События, вызывающие приостанов выполнения, и их адреса
Как уже говорилось во второй главе, процессы приостанавливаются до наступления определенного события, после которого они "пробуждаются" и переходят в состояние "готовности к выполнению" (с выгрузкой и без выгрузки из памяти). Такого рода абстрактное рассуждение недалеко от истины, ибо в конкретном воплощении совокупность событий отображается на совокупность виртуальных адресов (ядра). Адреса, с которыми связаны события, закодированы в ядре, и их единственное назначение состоит в их использовании в процессе отображения ожидаемого события на конкретный адрес. Как для абстрактного рассмотрения, так и для конкретной реализации события безразлично, сколько процессов одновременно ожидают его наступления. Как результат, возможно возникновение некоторых противоречий. Во-первых, когда событие наступает и процессы, ожидающие его, соответствующим образом оповещаются об этом, все они "пробуждаются" и переходят в состояние "готовности к выполнению". Ядро выводит процессы из состояния приостанова все сразу, а не по одному, несмотря на то, что они в принципе могут конкурировать за одну и ту же заблокированную структуру данных и большинство из них через небольшой промежуток времени опять вернется в состояние приостанова (более подробно об этом шла речь в главах и ). На изображены несколько процессов, приостановленных до наступления определенных событий.
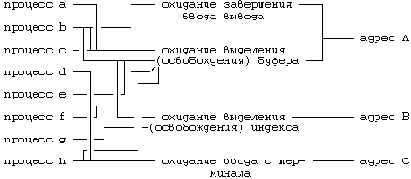
Рисунок 6.30. Процессы, приостановленные до наступления событий, и отображение событий на конкретные адреса
Еще одно противоречие связано с тем, что на один и тот же адрес могут отображаться несколько событий. На , например, события "освобождение буфера" и "завершение ввода-вывода" отображаются на адрес буфера ("адрес A"). Когда ввод-вывод в буфер завершается, ядро возобновляет выполнение всех процессов, приостановленных в ожидании наступления как того, так и другого события. Поскольку процесс, ожидающий завершения ввода-вывода, удерживает буфер заблокированным, другие процессы, которые ждали освобождения буфера, вновь приостановятся, ибо буфер все еще занят. Функционирование системы было бы более эффективным, если бы отображение событий на адреса было однозначным. Однако на практике такого рода противоречие на производительности системы не отражается, поскольку отображение на один адрес более одного события имеет место довольно редко, а также поскольку выполняющийся процесс обычно освобождает заблокированные ресурсы до того, как начнут выполняться другие процессы. Стилистически, тем не менее, механизм функционирования ядра стал бы более понятен, если бы отображение было однозначным.
|
алгоритм sleep входная информация: (1) адрес приостанова (2) приоритет выходная информация: 1, если процесс возобновляется по сиг- налу, который ему удалось уловить; вызов алгоритма longjump, если процесс возобновляется по сигналу, который ему не удалось уловить; 0 - во всех остальных случаях; { поднять приоритет работы процессора таким образом, чтобы заблокировать все прерывания; перевести процесс в состояние приостанова; включить процесс в хеш-очередь приостановленных процес- сов, базирующуюся на адресах приостанова; сохранить адрес приостанова в таблице процессов; сделать ввод для процесса приоритетным; если (приостанов процесса НЕ допускает прерываний) { выполнить переключение контекста; /* с этого места процесс возобновляет выполнение, когда "пробуждается" */ снизить приоритет работы процессора так, чтобы вновь разрешить прерывания (как было до приостанова про- цесса); возвратить (0); } /* приостанов процесса принимает прерывания, вызванные сигналами */ если (к процессу не имеет отношения ни один из сигналов) { выполнить переключение контекста; /* с этого места процесс возобновляет выполнение, когда "пробуждается" */ если (к процессу не имеет отношения ни один из сигна- лов) { восстановить приоритет работы процессора таким, каким он был в момент приостанова процесса; возвратить (0); } } удалить процесс из хеш-очереди приостановленных процес- сов, если он все еще находится там; восстановить приоритет работы процессора таким, каким он был в момент приостанова процесса; если (приоритет приостановленного процесса позволяет принимать сигналы) возвратить (1); запустить алгоритм longjump; } |
Рисунок 6.31. Алгоритм приостанова процесса
Сохранение контекста на случай аварийного завершения
Существуют ситуации, когда ядро вынуждено аварийно прерывать текущий порядок выполнения и немедленно переходить к исполнению ранее сохраненного контекста. В последующих разделах, где пойдет речь о приостановлении выполнения и о сигналах, будут описаны обстоятельства, при которых процессу приходится внезапно изменять свой контекст; в данном же разделе рассматривается механизм исполнения предыдущего контекста. Алгоритм сохранения контекста называется setjmp, а алгоритм восстановления контекста - longjmp . Механизм работы алгоритма setjmp похож на механизм функции save_context, рассмотренный в предыдущем разделе, если не считать того, что функция save_context помещает новый контекстный уровень в стек, в то время как setjmp сохраняет контекст в пространстве процесса и после выхода из него выполнение продолжается в прежнем контекстном уровне. Когда ядру понадобится восстановить контекст, сохраненный в результате работы алгоритма setjmp, оно исполнит алгоритм longjmp, который восстанавливает контекст из пространства процесса и имеет, как и setjmp, код завершения, равный 1.
СОХРАНЕНИЕ КОНТЕКСТА ПРОЦЕССА
Как уже говорилось ранее, ядро сохраняет контекст процесса, помещая в стек новый контекстный уровень. В частности, это имеет место, когда система получает прерывание, когда процесс вызывает системную функцию или когда ядро выполняет переключение контекста. Каждый из этих случаев подробно рассматривается в этом разделе.
Сообщения
С сообщениями работают четыре системных функции: msgget, которая возвращает (и в некоторых случаях создает) дескриптор сообщения, определяющий очередь сообщений и используемый другими системными функциями, msgctl, которая устанавливает и возвращает связанные с дескриптором сообщений параметры или удаляет дескрипторы, msgsnd, которая посылает сообщение, и msgrcv, которая получает сообщение.
Синтаксис вызова системной функции msgget: msgqid = msgget(key,flag);
где msgqid - возвращаемый функцией дескриптор, а key и flag имеют ту же семантику, что и в системной функции типа "get". Ядро хранит сообщения в связном списке (очереди), определяемом значением дескриптора, и использует значение msgqid в качестве указателя на массив заголовков очередей. Кроме вышеуказанных полей, описывающих общие для всего механизма права доступа, заголовок очереди содержит следующие поля:
Указатели на первое и последнее сообщение в списке; Количество сообщений и общий объем информации в списке в байтах; Максимальная емкость списка в байтах; Идентификаторы процессов, пославших и принявших сообщения последними; Поля, указывающие время последнего выполнения функций msgsnd, msgrcv и msgctl.
Когда пользователь вызывает функцию msgget для того, чтобы создать новый дескриптор, ядро просматривает массив очередей сообщений в поисках существующей очереди с указанным идентификатором. Если такой очереди нет, ядро выделяет новую очередь, инициализирует ее и возвращает идентификатор пользователю. В противном случае ядро проверяет наличие необходимых прав доступа и завершает выполнение функции.
Для посылки сообщения процесс использует системную функцию msgsnd: msgsnd(msgqid,msg,count,flag);
где msgqid - дескриптор очереди сообщений, обычно возвращаемый функцией msgget, msg - указатель на структуру, состоящую из типа в виде назначаемого пользователем целого числа и массива символов, count - размер информационного массива, flag - действие, предпринимаемое ядром в случае переполнения внутреннего буферного пространства.
| алгоритм msgsnd /* послать сообщение */ входная информация: (1) дескриптор очереди сообщений (2) адрес структуры сообщения (3) размер сообщения (4) флаги выходная информация: количество посланных байт { проверить правильность указания дескриптора и наличие соответствующих прав доступа; выполнить пока (для хранения сообщения не будет выделено место) { если (флаги не разрешают ждать) вернуться; приостановиться (до тех пор, пока место не освобо- дится); } получить заголовок сообщения; считать текст сообщения из пространства задачи в прост- ранство ядра; настроить структуры данных: выстроить очередь заголовков сообщений, установить в заголовке указатель на текст сообщения, заполнить поля, содержащие счетчики, время последнего выполнения операций и идентификатор процес- са; вывести из состояния приостанова все процессы, ожидающие разрешения считать сообщение из очереди; } |
Рисунок 11.4. Алгоритм посылки сообщения
Ядро проверяет (), имеется ли у посылающего сообщение процесса разрешения на запись по указанному дескриптору, не выходит ли размер сообщения за установленную системой границу, не содержится ли в очереди слишком большой объем информации, а также является ли тип сообщения положительным целым числом. Если все условия соблюдены, ядро выделяет сообщению место, используя карту сообщений (см. ), и копирует в это место данные из пространства пользователя. К сообщению присоединяется заголовок, после чего оно помещается в конец связного списка заголовков сообщений. В заголовке сообщения записывается тип и размер сообщения, устанавливается указатель на текст сообщения и производится корректировка содержимого различных полей заголовка очереди, содержащих статистическую информацию (количество сообщений в очереди и их суммарный объем в байтах, время последнего выполнения операций и идентификатор процесса, пославшего сообщение). Затем ядро выводит из состояния приостанова все процессы, ожидающие пополнения очереди сообщений. Если размер очереди в байтах превышает границу допустимости, процесс приостанавливается до тех пор, пока другие сообщения не уйдут из очереди. Однако, если процессу было дано указание не ждать (флаг IPC_NOWAIT), он немедленно возвращает управление с уведомлением об ошибке. На показана очередь сообщений, состоящая из заголовков сообщений, организованных в связные списки, с указателями на область текста.

Рисунок 11.5. Структуры данных, используемые в организации сообщений
Рассмотрим программу, представленную на . Процесс вызывает функцию msgget для того, чтобы получить дескриптор для записи с идентификатором MSGKEY. Длина сообщения принимается равной 256 байт, хотя используется только первое поле целого типа, в область текста сообщения копируется идентификатор процесса, типу сообщения присваивается значение 1, после чего вызывается функция msgsnd для посылки сообщения. Мы вернемся к этому примеру позже.
Процесс получает сообщения, вызывая функцию msgrcv по следующему формату: count = msgrcv(id,msg,maxcount,type,flag);
где id - дескриптор сообщения, msg - адрес пользовательской структуры, которая будет содержать полученное сообщение, maxcount - размер структуры msg, type - тип считываемого сообщения, flag - действие, предпринимаемое ядром в том случае, если в очереди сообщений нет. В переменной count пользователю возвращается число прочитанных байт сообщения.
Ядро проверяет (), имеет ли пользователь необходимые права доступа к очереди сообщений. Если тип считываемого сообщения имеет нулевое значение, ядро ищет первое по счету сообщение в связном списке. Если его размер меньше или равен размеру, указанному пользователем, ядро копирует текст сообщения в пользовательскую структуру и соответствующим образом настраивает свои внутренние структуры: уменьшает счетчик сообщений в очереди и суммарный объем информации в байтах, запоминает время получения сообщения и идентификатор процесса-получателя, перестраивает связный список и освобождает место в системном пространстве, где хранился текст сообщения. Если какие-либо процессы, ожидавшие получения сообщения, находились в состоянии приостанова из-за отсутствия свободного места в списке, ядро выводит их из этого состояния. Если размер сообщения превышает значение maxcount, указанное пользователем, ядро посылает системной функции уведомление об ошибке и оставляет сообщение в очереди. Если, тем не менее, процесс игнорирует ограничения на размер (в поле flag установлен бит MSG_NOERROR), ядро обрезает сообщение, возвращает запрошенное количество байт и удаляет сообщение из списка целиком.
|
#include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> #define MSGKEY 75 struct msgform { long mtype; char mtext[256]; }; main() { struct msgform msg; int msgid,pid,*pint; msgid = msgget(MSGKEY,0777); pid = getpid(); pint = (int *) msg.mtext; *pint = pid; /* копирование идентификатора * процесса в область текста * сообщения */ msg.mtype = 1; msgsnd(msgid,&msg,sizeof(int),0); msgrcv(msgid,&msg,256,pid,0); /* идентификатор * процесса используется в * качестве типа сообщения */ printf("клиент: получил от процесса с pid %d\n", *pint); } |
Рисунок 11.6. Пользовательский процесс
| алгоритм msgrcv /* получение сообщения */ входная информация: (1) дескриптор сообщения (2) адрес массива, в который заносится сообщение (3) размер массива (4) тип сообщения в запросе (5) флаги выходная информация: количество байт в полученном сообщении { проверить права доступа; loop: проверить правильность дескриптора сообщения; /* найти сообщение, нужное пользователю */ если (тип сообщения в запросе == 0) рассмотреть первое сообщение в очереди; в противном случае если (тип сообщения в запросе > 0) рассмотреть первое сообщение в очереди, имеющее данный тип; в противном случае /* тип сообщения в запросе < 0 */ рассмотреть первое из сообщений в очереди с наи- меньшим значением типа при условии, что его тип не превышает абсолютное значение типа, указанно- го в запросе; если (сообщение найдено) { переустановить размер сообщения или вернуть ошиб- ку, если размер, указанный пользователем слишком мал; скопировать тип сообщения и его текст из прост- ранства ядра в пространство задачи; разорвать связь сообщения с очередью; вернуть управление; } /* сообщений нет */ если (флаги не разрешают приостанавливать работу) вернуть управление с ошибкой; приостановиться (пока сообщение не появится в очере- ди); перейти на loop; } |
Процесс может получать сообщения определенного типа, если присвоит параметру type соответствующее значение. Если это положительное целое число, функция возвращает первое значение данного типа, если отрицательное, ядро определяет минимальное значение типа сообщений в очереди, и если оно не превышает абсолютное значение параметра type, возвращает процессу первое сообщение этого типа. Например, если очередь состоит из трех сообщений, имеющих тип 3, 1 и 2, соответственно, а пользователь запрашивает сообщение с типом -2, ядро возвращает ему сообщение типа 1. Во всех случаях, если условиям запроса не удовлетворяет ни одно из сообщений в очереди, ядро переводит процесс в состояние приостанова, разумеется если только в параметре flag не установлен бит IPC_NOWAIT (иначе процесс немедленно выходит из функции).
Рассмотрим программы, представленные на Рисунках и . Программа на Рисунке осуществляет общее обслуживание запросов пользовательских процессов (клиентов). Запросы, например, могут касаться информации, хранящейся в базе данных; обслуживающий процесс (сервер) выступает необходимым посредником при обращении к базе данных, такой порядок облегчает поддержание целостности данных и организацию их защиты от несанкционированного доступа. Обслуживающий процесс создает сообщение путем установки флага IPC _CREAT при выполнении функции msgget и получает все сообщения типа 1 - запросы от процессов-клиентов. Он читает текст сообщения, находит идентификатор процесса-клиента и приравнивает возвращаемое значение типа сообщения значению этого идентификатора. В данном примере обслуживающий процесс возвращает в тексте сообщения процессу-клиенту его идентификатор, и клиент получает сообщения с типом, равным идентификатору клиента. Таким образом, обслуживающий процесс получает сообщения только от клиентов, а клиент - только от обслуживающего процесса. Работа процессов реализуется в виде многоканального взаимодействия, строящегося на основе одной очереди сообщений.
|
#include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h> #define MSGKEY 75 struct msgform { long mtype; char mtext[256]; }msg; int msgid; main() { int i,pid,*pint; extern cleanup(); for (i = 0; i < 20; i++) signal(i,cleanup); msgid = msgget(MSGKEY,0777IPC_CREAT); for (;;) { msgrcv(msgid,&msg,256,1,0); pint = (int *) msg.mtext; pid = *pint; printf("сервер: получил от процесса с pid %d\n", pid); msg.mtype = pid; *pint = getpid(); msgsnd(msgid,&msg,sizeof(int),0); } } cleanup() { msgctl(msgid,IPC_RMID,0); exit(); } |
Сообщения имеют форму "тип - текст", где текст представляет собой поток байтов. Указание типа дает процессам возможность выбирать сообщения только определенного рода, что в файловой системе не так легко сделать. Таким образом, процессы могут выбирать из очереди сообщения определенного типа в порядке их поступления, причем эта очередность гарантируется ядром. Несмотря на то, что обмен сообщениями может быть реализован на пользовательском уровне средствами файловой системы, представленный вашему вниманию механизм обеспечивает более эффективную организацию передачи данных между процессами.
С помощью системной функции msgctl процесс может запросить информацию о статусе дескриптора сообщения, установить этот статус или удалить дескриптор сообщения из системы. Синтаксис вызова функции: msgctl(id,cmd,mstatbuf)
где id - дескриптор сообщения, cmd - тип команды, mstatbuf - адрес пользовательской структуры, в которой будут храниться управляющие параметры или результаты обработки запроса. Более подробно об аргументах функции пойдет речь в Приложении.
Вернемся к примеру, представленному на . Обслуживающий процесс принимает сигналы и с помощью функции cleanup удаляет очередь сообщений из системы. Если же им не было поймано ни одного сигнала или был получен сигнал SIGKILL, очередь сообщений остается в системе, даже если на нее не ссылается ни один из процессов. Дальнейшие попытки исключительно создания новой очереди сообщений с данным ключом (идентификатором) не будут иметь успех до тех пор, пока старая очередь не будет удалена из системы.
СОПРОВОЖДЕНИЕ ФАЙЛОВОЙ СИСТЕМЫ
Ядро поддерживает целостность системы в своей обычной работе. Тем не менее, такие чрезвычайные обстоятельства, как отказ питания, могут привести к фатальному сбою системы, в результате которого содержимое системы утрачивает свою согласованность: большинство данных в файловой системе доступно для использования, но некоторая несогласованность между ними имеет место. Команда fsck проверяет согласованность данных и в случае необходимости вносит в файловую систему исправления. Она обращается к файловой системе через блочный или строковый интерфейс () в обход традиционных методов доступа к файлам. В этом разделе рассматриваются некоторые примеры противоречивости данных, которая обнаруживается командой fsck.
Дисковый блок может принадлежать более чем одному индексу или списку свободных блоков. Когда файловая система открывается в первый раз, все дисковые блоки находятся в списке свободных блоков. Когда дисковый блок выбирается для использования, ядро удаляет его номер из списка свободных блоков и назначает блок индексу. Ядро не может переназначить дисковый блок другому индексу до тех пор, пока блок не будет возвращен в список свободных блоков. Таким образом, дисковый блок может либо находиться в списке свободных блоков, либо быть назначенным одному из индексов. Рассмотрим различные ситуации, могущие иметь место при освобождении ядром дискового блока, принадлежавшего файлу, с возвращением номера блока в суперблок, находящийся в памяти, и при выделении дискового блока новому файлу. Если ядро записывало на диск индекс и блоки нового файла, но перед внесением изменений в индекс прежнего файла на диске произошел сбой, оба индекса будут адресовать к одному и тому же номеру дискового блока. Подобным же образом, если ядро переписывало на диск суперблок и его списки свободных ресурсов и перед переписью старого индекса случился сбой, дисковый блок появится одновременно и в списке свободных блоков, и в старом индексе.
Если блок отсутствует как в списке свободных блоков, так и в файле, файловая система является несогласованной, ибо, как уже говорилось выше, все блоки обязаны где-нибудь присутствовать. Такая ситуация могла бы произойти, если бы блок был удален из файла и помещен в список свободных блоков в суперблоке. Если производилась запись прежнего файла на диск и система дала сбой перед записью суперблока, блок будет отсутствовать во всех списках, хранящихся на диске.
Индекс может иметь счетчик связей с ненулевым значением при том, что его номер отсутствует во всех каталогах файловой системы. Все файлы, за исключением каналов (непоименованных), должны присутствовать в древовидной структуре файловой системы. Если система дала сбой после создания канала или обычного файла, но перед созданием соответствующей этому каналу или файлу точки входа в каталог, индекс будет иметь в поле счетчика связей установленное значение, пусть даже он явно не присутствует в файловой системе. Еще одна проблема может возникнуть, если с помощью функции unlink была удалена связь каталога без проверки удаления из каталога всех содержащихся в нем связей с отдельными файлами.
Если формат индекса неверен (например, если значение поля типа файла не определено), значит где-то имеется ошибка. Это может произойти, если администратор смонтировал файловую систему, которая отформатирована неправильно. Ядро обращается к тем дисковым блокам, которые, как кажется ядру, содержат индексы, но в действительности оказывается, что они содержат данные.
Если номер индекса присутствует в записи каталога, но сам индекс свободен, файловая система является несогласованной, поскольку номер индекса в записи каталога должен быть номером назначенного индекса. Это могло бы произойти, если бы ядро, создавая новый файл и записывая на диск новую точку входа в каталог, не успела бы скопировать на диск индекс файла из-за сбоя. Также это может случиться, если процесс, удаляя связь файла с каталогом, запишет освободившийся индекс на диск, но не успеет откорректировать каталог из-за сбоя. Возникновение подобных ситуаций можно предотвратить, копируя на диск результаты работы в надлежащем порядке.
Если число свободных блоков или свободных индексов, записанное в суперблоке, не совпадает с их количеством на диске, файловая система так же является несогласованной. Итоговая информация в суперблоке всегда должна соответствовать информации о текущем состоянии файловой системы.
Comments:
Copyright ©
СОСТОЯНИЯ ПРОЦЕССА И ПЕРЕХОДЫ МЕЖДУ НИМИ
Как уже отмечалось в , время жизни процесса можно теоретически разбить на несколько состояний, описывающих процесс. Полный набор состояний процесса содержится в следующем перечне:
Процесс выполняется в режиме задачи. Процесс выполняется в режиме ядра. Процесс не выполняется, но готов к запуску под управлением ядра. Процесс приостановлен и находится в оперативной памяти. Процесс готов к запуску, но программа подкачки (нулевой процесс) должна еще загрузить процесс в оперативную память, прежде чем он будет запущен под управлением ядра. Это состояние будет предметом обсуждения в при рассмотрении системы подкачки. Процесс приостановлен и программа подкачки выгрузила его во внешнюю память, чтобы в оперативной памяти освободить место для других процессов. Процесс возвращен из привилегированного режима (режима ядра) в непривилегированный (режим задачи), ядро резервирует его и переключает контекст на другой процесс. Об отличии этого состояния от состояния 3 (готовность к запуску) пойдет речь ниже. Процесс вновь создан и находится в переходном состоянии; процесс существует, но не готов к выполнению, хотя и не приостановлен. Это состояние является начальным состоянием всех процессов, кроме нулевого. Процесс вызывает системную функцию exit и прекращает существование. Однако, после него осталась запись, содержащая код выхода, и некоторая хронометрическая статистика, собираемая родительским процессом. Это состояние является последним состоянием процесса.
представляет собой полную диаграмму переходов процесса из состояния в состояние. Рассмотрим с помощью модели переходов типичное поведение процесса. Ситуации, которые будут обсуждаться, несколько искусственны и процессы не всегда имеют дело с ними, но эти ситуации вполне применимы для иллюстрации различных переходов. Начальным состоянием модели является создание процесса родительским процессом с помощью системной функции fork; из этого состояния процесс неминуемо переходит в состояние готовности к запуску (3 или 5). Для простоты предположим, что процесс перешел в состояние "готовности к запуску в памяти" (3). Планировщик процессов в конечном счете выберет процесс для выполнения и процесс перейдет в состояние "выполнения в режиме ядра", где доиграет до конца роль, отведенную ему функцией fork.
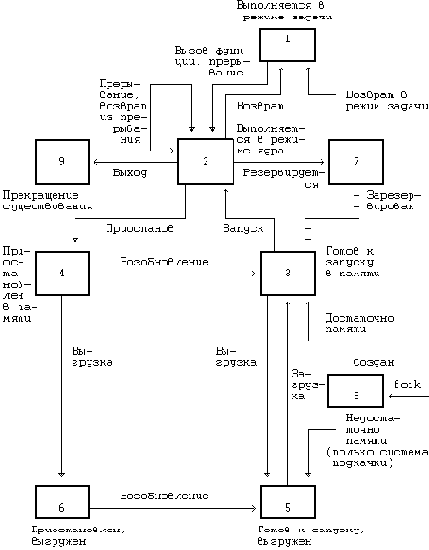
Процесс может управлять некоторыми из переходов на уровне задачи. Во-первых, один процесс может создать другой процесс. Тем не менее, в какое из состояний процесс перейдет после создания (т.е. в состояние "готов к выполнению, находясь в памяти" или в состояние "готов к выполнению, но выгружен") зависит уже от ядра. Процессу эти состояния не подконтрольны. Во-вторых, процесс может обратиться к различным системным функциям, чтобы перейти из состояния "выполнения в режиме задачи" в состояние "выполнения в режиме ядра", а также перейти в режим ядра по своей собственной воле. Тем не менее, момент возвращения из режима ядра от процесса уже не зависит; в результате каких-то событий он может никогда не вернуться из этого режима и из него перейдет в состояние "прекращения существования" (, где говорится о сигналах). Наконец, процесс может завершиться с помощью функции exit по своей собственной воле, но как указывалось ранее, внешние события могут потребовать завершения процесса без явного обращения к функции exit. Все остальные переходы относятся к жестко закрепленной части модели, закодированной в ядре, и являются результатом определенных событий, реагируя на них в соответствии с правилами, сформулированными в этой и последующих главах. Некоторые из правил уже упоминались: например, то, что процесс может выгрузить другой процесс, выполняющийся в ядре.
Две принадлежащие ядру структуры данных описывают процесс: запись в таблице процессов и пространство процесса. Таблица процессов содержит поля, которые должны быть всегда доступны ядру, а пространство процесса - поля, необходимость в которых возникает только у выполняющегося процесса. Поэтому ядро выделяет место для пространства процесса только при создании процесса: в нем нет необходимости, если записи в таблице процессов не соответствует конкретный процесс.
Запись в таблице процессов состоит из следующих полей:
Поле состояния, которое идентифицирует состояние процесса. Поля, используемые ядром при размещении процесса и его пространства в основной или внешней памяти. Ядро использует информацию этих полей для переключения контекста на процесс, когда процесс переходит из состояния "готов к выполнению, находясь в памяти" в состояние "выполнения в режиме ядра" или из состояния "резервирования" в состояние "выполнения в режиме задачи". Кроме того, ядро использует эту информацию при перекачки процессов из и в оперативную память (между двумя состояниями "в памяти" и двумя состояниями "выгружен"). Запись в таблице процессов содержит также поле, описывающее размер процесса и позволяющее ядру планировать выделение пространства для процесса. Несколько пользовательских идентификаторов (UID), устанавливающих различные привилегии процесса. Поля UID, например, описывают совокупность процессов, могущих обмениваться сигналами (см. следующую главу). Идентификаторы процесса (PID), указывающие взаимосвязь между процессами. Значения полей PID задаются при переходе процесса в состояние "создан" во время выполнения функции fork. Дескриптор события (устанавливается тогда, когда процесс приостановлен). В данной главе будет рассмотрено использование дескриптора события в алгоритмах функций sleep и wakeup. Параметры планирования, позволяющие ядру устанавливать порядок перехода процессов из состояния "выполнения в режиме ядра" в состояние "выполнения в режиме задачи". Поле сигналов, в котором перечисляются сигналы, посланные процессу, но еще не обработанные (). Различные таймеры, описывающие время выполнения процесса и использование ресурсов ядра и позволяющие осуществлять слежение за выполнением и вычислять приоритет планирования процесса. Одно из полей является таймером, который устанавливает пользователь и который необходим для посылки процессу сигнала тревоги (). Пространство процесса содержит поля, дополнительно характеризующие состояния процесса. В предыдущих главах были рассмотрены последние семь из приводимых ниже полей пространства процесса, которые мы для полноты вновь кратко перечислим: Указатель на таблицу процессов, который идентифицирует запись, соответствующую процессу. Пользовательские идентификаторы, устанавливающие различные привилегии процесса, в частности, права доступа к файлу (). Поля таймеров, хранящие время выполнения процесса (и его потомков) в режиме задачи и в режиме ядра. Вектор, описывающий реакцию процесса на сигналы. Поле операторского терминала, идентифицирующее "регистрационный терминал", который связан с процессом. Поле ошибок, в которое записываются ошибки, имевшие место при выполнении системной функции. Поле возвращенного значения, хранящее результат выполнения системной функции. Параметры ввода-вывода: объем передаваемых данных, адрес источника (или приемника) данных в пространстве задачи, смещения в файле (которыми пользуются операции ввода-вывода) и т.д. Имена текущего каталога и текущего корня, описывающие файловую систему, в которой выполняется процесс. Таблица пользовательских дескрипторов файла, которая описывает файлы, открытые процессом. Поля границ, накладывающие ограничения на размерные характеристики процесса и на размер файла, в который процесс может вести запись. Поле прав доступа, хранящее двоичную маску установок прав доступа к файлам, которые создаются процессом. Пространство состояний процесса и переходов между ними рассматривалось в данном разделе на логическом уровне. Каждое состояние имеет также физические характеристики, управляемые ядром, в частности, виртуальное адресное пространство процесса. Следующий раздел посвящен описанию модели распределения памяти; в остальных разделах состояния процесса и переходы между ними рассматриваются на физическом уровне, особое внимание при этом уделяется состояниям "выполнения в режиме задачи", "выполнения в режиме ядра", "резервирования" и "приостанова (в памяти)". В следующей главе затрагиваются состояния "создания" и "прекращения существования", а в - состояние "готовности к запуску в памяти". В обсуждаются два состояния выгруженного процесса и организация подкачки по обращению.
Comments:
Copyright ©
СОЗДАНИЕ ФАЙЛА
Системная функция open дает процессу доступ к существующему файлу, а системная функция creat создает в системе новый файл. Синтаксис вызова системной функции creat: fd = creat(pathname,modes);
где переменные pathname, modes и fd имеют тот же смысл, что и в системной функции open. Если прежде такого файла не существовало, ядро создает новый файл с указанным именем и указанными правами доступа к нему; если же такой файл уже существовал, ядро усекает файл (освобождает все существующие блоки данных и устанавливает размер файла равным 0) при наличии соответствующих прав доступа к нему . На Рисунке 5.12 приведен алгоритм создания файла.
| алгоритм creat входная информация: имя файла установки прав доступа к файлу выходная информация: дескриптор файла { получить индекс для данного имени файла (алгоритм namei); если (файл уже существует) { если (доступ не разрешен) { освободить индекс (алгоритм iput); возвратить (ошибку); } } в противном случае /* файл еще не существует */ { назначить свободный индекс из файловой системы (алго- ритм ialloc); создать новую точку входа в родительском каталоге: включить имя нового файла и номер вновь назначенного индекса; } выделить для индекса запись в таблице файлов, инициализи- ровать счетчик; если (файл существовал к моменту создания) освободить все блоки файла (алгоритм free); снять блокировку (с индекса); возвратить (пользовательский дескриптор файла); } |
Рисунок 5.12. Алгоритм создания файла
Ядро проводит синтаксический анализ имени пути поиска, используя алгоритм namei и следуя этому алгоритму буквально, когда речь идет о разборе имен каталогов. Однако, когда дело касается последней компоненты имени пути поиска, а именно идентификатора создаваемого файла, namei отмечает смещение в байтах до первой пустой позиции в каталоге и запоминает это смещение в пространстве процесса. Если ядро не обнаружило в каталоге компоненту имени пути поиска, оно в конечном счете впишет имя компоненты в только что найденную пустую позицию. Если в каталоге нет пустых позиций, ядро запоминает смещение до конца каталога и создает новую позицию там. Оно также запоминает в пространстве процесса индекс просматриваемого каталога и держит индекс заблокированным; каталог становится по отношению к новому файлу родительским каталогом. Ядро не записывает пока имя нового файла в каталог, так что в случае возникновения ошибок ядру приходится меньше переделывать. Оно проверяет наличие у процесса разрешения на запись в каталог. Поскольку процесс будет производить запись в каталог в результате выполнения функции creat, наличие разрешения на запись в каталог означает, что процессам дозволяется создавать файлы в каталоге.
Предположив, что под данным именем ранее не существовало файла, ядро назначает новому файлу индекс, используя алгоритм ialloc (). Затем оно записывает имя нового файла и номер вновь выделенного индекса в родительский каталог, а смещение в байтах сохраняет в пространстве процесса. Впоследствии ядро освобождает индекс родительского каталога, удерживаемый с того времени, когда в каталоге производился поиск имени файла. Родительский каталог теперь содержит имя нового файла и его индекс. Ядро записывает вновь выделенный индекс на диск (алгоритм bwrite), прежде чем записать на диск каталог с новым именем. Если между операциями записи индекса и каталога произойдет сбой системы, в итоге окажется, что выделен индекс, на который не ссылается ни одно из имен путей поиска в системе, однако система будет функционировать нормально. Если, с другой стороны, каталог был записан раньше вновь выделенного индекса и сбой системы произошел между ними, файловая система будет содержать имя пути поиска, ссылающееся на неверный индекс (более подробно об этом см. ).
Если данный файл уже существовал до вызова функции creat, ядро обнаруживает его индекс во время поиска имени файла. Старый файл должен позволять процессу производить запись в него, чтобы можно было создать "новый" файл с тем же самым именем, так как ядро изменяет содержимое файла при выполнении функции creat: оно усекает файл, освобождая все информационные блоки по алгоритму free, так что файл будет выглядеть как вновь созданный. Тем не менее, владелец и права доступа к файлу остаются прежними: ядро не передает право собственности на файл владельцу процесса и игнорирует права доступа, указанные процессом в вызове функции. Наконец, ядро не проверяет наличие разрешения на запись в каталог, являющийся родительским для существующего файла, поскольку оно не меняет содержимого каталога.
Функция creat продолжает работу, выполняя тот же алгоритм, что и функция open. Ядро выделяет созданному файлу запись в таблице файлов, чтобы процесс мог читать из файла, а также запись в таблице пользовательских дескрипторов файла, и в конце концов возвращает указатель на последнюю запись в виде пользовательского дескриптора файла.
(***) Системная функция open имеет два флага, O_CREAT (создание) и O_TRUNC (усечение). Если процесс устанавливает в вызове функции флаг O_CREAT и файл не существует, ядро создаст файл. Если файл уже существует, он не будет усечен, если только не установлен флаг O_TRUNC.
Comments:
Copyright ©
СОЗДАНИЕ ПРОЦЕССА
Единственным способом создания пользователем нового процесса в операционной системе UNIX является выполнение системной функции fork. Процесс, вызывающий функцию fork, называется родительским (процесс-родитель), вновь создаваемый процесс называется порожденным (процесс-потомок). Синтаксис вызова функции fork: pid = fork();
В результате выполнения функции fork пользовательский контекст и того, и другого процессов совпадает во всем, кроме возвращаемого значения переменной pid. Для родительского процесса в pid возвращается идентификатор порожденного процесса, для порожденного - pid имеет нулевое значение. Нулевой процесс, возникающий внутри ядра при загрузке системы, является единственным процессом, не создаваемым с помощью функции fork.
В ходе выполнения функции ядро производит следующую последовательность действий:
Отводит место в таблице процессов под новый процесс. Присваивает порождаемому процессу уникальный код идентификации. Делает логическую копию контекста родительского процесса. Поскольку те или иные составляющие процесса, такие как область команд, могут разделяться другими процессами, ядро может иногда вместо копирования области в новый физический участок памяти просто увеличить значение счетчика ссылок на область. Увеличивает значения счетчика числа файлов, связанных с процессом, как в таблице файлов, так и в таблице индексов. Возвращает родительскому процессу код идентификации порожденного процесса, а порожденному процессу - нулевое значение.
Реализацию системной функции fork, пожалуй, нельзя назвать тривиальной, так как порожденный процесс начинает свое выполнение, возникая как бы из воздуха. Алгоритм реализации функции для систем с замещением страниц по запросу и для систем с подкачкой процессов имеет лишь незначительные различия; все изложенное ниже в отношении этого алгоритма касается в первую очередь традиционных систем с подкачкой процессов, но с непременным акцентированием внимания на тех моментах, которые в системах с замещением страниц по запросу реализуются иначе. Кроме того, конечно, предполагается, что в системе имеется свободная оперативная память, достаточная для размещения порожденного процесса. В будет отдельно рассмотрен случай, когда для порожденного процесса не хватает памяти, и там же будут даны разъяснения относительно реализации алгоритма fork в системах с замещением страниц.
На приведен алгоритм создания процесса. Сначала ядро должно удостовериться в том, что для успешного выполнения алгоритма fork есть все необходимые ресурсы. В системе с подкачкой процессов для размещения порождаемого процесса требуется место либо в памяти, либо на диске; в системе с замещением страниц следует выделить память для вспомогательных таблиц (в частности, таблиц страниц). Если свободных ресурсов нет, алгоритм fork завершается неудачно. Ядро ищет место в таблице процессов для конструирования контекста порождаемого процесса и проверяет, не превысил ли пользователь, выполняющий fork, ограничение на максимально-допустимое количество параллельно запущенных процессов. Ядро также подбирает для нового процесса уникальный идентификатор, значение которого превышает на единицу максимальный из существующих идентификаторов. Если предлагаемый идентификатор уже присвоен другому процессу, ядро берет идентификатор, следующий по порядку. Как только будет достигнуто максимально-допустимое значение, отсчет идентификаторов опять начнется с 0. Поскольку большинство процессов имеет короткое время жизни, при переходе к началу отсчета значительная часть идентификаторов оказывается свободной.
На количество одновременно выполняющихся процессов накладывается ограничение (конфигурируемое), отсюда ни один из пользователей не может занимать в таблице процессов слишком много места, мешая тем самым другим пользователям создавать новые процессы. Кроме того, простым пользователям не разрешается создавать процесс, занимающий последнее свободное место в таблице процессов, в противном случае система зашла бы в тупик. Другими словами, поскольку в таблице процессов нет свободного места, то ядро не может гарантировать, что все существующие процессы завершатся естественным образом, поэтому новые процессы создаваться не будут. С другой стороны, суперпользователю нужно дать возможность исполнять столько процессов, сколько ему потребуется, конечно, учитывая размер таблицы процессов, при этом процесс, исполняемый суперпользователем, может занять в таблице и последнее свободное место. Предполагается, что суперпользователь может прибегать к решительным мерам и запускать процесс, побуждающий остальные процессы к завершению, если это вызывается необходимостью (, где говорится о системной функции kill).
| алгоритм fork входная информация: отсутствует выходная информация: для родительского процесса - идентифи- катор (PID) порожденного процесса для порожденного процесса - 0 { проверить доступность ресурсов ядра; получить свободное место в таблице процессов и уникаль- ный код идентификации (PID); проверить, не запустил ли пользователь слишком много процессов; сделать пометку о том, что порождаемый процесс находится в состоянии "создания"; скопировать информацию в таблице процессов из записи, соответствующей родительскому процессу, в запись, соот- ветствующую порожденному процессу; увеличить значения счетчиков ссылок на текущий каталог и на корневой каталог (если он был изменен); увеличить значение счетчика открытий файла в таблице файлов; сделать копию контекста родительского процесса (адресное пространство, команды, данные, стек) в памяти; поместить в стек фиктивный уровень системного контекста над уровнем системного контекста, соответствующим по- рожденному процессу; фиктивный контекстный уровень содержит информацию, необходимую порожденному процессу для того, чтобы знать все о себе и будучи выбранным для исполнения запускаться с этого места; если (в данный момент выполняется родительский процесс) { перевести порожденный процесс в состояние "готовности к выполнению"; возвратить (идентификатор порожденного процесса); /* из системы пользователю */ } в противном случае /* выполняется порожденный процесс */ { записать начальные значения в поля синхронизации ад- ресного пространства процесса; возвратить (0); /* пользователю */ } } |
Затем ядро присваивает начальные значения различным полям записи таблицы процессов, соответствующей порожденному процессу, копируя в них значения полей из записи родительского процесса. Например, порожденный процесс "наследует" у родительского процесса коды идентификации пользователя (реальный и тот, под которым исполняется процесс), группу процессов, управляемую родительским процессом, а также значение, заданное родительским процессом в функции nice и используемое при вычислении приоритета планирования. В следующих разделах мы поговорим о назначении этих полей. Ядро передает значение поля идентификатора родительского процесса в запись порожденного, включая последний в древовидную структуру процессов, и присваивает начальные значения различным параметрам планирования, таким как приоритет планирования, использование ресурсов центрального процессора и другие значения полей синхронизации. Начальным состоянием процесса является состояние "создания" (см. ).
После того ядро устанавливает значения счетчиков ссылок на файлы, с которыми автоматически связывается порождаемый процесс. Во-первых, порожденный процесс размещается в текущем каталоге родительского процесса. Число процессов, обращающихся в данный момент к каталогу, увеличивается на 1 и, соответственно, увеличивается значение счетчика ссылок на его индекс. Во-вторых, если родительский процесс или один из его предков уже выполнял смену корневого каталога с помощью функции chroot, порожденный процесс наследует и новый корень с соответствующим увеличением значения счетчика ссылок на индекс корня. Наконец, ядро просматривает таблицу пользовательских дескрипторов для родительского процесса в поисках открытых файлов, известных процессу, и увеличивает значение счетчика ссылок, ассоциированного с каждым из открытых файлов, в глобальной таблице файлов. Порожденный процесс не просто наследует права доступа к открытым файлам, но и разделяет доступ к файлам с родительским процессом, так как оба процесса обращаются в таблице файлов к одним и тем же записям. Действие fork в отношении открытых файлов подобно действию алгоритма dup: новая запись в таблице пользовательских дескрипторов файла указывает на запись в глобальной таблице файлов, соответствующую открытому файлу. Для dup, однако, записи в таблице пользовательских дескрипторов файла относятся к одному процессу; для fork - к разным процессам.
После завершения всех этих действий ядро готово к созданию для порожденного процесса пользовательского контекста. Ядро выделяет память для адресного пространства процесса, его областей и таблиц страниц, создает с помощью алгоритма dupreg копии всех областей родительского процесса и присоединяет с помощью алгоритма attachreg каждую область к порожденному процессу. В системе с подкачкой процессов ядро копирует содержимое областей, не являющихся областями разделяемой памяти, в новую зону оперативной памяти. Вспомним из о том, что в пространстве процесса хранится указатель на соответствующую запись в таблице процессов. За исключением этого поля, во всем остальном содержимое адресного пространства порожденного процесса в начале совпадает с содержимым пространства родительского процесса, но может расходиться после завершения алгоритма fork. Родительский процесс, например, после выполнения fork может открыть новый файл, к которому порожденный процесс уже не получит доступ автоматически.
Итак, ядро завершило создание статической части контекста порожденного процесса; теперь оно приступает к созданию динамической части. Ядро копирует в нее первый контекстный уровень родительского процесса, включающий в себя сохраненный регистровый контекст задачи и стек ядра в момент вызова функции fork. Если в данной реализации стек ядра является частью пространства процесса, ядро в момент создания пространства порожденного процесса автоматически создает и системный стек для него. В противном случае родительскому процессу придется скопировать в пространство памяти, ассоциированное с порожденным процессом, свой системный стек. В любом случае стек ядра для порожденного процесса совпадает с системным стеком его родителя. Далее ядро создает для порожденного процесса фиктивный контекстный уровень (2), в котором содержится сохраненный регистровый контекст из первого контекстного уровня. Значения счетчика команд (регистр PC) и других регистров, сохраняемые в регистровом контексте, устанавливаются таким образом, чтобы с их помощью можно было "восстанавливать" контекст порожденного процесса, пусть даже последний еще ни разу не исполнялся, и чтобы этот процесс при запуске всегда помнил о том, что он порожденный. Например, если программа ядра проверяет значение, хранящееся в регистре 0, для того, чтобы выяснить, является ли данный процесс родительским или же порожденным, то это значение переписывается в регистровый контекст порожденного процесса, сохраненный в составе первого уровня. Механизм сохранения используется тот же, что и при переключении контекста ().
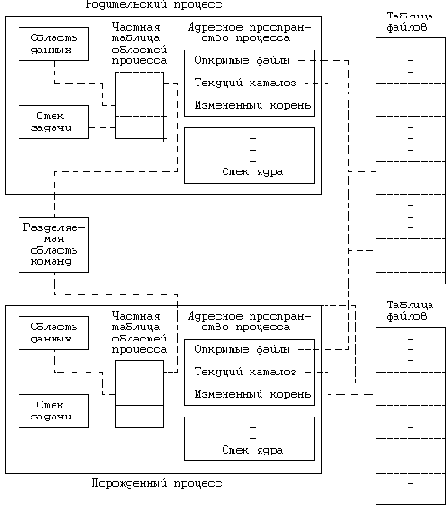
Рисунок 7.3. Создание контекста нового процесса при выполнении функции fork
Если контекст порожденного процесса готов, родительский процесс завершает свою роль в выполнении алгоритма fork, переводя порожденный процесс в состояние "готовности к запуску, находясь в памяти" и возвращая пользователю его идентификатор. Затем, используя обычный алгоритм планирования, ядро выбирает порожденный процесс для исполнения и тот "доигрывает" свою роль в алгоритме fork. Контекст порожденного процесса был задан родительским процессом; с точки зрения ядра кажется, что порожденный процесс возобновляется после приостанова в ожидании ресурса. Порожденный процесс при выполнении функции fork реализует ту часть программы, на которую указывает счетчик команд, восстанавливаемый ядром из сохраненного на уровне 2 регистрового контекста, и по выходе из функции возвращает нулевое значение.
На представлена логическая схема взаимодействия родительского и порожденного процессов с другими структурами данных ядра сразу после завершения системной функции fork. Итак, оба процесса совместно пользуются файлами, которые были открыты родительским процессом к моменту исполнения функции fork, при этом значение счетчика ссылок на каждый из этих файлов в таблице файлов на единицу больше, чем до вызова функции. Порожденный процесс имеет те же, что и родительский процесс, текущий и корневой каталоги, значение же счетчика ссылок на индекс каждого из этих каталогов так же становится на единицу больше, чем до вызова функции. Содержимое областей команд, данных и стека (задачи) у обоих процессов совпадает; по типу области и версии системной реализации можно установить, могут ли процессы разделять саму область команд в физических адресах.
Рассмотрим приведенную на программу, которая представляет собой пример разделения доступа к файлу при исполнении функции fork. Пользователю следует передавать этой программе два параметра - имя существующего файла и имя создаваемого файла. Процесс открывает существующий файл, создает новый файл и - при условии отсутствия ошибок - порождает новый процесс. Внутри программы ядро делает копию контекста родительского процесса для порожденного, при этом родительский процесс исполняется в одном адресном пространстве, а порожденный - в другом. Каждый из процессов может работать со своими собственными копиями глобальных переменных fdrd, fdwt и c, а также со своими собственными копиями стековых переменных argc и argv, но ни один из них не может обращаться к переменным другого процесса. Тем не менее, при выполнении функции fork ядро делает копию адресного пространства первого процесса для второго, и порожденный процесс, таким образом, наследует доступ к файлам родительского (то есть к файлам, им ранее открытым и созданным) с правом использования тех же самых дескрипторов.
Родительский и порожденный процессы независимо друг от друга, конечно, вызывают функцию rdwrt и в цикле считывают по одному байту информацию из исходного файла и переписывают ее в файл вывода. Функция rdwrt возвращает управление, когда при считывании обнаруживается конец файла. Ядро перед тем уже увеличило значения счетчиков ссылок на исходный и результирующий файлы в таблице файлов, и дескрипторы, используемые в обоих процессах, адресуют к одним и тем же строкам в таблице. Таким образом, дескрипторы fdrd в том и в другом процессах указывают на запись в таблице файлов, соответствующую исходному файлу, а дескрипторы, подставляемые в качестве fdwt, - на запись, соответствующую результирующему файлу (файлу вывода). Поэтому оба процесса никогда не обратятся вместе на чтение или запись к одному и тому же адресу, вычисляемому с помощью смещения внутри файла, поскольку ядро смещает внутрифайловые указатели после каждой операции чтения или записи. Несмотря на то, что, казалось бы, из-за того, что процессы распределяют между собой рабочую нагрузку, они копируют исходный файл в два раза быстрее, содержимое результирующего файла зависит от очередности, в которой ядро запускает процессы. Если ядро запускает процессы так, что они исполняют системные функции попеременно (чередуя и спаренные вызовы функций read-write), содержимое результирующего файла будет совпадать с содержимым исходного файла. Рассмотрим, однако, случай, когда процессы собираются считать из исходного файла последовательность из двух символов "ab". Предположим, что родительский процесс считал символ "a", но не успел записать его, так как ядро переключилось на контекст порожденного процесса. Если порожденный процесс считывает символ "b" и записывает его в результирующий файл до возобновления родительского процесса, строка "ab" в результирующем файле будет иметь вид "ba". Ядро не гарантирует согласование темпов выполнения процессов.
|
#include <fcntl.h> int fdrd, fdwt; char c; main(argc, argv) int argc; char *argv[]; { if (argc != 3) exit(1); if ((fdrd = open(argv[1],O_RDONLY)) == -1) exit(1); if ((fdwt = creat(argv[2],0666)) == -1) exit(1); fork(); /* оба процесса исполняют одну и ту же программу */ rdwrt(); exit(0); } rdwrt(); { for(;;) { if (read(fdrd,&c,1) != 1) return; write(fdwt,&c,1); } } |
Теперь перейдем к программе, представленной на , в которой процесс-потомок наследует от своего родителя файловые дескрипторы 0 и 1 (соответствующие стандартному вводу и стандартному выводу). При каждом выполнении системной функции pipe производится назначение двух файловых дескрипторов в массивах to_par и to_chil. Процесс вызывает функцию fork и делает копию своего контекста: каждый из процессов имеет доступ только к своим собственным данным, так же как и в предыдущем примере. Родительский процесс закрывает файл стандартного вывода (дескриптор 1) и дублирует дескриптор записи, возвращаемый в канал to_chil. Поскольку первое свободное место в таблице дескрипторов родительского процесса образовалось в результате только что выполненной операции закрытия (close) файла вывода, ядро переписывает туда дескриптор записи в канал и этот дескриптор становится дескриптором файла стандартного вывода для to_chil. Те же самые действия родительский процесс выполняет в отношении дескриптора файла стандартного ввода, заменяя его дескриптором чтения из канала to_par. И порожденный процесс закрывает файл стандартного ввода (дескриптор 0) и так же дублирует дескриптор чтения из канала to_chil. Поскольку первое свободное место в таблице дескрипторов файлов прежде было занято файлом стандартного ввода, его дескриптором становится дескриптор чтения из канала to_chil. Аналогичные действия выполняются и в отношении дескриптора файла стандартного вывода, заменяя его дескриптором записи в канал to_par. И тот, и другой процессы закрывают файлы, дескрипторы которых возвратила функция pipe - хорошая традиция, в чем нам еще предстоит убедиться. В результате, когда родительский процесс переписывает данные в стандартный вывод, запись ведется в канал to_chil и данные поступают к порожденному процессу, который считывает их через свой стандартный ввод. Когда же порожденный процесс пишет данные в стандартный вывод, запись ведется в канал to_par и данные поступают к родительскому процессу, считывающему их через свой стандартный ввод. Так через два канала оба процесса обмениваются сообщениями.
| #include <string.h> char string[] = "hello world"; main() { int count,i; int to_par[2],to_chil[2]; /* для каналов родителя и потомка */ char buf[256]; pipe(to_par); pipe(to_chil); if (fork() == 0) { /* выполнение порожденного процесса */ close(0); /* закрытие прежнего стандартного ввода */ dup(to_chil[0]); /* дублирование дескриптора чтения из канала в позицию стандартного ввода */ close(1); /* закрытие прежнего стандартного вывода */ dup(to_par[0]); /* дублирование дескриптора записи в канал в позицию стандартного вывода */ close(to_par[1]); /* закрытие ненужных дескрипторов close(to_chil[0]); канала */ close(to_par[0]); close(to_chil[1]); for (;;) { if ((count = read(0,buf,sizeof(buf))) == 0) exit(); write(1,buf,count); } } /* выполнение родительского процесса */ close(1); /* перенастройка стандартного ввода-вывода */ dup(to_chil[1]); close(0); dup(to_par[0]); close(to_chil[1]); close(to_par[0]); close(to_chil[0]); close(to_par[1]); for (i = 0; i < 15; i++) { write(1,string,strlen(string)); read(0,buf,sizeof(buf)); } } |
Результаты этой программы не зависят от того, в какой очередности процессы выполняют свои действия. Таким образом, нет никакой разницы, возвращается ли управление родительскому процессу из функции fork раньше или позже, чем порожденному процессу. И так же безразличен порядок, в котором процессы вызывают системные функции перед тем, как войти в свой собственный цикл, ибо они используют идентичные структуры ядра. Если процесс-потомок исполняет функцию read раньше, чем его родитель выполнит write, он будет приостановлен до тех пор, пока родительский процесс не произведет запись в канал и тем самым не возобновит выполнение потомка. Если родительский процесс записывает в канал до того, как его потомок приступит к чтению из канала, первый процесс не сможет в свою очередь считать данные из стандартного ввода, пока второй процесс не прочитает все из своего стандартного ввода и не произведет запись данных в стандартный вывод. С этого места порядок работы жестко фиксирован: каждый процесс завершает выполнение функций read и write и не может выполнить следующую операцию read до тех пор, пока другой процесс не выполнит пару read-write. Родительский процесс после 15 итераций завершает работу; порожденный процесс наталкивается на конец файла ("end-of-file"), поскольку канал не связан больше ни с одним из записывающих процессов, и тоже завершает работу. Если порожденный процесс попытается произвести запись в канал после завершения родительского процесса, он получит сигнал о том, что канал не связан ни с одним из процессов чтения.
Мы упомянули о том, что хорошей традицией в программировании является закрытие ненужных файловых дескрипторов. В пользу этого говорят три довода. Во-первых, дескрипторы файлов постоянно находятся под контролем системы, которая накладывает ограничение на их количество. Во-вторых, во время исполнения порожденного процесса присвоение дескрипторов в новом контексте сохраняется (в чем мы еще убедимся). Закрытие ненужных файлов до запуска процесса открывает перед программами возможность исполнения в "стерильных" условиях, свободных от любых неожиданностей, имея открытыми только файлы стандартного ввода-вывода и ошибок. Наконец, функция read для канала возвращает признак конца файла только в том случае, если канал не был открыт для записи ни одним из процессов. Если считывающий процесс будет держать дескриптор записи в канал открытым, он никогда не узнает, закрыл ли записывающий процесс работу на своем конце канала или нет. Вышеприведенная программа не работала бы надлежащим образом, если бы перед входом в цикл выполнения процессом-потомком не были закрыты дескрипторы записи в канал.
Comments:
Copyright ©
СОЗДАНИЕ СПЕЦИАЛЬНЫХ ФАЙЛОВ
Системная функция mknod создает в системе специальные файлы, в число которых включаются поименованные каналы, файлы устройств и каталоги. Она похожа на функцию creat в том, что ядро выделяет для файла индекс. Синтаксис вызова системной функции mknod: mknod(pathname,type and permissions,dev)
где pathname - имя создаваемой вершины в иерархической структуре файловой системы, type and permissions - тип вершины (например, каталог) и права доступа к создаваемому файлу, а dev указывает старший и младший номера устройства для блочных и символьных специальных файлов (). На Рисунке 5.13 приведен алгоритм, реализуемый функцией mknod при создании новой вершины.
| алгоритм создания новой вершины входная информация: вершина (имя файла) тип файла права доступа старший, младший номера устройства (для блочных и символьных специальных файлов) выходная информация: отсутствует { если (новая вершина не является поименованным каналом и пользователь не является суперпользователем) возвратить (ошибку); получить индекс вершины, являющейся родительской для новой вершины (алгоритм namei); если (новая вершина уже существует) { освободить родительский индекс (алгоритм iput); возвратить (ошибку); } назначить для новой вершины свободный индекс из файловой системы (алгоритм ialloc); создать новую запись в родительском каталоге: включить имя новой вершины и номер вновь назначенного индекса; освободить индекс родительского каталога (алгоритм iput); если (новая вершина является блочным или символьным спе- циальным файлом) записать старший и младший номера в структуру индек- са; освободить индекс новой вершины (алгоритм iput); } |
Рисунок 5.13. Алгоритм создания новой вершины
Ядро просматривает файловую систему в поисках имени файла, который оно собирается создать. Если файл еще пока не существует, ядро назначает ему новый индекс на диске и записывает имя нового файла и номер индекса в родительский каталог. Оно устанавливает значение поля типа файла в индексе, указывая, что файл является каналом, каталогом или специальным файлом. Наконец, если файл является специальным файлом устройства блочного или символьного типа, ядро записывает в индекс старший и младший номера устройства. Если функция mknod создает каталог, он будет существовать по завершении выполнения функции, но его содержимое будет иметь неверный формат (в каталоге будут отсутствовать записи с именами "." и ".."). рассматриваются шаги, необходимые для преобразования содержимого каталога в правильный формат.
| алгоритм смены каталога входная информация: имя нового каталога выходная информация: отсутствует { получить индекс для каталога с новым именем (алгоритм namei); если (индекс не является индексом каталога или же про- цессу не разрешен доступ к файлу) { освободить индекс (алгоритм iput); возвратить (ошибку); } снять блокировку с индекса; освободить индекс прежнего текущего каталога (алгоритм iput); поместить новый индекс в позицию для текущего каталога в пространстве процесса; } |
Comments:
Copyright ©
Среда выполнения процессов
Программой называется исполняемый файл, а процессом называется последовательность операций программы или часть программы при ее выполнении. В системе UNIX может одновременно выполняться множество процессов (эту особенность иногда называют мультипрограммированием или многозадачным режимом), при чем их число логически не ограничивается, и множество частей программы (такой как copy) может одновременно находиться в системе. Различные системные операции позволяют процессам порождать новые процессы, завершают процессы, синхронизируют выполнение этапов процесса и управляют реакцией на наступление различных событий. Благодаря различным обращениям к операционной системе, процессы выполняются независимо друг от друга.
Например, процесс, выполняющийся в программе, приведенной на Рисунке , запускает операцию fork, чтобы породить новый процесс. Новый процесс, именуемый порожденным процессом, получает значение кода завершения операции fork, равное 0, и активизирует операцию execl, которая выполняет программу copy (Рисунок ). Операция execl загружает файл "copy", который предположительно находится в текущем каталоге, в адресное пространство порожденного процесса и запускает программу с параметрами, полученными от пользователя. В случае успешного выполнения операции execl управление в вызвавший ее процесс не возвращается, поскольку процесс выполняется в новом адресном пространстве (подробнее об этом в ). Тем временем, процесс, запустивший операцию fork (родительский процесс), получает ненулевое значение кода завершения операции, вызывает операцию wait, которая приостанавливает его выполнение до тех пор, пока не закончится выполнение программы copy, и завершается (каждая программа имеет выход в конце главной процедуры, после которой располагаются программы стандартных библиотек Си, подключаемые в процессе компиляции). Например, если исполняемая программа называется run, пользователь запускает ее следующим образом: run oldfile newfile
Процесс выполняет копирование файла с именем "oldfile" в файл с именем "newfile" и выводит сообщение. Хотя данная программа мало что добавила к программе "copy", в ней появились четыре основных обращения к операционной системе, управляющие выполнением процессов: fork, exec, wait и exit.
| main(argc,argv) int argc; char *argv[]; { /* предусмотрено 2 аргумента: исходный файл и новый файл */ if (fork() == 0) execl("copy","copy",argv[1],argv[2],0); wait((int *)0) printf("copy done\n"); } |
Рисунок 1.4. Программа порождения нового процесса, выполняющего копирование файлов
Вообще использование обращений к операционной системе дает возможность пользователю создавать программы, выполняющие сложные действия, и как следствие, ядро операционной системы UNIX не включает в себя многие функции, являющиеся частью "ядра" в других системах. Такие функции, и среди них компиляторы и редакторы, в системе UNIX являются программами пользовательского уровня. Наиболее характерным примером подобной программы может служить командный процессор shell, с которым обычно взаимодействуют пользователи после входа в систему. Shell интерпретирует первое слово командной строки как имя команды: во многих командах, в том числе и в командах fork (породить новый процесс) и exec (выполнить порожденный процесс), сама команда ассоциируется с ее именем, все остальные слова в командной строке трактуются как параметры команды.
Shell обрабатывает команды трех типов. Во-первых, в качестве имени команды может быть указано имя исполняемого файла в объектном коде, полученного в результате компиляции исходного текста программы (например, программы на языке Си). Во-вторых, именем команды может быть имя командного файла, содержащего набор командных строк, обрабатываемых shell'ом. Наконец, команда может быть внутренней командой языка shell (в отличие от исполняемого файла). Наличие внутренних команд делает shell языком программирования в дополнение к функциям командного процессора; командный язык shell включает команды организации циклов (for-in-do-done и while-do-done), команды выполнения по условиям (if-then-else-fi), оператор выбора, команду изменения текущего для процесса каталога (cd) и некоторые другие. Синтаксис shell'а допускает сравнение с образцом и обработку параметров. Пользователям, запускающим команды, нет необходимости знать, какого типа эти команды.
Командный процессор shell ищет имена команд в указанном наборе каталогов, который можно изменить по желанию пользователя, вызвав shell. Shell обычно исполняет команду синхронно, с ожиданием завершения выполнения команды прежде, чем считать следующую командную строку. Тем не менее, допускается и асинхронное исполнение, когда очередная командная строка считывается и исполняется, не дожидаясь завершения выполнения предыдущей команды. О командах, выполняемых асинхронно, говорят, что они выполняются на фоне других команд. Например, ввод команды who
вызывает выполнение системой программы, хранящейся в файле /bin/who и осуществляющей вывод списка пользователей, которые в настоящий момент работают с системой. Пока команда who выполняется, командный процессор shell ожидает завершения ее выполнения и только затем запрашивает у пользователя следующую команду. Если же ввести команду who &
система выполнит программу who на фоне и shell готов немедленно принять следующую команду.
В среду выполнения каждого процесса в системе UNIX включается текущий каталог. Текущий для процесса каталог является начальным каталогом, имя которого присоединяется ко всем именам путей поиска, которые не начинаются с наклонной черты. Пользователь может запустить внутреннюю команду shell'а cd (изменить каталог) для перемещения по дереву файловой системы и для смены текущего каталога. Командная строка cd /usr/src/uts
делает текущим каталог "/usr/src/uts". Командная строка cd ../..
делает текущим каталог, который на две вершины "ближе" к корню (корневому каталогу): параметр ".." относится к каталогу, являющемуся родительским для текущего.
Поскольку shell является пользовательской программой и не входит в состав ядра операционной системы, его легко модифицировать и помещать в конкретные условия эксплуатации. Например, вместо командного процессора Баурна (называемого так по имени его создателя, Стива Баурна), являющегося частью версии V стандартной системы, можно использовать процессор команд Си, обеспечивающий работу механизма ведения истории изменений и позволяющий избегать повторного ввода только что использованных команд. В некоторых случаях при желании можно воспользоваться командным процессором shell с ограниченными возможностями, являющимся предыдущей версией обычного shell'а. Система может работать с несколькими командными процессорами одновременно. Пользователи имеют возможность запускать одновременно множество процессов, процессы же в свою очередь могут динамически порождать новые процессы и синхронизировать их выполнение. Все эти возможности обеспечиваются благодаря наличию мощных программных и аппаратных средств, составляющих среду выполнения процессов. Хотя привлекательность shell'а в наибольшей степени определяется его возможностями как языка программирования и его возможностями в обработке аргументов, в данном разделе основное внимание концентрируется на среде выполнения процессов, управление которой в системе возложено на командный процессор shell. Другие важные особенности shell'а выходят за рамки настоящей книги (подробное описание shell'а см. в [Bourne 78]).
STAT И FSTАТ
Системные функции stat и fstat позволяют процессам запрашивать информацию о статусе файла: типе файла, владельце файла, правах доступа, размере файла, числе связей, номере индекса и времени доступа к файлу. Синтаксис вызова функций: stat(pathname,statbuffer); fstat(fd,statbuffer);
где pathname - имя файла, fd - дескриптор файла, возвращаемый функцией open, statbuffer - адрес структуры данных пользовательского процесса, где будет храниться информация о статусе файла после завершения выполнения вызова. Системные функции просто переписывают поля из индекса в структуру statbuffer. Программа на иллюстрирует использование функций stat и fstat.
Рисунок 5.15. Дерево процессов и совместное использование каналов
Comments:
Copyright ©
Страницы и таблицы страниц
В этом разделе описывается модель организации памяти, которой мы будем пользоваться на протяжении всей книги, но которая не является особенностью системы UNIX. В организации памяти, базирующейся на страницах, физическая память разделяется на блоки одинакового размера, называемые страницами. Обычный размер страниц составляет от 512 байт до 4 Кбайт и определяется конфигурацией технических средств. Каждая адресуемая ячейка памяти содержится в некоторой странице и, следовательно, каждая ячейка памяти может адресоваться парой (номер страницы, смещение внутри страницы в байтах). Например, если объем машинной памяти составляет 2 в 32-й степени байт, а размер страницы 1 Кбайт, общее число страниц - 2 в 22-й степени; можно считать, что каждый 32-разрядный адрес состоит из 22-разрядного номера страницы и 10-разрядного смещения внутри страницы ().
Когда ядро назначает области физические страницы памяти, необходимости в назначении смежных страниц и вообще в соблюдении какой-либо очередности при назначении не возникает. Целью страничной организации памяти является повышение гибкости назначения физической памяти, которое строится по аналогии с назначением дисковых блоков файлам в файловой системе. Как и при назначении блоков файлу, так и при назначении области страниц памяти, преследуется задача повышения гибкости и сокращения неиспользуемого (вследствие фрагментации) пространства памяти.
| 58432 | |
| 0101 1000 0100 0011 0010 | |
| 01 0110 0001 | 00 0011 0010 |
| 161 | 32 |
Рисунок 6.3. Адресация физической памяти по страницам
| 0 | 177 |
| 1 | 54 |
| 2 | 209 |
| 3 | 17 |
Рисунок 6.4. Отображение логических номеров страниц на физические
Ядро устанавливает соотношение между виртуальными адресами области и машинными физическими адресами посредством отображения логических номеров страниц в области на физические номера страниц в машине, как это показано на . Поскольку область это непрерывное пространство виртуальных адресов программы, логический номер страницы служит указателем на элемент массива физических номеров страниц. Запись таблицы областей содержит указатель на таблицу физических номеров страниц, именуемую таблицей страниц. Записи таблицы страниц содержат машинно-зависимую информацию, такую как права доступа на чтение или запись страницы. Ядро поддерживает таблицы страниц в памяти и обращается к ним так же, как и ко всем остальным структурам данных ядра.
На приведен пример отображения процесса в физические адреса памяти. Пусть размер страницы составляет 1 Кбайт и пусть процессу нужно обратиться к объекту в памяти, имеющему виртуальный адрес 68432. Из таблицы областей видно, что виртуальный адрес начала области стека - 65536 (64К), если предположить, что стек растет в направлении увеличения адресов. После вычитания этого адреса из адреса 68432 получаем смещение в байтах внутри области, равное 2896. Так как каждая страница имеет размер 1 Кбайт, адрес указывает со смещением 848 на 2-ю (начиная с 0) страницу области, расположенной по физическому адресу 986К. В (где идет речь о загрузке области) рассматривается случай, когда запись таблицы страниц помечается "пустой".
В современных машинах используются разнообразные аппаратные регистры и кеши, которые повышают скорость выполнения вышеописанной процедуры трансляции адресов и без которых пересылки в памяти и адресные вычисления чересчур бы замедлились. Возобновляя выполнение процесса, ядро посредством загрузки соответствующих регистров сообщает техническим средствам управления памятью о том, в каких физических адресах выполняется процесс и где располагаются таблицы страниц. Поскольку такие операции являются машинно-зависимыми и в разных версиях реализуются по-разному, здесь мы их рассматривать не будем. Часть вопросов, связанных с архитектурой вычислительных систем, затрагивается в упражнениях.
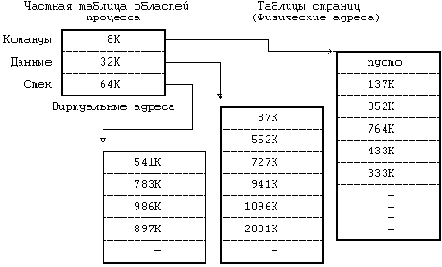
Рисунок 6.5. Преобразование виртуальных адресов в физические
Организацию управления памятью попробуем пояснить на следующем простом примере. Пусть память разбита на страницы размером 1 Кбайт каждая, обращение к которым осуществляется через описанные ранее таблицы страниц. Регистры управления памятью в системе группируются по три; первый регистр в тройке содержит адрес таблицы страниц в физической памяти, второй регистр содержит первый виртуальный адрес, отображаемый с помощью тройки регистров, третий регистр содержит управляющую информацию, такую как номера страниц в таблице страниц и права доступа к страницам (только чтение, чтение и запись). Такая модель соответствует вышеописанной модели области. Когда ядро готовит процесс к выполнению, оно загружает тройки регистров соответствующей информацией из записей частной таблицы областей процесса.
Если процесс обращается к ячейкам памяти, расположенным за пределами принадлежащего ему виртуального пространства, создается исключительная ситуация. Например, если область команд имеет размер 16 Кбайт (), а процесс обращается к виртуальному адресу 26К, создается исключительная ситуация, обрабатываемая операционной системой. То же самое происходит, если процесс пытается обратиться к памяти, не имея соответствующих прав доступа, например, пытается записать адрес в защищенную от записи область команд. И в том, и в другом примере процесс обычно завершается (более подробно об этом в следующей главе).
СТРУКТУРА ФАЙЛА ОБЫЧНОГО ТИПА
Как уже говорилось, индекс включает в себя таблицу адресов расположения информации файла на диске. Так как каждый блок на диске адресуется по своему номеру, в этой таблице хранится совокупность номеров дисковых блоков. Если бы данные файла занимали непрерывный участок на диске (то есть файл занимал бы линейную последовательность дисковых блоков), то для обращения к данным в файле было бы достаточно хранить в индексе адрес начального блока и размер файла. Однако, такая стратегия размещения данных не позволяет осуществлять простое расширение и сжатие файлов в файловой системе без риска фрагментации свободного пространства памяти на диске. Более того, ядру пришлось бы выделять и резервировать непрерывное пространство в файловой системе перед выполнением операций, могущих привести к увеличению размера файла.

Рисунок 4.5. Размещение непрерывных файлов и фрагментация свободного пространства
Предположим, например, что пользователь создает три файла, A, B и C, каждый из которых занимает 10 дисковых блоков, а также что система выделила для размещения этих трех файлов непрерывное место. Если потом пользователь захочет добавить 5 блоков с информацией к среднему файлу, B, ядру придется скопировать файл B в то место в файловой системе, где найдется окно размером 15 блоков. В дополнение к затратам ресурсов на проведение этой операции дисковые блоки, занимаемые информацией файла B, станут неиспользуемыми, если только они не понадобятся файлам размером не более 10 блоков (Рисунок 4.5). Ядро могло бы минимизировать фрагментацию пространства памяти, периодически запуская процедуры чистки памяти, уплотняющие имеющуюся память, но это потребовало бы дополнительного расхода временных и системных ресурсов.
В целях повышения гибкости ядро присоединяет к файлу по одному блоку, позволяя информации файла быть разбросанной по всей файловой системе. Но такая схема размещения усложняет задачу поиска данных. Таблица адресов содержит список номеров блоков, содержащих принадлежащую файлу информацию, однако простые вычисления показывают, что линейным списком блоков файла в индексе трудно управлять. Если логический блок занимает 1 Кбайт, то файлу, состоящему из 10 Кбайт, потребовался бы индекс на 10 номеров блоков, а файлу, состоящему из 100 Кбайт, понадобился бы индекс на 100 номеров блоков. Либо пусть размер индекса будет варьироваться в зависимости от размера файла, либо пришлось бы установить относительно жесткое ограничение на размер файла.
Для того, чтобы небольшая структура индекса позволяла работать с большими файлами, таблица адресов дисковых блоков приводится в соответствие со структурой, представленной на Рисунке 4.6. Версия V системы UNIX работает с 13 точками входа в таблицу адресов индекса, но принципиальные моменты не зависят от количества точек входа. Блок, имеющий пометку "прямая адресация" на рисунке, содержит номера дисковых блоков, в которых хранятся реальные данные. Блок, имеющий пометку "одинарная косвенная адресация", указывает на блок, содержащий список номеров блоков прямой адресации. Чтобы обратиться к данным с помощью блока косвенной адресации, ядро должно считать этот блок, найти соответствующий вход в блок прямой адресации и, считав блок прямой адресации, обнаружить данные. Блок, имеющий пометку "двойная косвенная адресация", содержит список номеров блоков одинарной косвенной адресации, а блок, имеющий пометку "тройная косвенная адресация", содержит список номеров блоков двойной косвенной адресации.
В принципе, этот метод можно было бы распространить и на поддержку блоков четверной косвенной адресации, блоков пятерной косвенной адресации и так далее, но на практике оказывается достаточно имеющейся структуры. Предположим, что размер логического блока в файловой системе 1 Кбайт и что номер блока занимает 32 бита (4 байта). Тогда в блоке может храниться до 256 номеров блоков. Расчеты показывают (Рисунок 4.7), что максимальный размер файла превышает 16 Гбайт, если использовать в индексе 10 блоков прямой адресации и 1 одинарной косвенной адресации, 1 двойной косвенной адресации и 1 тройной косвенной адресации. Если же учесть, что длина поля "размер файла" в индексе - 32 бита, то размер файла в действительности ограничен 4 Гбайтами (2 в степени 32).
Процессы обращаются к информации в файле, задавая смещение в байтах. Они рассматривают файл как поток байтов и ведут подсчет байтов, начиная с нулевого адреса и заканчивая адресом, равным размеру файла. Ядро переходит от байтов к блокам: файл начинается с нулевого логического блока и заканчивается блоком, номер которого определяется исходя из размера файла. Ядро обращается к индексу и превращает логический блок, принадлежащий файлу, в соответствующий дисковый блок. На представлен алгоритм bmap пересчета смещения в байтах от начала файла в номер физического блока на диске.
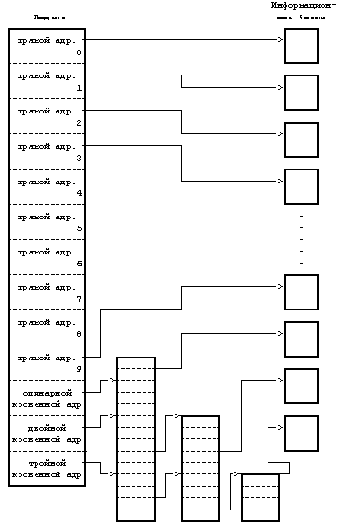
Рисунок 4.6. Блоки прямой и косвенной адресации в индексе
| 10 блоков прямой адресации по 1 Кбайту каждый = 10 Кбайт 1 блок косвенной адресации с 256 блоками прямой адресации = 256 Кбайт 1 блок двойной косвенной адресации с 256 блоками косвенной адресации = 64 Мбайта 1 блок тройной косвенной адресации с 256 блоками двойной косвенной адресации = 16 Гбайт |
| алгоритм bmap /* отображение адреса смещения в байтах от начала логического файла на адрес блока в файловой системе */ входная информация: (1) индекс (2) смещение в байтах выходная информация: (1) номер блока в файловой системе (2) смещение в байтах внутри блока (3) число байт ввода-вывода в блок (4) номер блока с продвижением { вычислить номер логического блока в файле исходя из заданного смещения в байтах; вычислить номер начального байта в блоке для ввода- вывода; /* выходная информация 2 */ вычислить количество байт для копирования пользова- телю; /* выходная информация 3 */ проверить возможность чтения с продвижением, пометить индекс; /* выходная информация 4 */ определить уровень косвенности; выполнить (пока уровень косвенности другой) { определить указатель в индексе или блок косвенной адресации исходя из номера логического блока в файле; получить номер дискового блока из индекса или из блока косвенной адресации; освободить буфер от данных, полученных в резуль- тате выполнения предыдущей операции чтения с диска (алгоритм brelse); если (число уровней косвенности исчерпано) возвратить (номер блока); считать дисковый блок косвенной адресации (алго- ритм bread); установить номер логического блока в файле исходя из уровня косвенности; } } |
Рассмотрим формат файла в блоках (Рисунок 4.9) и предположим, что дисковый блок занимает 1024 байта. Если процессу нужно обратиться к байту, имеющему смещение от начала файла, равное 9000, в результате вычислений ядро приходит к выводу, что этот байт располагается в блоке прямой адресации с номером 8 (начиная с 0). Затем ядро обращается к блоку с номером 367; 808-й байт в этом блоке (если вести отсчет с 0) и является 9000-м байтом в файле. Если процессу нужно обратиться по адресу, указанному смещением 350000 байт от начала файла, он должен считать блок двойной косвенной адресации, который на рисунке имеет номер 9156. Так как блок косвенной адресации имеет место для 256 номеров блоков, первым байтом, к которому будет получен доступ в результате обращения к блоку двойной косвенной адресации, будет байт с номером 272384 (256К + 10К); таким образом, байт с номером 350000 будет иметь в блоке двойной косвенной адресации номер 77616. Поскольку каждый блок одинарной косвенной адресации позволяет обращаться к 256 Кбайтам, байт с номером 350000 должен располагаться в нулевом блоке одинарной косвенной адресации для блока двойной косвенной адресации, а именно в блоке 331. Так как в каждом блоке прямой адресации для блока одинарной косвенной адресации хранится 1 Кбайт, байт с номером 77616 находится в 75-м блоке прямой адресации для блока одинарной косвенной адресации, а именно в блоке 3333. Наконец, байт с номером в файле 350000 имеет в блоке 3333 номер 816.
Рисунок 4.9. Размещение блоков в файле и его индексе
При ближайшем рассмотрении Рисунка 4. 9 обнаруживается, что несколько входов для блока в индексе имеют значение 0 и это значит, что в данных записях информация о логических блоках отсутствует. Такое имеет место, если в соответствующие блоки файла никогда не записывалась информация и по этой причине у номеров блоков остались их первоначальные нулевые значения. Для таких блоков пространство на диске не выделяется. Подобное расположение блоков в файле вызывается процессами, запускающими системные операции lseek и write (). В следующей главе также объясняется, каким образом ядро обрабатывает системные вызовы операции read, с помощью которой производится обращение к блокам.
Преобразование адресов с большими смещениями, в частности с использованием блоков тройной косвенной адресации, является сложной процедурой, требующей от ядра обращения уже к трем дисковым блокам в дополнение к индексу и информационному блоку. Даже если ядро обнаружит блоки в буферном кеше, операция останется дорогостоящей, так как ядру придется многократно обращаться к буферному кешу и приостанавливать свою работу в ожидании снятия блокировки с буферов. Насколько эффективен этот алгоритм на практике? Это зависит от того, как используется система, а также от того, кто является пользователем и каков состав задач, вызывающий потребность в более частом обращении к большим или, наоборот, маленьким файлам. Однако, как уже было замечено [Mullender 84], большинство файлов в системе UNIX имеет размер, не превышающий 10 Кбайт и даже 1 Кбайта ! Поскольку 10 Кбайт файла располагаются в блоках прямой адресации, к большей части данных, хранящихся в файлах, доступ может производиться за одно обращение к диску. Поэтому в отличие от обращения к большим файлам, работа с файлами стандартного размера протекает быстро.
В двух модификациях только что описанной структуры индекса предпринимается попытка использовать размерные характеристики файла. Основной принцип в реализации файловой системы BSD 4.2 [McKusick 84] состоит в том, что чем больше объем данных, к которым ядро может получить доступ за одно обращение к диску, тем быстрее протекает работа с файлом. Это свидетельствует в пользу увеличения размера логического блока на диске, поэтому в системе BSD разрешается иметь логические блоки размером 4 или 8 Кбайт. Однако, увеличение размера блоков на диске приводит к увеличению фрагментации блоков, при которой значительные участки дискового пространства остаются неиспользуемыми. Например, если размер логического блока 8 Кбайт, тогда файл размером 12 Кбайт занимает 1 полный блок и половину второго блока. Другая половина второго блока (4 Кбайта) фактически теряется; другие файлы не могут использовать ее для хранения данных. Если размеры файлов таковы, что число байт, попавших в последний блок, является равномерно распределенной величиной, то средние потери дискового пространства составляют полблока на каждый файл; объем теряемого дискового пространства достигает в файловой системе с логическими блоками размером 4 Кбайта 45% [McKusick 84]. Выход из этой ситуации в системе BSD состоит в выделении только части блока (фрагмента) для размещения оставшейся информации файла. Один дисковый блок может включать в себя фрагменты, принадлежащие нескольким файлам. Некоторые подробности этой реализации исследуются на примере упражнения в главе 5.
Второй модификацией рассмотренной классической структуры индекса является идея хранения в индексе информации файла (см. [Mullender 84]). Если увеличить размер индекса так, чтобы индекс занимал весь дисковый блок, небольшая часть блока может быть использована для собственно индексных структур, а оставшаяся часть - для хранения конца файла и даже во многих случаях для хранения файла целиком. Основное преимущество такого подхода заключается в том, что необходимо только одно обращение к диску для считывания индекса и всей информации, если файл помещается в индексном блоке.
(*) На примере 19978 файлов Маллендер и Танненбаум говорят, что приблизительно 85% файлов имеют размер менее 8 Кбайт и 48% - менее 1 Кбайта. Несмотря на то, что эти данные варьируются от одной реализации системы к другой, для многих реализаций системы UNIX они показательны.
Comments:
Copyright ©
СТРУКТУРА ОБЛАСТИ БУФЕРОВ (БУФЕРНОГО ПУЛА)
Ядро помещает информацию в область буферов, используя алгоритм поиска буферов, к которым наиболее долго не было обращений: после выделения буфера дисковому блоку нельзя использовать этот буфер для другого блока до тех пор, пока не будут задействованы все остальные буферы. Ядро управляет списком свободных буферов, который необходим для работы указанного алгоритма. Этот список представляет собой циклический перечень буферов с двунаправленными указателями и с формальными заголовками в начале и в конце перечня (Рисунок 3.2). Все буферы попадают в список при загрузке системы. Если нужен любой свободный буфер, ядро выбирает буфер из "головы" списка, но если в области буферов ищется определенный блок, может быть выбран буфер и из середины списка. И в том, и в другом случае буфер удаляется из списка свободных буферов. Если ядро возвращает буфер буферному пулу, этот буфер добавляется в хвост списка, либо в "голову" списка (в случае ошибки), но никогда не в середину. По мере удаления буферов из списка буфер с нужной информацией продвигается все ближе и ближе к "голове" списка (Рисунок 3.2). Следовательно, те буферы, которые находятся ближе к "голове" списка, в последний раз использовались раньше, чем буферы, находящиеся дальше от "головы" списка.
Рисунок 3.2. Список свободных буферов
Когда ядро обращается к дисковому блоку, оно сначала ищет буфер с соответствующей комбинацией номеров устройства и блока. Вместо того, чтобы просматривать всю область буферов, ядро организует из буферов особые очереди, хешированные по номеру устройства и номеру блока. В хеш-очереди ядро устанавливает для буферов циклическую связь в виде списка с двунаправленными указателями, структура которого похожа на структуру списка свободных буферов. Количество буферов в хеш-очереди варьируется в течение всего времени функционирования системы, в чем мы еще убедимся дальше. Ядро вынуждено прибегать к функции хеширования, чтобы единообразно распределять буферы между хеш-очередями, однако функция хеширования должна быть несложной, чтобы не пострадала производительность системы. Администраторы системы задают количество хеш-очередей при генерации операционной системы.
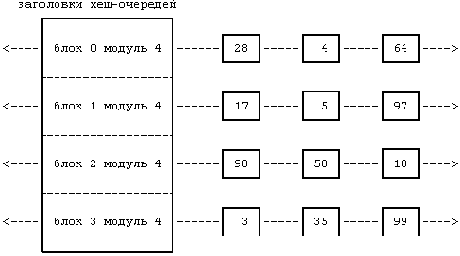
Рисунок 3.3. Буферы в хеш-очередях
На Рисунке 3.3 изображены буферы в хеш-очередях: заголовки хеш-очередей показаны в левой части рисунка, а квадратиками в каждой строке показаны буферы в соответствующей хеш-очереди. Так, квадратики с числами 28, 4 и 64 представляют буферы в хеш-очереди для "блока 0 модуля 4". Пунктирным линиям между буферами соответствуют указатели вперед и назад вдоль хеш-очереди; для простоты на следующих рисунках этой главы данные указатели не показываются, но их присутствие подразумевается. Кроме того, на рисунке блоки идентифицируются только своими номерами и функция хеширования построена на использовании только номеров блоков; однако на практике также используется номер устройства.
Любой буфер всегда находится в хеш-очереди, но его положение в очереди не имеет значения. Как уже говорилось, никакая пара буферов не может одновременно содержать данные одного и того же дискового блока; поэтому каждый дисковый блок в буферном пуле существует в одной и только одной хеш-очереди и представлен в ней только один раз. Тем не менее, буфер может находиться в списке свободных буферов, если его статус "свободен". Поскольку буфер может быть одновременно в хеш-очереди и в списке свободных буферов, у ядра есть два способа его обнаружения. Ядро просматривает хеш-очередь, если ему нужно найти определенный буфер, и выбирает буфер из списка свободных буферов, если ему нужен любой свободный буфер. В следующем разделе будет показано, каким образом ядро осуществляет поиск определенных дисковых блоков в буферном кеше, а также как оно работает с буферами в хеш-очередях и в списке свободных буферов. Еще раз напомним: буфер всегда находится в хеш -очереди, а в списке свободных буферов может быть, но может и отсутствовать.
Comments:
Copyright ©
СТРУКТУРА СИСТЕМЫ
На Рисунке изображена архитектура верхнего уровня системы UNIX. Технические средства, показанные в центре диаграммы, выполняют функции, обеспечивающие функционирование операционной системы и перечисленные в . Операционная система взаимодействует с аппаратурой непосредственно , обеспечивая обслуживание программ и их независимость от деталей аппаратной конфигурации. Если представить систему состоящей из пластов, в ней можно выделить системное ядро, изолированное от пользовательских
Рисунок 1.1. Архитектура системы UNIX
программ. Поскольку программы не зависят от аппаратуры, их легко переносить из одной системы UNIX в другую, функционирующую на другом комплексе технических средств, если только в этих программах не подразумевается работа с конкретным оборудованием. Например, программы, рассчитанные на определенный размер машинного слова, гораздо труднее переводить на другие машины по сравнению с программами, не требующими подобных установлений.
Программы, подобные командному процессору shell и редакторам (ed и vi) и показанные на внешнем по отношению к ядру слое, взаимодействуют с ядром при помощи хорошо определенного набора обращений к операционной системе. Обращения к операционной системе понуждают ядро к выполнению различных операций, которых требует вызывающая программа, и обеспечивают обмен данными между ядром и программой. Некоторые из программ, приведенных на рисунке, в стандартных конфигурациях системы известны как команды, однако на одном уровне с ними могут располагаться и доступные пользователю программы, такие как программа a.out, стандартное имя для исполняемого файла, созданного компилятором с языка Си. Другие прикладные программы располагаются выше указанных программ, на верхнем уровне, как это показано на рисунке. Например, стандартный компилятор с языка Си, cc, располагается на самом внешнем слое: он вызывает препроцессор для Си, ассемблер и загрузчик (компоновщик), т.е. отдельные программы предыдущего уровня. Хотя на рисунке приведена двухуровневая иерархия прикладных программ, пользователь может расширить иерархическую структуру на столько уровней, сколько необходимо. В самом деле, стиль программирования, принятый в системе UNIX, допускает разработку комбинации программ, выполняющих одну и ту же, общую задачу.
Многие прикладные подсистемы и программы, составляющие верхний уровень системы, такие как командный процессор shell, редакторы, SCCS (система обработки исходных текстов программ) и пакеты программ подготовки документации, постепенно становятся синонимом понятия "система UNIX". Однако все они пользуются услугами программ нижних уровней и в конечном счете ядра с помощью набора обращений к операционной системе. В версии V принято 64 типа обращений к операционной системе, из которых немногим меньше половины используются часто. Они имеют несложные параметры, что облегчает их использование, предоставляя при этом большие возможности пользователю. Набор обращений к операционной системе вместе с реализующими их внутренними алгоритмами составляют "тело" ядра, в связи с чем рассмотрение операционной системы UNIX в этой книге сводится к подробному изучению и анализу обращений к системе и их взаимодействия между собой. Короче говоря, ядро реализует функции, на которых основывается выполнение всех прикладных программ в системе UNIX, и им же определяются эти функции. В книге часто употребляются термины "система UNIX", "ядро" или "система", однако при этом имеется ввиду ядро операционной системы UNIX, что и должно вытекать из контекста.
(***) В некоторых реализациях системы UNIX операционная система взаимодействует с собственной операционной системой, которая, в свою очередь, взаимодействует с аппаратурой и выполняет необходимые функции по обслуживанию системы. В таких реализациях допускается инсталляция других операционных систем с загрузкой под их управлением прикладных программ параллельно с системой UNIX. Классическим примером подобной реализации явилась система MERT [Lycklama 78a]. Более новым примером могут служить реализации для компьютеров серии IBM 370 [Felton 84] и UNIVAC 1100 [Bodenstab 84].
Comments:
Copyright ©
Структуры данных, используемые подсистемой замещения страниц
Для поддержки функций управления памятью на машинном (низком) уровне и для реализации механизма замещения страниц ядро использует 4 основные структуры данных: записи таблицы страниц, дескрипторы дисковых блоков, таблицу содержимого страничных блоков (page frame data table - сокращенно: pfdata) и таблицу использования области подкачки. Место для таблицы pfdata выделяется один раз на все время жизни системы, для других же структур страницы памяти выделяются динамически.
Из главы 6 нам известно, что каждая область располагает своими таблицами страниц, с помощью которых осуществляется доступ к физической памяти. Каждая запись таблицы страниц () состоит из физического адреса страницы, кода защиты, в разрядах которого описываются права доступа процесса к странице (на чтение, запись и исполнение), а также следующих двоичных полей, используемых механизмом замещения страниц:
бит доступности бит упоминания бит модификации бит копирования при записи "возраст" страницы
Установка бита доступности свидетельствует о правильности содержимого страницы памяти, однако из того, что бит доступности выключен, не следует с необходимостью то, что ссылка на страницу недопустима, в чем мы убедимся позже. Бит упоминания устанавливается в том случае, если процесс делает ссылку на страницу, а бит модификации - в том случае, если процесс скорректировал содержимое страницы. Установка бита копирования при записи, производимая во время выполнения системной функции fork, свидетельствует о том, что ядру в случае, когда процесс корректирует содержимое страницы, следует создавать ее новую копию. Наконец, "возраст" страницы говорит о продолжительности ее пребывания в составе рабочего множества процесса. Биты доступности, копирования при записи и "возраст" страницы устанавливаются ядром, биты упоминания и модификации - аппаратным путем; в рассматриваются конфигурации, в которых эти возможности не поддерживаются аппаратурой.

Рисунок 9.12. Рабочее множество процесса

Рисунок 9.13. Записи таблицы страниц и дескрипторы дисковых блоков
Каждая запись таблицы страниц связана с дескриптором дискового блока, описывающим дисковую копию виртуальной страницы (). Поэтому процессы, использующие разделяемую область, обращаются к общим записям таблицы страниц и к одним и тем же дескрипторам дисковых блоков. Содержимое виртуальной страницы располагается либо в отдельном блоке на устройстве выгрузки, либо в исполняемом файле, либо вообще отсутствует на устройстве выгрузки. Если страница находится на устройстве выгрузки, в дескрипторе дискового блока содержится логический номер устройства и номер блока, по которым можно отыскать содержимое страницы. Если страница содержится в исполняемом файле, в дескрипторе дискового блока располагается номер логического блока в файле с содержимым страницы; ядро может быстро преобразовать этот номер в адрес на диске. В дескрипторе дискового блока также имеется информация о двух устанавливаемых функцией exec особых условиях: страница при обращении к ней заполняется ("demand fill") или обнуляется ("demand zero"). Разъяснения по этому поводу даются в .
В таблице pfdata описывается каждая страница физической памяти. Записи таблицы проиндексированы по номеру страницы и состоят из следующих полей:
Статус страницы, указывающий на то, что страница располагается на устройстве выгрузки или в исполняемом файле, что к странице произведено обращение по прямому доступу в память (путем считывания информации с устройства выгрузки), или на то, что страница может быть переназначена. Количество процессов, ссылающихся на страницу. Счетчик ссылок хранит число записей в таблице страниц, имеющих ссылку на текущую страницу. Это значение может отличаться от количества процессов, использующих разделяемую область с данной страницей, в чем мы убедимся чуть позже, когда будем снова обращаться к алгоритму функции fork. Логический номер устройства (устройства выгрузки или файловой системы) и номер блока, указывающие расположение содержимого страницы. Указатели на другие записи таблицы pfdata в соответствии со списком свободных страниц или с хеш-очередью страниц.
По аналогии с буферным кэшем ядро связывает записи таблицы pfdata в список свободных страниц и хеш-очередь. Список свободных страниц представляет собой буфер, который содержит страницы, доступные для переназначения, однако процесс, обратившийся к этим страницам, может столкнуться с ошибкой адресации, так и не получив соответствующую страницу из списка. Этот список дает ядру возможность сократить число операций чтения с устройства выгрузки. Ядро выделяет страницы из этого списка по вышеназванному принципу замещения "стариков". Ядро выстраивает записи таблицы в хеш-очередь в соответствии с номером устройства (выгрузки) и номером блока. Используя эти номера, ядро может быстро отыскать страницу, если она находится в памяти. Передавая физическую страницу области, ядро выбирает соответствующую запись из списка свободных страниц, исправляет указанные в ней номера устройства и блока и помещает ее в соответствующее место хеш-очереди.
Каждая запись таблицы использования области подкачки соответствует странице, находящейся на устройстве выгрузки. Запись содержит счетчик ссылок, показывающий количество записей таблицы страниц, в которых имеется ссылка на текущую страницу.
На показана взаимосвязь между записями таблицы страниц, дескрипторами дисковых блоков, записями таблицы pfdata и таблицы использования области подкачки. Виртуальный адрес 1493К отображается на запись таблицы страниц, соответствующую странице с физическим номером 794; дескриптор дискового блока, связанный с этой записью, свидетельствует о том, что содержимое страницы располагается на устройстве выгрузки с номером 1 в дисковом блоке с номером 2743. Запись таблицы pfdata, помимо того, что указывает на те же номера устройства и блока, сообщает, что счетчик ссылок на физическую страницу имеет значение, равное 1. Счетчик ссылок на виртуальную страницу (в записи таблицы использования области подкачки) свидетельствует о том, что на копию страницы на устройстве выгрузки ссылается только одна запись таблицы страниц.
9.2.1.1 Функция fork в системе с замещением страниц
Как уже говорилось в , во время выполнения функции fork ядро создает копию каждой области родительского процесса и присоединяет ее к процессу-потомку. В системе с замещением страниц ядро по традиции создает физическую копию адресного пространства процесса-родителя, что в общем случае является довольно расточительной операцией, поскольку процесс часто после выполнения функции fork обращается к функции exec и незамедлительно освобождает только что скопированное пространство. Если область разделяемая, в версии V вместо копирования страницы ядро просто увеличивает значение счетчика ссылок на область (в таблице областей, в таблице страниц и в таблице pfdata). Тем не менее, для частных областей, таких как область данных и стека, ядро отводит в таблице областей и таблице страниц новую запись, после чего просматривает в таблице страниц все записи процесса-родителя: если запись верна, ядро увеличивает значение счетчика ссылок в таблице pfdata, отражающее количество процессов, использующих страницу через разные области (в отличие от тех процессов, которые используют данную страницу через разделяемую область). Если страница располагается на устройстве выгрузки, ядро увеличивает значение счетчика ссылок в таблице использования области подкачки.

Рисунок 9.14. Взаимосвязь между структурами данных, участвующими в реализации механизма замещения страниц по обращению
Теперь на страницу могут ссылаться обе области, использующие эту страницу совместно, пока процесс не ведет на нее запись. Как только страница понадобится процессу для записи, ядро создаст ее копию, с тем, чтобы у каждой области была своя личная версия страницы. Для этого при выполнении функции fork в каждой записи таблицы страниц, соответствующей частным областям родителя и потомка, ядро устанавливает бит "копирования при записи". Если один из процессов попытается что-то записать на страницу, он получит отказ системы защиты, после чего для него будет создана новая копия содержимого страницы. Таким образом, физическое копирование страницы откладывается до того момента, когда в этом возникнет реальная потребность.
В качестве примера рассмотрим . Процессы разделяют доступ к таблице страниц совместно используемой области команд T, поэтому значение счетчика ссылок на область равно 2, а на страницы области единице (в таблице pfdata). Ядро назначает процессу-потомку новую область данных C1, являющуюся копией области P1 процесса-родителя. Обе области используют одни и те же записи таблицы страниц, это видно на примере страницы с виртуальным адресом 97К. Этой странице в таблице pfdata соответствует запись с номером 613, счетчик ссылок в которой равен 2, ибо на страницу ссылаются две области.

В ходе выполнения функции fork в системе BSD создается физическая копия страниц родительского процесса. Однако, учитывая наличие ситуаций, в которых создание физической копии не является обязательным, в системе BSD существует также функция vfork, которая используется в том случае, если процесс сразу по завершении функции fork собирается запустить функцию exec. Функция vfork не копирует таблицы страниц, поэтому она работает быстрее, чем функция fork в версии V системы UNIX. Однако процесс-потомок при этом исполняется в тех же самых физических адресах, что и его родитель, и может поэтому затереть данные и стек родительского процесса. Если программист использует функцию vfork неверно, может возникнуть опасная ситуация, поэтому вся ответственность за ее использование возлагается на программиста. Различие в подходах к рассматриваемому вопросу в системах UNIX и BSD имеет философский характер, они дают разный ответ на один и тот же вопрос: следует ли ядру скрывать особенности реализации своих функций, превращая их в тайну для пользователей, или же стоит дать опытным пользователям возможность повысить эффективность выполнения системных операций?
|
int global; main() { int local; local = 1; if (vfork() == 0) { /* потомок */ global = 2; /* запись в область данных родителя */ local = 3; /* запись в стек родителя */ _exit(); } printf("global %d local %d\n",global,local); } |
В качестве примера рассмотрим программу, приведенную на . После выполнения функции vfork процесс-потомок не запускает функцию exec, а переустанавливает значения переменных global и local и завершается (). Система гарантирует, что процесс-родитель приостанавливается до того момента, когда потомок исполнит функции exec или exit. Возобновив в конечном итоге свое выполнение, процесс-родитель обнаружит, что значения двух его переменных не совпадают с теми значениями, которые были у них до обращения к функции vfork ! Еще больший эффект может произвести возвращение процесса-потомка из функции, вызвавшей функцию vfork (см. ).
9.2.1.2 Функция exec в системе с замещением страниц
Как уже говорилось в , когда процесс обращается к системной функции exec, ядро считывает из файловой системы в память указанный исполняемый файл. Однако в системе с замещением страниц по запросу исполняемый файл, имеющий большой размер, может не уместиться в доступном пространстве основной памяти. Поэтому ядро не назначает ему сразу все пространство, а отводит место в памяти по мере надобности. Сначала ядро назначает файлу таблицы страниц и дескрипторы дисковых блоков, помечая страницы в записях таблиц как "заполняемые при обращении" (для всех данных, кроме имеющих тип bss) или "обнуляемые при обращении" (для данных типа bss). Считывая в память каждую страницу файла по алгоритму read, процесс получает ошибку из-за отсутствия (недоступности) данных. Подпрограмма обработки ошибок проверяет, является ли страница "заполняемой при обращении" (тогда ее содержимое будет немедленно затираться содержимым исполняемого файла и поэтому ее не надо очищать) или "обнуляемой при обращении" (тогда ее следует очистить). В мы увидим, как это происходит. Если процесс не может поместиться в памяти, "сборщик" страниц освобождает для него место, периодически откачивая из памяти неиспользуемые страницы.
В этой схеме видны явные недостатки. Во-первых, при чтении каждой страницы исполняемого файла процесс сталкивается с ошибкой из-за обращения к отсутствующей странице, пусть даже процесс никогда и не обращался к ней. Во-вторых, если после того, как "сборщик" страниц откачал часть страниц из памяти, была запущена функция exec, каждая только что выгруженная и вновь понадобившаяся страница потребует дополнительную операцию по ее загрузке. Чтобы повысить эффективность функции exec, ядро может востребовать страницу непосредственно из исполняемого файла, если данные в файле соответствующим образом настроены, что определяется значением т.н. "магического числа". Однако, использование стандартных алгоритмов доступа к файлу (например, bmap) потребовало бы при обращении к странице, состоящей из блоков косвенной адресации, больших затрат, связанных с многократным использованием буферного кэша для чтения каждого блока. Кроме того, функция bmap не является реентерабельной, отсюда возникает опасность нарушения целостности данных. Во время выполнения системной функции read ядро устанавливает в пространстве процесса значения различных параметров ввода-вывода. Если при попытке скопировать данные в пространство пользователя процесс столкнется с отсутствием нужной страницы, он, считывая страницу из файловой системы, может затереть содержащие эти параметры поля. Поэтому ядро не может прибегать к использованию обычных алгоритмов обработки ошибок данного рода. Конечно же алгоритмы должны быть в обычных случаях реентерабельными, поскольку у каждого процесса свое отдельное адресное пространство и процесс не может одновременно исполнять несколько системных функций.
Для того, чтобы считывать страницы непосредственно из исполняемого файла, ядро во время исполнения функции exec составляет список номеров дисковых блоков файла и присоединяет этот список к индексу файла. Работая с таблицами страниц такого файла, ядро находит дескриптор дискового блока, содержащего страницу, и запоминает номер блока внутри файла; этот номер позже используется при загрузке страницы из файла. На показан пример, в котором страница имеет адрес расположения в логическом блоке с номером 84 от начала файла. В области имеется указатель на индекс, в котором содержится номер соответствующего физического блока на диске (279).

Рисунок 9.17. Отображение файла на область
СТРУКТУРЫ ДАННЫХ ЯДРА
Большинство информационных структур ядра размещается в таблицах фиксированного размера, а не в динамически выделенной памяти. Преимущество такого подхода состоит в том, что программа ядра проста, но в ней ограничивается число элементов информационной структуры до значения, предварительно заданного при генерации системы. Если во время функционирования системы число элементов информационной структуры ядра выйдет за указанное значение, ядро не сможет динамически выделить место для новых элементов и должно сообщить об ошибке пользователю, сделавшему запрос. Если, с другой стороны, ядро сгенерировано таким образом, что выход за границы табличного пространства будет маловероятен, дополнительное табличное пространство может не понадобиться, поскольку оно не может быть использовано для других целей. Как бы то ни было, простота алгоритмов ядра представляется более важной, чем сжатие последних байтов оперативной памяти. Обычно в алгоритмах для поиска свободных мест в таблицах используются несложные циклы и этот метод более понятен и иногда более эффективен по сравнению с более сложными схемами выделения памяти.
Comments:
Copyright ©
СУПЕРБЛОК
До сих пор в этой главе описывалась структура файла, при этом предполагалось, что индекс предварительно связывался с файлом и что уже были определены дисковые блоки, содержащие информацию. В следующих разделах описывается, каким образом ядро назначает индексы и дисковые блоки. Чтобы понять эти алгоритмы, рассмотрим структуру суперблока.
Суперблок состоит из следующих полей:
размер файловой системы, количество свободных блоков в файловой системе, список свободных блоков, имеющихся в файловой системе, индекс следующего свободного блока в списке свободных блоков, размер списка индексов, количество свободных индексов в файловой системе, список свободных индексов в файловой системе, следующий свободный индекс в списке свободных индексов, заблокированные поля для списка свободных блоков и свободных индексов, флаг, показывающий, что в суперблок были внесены изменения.
В оставшейся части главы будет объяснено, как пользоваться массивами, указателями и замками блокировки. Ядро периодически переписывает суперблок на диск, если в суперблок были внесены изменения, для того, чтобы обеспечивалась согласованность с данными, хранящимися в файловой системе.
Comments:
Copyright ©
СВЯЗЬ ТИПА NEWCASTLЕ
В предыдущем разделе мы рассмотрели тип сильносвязанной системы, для которого характерна посылка всех возникающих на периферийном процессоре обращений к функциям подсистемы управления файлами на удаленный (центральный) процессор. Теперь перейдем к рассмотрению систем с менее сильной связью, которые состоят из машин, производящих обращение к файлам, находящимся на других машинах. В сети, состоящей из персональных компьютеров и рабочих станций, например, пользователи часто обращаются к файлам, расположенным на большой машине. В последующих двух разделах мы рассмотрим такие конфигурации систем, в которых все системные функции выполняются в локальных подсистемах, но при этом имеется возможность обращения к файлам (через функции подсистемы управления файлами), расположенным на других машинах.
Для идентифицирования удаленных файлов в этих системах используется один из следующих двух путей. В одних системах в составное имя файла добавляется специальный символ: компонента имени, предшествующая этому символу, идентифицирует машину, остальная часть имени - файл, находящийся на этой машине. Так, например, составное имя "sftig!/fs1/mjb/rje"
идентифицирует файл "/fs1/mjb/rje", находящийся на машине "sftig". Такая схема идентифицирования файла соответствует соглашению, установленному программой uucp относительно передачи файлов между системами типа UNIX. В другой схеме удаленные файлы идентифицируются добавлением к имени специального префикса, например: /../sftig/fs1/mjb/rje
где "/../" - префикс, свидетельствующий о том, что файл удаленный; вторая компонента имени файла является именем удаленной машины. В данной схеме используется привычный синтаксис имен файлов в системе UNIX, поэтому в отличие от первой схемы здесь пользовательским программам нет необходимости приноравливаться к использованию имен, имеющих необычную конструкцию (см. [Pike 85]).

Рисунок 13.9. Формулирование запросов к файловому серверу (процессору)
Всю оставшуюся часть раздела мы посвятим рассмотрению модели системы, использующей связь типа Newcastle, в которой ядро не занимается распознаванием удаленных файлов; эта функция полностью возлагается на подпрограммы из стандартной Си-библиотеки, выполняющие в данном случае роль системного интерфейса. Эти подпрограммы анализируют первую компоненту имени файла, в обоих описанных способах идентифицирования содержащую признак удаленности файла. В этом состоит отступление от заведенного порядка, при котором библиотечные подпрограммы не занимаются синтаксическим разбором имен файлов. На показано, каким образом формулируются запросы к файловому серверу. Если файл локальный, ядро локальной системы обрабатывает запрос обычным способом. Рассмотрим обратный случай: open("/../sftig/fs1/mjb/rje/file",O_RDONLY);
Подпрограмма open из Си- библиотеки анализирует первые две компоненты составного имени файла и узнает, что файл следует искать на удаленной машине "sftig". Чтобы иметь информацию о том, была ли ранее у процесса связь с данной машиной, подпрограмма заводит специальную структуру, в которой запоминает этот факт, и в случае отрицательного ответа устанавливает связь с файловым сервером, работающим на удаленной машине. Когда процесс формулирует свой первый запрос на дистанционную обработку, удаленный сервер подтверждает запрос, в случае необходимости ведет запись в поля пользовательского и группового кодов идентификации и создает процессспутник, который будет выступать от имени процесса-клиента.
Чтобы выполнять запросы клиента, спутник должен иметь на удаленной машине те же права доступа к файлам, что и клиент. Другими словами, пользователь "mjb" должен иметь и к удаленным, и к локальным файлам одинаковые права доступа. К сожалению, не исключена возможность того, что код идентификации клиента "mjb" может совпасть с кодом идентификации другого клиента удаленной машины. Таким образом, администраторам систем на работающих в сети машинах следует либо следить за назначением каждому пользователю кода идентификации, уникального для всей сети, либо в момент формулирования запроса на сетевое обслуживание выполнять преобразование кодов. Если это не будет сделано, процесс-спутник будет иметь на удаленной машине права другого клиента.
Более деликатным вопросом является получение в отношении работы с удаленными файлами прав суперпользователя. С одной стороны, клиент-суперпользователь не должен иметь те же права в отношении удаленной системы, чтобы не вводить в заблуждение средства защиты удаленной системы. С другой стороны, некоторые из программ, если им не предоставить права суперпользователя, просто не смогут работать. Примером такой программы является программа mkdir (см. ), создающая новый каталог. Удаленная система не разрешила бы клиенту создавать новый каталог, поскольку на удалении права суперпользователя не действуют. Проблема создания удаленных каталогов служит серьезным основанием для пересмотра системной функции mkdir в сторону расширения ее возможностей в автоматическом установлении всех необходимых пользователю связей. Тем не менее, получение setuid-программами (к которым относится и программа mkdir) прав суперпользователя по отношению к удаленным файлам все еще остается общей проблемой, требующей своего решения. Возможно, что наилучшим решением этой проблемы было бы установление для файлов дополнительных характеристик, описывающих доступ к ним со стороны удаленных суперпользователей; к сожалению, это потребовало бы внесения изменений в структуру дискового индекса (в части добавления новых полей) и породило бы слишком большой беспорядок в существующих системах.
Если подпрограмма open завершается успешно, локальная библиотека оставляет об этом соответствующую отметку в доступной для пользователя структуре, содержащей адрес сетевого узла, идентификатор процесса-спутника, дескриптор файла и другую аналогичную информацию. Библиотечные подпрограммы read и write устанавливают, исходя из дескриптора, является ли файл удаленным, и в случае положительного ответа посылают спутнику сообщение. Процесс-клиент взаимодействует со своим спутником во всех случаях обращения к системным функциям, нуждающимся в услугах удаленной машины. Если процесс обращается к двум файлам, расположенным на одной и той же удаленной машине, он пользуется одним спутником, но если файлы расположены на разных машинах, используются уже два спутника: по одному на каждой машине. Два спутника используются и в том случае, когда к файлу на удаленной машине обращаются два процесса. Вызывая системную функцию через спутника, процесс формирует сообщение, включающее в себя номер функции, имя пути поиска и другую необходимую информацию, аналогичную той, которая входит в структуру сообщения в системе с периферийными процессорами.
Механизм выполнения операций над текущим каталогом более сложен. Когда процесс выбирает в качестве текущего удаленный каталог, библиотечная подпрограмма посылает соответствующее сообщение спутнику, который изменяет текущий каталог, при этом подпрограмма запоминает, что каталог удаленный. Во всех случаях, когда имя пути поиска начинается с символа, отличного от наклонной черты (/), подпрограмма посылает это имя на удаленную машину, где процесс-спутник прокладывает маршрут, начиная с текущего каталога. Если текущий каталог - локальный, подпрограмма просто передает имя пути поиска ядру локальной системы. Системная функция chroot в отношении удаленного каталога выполняется похоже, но при этом ее выполнение для ядра локальной системы проходит незамеченным; строго говоря, процесс может оставить эту операцию без внимания, поскольку только библиотека фиксирует ее выполнение.
Когда процесс вызывает функцию fork, соответствующая библиотечная подпрограмма посылает сообщения каждому спутнику. Процессы -спутники выполняют операцию ветвления и посылают идентификаторы своих потомков клиенту-родителю. Процесс-клиент запускает системную функцию fork, которая передает управление порождаемому потомку; локальный потомок ведет диалог с удаленным потомком-спутником, адреса которого сохранила библиотечная подпрограмма. Такая трактовка функции fork облегчает процессам-спутникам контроль над открытыми файлами и текущими каталогами. Когда процесс, работающий с удаленными файлами, завершается (вызывая функцию exit), подпрограмма посылает сообщения всем его удаленным спутникам, чтобы они по получении сообщения проделали то же самое. Отдельные моменты реализации системных функций exec и exit затрагиваются в упражнениях.
Преимущество связи типа Newcastle состоит в том, что обращение процесса к удаленным файлам становится "прозрачным" (незаметным для пользователя), при этом в ядро системы никаких изменений вносить не нужно. Однако, данной разработке присущ и ряд недостатков. Прежде всего, при ее реализации возможно снижение производительности системы. В связи с использованием расширенной Си-библиотеки размер используемой каждым процессом памяти увеличивается, даже если процесс не обращается к удаленным файлам; библиотека дублирует функции ядра и требует для себя больше места в памяти. Увеличение размера процессов приводит к удлинению продолжительности периода запуска и может вызвать большую конкуренцию за ресурсы памяти, создавая условия для более частой выгрузки и подкачки задач. Локальные запросы будут исполняться медленнее из-за увеличения продолжительности каждого обращения к ядру, замедление может грозить и обработке удаленных запросов, затраты по пересылке которых по сети увеличиваются. Дополнительная обработка удаленных запросов на пользовательском уровне увеличивает количество переключений контекста, операций по выгрузке и подкачке процессов. Наконец, для того, чтобы обращаться к удаленным файлам, программы должны быть перекомпилированы с использованием новых библиотек; старые программы и поставленные объектные модули без этого работать с удаленными файлами не смогут. Все эти недостатки отсутствуют в системе, описываемой в следующем разделе.
Comments:
Copyright ©
СВОПИНГ
Описание алгоритма свопинга можно разбить на три части: управление пространством на устройстве выгрузки, выгрузка процессов из основной памяти и подкачка процессов в основную память.
ТАЙМЕР
В функции программы обработки прерываний по таймеру входит:
перезапуск часов, вызов на исполнение функций ядра, использующих встроенные часы, поддержка возможности профилирования выполнения процессов в режимах ядра и задачи; сбор статистики о системе и протекающих в ней процессах, слежение за временем, посылка процессам сигналов "будильника" по запросу, периодическое возобновление процесса подкачки (см. ), управление диспетчеризацией процессов.
Некоторые из функций реализуются при каждом прерывании по таймеру, другие - по прошествии нескольких таймерных тиков. Программа обработки прерываний по таймеру запускается с высоким приоритетом обращения к процессору, не допуская во время работы возникновения других внешних событий (таких как прерывания от периферийных устройств). Поэтому программа обработки прерываний по таймеру работает очень быстро, за максимально-короткое время пробегая свои критические отрезки, которые должны выполняться без прерываний со стороны других процессов. Алгоритм обработки прерываний по таймеру приведен на .
| #include <sys/types.h> #include <sys/stat.h> #include <sys/signal.h>
main(argc,argv) int argc; char *argv[]; { extern unsigned alarm(); extern wakeup(); struct stat statbuf; time_t axtime; if (argc != 2) { printf("только 1 аргумент\n"); exit(); } axtime = (time_t) 0; for (;;) { /* получение значения времени доступа к файлу */ if (stat(argv[1],&statbuf) == -1) { printf("файла с именем %s нет\n",argv[1]); exit(); } if (axtime != statbuf.st_atime) { printf("к файлу %s было обращение\n",argv[1]); axtime = statbuf.st_atime; } signal(SIGALRM,wakeup); /* подготовка к приему сигнала */ alarm(60); pause(); /* приостанов до получения сигнала */ } } wakeup() { } |
Рисунок 8.8. Программа, использующая системную функцию alarm
| алгоритм clock входная информация: отсутствует выходная информация: отсутствует { перезапустить часы; /* чтобы они снова посылали преры- вания */ если (таблица ответных сигналов не пуста) { установить время для ответных сигналов; запустить функцию callout, если время истекло; } если (профилируется выполнение в режиме ядра) запомнить значение счетчика команд в момент прерыва- ния; если (профилируется выполнение в режиме задачи) запомнить значение счетчика команд в момент прерыва- ния; собрать статистику о самой системе; собрать статистику о протекающих в системе процессах; выверить значение продолжительности ИЦП процессом; если (прошла 1 секунда или более и исполняется отрезок, не являющийся критическим) { для (всех процессов в системе) { установить "будильник", если он активен; выверить значение продолжительности ИЦП; если (процесс будет исполняться в режиме задачи) выверить приоритет процесса; } возобновить в случае необходимости выполнение про- цесса подкачки; } } |
Рисунок 8.9. Алгоритм обработки прерываний по таймеру
ТЕРМИНАЛЬНЫЕ ДРАЙВЕРЫ
Терминальные драйверы выполняют ту же функцию, что и остальные драйверы: управление передачей данных от и на терминалы. Однако, терминалы имеют одну особенность, связанную с тем, что они обеспечивают интерфейс пользователя с системой. Обеспечивая интерактивное использование системы UNIX, терминальные драйверы имеют свой внутренний интерфейс с модулями, интерпретирующими ввод и вывод строк. В каноническом режиме интерпретаторы строк преобразуют неструктурированные последовательности данных, введенные с клавиатуры, в каноническую форму (то есть в форму, соответствующую тому, что пользователь имел ввиду на самом деле) прежде, чем послать эти данные принимающему процессу; строковый интерфейс также преобразует неструктурированные последовательности выходных данных, созданных процессом, в формат, необходимый пользователю. В режиме без обработки строковый интерфейс передает данные между процессами и терминалом без каких-либо преобразований.
Программисты, например, работают на клавиатуре терминала довольно быстро, но с ошибками. На этот случай терминалы имеют клавишу стирания ("erase"; клавиша может быть обозначена таким образом), чтобы пользователь имел возможность стирать часть введенной строки и вводить коррективы. Терминалы пересылают машине всю введенную последовательность, включая и символы стирания (). В каноническом режиме строковый интерфейс буферизует информацию в строки (набор символов, заканчивающийся символом возврата каретки ()) и процессы стирают символы у себя, прежде чем переслать исправленную последовательность считывающему процессу.
В функции строкового интерфейса входят:
построчный разбор введенных последовательностей; обработка символов стирания; обработка символов "удаления", отменяющих все остальные символы, введенные до того в текущей строке; отображение символов, полученных терминалом; расширение выходных данных, например, преобразование символов табуляции в последовательности пробелов; сигнализирование процессам о зависании терминалов и прерывании строк или в ответ на нажатие пользователем клавиши удаления; предоставление возможности не обрабатывать специальные символы, такие как символы стирания, удаления и возврата каретки.
Функционирование без обработки подразумевает использование асинхронного терминала, поскольку процессы могут считывать символы в том виде, в каком они были введены, вместо того, чтобы ждать, когда пользователь нажмет клавишу ввода или возврата каретки.
Ричи отметил, что первые строковые интерфейсы, используемые еще при разработке системы в начале 70-х годов, работали в составе программ командного процессора и редактора, но не в ядре (см. [Ritchie 84], стр.1580). Однако, поскольку в их функциях нуждается множество программ, их место в составе ядра. Несмотря на то, что строковый интерфейс выполняет такие функции, из которых логически вытекает его место между терминальным драйвером и остальной частью ядра, ядро не запускает строковый интерфейс иначе, чем через терминальный драйвер. На показаны поток данных, проходящий через терминальный драйвер и строковый интерфейс, и соответствующие ему управляющие воздействия, проходящие через терминальный драйвер. Пользователи могут указать, какой строковый интерфейс используется посредством вызова системной функции ioctl, но реализовать схему, по которой одно устройство использовало бы несколько строковых интерфейсов одновременно, при чем каждый интерфейсный модуль, в свою очередь, успешно вызывал бы следующий модуль для обработки данных, довольно трудно.
Терминальный драйвер в каноническом режиме
Структуры данных, с которыми работают терминальные драйверы, связаны с тремя символьными списками: списком для хранения данных, выводимых на терминал, списком для хранения неструктурированных вводных данных, поступивших в результате выполнения программы обработки прерывания от терминала, вызванного попыткой пользователя ввести данные с клавиатуры, и списком для хранения обработанных входных данных, поступивших в результате преобразования строковым интерфейсом специальных символов (таких как символы стирания и удаления) в неструктурированном списке.
Когда процесс ведет запись на терминал (), терминальный драйвер запускает строковый интерфейс. Строковый интерфейс в цикле считывает символы из адресного пространства процесса и помещает их в символьный список для хранения выводных данных до тех пор, пока поток данных не будет исчерпан. Строковый интерфейс обрабатывает выводимые символы, например, заменяя символы табуляции на последовательности пробелов. Если количество символов в списке для хранения выводных данных превысит верхнюю отметку, строковый интерфейс вызывает процедуры драйвера, пересылающие данные из символьного списка на терминал и после этого приостанавливающие выполнение процесса, ведущего запись. Когда объем информации в списке для хранения выводных данных падает за нижнюю отметку, программа обработки прерываний возобновляет выполнение всех процессов, приостановленных до того момента, когда терминал сможет принять следующую порцию данных. Строковый интерфейс завершает цикл обработки, скопировав всю выводимую информацию из адресного пространства задачи в соответствующий символьный список, и вызывает выполнение процедур драйвера, пересылающих данные на терминал, о которых уже было сказано выше.
| алгоритм terminal_write { выполнить (пока из пространства задачи еще поступают данные) { если (на терминал поступает информация) { приступить к выполнению операции записи данных из списка, хранящего выводные данные; приостановиться (до того момента, когда терми- нал будет готов принять следующую порцию дан- ных); продолжить; /* возврат к началу цикла */ } скопировать данные в объеме символьного блока из пространства задачи в список, хранящий выводные данные: строковый интерфейс преобразует символы табуляции и т.д.; }
приступить к выполнению операции записи данных из спис- ка, хранящего выводные данные; } |
Чтение данных с терминала в каноническом режиме более сложная операция. В вызове системной функции read указывается количество байт, которые процесс хочет считать, но строковый интерфейс выполняет чтение по получении символа перевода каретки, даже если количество символов не указано. Это удобно с практической точки зрения, так как процесс не в состоянии предугадать, сколько символов пользователь введет с клавиатуры, и, с другой стороны, не имеет смысла ждать, когда пользователь введет большое число символов. Например, пользователи вводят командные строки для командного процессора shell и ожидают ответа shell'а на команду по получении символа возврата каретки. При этом нет никакой разницы, являются ли введенные строки простыми командами, такими как "date" или "who", или же это более сложные последовательности команд, подобные следующей: pic file* | tbl | eqn | troff -mm -Taps | apsend
Терминальный драйвер и строковый интерфейс ничего не знают о синтаксисе командного процессора shell, и это правильно, поскольку другие программы, которые считывают информацию с терминалов (например, редакторы), имеют различный синтаксис команд. Поэтому строковый интерфейс выполняет чтение по получении символа возврата каретки.
На показан алгоритм чтения с терминала. Предположим, что терминал работает в каноническом режиме; в будет рассмотрена работа в режиме без обработки. Если в настоящий момент в любом из символьных списков для хранения вводной информации отсутствуют данные, процесс, выполняющий чтение, приостанавливается до поступления первой строки данных. Когда данные поступают, программа обработки прерывания от терминала запускает "программу обработки прерывания" строкового интерфейса, которая помещает данные в список для хранения неструктурированных вводных данных для передачи процессам, осуществляющим чтение, и в список для хранения выводных данных, передаваемых в качестве эхосопровождения на терминал. Если введенная строка содержит символ возврата каретки, программа обработки прерывания возобновляет выполнение всех приостановленных процессов чтения. Когда процесс, осуществляющий чтение, выполняется, драйвер выбирает символы из списка для хранения неструктурированных вводных данных, обрабатывает символы стирания и удаления и помещает символы в канонический символьный список. Затем он копирует строку символов в адресное пространство задачи до символа возврата каретки или до исчерпания числа символов, указанного в вызове системной функции read, что встретится раньше. Однако, процесс может обнаружить, что данных, ради которых он возобновил свое выполнение, больше не существует: другие процессы считали данные с терминала и удалили их из списка для неструктурированных вводных данных до того, как первый процесс был запущен вновь. Такая ситуация похожа на ту, которая имеет место, когда из канала считывают данные несколько процессов.
|
алгоритм terminal_read { если (в каноническом символьном списке отсутствуют дан- ные) { выполнить (пока в списке для неструктурированных вводных данных отсутствует информация) { если (терминал открыт с параметром "no delay" (без задержки)) возвратить управление; если (терминал в режиме без обработки с использо- ванием таймера и таймер не активен) предпринять действия к активизации таймера (таблица ответных сигналов); приостановиться (до поступления данных с термина- ла); } /* в списке для неструктурированных вводных данных есть информация */ если (терминал в режиме без обработки) скопировать все данные из списка для неструктури- рованных вводных данных в канонический список; в противном случае /* терминал в каноническом ре- жиме */ { выполнить (пока в списке для неструктурированных вводных данных есть символы) { копировать по одному символу из списка для неструктурированных вводных данных в кано- нический список: выполнить обработку символов стирания и уда- ления; если (символ - "возврат каретки" или "конец файла") прерваться; /* выход из цикла */ } } } выполнить (пока в каноническом списке еще есть символы и не исчерпано количество символов, указанное в вызове функции read) копировать символы из символьных блоков канонического списка в адресное пространство задачи; } |
Рисунок 10.15. Алгоритм чтения с терминала
Обработка символов в направлении ввода и в направлении вывода асимметрична, что видно из наличия двух символьных списков для ввода и одного - для вывода. Строковый интерфейс выводит данные из пространства задачи, обрабатывает их и помещает их в список для хранения выводных данных. Для симметрии следовало бы иметь только один список для вводных данных. Однако, в таком случае потребовалось бы использование программы обработки прерываний для интерпретации символов стирания и удаления, что сделало бы процедуру более сложной и длительной и запретило бы возникновение других прерываний на все критическое время. Использование двух символьных списков для ввода подразумевает, что программа обработки прерываний может просто сбросить символы в список для неструктурированных вводных данных и возобновить выполнение процесса, осуществляющего чтение, который собственно и возьмет на себя работу по интерпретации вводных данных. При этом программа обработки прерываний немедленно помещает введенные символы в список для хранения выводных данных, так что пользователь испытывает лишь минимальную задержку при просмотре введенных символов на терминале.
|
char input[256]; main() { register int i; for (i = 0; i < 18; i++) { switch (fork()) { case -1: /* ошибка */ printf("операция fork не выполнена из-за ошибки\n"); exit(); default: /* родительский процесс */ break; case 0: /* порожденный процесс */ for (;;) { read(0,input,256); /* чтение строки */ printf("%d чтение %s\n",i,input); } } } } |
На приведена программа, в которой родительский процесс порождает несколько процессов, осуществляющих чтение из файла стандартного ввода, конкурируя за получение данных, вводимых с терминала. Ввод с терминала обычно осуществляется слишком медленно для того, чтобы удовлетворить все процессы, ведущие чтение, поэтому процессы большую часть времени находятся в приостановленном состоянии в соответствии с алгоритмом terminal_read, ожидая ввода данных. Когда пользователь вводит строку данных, программа обработки прерываний от терминала возобновляет выполнение всех процессов, ведущих чтение; поскольку они были приостановлены с одним и тем же уровнем приоритета, они выбираются для запуска с одинаковым уровнем приоритета. Пользователь не в состоянии предугадать, какой из процессов выполняется и считывает строку данных; успешно созданный процесс печатает значение переменной i в момент его создания. Все другие процессы в конце концов будут запущены, но вполне возможно, что они не обнаружат введенной информации в списках для хранения вводных данных и их выполнение снова будет приостановлено. Вся процедура повторяется для каждой введенной строки; нельзя дать гарантию, что ни один из процессов не захватит все введенные данные.
Одновременному чтению с терминала несколькими процессами присуща неоднозначность, но ядро справляется с ситуацией наилучшим образом. С другой стороны, ядро обязано позволять процессам одновременно считывать данные с терминала, иначе порожденные командным процессором shell процессы, читающие из стандартного ввода, никогда не будут работать, поскольку shell тоже обращается к стандартному вводу. Короче говоря, процессы должны синхронизировать свои обращения к терминалу на пользовательском уровне.
Когда пользователь вводит символ "конец файла" (Ctrl-d в ASCII), строковый интерфейс передает функции read введенную строку до символа конца файла, но не включая его. Он не передает данные (код возврата 0) функции read, если в символьном списке встретился только символ "конец файла"; вызывающий процесс сам распознает, что обнаружен конец файла и больше не следует считывать данные с терминала. Если еще раз обратиться к примерам программ по shell'у, приведенным в , можно отметить, что цикл работы shell'а завершается, когда пользователь нажимает <Ctrl-d>: функция read возвращает 0 и производится выход из shell'а.
В этом разделе рассмотрена работа терминалов ввода-вывода, которые передают данные на машину по одному символу за одну операцию, в точности как пользователь их вводит с клавиатуры. Интеллектуальные терминалы подготавливают свой вводной поток на внешнем устройстве, освобождая центральный процессор для другой работы. Структура драйверов для таких терминалов походит на структуру драйверов для терминалов ввода-вывода, несмотря на то, что функции строкового интерфейса различаются в зависимости от возможностей внешних устройств.
Терминальный драйвер в режиме без обработки символов
Пользователи устанавливают параметры терминала, такие как символы стирания и удаления, и извлекают значения текущих установок с помощью системной функции ioctl. Сходным образом они устанавливают необходимость эхо-сопровождения ввода данных с терминала, задают скорость передачи информации в бодах, заполняют очереди символов ввода и вывода или вручную запускают и останавливают выводной поток символов. В информационной структуре терминального драйвера хранятся различные управляющие установки (см. [SVID 85], стр.281), и строковый интерфейс получает параметры функции ioctl и устанавливает или считывает значения соответствующих полей структуры данных. Когда процесс устанавливает значения параметров терминала, он делает это для всех процессов, использующих терминал. Установки терминала не сбрасываются автоматически при выходе из процесса, сделавшего изменения в установках.
Процессы могут также перевести терминал в режим без обработки символов, в котором строковый интерфейс передает символы в точном соответствии с тем, как пользователь ввел их: обработка вводного потока полностью отсутствует. Однако, ядро должно знать, когда выполнить вызванную пользователем системную функцию read, поскольку символ возврата каретки трактуется как обычный введенный символ. Оно выполняет функцию read после того, как с терминала будет введено минимальное число символов или по прохождении фиксированного промежутка времени от момента получения с терминала любого набора символов. В последнем случае ядро хронометрирует ввод символов с терминала, помещая записи в таблицу ответных сигналов (). Оба критерия (минимальное число символов и фиксированный промежуток времени) задаются в вызове функции ioctl. Когда соответствующие критерии удовлетворены, программа обработки прерываний строкового интерфейса возобновляет выполнение всех приостановленных процессов. Драйвер пересылает все символы из списка для хранения неструктурированных вводных данных в канонический список и выполняет запрос процесса на чтение, следуя тому же самому алгоритму, что и в случае работы в каноническом режиме. Режим без обработки символов особенно важен в экранно-ориентированных приложениях, таких как экранный редактор vi, многие из команд которого не заканчиваются символом возврата каретки. Например, команда dw удаляет слово в текущей позиции курсора.
На приведена программа, использующая функцию ioctl для сохранения текущих установок терминала для файла с дескриптором 0, что соответствует значению дескриптора файла стандартного ввода. Функция ioctl с командой TCGETA приказывает драйверу извлечь установки и сохранить их в структуре с именем savetty в адресном пространстве задачи. Эта команда часто используется для того, чтобы определить, является ли файл терминалом или нет, поскольку она ничего не изменяет в системе: если она завершается неудачно, процессы предполагают, что файл не является терминалом. Здесь же, процесс вторично вызывает функцию ioctl для того, чтобы перевести терминал в режим без обработки: он отключает эхо-сопровождение ввода символов и готовится к выполнению операций чтения с терминала по получении с терминала 5 символов, как минимум, или по прохождении 10 секунд с момента ввода первой порции символов. Когда процесс получает сигнал о прерывании, он сбрасывает первоначальные параметры терминала и завершается.
| #include <signal.h> #include <termio.h> struct termio savetty; main() { extern sigcatch(); struct termio newtty; int nrd; char buf[32]; signal(SIGINT,sigcatch); if (ioctl(0,TCGETA,&savetty) == -1) { printf("ioctl завершилась неудачно: нет терминала\n"); exit(); } newtty = savetty; newtty.c_lflag &= ~ICANON;/* выход из канонического режима */ newtty.c_lflag &= ~ECHO; /* отключение эхо-сопровождения*/ newtty.c_cc[VMIN] = 5; /* минимум 5 символов */ newtty.c_cc[VTIME] = 100; /* интервал 10 секунд */ if (ioctl(0,TCSETAF,&newtty) == -1) { printf("не могу перевести тер-л в режим без обработки\n"); exit(); } for(;;) { nrd = read(0,buf,sizeof(buf)); buf[nrd] = 0; printf("чтение %d символов '%s'\n",nrd,buf); } } sigcatch() { ioctl(0,TCSETAF,&savetty); exit(); } |
|
#include <fcntl.h> main() { register int i,n; int fd; char buf[256]; /* открытие терминала только для чтения с опцией "no delay" */ if((fd = open("/dev/tty",O_RDONLYO_NDELAY)) == -1) exit(); n = 1; for(;;) /* всегда */ { for(i = 0; i < n; i++) ; if(read(fd,buf,sizeof(buf)) > 0) { printf("чтение с номера %d\n",n); n--; } else /* ничего не прочитано; возврат вследствие "no delay" */ n++; } } |
ТРАССИРОВКА ПРОЦЕССОВ
В системе UNIX имеется простейшая форма взаимодействия процессов, используемая в целях отладки, - трассировка процессов. Процесс-отладчик, например sdb, порождает трассируемый процесс и управляет его выполнением с помощью системной функции ptrace, расставляя и сбрасывая контрольные точки, считывая и записывая данные в его виртуальное адресное пространство. Трассировка процессов, таким образом, включает в себя синхронизацию выполнения процесса-отладчика и трассируемого процесса и управление выполнением последнего.
| if ((pid = fork()) == 0) { /* потомок - трассируемый процесс */ ptrace(0,0,0,0); exec("имя трассируемого процесса"); } /* продолжение выполнения процесса-отладчика */ for (;;) { wait((int *) 0); read(входная информация для трассировки команд) ptrace(cmd,pid,...); if (условие завершения трассировки) break; } |
Рисунок 11.1. Структура процесса отладки
Псевдопрограмма, представленная на , имеет типичную структуру отладочной программы. Отладчик порождает новый процесс, запускающий системную функцию ptrace, в результате чего в соответствующей процессу-потомку записи таблицы процессов ядро устанавливает бит трассировки. Процесс-потомок предназначен для запуска (exec) трассируемой программы. Например, если пользователь ведет отладку программы a.out, процесс-потомок запускает файл с тем же именем. Ядро отрабатывает функцию exec обычным порядком, но в финале замечает, что бит трассировки установлен, и посылает процессу-потомку сигнал прерывания. На выходе из функции exec, как и на выходе из любой другой функции, ядро проверяет наличие сигналов, обнаруживает только что посланный сигнал прерывания и исполняет программу трассировки процесса как особый случай обработки сигналов. Заметив установку бита трассировки, процесс-потомок выводит своего родителя из состояния приостанова, в котором последний находится вследствие исполнения функции wait, сам переходит в состояние трассировки, подобное состоянию приостанова (но не показанное на диаграмме состояний процесса, см. ), и выполняет переключение контекста.
Тем временем в обычной ситуации процесс-родитель (отладчик) переходит на пользовательский уровень, ожидая получения известия от трассируемого процесса. Когда соответствующее известие процессом-родителем будет получено, он выйдет из состояния ожидания (wait), прочитает (read) введенные пользователем команды и превратит их в серию обращений к функции ptrace, управляющих трассировкой процесса-потомка. Синтаксис вызова системной функции ptrace: ptrace(cmd,pid,addr,data);
где в качестве cmd указываются различные команды, например, чтения данных, записи данных, возобновления выполнения и т.п., pid - идентификатор трассируемого процесса, addr - виртуальный адрес ячейки в трассируемом процессе, где будет производиться чтение или запись, data - целое значение, предназначенное для записи. Во время исполнения системной функции ptrace ядро проверяет, имеется ли у отладчика потомок с идентификатором pid и находится ли этот потомок в состоянии трассировки, после чего заводит глобальную структуру данных, предназначенную для передачи данных между двумя процессами. Чтобы другие процессы, выполняющие трассировку, не могли затереть содержимое этой структуры, она блокируется ядром, ядро записывает в нее параметры cmd, addr и data, возобновляет процесс-потомок, переводит его в состояние "готовности к выполнению" и приостанавливается до получения от него ответа. Когда процесс-потомок продолжит свое выполнение (в режиме ядра), он исполнит соответствующую (трассируемую) команду, запишет результат в глобальную структуру и "разбудит" отладчика. В зависимости от типа команды потомок может вновь перейти в состояние трассировки и ожидать поступления новой команды или же выйти из цикла обработки сигналов и продолжить свое выполнение. При возобновлении работы отладчика ядро запоминает значение, возвращенное трассируемым процессом, снимает с глобальной структуры блокировку и возвращает управление пользователю.
Если в момент перехода процесса-потомка в состояние трассировки отладчик не находится в состоянии приостанова (wait), он не обнаружит потомка, пока не обратится к функции wait, после чего немедленно выйдет из функции и продолжит работу по вышеописанному плану.
| int data[32]; main() { int i; for (i = 0; i < 32; i++) printf("data[%d] = %d\n@,i,data[i]); printf("ptrace data addr Ox%x\n",data); } |
Рисунок 11.2. Программа trace (трассируемый процесс)
|
#define TR_SETUP 0 #define TR_WRITE 5 #define TR_RESUME 7 int addr; main(argc,argv) int argc; char *argv[]; { int i,pid; sscanf(argv[1],"%x",&addr); if ((pid = fork() == 0) { ptrace(TR_SETUP,0,0,0); execl("trace","trace",0); exit(); } for (i = 0; i < 32, i++) { wait((int *) 0); /* записать значение i в пространство процесса с * идентификатором pid по адресу, содержащемуся в * переменной addr */ if (ptrace(TR_WRITE,pid,addr,i) == -1) exit(); addr += sizeof(int); } /* трассируемый процесс возобновляет выполнение */ ptrace(TR_RESUME,pid,1,0); } |
Рассмотрим две программы, приведенные на Рисунках и и именуемые trace и debug, соответственно. При запуске программы trace с терминала массив data будет содержать нулевые значения; процесс выводит адрес массива и завершает работу. При запуске программы debug с передачей ей в качестве параметра значения, выведенного программой trace, происходит следующее: программа запоминает значение параметра в переменной addr, создает новый процесс, с помощью функции ptrace подготавливающий себя к трассировке, и запускает программу trace. На выходе из функции exec ядро посылает процессу-потомку (назовем его тоже trace) сигнал SIGTRAP (сигнал прерывания), процесс trace переходит в состояние трассировки, ожидая поступления команды от программы debug. Если процесс, реализующий программу debug, находился в состоянии приостанова, связанного с выполнением функции wait, он "пробуждается", обнаруживает наличие порожденного трассируемого процесса и выходит из функции wait. Затем процесс debug вызывает функцию ptrace, записывает значение переменной цикла i в пространство данных процесса trace по адресу, содержащемуся в переменной addr, и увеличивает значение переменной addr; в программе trace переменная addr хранит адрес точки входа в массив data. Последнее обращение процесса debug к функции ptrace вызывает запуск программы trace, и в этот момент массив data содержит значения от 0 до 31. Отладчики, подобные sdb, имеют доступ к таблице идентификаторов трассируемого процесса, из которой они получают информацию об адресах данных, используемых в качестве параметров функции ptrace.
Использование функции ptrace для трассировки процессов является обычным делом, но оно имеет ряд недостатков.
Для того, чтобы произвести передачу порции данных длиною в слово между процессом-отладчиком и трассируемым процессом, ядро должно выполнить четыре переключения контекста: оно переключает контекст во время вызова отладчиком функции ptrace, загружает и выгружает контекст трассируемого процесса и переключает контекст вновь на процесс-отладчик по получении ответа от трассируемого процесса. Все вышеуказанное необходимо, поскольку у отладчика нет иного способа получить доступ к виртуальному адресному пространству трассируемого процесса, отсюда замедленность протекания процедуры трассировки. Процесс-отладчик может вести одновременную трассировку нескольких процессов-потомков, хотя на практике эта возможность используется редко. Если быть более критичным, следует отметить, что отладчик может трассировать только своих ближайших потомков: если трассируемый процесс-потомок вызовет функцию fork, отладчик не будет иметь контроля над порождаемым, внучатым для него, процессом, что является серьезным препятствием в отладке многоуровневых программ. Если трассируемый процесс вызывает функцию exec, запускаемые образы задач тоже подвергаются трассировке под управлением ранее вызванной функции ptrace, однако отладчик может не знать имени исполняемого образа, что затрудняет проведение символьной отладки. Отладчик не может вести трассировку уже выполняющегося процесса, если отлаживаемый процесс не вызвал предварительно функцию ptrace, дав тем самым ядру свое согласие на трассировку. Это неудобно, так как в указанном случае выполняющийся процесс придется удалить из системы и перезапустить в режиме трассировки. Не разрешается трассировать setuid-программы, поскольку это может привести к нарушению защиты данных (ибо в результате выполнения функции ptrace в их адресное пространство производилась бы запись данных) и к выполнению недопустимых действий. Предположим, например, что setuid-программа запускает файл с именем "privatefile". Умелый пользователь с помощью функции ptrace мог бы заменить имя файла на "/bin/sh", запустив на выполнение командный процессор shell (и все программы, исполняемые shell'ом), не имея на то соответствующих полномочий. Функция exec игнорирует бит setuid, если процесс подвергается трассировке, тем самым адресное пространство setuid-программ защищается от пользовательской записи.
Киллиан [ Killian 84] описывает другую схему трассировки процессов, основанную на переключении файловых систем (см. ). Администратор монтирует файловую систему под именем "/proc"; пользователи идентифицируют процессы с помощью кодов идентификации и трактуют их как файлы, принадлежащие каталогу "/proc". Ядро дает разрешение на открытие файлов, исходя из кода идентификации пользователя процесса и кода идентификации группы. Пользователи могут обращаться к адресному пространству процесса путем чтения (read) файла и устанавливать точки прерываний путем записи (write) в файл. Функция stat сообщает различную статистическую информацию, касающуюся процесса. В данном подходе устранены три недостатка, присущие функции ptrace. Во-первых, эта схема работает быстрее, поскольку процесс-отладчик за одно обращение к указанным системным функциям может передавать больше информации, чем при работе с ptrace. Во-вторых, отладчик здесь может вести трассировку совершенно произвольных процессов, а не только своих потомков. Наконец, трассируемый процесс не должен предпринимать предварительно никаких действий по подготовке к трассировке; отладчик может трассировать и существующие процессы. Возможность вести отладку setuid-программ, предоставляемая только суперпользователю, реализуется как составная часть традиционного механизма защиты файлов.
Comments:
Copyright ©
Учет и статистика
В момент поступления прерывания по таймеру система может выполняться в режиме ядра или задачи, а также находиться в состоянии простоя (бездействия). Состояние простоя означает, что все процессы приостановлены в ожидании наступления события. Для каждого состояния процессора ядро имеет внутренние счетчики, устанавливаемые при каждом прерывании по таймеру. Позже пользовательские процессы могут проанализировать накопленную ядром статистическую информацию.
В пространстве каждого процесса имеются два поля для записи продолжительности времени, проведенного процессом в режиме ядра и задачи. В ходе обработки прерываний по таймеру ядро корректирует значение поля, соответствующего текущему режиму выполнения процесса. Процессы-родители собирают статистику о своих потомках при выполнении функции wait, беря за основу информацию, поступающую от завершающих свое выполнение потомков.
В пространстве каждого процесса имеется также одно поле для ведения учета использования памяти. В ходе обработки прерывания по таймеру ядро вычисляет общий объем памяти, занимаемый текущим процессом, исходя из размера частных областей процесса и его долевого участия в использовании разделяемых областей памяти. Если, например, процесс использует области данных и стека размером 25 и 40 Кбайт, соответственно, и разделяет с четырьмя другими процессами одну область команд размером 50 Кбайт, ядро назначает процессу 75 Кбайт памяти (50К/5 + 25К + 40К). В системе с замещением страниц ядро вычисляет объем используемой памяти путем подсчета числа используемых в каждой области страниц. Таким образом, если прерываемый процесс имеет две частные области и еще одну область разделяет с другим процессом, ядро назначает ему столько страниц памяти, сколько содержится в этих частных областях, плюс половину страниц, принадлежащих разделяемой области. Вся указанная информация отражается в учетной записи при завершении процесса и может быть использована для расчетов с заказчиками машинного времени.
УКАЗАНИЕ МЕСТА В ФАЙЛЕ, ГДЕ БУДЕТ ВЫПОЛНЯТЬСЯ ВВОД-ВЫВОД - LSEEК
Обычное использование системных функций read и write обеспечивает последовательный доступ к файлу, однако процессы могут использовать вызов системной функции lseek для указания места в файле, где будет производиться ввод-вывод, и осуществления произвольного доступа к файлу. Синтаксис вызова системной функции: position = lseek(fd,offset,reference);
где fd - дескриптор файла, идентифицирующий файл, offset - смещение в байтах, а reference указывает, является ли значение offset смещением от начала файла, смещением от текущей позиции ввода-вывода или смещением от конца файла. Возвращаемое значение, position, является смещением в байтах до места, где будет начинаться следующая операция чтения или записи. Например, в программе, приведенной на , процесс открывает файл, считывает байт, а затем вызывает функцию lseek, чтобы заменить значение поля смещения в таблице файлов величиной, равной 1023 (с переменной reference, имеющей значение 1), и выполняет цикл. Таким образом, программа считывает каждый 1024-й байт файла. Если reference имеет значение 0, ядро осуществляет поиск от начала файла, а если 2, ядро ведет поиск от конца файла. Функция lseek ничего не должна делать, кроме операции поиска, которая позиционирует головку чтения-записи на указанный дисковый сектор. Для того, чтобы выполнить функцию lseek, ядро просто выбирает значение смещения из таблицы файлов; в последующих вызовах функций read и write смещение из таблицы файлов используется в качестве начального смещения.
Comments:
Copyright ©
UNLINК
Системная функция unlink удаляет из каталога точку входа для файла. Синтаксис вызова функции unlink: unlink(pathname);
где pathname указывает имя файла, удаляемое из иерархии каталогов. Если процесс разрывает данную связь файла с каталогом при помощи функции unlink, по указанному в вызове функции имени файл не будет доступен, пока в каталоге не создана еще одна запись с этим именем. Например, при выполнении следующего фрагмента программы: unlink("myfile"); fd = open("myfile",O_RDONLY);
функция open завершится неудачно, поскольку к моменту ее выполнения в текущем каталоге больше не будет файла с именем myfile. Если удаляемое имя является последней связью файла с каталогом, ядро в итоге освобождает все информационные блоки файла. Однако, если у файла было несколько связей, он остается все еще доступным под другими именами.
Рисунок 5.30. Взаимная блокировка процессов при выполнении функции link
На представлен алгоритм функции unlink. Сначала для поиска файла с удаляемой связью ядро использует модификацию алгоритма namei, которая вместо индекса файла возвращает индекс родительского каталога. Ядро обращается к индексу файла в памяти, используя алгоритм iget. (Особый случай, связанный с удалением имени файла ".", будет рассмотрен в упражнении). После проверки отсутствия ошибок и (для исполняемых файлов) удаления из таблицы областей записей с неактивным разделяемым текстом () ядро стирает имя файла из родительского каталога: сделать значение номера индекса равным 0 достаточно для очистки места, занимаемого именем файла в каталоге. Затем ядро производит синхронную запись каталога на диск, гарантируя тем самым, что под своим прежним именем файл уже не будет доступен, уменьшает значение счетчика связей и с помощью алгоритма iput освобождает в памяти индексы родительского каталога и файла с удаляемой связью.
При освобождении в памяти по алгоритму iput индекса файла с удаляемой связью, если значения счетчика ссылок и счетчика связей становятся равными 0, ядро забирает у файла обратно дисковые блоки, которые он занимал. На этот индекс больше не указывает ни одно из файловых имен и индекс неактивен. Для того, чтобы забрать дисковые блоки, ядро в цикле просматривает таблицу содержимого индекса, освобождая все блоки прямой адресации немедленно (в соответствии с алгоритмом free). Что касается блоков косвенной адресации, ядро освобождает все блоки, появляющиеся на различных уровнях косвенности, рекурсивно, причем в первую очередь освобождаются блоки с меньшим уровнем. Оно обнуляет номера блоков в таблице содержимого индекса и устанавливает размер файла в индексе равным 0. Затем ядро очищает в индексе поле типа файла, указывая тем самым, что индекс свободен, и освобождает индекс по алгоритму ifree. Ядро делает необходимую коррекцию на диске, так как дисковая копия индекса все еще указывает на то, что индекс используется; теперь индекс свободен для назначения другим файлам.
| алгоритм unlink входная информация: имя файла выходная информация: отсутствует { получить родительский индекс для файла с удаляемой связью (алгоритм namei); /* если в качестве файла выступает текущий каталог... */ если (последней компонентой имени файла является ".") увеличить значение счетчика ссылок в индексе; в противном случае получить индекс для файла с удаляемой связью (алго- ритм iget); если (файл является каталогом, но пользователь не явля- ется суперпользователем) { освободить индексы (алгоритм iput); возвратить (ошибку); } если (файл имеет разделяемый текст и текущее значение счетчика связей равно 1) удалить записи из таблицы областей; в родительском каталоге: обнулить номер индекса для уда- ляемой связи; освободить индекс родительского каталога (алгоритм iput); уменьшить число связей файла; освободить индекс файла (алгоритм iput); /* iput проверяет, равно ли число связей 0, если * да, * освобождает блоки файла (алгоритм free) и * освобождает индекс (алгоритм ifree); */ } |
УПРАВЛЕНИЕ АДРЕСНЫМ ПРОСТРАНСТВОМ ПРОЦЕССА
В этой главе мы пока говорили о том, каким образом осуществляется переключение контекста между процессами и как контекстные уровни запоминаются в стеке и выбираются из стека, представляя контекст пользовательского уровня как статический объект, не претерпевающий изменений при восстановлении контекста процесса. Однако, с виртуальным адресным пространством процесса работают различные системные функции и, как будет показано в следующей главе, выполняют при этом операции над областями. В этом разделе рассматривается информационная структура области; системные функции, реализующие операции над областями, будут рассмотрены в следующей главе.
Запись таблицы областей содержит информацию, необходимую для описания области. В частности, она включает в себя следующие поля:
Указатель на индекс файла, содержимое которого было первоначально загружено в область Тип области (область команд, разделяемая память, область частных данных или стека) Размер области Местоположение области в физической памяти Статус (состояние) области, представляющий собой комбинацию из следующих признаков: заблокирована запрошена идет процесс ее загрузки в память готова, загружена в память Счетчик ссылок, в котором хранится количество процессов, ссылающихся на данную область.
К операциям работы с областями относятся: блокировка области, снятие блокировки с области, выделение области, присоединение области к пространству памяти процесса, изменение размера области, загрузка области из файла в пространство памяти процесса, освобождение области, отсоединение области от пространства памяти процесса и копирование содержимого области. Например, системная функция exec, в которой содержимое исполняемого файла накладывается на адресное пространство задачи, отсоединяет старые области, освобождает их в том случае, если они не являются разделяемыми, выделяет новые области, присоединяет их и загружает содержимым файла. В остальной части раздела операции над областями описываются более детально с ориентацией на модель управления памятью, рассмотренную ранее (с таблицами страниц и группами аппаратных регистров), и с ориентацией на алгоритмы назначения страниц физической памяти и таблиц страниц ().
Управление приоритетами
Процессы могут управлять своими приоритетами с помощью системной функции nice: nice(value);
где value - значение, в процессе пересчета прибавляемое к приоритету процесса: приоритет = (ИЦП/константа) + (базовый приоритет) + (значение nice)
Системная функция nice увеличивает или уменьшает значение поля nice в таблице процессов на величину параметра функции, при этом только суперпользователю дозволено указывать значения, увеличивающие приоритет процесса. Кроме того, только суперпользователь может указывать значения, лежащие ниже определенного порога. Пользователи, вызывающие системную функцию nice для того, чтобы понизить приоритет во время выполнения интенсивных вычислительных работ, "удобны, приятны" (nice) для остальных пользователей системы, отсюда название функции. Процессы наследуют значение nice у своего родителя при выполнении системной функции fork. Функция nice действует только для выполняющихся процессов; процесс не может сбросить значение nice у другого процесса. С практической точки зрения это означает, что если администратору системы понадобилось понизить приоритеты различных процессов, требующих для своего выполнения слишком много времени, у него не будет другого способа сделать это быстро, кроме как вызвать функцию удаления (kill) для всех них сразу.

Рисунок 8.5. Планирование на основе кольцевого списка и приоритеты процессов
Управление пространством на устройстве выгрузки
Устройство выгрузки является устройством блочного типа, которое представляет собой конфигурируемый раздел диска. Тогда как обычно ядро выделяет место для файлов по одному блоку за одну операцию, на устройстве выгрузки пространство выделяется группами смежных блоков. Пространство, выделяемое для файлов, используется статическим образом; поскольку схема назначения пространства под файлы действует в течение длительного периода времени, ее гибкость понимается в смысле сокращения числа случаев фрагментации и, следовательно, объемов неиспользуемого пространства в файловой системе. Выделение пространства на устройстве выгрузки, напротив, является временным, в сильной степени зависящим от механизма диспетчеризации процессов. Процесс, размещаемый на устройстве выгрузки, в конечном итоге вернется в основную память, освобождая место на внешнем устройстве. Поскольку время является решающим фактором и с учетом того, что ввод-вывод данных за одну мультиблочную операцию происходит быстрее, чем за несколько одноблочных операций, ядро выделяет на устройстве выгрузки непрерывное пространство, не беря во внимание возможную фрагментацию.
Так как схема выделения пространства на устройстве выгрузки отличается от схемы, используемой для файловых систем, структуры данных, регистрирующие свободное пространство, должны также отличаться. Пространство, свободное в файловых системах, описывается с помощью связного списка свободных блоков, доступ к которому осуществляется через суперблок файловой системы, информация о свободном пространстве на устройстве выгрузки собирается в таблицу, именуемую "карта памяти устройства". Карты памяти, помимо устройства выгрузки, используются и другими системными ресурсами (например, драйверами некоторых устройств), они дают возможность распределять память устройства (в виде смежных блоков) по методу первого подходящего.
Каждая строка в карте памяти состоит из адреса распределяемого ресурса и количества доступных единиц ресурса; ядро интерпретирует элементы строки в соответствии с типом карты. В самом начале карта памяти состоит из одной строки, содержащей адрес и общее количество ресурсов. Если карта описывает распределение памяти на устройстве выгрузки, ядро трактует каждую единицу ресурса как группу дисковых блоков, а адрес - как смещение в блоках от начала области выгрузки. Первоначальный вид карты памяти для устройства выгрузки, состоящего из 10000 блоков с начальным адресом, равным 1, показан на . Выделяя и освобождая ресурсы, ядро корректирует карту памяти, заботясь о том, чтобы в ней постоянно содержалась точная информация о свободных ресурсах в системе.
На представлен алгоритм выделения пространства с помощью карт памяти (malloc). Ядро просматривает карту в поисках первой строки, содержащей количество единиц ресурса, достаточное для удовлетворения запроса. Если запрос покрывает все количество единиц, содержащееся в строке, ядро удаляет строку и уплотняет карту (то есть в карте становится на одну строку меньше). В противном случае ядро переустанавливает адрес и число оставшихся единиц в строке в соответствии с числом единиц, выделенных по запросу. На показано, как меняется вид карты памяти для устройства выгрузки после выделения 100, 50 и вновь 100 единиц ресурса. В конечном итоге карта памяти принимает вид, показывающий, что первые 250 единиц ресурса выделены по запросам, и что теперь остались свободными 9750 единиц, начиная с адреса 251.

Рисунок 9.1. Первоначальный вид карты памяти для устройства выгрузки
| алгоритм malloc /* алгоритм выделения пространства с ис- пользованием карты памяти */ входная информация: (1) адрес /* указывает на тип ис- пользуемой карты */ (2) требуемое число единиц ресурса выходная информация: адрес - в случае успешного завершения 0 - в противном случае { для (каждой строки карты) { если (требуемое число единиц ресурса располагается в строке карты) { если (требуемое число == числу единиц в строке) удалить строку из карты; в противном случае отрегулировать стартовый адрес в строке; вернуть (первоначальный адрес строки); } } вернуть (0); } |
Освобождая ресурсы, ядро ищет для них соответствующее место в карте по адресу. При этом возможны три случая:
Освободившиеся ресурсы полностью закрывают пробел в карте памяти. Другими словами, они имеют смежные адреса с адресами ресурсов из строк, непосредственно предшествующей и следующей за данной. В этом случае ядро объединяет вновь освободившиеся ресурсы с ресурсами из указанных строк в одну строку карты памяти. Освободившиеся ресурсы частично закрывают пробел в карте памяти. Если они имеют адрес, смежный с адресом ресурсов из строки, непосредственно предшествующей или непосредственно следующей за данной (но не с адресами из обеих строк), ядро переустанавливает значение адреса и числа ресурсов в соответствующей строке с учетом вновь освободившихся ресурсов. Число строк в карте памяти остается неизменным. Освободившиеся ресурсы частично закрывают пробел в карте памяти, но их адреса не соприкасаются с адресами каких-либо других ресурсов карты. Ядро создает новую строку и вставляет ее в соответствующее место в карте.

Рисунок 9.3. Выделение пространства на устройстве выгрузки
Возвращаясь к предыдущему примеру, отметим, что если ядро освобождает 50 единиц ресурса, начиная с адреса 101, в карте памяти появится новая строка, поскольку освободившиеся ресурсы имеют адреса, не соприкасающиеся с адресами существующих строк карты. Если же затем ядро освободит 100 единиц ресурса, начиная с адреса 1, первая строка карты будет расширена, поскольку освободившиеся ресурсы имеют адрес, смежный с адресом первой строки. Эволюция состояний карты памяти для данного случая показана на .
Предположим, что ядру был сделан запрос на выделение 200 единиц (блоков) пространства устройства выгрузки. Поскольку первая строка карты содержит информацию только о 150 единицах, ядро привлекает для удовлетворения запроса информацию из второй строки (см. ). Наконец, предположим, что ядро освобождает 350 единиц пространства, начиная с адреса 151. Несмотря на то, что эти 350 единиц были выделены ядром в разное время, не существует причины, по которой ядро не могло бы освободить их все сразу. Ядро узнает о том, что освободившиеся ресурсы полностью закрывают разрыв между первой и второй строками карты, и вместо прежних двух создает одну строку, в которую включает и освободившиеся ресурсы.

Рисунок 9.4. Освобождение пространства на устройстве выгрузки

Рисунок 9.5. Выделение пространства на устройстве выгрузки, описанного во второй строке карты памяти
В традиционной реализации системы UNIX используется одно устройство выгрузки, однако в последних редакциях версии V допускается уже наличие множества устройств выгрузки. Ядро выбирает устройство выгрузки по схеме "кольцевого списка" при условии, что на устройстве имеется достаточный объем непрерывного адресного пространства. Администраторы могут динамически создавать и удалять из системы устройства выгрузки. Если устройство выгрузки удаляется из системы, ядро не выгружает данные на него; если же данные подкачиваются с удаляемого устройства, сначала оно опорожняется и только после освобождения принадлежащего устройству пространства устройство может быть удалено из системы.
УПРАВЛЕНИЕ СИСТЕМОЙ
К управляющим процессам, грубо говоря, относятся те процессы, которые выполняют различные функции по обеспечению благополучной работы пользователей системы. К таким функциям относятся форматирование дисков, создание новых файловых систем, восстановление разрушенных файловых систем, отладка ядра и др. С концептуальной точки зрения, между управляющими и пользовательскими процессами нет разницы. Они используют один и тот же набор обращений к операционной системе, доступный для всех. Управляющие процессы отличаются от обычных пользовательских процессов только правами и привилегиями, которыми они обладают. Например, режимы разрешения доступа к файлу могут предусматривать предоставление возможности работы с файлами для управляющих процессов и отсутствие такой возможности для обычных пользователей. Внутри системы ядро выделяет особого пользователя, именуемого суперпользователем, и наделяет его особыми привилегиями, о чем мы еще поговорим ниже. Пользователь может стать суперпользователем, если соответствующим образом зарегистрируется в системе или запустит специальную программу. Привилегии суперпользователя будут рассмотрены в следующих главах. Если сказать коротко, ядро системы не выделяет управляющие процессы в отдельный класс.
Рисунок 2.9. Многократная приостановка выполнения процессов, вызванная блокировкой
Comments:
Copyright ©
в программе debug будет отсутствовать
1. Что произойдет в том случае, если в программе debug будет отсутствовать вызов функции wait ()? (Намек: возможны два исхода.)
2. С помощью функции ptrace отладчик считывает данные из пространства трассируемого процесса по одному слову за одну операцию. Какие изменения следует произвести в ядре операционной системы для того, чтобы увеличить количество считываемых слов? Какие изменения при этом необходимо сделать в самой функции ptrace?
3. Расширьте область действия функции ptrace так, чтобы в качестве параметра pid можно было указывать идентификатор процесса, не являющегося потомком текущего процесса. Подумайте над вопросами, связанными с защитой информации: При каких обстоятельствах процессу может быть позволено читать данные из адресного пространства другого, произвольного процесса? При каких обстоятельствах разрешается вести запись в адресное пространство другого процесса?
4. Организуйте из функций работы с сообщениями библиотеку пользовательского уровня с использованием обычных файлов, поименованных каналов и элементов блокировки. Создавая очередь сообщений, откройте управляющий файл для записи в него информации о состоянии очереди; защитите файл с помощью средств захвата файлов и других удобных для вас механизмов. Посылая сообщение данного типа, создавайте поименованный канал для всех сообщений этого типа, если такого канала еще не было, и передавайте сообщение через него (с подсчетом переданных байт). Управляющий файл должен соотносить тип сообщения с именем поименованного канала. При чтении сообщений управляющий файл направляет процесс к соответствующему поименованному каналу. Сравните эту схему с механизмом, описанным в настоящей главе, по эффективности, сложности реализации и функциональным возможностям.
5. Какие действия пытается выполнить программа, представленная на ?
*6. Напишите программу, которая подключала бы область разделяемой памяти слишком близко к вершине стека задачи и позволяла бы стеку при увеличении пересекать границу разделяемой области. В какой момент произойдет фатальная ошибка памяти?
1. Решите проблему функционирования многопроцессорных систем таким образом, чтобы все процессоры в системе могли функционировать в режиме ядра, но не более одного одновременно. Такое решение будет отличаться от первой из предложенных в тексте схем, где только один процессор (главный) предназначен для реализации функций ядра. Как добиться того, чтобы в режиме ядра в каждый момент времени находился только один процессор? Какую стратегию обработки прерываний при этом можно считать приемлемой?
2. Используя системные функции работы с разделяемой областью памяти, протестируйте программу, реализующую семафорную блокировку (). Последовательности операций P-V над семафором могут независимо один от другого выполнять несколько процессов. Каким образом в программе следует реализовать индикацию и обработку ошибок?
3. Разработайте алгоритм выполнения операции CP (условный тип операции P), используя текст алгоритма операции P.
4. Объясните, зачем в алгоритмах операций P и V (Рисунки и ) нужна блокировка прерываний. В какие моменты ее следует осуществлять?
5. Почему при выполнении "циклической блокировки" вместо строки: while (! CP(семафор));
ядро не может использовать операцию P безусловного типа? (В качестве наводящего вопроса: что произойдет в том случае, если процесс запустит операцию P и приостановится?)
6. Обратимся к алгоритму getblk, приведенному в . Опишите реализацию алгоритма в многопроцессорной системе для случая, когда блок отсутствует в буферном кеше.
*7. Предположим, что при выполнении алгоритма выделения буфера возникла чрезвычайно сильная конкуренция за семафор, принадлежащий списку свободных буферов. Разработайте схему ослабления конкуренции за счет разбиения списка свободных буферов на два подсписка.
*8. Предположим, что у терминального драйвера имеется семафор, значение которого при инициализации сбрасывается в 0 и по которому процессы приостанавливают свою работу в случае переполнения буфера вывода на терминал. Когда терминал готов к приему следующей порции данных, он выводит из состояния ожидания все процессы, приостановленные по семафору. Разработайте схему возобновления процессов, использующую операции типа P и V. В случае необходимости введите дополнительные флаги и семафоры. Как должна вести себя схема в том случае, если процессы выводятся из состояния ожидания по прерыванию, но при этом текущий процессор не имеет возможности блокировать прерывания на других процессорах?
*9. Если точки входа в драйвер защищаются семафорами, должно соблюдаться условие освобождения семафора в случае перехода процесса в состояние приостанова. Как это реализуется на практике? Каким образом должна производиться обработка прерываний, поступающих в то время, пока семафор драйвера заблокирован?
10. Обратимся к системным функциям установки и контроля системного времени (). Разные процессоры могут иметь различную тактовую частоту. Как в этом случае указанные функции должны работать?
Comments:
Copyright ©
*1. Опишите реализацию системной функции exit в системе с периферийными процессорами. В чем разница между этим случаем и тем, когда процесс завершает свою работу по получении неперехваченного сигнала? Каким образом ядру следует сохранить дамп содержимого памяти?
2. Процессы не могут игнорировать сигналы типа SIGKILL; объясните, что происходит в периферийной системе, когда процесс получает такой сигнал.
*3. Опишите реализацию системной функции exec в системе с периферийными процессорами.
*4. Каким образом центральному процессору следует производить распределение процессов между периферийными процессорами с тем, чтобы сбалансировать общую нагрузку?
*5. Что произойдет в том случае, если у периферийного процессора не окажется достаточно памяти для размещения всех выгруженных на него процессов? Каким образом должны производиться выгрузка и подкачка процессов в сети?
6. Рассмотрим систему, в которой запросы к удаленному файловому серверу посылаются в случае обнаружения в имени файла специального префикса. Пусть процесс вызывает функцию execl("/../sftig/bin/sh","sh",0); Исполняемый модуль находится на удаленной машине, но должен выполняться в локальной системе. Объясните, каким образом удаленный модуль переносится в локальную систему.
7. Если администратору нужно добавить в существующую систему со связью типа Newcastle новые машины, то как об этом лучше всего проинформировать модули Си-библиотеки?
*8. Во время выполнения функции exec ядро затирает адресное пространство процесса, включая и библиотечные таблицы, используемые связью типа Newcastle для слежения за ссылками на удаленные файлы. После выполнения функции процесс должен сохранить возможность обращения к этим файлам по их старым дескрипторам. Опишите реализацию этого момента.
*9. Как показано в , вызов системной функции exit в системах со связью типа Newcastle приводит к посылке сообщения процессу-спутнику, заставляющего последний завершить свою работу. Это делается на уровне библиотечных подпрограмм. Что происходит, когда локальный процесс получает сигнал, побуждающий его завершить свою работу в режиме ядра?
1. Рассмотрим следующий набор команд: grep main a.c b.c c.c > grepout & wc -1 < grepout & rm grepout &
Амперсанд (символ "&") в конце каждой командной строки говорит командному процессору shell о том, что команду следует выполнить на фоне, при этом shell может выполнять все командные строки параллельно. Почему это не равноценно следующей командной строке? grep main a.c b.c c.c | wc -1
2. Рассмотрим пример программы, приведенный на Рисунке . Предположим, что в тот момент, когда при ее выполнении встретился комментарий, произошло переключение контекста и другой процесс убрал содержимое буфера из списка указателей с помощью следующих команд: remove(gp) struct queue *gp; { gp - > forp - > backp = gp - > backp; gp - > backp - > forp = gp - > forp; gp - > forp = gp - > backp = NULL; }
Рассмотрим три случая:
Процесс убирает из списка с указателями структуру bp1. Процесс убирает из списка с указателями структуру, следующую после структуры bp1. Процесс убирает из списка структуру, которая первоначально следовала за bp1 до того, как структура bp была наполовину включена в указанный список.
В каком состоянии будет список после того, как первый процесс завершит выполнение части программы, расположенной после комментариев?
3. Что произошло бы в том случае, если ядро попыталось бы возобновить выполнение всех процессов, приостановленных по событию, но в системе не было бы к этому моменту ни одного такого процесса?
Comments:
Copyright ©
1. Рассмотрим функцию хеширования применительно к Рисунку . Наилучшей функцией хеширования является та, которая единым образом распределяет блоки между хеш-очередями. Что Вы могли бы предложить в качестве оптимальной функции хеширования? Должна ли эта функция в своих расчетах использовать логический номер устройства?
2. В алгоритме getblk, если ядро удаляет буфер из списка свободных буферов, оно должно повысить приоритет прерывания работы процессора так, чтобы блокировать прерывания до проверки списка. Почему?
*3. В алгоритме getblk ядро должно повысить приоритет прерывания работы процессора так, чтобы блокировать прерывания до проверки занятости блока. (Это не показано в тексте.) Почему?
4. В алгоритме brelse ядро помещает буфер в "голову" списка свободных буферов, если содержимое буфера неверно. Если содержимое буфера неверно, должен ли буфер появиться в хеш-очереди?
5. Предположим, что ядро выполняет отложенную запись блока. Что произойдет, когда другой процесс выберет этот блок из его хеш-очереди? Из списка свободных буферов?
*6. Если несколько процессов оспаривают буфер, ядро гарантирует, что ни один из них не приостановится навсегда, но не гарантирует, что процесс не "зависнет" и дождется получения буфера. Переделайте алгоритм getblk так, чтобы процессу было в конечном итоге гарантировано получение буфера.
7. Переделайте алгоритмы getblk и brelse так, чтобы ядро следовало не схеме замещения буферов, к которым наиболее долго не было обращений, а схеме "первым пришел - первым вышел". Повторите то же самое со схемой замещения редко используемых буферов.
8. Опишите ситуацию в алгоритме bread, когда информация в буфере уже верна.
*9. Опишите различные ситуации, встречающиеся в алгоритме breada. Что произойдет в случае следующего выполнения алгоритма bread или breada, когда текущий блок прочитан с продвижением? В алгоритме breada, если первый или второй блок отсутствует в кеше, в дальнейшем при проверке правильности содержимого буфера предполагается, что блок мог быть в буферном пуле. Как это может быть?
1. В версии V системы UNIX разрешается использовать не более 14 символов на каждую компоненту имени пути поиска. Алгоритм namei отсекает лишние символы в компоненте. Что нужно сделать в файловой системе и в соответствующих алгоритмах, чтобы стали допустимыми имена компонент произвольной длины?
2. Предположим, что пользователь имеет закрытую версию системы UNIX, причем он внес в нее такие изменения, что имя компоненты теперь может состоять из 30 символов; закрытая версия системы обеспечивает тот же способ хранения записей каталогов, как и стандартная операционная система, за исключением того, что записи каталогов имеют длину 32 байта вместо 16. Если пользователь смонтирует закрытую файловую систему в стандартной операционной среде, что произойдет во время работы алгоритма namei, когда процесс обратится к файлу?
*3. Рассмотрим работу алгоритма namei по преобразованию имени пути поиска в идентификатор индекса. В течение всего просмотра ядро проверяет соответствие текущего рабочего индекса индексу каталога. Может ли другой процесс удалить (unlink) каталог? Каким образом ядро предупреждает такие действия? В следующей главе мы вернемся к этой проблеме.
*4. Разработайте структуру каталога, повышающую эффективность поиска имен файлов без использования линейного просмотра. Рассмотрите два способа: хеширование и n-арные деревья.
*5. Разработайте алгоритм сокращения количества просмотров каталога в поисках имени файла, используя запоминание часто употребляемых имен.
*6. В идеальном случае в файловой системе не должно быть свободных индексов с номерами, меньшими, чем номер "запомненного" индекса, используемый алгоритмом ialloc. Как случается, что это утверждение бывает ложным?
7. Суперблок является дисковым блоком и содержит кроме списка свободных блоков и другую информацию, как показано в данной главе. Поэтому список свободных блоков в суперблоке не может содержать больше номеров свободных блоков, чем может поместиться в одном дисковом блоке в связанном списке свободных дисковых блоков. Какое число номеров свободных блоков было бы оптимальным для хранения в одном блоке из связанного списка?
Comments:
Copyright ©
1. Рассмотрим программу, приведенную на . Какое значение возвращает каждая операция read и что при этом содержится в буфере? Опишите, что происходит в ядре во время выполнения каждого вызова read.
2. Вновь вернемся к программе на и предположим, что оператор lseek(fd,9000L,0); стоит перед первым обращением к функции read. Что ищет процесс и что при этом происходит в ядре?
3. Процесс может открыть файл для работы в режиме добавления записей в конец файла, при этом имеется в виду, что каждая операция записи располагает данные по адресу смещения, указывающего текущий конец файла. Таким образом, два процесса могут открыть файл для работы в режиме добавления записей в конец файла и вводить данные, не опасаясь затереть записи друг другу. Что произойдет, если процесс откроет файл в режиме добавления в конец, а записывающую головку установит на начало файла?
4. Библиотека стандартных подпрограмм ввода-вывода повышает эффективность выполнения пользователем операций чтения и записи благодаря буферизации данных в библиотеке и сохранению большого количества модулей обращения к операционной системе, необходимых пользователю. Как бы вы реализовали библиотечные функции fread и fwrite? Что должны делать библиотечные функции fopen и fclose?
|
#include <fcntl.h> main() { int fd; char buf[1024]; fd = creat("junk",0666); lseek(fd,2000L,2); /* ищется байт с номером 2000 */ write(fd,"hello",5); close(fd); fd = open("junk",O_RDONLY); read(fd,buf,1024); /* читает нули */ read(fd,buf,1024); /* считывает нечто, отличное от 0 */ read(fd,buf,1024); } |
Рисунок 5.35. Считывание нулей и конца файла
5. Если процесс читает данные из файла последовательно, ядро запоминает значение блока, прочитанного с продвижением, в индексе, хранящемся в памяти. Что произойдет, если несколько процессов будут одновременно вести последовательное считывание данных из одного и того же файла?
|
#include <fcntl.h> main() { int fd; char buf[256]; fd = open("/etc/passwd",O_RDONLY); if (read(fd,buf,1024) < 0) printf("чтение завершается неудачно\n"); } |
1. Составьте алгоритм преобразования виртуальных адресов в физические, на входе которого задаются виртуальный адрес и адрес точки входа в частную таблицу областей.
2. В машинах AT&T 3B2 и NSC серии 32000 используется двухуровневая схема трансляции виртуальных адресов в физические (с сегментацией). То есть в системе поддерживается указатель на таблицу страниц, каждая запись которой может адресовать фиксированную часть адресного пространства процесса по смещению в таблице. Сравните алгоритм трансляции виртуальных адресов на этих машинах с алгоритмом, изложенным в тексте при обсуждении модели управления памятью. Подумайте над проблемами производительности и потребности в памяти для размещения вспомогательных таблиц.
3. В архитектуре системы VAX-11 поддерживаются два набора регистров защиты памяти, используемых машиной в процессе трансляции пользовательских адресов. Механизм трансляции используется тот же, что и в предыдущем пункте, за одним исключением: указателей на таблицу страниц здесь два. Если процесс располагает тремя областями - команд, данных и стека - то каким образом, используя два набора регистров, следует производить отображение областей на таблицы страниц? Увеличение стека в архитектуре системы VAX-11 идет в направлении младших виртуальных адресов. Какой тогда вид имела бы область стека? В будет рассмотрена область разделяемой памяти: как она может быть реализована в архитектуре системы VAX-11?
4. Составьте алгоритм выделения и освобождения страниц памяти и таблиц страниц. Какие структуры данных следует использовать, чтобы достичь наивысшей производительности или наибольшей простоты реализации алгоритма?
5. Устройство управления памятью MC68451 для семейства микропроцессоров Motorola 68000 допускает выделение сегментов памяти размером от 256 байт до 16 мегабайт. Каждое (физическое) устройство управления памятью поддерживает 32 дескриптора сегментов. Опишите эффективный метод выделения памяти для этого случая. Каким образом осуществлялась бы реализация областей?
1. Запустите с терминала программу, приведенную на . Переадресуйте стандартный вывод данных в файл и сравните результаты между собой.
| main() { printf("hello\n"); if (fork() == 0) printf("world\n"); } |
Рисунок 7.33. Пример модуля, содержащего вызов функции fork и обращение к стандартному выводу
2. Разберитесь в механизме работы программы, приведенной на , и сравните ее результаты с результатами программы на .
| #include <fcntl.h> int fdrd,fdwt; char c; main(argc,argv) int argc; char *argv[]; { if (argc != 3) exit(1); fork(); if ((fdrd = open(argv[1],O_RDONLY)) == -1) exit(1); if (((fdwt = creat(argv[2],0666)) == -1) && ((fdwt = open(argv[2],O_WRONLY)) == -1)) exit(1); rdwrt(); } rdwrt() { for (;;) { if (read(fdrd,&c,1) != 1) return; write(fdwt,&c,1); } } |
Рисунок 7.34. Пример программы, в которой процесс-родитель и процесс-потомок не разделяют доступ к файлу
3. Еще раз обратимся к программе, приведенной на и показывающей, как два процесса обмениваются сообщениями, используя спаренные каналы. Что произойдет, если они попытаются вести обмен сообщениями, используя один канал?
4. Возможна ли потеря информации в случае, когда процесс получает несколько сигналов прежде чем ему предоставляется возможность отреагировать на них надлежащим образом? (Рассмотрите случай, когда процесс подсчитывает количество полученных сигналов о прерывании.) Есть ли необходимость в решении этой проблемы?
5. Опишите механизм работы системной функции kill.
6. Процесс в программе на принимает сигналы типа "гибель потомка" и устанавливает функцию обработки сигналов в исходное состояние. Что происходит при выполнении программы?
|
#include <signal.h> main() { extern catcher(); signal(SIGCLD,catcher); if (fork() == 0) exit(); /* пауза до момента получения сигнала */ pause(); } catcher() { printf("процесс-родитель получил сигнал\n"); signal(SIGCLD,catcher); } |
Рисунок 7.35. Программа, в которой процесс принимает сигналы типа "гибель потомка"
При переводе процессов в состояние приостанова ядро назначает процессу, ожидающему снятия блокировки с индекса, более высокий приоритет по сравнению с процессом, ожидающим освобождения буфера. Точно так же, процессы, ожидающие ввода с терминала, получают более высокий приоритет по сравнению с процессами, ожидающими возможности производить вывод на терминал. Объясните причины такого поведения ядра. * В алгоритме обработки прерываний по таймеру предусмотрен пересчет приоритетов и перезапуск процессов на выполнение с интервалом в 1 секунду. Придумайте алгоритм, в котором интервал перезапуска динамически меняется в зависимости от степени загрузки системы. Перевесит ли выигрыш усилия по усложнению алгоритма? В шестой редакции системы UNIX для расчета продолжительности ИЦП текущим процессом используется следующая формула: decay(ИЦП) = max (пороговый приоритет, ИЦП-10);
а в седьмой редакции: decay(ИЦП) = .8 * ИЦП;
Приоритет процесса в обеих редакциях вычисляется по формуле: приоритет = ИЦП/16 + (базовый уровень приоритета);
Повторите пример на , используя приведенные формулы.
Проделайте еще раз пример на с семью процессами вместо трех, а затем измените частоту прерываний по таймеру с 60 на 100 прерываний в секунду. Прокомментируйте результат. Разработайте схему, в которой система накладывает ограничение на продолжительность выполнения процесса, при превышении которого процесс завершается. Каким образом пользователь должен отличать такой процесс от процессов, для которых не должны существовать подобные ограничения? Каким образом должна работать схема, если единственным условием является ее запуск из shell'а? Когда процесс выполняет системную функцию wait и обнаруживает прекратившего существование потомка, ядро приплюсовывает к его ИЦП значение поля ИЦП потомка. Чем объясняется такое "наказание" процесса-родителя? Команда nice запускает последующую команду с передачей ей указанного значения, например: nice 6 nroff -mm big_memo > output
Напишите на языке Си программу, реализующую команду nice. Проследите на примере , каким образом будет осуществляться диспетчеризация процессов в том случае, если значение, передаваемое функцией nice для процесса A, равно 5 или -5. Проведите эксперимент с системной функцией renice x y, где x - код идентификации процесса (активного), а y - новое значение nice для указанного процесса. Вернемся к примеру, приведенному на . Предположим, что группе, в которую входит процесс A, выделяется 33% процессорного времени, а группе, в которую входит процесс B, - 66% процессорного времени. В какой последовательности будут исполняться процессы? Обобщите алгоритм вычисления приоритетов таким образом, чтобы значение группового ИЦП усреднялось. Выполните команду date. Команда без аргументов выводит текущую дату:
Набросайте схему реализации алгоритма mfree, который освобождает пространство памяти и возвращает его таблице свободного пространства.
В утверждается, что система блокирует перемещаемый процесс, чтобы другие процессы не могли его трогать с места до момента окончания операции. Что произошло бы, если бы система не делала этого?
Предположим, что в адресном пространстве процесса располагаются таблицы используемых процессом сегментов и страниц. Каким образом ядро может выгрузить это пространство из памяти?
Если стек ядра находится внутри адресного пространства процесса, почему процесс не может выгружать себя сам? Какой на Ваш взгляд должна быть системная программа выгрузки процессов, как она должна запускаться?
*Предположим, что ядро пытается выгрузить процесс, чтобы освободить место в памяти для других процессов, загружаемых с устройства выгрузки. Если ни на одном из устройств выгрузки для данного процесса нет места, процесс подкачки приостанавливает свою работу до тех пор, пока место не появится. Возможна ли ситуация, при которой все процессы, находящиеся в памяти, приостановлены, а все готовые к выполнению процессы находятся на устройстве выгрузки? Что нужно предпринять ядру для того, чтобы исправить это положение?
Рассмотрите еще раз пример, приведенный на , при условии, что в памяти есть место только для 1 процесса.
Обратимся к примеру, приведенному на . Составьте подобный пример, в котором процессу постоянно требуется для работы центральный процессор. Существует ли какой-нибудь способ снятия подобной напряженности?
|
main() { f(); g(); } f() { vfork(); } g() { int blast[100],i; for (i = 0; i < 100; i++) blast[i] = i; } |
Рисунок 9.29
Что произойдет в результате выполнения программы, приведенной на , в системе BSD 4.2? Каким будет стек процесса-родителя?
Почему после выполнения функции fork процесса-потомка предпочтительнее запускать впереди процесса-родителя, если на разделяемых страницах биты копирования при записи установлены? Каким образом ядро может заставить потомка запуститься первым?
* Предположим, что в системе имеются два файла устройств с одними и теми же старшим и младшим номерами, при том, что оба устройства - символьного типа. Если два процесса желают одновременно открыть физическое устройство, не будет никакой разницы, открывают ли они один и тот же файл устройства или же разные файлы. Что произойдет, когда они станут закрывать устройство?
* Вспомним из , что системной функции mknod требуется разрешение суперпользователя на создание нового специального файла устройства. Если доступ к устройству управляется правами доступа к файлу, почему функции mknod нужно разрешение суперпользователя?
Напишите программу, которая проверяет, что файловые системы на диске не перекрываются. Этой программе потребовались бы два аргумента: файл устройства, представляющий дисковый том, и дескриптор файла, откуда берутся номера секторов и их размер для диска данного типа. Для проверки отсутствия перекрытий этой программе понадобилась бы информация из суперблоков. Будет ли такая программа всегда правильной?
Программа mkfs инициализирует файловую систему на диске путем создания суперблока, выделения места для списка индексов, включения всех информационных блоков в связанный список и создания корневого каталога. Как бы вы написали программу mkfs? Как изменится эта программа при наличии таблицы содержимого тома? Каким образом следует инициализировать таблицу содержимого тома?
Программы mkfs и fsck () являются программами пользовательского уровня, а не частью ядра. Прокомментируйте это.
Предположим, что программисту нужно разработать базу данных, работающую в среде ОС UNIX. Программы базы данных выполняются на пользовательском уровне, а не в составе ядра. Как система управления базой данных будет взаимодействовать с диском? Подумайте над следующими вопросами:
Использование стандартного интерфейса файловой системы вместо непосредственной работы с неструктурированными данными на диске, Потребность в быстродействии, Необходимость знать, когда фактически данные располагаются на диске, Размер базы данных: должна ли она помещаться в одной файловой системе, занимать собой весь дисковый том или же располагаться на нескольких дисковых томах?
Уровни прерывания процессора
Ядро иногда обязано предупреждать возникновение прерываний во время критических действий, могущих в случае прерывания запортить информацию. Например, во время обработки списка с указателями возникновение прерывания от диска для ядра нежелательно, т.к. при обработке прерывания можно запортить указатели, что можно увидеть на примере в следующей главе. Обычно имеется ряд привилегированных команд, устанавливающих уровень прерывания процессора в слове состояния процессора. Установка уровня прерывания на определенное значение отсекает прерывания этого и более низких уровней, разрешая обработку только прерываний с более высоким приоритетом. На Рисунке показана последовательность уровней прерывания. Если ядро игнорирует прерывания от диска, в этом случае игнорируются и все остальные прерывания, кроме прерываний от часов и машинных сбоев.
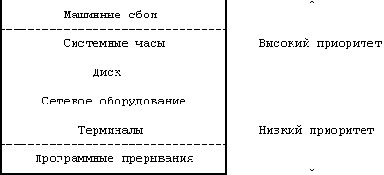
Рисунок 1.6. Стандартные уровни прерываний
УЗКИЕ МЕСТА В ФУНКЦИОНИРОВАНИИ МНОГОПРОЦЕССОРНЫХ СИСТЕМ
В данной главе нами были рассмотрены два метода реализации многопроцессорных версий системы UNIX: конфигурация, состоящая из главного и подчиненного процессоров, в которой только один процессор (главный) функционирует в режиме ядра, и метод, основанный на использовании семафоров и допускающий одновременное исполнение в режиме ядра всех имеющихся в системе процессов. Оба метода инвариантны к количеству процессоров, однако говорить о том, что с ростом числа процессоров общая производительность системы увеличивается с линейной скоростью, нельзя. Потери производительности возникают, во-первых, как следствие конкуренции за ресурсы памяти, которая выражается в увеличении продолжительности обращения к памяти. Во-вторых, в схеме, основанной на использовании семафоров, к этой конкуренции добавляется соперничество за семафоры; процессы зачастую обнаруживают семафоры захваченными, больше процессов находится в очереди, долгое время ожидая получения доступа к семафорам. Первая схема, основанная на использовании главного и подчиненного процессоров, тоже не лишена недостатков: по мере увеличения числа процессоров главный процессор становится узким местом в системе, поскольку только он один может функционировать в режиме ядра. Несмотря на то, что более внимательное техническое проектирование позволяет сократить конкуренцию до разумного минимума и в некоторых случаях приблизить скорость повышения производительности системы при увеличении числа процессоров к линейной (см., например, [Beck 85]), все построенные с использованием современной технологии многопроцессорные системы имеют предел, за которым расширение состава процессоров не сопровождается увеличением производительности системы.
Comments:
Copyright ©
Вход в систему
Как показано в , процесс начальной загрузки, имеющий номер 1, выполняет бесконечный цикл чтения из файла "/etc/inittab" инструкций о том, что нужно делать, если загружаемая система определена как "однопользовательская" или "многопользовательская". В многопользовательском режиме самой первой обязанностью процесса начальной загрузки является предоставление пользователям возможности регистрироваться в системе с терминалов (). Он порождает процессы, именуемые getty-процессами (от "get tty" - получить терминал), и следит за тем, какой из процессов открывает какой терминал; каждый getty-процесс устанавливает свою группу процессов, используя вызов системной функции setpgrp, открывает отдельную терминальную линию и обычно приостанавливается во время выполнения функции open до тех пор, пока машина не получит аппаратную связь с терминалом. Когда функция open возвращает управление, getty-процесс исполняет программу login (регистрации в системе), которая требует от пользователей, чтобы они идентифицировали себя указанием регистрационного имени и пароля. Если пользователь зарегистрировался успешно, программа login наконец запускает командный процессор shell и пользователь приступает к работе. Этот вызов shell'а именуется "login shell" (регистрационный shell, регистрационный интерпретатор команд). Процесс, связанный с shell'ом, имеет тот же идентификатор, что и начальный getty-процесс, поэтому login shell является процессом, возглавляющим группу процессов. Если пользователь не смог успешно зарегистрироваться, программа регистрации завершается через определенный промежуток времени, закрывая открытую терминальную линию, а процесс начальной загрузки порождает для этой линии следующий getty-процесс. Процесс начальной загрузки делает паузу до получения сигнала об окончании порожденного ранее процесса. После возобновления работы он выясняет, был ли прекративший существование процесс регистрационным shell'ом и если это так, порождает еще один getty-процесс, открывающий терминал, вместо прекратившего существование.
| алгоритм login /* процедура регистрации */ { исполняется getty-процесс: установить группу процессов (вызов функции setpgrp); открыть терминальную линию; /* приостанов до завершения открытия */ если (открытие завершилось успешно) { исполнить программу регистрации: запросить имя пользователя; отключить эхо-сопровождение, запросить пароль; если (регистрация прошла успешно) /* найден соответствующий пароль в /etc/passwd */ { перевести терминал в канонический режим (ioctl); исполнить shell; } в противном случае считать количество попыток регистрации, пытаться зарегистрироваться снова до достижения опреде- ленной точки; } } |
Рисунок 10.19. Алгоритм регистрации
(****) В этом разделе рассматривается использование терминалов ввода-вывода, которые передают все символы, введенные пользователем, без обработки.
(*****) В данной главе используется общий термин "возврат каретки" для обозначения символов возврата каретки и перевода строки.
Comments:
Copyright ©
Внутренние системные тайм-ауты
Некоторым из процедур ядра, в частности драйверам устройств и сетевым протоколам, требуется вызов функций ядра в режиме реального времени. Например, процесс может перевести терминал в режим ввода без обработки символов, при котором ядро выполняет запросы пользователя на чтение с терминала через фиксированные промежутки времени, не дожидаясь, когда пользователь нажмет клавишу "возврата каретки" (см. ). Ядро хранит всю необходимую информацию в таблице ответных сигналов (), в том числе имя функции, запускаемой по истечении интервала времени, параметр, передаваемый этой функции, а также продолжительность интервала (в таймерных тиках) до момента запуска функции.
Пользователь не имеет возможности напрямую контролировать записи в таблице ответных сигналов; для работы с ними существуют различные системные алгоритмы. Ядро сортирует записи в этой таблице в соответствии с величиной интервала до момента запуска функций. В связи с этим для каждой записи таблицы запоминается не общая продолжительность интервала, а только промежуток времени между моментами запуска данной и предыдущей функций. Общая продолжительность интервала до момента запуска функции складывается из промежутков времени между моментами запуска всех функций, начиная с первой и вплоть до текущей.

Рисунок 8.10. Включение новой записи в таблицу ответных сигналов
На приведен пример добавления новой записи в таблицу ответных сигналов. (К отрицательному значению поля "время до запуска" для функции a мы вернемся несколько позже). Создавая новую запись, ядро отводит для нее надлежащее место и соответствующим образом переустанавливает значение поля "время до запуска" в записи, следующей за добавляемой. Судя по рисунку, ядро собирается запустить функцию f через 5 таймерных тиков: оно отводит место для нее в таблице сразу после функции b и заносит в поле "время до запуска" значение, равное 2 (тогда сумма значений этих полей для функций b и f составит 5), и меняет "время до запуска" функции c на 8 (при этом функция c все равно запускается через 13 таймерных тиков). В одних версиях ядро пользуется связным списком указателей на записи таблицы ответных сигналов, в других меняет положение записей при корректировке таблицы. Последний способ требует значительно меньших издержек при условии, что ядро не будет слишком часто обращаться к таблице.
При каждом поступлении прерывания по таймеру программа обработки прерывания проверяет наличие записей в таблице ответных сигналов и в случае их обнаружения уменьшает значение поля "время до запуска" в первой записи. Способ хранения продолжительности интервалов до момента запуска каждой функции, выбранный ядром, позволяет, уменьшив значение поля "время до запуска" в одной только первой записи, соответственно уменьшить продолжительность интервала до момента запуска функций, описанных во всех записях таблицы. Если в указанном поле первой записи хранится отрицательное или нулевое значение, соответствующую функцию следует запустить. Программа обработки прерываний по таймеру не запускает функцию немедленно, таким образом она не блокирует возникновение последующих прерываний данного типа. Текущий приоритет работы процессора вроде бы не позволяет таким прерываниям вмешиваться в выполнение процесса, однако ядро не имеет представления о том, сколько времени потребуется на исполнение функции. Казалось бы, если функция выполняется дольше одного таймерного тика, все последующие прерывания должны быть заблокированы. Вместо этого, программа обработки прерываний в типичной ситуации оформляет вызов функции как "программное прерывание", порождаемое выполнением отдельной машинной команды. Поскольку среди всех прерываний программные прерывания имеют самый низкий приоритет, они блокируются, пока ядро не закончит обработку всех остальных прерываний. С момента завершения подготовки к запуску функции и до момента возникновения вызываемого запуском функции программного прерывания может произойти множество прерываний, в том числе и программных, в таком случае в поле "время до запуска", принадлежащее первой записи таблицы, будет занесено отрицательное значение. Когда же наконец программное прерывание происходит, программа обработки прерываний убирает из таблицы все записи с истекшими значениями полей "время до запуска" и вызывает соответствующую функцию.
Поскольку в указанном поле в начальных записях таблицы может храниться отрицательное или нулевое значение, программа обработки прерываний должна найти в таблице первую запись с положительным значением поля и уменьшить его. Пусть, например, функции a соответствует "время до запуска", равное -2 (), то есть перед тем, как функция a была выбрана на выполнение, система получила 2 прерывания по таймеру. При условии, что функция b 2 тика назад уже была в таблице, ядро пропускает запись, соответствующую функции a, и уменьшает значение поля "время до запуска" для функции b.
ВВЕДЕНИЕ В ОСНОВНЫЕ ПОНЯТИЯ СИСТЕМЫ
В это разделе дается обзор некоторых основных информационных структур, используемых ядром системы, и более подробно описывается функционирование модулей ядра, показанных на Рисунке .
ВЫДЕЛЕНИЕ ДИСКОВЫХ БЛОКОВ
Когда процесс записывает данные в файл, ядро должно выделять из файловой системы дисковые блоки под информационные блоки прямой адресации и иногда под блоки косвенной адресации. Суперблок файловой системы содержит массив, используемый для хранения номеров свободных дисковых блоков в файловой системе. Сервисная программа mkfs ("make file system" - создать файловую систему) организует информационные блоки в файловой системе в виде списка с указателями так, что каждый элемент списка указывает на дисковый блок, в котором хранится массив номеров свободных дисковых блоков, а один из элементов массива хранит номер следующего блока данного списка.
Когда ядру нужно выделить блок из файловой системы (алгоритм alloc, ), оно выделяет следующий из блоков, имеющихся в списке в суперблоке. Выделенный однажды, блок не может быть переназначен до тех пор, пока не освободится. Если выделенный блок является последним блоком, имеющимся в кеше суперблока, ядро трактует его как указатель на блок, в котором хранится список свободных блоков. Ядро читает блок, заполняет массив в суперблоке новым списком номеров блоков и после этого продолжает работу с первоначальным номером блока. Оно выделяет буфер для блока и очищает содержимое буфера (обнуляет его). Дисковый блок теперь считается назначенным и у ядра есть буфер для работы с ним. Если в файловой системе нет свободных блоков, вызывающий процесс получает сообщение об ошибке.
Если процесс записывает в файл большой объем информации, он неоднократно запрашивает у системы блоки для хранения информации, но ядро назначает каждый раз только по одному блоку. Программа mkfs пытается организовать первоначальный связанный список номеров свободных блоков так, чтобы номера блоков, передаваемых файлу, были рядом друг с другом. Благодаря этому повышается производительность, поскольку сокращается время поиска на диске и время ожидания при последовательном чтении файла процессом. На Рисунке 4.18 номера блоков даны в настоящем формате, определяемом скоростью вращения диска. К сожалению, очередность номеров блоков в списке свободных блоков перепутана в связи с частыми обращениями к списку со стороны процессов, ведущих запись в файлы и удаляющих их, в результате чего номера блоков поступают в список и покидают его в случайном порядке. Ядро не предпринимает попыток сортировать номера блоков в списке.
Рисунок 4.18. Список номеров свободных дисковых блоков с указателями
Алгоритм освобождения блока free - обратный алгоритму выделения блока. Если список в суперблоке не полон, номер вновь освобожденного блока включается в этот список. Если, однако, список полон, вновь освобожденный блок становится связным блоком; ядро переписывает в него список из суперблока и копирует блок на диск. Затем номер вновь освобожденного блока включается в список свободных блоков в суперблоке. Этот номер становится единственным номером в списке.
На Рисунке 4.20 показана последовательность операций alloc и free для случая, когда в исходный момент список свободных блоков содержал один элемент. Ядро освобождает блок 949 и включает номер блока в список. Затем оно выделяет этот блок и удаляет его номер из списка. Наконец, оно выделяет блок 109 и удаляет его номер из списка. Поскольку список свободных блоков в суперблоке теперь пуст, ядро снова наполняет список, копируя в него содержимое блока 109, являющегося следующей связью в списке с указателями. На Рисунке 4.20(г) показан заполненный список в суперблоке и следующий связной блок с номером 211.
| алгоритм alloc /* выделение блока файловой системы */ входная информация: номер файловой системы выходная информация: буфер для нового блока { выполнить (пока суперблок заблокирован) приостановиться (до того момента, когда с суперблока будет снята блокировка); удалить блок из списка свободных блоков в суперблоке; если (из списка удален последний блок) { заблокировать суперблок; прочитать блок, только что взятый из списка свобод- ных (алгоритм bread); скопировать номера блоков, хранящиеся в данном бло- ке, в суперблок; освободить блочный буфер (алгоритм brelse); снять блокировку с суперблока; возобновить выполнение процессов (после снятия бло- кировки с суперблока); } получить буфер для блока, удаленного из списка (алго- ритм getblk); обнулить содержимое буфера; уменьшить общее число свободных блоков; пометить суперблок как "измененный"; возвратить буфер; } |
Алгоритмы назначения и освобождения индексов и дисковых блоков сходятся в том, что ядро использует суперблок в качестве кеша, хранящего указатели на свободные ресурсы - номера блоков и номера индексов. Оно поддерживает список номеров блоков с указателями, такой, что каждый номер свободного блока в файловой системе появляется в некотором элементе списка, но ядро не поддерживает такого списка для свободных индексов. Тому есть три причины.
Ядро устанавливает, свободен ли индекс или нет, проверяя: если поле типа файла очищено, индекс свободен. Ядро не нуждается в другом механизме описания свободных индексов. Тем не менее, оно не может определить, свободен ли блок или нет, только взглянув на него. Ядро не может уловить различия между маской, показывающей, что блок свободен, и информацией, случайно имеющей сходную маску. Следовательно, ядро нуждается во внешнем механизме идентификации свободных блоков, в качестве него в традиционных реализациях системы используется список с указателями. Сама конструкция дисковых блоков наводит на мысль об использовании списков с указателями: в дисковом блоке легко разместить большие списки номеров свободных блоков. Но индексы не имеют подходящего места для массового хранения списков номеров свободных индексов. Пользователи имеют склонность чаще расходовать дисковые блоки, нежели индексы, поэтому кажущееся запаздывание в работе при просмотре диска в поисках свободных индексов не является таким критическим, как если бы оно имело место при поисках свободных дисковых блоков.
Рисунок 4.20. Запрашивание и освобождение дисковых блоков
Comments:
Copyright ©
Выделение области
Ядро выделяет новую область (по алгоритму allocreg, ) во время выполнения системных функций fork, exec и shmget (получить разделяемую память). Ядро поддерживает таблицу областей, записям которой соответствуют точки входа либо в списке свободных областей, либо в списке активных областей. При выделении записи в таблице областей ядро выбирает из списка свободных областей первую доступную запись, включает ее в список активных областей, блокирует область и делает пометку о ее типе (разделяемая или частная). За некоторым исключением каждый процесс ассоциируется с исполняемым файлом (после того, как была выполнена команда exec), и в алгоритме allocreg поле индекса в записи таблицы областей устанавливается таким образом, чтобы оно указывало на индекс исполняемого файла. Индекс идентифицирует область для ядра, поэтому другие процессы могут при желании разделять область. Ядро увеличивает значение счетчика ссылок на индекс, чтобы помешать другим процессам удалять содержимое файла при выполнении функции unlink, об этом еще будет идти речь в . Результатом алгоритма allocreg является назначение и блокировка области.
| алгоритм allocreg /* разместить информационную структуру области */ входная информация: (1) указатель индекса (2) тип области выходная информация: заблокированная область { выбрать область из списка свободных областей; назначить области тип; присвоить значение указателю индекса; если (указатель индекса имеет ненулевое значение) увеличить значение счетчика ссылок на индекс; включить область в список активных областей; возвратить (заблокированную область); } |
Рисунок 6.18. Алгоритм выделения области
Выгрузка процессов
Ядро выгружает процесс, если испытывает потребность в свободной памяти, которая может возникнуть в следующих случаях:
Произведено обращение к системной функции fork, которая должна выделить место в памяти для процесса-потомка. Произведено обращение к системной функции brk, увеличивающей размер процесса. Размер процесса увеличился в результате естественного увеличения стека процесса. Ядру нужно освободить в памяти место для подкачки ранее выгруженных процессов.
Обращение к системной функции fork выделено в особую ситуацию, поскольку это единственный случай, когда пространство памяти, ранее занятое процессом (родителем), не освобождается.
Когда ядро принимает решение о том, что процесс будет выгружен из основной памяти, оно уменьшает значение счетчика ссылок, ассоциированного с каждой областью процесса, и выгружает те области, у которых счетчик ссылок стал равным 0. Ядро выделяет место на устройстве выгрузки и блокирует процесс в памяти (в случаях 1-3), запрещая его выгрузку (см. ) до тех пор, пока не закончится текущая операция выгрузки. Адрес места выгрузки областей ядро сохраняет в соответствующих записях таблицы областей.
За одну операцию ввода-вывода, в которой участвуют устройство выгрузки и адресное пространство задачи и которая осуществляется через буферный кеш, ядро выгружает максимально-возможное количество данных. Если аппаратура не в состоянии передать за одну операцию содержимое нескольких страниц памяти, перед программами ядра встает задача осуществить передачу содержимого памяти за несколько шагов по одной странице за каждую операцию. Таким образом, точная скорость и механизм передачи данных определяются, помимо всего прочего, возможностями дискового контроллера и стратегией распределения памяти. Например, если используется страничная организация памяти, существует вероятность, что выгружаемые данные занимают несмежные участки физической памяти. Ядро обязано собирать информацию об адресах страниц с выгружаемыми данными, которую впоследствии использует дисковый драйвер, осуществляющий управление процессом ввода-вывода. Перед тем, как выгрузить следующую порцию данных, программа подкачки (выгрузки) ждет завершения предыдущей операции ввода-вывода.
При этом перед ядром не встает задача переписать на устройство выгрузки содержимое виртуального адресного пространства процесса полностью. Вместо этого ядро копирует на устройство выгрузки содержимое физической памяти, отведенной процессу, игнорируя неиспользуемые виртуальные адреса. Когда ядро подкачивает процесс обратно в память, оно имеет у себя карту виртуальных адресов процесса и может переназначить процессу новые адреса. Ядро считывает копию процесса из буферного кеша в физическую память, в те ячейки, для которых установлено соответствие с виртуальными адресами процесса.
На приведен пример отображения образа процесса в памяти на адресное пространство устройства выгрузки (). Процесс располагает тремя областями: команд, данных и стека. Область команд заканчивается на виртуальном адресе 2К, а область данных начинается с адреса 64К, таким образом в виртуальном адресном пространстве образовался пропуск в 62 Кбайта. Когда ядро выгружает процесс, оно выгружает содержимое страниц памяти с адресами 0, 1К, 64К, 65К, 66К и 128К; на устройстве выгрузки не будет отведено место под пропуск в 62 Кбайта между областями команд и данных, как и под пропуск в 61 Кбайт между областями данных и стека, ибо пространство на устройстве выгрузки заполняется непрерывно. Когда ядро загружает процесс обратно в память, оно уже знает из карты памяти процесса о том, что процесс имеет в своем пространстве неиспользуемый участок размером 62К, и с учетом этого соответственно выделяет физическую память. Этот случай проиллюстрирован с помощью . Сравнение Рисунков и показывает, что физические адреса, занимаемые процессом до и после выгрузки, не совпадают между собой; однако, на пользовательском уровне процесс не обращает на это никакого внимания, поскольку содержимое его виртуального пространства осталось тем же самым.
Теоретически все пространство памяти, занятое процессом, в том числе его личное адресное пространство и стек ядра, может быть выгружено, хотя ядро и может временно заблокировать область в памяти на время выполнения критической операции. Однако практически, ядро не выгружает содержимое адресного пространства процесса, если в нем находятся таблицы преобразования адресов (адресные таблицы) процесса. Практическими соображениями так же диктуются условия, при которых процесс может выгрузить самого себя или потребовать своей выгрузки другим процессом (см. ).

Рисунок 9.6. Отображение пространства процесса на устройство выгрузки

Рисунок 9.7. Загрузка процесса в память
9.1.2.1 Выгрузка при выполнении системной функции fork
В описании системной функции fork () предполагалось, что процесс-родитель получил в свое распоряжение память, достаточную для создания контекста потомка. Если это условие не выполняется, ядро выгружает процесс из памяти, не освобождая пространство памяти, занимаемое его (родителя) копией. Когда процедура выгрузки завершится, процесс-потомок будет располагаться на устройстве выгрузки; процесс-родитель переводит своего потомка в состояние "готовности к выполнению" (см. ) и возвращается в режим задачи. Поскольку процесс-потомок находится в состоянии "готовности к выполнению", программа подкачки в конце концов загрузит его в память, где ядро запустит его на выполнение; потомок завершит тем самым свою роль в выполнении системной функции fork и вернется в режим задачи.
9.1.2.2 Выгрузка с расширением
Если процесс испытывает потребность в дополнительной физической памяти, либо в результате расширения стека, либо в результате запуска функции brk, и если эта потребность превышает доступные резервы памяти, ядро выполняет операцию выгрузки процесса с расширением его размера на устройстве выгрузки. На устройстве выгрузки ядро резервирует место для размещения процесса с учетом расширения его размера. Затем производится перенастройка таблицы преобразования адресов процесса с учетом дополнительного виртуального пространства, но без выделения физической памяти (в связи с ее отсутствием). Наконец, ядро выгружает процесс, выполняя процедуру выгрузки обычным порядком и обнуляя вновь выделенное пространство на устройстве (см. ). Когда несколько позже ядро будет загружать процесс обратно в память, физическое пространство будет выделено уже с учетом нового состояния таблицы преобразования адресов. В момент возобновления у процесса уже будет в распоряжении память достаточного объема.

Рисунок 9.8. Перенастройка карты памяти в случае выгрузки с расширением
Мы рассмотрели несколько форм взаимодействия
Мы рассмотрели несколько форм взаимодействия процессов. Первой формой, положившей начало обсуждению, явилась трассировка процессов - взаимодействие двух процессов, выступающее в качестве полезного средства отладки программ. При всех своих преимуществах трассировка процессов с помощью функции ptrace все же достаточно дорогостоящее и примитивное мероприятие, поскольку за один сеанс функция способна передать строго ограниченный объем данных, требуется большое количество переключений контекста, взаимодействие ограничивается только формой отношений родитель-потомок, и наконец, сама трассировка производится только по обоюдному согласию участвующих в ней процессов. В версии V системы UNIX имеется пакет взаимодействия процессов (IPC), включающий в себя механизмы обмена сообщениями, работы с семафорами и разделения памяти. К сожалению, все эти механизмы имеют узкоспециальное назначение, не имеют хорошей стыковки с другими элементами операционной системы и не действуют в сети. Тем не менее, они используются во многих приложениях и по сравнению с другими схемами отличаются более высокой эффективностью.
Система UNIX поддерживает широкий спектр вычислительных сетей. Традиционные методы согласования протоколов в сильной степени полагаются на помощь системной функции ioctl, однако в разных типах сетей они реализуются по-разному. В системе BSD имеются системные функции для работы с гнездами, поддерживающие более универсальную структуру сетевого взаимодействия. В будущем в версию V предполагается включить описанный в главе 10 потоковый механизм, повышающий согласованность работы в сети.
Comments:
Copyright ©
В данной главе нами были рассмотрены три схемы работы с расположенными на удаленных машинах файлами, трактующие удаленные файловые системы как расширение локальной. Архитектурные различия между этими схемами показаны на . Все они в свою очередь отличаются от многопроцессорных систем, описанных в предыдущей главе, тем, что здесь процессоры не используют физическую память совместно. Система с периферийными процессорами состоит из сильносвязанного набора процессоров, совместно использующих файловые ресурсы центрального процессора. Связь типа Newcastle обеспечивает скрытый ("прозрачный") доступ к удаленным файлам, но не средствами ядра операционной системы, а благодаря использованию специальной Си-библиотеки. По этой причине все программы, предполагающие использовать связь данного типа, должны быть перекомпилированы, что в общем-то является серьезным недостатком этой схемы. Удаленность файла обозначается с помощью специальной последовательности символов, описывающих машину, на которой расположен файл, и это является еще одним фактором, ограничивающим мобильность программ.
В "прозрачных" распределенных системах для доступа к удаленным файлам используется модификация системной функции mount. Индексы в локальной системе содержат отметку о том, что они относятся к удаленным файлам, и локальное ядро посылает на удаленную систему сообщение, описывающее запрашиваемую системную функцию, ее параметры и удаленный индекс. Связь в "прозрачной" распределенной системе поддерживается в двух формах: в форме вызова удаленной процедуры (на удаленную машину посылается сообщение, содержащее перечень операций, связанных с индексом) и в форме вызова удаленной системной функции (сообщение описывает запрашиваемую функцию). В заключительной части главы рассмотрены вопросы, имеющие отношение к обработке дистанционных запросов с помощью процессов-спутников и серверов.
Comments:
Copyright ©
В данной главе была рассмотрена структура буферного кеша и различные способы, которыми ядро размещает блоки в кеше. В алгоритмах буферизации сочетаются несколько простых идей, которые в сумме обеспечивают работу механизма кеширования. При работе с блоками в буферном кеше ядро использует алгоритм замены буферов, к которым наиболее долго не было обращений, предполагая, что к блокам, к которым недавно было обращение, вероятно, вскоре обратятся снова. Очередность, в которой буферы появляются в списке свободных буферов, соответствует очередности их предыдущего использования. Остальные алгоритмы обслуживания буферов, типа "первым пришел - первым вышел" и замещения редко используемых, либо являются более сложными в реализации, либо снижают процент попадания в кеш. Использование функции хеширования и хеш-очередей дает ядру возможность ускорить поиск заданных блоков, а использование двунаправленных указателей в списках облегчает исключение буферов.
Ядро идентифицирует нужный ему блок по номеру логического устройства и номеру блока. Алгоритм getblk просматривает буферный кеш в поисках блока и, если буфер присутствует и свободен, блокирует буфер и возвращает его. Если буфер заблокирован, обратившийся к нему процесс приостанавливается до тех пор, пока буфер не освободится. Механизм блокирования гарантирует, что только один процесс в каждый момент времени работает с буфером. Если в кеше блок отсутствует, ядро назначает блоку свободный буфер, блокирует и возвращает его. Алгоритм bread выделяет блоку буфер и при необходимости читает туда информацию. Алгоритм bwrite копирует информацию в предварительно выделенный буфер. Если при выполнении указанных алгоритмов ядро не увидит необходимости в немедленном копировании данных на диск, оно пометит буфер для "отложенной записи", чтобы избежать излишнего ввода-вывода. К сожалению, процедура откладывания записи сопровождается тем, что процесс никогда не уверен, в какой момент данные физически попадают на диск. Если ядро записывает данные на диск синхронно, оно поручает драйверу диска передать блок файловой системе и ждет прерывания, сообщающего об окончании ввода-вывода.
Существует множество способов использования ядром буферного кеша. Посредством буферного кеша ядро обеспечивает обмен данными между прикладными программами и файловой системой, передачу дополнительной системной информации, например, индексов, между алгоритмами ядра и файловой системой. Ядро также использует буферный кеш, когда читает программы в память для выполнения. В следующих главах будет рассмотрено множество алгоритмов, использующих процедуры, описанные в данной главе. Другие алгоритмы, которые кешируют индексы и страницы памяти, также используют приемы, похожие на те, что описаны для буферного кеша.
Comments:
Copyright ©
Индекс представляет собой структуру данных, в которой описываются атрибуты файла, в том числе расположение информации файла на диске. Существует две разновидности индекса: копия на диске, в которой хранится информация индекса, пока файл находится в работе, и копия в памяти, где хранится информация об активных файлах. Алгоритмы ialloc и ifree управляют назначением файлу дискового индекса во время выполнения системных операций creat, mknod, pipe и unlink (см. следующую главу), а алгоритмы iget и iput управляют выделением индексов в памяти в момент обращения процесса к файлу. Алгоритм bmap определяет местонахождение дисковых блоков, принадлежащих файлу, используя предварительно заданное смещение в байтах от начала файла. Каталоги представляют собой файлы, которые устанавливают соответствие между компонентами имен файлов и номерами индексов. Алгоритм namei преобразует имена файлов, с которыми работают процессы, в идентификаторы индексов, с которыми работает ядро. Наконец, ядро управляет назначением файлу новых дисковых блоков, используя алгоритмы alloc и free.
Структуры данных, рассмотренные в настоящей главе, состоят из связанных списков, хеш-очередей и линейных массивов, и поэтому алгоритмы, работающие с рассмотренными структурами данных, достаточно просты. Сложности появляются тогда, когда возникает конкуренция, вызываемая взаимодействием алгоритмов между собой, и некоторые из этих проблем синхронизации рассмотрены в тексте. Тем не менее, алгоритмы не настолько детально разработаны и могут служить иллюстрацией простоты конструкции системы.
Вышеописанные структуры и алгоритмы работают внутри ядра и невидимы для пользователя. С точки зрения общей архитектуры системы (), алгоритмы, рассмотренные в данной главе, имеют отношение к нижней половине подсистемы управления файлами. Следующая глава посвящена разбору обращений к операционной системе, обеспечивающих функционирование пользовательского интерфейса, и описанию верхней половины подсистемы управления файлами, из которой вызывается выполнение рассмотренных здесь алгоритмов.
Comments:
Copyright ©
Этой главой завершается первая часть книги, посвященная рассмотрению особенностей файловой системы. Глава познакомила пользователя с тремя таблицами, принадлежащими ядру: таблицей пользовательских дескрипторов файла, системной таблицей файлов и таблицей монтирования. В ней рассмотрены алгоритмы выполнения системных функций, имеющих отношение к файловой системе, и взаимодействие между этими функциями. Исследованы некоторые абстрактные свойства файловой системы, позволяющие системе UNIX поддерживать файловые системы различных типов. Наконец, описан механизм выполнения команды fsck, контролирующей целостность и согласованность данных в файловой системе.
Comments:
Copyright ©
Мы завершили рассмотрение контекста процесса. Процессы в системе UNIX могут находиться в различных логических состояниях и переходить из состояния в состояние в соответствии с установленными правилами перехода, при этом информация о состоянии сохраняется в таблице процессов и в адресном пространстве процесса. Контекст процесса состоит из пользовательского контекста и системного контекста. Пользовательский контекст состоит из программ процесса, данных, стека задачи и областей разделяемой памяти, а системный контекст состоит из статической части (запись в таблице процессов, адресное пространство процесса и информация, необходимая для отображения адресного пространства) и динамической части (стек ядра и сохраненное состояние регистров предыдущего контекстного уровня системы), которые запоминаются в стеке и выбираются из стека при выполнении процессом обращений к системным функциям, при обработке прерываний и при переключениях контекста. Пользовательский контекст процесса распадается на отдельные области, которые представляют собой непрерывные участки виртуального адресного пространства и трактуются как самостоятельные объекты использования и защиты. В модели управления памятью, которая использовалась при описании формата виртуального адресного пространства процесса, предполагалось наличие у каждой области процесса своей таблицы страниц. Ядро располагает целым набором различных алгоритмов для работы с областями. В заключительной части главы были рассмотрены алгоритмы приостанова (sleep) и возобновления (wakeup) процессов. Структуры и алгоритмы, описанные в данной главе, будут использоваться в последующих главах при рассмотрении системных функций управления процессами и планирования их выполнения, а также при объяснении различных методов распределения памяти.
Comments:
Copyright ©
В данной главе были рассмотрены системные функции, предназначенные для работы с контекстом процесса и для управления выполнением процесса. Системная функция fork создает новый процесс, копируя для него содержимое всех областей, подключенных к родительскому процессу. Особенность реализации функции fork состоит в том, что она выполняет инициализацию сохраненного регистрового контекста порожденного процесса, таким образом этот процесс начинает выполняться, не дожидаясь завершения функции, и уже в теле функции начинает осознавать свою предназначение как потомка. Все процессы завершают свое выполнение вызовом функции exit, которая отсоединяет области процесса и посылает его родителю сигнал "гибель потомка". Процесс-родитель может совместить момент продолжения своего выполнения с моментом завершения процесса-потомка, используя системную функцию wait. Системная функция exec дает процессу возможность запускать на выполнение другие программы, накладывая содержимое исполняемого файла на свое адресное пространство. Ядро отсоединяет области, ранее занимаемые процессом, и назначает процессу новые области в соответствии с потребностями исполняемого файла. Совместное использование областей команд и наличие режима "sticky-bit" дают возможность более рационально использовать память и экономить время, затрачиваемое на подготовку к запуску программ. Простым пользователям предоставляется возможность получать привилегии других пользователей, даже суперпользователя, благодаря обращению к услугам системной функции setuid и setuid-программ. С помощью функции brk процесс может изменять размер своей области данных. Функция signal дает процессам возможность управлять своей реакцией на поступающие сигналы. При получении сигнала производится обращение к специальной функции обработки сигнала с внесением соответствующих изменений в стек задачи и в сохраненный регистровый контекст задачи. Процессы могут сами посылать сигналы, используя системную функцию kill, они могут также контролировать получение сигналов, предназначенных группе процессов, прибегая к услугам функции setpgrp.
Командный процессор shell и процесс начальной загрузки init используют стандартные обращения к системным функциям, производя набор операций, в других системах обычно выполняемых ядром. Shell интерпретирует команды пользователя, переназначает стандартные файлы ввода-вывода данных и выдачи ошибок, порождает процессы, организует каналы между порожденными процессами, синхронизирует свое выполнение с этими процессами и формирует коды, возвращаемые командами. Процесс init тоже порождает различные процессы, в частности, управляющие работой пользователя за терминалом. Когда такой процесс завершается, init может породить для выполнения той же самой функции еще один процесс, если это вытекает из информации файла "/etc/inittab".
Comments:
Copyright ©
В этой главе описаны полная структура системы UNIX, взаимоотношения между процессами, выполняющимися в режиме задачи и в режиме ядра, а также аппаратная среда функционирования ядра операционной системы. Процессы выполняются в режиме задачи или в режиме ядра, в котором они пользуются услугами системы благодаря наличию набора обращений к операционной системе. Архитектура системы поддерживает такой стиль программирования, при котором из небольших программ, выполняющих только отдельные функции, но хорошо, составляются более сложные программы, использующие механизм каналов и переназначение ввода-вывода.
Обращения к операционной системе позволяют процессам производить операции, которые иначе не выполняются. В дополнение к обработке подобных обращений ядро операционной системы осуществляет общие учетные операции, управляет планированием процессов, распределением памяти и защитой процессов в оперативной памяти, обслуживает прерывания, управляет файлами и устройствами и обрабатывает особые ситуации, возникающие в системе. В функции ядра системы UNIX намеренно не включены многие функции, являющиеся частью других операционных систем, поскольку набор обращений к системе позволяет процессам выполнять все необходимые операции на пользовательском уровне. В содержится более детальная информация о ядре, описывающая его архитектуру и вводящая некоторые основные понятия, которые используются при описании его функционирования.
Comments:
Copyright ©
В настоящей главе был описан основной алгоритм диспетчеризации процессов в системе UNIX. С каждым процессом в системе связывается приоритет планирования, значение которого появляется в момент перехода процесса в состояние приостанова и периодически корректируется программой обработки прерываний по таймеру. Приоритет, присваиваемый процессу в момент перехода в состояние приостанова, имеет значение, зависящее от того, какой из алгоритмов ядра исполнялся процессом в этот момент. Значение приоритета, присваиваемое процессу во время выполнения программой обработки прерываний по таймеру (или в тот момент, когда процесс возвращается из режима ядра в режим задачи), зависит от того, сколько времени процесс занимал ЦП: процесс получает низкий приоритет, если он обращался к ЦП, и высокий - в противном случае. Системная функция nice дает процессу возможность влиять на собственный приоритет путем добавления параметра, участвующего в пересчете приоритета. В главе были также рассмотрены системные функции, связанные с временем выполнения системы и протекающих в ней процессов: с установкой и получением системного времени, получением времени выполнения процессов и установкой сигналов "будильника". Кроме того, описаны функции программы обработки прерываний по таймеру, которая следит за временем в системе, управляет таблицей ответных сигналов, собирает статистику, а также подготавливает запуск планировщика процессов, программы подкачки и "сборщика" страниц. Программа подкачки и "сборщик" страниц являются объектами рассмотрения в следующей главе.
Comments:
Copyright ©
Прочитанная глава была посвящена рассмотрению алгоритмов подкачки процессов и замещения страниц, используемых в версии V системы UNIX. Алгоритм подкачки процессов реализует перемещение процессов целиком между основной памятью и устройством выгрузки. Ядро выгружает процессы из памяти, если их размер поглощает всю свободную память в системе (в результате выполнения функций fork, exec и sbrk или в результате естественного увеличения стека), или в том случае, если требуется освободить память для загрузки процесса. Загрузку процессов выполняет специальный процесс подкачки (процесс 0), который запускается всякий раз, как на устройстве выгрузки появляются процессы, готовые к выполнению. Процесс подкачки не прекращает своей работы до тех пор, пока на устройстве выгрузки не останется ни одного такого процесса или пока в основной памяти не останется свободного места. В последнем случае процесс подкачки пытается выгрузить что-нибудь из основной памяти, но в его обязанности входит также слежение за соблюдением требования минимальной продолжительности пребывания выгружаемых процессов в памяти (в целях предотвращения холостой перекачки); по этой причине процесс подкачки не всегда достигает успеха в своей работе. Возобновление процесса подкачки в случае возникновения необходимости в нем производит с интервалом в одну секунду программа обработки прерываний по таймеру.
В системе с замещением страниц по запросу процессы могут исполняться, даже если их виртуальное адресное пространство загружено в память не полностью; поэтому виртуальный размер процесса может превышать объем доступной физической памяти в системе. Когда ядро испытывает потребность в свободных страницах, "сборщик" страниц просматривает все активные страницы в каждой области, помечая для выгрузки те из них, которые достаточно "созрели" для этого, и в конечном итоге откачивает их на устройство выгрузки. Когда процесс обращается к виртуальной странице, которая в настоящий момент выгружена из памяти, он получает отказ из-за недоступности данных. Ядро запускает программу обработки отказа, которая назначает области новую физическую страницу памяти и копирует в нее содержимое виртуальной страницы.
Повысить производительность системы при использовании алгоритма замещения страниц по запросу можно несколькими способами. Во-первых, если процесс вызывает функцию fork, ядро использует бит копирования при записи, тем самым в большинстве случаев снимая необходимость в физическом копировании страниц. Во-вторых, ядро может запросить содержимое страницы исполняемого файла прямо из файловой системы, устраняя потребность в вызове функции exec для незамедлительного считывания файла в память. Это способствует повышению производительности, поскольку не исключена возможность того, что подобные страницы так никогда и не потребуются процессу, и устраняет излишнюю холостую перекачку, имеющую место в том случае, если "сборщик" страниц выгружает эти страницы из памяти до того, как в них возникает потребность.
Comments:
Copyright ©
Данная глава представляет собой обзор драйверов устройств в системе UNIX. Устройства могут быть либо блочного, либо символьного типа; интерфейс между устройствами и остальной частью ядра определяется типом устройств. Интерфейсом для устройств блочного типа выступает таблица ключей устройств ввода-вывода блоками, состоящая из точек входа, соответствующих процедурам открытия и закрытия устройств и стратегической процедуре. Стратегическая процедура управляет передачей данных от и к устройству блочного типа. Интерфейсом для устройств символьного типа выступает таблица ключей устройств посимвольного ввода-вывода, которая состоит из точек входа, соответствующих процедурам открытия и закрытия устройства, чтения, записи и процедуре ioctl. Системная функция ioctl использует при обращении к устройствам символьного типа свой собственный интерфейс, который позволяет осуществлять передачу управляющей информации между процессами и устройствами. По получении прерывания от устройства ядро вызывает программу обработки соответствующего прерывания, опираясь на информацию, хранящуюся в таблице векторов прерываний, и на параметры, сообщенные устройством, от которого поступило прерывание.
Дисковые драйверы превращают номера логических блоков, используемые файловой системой, в физические адреса на диске. Блочный интерфейс дает возможность ядру буферизовать данные. Взаимодействие без обработки ускоряет ввод-вывод на диск, но игнорирует буферный кеш, увеличивая тем самым шансы разрушить файловую систему.
Терминальные драйверы осуществляют непосредственное взаимодействие с пользователями. Ядро связывает с каждым терминалом три символьных списка, один для неструктурированного ввода с клавиатуры, один для ввода с обработкой символов стирания, удаления и возврата каретки и один для вывода. Системная функция ioctl дает процессам возможность следить за тем, как ядро обрабатывает вводимые данные, переводя терминал в канонический режим или устанавливая значения различных параметров для режима без обработки символов. Getty-процесс открывает терминальные линии и ждет связи: он формирует группу процессов во главе с регистрационным shell'ом, инициализирует с помощью функции ioctl параметры терминала и обращается к пользователю с предложением зарегистрироваться. Установленный таким образом операторский терминал посылает процессам в группе сигналы в ответ на возникновение таких событий, как "зависание" пользователя или нажатие им клавиши прерывания.
Потоки выступают средством повышения модульности построения драйверов устройств и протоколов. Поток - это полнодуплексная связь между процессами и драйверами устройств, которая может включать в себя строковые интерфейсы и протоколы для промежуточной обработки данных. Модули потоков характеризуются четко определенным взаимодействием и гибкостью, позволяющей использовать их в сочетании с другими модулями. Эта гибкость имеет особое значение для сетевых протоколов и драйверов.
Comments:
Copyright ©
ВЫВОДЫ И ОБЗОР ПОСЛЕДУЮЩИХ ГЛАВ
В этой главе описана архитектура ядра операционной системы; его основными компонентами выступают подсистема управления файлами и подсистема управления процессами. Подсистема управления файлами управляет хранением и выборкой данных в пользовательских файлах. Файлы организованы в виде файловых систем, которые трактуются как логические устройства; физическое устройство, такое как диск, может содержать несколько логических устройств (файловых систем). Каждая файловая система имеет суперблок, в котором описывается структура и содержимое файловой системы, каждый файл в файловой системе описывается индексом, хранящим атрибуты файла. Системные операции работают с файлами, используя индексы.
Процессы находятся в различных состояниях и переходят из состояния в состояние, следуя определенным правилам перехода. В частности, процессы, выполняющиеся в режиме ядра, могут приостановить свое выполнение и перейти в состояние "сна", но ни один процесс не может перевести в это состояние другой процесс. Ядро является невыгружаемым и это означает, что процесс, выполняющийся в режиме ядра, будет продолжать свое выполнение до тех пор, пока не перейдет в состояние "сна" или пока не вернется в режим задачи. Ядро обеспечивает целостность своих информационных структур благодаря своей невыгружаемости, а также путем блокирования прерываний на время выполнения критических секций программы.
В остальных частях главы детально описываются подсистемы, изображенные на Рисунке , а также взаимодействие между ними, начиная с подсистемы управления файлами и включая подсистему управления процессами. В следующей главе рассматривается буфер сверхоперативной памяти (кеш) и описываются алгоритмы управления буфером, используемые в главах 4, 5 и 7. рассматриваются внутренние алгоритмы файловой системы, включая обработку индексов, структуру файлов, преобразование имени пути в индекс. рассматриваются системные операции, которые, используя приведенные в главе 4 алгоритмы, обращаются к файловой системе, т.е. такие, как open, close, read и write. имеет дело с понятием контекста процесса и его адресным пространством, а рассматривает системные операции, связанные с управлением процессами и использующие алгоритмы главы 6. касается планирования выполнения процессов, обсуждаются алгоритмы распределения памяти. посвящена драйверам устройств, рассмотрение которых до того откладывалось, чтобы прежде объяснить связь драйвера терминала с управлением процессами. представлено несколько форм взаимодействия процессов. Наконец, в последних двух главах рассматриваются вопросы, связанные с углубленным изучением особенностей системы, в частности, особенности многопроцессорных систем и распределенных систем.
Comments:
Copyright ©
ВЫЗОВ ДРУГИХ ПРОГРАММ
Системная функция exec дает возможность процессу запускать другую программу, при этом соответствующий этой программе исполняемый файл будет располагаться в пространстве памяти процесса. Содержимое пользовательского контекста после вызова функции становится недоступным, за исключением передаваемых функции параметров, которые переписываются ядром из старого адресного пространства в новое. Синтаксис вызова функции: execve(filename,argv,envp)
где filename - имя исполняемого файла, argv - указатель на массив параметров, которые передаются вызываемой программе, а envp - указатель на массив параметров, составляющих среду выполнения вызываемой программы. Вызов системной функции exec осуществляют несколько библиотечных функций, таких как execl, execv, execle и т.д. В том случае, когда программа использует параметры командной строки main(argc,argv) ,
массив argv является копией одноименного параметра, передаваемого функции exec. Символьные строки, описывающие среду выполнения вызываемой программы, имеют вид "имя=значение" и содержат полезную для программ информацию, такую как начальный каталог пользователя и путь поиска исполняемых программ. Процессы могут обращаться к параметрам описания среды выполнения, используя глобальную переменную environ, которую заводит начальная процедура Си-интерпретатора.
| алгоритм exec входная информация: (1) имя файла (2) список параметров (3) список переменных среды выходная информация: отсутствует { получить индекс файла (алгоритм namei); проверить, является ли файл исполнимым и имеет ли поль- зователь право на его исполнение; прочитать информацию из заголовков файла и проверить, является ли он загрузочным модулем; скопировать параметры, переданные функции, из старого адресного пространства в системное пространство; для (каждой области, присоединенной к процессу) отсоединить все старые области (алгоритм detachreg); для (каждой области, определенной в загрузочном модуле) { выделить новые области (алгоритм allocreg); присоединить области (алгоритм attachreg); загрузить область в память по готовности (алгоритм loadreg); } скопировать параметры, переданные функции, в новую об- ласть стека задачи; специальная обработка для setuid-программ, трассировка; проинициализировать область сохранения регистров задачи (в рамках подготовки к возвращению в режим задачи); освободить индекс файла (алгоритм iput); } |
Рисунок 7.19. Алгоритм функции exec
На представлен алгоритм выполнения системной функции exec. Сначала функция обращается к файлу по алгоритму namei, проверяя, является ли файл исполнимым и отличным от каталога, а также проверяя наличие у пользователя права исполнять программу. Затем ядро, считывая заголовок файла, определяет размещение информации в файле (формат файла).
На изображен логический формат исполняемого файла в файловой системе, обычно генерируемый транслятором или загрузчиком. Он разбивается на четыре части:
Главный заголовок, содержащий информацию о том, на сколько разделов делится файл, а также содержащий начальный адрес исполнения процесса и некоторое "магическое число", описывающее тип исполняемого файла. Заголовки разделов, содержащие информацию, описывающую каждый раздел в файле: его размер, виртуальные адреса, в которых он располагается, и др. Разделы, содержащие собственно "данные" файла (например, текстовые), которые загружаются в адресное пространство процесса. Разделы, содержащие смешанную информацию, такую как таблицы идентификаторов и другие данные, используемые в процессе отладки.

Рисунок 7.20. Образ исполняемого файла
Указанные составляющие с развитием самой системы видоизменяются, однако во всех исполняемых файлах обязательно присутствует главный заголовок с полем типа файла.
Тип файла обозначается коротким целым числом (представляется в машине полусловом), которое идентифицирует файл как загрузочный модуль, давая тем самым ядру возможность отслеживать динамические характеристики его выполнения. Например, в машине PDP 11/70 определение типа файла как загрузочного модуля свидетельствует о том, что процесс, исполняющий файл, может использовать до 128 Кбайт памяти вместо 64 Кбайт (), тем не менее в системах с замещением страниц тип файла все еще играет существенную роль, в чем нам предстоит убедиться во время знакомства с главой 9.
Вернемся к алгоритму. Мы остановились на том, что ядро обратилось к индексу файла и установило, что файл является исполнимым. Ядру следовало бы освободить память, занимаемую пользовательским контекстом процесса. Однако, поскольку в памяти, подлежащей освобождению, располагаются передаваемые новой программе параметры, ядро первым делом копирует их из адресного пространства в промежуточный буфер на время, пока не будут отведены области для нового пространства памяти.
Поскольку параметрами функции exec выступают пользовательские адреса массивов символьных строк, ядро по каждой строке сначала копирует в системную память адрес строки, а затем саму строку. Для хранения строки в разных версиях системы могут быть выбраны различные места. Чаще принято хранить строки в стеке ядра (локальная структура данных, принадлежащая программе ядра), на нераспределяемых участках памяти (таких как страницы), которые можно занимать только временно, а также во внешней памяти (на устройстве выгрузки).
С точки зрения реализации проще всего для копирования параметров в новый пользовательский контекст обратиться к стеку ядра. Однако, поскольку размер стека ядра, как правило, ограничивается системой, а также поскольку параметры функции exec могут иметь произвольную длину, этот подход следует сочетать с другими подходами. При рассмотрении других вариантов обычно останавливаются на способе хранения, обеспечивающем наиболее быстрый доступ к строкам. Если доступ к страницам памяти в системе реализуется довольно просто, строки следует размещать на страницах, поскольку обращение к оперативной памяти осуществляется быстрее, чем к внешней (устройству выгрузки).
После копирования параметров функции exec в системную память ядро отсоединяет области, ранее присоединенные к процессу, используя алгоритм detachreg. Несколько позже мы еще поговорим о специальных действиях, выполняемых в отношении областей команд. К рассматриваемому моменту процесс уже лишен пользовательского контекста и поэтому возникновение в дальнейшем любой ошибки неизбежно будет приводить к завершению процесса по сигналу. Такими ошибками могут быть обращение к пространству, не описанному в таблице областей ядра, попытка загрузить программу, имеющую недопустимо большой размер или использующую области с пересекающимися адресами, и др. Ядро выделяет и присоединяет к процессу области команд и данных, загружает в оперативную память содержимое исполняемого файла (алгоритмы allocreg, attachreg и loadreg, соответственно). Область данных процесса изначально поделена на две части: данные, инициализация которых была выполнена во время компиляции, и данные, не определенные компилятором ("bss"). Область памяти первоначально выделяется для проинициализированных данных. Затем ядро увеличивает размер области данных для размещения данных типа "bss" (алгоритм growreg) и обнуляет их значения. Напоследок ядро выделяет и присоединяет к процессу область стека и отводит пространство памяти для хранения параметров функции exec. Если параметры функции размещаются на страницах, те же страницы могут быть использованы под стек. В противном случае параметры функции размещаются в стеке задачи.
В пространстве процесса ядро стирает адреса пользовательских функций обработки сигналов, поскольку в новом пользовательском контексте они теряют свое значение. Однако и в новом контексте рекомендации по игнорированию тех или иных сигналов остаются в силе. Ядро устанавливает в регистрах для режима задачи значения из сохраненного регистрового контекста, в частности первоначальное значение указателя вершины стека (sp) и счетчика команд (pc): первоначальное значение счетчика команд было занесено загрузчиком в заголовок файла. Для setuid-программ и для трассировки процесса ядро предпринимает особые действия, на которых мы еще остановимся во время рассмотрения глав 8 и 11, соответственно. Наконец, ядро запускает алгоритм iput, освобождая индекс, выделенный по алгоритму namei в самом начале выполнения функции exec. Алгоритмы namei и iput в функции exec выполняют роль, подобную той, которую они выполняют при открытии и закрытии файла; состояние файла во время выполнения функции exec похоже на состояние открытого файла, если не принимать во внимание отсутствие записи о файле в таблице файлов. По выходе из функции процесс исполняет текст новой программы. Тем не менее, процесс остается тем же, что и до выполнения функции; его идентификатор не изменился, как не изменилось и его место в иерархии процессов. Изменению подвергся только пользовательский контекст процесса.
| main() { int status; if (fork() == 0) execl("/bin/date","date",0); wait(&status); } |
В качестве примера можно привести программу (), в которой создается процесс-потомок, запускающий функцию exec. Сразу по завершении функции fork процесс-родитель и процесс-потомок начинают исполнять независимо друг от друга копии одной и той же программы. К моменту вызова процессом-потомком функции exec в его области команд находятся инструкции этой программы, в области данных располагаются строки "/bin/date" и "date", а в стеке - записи, которые будут извлечены по выходе из exec. Ядро ищет файл "/bin/date" в файловой системе, обнаружив его, узнает, что его может исполнить любой пользователь, а также то, что он представляет собой загрузочный модуль, готовый для исполнения. По условию первым параметром функции exec, включаемым в список параметров argv, является имя исполняемого файла (последняя компонента имени пути поиска файла). Таким образом, процесс имеет доступ к имени программы на пользовательском уровне, что иногда может оказаться полезным (). Затем ядро копирует строки "/bin/date" и "date" во внутреннюю структуру хранения и освобождает области команд, данных и стека, занимаемые процессом. Процессу выделяются новые области команд, данных и стека, в область команд переписывается командная секция файла "/bin/date", в область данных - секция данных файла. Ядро восстанавливает первоначальный список параметров (в данном случае это строка символов "date") и помещает его в область стека. Вызвав функцию exec, процесс-потомок прекращает выполнение старой программы и переходит к выполнению программы "date"; когда программа "date" завершится, процесс-родитель, ожидающий этого момента, получит код завершения функции exit.
Вплоть до настоящего момента мы предполагали, что команды и данные размещаются в разных секциях исполняемой программы и, следовательно, в разных областях текущего процесса. Такое размещение имеет два основных преимущества: простота организации защиты от несанкционированного доступа и возможность разделения областей различными процессами. Если бы команды и данные находились в одной области, система не смогла бы предотвратить затирание команд, поскольку ей не были бы известны адреса, по которым они располагаются. Если же команды и данные находятся в разных областях, система имеет возможность пользоваться механизмами аппаратной защиты области команд процесса. Когда процесс случайно попытается что-то записать в область, занятую командами, он получит отказ, порожденный системой защиты и приводящий обычно к аварийному завершению процесса.
|
#include <signal.h> main() { int i,*ip; extern f(),sigcatch(); ip = (int *)f; /* присвоение переменной ip значения ад- реса функции f */ for (i = 0; i < 20; i++) signal(i,sigcatch); *ip = 1; /* попытка затереть адрес функции f */ printf("после присвоения значения ip\n"); f(); } f() { } sigcatch(n) int n; { printf("принят сигнал %d\n",n); exit(1); } |
В качестве примера можно привести программу (), которая присваивает переменной ip значение адреса функции f и затем делает распоряжение принимать все сигналы. Если программа скомпилирована так, что команды и данные располагаются в разных областях, процесс, исполняющий программу, при попытке записать что-то по адресу в ip встретит порожденный системой защиты отказ, поскольку область команд защищена от записи. При работе на компьютере AT&T 3B20 ядро посылает процессу сигнал SIGBUS, в других системах возможна посылка других сигналов. Процесс принимает сигнал и завершается, не дойдя до выполнения команды вывода на печать в процедуре main. Однако, если программа скомпилирована так, что команды и данные располагаются в одной области (в области данных), ядро не поймет, что процесс пытается затереть адрес функции f. Адрес f станет равным 1. Процесс исполнит команду вывода на печать в процедуре main, но когда запустит функцию f, произойдет ошибка, связанная с попыткой выполнения запрещенной команды. Ядро пошлет процессу сигнал SIGILL и процесс завершится.
Расположение команд и данных в разных областях облегчает поиск и предотвращение ошибок адресации. Тем не менее, в ранних версиях системы UNIX команды и данные разрешалось располагать в одной области, поскольку на машинах PDP размер процесса был сильно ограничен: программы имели меньший размер и существенно меньшую сегментацию, если команды и данные занимали одну и ту же область. В последних версиях системы таких строгих ограничений на размер процесса нет и в дальнейшем возможность загрузки команд и данных в одну область компиляторами не будет поддерживаться.
Второе преимущество раздельного хранения команд и данных состоит в возможности совместного использования областей процессами. Если процесс не может вести запись в область команд, команды процесса не претерпевают никаких изменений с того момента, как ядро загрузило их в область команд из командной секции исполняемого файла. Если один и тот же файл исполняется несколькими процессами, в целях экономии памяти они могут иметь одну область команд на всех. Таким образом, когда ядро при выполнении функции exec отводит область под команды процесса, оно проверяет, имеется ли возможность совместного использования процессами команд исполняемого файла, что определяется "магическим числом" в заголовке файла. Если да, то с помощью алгоритма xalloc ядро ищет существующую область с командами файла или назначает новую в случае ее отсутствия (см. ).
Исполняя алгоритм xalloc, ядро просматривает список активных областей в поисках области с командами файла, индекс которого совпадает с индексом исполняемого файла. В случае ее отсутствия ядро выделяет новую область (алгоритм allocreg), присоединяет ее к процессу (алгоритм attachreg), загружает ее в память (алгоритм loadreg) и защищает от записи (read-only). Последний шаг предполагает, что при попытке процесса записать что-либо в область команд будет получен отказ, вызванный системой защиты памяти. В случае обнаружения области с командами файла в списке активных областей осуществляется проверка ее наличия в памяти (она может быть либо загружена в память, либо выгружена из памяти) и присоединение ее к процессу. В завершение выполнения алгоритма xalloc ядро снимает с области блокировку, а позднее, следуя алгоритму detachreg при выполнении функций exit или exec, уменьшает значение счетчика областей. В традиционных реализациях системы поддерживается таблица команд, к которой ядро обращается в случаях, подобных описанному. Таким образом, совокупность областей команд можно рассматривать как новую версию этой таблицы.
Напомним, что если область при выполнении алгоритма allocreg () выделяется впервые, ядро увеличивает значение счетчика ссылок на индекс, ассоциированный с областью, при этом значение счетчика ссылок нами уже было увеличено в самом начале выполнения функции exec (алгоритм namei). Поскольку ядро уменьшает значение счетчика только один раз в завершение выполнения функции exec (по алгоритму iput), значение счетчика ссылок на индекс файла, ассоциированного с разделяемой областью команд и исполняемого в настоящий момент, равно по меньшей мере 1. Поэтому когда процесс разрывает связь с файлом (функция unlink), содержимое файла остается нетронутым (не претерпевает изменений). После загрузки в память сам файл ядру становится ненужен, ядро интересует только указатель на копию индекса файла в памяти, содержащийся в таблице областей; этот указатель и будет идентифицировать файл, связанный с областью. Если бы значение счетчика ссылок стало равным 0, ядро могло бы передать копию индекса в памяти другому файлу, тем самым делая сомнительным значение указателя на индекс в записи таблицы областей: если бы пользователю пришлось исполнить новый файл, используя функцию exec, ядро по ошибке связало бы его с областью команд старого файла. Эта проблема устраняется благодаря тому, что ядро при выполнении алгоритма allocreg увеличивает значение счетчика ссылок на индекс, предупреждая тем самым переназначение индекса в памяти другому файлу. Когда процесс во время выполнения функций exit или exec отсоединяет область команд, ядро уменьшает значение счетчика ссылок на индекс (по алгоритму freereg), если только связь индекса с областью не помечена как "неотъемлемая".
| алгоритм xalloc /* выделение и инициализация области команд */ входная информация: индекс исполняемого файла выходная информация: отсутствует { если (исполняемый файл не имеет отдельной области команд) вернуть управление; если (уже имеется область команд, ассоциированная с ин- дексом исполняемого файла) { /* область команд уже существует ... подключиться к ней */ заблокировать область; выполнить пока (содержимое области еще не доступно) { /* операции над счетчиком ссылок, предохраняющие от глобального удаления области */ увеличить значение счетчика ссылок на область; снять с области блокировку; приостановиться (пока содержимое области не станет доступным); заблокировать область; уменьшить значение счетчика ссылок на область; } присоединить область к процессу (алгоритм attachreg); снять с области блокировку; вернуть управление; } /* интересующая нас область команд не существует -- соз- дать новую */ выделить область команд (алгоритм allocreg); /* область заблоки- рована */ если (область помечена как "неотъемлемая") отключить соответствующий флаг; подключить область к виртуальному адресу, указанному в заголовке файла (алгоритм attachreg); если (файл имеет специальный формат для системы с замеще- нием страниц) /* этот случай будет рассмотрен в главе 9 */ в противном случае /* файл не имеет специального фор- мата */ считать команды из файла в область (алгоритм loadreg); изменить режим защиты области в записи частной таблицы областей процесса на "read-only"; снять с области блокировку; } |
Рисунок 7.23. Алгоритм выделения областей команд

Рисунок 7.24. Взаимосвязь между таблицей индексов и таблицей областей в случае совместного использования процессами одной области команд
Рассмотрим в качестве примера ситуацию, приведенную на , где показана взаимосвязь между структурами данных в процессе выполнения функции exec по отношению к файлу "/bin/date" при условии расположения команд и данных файла в разных областях. Когда процесс исполняет файл "/bin/date" первый раз, ядро назначает для команд файла точку входа в таблице областей () и по завершении выполнения функции exec оставляет счетчик ссылок на индекс равным 1. Когда файл "/bin/date" завершается, ядро запускает алгоритмы detachreg и freereg, сбрасывая значение счетчика ссылок в 0. Однако, если ядро в первом случае не увеличило значение счетчика, оно по завершении функции exec останется равным 0 и индекс на всем протяжении выполнения процесса будет находиться в списке свободных индексов. Предположим, что в это время свободный индекс понадобился процессу, запустившему с помощью функции exec файл "/bin/who", тогда ядро может выделить этому процессу индекс, ранее принадлежавший файлу "/ bin/date". Просматривая таблицу областей в поисках индекса файла "/bin/who", ядро вместо него выбрало бы индекс файла "/bin/date". Считая, что область содержит команды файла "/bin/who", ядро исполнило бы совсем не ту программу. Поэтому значение счетчика ссылок на индекс активного файла, связанного с разделяемой областью команд, должно быть не меньше единицы, чтобы ядро не могло переназначить индекс другому файлу.
Возможность совместного использования различными процессами одних и тех же областей команд позволяет экономить время, затрачиваемое на запуск программы с помощью функции exec. Администраторы системы могут с помощью системной функции (и команды) chmod устанавливать для часто исполняемых файлов режим "sticky-bit", сущность которого заключается в следующем. Когда процесс исполняет файл, для которого установлен режим "sticky-bit", ядро не освобождает область памяти, отведенную под команды файла, отсоединяя область от процесса во время выполнения функций exit или exec, даже если значение счетчика ссылок на индекс становится равным 0. Ядро оставляет область команд в первоначальном виде, при этом значение счетчика ссылок на индекс равно 1, пусть даже область не подключена больше ни к одному из процессов. Если же файл будет еще раз запущен на выполнение (уже другим процессом), ядро в таблице областей обнаружит запись, соответствующую области с командами файла. Процесс затратит на запуск файла меньше времени, так как ему не придется читать команды из файловой системы. Если команды файла все еще находятся в памяти, в их перемещении не будет необходимости; если же команды выгружены во внешнюю память, будет гораздо быстрее загрузить их из внешней памяти, чем из файловой системы (см. об этом в ).
Ядро удаляет из таблицы областей записи, соответствующие областям с командами файла, для которого установлен режим "sticky-bit" (иными словами, когда область помечена как "неотъемлемая" часть файла или процесса), в следующих случаях:
Если процесс открыл файл для записи, в результате соответствующих операций содержимое файла изменится, при этом будет затронуто и содержимое области. Если процесс изменил права доступа к файлу (chmod), отменив режим "sticky-bit", файл не должен оставаться в таблице областей. Если процесс разорвал связь с файлом (unlink), он не сможет больше исполнять этот файл, поскольку у файла не будет точки входа в файловую систему; следовательно, и все остальные процессы не будут иметь доступа к записи в таблице областей, соответствующей файлу. Поскольку область с командами файла больше не используется, ядро может освободить ее вместе с остальными ресурсами, занимаемыми файлом. Если процесс демонтирует файловую систему, файл перестает быть доступным и ни один из процессов не может его исполнить. В остальном - все как в предыдущем случае. Если ядро использовало уже все пространство внешней памяти, отведенное под выгрузку задач, оно пытается освободить часть памяти за счет областей, имеющих пометку "sticky-bit", но не используемых в настоящий момент. Несмотря на то, что эти области могут вскоре понадобиться другим процессам, потребности ядра являются более срочными.
В первых двух случаях область команд с пометкой "sticky-bit" должна быть освобождена, поскольку она больше не отражает текущее состояние файла. В остальных случаях это делается из практических соображений. Конечно же ядро освобождает область только при том условии, что она не используется ни одним из выполняющихся процессов (счетчик ссылок на нее имеет нулевое значение); в противном случае это привело бы к аварийному завершению выполнения системных функций open, unlink и umount (случаи 1, 3 и 4, соответственно).
Если процесс запускает с помощью функции exec самого себя, алгоритм выполнения функции несколько усложняется. По команде sh script командный процессор shell порождает новый процесс (новую ветвь), который инициирует запуск shell'а (с помощью функции exec) и исполняет команды файла "script". Если процесс запускает самого себя и при этом его область команд допускает совместное использование, ядру придется следить за тем, чтобы при обращении ветвей процесса к индексам и областям не возникали взаимные блокировки. Иначе говоря, ядро не может, не снимая блокировки со "старой" области команд, попытаться заблокировать "новую" область, поскольку на самом деле это одна и та же область. Вместо этого ядро просто оставляет "старую" область команд присоединенной к процессу, так как в любом случае ей предстоит повторное использование.
Обычно процессы вызывают функцию exec после функции fork; таким образом, во время выполнения функции fork процесс-потомок копирует адресное пространство своего родителя, но сбрасывает его во время выполнения функции exec и по сравнению с родителем исполняет образ уже другой программы. Не было бы более естественным объединить две системные функции в одну, которая бы загружала программу и исполняла ее под видом нового процесса? Ричи высказал предположение, что возникновение fork и exec как отдельных системных функций обязано тому, что при создании системы UNIX функция fork была добавлена к уже существующему образу ядра системы (см. [Ritchie 84a], стр.1584). Однако, разделение fork и exec важно и с функциональной точки зрения, поскольку в этом случае процессы могут работать с дескрипторами файлов стандартного ввода-вывода независимо, повышая тем самым "элегантность" использования каналов. Пример, показывающий использование этой возможности, приводится в разделе 7.8.
(**) В PDP 11 "магические числа" имеют значения, соответствующие командам перехода; при выполнении этих команд в ранних версиях системы управление передавалось в разные места программы в зависимости от размера заголовка и от типа исполняемого файла. Эта особенность больше не используется с тех пор, как система стала разрабатываться на языке Си.
(***) Например, в версии V стандартные программы переименования файла (mv), копирования файла (cp) и компоновки файла (ln), поскольку исполняют похожие действия, вызывают один и тот же исполняемый файл. По имени вызываемой программы процесс узнает, какие действия в настоящий момент требуются пользователю.
Comments:
Copyright ©
ВЗАИМОДЕЙСТВИЕ ДРАЙВЕРОВ С ПРОГРАММНОЙ И АППАРАТНОЙ СРЕДОЙ
В системе UNIX имеется два типа устройств - устройства ввода/вывода блоками и устройства неструктурированного или посимвольного ввода-вывода. Как уже говорилось в , устройства ввода-вывода блоками, такие как диски и ленты, для остальной части системы выглядят как запоминающие устройства с произвольной выборкой; к устройствам посимвольного ввода-вывода относятся все другие устройства, в том числе терминалы и сетевое оборудование. Устройства ввода-вывода блоками могут иметь интерфейс и с устройствами посимвольного ввода-вывода.
Пользователь взаимодействует с устройствами через посредничество файловой системы (см. ). Каждое устройство имеет имя, похожее на имя файла, и пользователь обращается к нему как к файлу. Специальный файл устройства имеет индекс и занимает место в иерархии каталогов файловой системы. Файл устройства отличается от других файлов типом файла, хранящимся в его индексе, либо "блочный", либо "символьный специальный", в зависимости от устройства, которое этот файл представляет. Если устройство имеет как блочный, так и символьный интерфейс, его представляют два файла: специальный файл устройства ввода-вывода блоками и специальный файл устройства посимвольного ввода-вывода. Системные функции для обычных файлов, такие как open, close, read и write, имеют то же значение и для устройств, в чем мы убедимся позже. Системная функция ioctl предоставляет процессам возможность управлять устройствами посимвольного ввода-вывода, но не применима в отношении к файлам обычного типа (). Тем не менее, драйверам устройств нет необходимости поддерживать полный набор системных функций. Например, вышеупомянутый драйвер трассировки дает процессам возможность читать записи, созданные другими драйверами, но не позволяет создавать их.
ВЗАИМОДЕЙСТВИЕ ПРОЦЕССОВ В ВЕРСИИ V СИСТЕМЫ
Пакет IPC (interprocess communication) в версии V системы UNIX включает в себя три механизма. Механизм сообщений дает процессам возможность посылать другим процессам потоки сформатированных данных, механизм разделения памяти позволяет процессам совместно использовать отдельные части виртуального адресного пространства, а семафоры - синхронизировать свое выполнение с выполнением параллельных процессов. Несмотря на то, что они реализуются в виде отдельных блоков, им присущи общие свойства.
С каждым механизмом связана таблица, в записях которой описываются все его детали. В каждой записи содержится числовой ключ (key), который представляет собой идентификатор записи, выбранный пользователем. В каждом механизме имеется системная функция типа "get", используемая для создания новой или поиска существующей записи; параметрами функции являются идентификатор записи и различные флаги (flag). Ядро ведет поиск записи по ее идентификатору в соответствующей таблице. Процессы могут с помощью флага IPC_PRIVATE гарантировать получение еще неиспользуемой записи. С помощью флага IPC_CREAT они могут создать новую запись, если записи с указанным идентификатором нет, а если еще к тому же установить флаг IPC_EXCL, можно получить уведомление об ошибке в том случае, если запись с таким идентификатором существует. Функция возвращает некий выбранный ядром дескриптор, предназначенный для последующего использования в других системных функциях, таким образом, она работает аналогично системным функциям creat и open. В каждом механизме ядро использует следующую формулу для поиска по дескриптору указателя на запись в таблице структур данных: указатель = значение дескриптора по модулю от числа записей в таблице Если, например, таблица структур сообщений состоит из 100 записей, дескрипторы, связанные с записью номер 1, имеют значения, равные 1, 101, 201 и т.д. Когда процесс удаляет запись, ядро увеличивает значение связанного с ней дескриптора на число записей в таблице: полученный дескриптор станет новым дескриптором этой записи, когда к ней вновь будет произведено обращение при помощи функции типа "get". Процессы, которые будут пытаться обратиться к записи по ее старому дескриптору, потерпят неудачу. Обратимся вновь к предыдущему примеру. Если с записью 1 связан дескриптор, имеющий значение 201, при его удалении ядро назначит записи новый дескриптор, имеющий значение 301. Процессы, пытающиеся обратиться к дескриптору 201, получат ошибку, поскольку этого дескриптора больше нет. В конечном итоге ядро произведет перенумерацию дескрипторов, но пока это произойдет, может пройти значительный промежуток времени. Каждая запись имеет некую структуру данных, описывающую права доступа к ней и включающую в себя пользовательский и групповой коды идентификации, которые имеет процесс, создавший запись, а также пользовательский и групповой коды идентификации, установленные системной функцией типа "control" (об этом ниже), и двоичные коды разрешений чтения-записи-исполнения для владельца, группы и прочих пользователей, по аналогии с установкой прав доступа к файлам. В каждой записи имеется другая информация, описывающая состояние записи, в частности, идентификатор последнего из процессов, внесших изменения в запись (посылка сообщения, прием сообщения, подключение разделяемой памяти и т.д.), и время последнего обращения или корректировки. В каждом механизме имеется системная функция типа "control", запрашивающая информацию о состоянии записи, изменяющая эту информацию или удаляющая запись из системы. Когда процесс запрашивает информацию о состоянии записи, ядро проверяет, имеет ли процесс разрешение на чтение записи, после чего копирует данные из записи таблицы по адресу, указанному пользователем. При установке значений принадлежащих записи параметров ядро проверяет, совпадают ли между собой пользовательский код идентификации процесса и идентификатор пользователя (или создателя), указанный в записи, не запущен ли процесс под управлением суперпользователя; одного разрешения на запись недостаточно для установки параметров. Ядро копирует сообщенную пользователем информацию в запись таблицы, устанавливая значения пользовательского и группового кодов идентификации, режимы доступа и другие параметры (в зависимости от типа механизма). Ядро не изменяет значения полей, описывающих пользовательский и групповой коды идентификации создателя записи, поэтому пользователь, создавший запись, сохраняет управляющие права на нее. Пользователь может удалить запись, либо если он является суперпользователем, либо если идентификатор процесса совпадает с любым из идентификаторов, указанных в структуре записи. Ядро увеличивает номер дескриптора, чтобы при следующем назначении записи ей был присвоен новый дескриптор. Следовательно, как уже ранее говорилось, если процесс попытается обратиться к записи по старому дескриптору, вызванная им функция получит отказ.
Взаимодействие с операционной системой через вызовы системных функций
Такого рода взаимодействие с ядром было предметом рассмотрения в предыдущих главах, где шла речь об обычном вызове функций. Очевидно, что обычная последовательность команд обращения к функции не в состоянии переключить выполнения процесса с режима задачи на режим ядра. Компилятор с языка Си использует библиотеку функций, имена которых совпадают с именами системных функций, иначе ссылки на системные функции в пользовательских программах были бы ссылками на неопределенные имена. В библиотечных функциях обычно исполняется команда, переводящая выполнение процесса в режим ядра и побуждающая ядро к запуску исполняемого кода системной функции. В дальнейшем эта команда именуется "внутренним прерыванием операционной системы". Библиотечные процедуры исполняются в режиме задачи, а взаимодействие с операционной системой через вызов системной функции можно определить в нескольких словах как особый случай программы обработки прерывания. Библиотечные функции передают ядру уникальный номер системной функции одним из машинно-зависимых способов - либо как параметр внутреннего прерывания операционной системы, либо через отдельный регистр, либо через стек - а ядро таким образом определяет тип вызываемой функции.
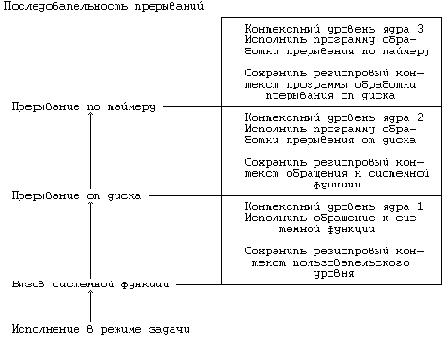
Рисунок 6.11. Примеры прерываний
Обрабатывая внутреннее прерывание операционной системы, ядро по номеру системной функции ведет в таблице поиск адреса соответствующей процедуры ядра, то есть точки входа системной функции, и количества передаваемых функции параметров (). Ядро вычисляет адрес (пользовательский) первого параметра функции, прибавляя (или вычитая, в зависимости от направления увеличения стека) смещение к указателю вершины стека задачи (аналогично для всех параметров функции). Наконец, ядро копирует параметры задачи в пространство процесса и вызывает соответствующую процедуру, которая выполняет системную функцию. После исполнения процедуры ядро выясняет, не было ли ошибки. Если ошибка была, ядро делает соответствующие установки в сохраненном регистровом контексте задачи, при этом в регистре PS обычно устанавливается бит переноса, а в нулевой регистр заносится номер ошибки. Если при выполнении системной функции не было ошибок, ядро очищает в регистре PS бит переноса и заносит возвращаемые функцией значения в регистры 0 и 1 в сохраненном регистровом контексте задачи. Когда ядро возвращается после обработки внутреннего прерывания операционной системы в режим задачи, оно попадает в следующую библиотечную инструкцию после прерывания. Библиотечная функция интерпретирует возвращенные ядром значения и передает их программе пользователя.
| алгоритм syscall /* алгоритм запуска системной функции */ входная информация: номер системной функции выходная информация: результат системной функции { найти запись в таблице системных функций, соответствую- щую указанному номеру функции; определить количество параметров, передаваемых функции; скопировать параметры из адресного пространства задачи в пространство процесса; сохранить текущий контекст для аварийного завершения (см. раздел 6.44); запустить в ядре исполняемый код системной функции; если (во время выполнения функции произошла ошибка) { установить номер ошибки в нулевом регистре сохра- ненного регистрового контекста задачи; включить бит переноса в регистре PS сохраненного регистрового контекста задачи; } в противном случае занести возвращаемые функцией значения в регистры 0 и 1 в сохраненном регистровом контексте задачи; } |
В качестве примера рассмотрим программу, которая создает файл с разрешением чтения и записи в него для всех пользователей (режим доступа 0666) и которая приведена в верхней части . Далее на рисунке изображен отредактированный фрагмент сгенерированного кода программы после компиляции и дисассемблирования (создания по объектному коду эквивалентной программы на языке ассемблера) в системе Motorola 68000. На изображена конфигурация стека для системной функции создания. Компилятор генерирует программу помещения в стек задачи двух параметров, один из которых содержит установку прав доступа (0666), а другой - переменную "имя файла" . Затем из адреса 64 процесс вызывает библиотечную функцию creat (адрес 7a), аналогичную соответствующей системной функции. Адрес точки возврата из функции 6a, этот адрес помещается процессом в стек. Библиотечная функция creat засылает в регистр 0 константу 8 и исполняет команду прерывания (trap), которая переключает процесс из режима задачи в режим ядра и заставляет его обратиться к системной функции. Заметив, что процесс вызывает системную функцию, ядро выбирает из регистра 0 номер функции (8) и определяет таким образом, что вызвана функция creat. Просматривая внутреннюю таблицу, ядро обнаруживает, что системной функции creat необходимы два параметра; восстанавливая регистровый контекст предыдущего уровня, ядро копирует параметры из пользовательского пространства в пространство процесса. Процедуры ядра, которым понадобятся эти параметры, могут найти их в определенных местах адресного пространства процесса. По завершении исполнения кода функции creat управление возвращается программе обработки обращений к операционной системе, которая проверяет, установлено ли поле ошибки в пространстве процесса (то есть имела ли место во время выполнения функции ошибка); если да, программа устанавливает в регистре PS бит переноса, заносит в регистр 0 код ошибки и возвращает управление ядру. Если ошибок не было, в регистры 0 и 1 ядро заносит код завершения. Возвращая управление из программы обработки обращений к операционной системе в режим задачи, библиотечная функция проверяет состояние бита переноса в регистре PS (по адресу 7): если бит установлен, управление передается по адресу 13c, из нулевого регистра выбирается код ошибки и помещается в глобальную переменную errno по адресу 20, в регистр 0 заносится -1, и управление возвращается на следующую после адреса 64 (где производится вызов функции) команду. Код завершения функции имеет значение -1, что указывает на ошибку в выполнении системной функции. Если же бит переноса в регистре PS при переходе из режима ядра в режим задачи имеет нулевое значение, процесс с адреса 7 переходит по адресу 86 и возвращает управление вызвавшей программе (адрес 64); регистр 0 содержит возвращаемое функцией значение.
| char name[] = "file"; main() { int fd; fd = creat(name,0666); } |
|
Фрагменты ассемблерной программы, сгенерированной в системе Motorola 68000 Адрес Команда - - # текст главной программы - 58: mov &Ox1b6,(%sp) # поместить код 0666 в стек 5e: mov &Ox204,-(%sp) # поместить указатель вершины # стека и переменную "имя файла" # в стек 64: jsr Ox7a # вызов библиотечной функции # создания файла - - # текст библиотечной функции создания файла 7a: movq &Ox8,%d0 # занести значение 8 в регистр 0 7c: trap &Ox0 # внутреннее прерывание операци- # онной системы 7e: bcc &Ox6 <86> # если бит переноса очищен, # перейти по адресу 86 80: jmp Ox13c # перейти по адресу 13c 86: rts # возврат из подпрограммы - - # текст обработки ошибок функции 13c: mov %d0,&Ox20e # поместить содержимое регистра # 0 в ячейку 20e (переменная # errno) 142: movq &-Ox1,%d0 # занести в регистр 0 константу # -1 144: mova %d0,%a0 146: rts # возврат из подпрограммы |
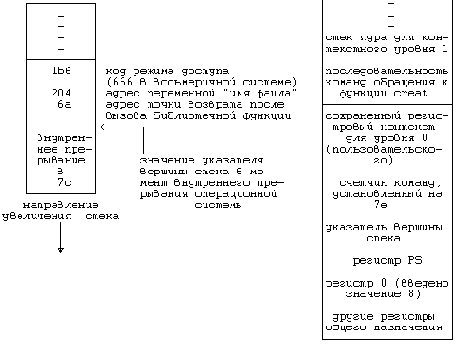
Рисунок 6.14. Конфигурация стека для системной функции creat
Несколько библиотечных функций могут отображаться на одну точку входа в список системных функций. Каждая точка входа определяет точные синтаксис и семантику обращения к системной функции, однако более удобный интерфейс обеспечивается с помощью библиотек. Существует, например, несколько конструкций системной функции exec, таких как execl и execle, выполняющих одни и те же действия с небольшими отличиями. Библиотечные функции, соответствующие этим конструкциям, при обработке параметров реализуют заявленные свойства, но в конечном итоге, отображаются на одну и ту же функцию ядра.
(**) Очередность, в которой компилятор вычисляет и помещает в стек параметры функции, зависит от реализации системы.
ВЗАИМОДЕЙСТВИЕ В СЕТИ
Программы, поддерживающие межмашинную связь, такие, как электронная почта, программы дистанционной пересылки файлов и удаленной регистрации, издавна используются в качестве специальных средств организации подключений и информационного обмена. Так, например, стандартные программы, работающие в составе электронной почты, сохраняют текст почтовых сообщений пользователя в отдельном файле (для пользователя "mjb" этот файл имеет имя "/usr/mail/mjb"). Когда один пользователь посылает другому почтовое сообщение на ту же машину, программа mail (почта) добавляет сообщение в конец файла адресата, используя в целях сохранения целостности различные блокирующие и временные файлы. Когда адресат получает почту, программа mail открывает принадлежащий ему почтовый файл и читает сообщения. Для того, чтобы послать сообщение на другую машину, программа mail должна в конечном итоге отыскать на ней соответствующий почтовый файл. Поскольку программа не может работать с удаленными файлами непосредственно, процесс, протекающий на другой машине, должен действовать в качестве агента локального почтового процесса; следовательно, локальному процессу необходим способ связи со своим удаленным агентом через межмашинные границы. Локальный процесс является клиентом удаленного обслуживающего (серверного) процесса.
Поскольку в системе UNIX новые процессы создаются с помощью системной функции fork, к тому моменту, когда клиент попытается выполнить подключение, обслуживающий процесс уже должен существовать. Если бы в момент создания нового процесса удаленное ядро получало запрос на подключение (по каналам межмашинной связи), возникла бы несогласованность с архитектурой системы. Чтобы избежать этого, некий процесс, обычно init, порождает обслуживающий процесс, который ведет чтение из канала связи, пока не получает запрос на обслуживание, после чего в соответствии с некоторым протоколом выполняет установку соединения. Выбор сетевых средств и протоколов обычно выполняют программы клиента и сервера, основываясь на информации, хранящейся в прикладных базах данных; с другой стороны, выбранные пользователем средства могут быть закодированы в самих программах.
В качестве примера рассмотрим программу uucp, которая обслуживает пересылку файлов в сети и исполнение команд на удалении (см. [Nowitz 80]). Процесс-клиент запрашивает в базе данных адрес и другую маршрутную информацию (например, номер телефона), открывает автокоммутатор, записывает или проверяет информацию в дескрипторе открываемого файла и вызывает удаленную машину. Удаленная машина может иметь специальные линии, выделенные для использования программой uucp; выполняющийся на этой машине процесс init порождает getty-процессы - серверы, которые управляют линиями и получают извещения о подключениях. После выполнения аппаратного подключения процесс-клиент регистрируется в системе в соответствии с обычным протоколом регистрации: getty-процесс запускает специальный интерпретатор команд, uucico, указанный в файле "/etc/passwd", а процесс-клиент передает на удаленную машину последовательность команд, тем самым заставляя ее исполнять процессы от имени локальной машины.
Сетевое взаимодействие в системе UNIX представляет серьезную проблему, поскольку сообщения должны включать в себя как информационную, так и управляющую части. В управляющей части сообщения может располагаться адрес назначения сообщения. В свою очередь, структура адресных данных зависит от типа сети и используемого протокола. Следовательно, процессам нужно знать тип сети, а это идет вразрез с тем принципом, по которому пользователи не должны обращать внимания на тип файла, ибо все устройства для пользователей выглядят как файлы. Традиционные методы реализации сетевого взаимодействия при установке управляющих параметров в сильной степени полагаются на помощь системной функции ioctl, однако в разных типах сетей этот момент воплощается по-разному. Отсюда возникает нежелательный побочный эффект, связанный с тем, что программы, разработанные для одной сети, в других сетях могут не заработать.
Чтобы разработать сетевые интерфейсы для системы UNIX, были предприняты значительные усилия. Реализация потоков в последних редакциях версии V располагает элегантным механизмом поддержки сетевого взаимодействия, обеспечивающим гибкое сочетание отдельных модулей протоколов и их согласованное использование на уровне задач. Следующий раздел посвящен краткому описанию метода решения данных проблем в системе BSD, основанного на использовании гнезд.
Comments:
Copyright ©
WRIТЕ
Синтаксис вызова системной функции write (писать): number = write(fd,buffer,count);
где переменные fd, buffer, count и number имеют тот же смысл, что и для вызова системной функции read. Алгоритм записи в обычный файл похож на алгоритм чтения из обычного файла. Однако, если в файле отсутствует блок, соответствующий смещению в байтах до места, куда должна производиться запись, ядро выделяет блок, используя алгоритм alloc, и присваивает ему номер в соответствии с точным указанием места в таблице содержимого индекса. Если смещение в байтах совпадает со смещением для блока косвенной адресации, ядру, возможно, придется выделить несколько блоков для использования их в качестве блоков косвенной адресации и информационных блоков. Индекс блокируется на все время выполнения функции write, так как ядро может изменить индекс, выделяя новые блоки; разрешение другим процессам обращаться к файлу может разрушить индекс, если несколько процессов выделяют блоки одновременно, используя одни и те же значения смещений. Когда запись завершается, ядро корректирует размер файла в индексе, если файл увеличился в размере.
| #include <fcntl.h> main() { int fd1,fd2; char buf1[512],buf2[512];
fd1 = open("/etc/passwd",O_RDONLY); fd2 = open("/etc/passwd",O_RDONLY); | read(fd1,buf1,sizeof(buf1)); read(fd2,buf2,sizeof(buf2)); | } |
Рисунок 5.9. Чтение из файла с использованием двух дескрипторов
Предположим, к примеру, что процесс записывает в файл байт с номером 10240, наибольшим номером среди уже записанных в файле. Обратившись к байту в файле по алгоритму bmap, ядро обнаружит, что в файле отсутствует не только соответствующий этому байту блок, но также и нужный блок косвенной адресации. Ядро назначает дисковый блок в качестве блока косвенной адресации и записывает номер блока в копии индекса, хранящейся в памяти. Затем оно выделяет дисковый блок под данные и записывает его номер в первую позицию вновь созданного блока косвенной адресации.
Так же, как в алгоритме read, ядро входит в цикл, записывая на диск по одному блоку на каждой итерации. При этом на каждой итерации ядро определяет, будет ли производиться запись целого блока или только его части. Если записывается только часть блока, ядро в первую очередь считывает блок с диска для того, чтобы не затереть те части, которые остались без изменений, а если записывается целый блок, ядру не нужно читать весь блок, так как в любом случае оно затрет предыдущее содержимое блока. Запись осуществляется поблочно, однако ядро использует отложенную запись () данных на диск, запоминая их в кеше на случай, если они понадобятся вскоре другому процессу для чтения или записи, а также для того, чтобы избежать лишних обращений к диску. Отложенная запись, вероятно, наиболее эффективна для каналов, так как другой процесс читает канал и удаляет из него данные (). Но даже для обычных файлов отложенная запись эффективна, если файл создается временно и вскоре будет прочитан. Например, многие программы, такие как редакторы и электронная почта, создают временные файлы в каталоге "/tmp" и быстро удаляют их. Использование отложенной записи может сократить количество обращений к диску для записи во временные файлы.
Comments:
Copyright ©
ЗАГОЛОВКИ БУФЕРА
Во время инициализации системы ядро выделяет место под совокупность буферов, потребность в которых определяется в зависимости от размера памяти и производительности системы. Каждый буфер состоит из двух частей: области памяти, в которой хранится информация, считываемая с диска, и заголовка буфера, который идентифицирует буфер. Поскольку существует однозначное соответствие между заголовками буферов и массивами данных, в нижеследующем тексте используется термин "буфер" в ссылках как на ту, так и на другую его составляющую, и о какой из частей буфера идет речь будет понятно из контекста.
Информация в буфере соответствует информации в одном логическом блоке диска в файловой системе, и ядро распознает содержимое буфера, просматривая идентифицирующие поля в его заголовке. Буфер представляет собой копию дискового блока в памяти; содержимое дискового блока отображается в буфер, но это отображение временное, поскольку оно имеет место до того момента, когда ядро примет решение отобразить в буфер другой дисковый блок. Один дисковый блок не может быть одновременно отображен в несколько буферов. Если бы два буфера содержали информацию для одного и того же дискового блока, ядро не смогло бы определить, в каком из буферов содержится текущая информация, и, возможно, возвратило бы на диск некорректную информацию. Предположим, например, что дисковый блок отображается в два буфера, A и B. Если ядро запишет данные сначала в буфер A, а затем в буфер B, дисковый блок будет содержать данные из буфера B, если в результате операций записи буфер заполнится до конца. Однако, если ядро изменит порядок, в котором оно копирует содержимое буферов на диск, на противоположный, дисковый блок будет содержать некорректные данные.
Заголовок буфера (Рисунок 3.1) содержит поле "номер устройства" и поле "номер блока", которые определяют файловую систему и номер блока с информацией на диске и однозначно идентифицируют буфер. Номер устройства - это логический номер файловой системы (), а не физический номер устройства (диска). Заголовок буфера также содержит указатель на область памяти для буфера, размер которой должен быть не меньше размера дискового блока, и поле состояния, в котором суммируется информация о текущем состоянии буфера. Состояние буфера представляет собой комбинацию из следующих условий:
буфер заблокирован (термины "заблокирован (недоступен)" и "занят" равнозначны, так же, как и понятия "свободен" и "доступен"), буфер содержит правильную информацию, ядро должно переписать содержимое буфера на диск перед тем, как переназначить буфер; это условие известно, как "задержка, вызванная записью", ядро читает или записывает содержимое буфера на диск, процесс ждет освобождения буфера.
В заголовке буфера также содержатся два набора указателей, используемые алгоритмами выделения буфера, которые поддерживают общую структуру области буферов (буферного пула), о чем подробнее будет говориться в следующем разделе.
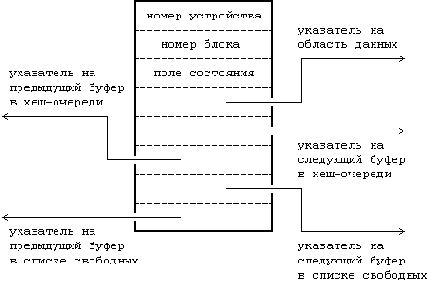
Рисунок 3.1. Заголовок буфера
Comments:
Copyright ©
Загрузка области
В системе, где поддерживается подкачка страниц по обращению, ядро может "отображать" файл в адресное пространство процесса во время выполнения функции exec, подготавливая последующее чтение по запросу отдельных физических страниц (). Если же подкачка страниц по обращению не поддерживается, ядру приходится копировать исполняемый файл в память, загружая области процесса по указанным в файле виртуальным адресам. Ядро может присоединить область к разным виртуальным адресам, по которым будет загружаться содержимое файла, создавая таким образом "разрыв" в таблице страниц (вспомним ). Эта возможность может пригодиться, например, когда требуется проявлять ошибку памяти (memory fault) в случае обращения пользовательских программ к нулевому адресу (если последнее запрещено). Переменные указатели в программах иногда задаются неверно (отсутствует проверка их значений на равенство 0) и в результате не могут использоваться в качестве указателей адресов. Если страницу с нулевым адресом соответствующим образом защитить, процессы, случайно обратившиеся к этому адресу, натолкнутся на ошибку и будут аварийно завершены, и это ускорит обнаружение подобных ошибок в программах.
| алгоритм growreg /* изменение размера области */ входная информация: (1) указатель на точку входа в частной таблице областей процесса (2) величина, на которую нужно изме- нить размер области (может быть как положительной, так и отрица- тельной) выходная информация: отсутствует { если (размер области увеличивается) { проверить допустимость нового размера области; выделить вспомогательные таблицы (страниц); если (в системе не поддерживается замещение страниц по обращению) { выделить дополнительную память; проинициализировать при необходимости значения полей в дополнительных таблицах; } } в противном случае /* размер области уменьшается */ { освободить физическую память; освободить вспомогательные таблицы; }
провести в случае необходимости инициализацию других вспомогательных таблиц; переустановить значение поля размера в таблице процес- сов; } |
Рисунок 6.21. Алгоритм изменения размера области
При загрузке файла в область алгоритм loadreg () проверяет разрыв между виртуальным адресом, по которому область присоединяется к процессу, и виртуальным адресом, с которого располагаются данные области, и расширяет область в соответствии с требуемым объемом памяти. Затем область переводится в состояние "загрузки в память", при котором данные для области считываются из файла в память с помощью встроенной модификации алгоритма системной функции read.
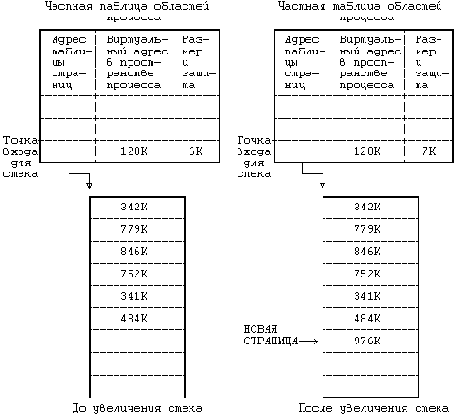
Рисунок 6.22. Увеличение области стека на 1 Кбайт
Если ядро загружает область команд, которая может разделяться несколькими процессами, возможна ситуация, когда процесс попытается воспользоваться областью до того, как ее содержимое будет полностью загружено, так как процесс загрузки может приостановиться во время чтения файла. Подробно о том, как это происходит и почему при этом нельзя использовать блокировки, мы поговорим, когда будем вести речь о функции exec в и в . Чтобы устранить эту проблему, ядро проверяет статус области и не разрешает к ней доступ до тех пор, пока загрузка области не будет закончена. По завершении реализации алгоритма loadreg ядро возобновляет выполнение всех процессов, ожидающих окончания загрузки области, и изменяет статус области ("готова, загружена в память").
Предположим, например, что ядру нужно загрузить текст размером 7K в область, присоединенную к процессу по виртуальному адресу 0, но при этом оставить промежуток размером 1 Кбайт от начала области (). К этому времени ядро уже выделило запись в таблице областей и присоединило область по адресу 0 с помощью алгоритмов allocreg и attachreg. Теперь же ядро запускает алгоритм loadreg, в котором действия алгоритма growreg выполняются дважды - во-первых, при выделении в начале области промежутка в 1 Кбайт, и во-вторых, при выделении места для содержимого области - и алгоритм growreg назначает для области таблицу страниц. Затем ядро заносит в соответствующие поля пространства процесса установочные значения для чтения данных из файла: считываются 7 Кбайт, начиная с адреса, указанного в виде смещения внутри файла (параметр алгоритма), и записываются в виртуальное пространство процесса по адресу 1K.
| алгоритм loadreg /* загрузка части файла в область */ входная информация: (1) указатель на точку входа в частную таблицу областей процесса (2) виртуальный адрес загрузки (3) указатель индекса файла (4) смещение в байтах до начала считы- ваемой части файла (5) объем загружаемых данных в байтах выходная информация: отсутствует { увеличить размер области до требуемой величины (алгоритм growreg); записать статус области как "загружаемой в память"; снять блокировку с области; установить в пространстве процесса значения параметров чтения из файла: виртуальный адрес, по которому будут размещены счи- тываемые данные; смещение до начала считываемой части файла; объем данных, считываемых из файла, в байтах; загрузить файл в область (встроенная модификация алго- ритма read); заблокировать область; записать статус области как "полностью загруженной в па- мять"; возобновить выполнение всех процессов, ожидающих оконча- ния загрузки области; } |
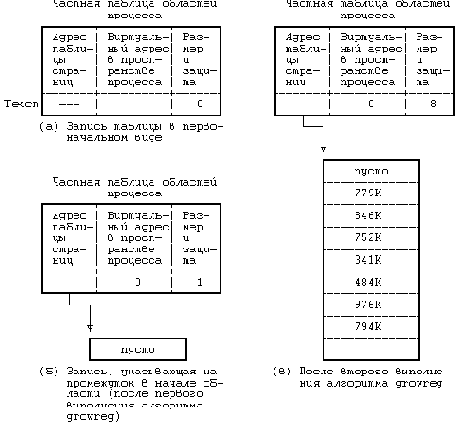
Рисунок 6.24. Загрузка области команд (текста)
| алгоритм freereg /* освобождение выделенной области */ входная информация: указатель на (заблокированную) область выходная информация: отсутствует { если (счетчик ссылок на область имеет ненулевое значе- ние) { /* область все еще используется одним из процессов */ снять блокировку с области; если (область ассоциирована с индексом) снять блокировку с индекса; возвратить управление; } если (область ассоциирована с индексом) освободить индекс (алгоритм iput); освободить связанную с областью физическую память; освободить связанные с областью вспомогательные таблицы; очистить поля области; включить область в список свободных областей; снять блокировку с области; } |
Загрузка (подкачка) процессов
Нулевой процесс (процесс подкачки) является единственным процессом, загружающим другие процессы в память с устройств выгрузки. Процесс подкачки начинает работу по выполнению этой своей единственной функции по окончании инициализации системы (как уже говорилось в ). Он загружает процессы в память и, если ему не хватает места в памяти, выгружает оттуда некоторые из процессов, находящихся там. Если у процесса подкачки нет работы (например, отсутствуют процессы, ожидающие загрузки в память) или же он не в состоянии выполнить свою работу (ни один из процессов не может быть выгружен), процесс подкачки приостанавливается; ядро периодически возобновляет его выполнение. Ядро планирует запуск процесса подкачки точно так же, как делает это в отношении других процессов, ориентируясь на более высокий приоритет, при этом процесс подкачки выполняется только в режиме ядра. Процесс подкачки не обращается к функциям операционной системы, а использует в своей работе только внутренние функции ядра; он является архетипом всех процессов ядра.
Как уже вкратце говорилось в , программа обработки прерываний по таймеру измеряет время нахождения каждого процесса в памяти или в состоянии выгрузки. Когда процесс подкачки возобновляет свою работу по загрузке процессов в память, он просматривает все процессы, находящиеся в состоянии "готовности к выполнению, будучи выгруженными", и выбирает из них один, который находится в этом состоянии дольше остальных (см. ). Если имеется достаточно свободной памяти, процесс подкачки загружает выбранный процесс, выполняя операции в последовательности, обратной выгрузке процесса. Сначала выделяется физическая память, затем с устройства выгрузки считывается нужный процесс и освобождается место на устройстве.
Если процесс подкачки выполнил процедуру загрузки успешно, он вновь просматривает совокупность выгруженных, но готовых к выполнению процессов в поисках следующего процесса, который предполагается загрузить в память, и повторяет указанную последовательность действий. В конечном итоге возникает одна из следующих ситуаций:
На устройстве выгрузки больше нет ни одного процесса, готового к выполнению. Процесс подкачки приостанавливает свою работу до тех пор, пока не возобновится процесс на устройстве выгрузки или пока ядро не выгрузит процесс, готовый к выполнению. (Вспомним диаграмму состояний на ). Процесс подкачки обнаружил процесс, готовый к загрузке, но в системе недостаточно памяти для его размещения. Процесс подкачки пытается загрузить другой процесс и в случае успеха перезапускает алгоритм подкачки, продолжая поиск загружаемых процессов.
Если процессу подкачки нужно выгрузить процесс, он просматривает все процессы в памяти. Прекратившие свое существование процессы не подходят для выгрузки, поскольку они не занимают физическую память; также не могут быть выгружены процессы, заблокированные в памяти, например, выполняющие операции над областями. Ядро предпочитает выгружать приостановленные процессы, поскольку процессы, готовые к выполнению, имеют больше шансов быть вскоре выбранными на выполнение. Решение о выгрузке процесса принимается ядром на основании его приоритета и продолжительности его пребывания в памяти. Если в памяти нет ни одного приостановленного процесса, решение о том, какой из процессов, готовых к выполнению, следует выгрузить, зависит от значения, присвоенного процессу функцией nice, а также от продолжительности пребывания процесса в памяти.
Процесс, готовый к выполнению, должен быть резидентным в памяти в течение по меньшей мере 2 секунд до того, как уйти из нее, а процесс, загружаемый в память, должен по меньшей мере 2 секунды пробыть на устройстве выгрузки. Если процесс подкачки не может найти ни одного процесса, подходящего для выгрузки, или ни одного процесса, подходящего для загрузки, или ни одного процесса, перед выгрузкой не менее 2 секунд () находившегося в памяти, он приостанавливает свою работу по причине того, что ему нужно загрузить процесс в память, а в памяти нет места для его размещения. В этой ситуации таймер возобновляет выполнение процесса подкачки через каждую секунду. Ядро также возобновляет работу процесса подкачки в том случае, когда один из процессов переходит в состояние приостанова, так как последний может оказаться более подходящим для выгрузки процессом по сравнению с ранее рассмотренными. Если процесс подкачки расчистил место в памяти или если он был приостановлен по причине невозможности сделать это, он возобновляет свою работу с перезапуска алгоритма подкачки (с самого его начала), вновь предпринимая попытку загрузить ожидающие выполнения процессы.
| алгоритм swapper /* загрузка выгруженных процессов, * выгрузка других процессов с целью * расчистки места в памяти */ входная информация: отсутствует выходная информация: отсутствует { loop: для (всех выгруженных процессов, готовых к выполнению) выбрать процесс, находящийся в состоянии выгружен- ности дольше остальных; если (таких процессов нет) { приостановиться (до момента, когда возникнет необ- ходимость в загрузке процессов); перейти на loop; } если (в основной памяти достаточно места для размеще- ния процесса) { загрузить процесс; перейти на loop; } /* loop2: сюда вставляются исправления, внесенные в алго- * ритм */ для (всех процессов, загруженных в основную память, кроме прекративших существование и заблокированных в памяти) { если (есть хотя бы один приостановленный процесс) выбрать процесс, у которого сумма приоритета и продолжительности нахождения в памяти наи- большая; в противном случае /* нет ни одного приостанов- * ленного процесса */ выбрать процесс, у которого сумма продолжи- тельности нахождения в памяти и значения nice наибольшая; } если (выбранный процесс не является приостановленным или не соблюдены условия резидентности) приостановиться (до момента, когда появится воз- можность загрузить процесс); в противном случае выгрузить процесс; перейти на loop; /* на loop2 в исправленном алгорит- * ме */ } |
Рисунок 9.9. Алгоритм подкачки
На показана динамика выполнения пяти процессов с указанием моментов их участия в реализации алгоритма подкачки. Положим для простоты, что все процессы интенсивно используют ресурсы центрального процессора и что они не производят обращений к системным функциям; следовательно, переключение контекста происходит только в результате возникновения прерываний по таймеру с интервалом в 1 секунду. Процесс подкачки исполняется с наивысшим приоритетом планирования, поэтому он всегда укладывается в секундный интервал, когда ему есть что делать. Предположим далее, что процессы имеют одинаковый размер и что в основной памяти могут одновременно поместиться только два процесса. Сначала в памяти находятся процессы A и B, остальные процессы выгружены. Процесс подкачки не может стронуть с места ни один процесс в течение первых двух секунд, поскольку этого требует условие нахождения перемещаемого процесса в течение этого интервала на одном месте (в памяти или на устройстве выгрузки), однако по истечении 2 секунд процесс подкачки выгружает процессы A и B и загружает на их место процессы C и D. Он пытается также загрузить и процесс E, но терпит неудачу, поскольку в основной памяти недостаточно места для этого. На 3-секундной отметке процесс E все еще годен для загрузки, поскольку он находился все 3 секунды на устройстве выгрузки, но процесс подкачки не может выгрузить из памяти ни один из процессов, ибо они находятся в памяти менее 2 секунд. На 4-секундной отметке процесс подкачки выгружает процессы C и D и загружает вместо них процессы E и A.
Процесс подкачки выбирает процессы для загрузки, основываясь на продолжительности их пребывания на устройстве выгрузки. В качестве другого критерия может применяться более высокий приоритет загружаемого процесса по сравнению с остальными, готовыми к выполнению процессами, поскольку такой процесс более предпочтителен для запуска. Практика показала, что такой подход "несколько" повышает пропускную способность системы в условиях сильной загруженности (см. [Peachey 84]).
Алгоритм выбора процесса для выгрузки из памяти с целью освобождения места требуемого объема имеет, однако, более серьезные изъяны. Во-первых, процесс подкачки производит выгрузку на основании приоритета, продолжительности нахождения в памяти и значения nice. Несмотря на то, что он производит выгрузку процесса с единственной целью - освободить в памяти место для загружаемого процесса, он может выгрузить и процесс, который не освобождает место требуемого размера. Например, если процесс подкачки пытается загрузить в память процесс размером 1 Мбайт, а в системе отсутствует свободная память, будет далеко не достаточно выгрузить процесс, занимающий только 2 Кбайта памяти. В качестве альтернативы может быть предложена стратегия выгрузки групп процессов при условии, что они освобождают место, достаточное для размещения загружаемых процессов.Эксперименты с использованием машины PDP 11/23 показали,что в условиях сильной загруженности такая стратегия может увеличить производительность системы почти на 10 процентов (см. [Peachey 84]).
Во-вторых, если процесс подкачки приостановил свою работу изза того, что в памяти не хватило места для загрузки процесса, после возобновления он вновь выбирает процесс для загрузки в память, несмотря на то, что ранее им уже был сделан выбор. Причина такого поведения заключается в том, что за прошедшее время в состояние готовности к выполнению могли перейти другие выгруженные процессы, более подходящие для загрузки в память по сравнению с ранее выбранным процессом. Однако от этого мало утешения для ранее выбранного процесса, все еще пытающегося загрузиться в память. В некоторых реализациях процесс подкачки стремится к тому, чтобы перед загрузкой в память одного крупного процесса выгрузить большое количество процессов маленького размера, это изменение в базовом алгоритме подкачки отражено в комментариях к алгоритму ().
В-третьих, если процесс подкачки выбирает для выгрузки процесс, находящийся в состоянии "готовности к выполнению", не исключена возможность того, что этот процесс после загрузки в память ни разу не был запущен на исполнение. Этот случай показан на , из которого видно, что ядро загружает процесс D на 2- секундной отметке, запускает процесс C, а затем на 3-секундной отметке процесс D выгружается в пользу процесса E (уступая последнему в значении nice), несмотря на то, что процессу D так и не был предоставлен ЦП. Понятно, что такая ситуация является нежелательной.
Следует упомянуть еще об одной опасности. Если при попытке выгрузить процесс на устройстве выгрузки не будет найдено свободное место, в системе может возникнуть тупиковая ситуация, при которой: все процессы в основной памяти находятся в состоянии приостанова, все готовые к выполнению процессы выгружены, для новых процессов на устройстве выгрузки уже нет места, нет свободного места и в основной памяти. Эта ситуация разбирается в . Интерес к проблемам, связанным с подкачкой процессов, в последние годы спал в связи с реализацией алгоритмов подкачки страниц памяти.


(*) Для простоты виртуальное адресное пространство процесса на этом и на всех последующих рисунках изображается в виде линейного массива точек входа в таблицу страниц, не принимая во внимание тот факт, что каждая область обычно имеет свою отдельную таблицу страниц.
(**) В версии 6 системы UNIX процесс не может быть выгружен из памяти с целью расчистки места для загружаемого процесса до тех пор, пока загружаемый процесс не проведет на диске 3 секунды. Уходящий из памяти процесс должен провести в памяти не менее 2 секунд. Временной интервал таким образом делится на части, в результате чего повышается производительность системы.
ЗАГРУЗКА СИСТЕМЫ И НАЧАЛЬНЫЙ ПРОЦЕСС
Для того, чтобы перевести систему из неактивное состояние в активное, администратор выполняет процедуру "начальной загрузки". На разных машинах эта процедура имеет свои особенности, однако во всех случаях она реализует одну и ту же цель: загрузить копию операционной системы в основную память машины и запустить ее на исполнение. Обычно процедура начальной загрузки включает в себя несколько этапов. Переключением клавиш на пульте машины администратор может указать адрес специальной программы аппаратной загрузки, а может, нажав только одну клавишу, дать команду машине запустить процедуру загрузки, исполненную в виде микропрограммы. Эта программа может состоять из нескольких команд, подготавливающих запуск другой программы. В системе UNIX процедура начальной загрузки заканчивается считыванием с диска в память блока начальной загрузки (нулевого блока). Программа, содержащаяся в этом блоке, загружает из файловой системы ядро ОС (например, из файла с именем "/unix" или с другим именем, указанным администратором). После загрузки ядра системы в память управление передается по стартовому адресу ядра и ядро запускается на выполнение (алгоритм start, ).
Ядро инициализирует свои внутренние структуры данных. Среди прочих структур ядро создает связные списки свободных буферов и индексов, хеш-очереди для буферов и индексов, инициализирует структуры областей, точки входа в таблицы страниц и т.д. По окончании этой фазы ядро монтирует корневую файловую систему и формирует среду выполнения нулевого процесса, среди всего прочего создавая пространство процесса, инициализируя нулевую точку входа в таблице процесса и делая корневой каталог текущим для процесса.
Когда формирование среды выполнения процесса заканчивается, система исполняется уже в виде нулевого процесса. Нулевой процесс "ветвится", запуская алгоритм fork прямо из ядра, поскольку сам процесс исполняется в режиме ядра. Порожденный нулевым новый процесс, процесс 1, запускается в том же режиме и создает свой пользовательский контекст, формируя область данных и присоединяя ее к своему адресному пространству. Он увеличивает размер области до надлежащей величины и переписывает программу загрузки из адресного пространства ядра в новую область: эта программа теперь будет определять контекст процесса 1. Затем процесс 1 сохраняет регистровый контекст задачи, "возвращается" из режима ядра в режим задачи и исполняет только что переписанную программу. В отличие от нулевого процесса, который является процессом системного уровня, выполняющимся в режиме ядра, процесс 1 относится к пользовательскому уровню. Код, исполняемый процессом 1, включает в себя вызов системной функции exec, запускающей на выполнение программу из файла "/etc/init". Обычно процесс 1 именуется процессом init, поскольку он отвечает за инициализацию новых процессов.
| алгоритм start /* процедура начальной загрузки системы */ входная информация: отсутствует выходная информация: отсутствует { проинициализировать все структуры данных ядра; псевдо-монтирование корня; сформировать среду выполнения процесса 0; создать процесс 1; { /* процесс 1 */ выделить область; подключить область к адресному пространству процесса init; увеличить размер области для копирования в нее ис- полняемого кода; скопировать из пространства ядра в адресное прост- ранство процесса код программы, исполняемой процес- сом; изменить режим выполнения: вернуться из режима ядра в режим задачи; /* процесс init далее выполняется самостоятельно -- * в результате выхода в режим задачи, * init исполняет файл "/etc/init" и становится * "обычным" пользовательским процессом, производя- * щим обращения к системным функциям */ } /* продолжение нулевого процесса */ породить процессы ядра; /* нулевой процесс запускает программу подкачки, управ- * ляющую распределением адресного пространства процес- * сов между основной памятью и устройствами выгрузки. * Это бесконечный цикл; нулевой процесс обычно приоста- * навливает свою работу, если необходимости в нем боль- * ше нет. */ исполнить программу, реализующую алгоритм подкачки; } |
Рисунок 7.30. Алгоритм загрузки системы
Казалось бы, зачем ядру копировать программу, запускаемую с помощью функции exec, в адресное пространство процесса 1? Он мог бы обратиться к внутреннему варианту функции прямо из ядра, однако, по сравнению с уже описанным алгоритмом это было бы гораздо труднее реализовать, ибо в этом случае функции exec пришлось бы производить анализ имен файлов в пространстве ядра, а не в пространстве задачи. Подобная деталь, требующаяся только для процесса init, усложнила бы программу реализации функции exec и отрицательно отразилась бы на скорости выполнения функции в более общих случаях.
Процесс init () выступает диспетчером процессов, который порождает процессы, среди всего прочего позволяющие пользователю регистрироваться в системе. Инструкции о том, какие процессы нужно создать, считываются процессом init из файла "/etc/inittab". Строки файла включают в себя идентификатор состояния "id" (однопользовательский режим, многопользовательский и т. д.), предпринимаемое действие (см. ) и спецификацию программы, реализующей это действие (см. ). Процесс init просматривает строки файла до тех пор, пока не обнаружит идентификатор состояния, соответствующего тому состоянию, в котором находится процесс, и создает процесс, исполняющий программу с указанной спецификацией. Например, при запуске в многопользовательском режиме (состояние 2) процесс init обычно порождает getty-процессы, управляющие функционированием терминальных линий, входящих в состав системы. Если регистрация пользователя прошла успешно, getty-процесс, пройдя через процедуру login, запускает на исполнение регистрационный shell (см. ). Тем временем процесс init находится в состоянии ожидания (wait), наблюдая за прекращением существования своих потомков, а также "внучатых" процессов, оставшихся "сиротами" после гибели своих родителей.
Процессы в системе UNIX могут быть либо пользовательскими, либо управляющими, либо системными. Большинство из них составляют пользовательские процессы, связанные с пользователями через терминалы. Управляющие процессы не связаны с конкретными пользователями, они выполняют широкий спектр системных функций, таких как администрирование и управление сетями, различные периодические операции, буферизация данных для вывода на устройство построчной печати и т.д. Процесс init может порождать управляющие процессы, которые будут существовать на протяжении всего времени жизни системы, в различных случаях они могут быть созданы самими пользователями. Они похожи на пользовательские процессы тем, что они исполняются в режиме задачи и прибегают к услугам системы путем вызова соответствующих системных функций.
Системные процессы выполняются исключительно в режиме ядра. Они могут порождаться нулевым процессом (например, процесс замещения страниц vhand), который затем становится процессом подкачки. Системные процессы похожи на управляющие процессы тем, что они выполняют системные функции, при этом они обладают большими возможностями приоритетного выполнения, поскольку лежащие в их основе программные коды являются составной частью ядра. Они могут обращаться к структурам данных и алгоритмам ядра, не прибегая к вызову системных функций, отсюда вытекает их исключительность. Однако, они не обладают такой же гибкостью, как управляющие процессы, поскольку для того, чтобы внести изменения в их программы, придется еще раз перекомпилировать ядро.
|
алгоритм init /* процесс init, в системе именуемый "процесс 1" */ входная информация: отсутствует выходная информация: отсутствует { fd = open("/etc/inittab",O_RDONLY); while (line_read(fd,buffer)) { /* читать каждую строку файлу */ if (invoked state != buffer state) continue; /* остаться в цикле while */ /* найден идентификатор соответствующего состояния */ if (fork() == 0) { execl("процесс указан в буфере"); exit(); } /* процесс init не дожидается завершения потомка */ /* возврат в цикл while */ } while ((id = wait((int*) 0)) != -1) { /* проверка существования потомка; * если потомок прекратил существование, рассматри- * вается возможность его перезапуска */ /* в противном случае, основной процесс просто про- * должает работу */ } } |
|
Формат: идентификатор, состояние, действие, спецификация процесса Поля разделены между собой двоеточиями Комментарии в конце строки начинаются с символа '#' co::respawn:/etc/getty console console #Консоль в машзале 46:2:respawn:/etc/getty -t 60 tty46 4800H #комментарии |
Comments:
Copyright ©
ЗАХВАТ ФАЙЛА И ЗАПИСИ
В первой версии системы UNIX, разработанной Томпсоном и Ричи, отсутствовал внутренний механизм, с помощью которого процессу мог бы быть обеспечен исключительный доступ к файлу. Механизм захвата был признан излишним, поскольку, как отмечает Ричи, "мы не имеем дела с большими базами данных, состоящими из одного файла, которые поддерживаются независимыми процессами" (см. [Ritchie 81]). Для того, чтобы повысить привлекательность системы UNIX для коммерческих пользователей, работающих с базами данных, в версию V системы ныне включены механизмы захвата файла и записи. Захват файла - это средство, позволяющее запретить другим процессам производить чтение или запись любой части файла, а захват записи - это средство, позволяющее запретить другим процессам производить ввод-вывод указанных записей (частей файла между указанными смещениями). В рассматривается реализация механизма захвата файла и записи.
Comments:
Copyright ©
Закрытие каналов
При закрытии канала процесс выполняет ту же самую процедуру, что и при закрытии обычного файла, за исключением того, что ядро, прежде чем освободить индекс канала, выполняет специальную обработку. Оно уменьшает количество процессов чтения из канала или записи в канал в зависимости от типа файлового дескриптора. Если значение счетчика числа записывающих в канал процессов становится равным 0 и имеются процессы, приостановленные в ожидании чтения данных из канала, ядро возобновляет выполнение последних и они завершают свои операции чтения без возврата каких-либо данных. Если становится равным 0 значение счетчика числа считывающих из канала процессов и имеются процессы, приостановленные в ожидании возможности записи данных в канал, ядро возобновляет выполнение последних и посылает им сигнал () об ошибке. В обоих случаях не имеет смысла продолжать держать процессы приостановленными, если нет надежды на то, что состояние канала когда-нибудь изменится. Например, если процесс ожидает возможности производить чтение из непоименованного канала и в системе больше нет процессов, записывающих в этот канал, значит, записывающий процесс никогда не появится. Несмотря на то, что если канал поименованный, в принципе возможно появление нового считывающего или записывающего процесса, ядро трактует эту ситуацию точно так же, как и для непоименованных каналов. Если к каналу не обращается ни один записывающий или считывающий процесс, ядро освобождает все информационные блоки канала и переустанавливает индекс таким образом, чтобы он указывал на то, что канал пуст. Когда ядро освобождает индекс обычного канала, оно освобождает для переназначения и дисковую копию этого индекса.
Замещение страниц на менее сложной технической базе
Наибольшая действенность алгоритмов замещения страниц по запросу (обращению) достигается в том случае, если биты упоминания и модификации устанавливаются аппаратным путем и тем же путем вызывается отказ системы защиты при попытке записи в страницу, имеющую признак "копирования при записи". Тем не менее, указанные алгоритмы вполне применимы даже тогда, когда аппаратура распознает только бит доступности и код защиты. Если бит доступности, устанавливаемый аппаратно, дублируется программно-устанавливаемым битом, показывающим, действительно ли страница доступна или нет, ядро могло бы отключить аппаратно-устанавливаемый бит и проимитировать установку остальных битов программным путем. Так, например, в машине VAX-11 бит упоминания отсутствует (см. [Levy 82]). Ядро может отключить аппаратно-устанавливаемый бит доступности для страницы и дальше работать по следующему плану. Если процесс ссылается на страницу, он получает отказ, поскольку бит доступности сброшен, и в игру вступает программа обработки отказа, исследующая страницу. Поскольку "программный" бит доступности установлен, ядро знает, что страница действительно доступна и находится в памяти; оно устанавливает "программный" бит упоминания и "аппаратный" бит доступности, но ему еще предстоит узнать о том, что на страницу была сделана ссылка. Последующие ссылки на страницу уже не встретят отказ, ибо "аппаратный" бит доступности установлен. Когда с ней будет работать "сборщик" страниц, он вновь сбросит "аппаратный" бит доступности, вызывая тем самым от казы на все последующие обращения к странице и возвращая систему к началу цикла. Этот случай показан на .

Рисунок 9.28. Имитация установки "аппаратного" бита модификации программными средствами
(***) Если при исполнении команды возникает ошибка, связанная с отсутствием страницы, после обработки ошибки ЦП обязан перезапустить команду, поскольку промежуточные результаты, полученные к моменту возникновения ошибки, могут быть утрачены.
(****) Функция exit используется в варианте _exit, потому что она "очищает" структуры данных, передаваемые через стандартный ввод-вывод (на пользовательском уровне), для обоих процессов, так что оператор printf, используемый родителем, не даст правильный результат - еще один нежелательный побочный эффект от применения функции vfork.
Comments:
Copyright ©
ЗАВЕРШЕНИЕ ВЫПОЛНЕНИЯ ПРОЦЕССА
В системе UNIX процесс завершает свое выполнение, запуская системную функцию exit. После этого процесс переходит в состояние "прекращения существования" (см. ), освобождает ресурсы и ликвидирует свой контекст. Синтаксис вызова функции: exit(status);
где status - значение, возвращаемое функцией родительскому процессу. Процессы могут вызывать функцию exit как в явном, так и в неявном виде (по окончании выполнения программы: начальная процедура (startup), компонуемая со всеми программами на языке Си, вызывает функцию exit на выходе программы из функции main, являющейся общей точкой входа для всех программ). С другой стороны, ядро может вызывать функцию exit по своей инициативе, если процесс не принял посланный ему сигнал (об этом мы уже говорили выше). В этом случае значение параметра status равно номеру сигнала.
Система не накладывает никакого ограничения на продолжительность выполнения процесса, и зачастую процессы существуют в течение довольно длительного времени. Нулевой процесс (программа подкачки) и процесс 1 (init), к примеру, существуют на протяжении всего времени жизни системы. Продолжительными процессами являются также getty-процессы, контролирующие работу терминальной линии, ожидая регистрации пользователей, и процессы общего назначения, выполняемые под руководством администратора.
На приведен алгоритм функции exit. Сначала ядро отменяет обработку всех сигналов, посылаемых процессу, поскольку ее продолжение становится бессмысленным. Если процесс, вызывающий функцию exit, возглавляет группу процессов, ассоциированную с операторским терминалом (см. ), ядро делает предположение о том, что пользователь прекращает работу, и посылает всем процессам в группе сигнал о "зависании". Таким образом, если пользователь в регистрационном shell'е нажмет последовательность клавиш, означающую "конец файла" (Ctrl-d), при этом с терминалом остались связанными некоторые из существующих процессов, процесс, выполняющий функцию exit, пошлет им всем сигнал о "зависании". Кроме того, ядро сбрасывает в ноль значение кода группы процессов для всех процессов, входящих в данную группу, поскольку не исключена возможность того, что позднее текущий код идентификации процесса (процесса, который вызвал функцию exit) будет присвоен другому процессу и тогда последний возглавит группу с указанным кодом. Процессы, входившие в старую группу, в новую группу входить не будут. После этого ядро просматривает дескрипторы открытых файлов, закрывает каждый из этих файлов по алгоритму close и освобождает по алгоритму iput индексы текущего каталога и корня (если он изменялся).
| алгоритм exit входная информация: код, возвращаемый родительскому про- цессу выходная информация: отсутствует { игнорировать все сигналы; если (процесс возглавляет группу процессов, ассоцииро- ванную с операторским терминалом) { послать всем процессам, входящим в группу, сигнал о "зависании"; сбросить в ноль код группы процессов; } закрыть все открытые файлы (внутренняя модификация алго- ритма close); освободить текущий каталог (алгоритм iput); освободить области и память, ассоциированную с процессом (алгоритм freereg); создать запись с учетной информацией; прекратить существование процесса (перевести его в соот- ветствующее состояние); назначить всем процессам-потомкам в качестве родителя процесс init (1); если кто-либо из потомков прекратил существование, послать процессу init сигнал "гибель потомка"; послать сигнал "гибель потомка" родителю данного процес- са; переключить контекст; } |
Рисунок 7.14. Алгоритм функции exit
Наконец, ядро освобождает всю выделенную задаче память вместе с соответствующими областями (по алгоритму detachreg) и переводит процесс в состояние прекращения существования. Ядро сохраняет в таблице процессов код возврата функции exit (status), а также суммарное время исполнения процесса и его потомков в режиме ядра и режиме задачи. В при рассмотрении функции wait будет показано, каким образом процесс получает информацию о времени выполнения своих потомков. Ядро также создает в глобальном учетном файле запись, которая содержит различную статистическую информацию о выполнении процесса, такую как код идентификации пользователя, использование ресурсов центрального процессора и памяти, объем потоков ввода-вывода, связанных с процессом. Пользовательские программы могут в любой момент обратиться к учетному файлу за статистическими данными, представляющими интерес с точки зрения слежения за функционированием системы и организации расчетов с пользователями. Ядро удаляет процесс из дерева процессов, а его потомков передает процессу 1 (init). Таким образом, процесс 1 становится законным родителем всех продолжающих существование потомков завершающегося процесса. Если кто-либо из потомков прекращает существование, завершающийся процесс посылает процессу init сигнал "гибель потомка" для того, чтобы процесс начальной загрузки мог удалить запись о потомке из таблицы процессов (см. ); кроме того, завершающийся процесс посылает этот сигнал своему родителю. В типичной ситуации родительский процесс синхронизирует свое выполнение с завершающимся потомком с помощью системной функции wait. Прекращая существование, процесс переключает контекст и ядро может теперь выбирать для исполнения следующий процесс; ядро с этих пор уже не будет исполнять процесс, прекративший существование.
В программе, приведенной на , процесс создает новый процесс, который печатает свой код идентификации и вызывает системную функцию pause, приостанавливаясь до получения сигнала. Процесс-родитель печатает PID своего потомка и завершается, возвращая только что выведенное значение через параметр status. Если бы вызов функции exit отсутствовал, начальная процедура сделала бы его по выходе процесса из функции main. Порожденный процесс продолжает ожидать получения сигнала, даже если его родитель уже завершился.
Comments:
Copyright ©