство процесса по адресу 1K.
. Включение новой записи в таблицу ответных сигналов
Рисунок 8.10. Включение новой записи в таблицу ответных сигналов
На Рисунке 8.10 приведен пример добавления новой записи в таблицу ответных сигналов. (К отрицательному значению поля "время до запуска" для функции a мы вернемся несколько позже). Создавая новую запись, ядро отводит для нее надлежащее место и соответствующим образом переустанавливает значение поля "время до запуска" в записи, следующей за добавляемой. Судя по рисунку, ядро собирается запустить функцию f через 5 таймерных тиков: оно отводит место для нее в таблице сразу после функции b и заносит в поле "время до запуска" значение, равное 2 (тогда сумма значений этих полей для функций b и f составит 5), и меняет "время до запуска" функции c на 8 (при этом функция c все равно запускается через 13 таймерных тиков). В одних версиях ядро пользуется связным списком указателей на записи таблицы ответных сигналов, в других меняет положение записей при корректировке таблицы. Последний способ требует значительно меньших издержек при условии, что ядро не будет слишком часто обращаться к таблице.
При каждом поступлении прерывания по таймеру программа обработки прерывания проверяет наличие записей в таблице ответных сигналов и в случае их обнаружения уменьшает значение поля "время до запуска" в первой записи. Способ хранения продолжительности интервалов до момента запуска каждой функции, выбранный ядром, позволяет, уменьшив значение поля "время до запуска" в одной только первой записи, соответственно уменьшить продолжительность интервала до момента запуска функций, описанных во всех записях таблицы. Если в указанном поле первой записи хранится отрицательное или нулевое значение, соответствующую функцию следует запустить. Программа обработки прерываний по таймеру не запускает функцию немедленно, таким образом она не блокирует возникновение последующих прерываний данного типа. Текущий приоритет работы процессора вроде бы не позволяет таким прерываниям вмешиваться в выполнение процесса, однако ядро не имеет представления о том, сколько времени потребуется на исполнение функции. Казалось бы, если функция выполняется дольше одного таймерного тика, все последующие прерывания должны быть заблокированы. Вместо этого, программа обработки прерываний в типичной ситуации оформляет вызов функции как "программное прерывание", порождаемое выполнением отдельной машинной команды. Поскольку среди всех прерываний программные прерывания имеют самый низкий приоритет, они блокируются, пока ядро не закончит обработку всех остальных прерываний. С момента завершения подготовки к запуску функции и до момента возникновения вызываемого запуском функции программного прерывания может произойти множество прерываний, в том числе и программных, в таком случае в поле "время до запуска", принадлежащее первой записи таблицы, будет занесено отрицательное значение. Когда же наконец программное прерывание происходит, программа обработки прерываний убирает из таблицы все записи с истекшими значениями полей "время до запуска" и вызывает соответствующую функцию.
Поскольку в указанном поле в начальных записях таблицы может храниться отрицательное или нулевое значение, программа обработки прерываний должна найти в таблице первую запись с положительным значением поля и уменьшить его. Пусть, например, функции a соответствует "время до запуска", равное -2 (Рисунок 8.10), то есть перед тем, как функция a была выбрана на выполнение, система получила 2 прерывания по таймеру. При условии, что функция b 2 тика назад уже была в таблице, ядро пропускает запись, соответствующую функции a, и уменьшает значение поля "время до запуска" для функции b.
. Включение символов в символьный список
Рисунок 10.12. Включение символов в символьный список
Второй случай выделения буфера
Рисунок 3.7. Второй случай выделения буфера

Если при выполнении алгоритма getblk имеет место случай 3, ядро так же должно выделить буфер из списка свободных буферов. Однако, оно обнаруживает, что удаляемый из списка буфер был помечен для отложенной переписи, поэтому прежде чем использовать буфер ядро должно переписать его содержимое на диск. Ядро приступает к асинхронной записи на диск и пытается выделить другой буфер из списка. Когда асинхронная запись заканчивается, ядро освобождает буфер и помещает его в начало списка свободных буферов. Буфер сам продвинулся от конца списка свободных буферов к началу списка. Если после асинхронной переписи ядру бы понадобилось поместить буфер в конец списка, буфер получил бы "зеленую улицу" по всему списку свободных буферов, результат такого перемещения противоположен действию алгоритма поиска буферов, к которым наиболее долго не было обращений. Например, если обратиться к Рисунку 3.8, ядро не смогло обнаружить блок 18, но когда попыталось выделить первые два буфера (по очереди) в списке свободных буферов, то оказалось, что они оба помечены для отложенной переписи. Ядро удалило их из списка, запустило операции переписи на диск в соответствующие блоки, и выделило третий буфер из списка, блок 4. Далее ядро присвоило новые значения полям буфера "номер устройства" и "номер блока" и включило буфер, получивший имя "блок 18", в новую хеш-очередь.
В четвертом случае (Рисунок 3.9) ядро, работая с процессом A, не смогло найти дисковый блок в соответствующей хеш-очереди и предприняло попытку выделить из списка свободных буферов новый буфер, как в случае 2. Однако, в списке не оказалось ни одного буфера, поэтому процесс A приостановился до тех пор, пока другим процессом не будет выполнен алгоритм brelse, высвобождающий буфер. Планируя выполнение процесса A, ядро вынуждено снова просматривать хеш-очередь в поисках блока. Оно не в состоянии немедленно выделить буфер из списка свободных буферов, так как возможна ситуация, когда свободный буфер ожидают сразу несколько процессов и одному из них будет выделен вновь освободившийся буфер, на который уже нацелился процесс A. Таким образом, алгоритм поиска блока снова гарантирует, что только один буфер включает содержимое дискового блока. На Рисунке 3.10 показана конкуренция между двумя процессами за освободившийся буфер.
Последний случай (Рисунок 3.11) наиболее сложный, поскольку он связан с комплексом взаимоотношений между несколькими процессами. Предположим, что ядро, работая с процессом A, ведет поиск дискового блока и выделяет буфер, но приостанавливает выполнение процесса перед освобождением буфера. Например, если процесс A попытается считать дисковый блок и выделить буфер, как в случае 2, то он приостановится до момента завершения передачи данных с диска. Предположим, что пока процесс A приостановлен, ядро активизирует второй процесс, B, который пытается обратиться к дисковому блоку, чей буфер был только что заблокирован процессом A. Процесс B (случай 5) обнаружит этот захваченный блок в хеш-очереди. Так как использовать захваченный буфер не разрешается и, кроме того, нельзя выделить для одного и того же дискового блока второй буфер, процесс B помечает буфер как "запрошенный" и затем приостанавливается до того момента, когда процесс A освободит данный буфер.
В конце концов процесс A освобождает буфер и замечает, что он запрошен. Тогда процесс A "будит" все процессы, приостановленные по событию "буфер становится свободным", включая и процесс B. Когда же ядро вновь запустит на выполнение процесс B, процесс B должен будет убедиться в том, что буфер свободен. Возможно, что третий процесс, C, ждал освобождения этого же буфера, и ядро запланировало активизацию процесса C раньше B; при этом процесс C мог приостановиться и оставить буфер заблокированным. Следовательно, процесс B должен проверить то, что блок действительно свободен.
Выделение пространства на устройстве
Рисунок 9.5. Выделение пространства на устройстве выгрузки, описанного во второй строке карты памяти
В традиционной реализации системы UNIX используется одно устройство выгрузки, однако в последних редакциях версии V допускается уже наличие множества устройств выгрузки. Ядро выбирает устройство выгрузки по схеме "кольцевого списка" при условии, что на устройстве имеется достаточный объем непрерывного адресного пространства. Администраторы могут динамически создавать и удалять из системы устройства выгрузки. Если устройство выгрузки удаляется из системы, ядро не выгружает данные на него; если же данные подкачиваются с удаляемого устройства, сначала оно опорожняется и только после освобождения принадлежащего устройству пространства устройство может быть удалено из системы.
Выделение пространства на устройстве выгрузки
Рисунок 9.3. Выделение пространства на устройстве выгрузки
Возвращаясь к предыдущему примеру, отметим, что если ядро освобождает 50 единиц ресурса, начиная с адреса 101, в карте памяти появится новая строка, поскольку освободившиеся ресурсы имеют адреса, не соприкасающиеся с адресами существующих строк карты. Если же затем ядро освободит 100 единиц ресурса, начиная с адреса 1, первая строка карты будет расширена, поскольку освободившиеся ресурсы имеют адрес, смежный с адресом первой строки. Эволюция состояний карты памяти для данного случая показана на Рисунке 9.4.
Предположим, что ядру был сделан запрос на выделение 200 единиц (блоков) пространства устройства выгрузки. Поскольку первая строка карты содержит информацию только о 150 единицах, ядро привлекает для удовлетворения запроса информацию из второй строки (см. Рисунок 9.5). Наконец, предположим, что ядро освобождает 350 единиц пространства, начиная с адреса 151. Несмотря на то, что эти 350 единиц были выделены ядром в разное время, не существует причины, по которой ядро не могло бы освободить их все сразу. Ядро узнает о том, что освободившиеся ресурсы полностью закрывают разрыв между первой и второй строками карты, и вместо прежних двух создает одну строку, в которую включает и освободившиеся ресурсы.
. Взаимная блокировка процессов при выполнении функции link
Рисунок 5.30. Взаимная блокировка процессов при выполнении функции link

На Рисунке 5.31 представлен алгоритм функции unlink. Сначала для поиска файла с удаляемой связью ядро использует модификацию алгоритма namei, которая вместо индекса файла возвращает индекс родительского каталога. Ядро обращается к индексу файла в памяти, используя алгоритм iget. (Особый случай, связанный с удалением имени файла ".", будет рассмотрен в упражнении). После проверки отсутствия ошибок и (для исполняемых файлов) удаления из таблицы областей записей с неактивным разделяемым текстом (глава 7) ядро стирает имя файла из родительского каталога: сделать значение номера индекса равным 0 достаточно для очистки места, занимаемого именем файла в каталоге. Затем ядро производит синхронную запись каталога на диск, гарантируя тем самым, что под своим прежним именем файл уже не будет доступен, уменьшает значение счетчика связей и с помощью алгоритма iput освобождает в памяти индексы родительского каталога и файла с удаляемой связью.
При освобождении в памяти по алгоритму iput индекса файла с удаляемой связью, если значения счетчика ссылок и счетчика связей становятся равными 0, ядро забирает у файла обратно дисковые блоки, которые он занимал. На этот индекс больше не указывает ни одно из файловых имен и индекс неактивен. Для того, чтобы забрать дисковые блоки, ядро в цикле просматривает таблицу содержимого индекса, освобождая все блоки прямой адресации немедленно (в соответствии с алгоритмом free). Что касается блоков косвенной адресации, ядро освобождает все блоки, появляющиеся на различных уровнях косвенности, рекурсивно, причем в первую очередь освобождаются блоки с меньшим уровнем. Оно обнуляет номера блоков в таблице содержимого индекса и устанавливает размер файла в индексе равным 0. Затем ядро очищает в индексе поле типа файла, указывая тем самым, что индекс свободен, и освобождает индекс по алгоритму ifree. Ядро делает необходимую коррекцию на диске, так как дисковая копия индекса все еще указывает на то, что индекс используется; теперь индекс свободен для назначения другим файлам.
. Взаимосвязь между процессами
Рисунок 7.29. Взаимосвязь между процессами, исполняющими командную строку ls -l|wc
Из приведенного текста программы видно, как shell обрабатывает командную строку, используя один канал. Допустим, что командная строка имеет вид:
ls -l|wcПосле создания родительским процессом нового процесса процесс-потомок создает канал. Затем процесс-потомок создает свое ответвление; он и его потомок обрабатывают по одной компоненте командной строки. "Внучатый" процесс исполняет первую компоненту строки (ls): он собирается вести запись в канал, поэтому он закрывает старый файл стандартного вывода, передает его дескриптор каналу и закрывает старый дескриптор записи в канал, в котором (в дескрипторе) уже нет необходимости. Родитель (wc) "внучатого" процесса (ls) является потомком основного процесса, реализующего программу shell'а (см. Рисунок 7.29). Этот процесс (wc) закрывает свой файл стандартного ввода и передает его дескриптор каналу, в результате чего канал становится файлом стандартного ввода. Затем закрывается старый и уже не нужный дескриптор чтения из канала и исполняется вторая компонента командной строки. Оба порожденных процесса выполняются асинхронно, причем выход одного процесса поступает на вход другого. Тем временем основной процесс дожидается завершения своего потомка (wc), после чего продолжает свою обычную работу: по завершении процесса, выполняющего команду wc, вся командная строка является обработанной. Shell возвращается в цикл и считывает следующую командную строку.
. Взаимосвязь между структурами
Рисунок 9.14. Взаимосвязь между структурами данных, участвующими в реализации механизма замещения страниц по обращению
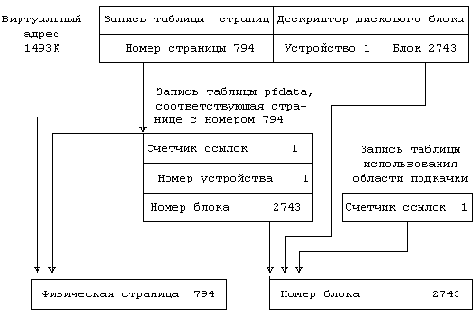
Теперь на страницу могут ссылаться обе области, использующие эту страницу совместно, пока процесс не ведет на нее запись. Как только страница понадобится процессу для записи, ядро создаст ее копию, с тем, чтобы у каждой области была своя личная версия страницы. Для этого при выполнении функции fork в каждой записи таблицы страниц, соответствующей частным областям родителя и потомка, ядро устанавливает бит "копирования при записи". Если один из процессов попытается что-то записать на страницу, он получит отказ системы защиты, после чего для него будет создана новая копия содержимого страницы. Таким образом, физическое копирование страницы откладывается до того момента, когда в этом возникнет реальная потребность.
В качестве примера рассмотрим Рисунок 9.15. Процессы разделяют доступ к таблице страниц совместно используемой области команд T, поэтому значение счетчика ссылок на область равно 2, а на страницы области единице (в таблице pfdata). Ядро назначает процессу-потомку новую область данных C1, являющуюся копией области P1 процесса-родителя. Обе области используют одни и те же записи таблицы страниц, это видно на примере страницы с виртуальным адресом 97К. Этой странице в таблице pfdata соответствует запись с номером 613, счетчик ссылок в которой равен 2, ибо на страницу ссылаются две области.
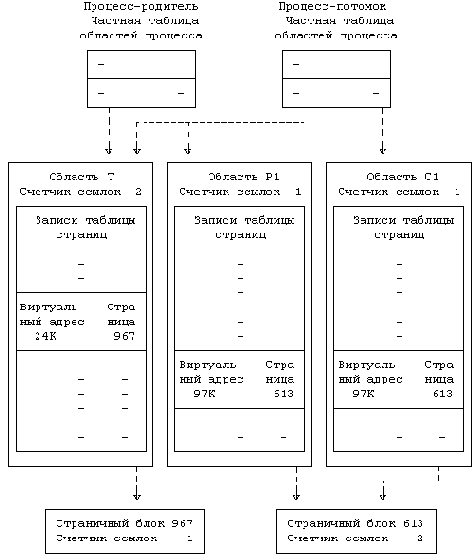
Заголовок буфера
Рисунок 3.1. Заголовок буфера

. Загрузка области команд (текста)
Рисунок 6.24. Загрузка области команд (текста)
Загрузка процесса в память
Рисунок 9.7. Загрузка процесса в память
9.1.2.1 Выгрузка при выполнении системной функции fork
В описании системной функции fork (раздел 7.1) предполагалось, что процесс-родитель получил в свое распоряжение память, достаточную для создания контекста потомка. Если это условие не выполняется, ядро выгружает процесс из памяти, не освобождая пространство памяти, занимаемое его (родителя) копией. Когда процедура выгрузки завершится, процесс-потомок будет располагаться на устройстве выгрузки; процесс-родитель переводит своего потомка в состояние "готовности к выполнению" (см. Рисунок 6.1) и возвращается в режим задачи. Поскольку процесс-потомок находится в состоянии "готовности к выполнению", программа подкачки в конце концов загрузит его в память, где ядро запустит его на выполнение; потомок завершит тем самым свою роль в выполнении системной функции fork и вернется в режим задачи.
9.1.2.2 Выгрузка с расширением
Если процесс испытывает потребность в дополнительной физической памяти, либо в результате расширения стека, либо в результате запуска функции brk, и если эта потребность превышает доступные резервы памяти, ядро выполняет операцию выгрузки процесса с расширением его размера на устройстве выгрузки. На устройстве выгрузки ядро резервирует место для размещения процесса с учетом расширения его размера. Затем производится перенастройка таблицы преобразования адресов процесса с учетом дополнительного виртуального пространства, но без выделения физической памяти (в связи с ее отсутствием). Наконец, ядро выгружает процесс, выполняя процедуру выгрузки обычным порядком и обнуляя вновь выделенное пространство на устройстве (см. Рисунок 9.8). Когда несколько позже ядро будет загружать процесс обратно в память, физическое пространство будет выделено уже с учетом нового состояния таблицы преобразования адресов. В момент возобновления у процесса уже будет в распоряжении память достаточного объема.
. Загрузка процессов в случае
Рисунок 9.11. Загрузка процессов в случае разбивки временных интервалов на части

(*) Для простоты виртуальное адресное пространство процесса на этом и на всех последующих рисунках изображается в виде линейного массива точек входа в таблицу страниц, не принимая во внимание тот факт, что каждая область обычно имеет свою отдельную таблицу страниц.
(**) В версии 6 системы UNIX процесс не может быть выгружен из памяти с целью расчистки места для загружаемого процесса до тех пор, пока загружаемый процесс не проведет на диске 3 секунды. Уходящий из памяти процесс должен провести в памяти не менее 2 секунд. Временной интервал таким образом делится на части, в результате чего повышается производительность системы.
. Записи таблицы страниц и дескрипторы дисковых блоков
Рисунок 9.13. Записи таблицы страниц и дескрипторы дисковых блоков
Каждая запись таблицы страниц связана с дескриптором дискового блока, описывающим дисковую копию виртуальной страницы (Рисунок 9.13). Поэтому процессы, использующие разделяемую область, обращаются к общим записям таблицы страниц и к одним и тем же дескрипторам дисковых блоков. Содержимое виртуальной страницы располагается либо в отдельном блоке на устройстве выгрузки, либо в исполняемом файле, либо вообще отсутствует на устройстве выгрузки. Если страница находится на устройстве выгрузки, в дескрипторе дискового блока содержится логический номер устройства и номер блока, по которым можно отыскать содержимое страницы. Если страница содержится в исполняемом файле, в дескрипторе дискового блока располагается номер логического блока в файле с содержимым страницы; ядро может быстро преобразовать этот номер в адрес на диске. В дескрипторе дискового блока также имеется информация о двух устанавливаемых функцией exec особых условиях: страница при обращении к ней заполняется ("demand fill") или обнуляется ("demand zero"). Разъяснения по этому поводу даются в разделе 9.2.1.2.
В таблице pfdata описывается каждая страница физической памяти. Записи таблицы проиндексированы по номеру страницы и состоят из следующих полей:
Статус страницы, указывающий на то, что страница располагается на устройстве выгрузки или в исполняемом файле, что к странице произведено обращение по прямому доступу в память (путем считывания информации с устройства выгрузки), или на то, что страница может быть переназначена. Количество процессов, ссылающихся на страницу. Счетчик ссылок хранит число записей в таблице страниц, имеющих ссылку на текущую страницу. Это значение может отличаться от количества процессов, использующих разделяемую область с данной страницей, в чем мы убедимся чуть позже, когда будем снова обращаться к алгоритму функции fork. Логический номер устройства (устройства выгрузки или файловой системы) и номер блока, указывающие расположение содержимого страницы. Указатели на другие записи таблицы pfdata в соответствии со списком свободных страниц или с хеш-очередью страниц.По аналогии с буферным кэшем ядро связывает записи таблицы pfdata в список свободных страниц и хеш-очередь. Список свободных страниц представляет собой буфер, который содержит страницы, доступные для переназначения, однако процесс, обратившийся к этим страницам, может столкнуться с ошибкой адресации, так и не получив соответствующую страницу из списка. Этот список дает ядру возможность сократить число операций чтения с устройства выгрузки. Ядро выделяет страницы из этого списка по вышеназванному принципу замещения "стариков". Ядро выстраивает записи таблицы в хеш-очередь в соответствии с номером устройства (выгрузки) и номером блока. Используя эти номера, ядро может быстро отыскать страницу, если она находится в памяти. Передавая физическую страницу области, ядро выбирает соответствующую запись из списка свободных страниц, исправляет указанные в ней номера устройства и блока и помещает ее в соответствующее место хеш-очереди.
Каждая запись таблицы использования области подкачки соответствует странице, находящейся на устройстве выгрузки. Запись содержит счетчик ссылок, показывающий количество записей таблицы страниц, в которых имеется ссылка на текущую страницу.
На Рисунке 9.14 показана взаимосвязь между записями таблицы страниц, дескрипторами дисковых блоков, записями таблицы pfdata и таблицы использования области подкачки. Виртуальный адрес 1493К отображается на запись таблицы страниц, соответствующую странице с физическим номером 794; дескриптор дискового блока, связанный с этой записью, свидетельствует о том, что содержимое страницы располагается на устройстве выгрузки с номером 1 в дисковом блоке с номером 2743. Запись таблицы pfdata, помимо того, что указывает на те же номера устройства и блока, сообщает, что счетчик ссылок на физическую страницу имеет значение, равное 1. Счетчик ссылок на виртуальную страницу (в записи таблицы использования области подкачки) свидетельствует о том, что на копию страницы на устройстве выгрузки ссылается только одна запись таблицы страниц.
9.2.1.1 Функция fork в системе с замещением страниц
Как уже говорилось в разделе 7.1, во время выполнения функции fork ядро создает копию каждой области родительского процесса и присоединяет ее к процессу-потомку. В системе с замещением страниц ядро по традиции создает физическую копию адресного пространства процесса-родителя, что в общем случае является довольно расточительной операцией, поскольку процесс часто после выполнения функции fork обращается к функции exec и незамедлительно освобождает только что скопированное пространство. Если область разделяемая, в версии V вместо копирования страницы ядро просто увеличивает значение счетчика ссылок на область (в таблице областей, в таблице страниц и в таблице pfdata). Тем не менее, для частных областей, таких как область данных и стека, ядро отводит в таблице областей и таблице страниц новую запись, после чего просматривает в таблице страниц все записи процесса-родителя: если запись верна, ядро увеличивает значение счетчика ссылок в таблице pfdata, отражающее количество процессов, использующих страницу через разные области (в отличие от тех процессов, которые используют данную страницу через разделяемую область). Если страница располагается на устройстве выгрузки, ядро увеличивает значение счетчика ссылок в таблице использования области подкачки.
. Запрашивание и освобождение дисковых блоков
Рисунок 4.20. Запрашивание и освобождение дисковых блоков
